Businesses generally generate and stock colossal quantities of data from which they derive significant insights for rapid and decent decision-making using BI (Business Intelligence). Because of the mixture and complexity of this data, productive and cost-effective data analytics is needed. Data Automation is a crucial process that can be implemented and integrated to attain this purpose.
What is data automation?
Data Automation is interpreted as handling, uploading, and processing data utilizing automated technologies instead of manually conducting these procedures. The long-term viability of your data pipeline device relies on automating the data ingestion method. Any updated data operate the danger of being halted because it is an extra task that an individual must obtain, along with their other obligations. Data Automation restores manual labor in the data ecosystem with computers and methods that do the function for you.
Without human intervention, this procedure compiles, stores, transforms, and analyses data utilizing intelligent processes, artificial intelligence, infrastructure, and software. Data sourcing can be automated to conserve time and money while boosting corporate efficiency. Data Automation also benefits in curtailing errors by assuring that data is packed in a structured manner. For your company to progress on the proper path, you will require to collect main business understandings from your data. As an outcome, having an automated data analytics procedure allows business users to concentrate on data analysis instead of data preparation.
Elements of Data Automation
Extract, Transform, and Load are the three central components of Data Automation and are characterized below:
Extract: It includes extracting data from single or various source systems.
Transform: It adapts your data into the required structure, like a CSV flat-file format. This might include restoring all state abbreviations with the entire state word.
Load: In this issue, the open data portal transfers data from one operation to another.
Each step is crucial for fully automating and appropriately completing your data uploads.
Are you looking to automate data processes?
Automate data tasks like cleaning, extraction, parsing, and more with Nanonets’ no-code workflow platform for free. You can contact our team to set up a complex use case if you have a complex use case.
Benefits of Data Automation
An industry can aid extensively from Data Automation. These goals have been understood in detail below:
Reduction in Processing Time
Processing enormous data from disparate references is not a simple task. Data extracted from various sources differ in format. It must be formalized and assessed before being packed into a unified network. Automation recoups a lot of time in dealing with chores that form a portion of the data pipeline. Also, it reduces manual intervention, which implies low reserve utilization, time savings, and improved data reliability.
Capacity to Scale and Performance Improvement
Data Automation assures better scalability and performance of your data set. For instance, by facilitating Change Data Capture (CDC), all the modifications made at the source level are produced throughout the investment system based on triggers. Contrary to this, manually updating data chores consumes time and expects substantial expertise.
With automated data integration equipment, packing data and regulating CDC simultaneously is just a matter of hauling and lowering objects on the visual designer. Analytical momentum can be enhanced through automation. When an analysis expects little human input, a data scientist can conduct analytics more quickly, and computers can efficiently perform complicated and time-consuming jobs for humans. The key to efficiently assessing huge data is automation.
Cost Efficiency
Automated data analytics recoups time and money for industries. Employee time is more costly during data analysis than computing resources, and devices can execute analytics rapidly.
Better Allocation of Time
Data scientists can concentrate on producing fresh insights to support decision-making by automating assignments that do not expect a lot of human originality. Several members of a data team benefit from data analytics automation. It enables data scientists to function with high-quality, complete, and up-to-date data.
Improved Customer Experience
Delivering an outstanding product or service is not enough. Consumers predict an optimistic experience with you as well. From your accounting board to consumer care, Data Automation ensures that your faculty has the related data at their fingertips to fulfill your clients’ needs.
Improved Data Quality
Manually processing enormous amounts of data uncovers you to the hazard of human mistakes, and relying on obsolete, poorly integrated technology to maintain track of data uncovers you to the same difficulty. Data processing is adequately suited to error-free technology
Sales Strategy and Management
Your sales and marketing committees rely on detailed data to specify good prospects and attain them through adapted campaigns. Data Automation can enable you to maintain your data consistently and up to date, delivering you the highest opportunity for success.
How to automate data in your organization?
You must ensure proper processes to automate data in your organization. Here are the steps to get started with data automation:
Identify the data:
Identify the data that you need to automate. Select the datasets from which you can draw data and ensure you have proper access to download or edit the data.
Select proper data automation platform
Ensure you have the proper toolset to collect, analyze and report the data properly. Ensure the platform you select integrates with all your business software and has workflow automation to automate mundane data tasks easily. This lifts extra load from employees, who can focus on strategy and implementation.
Developing and Testing ETL Process
Map out all the steps to data processing. Know what data sources to connect, what variables you need to pick, what format of values you need, and what do you expect in the output.
A proper ETL process can streamline data automation with rule-based workflows.
Scheduling the Automated Work
Plan your dataset to be revised daily. You can pertain to the metadata areas you compiled as part of your data inventory concerning refresh frequency, data collection, and update frequency.
Once you’ve Set clear objectives and expectations for the automation procedure ahead of time, it can help teams cooperate effectively once the automated procedure is implemented and keep track of its improvement.
Nanonets for Enterprise Data Automation
Nanonets is an AI-based intelligent document processing software with advanced workflow automation and best-in-class OCR software. Nanonets can extract data from any document (images, handwritten images, PDFs, and more) on autopilot. You can use no-code workflows to perform tasks like
And more.
Nanonets is an entirely customizable platform, which means you can customize it according to your use case and requirements. Nanonets is used across multiple industries like finance, construction, logistics, healthcare, banking, and more.
Let’s look at some easy use cases of data automation on Nanonets.
Data Formatting Automation
Extracting tabular data from PDF document on Nanonets
How to do data automation with Nanonets?
Enterprises have a lot of documents, and there are a lot of tasks that need to be done manually, which can be automated using Nanonets.
Every company makes purchases. And they get multiple documents from their vendors and internal teams, which need to be verified before a payment is made.
Let’s pick up a use case on how an organization can automate data matching between purchase orders, sales orders, and invoices and automate approvals, subsequent payments, and data upload.
Here’s how the flow would look like on Nanonets:
Step 1: The documents are automatically uploaded to the platform. The Nanonets platform identifies the document type automatically and sends the document to extract data from the document.

Step 2: Once the data is extracted, now is the time to match the data.

You can look up the values from the extracted data and match the data. In case of any mismatch, the file will be routed for a manual review. You can add triggers easily using no-code workflow blocks.
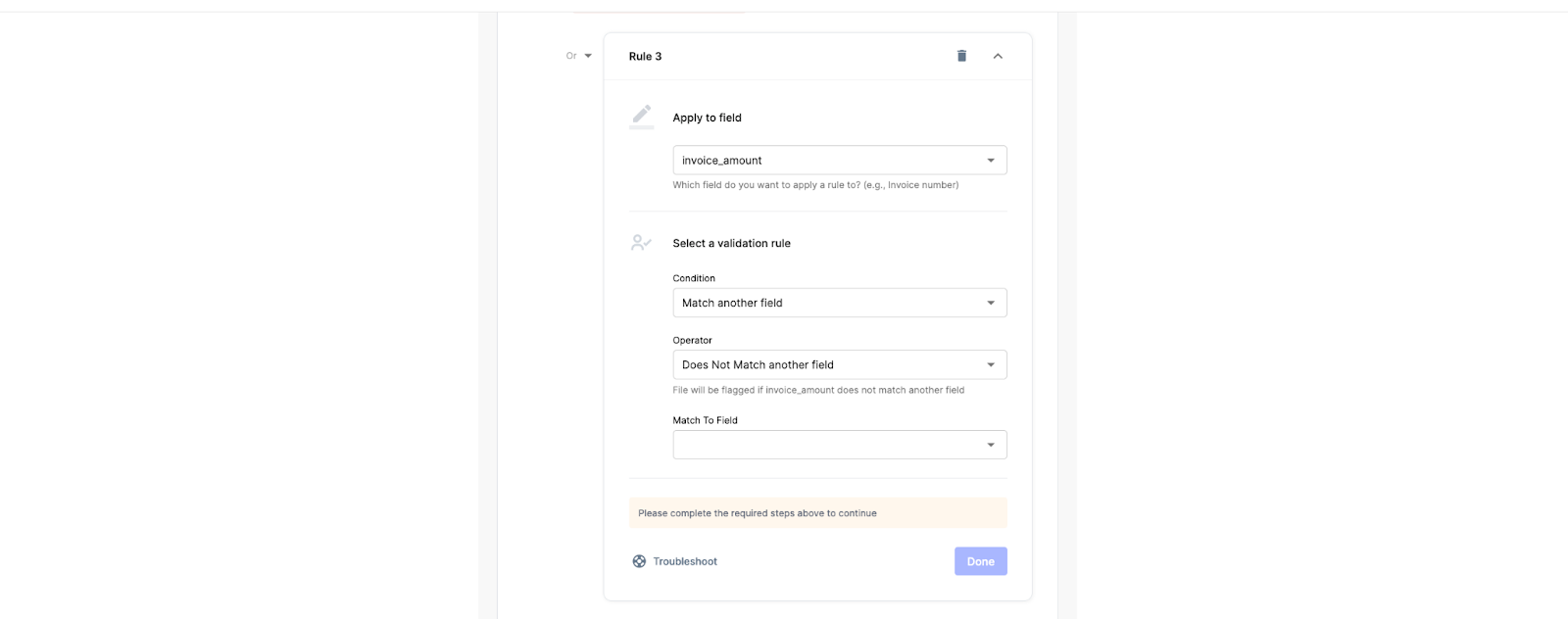
Step 4: Once everything is cleared, the payment request can be sent to Nanonets Flow.

This is just one of the ways in which data can be automated on Nanonets.
Nanonets can be used for a variety of tasks including and limited to
In case you have another use case in mind, please reach out to us. We can help you automate data extraction, processing, and archiving using no-code workflows at a fraction of the cost.
What data should you automate?
As much data as feasible! The more that you approve an “automate by default” strategy to uploading data, the limited reserves you will require long term for conserving high data quality. Here is some advice for locating candidate datasets for automatic uploads:
- Is the dataset edited quarterly or more often?
- Are modifications or any form of manipulation required to be done to the dataset past uploading?
- Is the dataset huge (greater than 250MB)?
- Can you only get the altered rows for each successive update (rather than the full file)?
- Is it apparent to get data from the source network rather than from an individual?
Datasets that urge a “yes” to any of the above-given questions are great nominees for automating updates because automation can eliminate the risk of a lack of resources and time later on.
Understanding Data Automation Strategy
It is significant to have a comprehensive Data Automation proposal for your corporation. Having a technique in place for a long time can enable you to engage adequate people at an opportune moment within your corporation. Without a robust Data Automation technique, your company will wander from the route it should be on, consuming time and resources. It could also amount to you additional money in terms of lost earnings. As an outcome, your data process automation proposal should align with your industry goals.
Automate mundane data processing tasks with 0 errors using Nanonets no-code workflows!
How to develop a Data Automation Strategy?
Here are some points that can be attempted to formulate your Data Automation Strategy:
Identification of Problems
Deduce which of your corporation’s core regions could aid from automation. Solely consider where Data Automation might be helpful. Evaluate this: how much of your data investigators’ time is used doing physical work? Which elements of your data systems are constantly failing? Make a list of all the procedures that could be enhanced.
Classification of Data
The preliminary stage in Data Automation is to sort source data into classifications based on their significance and accessibility. Peek through your source system index to see which references you have entries too. If you will utilize an automated data extraction tool, ensure it benefits the formats crucial to your business.
Prioritization of Operations
Use the quantity of time expended to assess the significance of a procedure. The greater the amount of time spent on physical labor, the more significant the effect of automation on the bottom line. Make specific characteristics in the time it will seize to automate a process. Sharp wins are the means to go because they maintain everyone’s spirits while indicating the significance of automation to the industry owners.
Outlining Required Transformations
The subsequent stage specifies necessary modifications to restore the source data to the target quantity. It could be as easy as turning hard acronyms into full-text words or as complicated as converting a relational database to a CSV file. Specifying the essential transformations to attain the intended outcomes during Data Automation is crucial; otherwise, your whole dataset might get polluted.
Execution of the Operations
The execution of data techniques is technically the most problematic component. These implement three distinct processes: adequate reporting, engineering pipelines, and decent machine-learning methods.
Schedule Data for Updates
The following step is to record your data so that it gets revised on a normal basis. For this phase, you are instructed to utilize an ETL product with process automation characteristics such as workflow automation, task scheduling, and so on. This assures that the procedure is carried out without physical intervention.
Want to automate repetitive manual tasks? Save Time, Effort & Money while enhancing efficiency!
Disadvantages of Data Automation
Data automation can be helpful for your business, but there are some disadvantages.
One disadvantage is that it can cost a lot of money to use data automation. Before making a decision, you should consider how much money you will need to spend and how much you will make back from using automation.
Another disadvantage is that intelligent automation can take away jobs. Some people might lose their jobs because they are not needed anymore. But this does not always have to be a bad thing. Intelligent data automation can help people do more exciting and important work and help a business make more money, which can create new jobs.
Finally, sometimes data automation can become repetitive, especially when production procedures change. It’s important to make sure that your automation system can be easily changed to fit new products or production methods.
In case, you have another use case in mind, please reach out to us. We can help you automate data extraction, processing, and archiving using no-code workflows at a fraction of the cost.
Read more about data processing on Nanonets:
FAQs
Source Data Automation
It is like the automation of data that is accomplished by extracting data from source networks; there is source data automation. It implies inserting data on an equal basis to using Bar Code Readers at supermarkets. This facilitates the store owners to have all the data needed to regulate sales and inventory to make the next quarter’s inventory conclusions.
It is a preferred data entry technique because it eradicates human efforts and uncertainties. The traditional data entry techniques involve obtaining information on paper and transporting it to the automated database management software for examination. Human work is less inclined to be free of errors, redundancy, inaccuracy, and inconsistent data directed to faulty calculation.
Thus, the Source Data Automation devices feed data immediately so you are prepared to process data accessible instantaneously. One cannot question the precision of this process because computers retain consistency and calculations.
What is an Example of Source Data Automation?
Data automation has made commercial data entry more detailed and accessible, saving enormous costs on employing people who would do the job for you with unavoidable inaccuracy.
For example, when individuals spot their orders at diners, the charges are immediately recorded in the database through touch screens. Thus, the data is not presumed to be documented twice by a diner. Most fast-food chains and retail stores use these exhibits on their workstations. Apart from producing accurate bills, source data automation is the objective of these appliances.
Added benefits of source data automation comprise little time expended on the checkout counter by each consumer by eradicating the necessity for manual inputs. All supermarkets can spot bar codes on their commodities and then scan them at the moment of checkout, record all the essential information, and produce the bills. The data compiled will provide data about which product is selling more rapidly than others in the inventory, providing the sufficient owner time to restock.
The assessments also have Magnetic coding, which is decrypted by MICRs, making the check processing simpler and cost-effective. The time that counter operators conserve in handling each consumer can be used to expand services to more consumers every day, enabling organizations to thrive. Here is some equipment utilized for source data automation.
Source data-entry equipment is meant to rapidly examine the data in a consistent format and feed it into the computer. Some of them are:
Data-entry devices
Scanners: A scanner utilizes light-sensing technology to read the portrait placed in front of it and store it in the computer in a digital form.
Bar-code Readers: A Bar Code Reader, as the name indicates, is used to examine and understand barcodes. These barcodes are progressed coding symbols including all the data about the product and its rate. Once the reader examines the code, it translates it into a digital layout stocked on the computer.
Radio Frequency Identification (RFID): RFID uses microchips to examine the labels. Each microchip has its energy source and includes code numbers inspected by RFIDs. This more advanced data automation method has begun to renovate bar code readers in various scenarios.
MICR – Magnetic Ink Character Recognition: These are substantial recognition equipment that read magnetized ink, such as that published on the bottom of checks.
OMR — Optical Mark Recognition: It stores candidates’ totals in a test and implicates pencil marks on unique OMR papers. It uses light and ambiguity of blanks to discern data.
OCR — Optical Character Recognition: Various institutions that have their consumers fill feedback forms manually need an email address to improve their mailing list more than analyses. They can use OCR software to restore handwritten messages into a computer-editable script. The equipment looks like a handheld scanner and converts data into a digital layout that can be conserved in the computers.
What is Big Data Automation?
Big Data has revolutionized the organizational and digital landscape in how they function. The analytics has questioned all the discrepancies in employee achievement or a specific product in the market. This superior technology enables institutions to find patterns in the version, whether it is rectifying or comprehending it.
However, the compilation of Big Data might pose problems for an institution because there are insufficient human and financial resources. Fortunately, data automation has reached to the rescue of industries, enabling data collection without pertaining manual actions. In this way, projections can be accomplished without having to go through an additional step to correct physical efforts.
Understanding Data Access and Ownership
Various groups will own elements of the ETL process, relying on your team arrangement:
Centralized Data Access and Operation
The whole ETL procedure, as well as any Data Automation, is acquired by the main IT department.
Hybrid Data Access and Operation
The selection and transformation methods are typically acquired by separate agencies and offices, while the central IT institution often acquires the loading procedure.
Decentralized Data Access and Operation
Each agency or office will be in charge of its own ETL procedure.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://nanonets.com/blog/data-automation/

