Trong bối cảnh sản xuất đang phát triển, sức mạnh biến đổi của AI và học máy (ML) là điều hiển nhiên, thúc đẩy một cuộc cách mạng kỹ thuật số giúp hợp lý hóa các hoạt động và tăng năng suất. Tuy nhiên, tiến trình này đặt ra những thách thức đặc biệt cho các doanh nghiệp khi điều hướng các giải pháp dựa trên dữ liệu. Các cơ sở công nghiệp phải vật lộn với khối lượng lớn dữ liệu phi cấu trúc, có nguồn gốc từ các cảm biến, hệ thống đo từ xa và thiết bị phân tán trên các dây chuyền sản xuất. Dữ liệu thời gian thực rất quan trọng đối với các ứng dụng như bảo trì dự đoán và phát hiện bất thường, tuy nhiên việc phát triển mô hình ML tùy chỉnh cho từng trường hợp sử dụng công nghiệp với dữ liệu chuỗi thời gian như vậy đòi hỏi thời gian và nguồn lực đáng kể từ các nhà khoa học dữ liệu, cản trở việc áp dụng rộng rãi.
Trí tuệ nhân tạo sử dụng các mô hình nền tảng được đào tạo trước (FM) lớn như Claude có thể nhanh chóng tạo ra nhiều nội dung khác nhau từ văn bản đàm thoại đến mã máy tính dựa trên các lời nhắc văn bản đơn giản, được gọi là nhắc nhở bắn không. Điều này giúp loại bỏ nhu cầu các nhà khoa học dữ liệu phải phát triển các mô hình ML cụ thể theo cách thủ công cho từng trường hợp sử dụng và do đó dân chủ hóa quyền truy cập AI, mang lại lợi ích ngay cả cho các nhà sản xuất nhỏ. Công nhân đạt được năng suất thông qua những hiểu biết sâu sắc do AI tạo ra, các kỹ sư có thể chủ động phát hiện những điểm bất thường, các nhà quản lý chuỗi cung ứng tối ưu hóa hàng tồn kho và lãnh đạo nhà máy đưa ra các quyết định sáng suốt dựa trên dữ liệu.
Tuy nhiên, các FM độc lập gặp phải những hạn chế trong việc xử lý dữ liệu công nghiệp phức tạp với các ràng buộc về kích thước ngữ cảnh (thường là dưới 200,000 token), điều này đặt ra những thách thức. Để giải quyết vấn đề này, bạn có thể sử dụng khả năng tạo mã của FM để phản hồi các truy vấn ngôn ngữ tự nhiên (NLQ). Đại lý như gấu trúcAI bắt đầu hoạt động, chạy mã này trên dữ liệu chuỗi thời gian có độ phân giải cao và xử lý lỗi bằng FM. PandasAI là một thư viện Python bổ sung các khả năng AI tổng quát cho gấu trúc, công cụ xử lý và phân tích dữ liệu phổ biến.
Tuy nhiên, các NLQ phức tạp, chẳng hạn như xử lý dữ liệu chuỗi thời gian, tổng hợp nhiều cấp độ và các thao tác xoay bảng hoặc bảng chung, có thể mang lại độ chính xác của tập lệnh Python không nhất quán với dấu nhắc không bắn.
Để nâng cao độ chính xác của việc tạo mã, chúng tôi đề xuất xây dựng động lời nhắc chụp nhiều lần đối với NLQ. Lời nhắc nhiều lần cung cấp ngữ cảnh bổ sung cho FM bằng cách hiển thị cho nó một số ví dụ về đầu ra mong muốn cho các lời nhắc tương tự, nâng cao độ chính xác và tính nhất quán. Trong bài đăng này, lời nhắc chụp nhiều lần được lấy từ phần nhúng chứa mã Python chạy thành công trên loại dữ liệu tương tự (ví dụ: dữ liệu chuỗi thời gian có độ phân giải cao từ các thiết bị Internet of Things). Lời nhắc nhiều lần chụp được xây dựng linh hoạt cung cấp bối cảnh phù hợp nhất với FM và tăng cường khả năng của FM trong phép tính toán nâng cao, xử lý dữ liệu chuỗi thời gian và hiểu từ viết tắt dữ liệu. Phản hồi cải tiến này tạo điều kiện cho nhân viên doanh nghiệp và nhóm vận hành tương tác với dữ liệu, thu được thông tin chi tiết mà không yêu cầu kỹ năng khoa học dữ liệu sâu rộng.
Ngoài việc phân tích dữ liệu chuỗi thời gian, FM còn chứng tỏ giá trị trong các ứng dụng công nghiệp khác nhau. Đội bảo trì đánh giá tình trạng tài sản, chụp ảnh để Nhận thức lại Amazon-các bản tóm tắt chức năng dựa trên và phân tích nguyên nhân gốc rễ của sự bất thường bằng cách sử dụng các tìm kiếm thông minh với Truy xuất thế hệ tăng cường (GIẺ). Để đơn giản hóa các quy trình công việc này, AWS đã giới thiệu nền tảng Amazon, cho phép bạn xây dựng và mở rộng quy mô các ứng dụng AI tổng quát với các FM được đào tạo trước hiện đại như Claude v2. Với Cơ sở kiến thức về Amazon Bedrock, bạn có thể đơn giản hóa quy trình phát triển RAG để cung cấp phân tích nguyên nhân cốt lõi của sự bất thường chính xác hơn cho công nhân nhà máy. Bài đăng của chúng tôi giới thiệu một trợ lý thông minh dành cho các trường hợp sử dụng công nghiệp do Amazon Bedrock cung cấp, giải quyết các thách thức NLQ, tạo bản tóm tắt bộ phận từ hình ảnh và tăng cường phản hồi FM để chẩn đoán thiết bị thông qua phương pháp RAG.
Tổng quan về giải pháp
Sơ đồ sau minh họa kiến trúc giải pháp.

Quy trình làm việc bao gồm ba trường hợp sử dụng riêng biệt:
Trường hợp sử dụng 1: NLQ với dữ liệu chuỗi thời gian
Quy trình làm việc của NLQ với dữ liệu chuỗi thời gian bao gồm các bước sau:
- Chúng tôi sử dụng hệ thống giám sát tình trạng có khả năng ML để phát hiện sự bất thường, chẳng hạn như Amazon Monitron, để theo dõi tình trạng thiết bị công nghiệp. Amazon Monitron có thể phát hiện các lỗi thiết bị tiềm ẩn từ các phép đo nhiệt độ và độ rung của thiết bị.
- Chúng tôi thu thập dữ liệu chuỗi thời gian bằng cách xử lý Amazon Monitron dữ liệu thông qua Luồng dữ liệu Amazon Kinesis và Firehose dữ liệu của Amazon, chuyển đổi nó thành định dạng CSV dạng bảng và lưu nó ở dạng Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) xô.
- Người dùng cuối có thể bắt đầu trò chuyện với dữ liệu chuỗi thời gian của họ trong Amazon S3 bằng cách gửi truy vấn ngôn ngữ tự nhiên tới ứng dụng Streamlit.
- Ứng dụng Streamlit chuyển tiếp truy vấn của người dùng tới Mô hình nhúng văn bản Amazon Bedrock Titan để nhúng truy vấn này và thực hiện tìm kiếm tương tự trong một Dịch vụ Tìm kiếm Mở của Amazon chỉ mục chứa các NLQ trước đó và mã ví dụ.
- Sau khi tìm kiếm điểm tương đồng, các ví dụ tương tự hàng đầu, bao gồm các câu hỏi NLQ, lược đồ dữ liệu và mã Python, sẽ được chèn vào lời nhắc tùy chỉnh.
- PandasAI gửi lời nhắc tùy chỉnh này tới mẫu Amazon Bedrock Claude v2.
- Ứng dụng sử dụng tác nhân PandasAI để tương tác với mô hình Amazon Bedrock Claude v2, tạo mã Python để phân tích dữ liệu Amazon Monitron và phản hồi NLQ.
- Sau khi mô hình Amazon Bedrock Claude v2 trả về mã Python, PandasAI chạy truy vấn Python trên dữ liệu Amazon Monitron được tải lên từ ứng dụng, thu thập đầu ra mã và giải quyết mọi lần thử lại cần thiết đối với các lần chạy không thành công.
- Ứng dụng Streamlit thu thập phản hồi thông qua PandasAI và cung cấp đầu ra cho người dùng. Nếu kết quả đầu ra đạt yêu cầu, người dùng có thể đánh dấu nó là hữu ích, lưu mã Python do NLQ và Claude tạo trong Dịch vụ OpenSearch.
Trường hợp sử dụng 2: Tổng hợp các bộ phận bị hỏng hóc
Trường hợp sử dụng tạo tóm tắt của chúng tôi bao gồm các bước sau:
- Sau khi người dùng biết tài sản công nghiệp nào có hành vi bất thường, họ có thể tải lên hình ảnh của bộ phận bị trục trặc để xác định xem bộ phận này có vấn đề gì về mặt vật lý hay không theo thông số kỹ thuật và điều kiện vận hành của nó.
- Người dùng có thể sử dụng API DetectText nhận dạng của Amazon để trích xuất dữ liệu văn bản từ những hình ảnh này.
- Dữ liệu văn bản được trích xuất được đưa vào lời nhắc dành cho mô hình Amazon Bedrock Claude v2, cho phép mô hình tạo bản tóm tắt 200 từ về phần bị trục trặc. Người dùng có thể sử dụng thông tin này để thực hiện kiểm tra thêm bộ phận.
Trường hợp sử dụng 3: Chẩn đoán nguyên nhân gốc rễ
Trường hợp sử dụng chẩn đoán nguyên nhân gốc rễ của chúng tôi bao gồm các bước sau:
- Người dùng lấy dữ liệu doanh nghiệp ở nhiều định dạng tài liệu khác nhau (PDF, TXT, v.v.) liên quan đến nội dung gặp trục trặc và tải chúng lên bộ chứa S3.
- Cơ sở kiến thức về các tệp này được tạo trong Amazon Bedrock bằng mô hình nhúng văn bản Titan và kho lưu trữ vectơ Dịch vụ OpenSearch mặc định.
- Người dùng đặt ra các câu hỏi liên quan đến chẩn đoán nguyên nhân gốc rễ khiến thiết bị gặp trục trặc. Các câu trả lời được tạo ra thông qua cơ sở kiến thức Amazon Bedrock bằng cách tiếp cận RAG.
Điều kiện tiên quyết
Để làm theo bài đăng này, bạn phải đáp ứng các điều kiện tiên quyết sau:
Triển khai hạ tầng giải pháp
Để thiết lập tài nguyên giải pháp của bạn, hãy hoàn thành các bước sau:
- Triển khai Hình thành đám mây AWS mẫu opensearchsagemaker.yml, tạo ra một bộ sưu tập và chỉ mục Dịch vụ OpenSearch, Amazon SageMaker phiên bản máy tính xách tay và nhóm S3. Bạn có thể đặt tên cho ngăn xếp AWS CloudFormation này là:
genai-sagemaker. - Mở phiên bản sổ ghi chép SageMaker trong JupyterLab. Bạn sẽ tìm thấy những điều sau đây Repo GitHub đã được tải xuống trong trường hợp này: khai thác tiềm năng của hoạt động sản xuất-ai-trong-công nghiệp.
- Chạy sổ ghi chép từ thư mục sau trong kho lưu trữ này: mở khóa-tiềm năng của thế hệ-ai-trong-công nghiệp-hoạt động/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Sổ ghi chép này sẽ tải chỉ mục Dịch vụ OpenSearch bằng sổ ghi chép SageMaker để lưu trữ các cặp khóa-giá trị từ 23 ví dụ NLQ hiện có.
- Tải tài liệu lên từ thư mục dữ liệu tài sảnpartdoc trong kho lưu trữ GitHub vào nhóm S3 được liệt kê trong kết quả đầu ra của ngăn xếp CloudFormation.

Tiếp theo, bạn tạo cơ sở kiến thức cho các tài liệu trong Amazon S3.
- Trên bảng điều khiển Amazon Bedrock, chọn Kiến thức cơ bản trong khung điều hướng.
- Chọn Tạo nền tảng kiến thức.
- Trong Tên cơ sở kiến thức, nhập tên.
- Trong Vai trò thời gian chạy, lựa chọn Tạo và sử dụng vai trò dịch vụ mới.
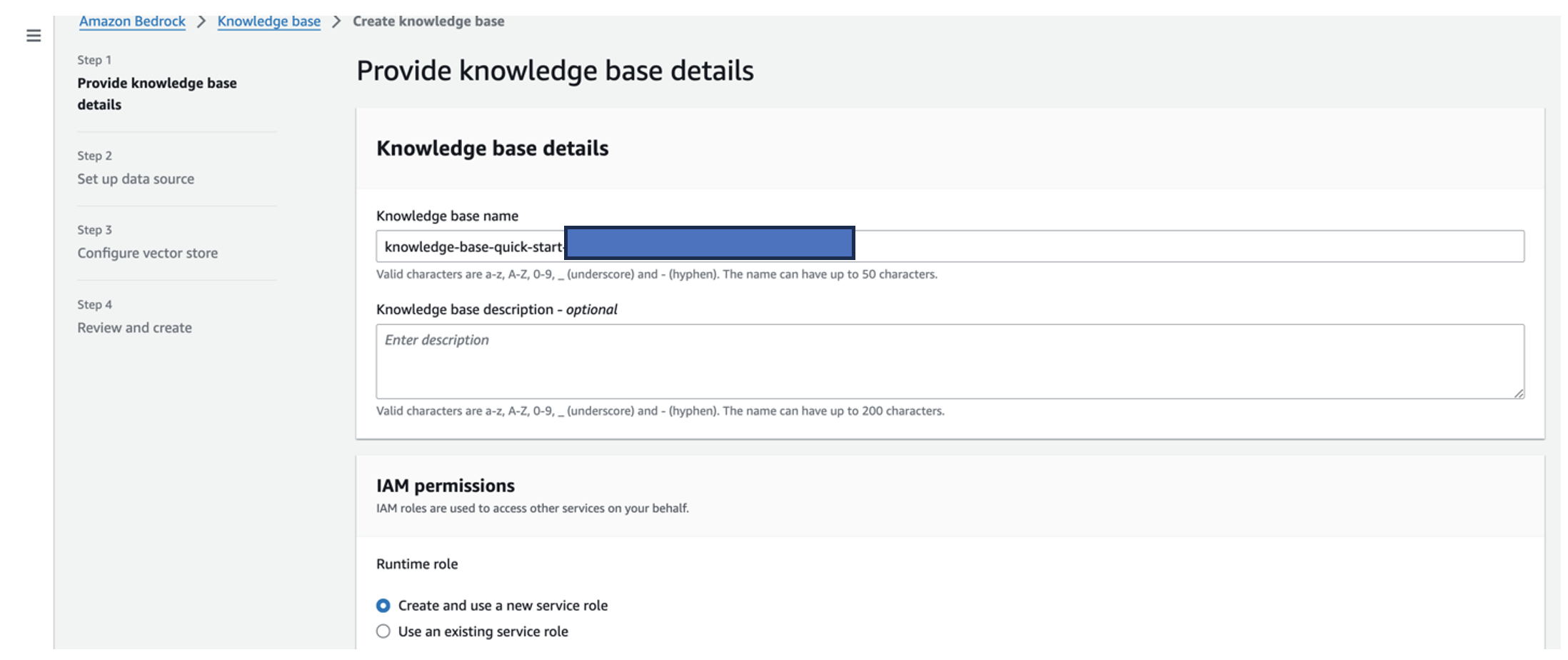
- Trong Tên nguồn dữ liệu, hãy nhập tên nguồn dữ liệu của bạn.
- Trong URI S3, hãy nhập đường dẫn S3 của nhóm nơi bạn đã tải lên tài liệu về nguyên nhân gốc rễ.
- Chọn Sau.
 Mô hình nhúng Titan được chọn tự động.
Mô hình nhúng Titan được chọn tự động. - Chọn Tạo nhanh một cửa hàng vector mới.
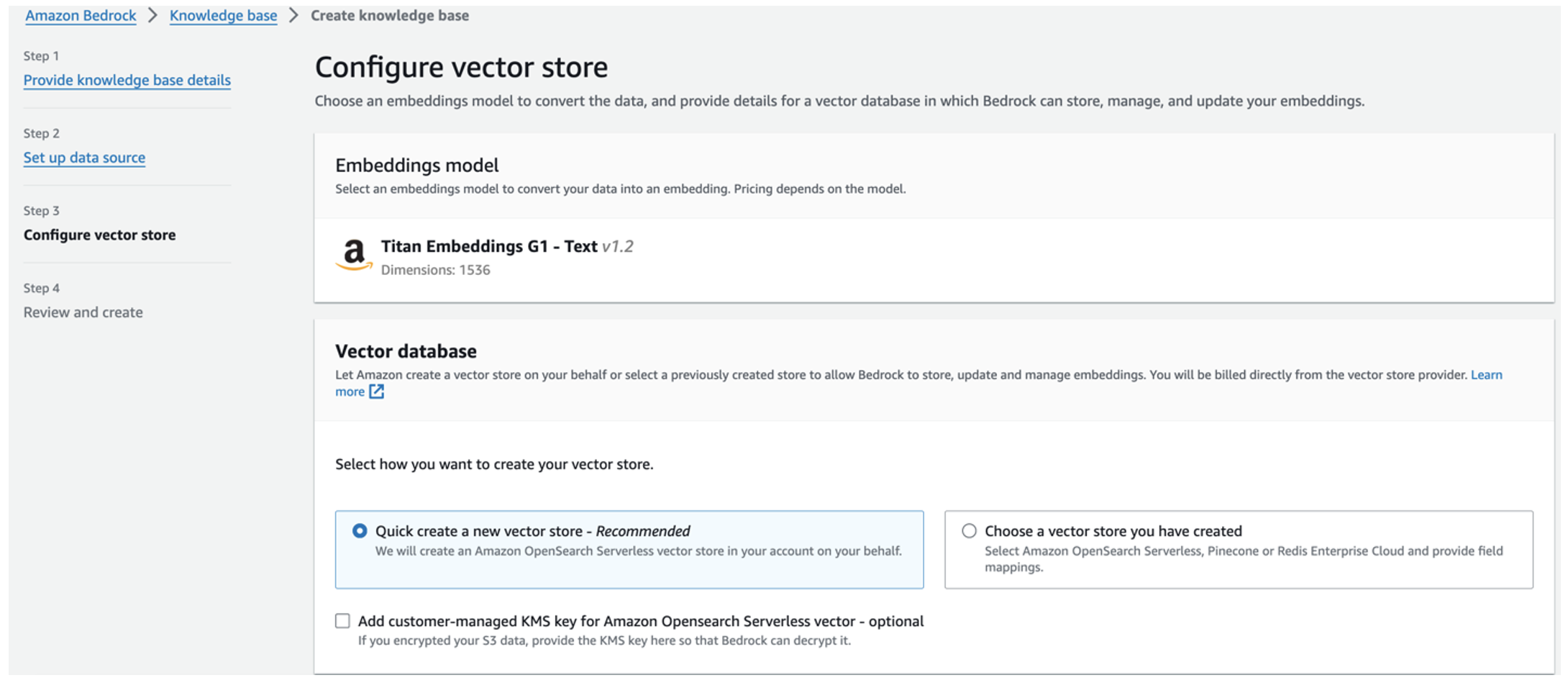
- Xem lại cài đặt của bạn và tạo cơ sở kiến thức bằng cách chọn Tạo nền tảng kiến thức.
- Sau khi cơ sở tri thức được tạo thành công, chọn Đồng bộ để đồng bộ hóa nhóm S3 với cơ sở kiến thức.

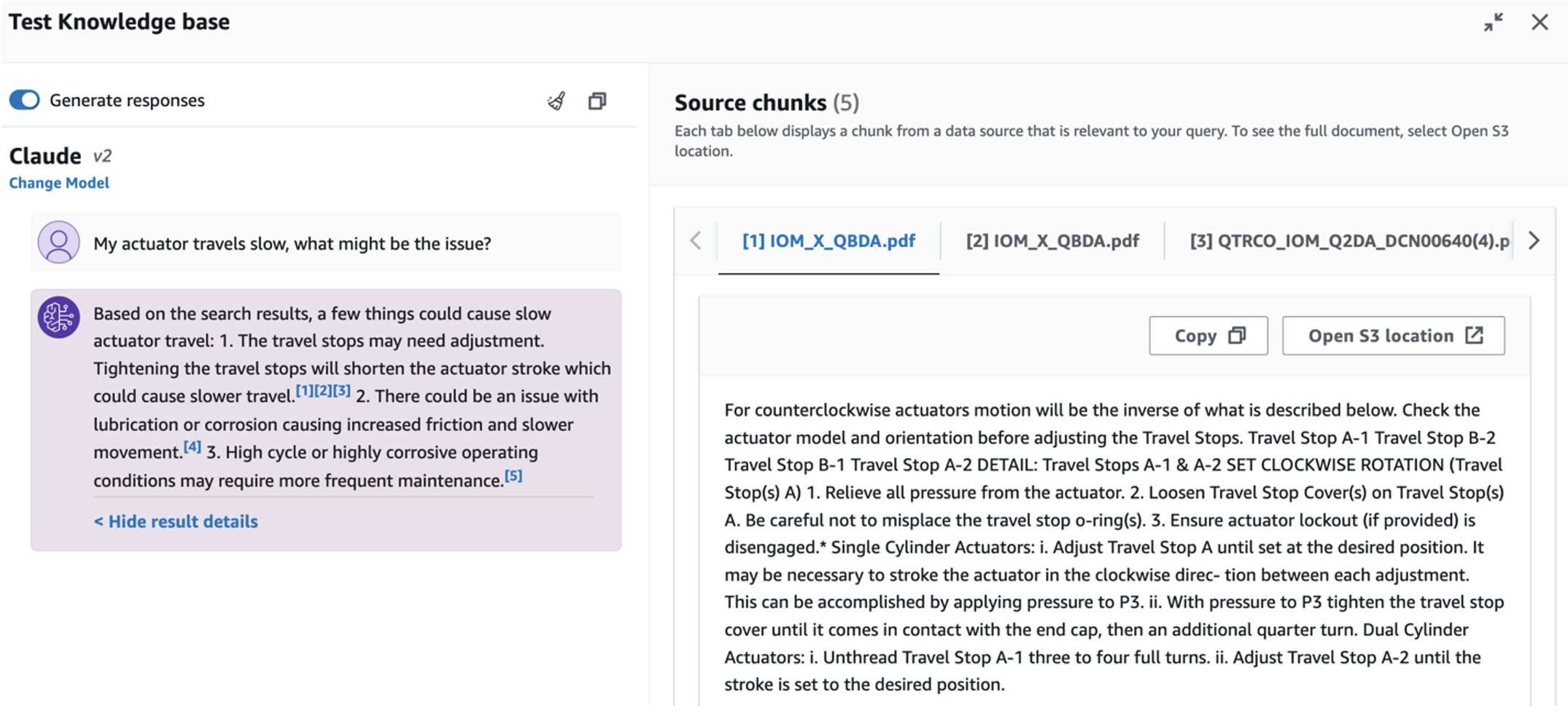
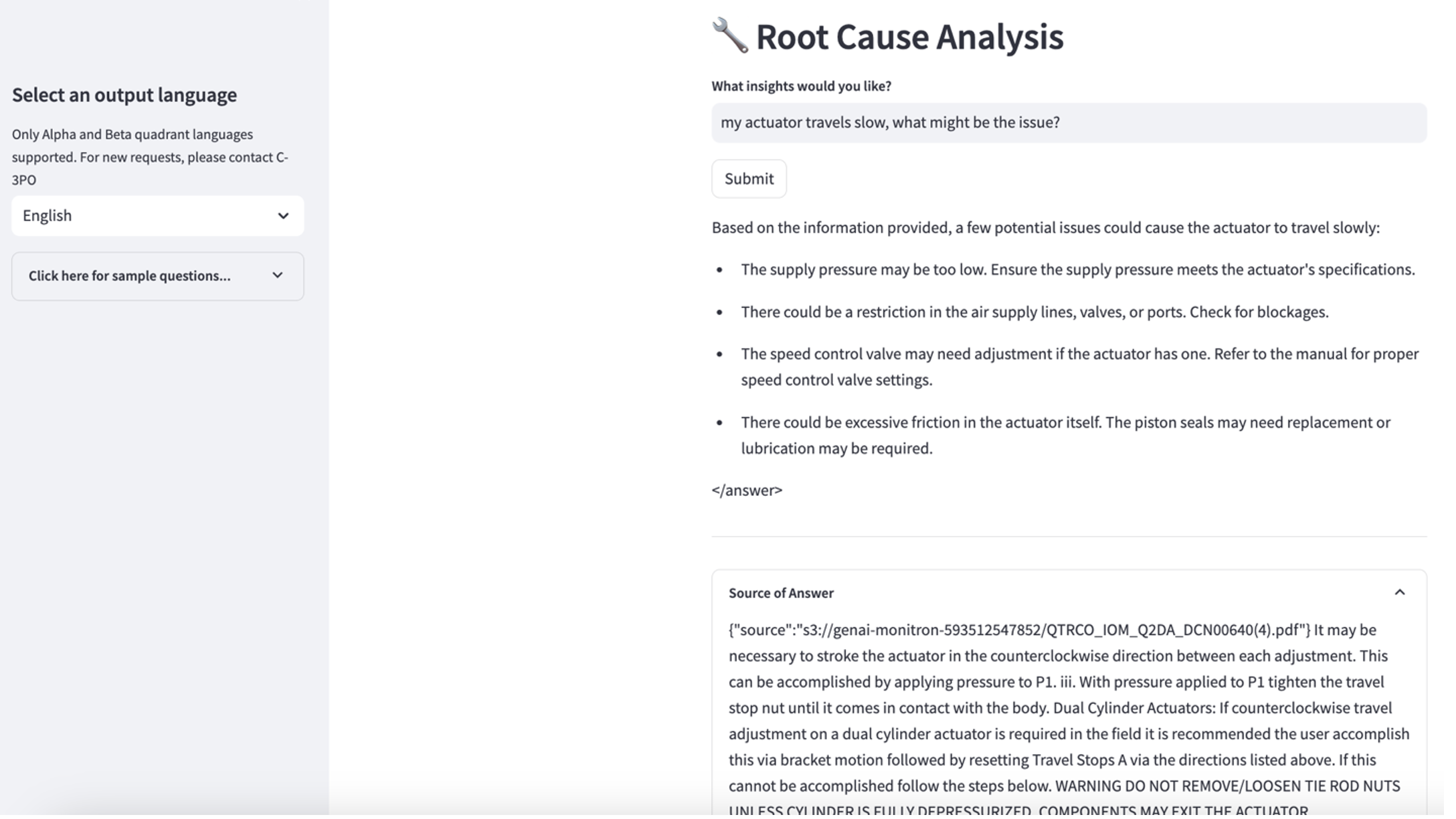
- Sau khi thiết lập cơ sở kiến thức, bạn có thể kiểm tra phương pháp RAG để chẩn đoán nguyên nhân gốc rễ bằng cách đặt các câu hỏi như “Bộ truyền động của tôi di chuyển chậm, vấn đề có thể là gì?”
Bước tiếp theo là triển khai ứng dụng với các gói thư viện cần thiết trên PC hoặc phiên bản EC2 (Ubuntu Server 22.04 LTS).
- Thiết lập thông tin đăng nhập AWS của bạn với AWS CLI trên PC cục bộ của bạn. Để đơn giản, bạn có thể sử dụng cùng vai trò quản trị viên mà bạn đã sử dụng để triển khai ngăn xếp CloudFormation. Nếu bạn đang sử dụng Amazon EC2, đính kèm vai trò IAM phù hợp vào phiên bản.
- Clone Repo GitHub:
- Thay đổi thư mục thành
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcvà chạysetup.shscript trong thư mục này để cài đặt các gói cần thiết, bao gồm LangChain và PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Chạy ứng dụng Streamlit bằng lệnh sau:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Cung cấp ARN bộ sưu tập Dịch vụ OpenSearch mà bạn đã tạo trong Amazon Bedrock ở bước trước.
Trò chuyện với trợ lý tình trạng tài sản của bạn
Sau khi hoàn tất quá trình triển khai toàn diện, bạn có thể truy cập ứng dụng qua localhost trên cổng 8501, cổng này sẽ mở ra một cửa sổ trình duyệt có giao diện web. Nếu bạn đã triển khai ứng dụng trên phiên bản EC2, cho phép truy cập cổng 8501 thông qua quy tắc gửi đến của nhóm bảo mật. Bạn có thể điều hướng đến các tab khác nhau cho các trường hợp sử dụng khác nhau.
Khám phá trường hợp sử dụng 1
Để khám phá ca sử dụng đầu tiên, hãy chọn Thông tin chi tiết về dữ liệu và biểu đồ. Bắt đầu bằng cách tải lên dữ liệu chuỗi thời gian của bạn. Nếu bạn không có tệp dữ liệu chuỗi thời gian hiện có để sử dụng, bạn có thể tải lên tệp sau tệp CSV mẫu với dữ liệu dự án Amazon Monitron ẩn danh. Nếu bạn đã có dự án Amazon Monitron, hãy tham khảo Tạo thông tin chi tiết có thể hành động để quản lý bảo trì dự đoán với Amazon Monitron và Amazon Kinesis để truyền dữ liệu Amazon Monitron của bạn tới Amazon S3 và sử dụng dữ liệu của bạn với ứng dụng này.
Khi quá trình tải lên hoàn tất, hãy nhập truy vấn để bắt đầu cuộc trò chuyện với dữ liệu của bạn. Thanh bên trái cung cấp một loạt các câu hỏi ví dụ để thuận tiện cho bạn. Các ảnh chụp màn hình sau đây minh họa phản hồi và mã Python do FM tạo ra khi nhập câu hỏi, chẳng hạn như “Hãy cho tôi biết số lượng cảm biến duy nhất cho mỗi trang web được hiển thị tương ứng là Cảnh báo hoặc Báo động?” (một câu hỏi ở mức độ khó) hoặc “Đối với các cảm biến hiển thị tín hiệu nhiệt độ là KHÔNG Khỏe mạnh, bạn có thể tính khoảng thời gian tính bằng ngày cho mỗi cảm biến hiển thị tín hiệu rung bất thường không?” (một câu hỏi ở cấp độ thử thách). Ứng dụng sẽ trả lời câu hỏi của bạn và cũng sẽ hiển thị tập lệnh phân tích dữ liệu Python mà nó đã thực hiện để tạo ra các kết quả như vậy.


Nếu bạn hài lòng với câu trả lời, bạn có thể đánh dấu nó là Hữu ích, lưu mã Python do NLQ và Claude tạo vào chỉ mục Dịch vụ tìm kiếm mở.

Khám phá trường hợp sử dụng 2
Để khám phá trường hợp sử dụng thứ hai, hãy chọn Tóm tắt hình ảnh đã chụp trong ứng dụng Streamlit. Bạn có thể tải lên hình ảnh tài sản công nghiệp của mình và ứng dụng sẽ tạo bản tóm tắt 200 từ về thông số kỹ thuật và điều kiện vận hành dựa trên thông tin hình ảnh. Ảnh chụp màn hình sau đây hiển thị phần tóm tắt được tạo từ hình ảnh của bộ truyền động động cơ dây đai. Để kiểm tra tính năng này, nếu thiếu hình ảnh phù hợp, bạn có thể sử dụng cách sau hình ảnh ví dụ.
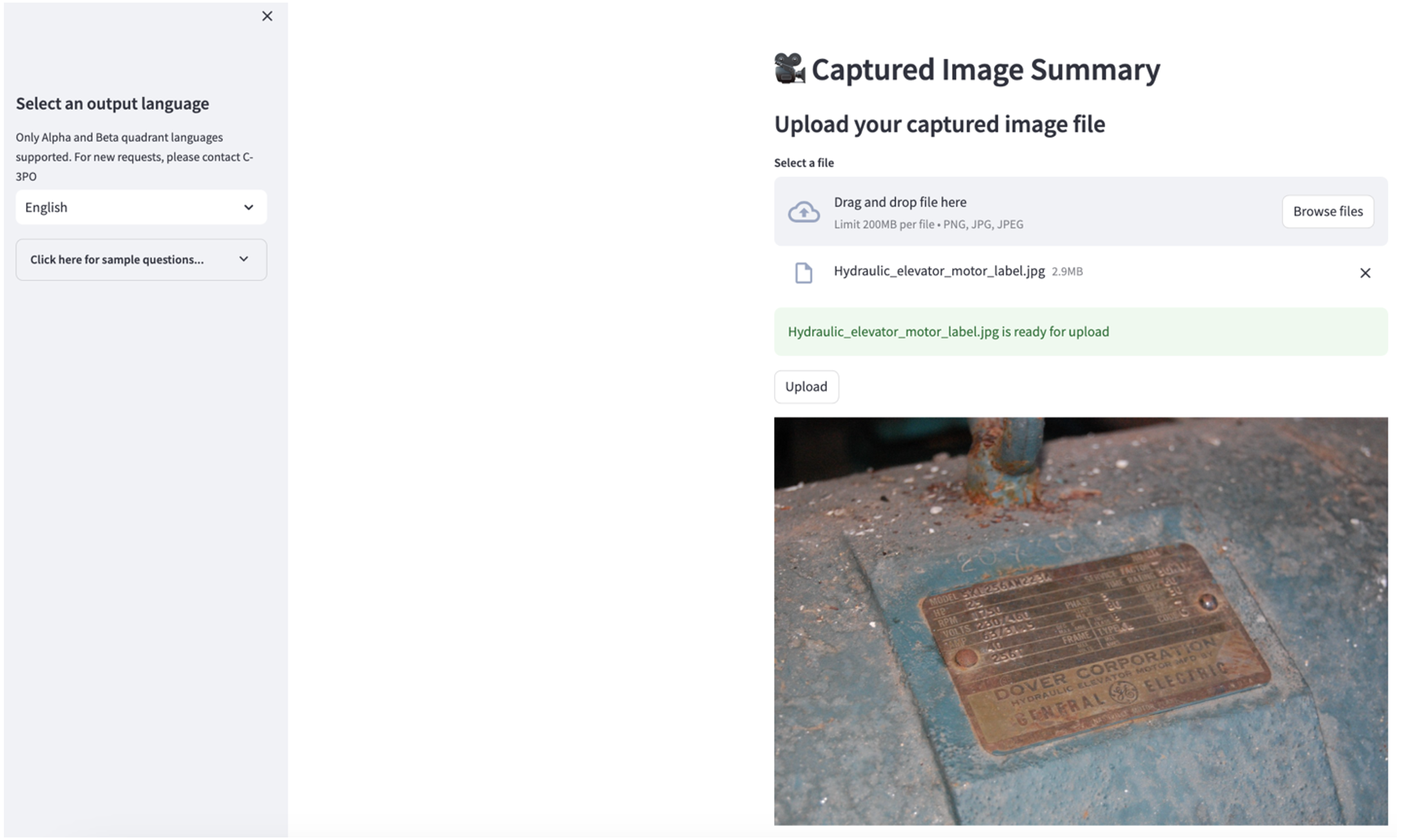
Nhãn động cơ thang máy thủy lực” của Clarence Risher được cấp phép theo CC BY-SA 2.0.

Khám phá trường hợp sử dụng 3
Để khám phá ca sử dụng thứ ba, hãy chọn Chẩn đoán nguyên nhân gốc rễ chuyển hướng. Nhập một truy vấn liên quan đến tài sản công nghiệp bị hỏng của bạn, chẳng hạn như "Thiết bị truyền động của tôi di chuyển chậm, vấn đề có thể là gì?" Như được mô tả trong ảnh chụp màn hình sau, ứng dụng sẽ đưa ra phản hồi kèm theo đoạn trích tài liệu nguồn được sử dụng để tạo ra câu trả lời.
Ca sử dụng 1: Chi tiết thiết kế
Trong phần này, chúng ta thảo luận chi tiết về thiết kế của quy trình làm việc của ứng dụng cho trường hợp sử dụng đầu tiên.
Xây dựng lời nhắc tùy chỉnh
Truy vấn ngôn ngữ tự nhiên của người dùng có các mức độ khó khác nhau: dễ, khó và thử thách.
Các câu hỏi đơn giản có thể bao gồm các yêu cầu sau:
- Chọn các giá trị duy nhất
- Đếm tổng số
- Sắp xếp giá trị
Đối với những câu hỏi này, PandasAI có thể tương tác trực tiếp với FM để tạo tập lệnh Python để xử lý.
Các câu hỏi khó yêu cầu thao tác tổng hợp cơ bản hoặc phân tích chuỗi thời gian, chẳng hạn như sau:
- Chọn giá trị đầu tiên và nhóm kết quả theo thứ bậc
- Thực hiện thống kê sau khi lựa chọn bản ghi ban đầu
- Số lượng dấu thời gian (ví dụ: tối thiểu và tối đa)
Đối với những câu hỏi khó, mẫu nhắc nhở có hướng dẫn chi tiết từng bước sẽ hỗ trợ FM đưa ra câu trả lời chính xác.
Các câu hỏi ở cấp độ thử thách cần tính toán nâng cao và xử lý chuỗi thời gian, chẳng hạn như sau:
- Tính toán thời lượng bất thường cho mỗi cảm biến
- Tính toán cảm biến bất thường cho trang web hàng tháng
- So sánh số đọc cảm biến trong điều kiện hoạt động bình thường và điều kiện bất thường
Đối với những câu hỏi này, bạn có thể sử dụng nhiều cảnh quay trong lời nhắc tùy chỉnh để nâng cao độ chính xác của câu trả lời. Nhiều bức ảnh như vậy hiển thị các ví dụ về xử lý chuỗi thời gian và tính toán toán học nâng cao, đồng thời sẽ cung cấp bối cảnh để FM thực hiện suy luận có liên quan về phân tích tương tự. Việc chèn động các ví dụ phù hợp nhất từ ngân hàng câu hỏi NLQ vào lời nhắc có thể là một thách thức. Một giải pháp là xây dựng các phần nhúng từ các mẫu câu hỏi NLQ hiện có và lưu các phần nhúng này vào kho lưu trữ vectơ như Dịch vụ OpenSearch. Khi một câu hỏi được gửi đến ứng dụng Streamlit, câu hỏi đó sẽ được vector hóa bởi Nền ĐáNhúng. N phần nhúng có liên quan nhất cho câu hỏi đó được truy xuất bằng cách sử dụng opensearch_vector_search.similarity_search và chèn vào mẫu lời nhắc dưới dạng lời nhắc nhiều lần.
Sơ đồ sau minh họa quy trình làm việc này.
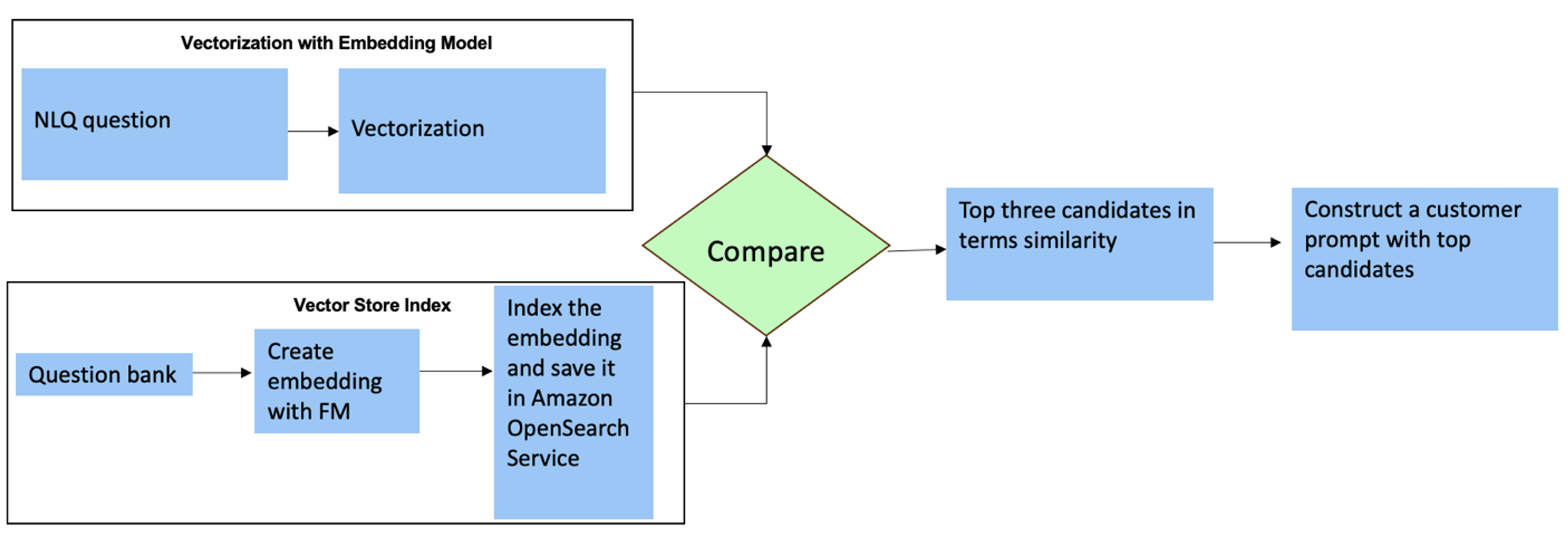
Lớp nhúng được xây dựng bằng ba công cụ chính:
- Mô hình nhúng – Chúng tôi sử dụng Bộ nhúng Amazon Titan có sẵn thông qua Amazon Bedrock (amazon.titan-nhúng-text-v1) để tạo ra các biểu diễn số của tài liệu văn bản.
- Cửa hàng vectơ – Đối với kho lưu trữ vectơ của mình, chúng tôi sử dụng Dịch vụ OpenSearch thông qua khung LangChain, hợp lý hóa việc lưu trữ các phần nhúng được tạo từ các ví dụ NLQ trong sổ ghi chép này.
- Chỉ số – Chỉ mục Dịch vụ Tìm kiếm Mở đóng vai trò then chốt trong việc so sánh các phần nhúng đầu vào với các phần nhúng tài liệu và tạo điều kiện thuận lợi cho việc truy xuất các tài liệu liên quan. Vì mã ví dụ Python được lưu dưới dạng tệp JSON nên chúng được lập chỉ mục trong Dịch vụ OpenSearch dưới dạng vectơ thông qua một OpenSearchVevtorSearch.fromtexts Lệnh gọi API.
Bộ sưu tập liên tục các ví dụ do con người kiểm tra thông qua Streamlit
Khi bắt đầu phát triển ứng dụng, chúng tôi chỉ bắt đầu với 23 ví dụ đã lưu trong chỉ mục Dịch vụ OpenSearch dưới dạng nội dung nhúng. Khi ứng dụng đi vào hoạt động tại hiện trường, người dùng bắt đầu nhập NLQ của họ thông qua ứng dụng. Tuy nhiên, do mẫu có sẵn một số ví dụ hạn chế nên một số NLQ có thể không tìm thấy lời nhắc tương tự. Để liên tục làm phong phú thêm các nội dung nhúng này và đưa ra lời nhắc người dùng phù hợp hơn, bạn có thể sử dụng ứng dụng Streamlit để thu thập các ví dụ do con người kiểm tra.
Trong ứng dụng, chức năng sau phục vụ mục đích này. Khi người dùng cuối thấy kết quả đầu ra hữu ích và chọn Hữu ích, ứng dụng thực hiện theo các bước sau:
- Sử dụng phương thức gọi lại từ PandasAI để thu thập tập lệnh Python.
- Định dạng lại tập lệnh Python, câu hỏi đầu vào và siêu dữ liệu CSV thành một chuỗi.
- Kiểm tra xem ví dụ NLQ này đã tồn tại trong chỉ mục Dịch vụ OpenSearch hiện tại hay chưa bằng cách sử dụng opensearch_vector_search.similarity_search_with_score.
- Nếu không có ví dụ tương tự, NLQ này sẽ được thêm vào chỉ mục Dịch vụ OpenSearch bằng cách sử dụng opensearch_vector_search.add_texts.
Trong trường hợp người dùng chọn Không hữu dụng, không có hành động nào được thực hiện. Quá trình lặp đi lặp lại này đảm bảo rằng hệ thống liên tục cải tiến bằng cách kết hợp các ví dụ do người dùng đóng góp.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Bằng cách kết hợp hoạt động kiểm tra của con người, số lượng mẫu trong Dịch vụ OpenSearch có sẵn để nhúng nhanh chóng sẽ tăng lên khi ứng dụng được sử dụng nhiều hơn. Tập dữ liệu nhúng mở rộng này giúp nâng cao độ chính xác của tìm kiếm theo thời gian. Cụ thể, đối với các NLQ đầy thử thách, độ chính xác phản hồi của FM đạt xấp xỉ 90% khi chèn động các ví dụ tương tự để xây dựng lời nhắc tùy chỉnh cho từng câu hỏi NLQ. Điều này thể hiện mức tăng đáng chú ý là 28% so với các kịch bản không có lời nhắc chụp nhiều cảnh.
Ca sử dụng 2: Chi tiết thiết kế
Trên ứng dụng Streamlit Tóm tắt hình ảnh đã chụp tab, bạn có thể tải trực tiếp tệp hình ảnh lên. Việc này sẽ khởi tạo API nhận dạng lại Amazon (phát hiện văn bản API), trích xuất văn bản từ nhãn hình ảnh chi tiết thông số kỹ thuật của máy. Sau đó, dữ liệu văn bản được trích xuất sẽ được gửi đến mô hình Amazon Bedrock Claude dưới dạng ngữ cảnh của lời nhắc, dẫn đến bản tóm tắt dài 200 từ.
Từ góc độ trải nghiệm người dùng, việc bật chức năng phát trực tuyến cho tác vụ tóm tắt văn bản là điều tối quan trọng, cho phép người dùng đọc bản tóm tắt do FM tạo theo từng phần nhỏ hơn thay vì chờ toàn bộ đầu ra. Amazon Bedrock tạo điều kiện phát trực tuyến thông qua API của nó (bedrock_runtime.invoke_model_with_response_stream).
Ca sử dụng 3: Chi tiết thiết kế
Trong kịch bản này, chúng tôi đã phát triển một ứng dụng chatbot tập trung vào phân tích nguyên nhân gốc rễ, sử dụng phương pháp RAG. Chatbot này lấy từ nhiều tài liệu liên quan đến thiết bị vòng bi để hỗ trợ phân tích nguyên nhân gốc rễ. Chatbot phân tích nguyên nhân gốc rễ dựa trên RAG này sử dụng cơ sở kiến thức để tạo ra các biểu diễn hoặc phần nhúng văn bản vectơ. Cơ sở Kiến thức dành cho Amazon Bedrock là một khả năng được quản lý toàn phần giúp bạn triển khai toàn bộ quy trình làm việc RAG, từ nhập đến truy xuất và tăng cường nhanh chóng mà không cần phải xây dựng các tích hợp tùy chỉnh cho nguồn dữ liệu hay quản lý luồng dữ liệu và chi tiết triển khai RAG.
Khi hài lòng với phản hồi cơ sở kiến thức từ Amazon Bedrock, bạn có thể tích hợp phản hồi nguyên nhân cốt lõi từ cơ sở kiến thức vào ứng dụng Streamlit.
Làm sạch
Để tiết kiệm chi phí, hãy xóa các tài nguyên bạn đã tạo trong bài đăng này:
- Xóa cơ sở kiến thức khỏi Amazon Bedrock.
- Xóa chỉ mục Dịch vụ OpenSearch.
- Xóa ngăn xếp CloudFormation genai-sagemaker.
- Dừng phiên bản EC2 nếu bạn đã sử dụng phiên bản EC2 để chạy ứng dụng Streamlit.
Kết luận
Các ứng dụng AI sáng tạo đã biến đổi nhiều quy trình kinh doanh khác nhau, nâng cao năng suất và bộ kỹ năng của người lao động. Tuy nhiên, những hạn chế của FM trong việc xử lý phân tích dữ liệu chuỗi thời gian đã cản trở việc sử dụng đầy đủ chúng của các khách hàng công nghiệp. Hạn chế này đã cản trở việc áp dụng AI tổng quát cho loại dữ liệu chiếm ưu thế được xử lý hàng ngày.
Trong bài đăng này, chúng tôi đã giới thiệu một giải pháp Ứng dụng AI tổng quát được thiết kế để giảm bớt thách thức này cho người dùng công nghiệp. Ứng dụng này sử dụng một tác nhân nguồn mở, PandasAI, để tăng cường khả năng phân tích chuỗi thời gian của FM. Thay vì gửi dữ liệu chuỗi thời gian trực tiếp tới FM, ứng dụng sử dụng PandasAI để tạo mã Python để phân tích dữ liệu chuỗi thời gian phi cấu trúc. Để nâng cao độ chính xác của việc tạo mã Python, quy trình tạo lời nhắc tùy chỉnh có sự kiểm tra của con người đã được triển khai.
Được trao quyền với những hiểu biết sâu sắc về tình trạng tài sản của mình, các công nhân công nghiệp có thể khai thác tối đa tiềm năng của AI trong các trường hợp sử dụng khác nhau, bao gồm chẩn đoán nguyên nhân gốc rễ và lập kế hoạch thay thế bộ phận. Với Cơ sở kiến thức dành cho Amazon Bedrock, giải pháp RAG giúp các nhà phát triển dễ dàng xây dựng và quản lý.
Quỹ đạo của hoạt động và quản lý dữ liệu doanh nghiệp rõ ràng đang hướng tới việc tích hợp sâu hơn với AI tổng hợp để có được những hiểu biết toàn diện về tình trạng hoạt động. Sự thay đổi này, do Amazon Bedrock dẫn đầu, được khuếch đại đáng kể nhờ sự mạnh mẽ và tiềm năng ngày càng tăng của LLM như Amazon Bedrock Claude 3 để nâng cao hơn nữa các giải pháp. Để tìm hiểu thêm, hãy truy cập tham khảo ý kiến Tài liệu về Amazon Bedrock, và bắt tay vào thực hiện Hội thảo Amazon Bedrock.
Giới thiệu về tác giả
 Julia Hồ là Kiến trúc sư giải pháp AI/ML cấp cao tại Amazon Web Services. Cô ấy chuyên về AI sáng tạo, Khoa học dữ liệu ứng dụng và kiến trúc IoT. Hiện tại, cô là thành viên của nhóm Amazon Q và là thành viên/cố vấn tích cực trong Cộng đồng lĩnh vực kỹ thuật học máy. Cô làm việc với khách hàng, từ các công ty khởi nghiệp đến các doanh nghiệp, để phát triển các giải pháp AI có tính sáng tạo tuyệt vời. Cô đặc biệt đam mê việc tận dụng Mô hình ngôn ngữ lớn để phân tích dữ liệu nâng cao và khám phá các ứng dụng thực tế nhằm giải quyết các thách thức trong thế giới thực.
Julia Hồ là Kiến trúc sư giải pháp AI/ML cấp cao tại Amazon Web Services. Cô ấy chuyên về AI sáng tạo, Khoa học dữ liệu ứng dụng và kiến trúc IoT. Hiện tại, cô là thành viên của nhóm Amazon Q và là thành viên/cố vấn tích cực trong Cộng đồng lĩnh vực kỹ thuật học máy. Cô làm việc với khách hàng, từ các công ty khởi nghiệp đến các doanh nghiệp, để phát triển các giải pháp AI có tính sáng tạo tuyệt vời. Cô đặc biệt đam mê việc tận dụng Mô hình ngôn ngữ lớn để phân tích dữ liệu nâng cao và khám phá các ứng dụng thực tế nhằm giải quyết các thách thức trong thế giới thực.
 Sudeesh Sasidharan là Kiến trúc sư giải pháp cấp cao tại AWS, trong nhóm Năng lượng. Sudeesh thích thử nghiệm các công nghệ mới và xây dựng các giải pháp sáng tạo nhằm giải quyết những thách thức kinh doanh phức tạp. Khi anh ấy không thiết kế các giải pháp hoặc mày mò các công nghệ mới nhất, bạn có thể thấy anh ấy đang tập luyện trái tay trên sân tennis.
Sudeesh Sasidharan là Kiến trúc sư giải pháp cấp cao tại AWS, trong nhóm Năng lượng. Sudeesh thích thử nghiệm các công nghệ mới và xây dựng các giải pháp sáng tạo nhằm giải quyết những thách thức kinh doanh phức tạp. Khi anh ấy không thiết kế các giải pháp hoặc mày mò các công nghệ mới nhất, bạn có thể thấy anh ấy đang tập luyện trái tay trên sân tennis.
 Neil Desai là giám đốc điều hành công nghệ với hơn 20 năm kinh nghiệm trong lĩnh vực trí tuệ nhân tạo (AI), khoa học dữ liệu, công nghệ phần mềm và kiến trúc doanh nghiệp. Tại AWS, ông lãnh đạo một nhóm gồm các kiến trúc sư giải pháp chuyên gia về dịch vụ AI toàn cầu, giúp khách hàng xây dựng các giải pháp sáng tạo dựa trên AI, chia sẻ các phương pháp hay nhất với khách hàng và thúc đẩy lộ trình sản phẩm. Trong các vai trò trước đây của mình tại Vestas, Honeywell và Quest Diagnostics, Neil đã giữ vai trò lãnh đạo trong việc phát triển và tung ra các sản phẩm và dịch vụ đổi mới giúp các công ty cải thiện hoạt động, giảm chi phí và tăng doanh thu. Anh ấy đam mê sử dụng công nghệ để giải quyết các vấn đề trong thế giới thực và là một nhà tư tưởng chiến lược với thành tích thành công đã được chứng minh.
Neil Desai là giám đốc điều hành công nghệ với hơn 20 năm kinh nghiệm trong lĩnh vực trí tuệ nhân tạo (AI), khoa học dữ liệu, công nghệ phần mềm và kiến trúc doanh nghiệp. Tại AWS, ông lãnh đạo một nhóm gồm các kiến trúc sư giải pháp chuyên gia về dịch vụ AI toàn cầu, giúp khách hàng xây dựng các giải pháp sáng tạo dựa trên AI, chia sẻ các phương pháp hay nhất với khách hàng và thúc đẩy lộ trình sản phẩm. Trong các vai trò trước đây của mình tại Vestas, Honeywell và Quest Diagnostics, Neil đã giữ vai trò lãnh đạo trong việc phát triển và tung ra các sản phẩm và dịch vụ đổi mới giúp các công ty cải thiện hoạt động, giảm chi phí và tăng doanh thu. Anh ấy đam mê sử dụng công nghệ để giải quyết các vấn đề trong thế giới thực và là một nhà tư tưởng chiến lược với thành tích thành công đã được chứng minh.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

