Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance.
With this massive data growth, data proliferation across your data stores, data warehouse, and data lakes can become equally challenging. With a modern data architecture on AWS, you can rapidly build scalable data lakes; use a broad and deep collection of purpose-built data services; ensure compliance via unified data access, security, and governance; scale your systems at a low cost without compromising performance; and share data across organizational boundaries with ease, allowing you to make decisions with speed and agility at scale.
You can take all your data from various silos, aggregate that data in your data lake, and perform analytics and machine learning (ML) directly on top of that data. You can also store other data in purpose-built data stores to analyze and get fast insights from both structured and unstructured data. This data movement can be inside-out, outside-in, around the perimeter or sharing across.
For example, application logs and traces from web applications can be collected directly in a data lake, and a portion of that data can be moved out to a log analytics store like Amazon OpenSearch Service for daily analysis. We think of this concept as inside-out data movement. The analyzed and aggregated data stored in Amazon OpenSearch Service can again be moved to the data lake to run ML algorithms for downstream consumption from applications. We refer to this concept as outside-in data movement.
Let’s look at an example use case. Example Corp. is a leading Fortune 500 company that specializes in social content. They have hundreds of applications generating data and traces at approximately 500 TB per day and have the following criteria:
- Have logs available for fast analytics for 2 days
- Beyond 2 days, have data available in a storage tier that can be made available for analytics with a reasonable SLA
- Retain the data beyond 1 week in cold storage for 30 days (for purposes of compliance, auditing, and others)
In the following sections, we discuss three possible solutions to address similar use cases:
- Tiered storage in Amazon OpenSearch Service and data lifecycle management
- On-demand ingestion of logs using Amazon OpenSearch Ingestion
- Amazon OpenSearch Service direct queries with Amazon Simple Storage Service (Amazon S3)
Solution 1: Tiered storage in OpenSearch Service and data lifecycle management
OpenSearch Service supports three integrated storage tiers: hot, UltraWarm, and cold storage. Based on your data retention, query latency, and budgeting requirements, you can choose the best strategy to balance cost and performance. You can also migrate data between different storage tiers.
Hot storage is used for indexing and updating, and provides the fastest access to data. Hot storage takes the form of an instance store or Amazon Elastic Block Store (Amazon EBS) volumes attached to each node.
UltraWarm offers significantly lower costs per GiB for read-only data that you query less frequently and doesn’t need the same performance as hot storage. UltraWarm nodes use Amazon S3 with related caching solutions to improve performance.
Cold storage is optimized to store infrequently accessed or historical data. When you use cold storage, you detach your indexes from the UltraWarm tier, making them inaccessible. You can reattach these indexes in a few seconds when you need to query that data.
For more details on data tiers within OpenSearch Service, refer to Choose the right storage tier for your needs in Amazon OpenSearch Service.
Solution overview
The workflow for this solution consists of the following steps:
- Incoming data generated by the applications is streamed to an S3 data lake.
- Data is ingested into Amazon OpenSearch using S3-SQS near-real-time ingestion through notifications set up on the S3 buckets.
- After 2 days, hot data is migrated to UltraWarm storage to support read queries.
- After 5 days in UltraWarm, the data is migrated to cold storage for 21 days and detached from any compute. The data can be reattached to UltraWarm when needed. Data is deleted from cold storage after 21 days.
- Daily indexes are maintained for easy rollover. An Index State Management (ISM) policy automates the rollover or deletion of indexes that are older than 2 days.
The following is a sample ISM policy that rolls over data into the UltraWarm tier after 2 days, moves it to cold storage after 5 days, and deletes it from cold storage after 21 days:
Considerations
UltraWarm uses sophisticated caching techniques to enable querying for infrequently accessed data. Although the data access is infrequent, the compute for UltraWarm nodes needs to be running all the time to make this access possible.
When operating at PB scale, to reduce the area of effect of any errors, we recommend decomposing the implementation into multiple OpenSearch Service domains when using tiered storage.
The next two patterns remove the need to have long-running compute and describe on-demand techniques where the data is either brought when needed or queried directly where it resides.
Solution 2: On-demand ingestion of logs data through OpenSearch Ingestion
OpenSearch Ingestion is a fully managed data collector that delivers real-time log and trace data to OpenSearch Service domains. OpenSearch Ingestion is powered by the open source data collector Data Prepper. Data Prepper is part of the open source OpenSearch project.
With OpenSearch Ingestion, you can filter, enrich, transform, and deliver your data for downstream analysis and visualization. You configure your data producers to send data to OpenSearch Ingestion. It automatically delivers the data to the domain or collection that you specify. You can also configure OpenSearch Ingestion to transform your data before delivering it. OpenSearch Ingestion is serverless, so you don’t need to worry about scaling your infrastructure, operating your ingestion fleet, and patching or updating the software.
There are two ways that you can use Amazon S3 as a source to process data with OpenSearch Ingestion. The first option is S3-SQS processing. You can use S3-SQS processing when you require near-real-time scanning of files after they are written to S3. It requires an Amazon Simple Queue Service (Amazon S3) queue that receives S3 Event Notifications. You can configure S3 buckets to raise an event any time an object is stored or modified within the bucket to be processed.
Alternatively, you can use a one-time or recurring scheduled scan to batch process data in an S3 bucket. To set up a scheduled scan, configure your pipeline with a schedule at the scan level that applies to all your S3 buckets, or at the bucket level. You can configure scheduled scans with either a one-time scan or a recurring scan for batch processing.
For a comprehensive overview of OpenSearch Ingestion, see Amazon OpenSearch Ingestion. For more information about the Data Prepper open source project, visit Data Prepper.
Solution overview
We present an architecture pattern with the following key components:
- Application logs are streamed into to the data lake, which helps feed hot data into OpenSearch Service in near-real time using OpenSearch Ingestion S3-SQS processing.
- ISM policies within OpenSearch Service handle index rollovers or deletions. ISM policies let you automate these periodic, administrative operations by triggering them based on changes in the index age, index size, or number of documents. For example, you can define a policy that moves your index into a read-only state after 2 days and then deletes it after a set period of 3 days.
- Cold data is available in the S3 data lake to be consumed on demand into OpenSearch Service using OpenSearch Ingestion scheduled scans.
The following diagram illustrates the solution architecture.
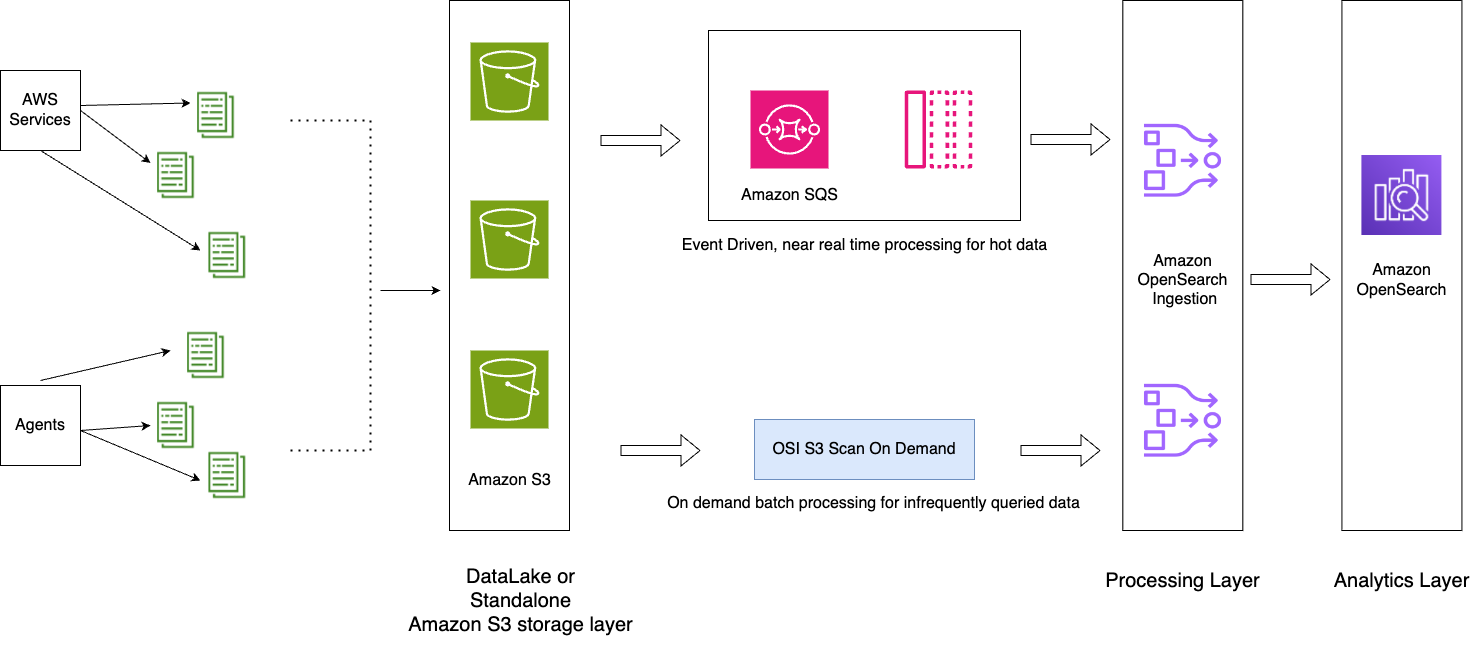
The workflow includes the following steps:
- Incoming data generated by the applications is streamed to the S3 data lake.
- For the current day, data is ingested into OpenSearch Service using S3-SQS near-real-time ingestion through notifications set up in the S3 buckets.
- Daily indexes are maintained for easy rollover. An ISM policy automates the rollover or deletion of indexes that are older than 2 days.
- If a request is made for analysis of data beyond 2 days and the data is not in the UltraWarm tier, data will be ingested using the one-time scan feature of Amazon S3 between the specific time window.
For example, if the present day is January 10, 2024, and you need data from January 6, 2024 at a specific interval for analysis, you can create an OpenSearch Ingestion pipeline with an Amazon S3 scan in your YAML configuration, with the start_time and end_time to specify when you want the objects in the bucket to be scanned:
Considerations
Take advantage of compression
Data in Amazon S3 can be compressed, which reduces your overall data footprint and results in significant cost savings. For example, if you are generating 15 PB of raw JSON application logs per month, you can use a compression mechanism like GZIP, which can reduce the size to approximately 1PB or less, resulting in significant cost savings.
Stop the pipeline when possible
OpenSearch Ingestion scales automatically between the minimum and maximum OCUs set for the pipeline. After the pipeline has completed the Amazon S3 scan for the specified duration mentioned in the pipeline configuration, the pipeline continues to run for continuous monitoring at the minimum OCUs.
For on-demand ingestion for past time durations where you don’t expect new objects to be created, consider using supported pipeline metrics such as recordsOut.count to create Amazon CloudWatch alarms that can stop the pipeline. For a list of supported metrics, refer to Monitoring pipeline metrics.
CloudWatch alarms perform an action when a CloudWatch metric exceeds a specified value for some amount of time. For example, you might want to monitor recordsOut.count to be 0 for longer than 5 minutes to initiate a request to stop the pipeline through the AWS Command Line Interface (AWS CLI) or API.
Solution 3: OpenSearch Service direct queries with Amazon S3
OpenSearch Service direct queries with Amazon S3 (preview) is a new way to query operational logs in Amazon S3 and S3 data lakes without needing to switch between services. You can now analyze infrequently queried data in cloud object stores and simultaneously use the operational analytics and visualization capabilities of OpenSearch Service.
OpenSearch Service direct queries with Amazon S3 provides zero-ETL integration to reduce the operational complexity of duplicating data or managing multiple analytics tools by enabling you to directly query your operational data, reducing costs and time to action. This zero-ETL integration is configurable within OpenSearch Service, where you can take advantage of various log type templates, including predefined dashboards, and configure data accelerations tailored to that log type. Templates include VPC Flow Logs, Elastic Load Balancing logs, and NGINX logs, and accelerations include skipping indexes, materialized views, and covered indexes.
With OpenSearch Service direct queries with Amazon S3, you can perform complex queries that are critical to security forensics and threat analysis and correlate data across multiple data sources, which aids teams in investigating service downtime and security events. After you create an integration, you can start querying your data directly from OpenSearch Dashboards or the OpenSearch API. You can audit connections to ensure that they are set up in a scalable, cost-efficient, and secure way.
Direct queries from OpenSearch Service to Amazon S3 use Spark tables within the AWS Glue Data Catalog. After the table is cataloged in your AWS Glue metadata catalog, you can run queries directly on your data in your S3 data lake through OpenSearch Dashboards.
Solution overview
The following diagram illustrates the solution architecture.
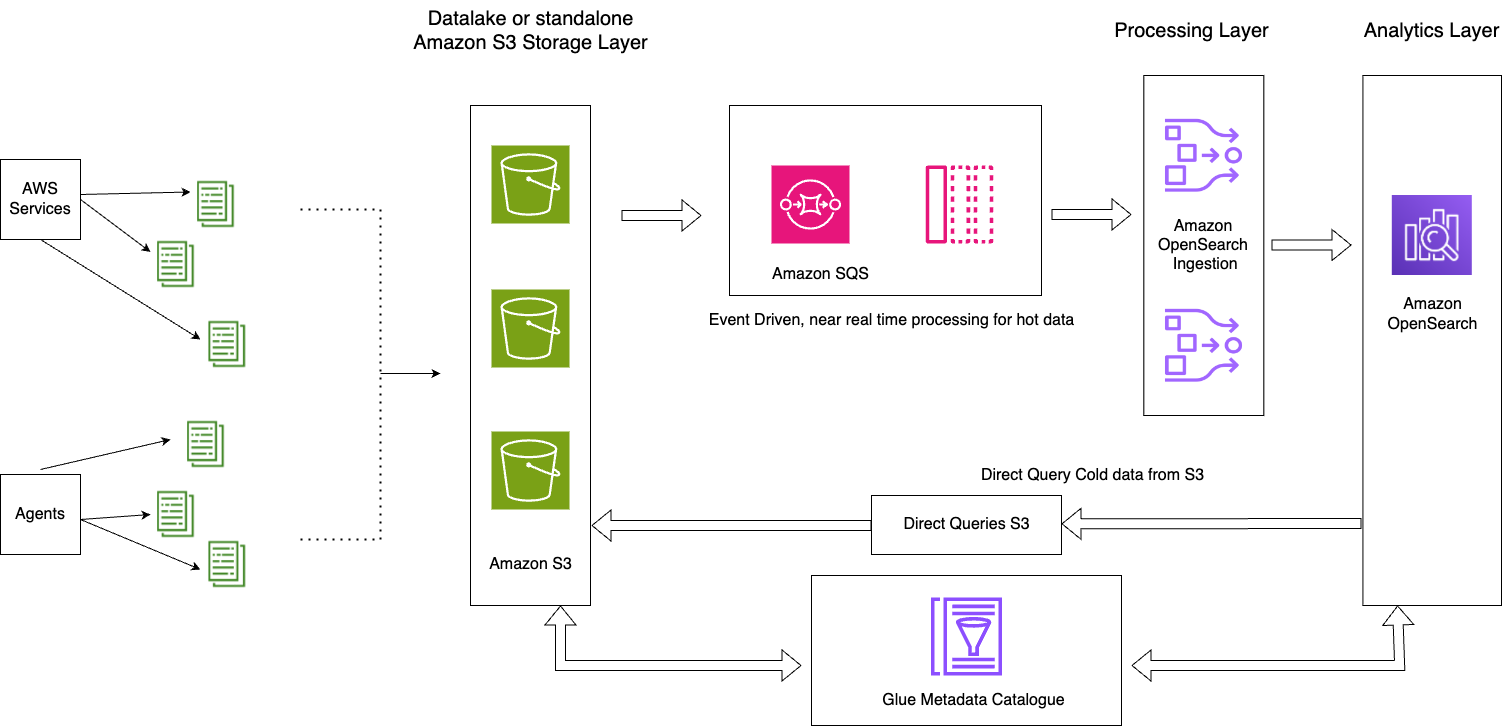
This solution consists of the following key components:
- The hot data for the current day is stream processed into OpenSearch Service domains through the event-driven architecture pattern using the OpenSearch Ingestion S3-SQS processing feature
- The hot data lifecycle is managed through ISM policies attached to daily indexes
- The cold data resides in your Amazon S3 bucket, and is partitioned and cataloged
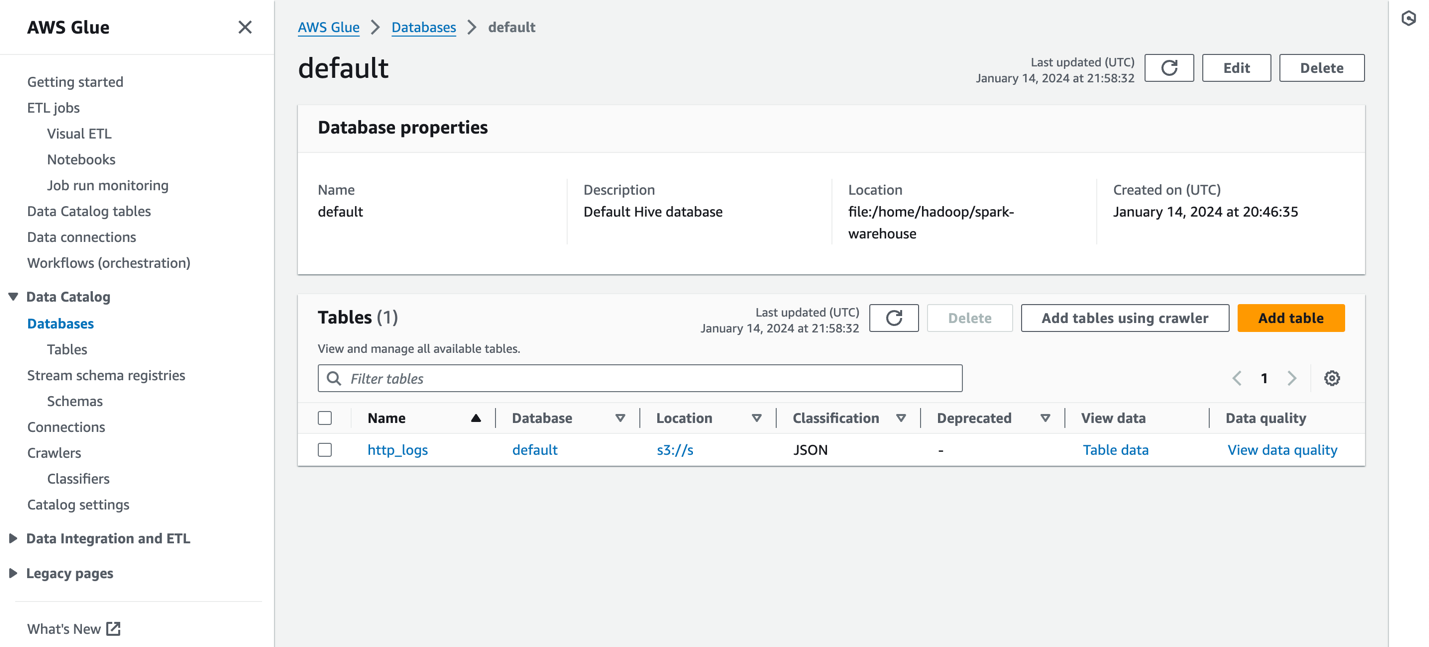
The following screenshot shows a sample http_logs table that is cataloged in the AWS Glue metadata catalog. For detailed steps, refer to Data Catalog and crawlers in AWS Glue.
Before you create a data source, you should have an OpenSearch Service domain with version 2.11 or later and a target S3 table in the AWS Glue Data Catalog with the appropriate AWS Identity and Access Management (IAM) permissions. IAM will need access to the desired S3 buckets and have read and write access to the AWS Glue Data Catalog. The following is a sample role and trust policy with appropriate permissions to access the AWS Glue Data Catalog through OpenSearch Service:
The following is a sample custom policy with access to Amazon S3 and AWS Glue:
To create a new data source on the OpenSearch Service console, provide the name of your new data source, specify the data source type as Amazon S3 with the AWS Glue Data Catalog, and choose the IAM role for your data source.
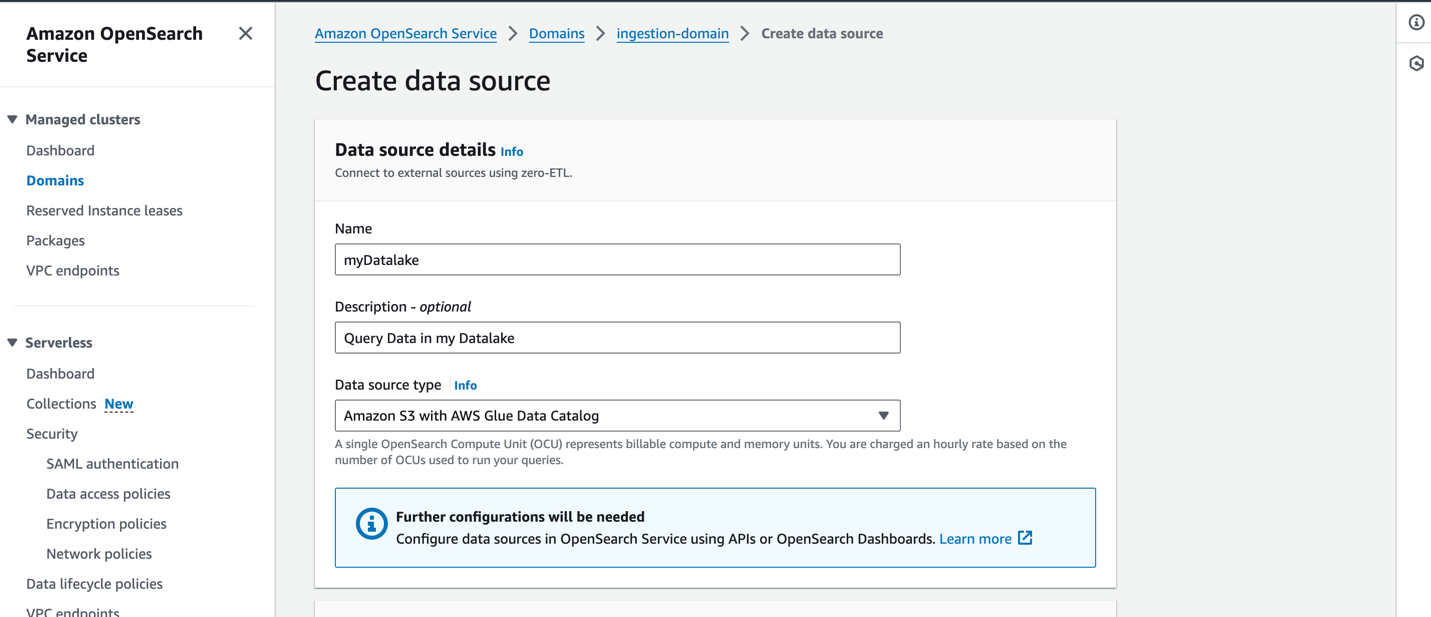
After you create a data source, you can go to the OpenSearch dashboard of the domain, which you use to configure access control, define tables, set up log type-based dashboards for popular log types, and query your data.

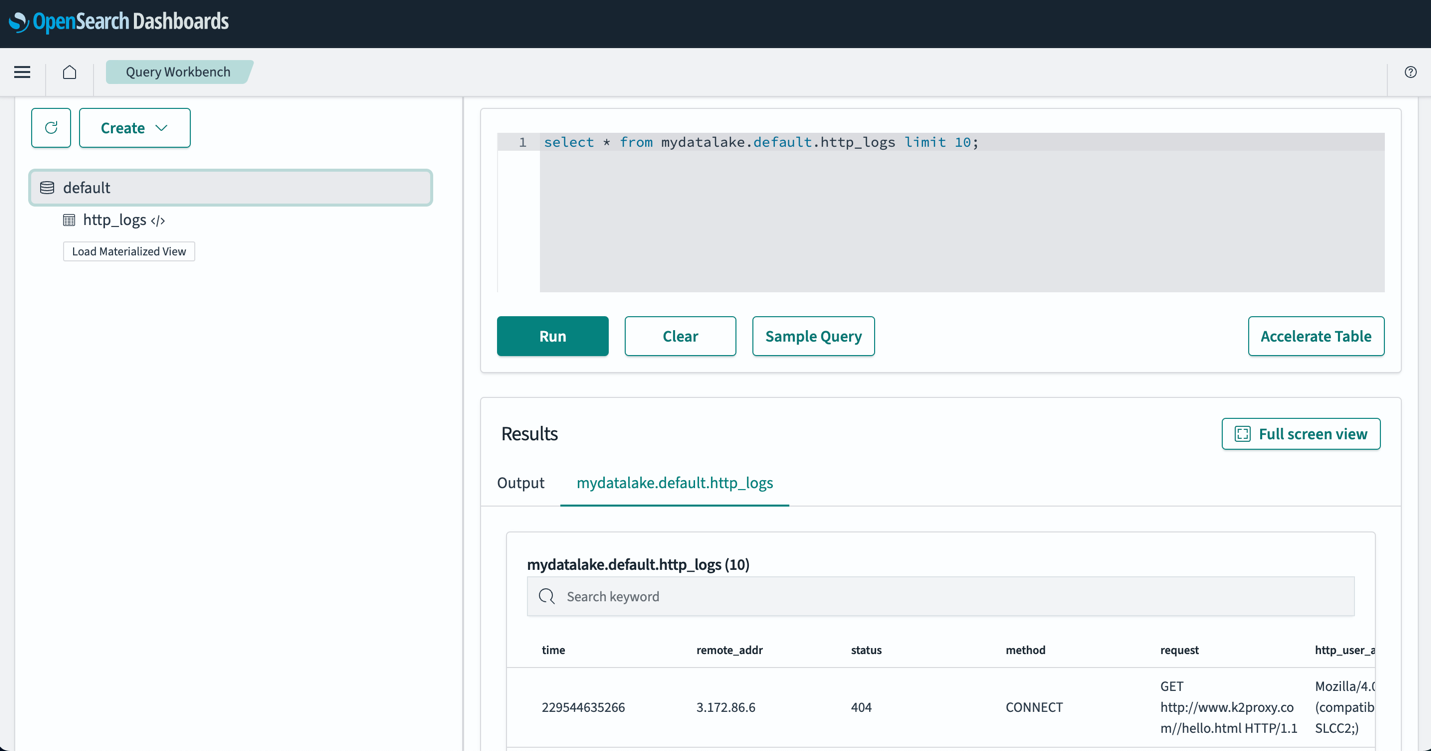
After you set up your tables, you can query your data in your S3 data lake through OpenSearch Dashboards. You can run a sample SQL query for the http_logs table you created in the AWS Glue Data Catalog tables, as shown in the following screenshot.
Best practices
Ingest only the data you need
Work backward from your business needs and establish the right datasets you’ll need. Evaluate if you can avoid ingesting noisy data and ingest only curated, sampled, or aggregated data. Using these cleaned and curated datasets will help you optimize the compute and storage resources needed to ingest this data.
Reduce the size of data before ingestion
When you design your data ingestion pipelines, use strategies such as compression, filtering, and aggregation to reduce the size of the ingested data. This will permit smaller data sizes to be transferred over the network and stored in your data layer.
Conclusion
In this post, we discussed solutions that enable petabyte-scale log analytics using OpenSearch Service in a modern data architecture. You learned how to create a serverless ingestion pipeline to deliver logs to an OpenSearch Service domain, manage indexes through ISM policies, configure IAM permissions to start using OpenSearch Ingestion, and create the pipeline configuration for data in your data lake. You also learned how to set up and use the OpenSearch Service direct queries with Amazon S3 feature (preview) to query data from your data lake.
To choose the right architecture pattern for your workloads when using OpenSearch Service at scale, consider the performance, latency, cost and data volume growth over time in order to make the right decision.
- Use Tiered storage architecture with Index State Management policies when you need fast access to your hot data and want to balance the cost and performance with UltraWarm nodes for read-only data.
- Use On Demand Ingestion of your data into OpenSearch Service when you can tolerate ingestion latencies to query your data not retained in your hot nodes. You can achieve significant cost savings when using compressed data in Amazon S3 and ingesting data on demand into OpenSearch Service.
- Use Direct query with S3 feature when you want to directly analyze your operational logs in Amazon S3 with the rich analytics and visualization features of OpenSearch Service.
As a next step, refer to the Amazon OpenSearch Developer Guide to explore logs and metric pipelines that you can use to build a scalable observability solution for your enterprise applications.
About the Authors
 Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
 Muthu Pitchaimani is a Senior Specialist Solutions Architect with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Senior Specialist Solutions Architect with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
 Sam Selvan is a Principal Specialist Solution Architect with Amazon OpenSearch Service.
Sam Selvan is a Principal Specialist Solution Architect with Amazon OpenSearch Service.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

