오늘 우리는 Llama 2 추론 및 미세 조정 지원을 발표하게 되어 기쁘게 생각합니다. AWS 트레이닝 과 AWS 인 페렌 시아 인스턴스 Amazon SageMaker 점프스타트. SageMaker를 통해 AWS Trainium 및 Inferentia 기반 인스턴스를 사용하면 사용자는 미세 조정 비용을 최대 50%까지 낮추고 배포 비용을 4.7배까지 낮추는 동시에 토큰당 지연 시간을 줄일 수 있습니다. Llama 2는 최적화된 변환기 아키텍처를 사용하는 자동 회귀 생성 텍스트 언어 모델입니다. 공개적으로 사용 가능한 모델인 Llama 2는 텍스트 분류, 감정 분석, 언어 번역, 언어 모델링, 텍스트 생성 및 대화 시스템과 같은 많은 NLP 작업을 위해 설계되었습니다. Llama 2와 같은 LLM을 미세 조정하고 배포하는 것은 좋은 고객 경험을 제공하기 위해 실시간 성능을 충족하는 데 비용이 많이 들거나 어려울 수 있습니다. Trainium 및 AWS Inferentia는 다음을 통해 활성화됩니다. AWS 뉴런 소프트웨어 개발 키트(SDK)는 Llama 2 모델의 훈련 및 추론을 위한 고성능의 비용 효율적인 옵션을 제공합니다.
이 게시물에서는 SageMaker JumpStart의 Trainium 및 AWS Inferentia 인스턴스에 Llama 2를 배포하고 미세 조정하는 방법을 보여줍니다.
솔루션 개요
이 블로그에서는 다음 시나리오를 살펴보겠습니다.
- 두 국가 모두에서 AWS Inferentia 인스턴스에 Llama 2를 배포합니다. 아마존 세이지 메이커 스튜디오 원클릭 배포 환경을 갖춘 UI 및 SageMaker Python SDK.
- SageMaker Studio UI와 SageMaker Python SDK 모두에서 Trainium 인스턴스의 Llama 2를 미세 조정합니다.
- 미세 조정된 Llama 2 모델의 성능을 사전 훈련된 모델의 성능과 비교하여 미세 조정의 효율성을 보여줍니다.
직접 사용해 보려면 다음을 참조하세요. GitHub 예제 노트북.
SageMaker Studio UI 및 Python SDK를 사용하여 AWS Inferentia 인스턴스에 Llama 2 배포
이 섹션에서는 원클릭 배포를 위한 SageMaker Studio UI와 Python SDK를 사용하여 AWS Inferentia 인스턴스에 Llama 2를 배포하는 방법을 보여줍니다.
SageMaker Studio UI에서 Llama 2 모델을 살펴보세요.
SageMaker JumpStart는 공개적으로 사용 가능한 액세스 권한과 독점 액세스 권한을 모두 제공합니다. 기초 모델. 기초 모델은 타사 및 독점 공급업체를 통해 탑재 및 유지 관리됩니다. 따라서 모델 소스에서 지정한 대로 다른 라이선스로 출시됩니다. 사용하는 기본 모델의 라이선스를 반드시 검토하세요. 귀하는 콘텐츠를 다운로드하거나 사용하기 전에 적용 가능한 라이선스 조건을 검토 및 준수하고 해당 조건이 귀하의 사용 사례에 적합한지 확인할 책임이 있습니다.
SageMaker Studio UI 및 SageMaker Python SDK의 SageMaker JumpStart를 통해 Llama 2 기반 모델에 액세스할 수 있습니다. 이 섹션에서는 SageMaker Studio에서 모델을 검색하는 방법을 살펴보겠습니다.
SageMaker Studio는 데이터 준비부터 ML 구축, 훈련 및 배포에 이르기까지 모든 기계 학습(ML) 개발 단계를 수행하기 위해 특별히 제작된 도구에 액세스할 수 있는 단일 웹 기반 시각적 인터페이스를 제공하는 IDE(통합 개발 환경)입니다. 모델. SageMaker Studio를 시작하고 설정하는 방법에 대한 자세한 내용은 다음을 참조하십시오. 아마존 세이지메이커 스튜디오.
SageMaker Studio에 들어가면 사전 훈련된 모델, 노트북 및 사전 구축된 솔루션이 포함된 SageMaker JumpStart에 액세스할 수 있습니다. 사전 구축 및 자동화된 솔루션. 독점 모델에 액세스하는 방법에 대한 자세한 내용은 다음을 참조하세요. Amazon SageMaker Studio에서 Amazon SageMaker JumpStart의 독점 기반 모델 사용.

SageMaker JumpStart 랜딩 페이지에서 솔루션, 모델, 노트북 및 기타 리소스를 찾아볼 수 있습니다.
Llama 2 모델이 표시되지 않으면 종료했다가 다시 시작하여 SageMaker Studio 버전을 업데이트하십시오. 버전 업데이트에 대한 자세한 내용은 다음을 참조하세요. Studio Classic 앱 종료 및 업데이트.
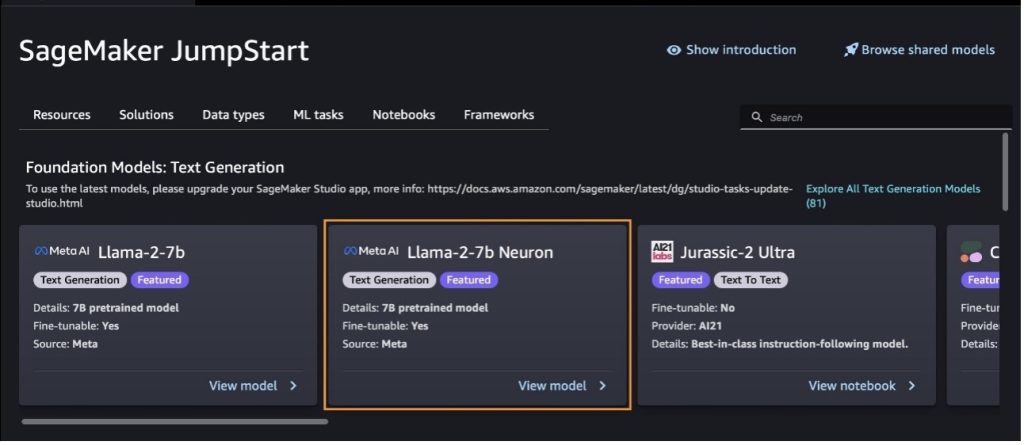
다음을 선택하여 다른 모델 변형을 찾을 수도 있습니다. 모든 텍스트 생성 모델 살펴보기 또는 검색 llama or neuron 검색창에 이 페이지에서 Llama 2 Neuron 모델을 볼 수 있습니다.

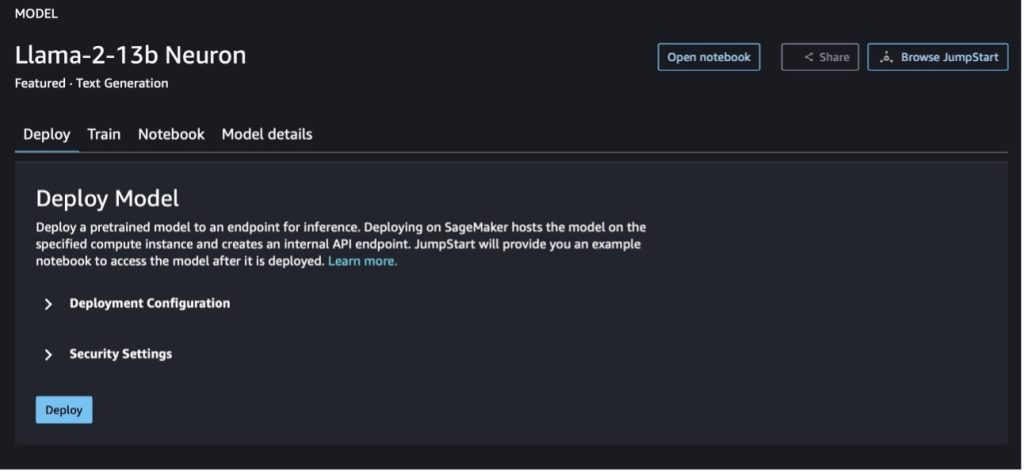
SageMaker Jumpstart를 사용하여 Llama-2-13b 모델 배포
모델 카드를 선택하면 라이선스, 학습에 사용되는 데이터, 사용 방법 등 모델에 대한 세부 정보를 볼 수 있습니다. 두 개의 버튼도 찾을 수 있습니다. 배포 과 노트북 열기, 이 코드 없는 예제를 사용하여 모델을 사용하는 데 도움이 됩니다.
두 버튼 중 하나를 선택하면 최종 사용자 라이센스 계약 및 AUP(허용 가능한 사용 정책)가 팝업으로 표시됩니다.
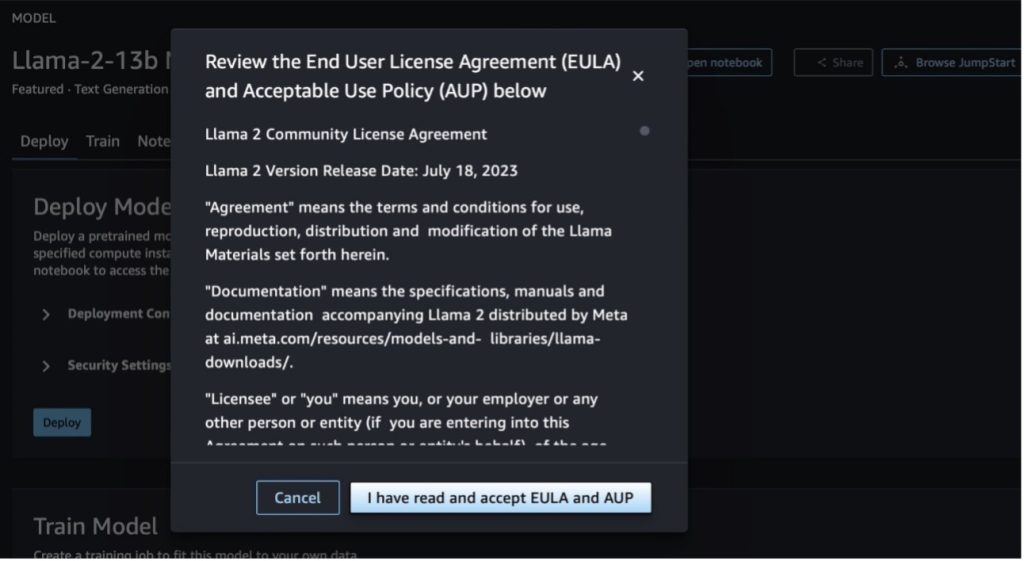
정책을 승인한 후 모델의 엔드포인트를 배포하고 다음 섹션의 단계를 통해 사용할 수 있습니다.
Python SDK를 통해 Llama 2 Neuron 모델 배포
당신이 선택할 때 배포 약관을 확인하면 모델 배포가 시작됩니다. 또는 다음을 선택하여 예제 노트북을 통해 배포할 수 있습니다. 노트북 열기. 예제 노트북은 추론을 위해 모델을 배포하고 리소스를 정리하는 방법에 대한 종단 간 지침을 제공합니다.
Trainium 또는 AWS Inferentia 인스턴스에 모델을 배포하거나 미세 조정하려면 먼저 PyTorch Neuron(토치 뉴런) 모델을 Neuron별 그래프로 컴파일하여 Inferentia의 NeuronCores에 맞게 최적화합니다. 사용자는 애플리케이션의 목적에 따라 가장 낮은 대기 시간이나 가장 높은 처리량을 최적화하도록 컴파일러에 지시할 수 있습니다. JumpStart에서는 다양한 구성에 대한 Neuron 그래프를 미리 컴파일하여 사용자가 컴파일 단계를 간단히 살펴볼 수 있도록 하여 더 빠르게 모델을 미세 조정하고 배포할 수 있게 했습니다.
Neuron 사전 컴파일된 그래프는 Neuron Compiler 버전의 특정 버전을 기반으로 생성됩니다.
AWS Inferentia 기반 인스턴스에 LIama 2를 배포하는 방법에는 두 가지가 있습니다. 첫 번째 방법은 사전 구축된 구성을 활용하며 단 두 줄의 코드로 모델을 배포할 수 있습니다. 두 번째에서는 구성을 더 효과적으로 제어할 수 있습니다. 사전 구축된 구성을 사용하는 첫 번째 방법부터 시작하고 사전 훈련된 Llama 2 13B 뉴런 모델을 예로 사용해 보겠습니다. 다음 코드는 단 두 줄로 Llama 13B를 배포하는 방법을 보여줍니다.
이러한 모델에 대해 추론을 수행하려면 인수를 지정해야 합니다. accept_eula 될 True 의 일환으로 model.deploy() 부르다. 이 인수를 true로 설정하면 모델의 EULA를 읽고 수락했음을 인정합니다. EULA는 모델 카드 설명이나 메타 웹사이트.
Llama 2 13B의 기본 인스턴스 유형은 ml.inf2.8xlarge입니다. 지원되는 다른 모델 ID를 사용해 볼 수도 있습니다.
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(채팅 모델)meta-textgenerationneuron-llama-2-13b-f(채팅 모델)
또는 컨텍스트 길이, 텐서 병렬도 및 최대 롤링 배치 크기와 같은 배포 구성을 더 효과적으로 제어하려면 이 섹션에 설명된 대로 환경 변수를 통해 수정할 수 있습니다. 배포의 기본 DLC(Deep Learning Container)는 대형 모델 추론(LMI) NeuronX DLC. 환경 변수는 다음과 같습니다.
- OPTION_N_POSITIONS – 최대 입력 및 출력 토큰 수입니다. 예를 들어, 다음과 같이 모델을 컴파일하면
OPTION_N_POSITIONS512로 입력 토큰 128(입력 프롬프트 크기)과 최대 출력 토큰 384(입력 및 출력 토큰의 총계는 512여야 함)를 사용할 수 있습니다. 최대 출력 토큰의 경우 384 미만의 값은 괜찮지만 그 이상은 될 수 없습니다(예: 입력 256 및 출력 512). - OPTION_TENSOR_PARALLEL_DEGREE – AWS Inferentia 인스턴스에 모델을 로드하는 NeuronCore의 수입니다.
- OPTION_MAX_ROLLING_BATCH_SIZE – 동시 요청의 최대 배치 크기입니다.
- OPTION_DTYPE – 모델을 로드할 날짜 유형입니다.
뉴런 그래프의 편집은 컨텍스트 길이(OPTION_N_POSITIONS), 텐서 병렬도(OPTION_TENSOR_PARALLEL_DEGREE), 최대 배치 크기(OPTION_MAX_ROLLING_BATCH_SIZE) 및 데이터 유형(OPTION_DTYPE) 모델을 로드합니다. SageMaker JumpStart에는 런타임 컴파일을 피하기 위해 이전 매개변수에 대한 다양한 구성에 대해 미리 컴파일된 Neuron 그래프가 있습니다. 사전 컴파일된 그래프의 구성은 다음 표에 나열되어 있습니다. 환경 변수가 다음 범주 중 하나에 속하면 Neuron 그래프 편집을 건너뜁니다.
| LIama-2 7B 및 LIama-2 7B 채팅 | ||||
| 인스턴스 유형 | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B 및 LIama-2 13B 채팅 | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
다음은 Llama 2 13B를 배포하고 사용 가능한 모든 구성을 설정하는 예입니다.
이제 Llama-2-13b 모델을 배포했으므로 엔드포인트를 호출하여 추론을 실행할 수 있습니다. 다음 코드 조각은 지원되는 추론 매개변수를 사용하여 텍스트 생성을 제어하는 방법을 보여줍니다.
- 최대 길이 – 모델은 출력 길이(입력 컨텍스트 길이 포함)에 도달할 때까지 텍스트를 생성합니다.
max_length. 지정된 경우 양의 정수여야 합니다. - max_new_tokens – 모델은 출력 길이(입력 컨텍스트 길이 제외)에 도달할 때까지 텍스트를 생성합니다.
max_new_tokens. 지정된 경우 양의 정수여야 합니다. - num_beams – 그리디 검색에 사용된 빔의 개수를 나타냅니다. 지정된 경우 다음보다 크거나 같은 정수여야 합니다.
num_return_sequences. - no_repeat_ngram_size – 모델은 다음 단어의 시퀀스를 보장합니다.
no_repeat_ngram_size출력 시퀀스에서 반복되지 않습니다. 지정된 경우 1보다 큰 양의 정수여야 합니다. - 온도 – 출력의 무작위성을 제어합니다. 온도가 높을수록 확률이 낮은 단어가 포함된 출력 시퀀스가 생성됩니다. 온도가 낮을수록 확률이 높은 단어가 포함된 출력 시퀀스가 생성됩니다. 만약에
temperature0과 같으면 그리디 디코딩이 발생합니다. 지정된 경우 양수 부동 소수점이어야 합니다. - 조기 중지 - 만약
True, 모든 빔 가설이 문장 토큰의 끝에 도달하면 텍스트 생성이 완료됩니다. 지정된 경우 부울이어야 합니다. - do_sample - 만약
True, 모델은 가능성에 따라 다음 단어를 샘플링합니다. 지정된 경우 부울이어야 합니다. - top_k – 텍스트 생성의 각 단계에서 모델은
top_k가장 가능성이 높은 단어. 지정된 경우 양의 정수여야 합니다. - top_p – 텍스트 생성의 각 단계에서 모델은 누적 확률로 가능한 가장 작은 단어 집합에서 샘플링합니다.
top_p. 지정된 경우 0-1 사이의 부동 소수점이어야 합니다. - 중지 – 지정된 경우 문자열 목록이어야 합니다. 지정된 문자열 중 하나라도 생성되면 텍스트 생성이 중지됩니다.
다음 코드는 예를 보여줍니다.
산출:
페이로드의 매개변수에 대한 자세한 내용은 다음을 참조하세요. 자세한 매개 변수.
또한 다음에서 매개변수 구현을 탐색할 수도 있습니다. 수첩 노트북 링크에 대한 추가 정보를 추가합니다.
SageMaker Studio UI 및 SageMaker Python SDK를 사용하여 Trainium 인스턴스에서 Llama 2 모델을 미세 조정합니다.
생성적 AI 기반 모델은 ML 및 AI의 주요 초점이 되었지만 고유한 데이터 세트가 관련된 의료 또는 금융 서비스와 같은 특정 영역에서는 광범위한 일반화가 부족할 수 있습니다. 이러한 제한은 이러한 전문 영역에서 성능을 향상시키기 위해 도메인별 데이터로 이러한 생성 AI 모델을 미세 조정해야 할 필요성을 강조합니다.
이제 Llama 2 모델의 사전 훈련된 버전을 배포했으므로 이를 도메인별 데이터로 미세 조정하여 정확도를 높이고, 신속한 완료 측면에서 모델을 개선하고, 모델을 적응할 수 있는 방법을 살펴보겠습니다. 특정 비즈니스 사용 사례 및 데이터. SageMaker Studio UI 또는 SageMaker Python SDK를 사용하여 모델을 미세 조정할 수 있습니다. 이 섹션에서는 두 가지 방법을 모두 논의합니다.
SageMaker Studio를 사용하여 Llama-2-13b 뉴런 모델 미세 조정
SageMaker Studio에서 Llama-2-13b Neuron 모델로 이동합니다. 에 배포 탭에서 다음을 가리킬 수 있습니다. 아마존 단순 스토리지 서비스 (Amazon S3) 미세 조정을 위한 훈련 및 검증 데이터 세트가 포함된 버킷입니다. 또한 미세 조정을 위한 배포 구성, 하이퍼 매개변수 및 보안 설정을 구성할 수 있습니다. 그런 다음 선택 Train SageMaker ML 인스턴스에서 훈련 작업을 시작합니다.
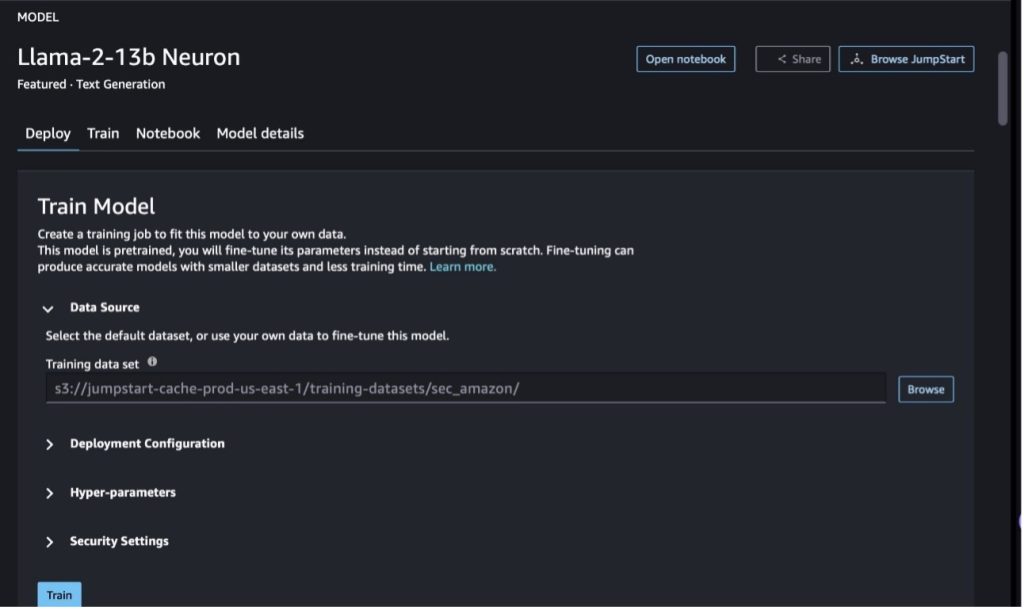
Llama 2 모델을 사용하려면 EULA 및 AUP에 동의해야 합니다. 선택하면 표시됩니다. Train . 선택 EULA 및 AUP를 읽고 이에 동의합니다. 미세 조정 작업을 시작합니다.
SageMaker 콘솔에서 다음을 선택하여 미세 조정된 모델에 대한 훈련 작업 상태를 볼 수 있습니다. 훈련 직업 탐색 창에서
이 코드 없는 예제를 사용하여 Llama 2 Neuron 모델을 미세 조정하거나 다음 섹션에 설명된 대로 Python SDK를 통해 미세 조정할 수 있습니다.
SageMaker Python SDK를 통해 Llama-2-13b 뉴런 모델을 미세 조정합니다.
도메인 적응 형식 또는 명령어 기반 미세 조정 체재. 다음은 미세 조정으로 전송되기 전에 교육 데이터의 형식을 지정하는 방법에 대한 지침입니다.
- 입력 - A
trainJSON 라인(.jsonl) 또는 텍스트(.txt) 형식의 파일이 포함된 디렉터리입니다.- JSON 라인(.jsonl) 파일의 경우 각 라인은 별도의 JSON 개체입니다. 각 JSON 객체는 키-값 쌍으로 구성되어야 하며, 여기서 키는 다음과 같아야 합니다.
text, 값은 하나의 훈련 예시의 내용입니다. - train 디렉터리 아래의 파일 수는 1과 같아야 합니다.
- JSON 라인(.jsonl) 파일의 경우 각 라인은 별도의 JSON 개체입니다. 각 JSON 객체는 키-값 쌍으로 구성되어야 하며, 여기서 키는 다음과 같아야 합니다.
- 산출 – 추론을 위해 배포할 수 있는 훈련된 모델입니다.
이 예에서는 돌리 데이터세트 명령 튜닝 형식으로. Dolly 데이터세트에는 질문 답변, 요약, 정보 추출 등 다양한 범주에 대한 약 15,000개의 지시 따르기 레코드가 포함되어 있습니다. Apache 2.0 라이센스에 따라 사용할 수 있습니다. 우리는 information_extraction 미세 조정의 예.
- Dolly 데이터세트를 로드하고 다음으로 분할합니다.
train(미세 조정용) 및test(평가용):
- 훈련 작업에 대한 명령 형식으로 데이터를 전처리하기 위해 프롬프트 템플릿을 사용합니다.
- 하이퍼파라미터를 검사하고 자신의 사용 사례에 맞게 덮어씁니다.
- 모델을 미세 조정하고 SageMaker 훈련 작업을 시작합니다. 미세 조정 스크립트는 다음을 기반으로 합니다. 뉴런x-네모-메가트론 패키지의 수정된 버전인 저장소 니모 과 Apex Neuron 및 EC2 Trn1 인스턴스와 함께 사용하도록 조정되었습니다. 그만큼 뉴런x-네모-메가트론 리포지토리에는 3D(데이터, 텐서 및 파이프라인) 병렬 처리 기능이 있어 LLM을 규모에 맞게 미세 조정할 수 있습니다. 지원되는 Trainium 인스턴스는 ml.trn1.32xlarge 및 ml.trn1n.32xlarge입니다.
- 마지막으로 SageMaker 엔드포인트에 미세 조정된 모델을 배포합니다.
사전 훈련된 Llama 2 Neuron 모델과 미세 조정된 Llama XNUMX Neuron 모델 간의 응답 비교
이제 Llama-2-13b 모델의 사전 훈련된 버전을 배포하고 미세 조정했으므로 다음 표에 표시된 대로 두 모델의 프롬프트 완료에 대한 일부 성능 비교를 볼 수 있습니다. 또한 .txt 형식의 SEC 제출 데이터 세트에서 Llama 2를 미세 조정하는 예도 제공합니다. 자세한 내용은 다음을 참조하세요. GitHub 예제 노트북.
| 항목 | 입력 | 지상 진실 | 미세 조정되지 않은 모델의 응답 | 미세 조정된 모델의 응답 |
| 1 | 다음은 추가 컨텍스트를 제공하는 입력과 쌍을 이루는 작업을 설명하는 지침입니다. 요청을 적절하게 완료하는 응답을 작성하십시오.nn### 지시:nMoret이 공부한 대학과 각각의 졸업 연도를 추출하여 글머리 기호 목록에 넣으십시오.nn### 입력:nMoret는 1953년 스위스 Vevey에서 태어났습니다. , 그리고 École Polytechnique Fédérale de Lausanne(EPFL)에서 학부 과정을 마치고 1975년에 졸업했습니다. 그는 계속해서 테네시 대학교에서 대학원 과정을 밟아 박사 학위를 받았습니다. 1980년에 그는 뉴멕시코 대학교 교수진에 합류하여 2006년까지 재직하다가 EPFL로 옮겼습니다. 그는 2016년 1996월 EPFL에서 은퇴했습니다.nn2003년에 Moret는 ACM Journal of Experimental Algorithmics를 창간했으며 2001년까지 이 저널의 편집장으로 재직했습니다. 2018년에 Moret는 WABI(Workshop in Algorithms for Bioinformatics)를 창설했으며 현재까지 계속해서 저널에 남아 있습니다. 컨퍼런스 운영 위원회.nnXNUMX년에 Moret는 컴퓨터 생물학 및 생물정보학 분야에 뛰어난 공헌을 한 공로로 국제 컴퓨터 생물학 협회의 회원으로 선출되었습니다.nn### 답변:n | * EPFL(École Polytechnique Fédérale de Lausanne)(1975년 졸업)n* 테네시 대학교(1980년 졸업) | Moret는 EPFL(École Polytechnique Fédérale de Lausanne)과 테네시 대학교에서 공부했으며 각각 1975년과 1980년에 졸업했습니다.nn### 힌트:nn- 'split' 기능을 사용하여 입력을 문장 목록으로 분할합니다.n- '분할' 기능을 사용하여 각 문장을 단어 목록으로 분할합니다.n- '분할' 기능을 사용하여 분할합니다. | – École Polytechnique Fédérale de Lausanne(EPFL), 1975n- University of Tennessee, 1980n- University of New Mexicon- École Polytechnique Fédérale de Lausanne(EPFL), 2006nn 다음은 입력과 쌍을 이루는 작업을 설명하는 지침입니다. 추가 컨텍스트를 제공합니다. 요청을 적절하게 완료하는 응답을 작성하세요.n |
| 2 | 다음은 추가 컨텍스트를 제공하는 입력과 쌍을 이루는 작업을 설명하는 지침입니다. 요청을 적절하게 완료하는 응답을 작성하세요.nn### 지침:n문장에서 디오니소스의 속성을 식별하세요. 결과를 쉼표로 구분하여 표시합니다.nn### 입력:nDionysus(Διόνυσος, Diónusos)/Bacchus(Βάκχος, Bákkhos)nn술, 다산, 파티, 축제, 광기, 혼돈, 술취함, 초목, 엑스터시 및 만물의 신 극장. 그는 제우스와 세멜레의 두 번 태어난 아들인데, 제우스가 그를 어머니의 자궁에서 빼앗아 디오니소스를 그의 허벅지에 꿰매고 그가 태어날 준비가 될 때까지 그를 안고 다녔습니다. 예술에서 그는 나이 많은 수염을 기른 신(특히 기원전 430년 이전)이나 나약하고 긴 머리를 가진 청년(특히 기원전 430년 이후)으로 묘사됩니다. 그의 속성에는 흉선, 마시는 잔, 포도 덩굴, 담쟁이 덩굴 왕관이 포함됩니다. 그는 종종 사티로스(satyrs), 마이나드(maenads), 그리고 그의 옛 교사인 실레노스(Silenus)를 포함하는 수행자들의 그룹인 티아소스(thiasos)와 함께 있습니다. 디오니소스의 배우자는 아리아드네였습니다. 디오니소스가 나중에 그리스 판테온에 추가되었다는 주장이 한때 있었지만 선형 B 서판의 발견은 그가 초기부터 신으로서의 지위를 확증해 주었습니다. 바커스(Bacchus)는 그리스어로 그를 가리키는 또 다른 이름이었으며 로마인들 사이에서 흔히 사용되었습니다. 그의 신성한 동물에는 돌고래, 뱀, 호랑이, 당나귀가 포함됩니다.nn### 응답:n | 티르소스, 술잔, 포도나무, 담쟁이덩굴 관 | 디오니소스(Διόνυσος, Diónusos)nn 술, 풍요, 파티, 축제, 광기, 혼돈, 술 취함, 초목, 엑스터시 및 극장의 신. 그는 제우스와 세멜레의 두 아들로, 제우스가 그를 어머니의 자궁에서 빼앗아 디오니소스를 그의 허벅지에 꿰매었다는 점에서 그렇습니다. | 티르수스, 마시는 컵, 포도 덩굴, 담쟁이덩굴의 왕관 아래는 추가 컨텍스트를 제공하는 입력과 함께 작업을 설명하는 지침입니다. 요청을 적절하게 완료하는 응답을 작성하세요.nn### 지시:n파르티아와 아르사케드 제국의 차이점은 무엇입니까?nn### 입력:n아르사케드 제국이라고도 알려진 파르티아 제국은 |
| 3 | 다음은 추가 컨텍스트를 제공하는 입력과 쌍을 이루는 작업을 설명하는 지침입니다. 요청을 적절하게 완료하는 응답을 작성하세요.nn### 지시:n우즈베키스탄의 수도에 가장 큰 그리스 공동체가 있는 이유는 무엇입니까?nn### 입력:n우즈베키스탄의 그리스인은 약 9,000명입니다. 이 공동체는 1940년대에 러시아에서 우즈베키스탄으로 강제 추방된 그리스인과 그리스에서 온 정치적 난민들로 구성되어 있습니다. 제30,000차 세계대전 이전에는 약 11,000명의 그리스인이 이 나라에 살았고, 그리스 내전과 그리스 민주군이 패배한 후에는 추가로 40,000명이 도착했습니다. 그 수는 1960년대 약 19명에 달했던 최고치에서 감소했습니다. 주된 이유는 그리스 내전 이후 정치적 이유로 추방되었던 모든 그리스인의 귀환을 법으로 허용한 냉전 종식 이후 그리스로의 이주 때문이다. 이 나라에서 가장 큰 그리스 공동체는 수도인 타슈켄트에 있으며, 그곳에서 대부분의 그리스 정치 난민들은 소련 당국에 의해 이주되었습니다. 고대에 이 나라의 남쪽은 헬레니즘 셀레우코스 왕국의 일부였으나 그 이후로 그곳의 소수의 그리스 공동체가 동화되었습니다. 그리스인을 대표하는 가장 중요한 조직은 타슈켄트그리스문화협회이다. 이 조직의 활동에는 그리스어 교육(총 571명의 학생이 참여하는 XNUMX개 수업, 성인 수업)과 그리스 춤 및 음악 교육이 포함됩니다.nn### 응답:n | 우즈베키스탄에 있는 그리스 정치 난민의 대부분은 소련 당국에 의해 수도 타슈켄트로 이주되었습니다. | n“`n우즈베키스탄의 수도에는 그리스인이 약 9,000명 정도 있기 때문에 가장 큰 그리스 공동체가 있습니다. 이 공동체는 1940년대에 러시아에서 우즈베키스탄으로 강제 추방된 그리스인과 그리스에서 온 정치적 난민들로 구성되어 있습니다. 제30,000차 세계대전 이전에는 약 11,00명의 그리스인이 이 나라에 살았고, 그 이후에는 XNUMX명이 살았습니다. | 우즈베키스탄의 수도에는 그리스에서 추방된 후 소련 당국에 의해 대부분의 그리스 정치 난민이 이주한 곳이기 때문에 가장 큰 그리스 공동체가 있습니다.nn 다음은 다음을 제공하는 입력과 함께 작업을 설명하는 지침입니다. 추가 맥락. 요청을 적절하게 완료하는 응답을 작성하세요.nn### 지침:n파르티아 제국과 아르사신드 제국의 차이점은 무엇입니까?nn### 입력:n |
미세 조정된 모델의 응답은 사전 훈련된 모델의 응답에 비해 정밀도, 관련성 및 명확성이 크게 향상되었음을 확인할 수 있습니다. 어떤 경우에는 사용 사례에 맞게 사전 훈련된 모델을 사용하는 것만으로는 충분하지 않을 수 있으므로 이 기술을 사용하여 미세 조정하면 솔루션이 데이터 세트에 더욱 개인화될 수 있습니다.
정리
훈련 작업을 완료하고 기존 리소스를 더 이상 사용하지 않으려면 다음 코드를 사용하여 리소스를 삭제하십시오.
결론
SageMaker에서 Llama 2 Neuron 모델을 배포하고 미세 조정하면 대규모 생성 AI 모델을 관리하고 최적화하는 데 있어 상당한 발전이 이루어졌습니다. Llama-2-7b 및 Llama-2-13b와 같은 변형을 포함한 이러한 모델은 Neuron을 사용하여 AWS Inferentia 및 Trainium 기반 인스턴스에서 효율적인 훈련 및 추론을 수행하여 성능과 확장성을 향상시킵니다.
SageMaker JumpStart UI 및 Python SDK를 통해 이러한 모델을 배포하는 기능은 유연성과 사용 편의성을 제공합니다. 널리 사용되는 ML 프레임워크와 고성능 기능을 지원하는 Neuron SDK를 사용하면 이러한 대규모 모델을 효율적으로 처리할 수 있습니다.
도메인별 데이터에 대해 이러한 모델을 미세 조정하는 것은 전문 분야에서 관련성과 정확성을 높이는 데 중요합니다. SageMaker Studio UI 또는 Python SDK를 통해 수행할 수 있는 프로세스를 통해 특정 요구 사항에 맞게 사용자 정의할 수 있으므로 신속한 완료 및 응답 품질 측면에서 모델 성능이 향상됩니다.
이에 비해 이러한 모델의 사전 훈련된 버전은 강력하기는 하지만 더 일반적이거나 반복적인 응답을 제공할 수 있습니다. 미세 조정은 모델을 특정 상황에 맞게 조정하여 보다 정확하고 관련성이 높으며 다양한 응답을 제공합니다. 이러한 사용자 정의는 사전 훈련된 모델과 미세 조정된 모델의 응답을 비교할 때 특히 두드러지며, 후자는 출력의 품질과 특이성이 눈에 띄게 향상되었음을 보여줍니다. 결론적으로, SageMaker에서 Neuron Llama 2 모델을 배포하고 미세 조정하는 것은 고급 AI 모델을 관리하기 위한 강력한 프레임워크를 나타내며, 특히 특정 도메인이나 작업에 맞게 조정될 때 성능과 적용성이 크게 향상됩니다.
샘플 SageMaker를 참조하여 지금 시작해보세요. 수첩.
GPU 기반 인스턴스에 사전 훈련된 Llama 2 모델을 배포하고 미세 조정하는 방법에 대한 자세한 내용은 다음을 참조하세요. Amazon SageMaker JumpStart에서 텍스트 생성을 위해 Llama 2 미세 조정 과 이제 Meta의 Llama 2 기반 모델을 Amazon SageMaker JumpStart에서 사용할 수 있습니다.
저자들은 Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne 및 Mike James의 기술적인 기여에 감사를 표하고 싶습니다.
저자에 관하여
 신황 Amazon SageMaker JumpStart 및 Amazon SageMaker 내장 알고리즘의 수석 응용 과학자입니다. 그는 확장 가능한 기계 학습 알고리즘 개발에 중점을 둡니다. 그의 연구 관심 분야는 자연어 처리, 테이블 형식 데이터에 대한 설명 가능한 딥 러닝, 비모수 시공간 클러스터링의 강력한 분석입니다. 그는 ACL, ICDM, KDD 컨퍼런스 및 왕립 통계 학회: 시리즈 A에서 많은 논문을 발표했습니다.
신황 Amazon SageMaker JumpStart 및 Amazon SageMaker 내장 알고리즘의 수석 응용 과학자입니다. 그는 확장 가능한 기계 학습 알고리즘 개발에 중점을 둡니다. 그의 연구 관심 분야는 자연어 처리, 테이블 형식 데이터에 대한 설명 가능한 딥 러닝, 비모수 시공간 클러스터링의 강력한 분석입니다. 그는 ACL, ICDM, KDD 컨퍼런스 및 왕립 통계 학회: 시리즈 A에서 많은 논문을 발표했습니다.
 니틴 유세비우스 소프트웨어 엔지니어링, 엔터프라이즈 아키텍처 및 AI/ML 분야의 경험이 있는 AWS의 수석 엔터프라이즈 솔루션 아키텍트입니다. 그는 생성 AI의 가능성을 탐구하는 데 깊은 열정을 갖고 있습니다. 그는 고객과 협력하여 고객이 AWS 플랫폼에서 잘 설계된 애플리케이션을 구축할 수 있도록 지원하고 기술 문제를 해결하고 클라우드 여정을 지원하는 데 전념하고 있습니다.
니틴 유세비우스 소프트웨어 엔지니어링, 엔터프라이즈 아키텍처 및 AI/ML 분야의 경험이 있는 AWS의 수석 엔터프라이즈 솔루션 아키텍트입니다. 그는 생성 AI의 가능성을 탐구하는 데 깊은 열정을 갖고 있습니다. 그는 고객과 협력하여 고객이 AWS 플랫폼에서 잘 설계된 애플리케이션을 구축할 수 있도록 지원하고 기술 문제를 해결하고 클라우드 여정을 지원하는 데 전념하고 있습니다.
 마두르 프라샨트 AWS의 생성 AI 분야에서 일하고 있습니다. 그는 인간의 사고와 생성적 AI의 교차점에 열정을 갖고 있습니다. 그의 관심은 생성적 AI, 특히 유용하고 무해하며 무엇보다도 고객에게 최적인 솔루션을 구축하는 데 있습니다. 업무 외에 그는 요가, 하이킹, 쌍둥이와 함께 시간 보내기, 기타 연주를 좋아합니다.
마두르 프라샨트 AWS의 생성 AI 분야에서 일하고 있습니다. 그는 인간의 사고와 생성적 AI의 교차점에 열정을 갖고 있습니다. 그의 관심은 생성적 AI, 특히 유용하고 무해하며 무엇보다도 고객에게 최적인 솔루션을 구축하는 데 있습니다. 업무 외에 그는 요가, 하이킹, 쌍둥이와 함께 시간 보내기, 기타 연주를 좋아합니다.
 드완 차우두리 Amazon Web Services의 소프트웨어 개발 엔지니어입니다. 그는 Amazon SageMaker의 알고리즘과 JumpStart 제품을 담당하고 있습니다. AI/ML 인프라 구축 외에도 그는 확장 가능한 분산 시스템 구축에도 열정적입니다.
드완 차우두리 Amazon Web Services의 소프트웨어 개발 엔지니어입니다. 그는 Amazon SageMaker의 알고리즘과 JumpStart 제품을 담당하고 있습니다. AI/ML 인프라 구축 외에도 그는 확장 가능한 분산 시스템 구축에도 열정적입니다.
 하오저우 Amazon SageMaker의 연구 과학자입니다. 그 전에는 Amazon Fraud Detector의 사기 탐지를 위한 기계 학습 방법 개발에 참여했습니다. 그는 기계 학습, 최적화, 생성 AI 기술을 다양한 실제 문제에 적용하는 데 열정을 갖고 있습니다. 그는 노스웨스턴대학교에서 전기공학 박사학위를 취득했습니다.
하오저우 Amazon SageMaker의 연구 과학자입니다. 그 전에는 Amazon Fraud Detector의 사기 탐지를 위한 기계 학습 방법 개발에 참여했습니다. 그는 기계 학습, 최적화, 생성 AI 기술을 다양한 실제 문제에 적용하는 데 열정을 갖고 있습니다. 그는 노스웨스턴대학교에서 전기공학 박사학위를 취득했습니다.
 칭란 AWS의 소프트웨어 개발 엔지니어입니다. 그는 고성능 ML 추론 솔루션 및 고성능 로깅 시스템을 포함하여 Amazon에서 여러 도전적인 제품을 작업해 왔습니다. Qing의 팀은 요구되는 매우 짧은 지연 시간으로 Amazon Advertising에서 첫 번째 XNUMX억 매개변수 모델을 성공적으로 출시했습니다. Qing은 인프라 최적화 및 딥 러닝 가속화에 대한 심층 지식을 보유하고 있습니다.
칭란 AWS의 소프트웨어 개발 엔지니어입니다. 그는 고성능 ML 추론 솔루션 및 고성능 로깅 시스템을 포함하여 Amazon에서 여러 도전적인 제품을 작업해 왔습니다. Qing의 팀은 요구되는 매우 짧은 지연 시간으로 Amazon Advertising에서 첫 번째 XNUMX억 매개변수 모델을 성공적으로 출시했습니다. Qing은 인프라 최적화 및 딥 러닝 가속화에 대한 심층 지식을 보유하고 있습니다.
 Ashish Khetan 박사 Amazon SageMaker 내장 알고리즘을 사용하는 수석 응용 과학자이며 기계 학습 알고리즘 개발을 돕습니다. 그는 University of Illinois Urbana-Champaign에서 박사 학위를 받았습니다. 그는 기계 학습 및 통계적 추론 분야에서 활동적인 연구원이며 NeurIPS, ICML, ICLR, JMLR, ACL 및 EMNLP 컨퍼런스에서 많은 논문을 발표했습니다.
Ashish Khetan 박사 Amazon SageMaker 내장 알고리즘을 사용하는 수석 응용 과학자이며 기계 학습 알고리즘 개발을 돕습니다. 그는 University of Illinois Urbana-Champaign에서 박사 학위를 받았습니다. 그는 기계 학습 및 통계적 추론 분야에서 활동적인 연구원이며 NeurIPS, ICML, ICLR, JMLR, ACL 및 EMNLP 컨퍼런스에서 많은 논문을 발표했습니다.
 리 장 박사 데이터 과학자와 기계 학습 실무자가 모델 교육 및 배포를 시작하고 Amazon SageMaker에서 강화 학습을 사용하는 데 도움이 되는 서비스인 Amazon SageMaker JumpStart 및 Amazon SageMaker 내장 알고리즘의 수석 제품 관리자 기술입니다. IBM Research의 수석 연구원이자 마스터 발명가로서의 그의 과거 작업은 IEEE INFOCOM에서 시간 테스트 논문 상을 수상했습니다.
리 장 박사 데이터 과학자와 기계 학습 실무자가 모델 교육 및 배포를 시작하고 Amazon SageMaker에서 강화 학습을 사용하는 데 도움이 되는 서비스인 Amazon SageMaker JumpStart 및 Amazon SageMaker 내장 알고리즘의 수석 제품 관리자 기술입니다. IBM Research의 수석 연구원이자 마스터 발명가로서의 그의 과거 작업은 IEEE INFOCOM에서 시간 테스트 논문 상을 수상했습니다.
 캄란 칸, AWS Inferentina/Trianium 수석 기술 비즈니스 개발 관리자. 그는 고객이 AWS Inferentia 및 AWS Trainium을 사용하여 딥 러닝 훈련 및 추론 워크로드를 배포하고 최적화하도록 돕는 데 10년이 넘는 경험을 갖고 있습니다.
캄란 칸, AWS Inferentina/Trianium 수석 기술 비즈니스 개발 관리자. 그는 고객이 AWS Inferentia 및 AWS Trainium을 사용하여 딥 러닝 훈련 및 추론 워크로드를 배포하고 최적화하도록 돕는 데 10년이 넘는 경험을 갖고 있습니다.
 조 세네르키아 AWS의 수석 제품 관리자입니다. 그는 딥 러닝, 인공 지능 및 고성능 컴퓨팅 워크로드를 위한 Amazon EC2 인스턴스를 정의하고 구축합니다.
조 세네르키아 AWS의 수석 제품 관리자입니다. 그는 딥 러닝, 인공 지능 및 고성능 컴퓨팅 워크로드를 위한 Amazon EC2 인스턴스를 정의하고 구축합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/

