그 핵심에서, 랭체인 언어 모델의 기능을 활용하는 애플리케이션 제작을 위해 맞춤화된 혁신적인 프레임워크입니다. 개발자가 상황을 인식하고 정교한 추론이 가능한 애플리케이션을 만들 수 있도록 설계된 툴킷입니다.
이는 LangChain 애플리케이션이 프롬프트 지침이나 콘텐츠 기반 응답과 같은 컨텍스트를 이해하고 응답 방법이나 취해야 할 조치 결정과 같은 복잡한 추론 작업에 언어 모델을 사용할 수 있음을 의미합니다. LangChain은 지능형 애플리케이션 개발에 대한 통합 접근 방식을 나타내며 다양한 구성 요소를 통해 개념에서 실행까지의 과정을 단순화합니다.
LangChain 이해하기
LangChain은 단순한 프레임워크 그 이상입니다. 이는 여러 필수 부분으로 구성된 본격적인 생태계입니다.
- 첫째, Python과 JavaScript 모두에서 사용할 수 있는 LangChain 라이브러리가 있습니다. 이러한 라이브러리는 LangChain의 중추로서 다양한 구성 요소에 대한 인터페이스와 통합을 제공합니다. 이러한 구성요소를 응집력 있는 체인 및 에이전트로 결합하기 위한 기본 런타임과 즉시 사용할 수 있는 기성 구현을 제공합니다.
- 다음으로 LangChain 템플릿이 있습니다. 이는 다양한 작업에 맞게 조정된 배포 가능한 참조 아키텍처 모음입니다. 챗봇을 구축하든 복잡한 분석 도구를 구축하든 이 템플릿은 확실한 시작점을 제공합니다.
- LangServe는 LangChain 체인을 REST API로 배포하기 위한 다목적 라이브러리 역할을 합니다. 이 도구는 LangChain 프로젝트를 접근 가능하고 확장 가능한 웹 서비스로 전환하는 데 필수적입니다.
- 마지막으로 LangSmith는 개발자 플랫폼 역할을 합니다. 모든 LLM 프레임워크에 구축된 체인을 디버깅, 테스트, 평가 및 모니터링하도록 설계되었습니다. LangChain과의 원활한 통합으로 인해 LangChain은 애플리케이션을 개선하고 완벽하게 만드는 것을 목표로 하는 개발자에게 없어서는 안 될 도구가 되었습니다.
이러한 구성 요소를 함께 사용하면 애플리케이션을 쉽게 개발, 생산 및 배포할 수 있습니다. LangChain을 사용하면 지침용 템플릿을 참조하여 라이브러리를 사용하여 애플리케이션을 작성하는 것부터 시작합니다. 그런 다음 LangSmith는 체인을 검사, 테스트 및 모니터링하여 애플리케이션이 지속적으로 개선되고 배포할 준비가 되었는지 확인하는 데 도움을 줍니다. 마지막으로 LangServe를 사용하면 모든 체인을 API로 쉽게 변환하여 배포가 쉬워집니다.
다음 섹션에서는 LangChain을 설정하는 방법과 지능형 언어 모델 기반 애플리케이션을 만드는 여정을 시작하는 방법에 대해 자세히 살펴보겠습니다.
귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
설치 및 설정
LangChain의 세계로 뛰어들 준비가 되셨나요? 설정은 간단하며 이 가이드에서는 프로세스를 단계별로 안내합니다.
LangChain 여정의 첫 번째 단계는 이를 설치하는 것입니다. pip나 conda를 사용하면 쉽게 할 수 있습니다. 터미널에서 다음 명령을 실행하세요.
pip install langchain
최신 기능을 선호하고 좀 더 모험을 즐기는 사람들을 위해 소스에서 직접 LangChain을 설치할 수 있습니다. 저장소를 복제하고 다음으로 이동합니다. langchain/libs/langchain 예배 규칙서. 그런 다음 다음을 실행합니다.
pip install -e .
실험적 기능을 사용하려면 설치를 고려하세요. langchain-experimental. 최첨단 코드가 포함된 패키지이며 연구 및 실험 목적으로 사용됩니다. 다음을 사용하여 설치하십시오.
pip install langchain-experimental
LangChain CLI는 LangChain 템플릿 및 LangServe 프로젝트 작업을 위한 편리한 도구입니다. LangChain CLI를 설치하려면 다음을 사용하십시오.
pip install langchain-cli
LangServe는 LangChain 체인을 REST API로 배포하는 데 필수적입니다. LangChain CLI와 함께 설치됩니다.
LangChain은 모델 공급자, 데이터 저장소, API 등과의 통합이 필요한 경우가 많습니다. 이 예에서는 OpenAI의 모델 API를 사용하겠습니다. 다음을 사용하여 OpenAI Python 패키지를 설치합니다.
pip install openai
API에 액세스하려면 OpenAI API 키를 환경 변수로 설정하세요.
export OPENAI_API_KEY="your_api_key"
또는 Python 환경에서 직접 키를 전달하세요.
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain을 사용하면 모듈을 통해 언어 모델 애플리케이션을 생성할 수 있습니다. 이러한 모듈은 독립형이거나 복잡한 사용 사례를 위해 구성될 수 있습니다. 이 모듈은 –
- 모델 입출력: 다양한 언어 모델과의 상호 작용을 촉진하여 입력과 출력을 효율적으로 처리합니다.
- 검색: 동적 데이터 활용에 중요한 애플리케이션별 데이터에 대한 액세스 및 상호 작용을 가능하게 합니다.
- 에이전트: 높은 수준의 지침을 기반으로 적절한 도구를 선택하도록 애플리케이션을 강화하여 의사 결정 기능을 향상시킵니다.
- 쇠사슬: 애플리케이션 개발을 위한 빌딩 블록 역할을 하는 사전 정의되고 재사용 가능한 구성을 제공합니다.
- 메모리: 컨텍스트 인식 상호 작용에 필수적인 여러 체인 실행 전반에 걸쳐 애플리케이션 상태를 유지합니다.
각 모듈은 특정 개발 요구 사항을 대상으로 하여 LangChain을 고급 언어 모델 애플리케이션 생성을 위한 포괄적인 툴킷으로 만듭니다.
위의 구성품과 함께 우리는 또한 랭체인 표현 언어(LCEL), 이는 모듈을 쉽게 함께 구성하는 선언적 방법이며, 이를 통해 범용 Runnable 인터페이스를 사용하여 구성 요소를 연결할 수 있습니다.
LCEL은 다음과 같습니다.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
이제 기본 사항을 다루었으므로 다음을 계속 진행하겠습니다.
- 각 Langchain 모듈을 자세히 살펴보세요.
- LangChain 표현 언어를 사용하는 방법을 알아보세요.
- 일반적인 사용 사례를 살펴보고 구현해 보세요.
- LangServe를 사용하여 엔드투엔드 애플리케이션을 배포하세요.
- 디버깅, 테스트 및 모니터링에 대해서는 LangSmith를 확인하세요.
시작하자!
모듈 I : 모델 I/O
LangChain에서 모든 애플리케이션의 핵심 요소는 언어 모델을 중심으로 이루어집니다. 이 모듈은 모든 언어 모델과 효과적으로 인터페이스할 수 있는 필수 빌딩 블록을 제공하여 원활한 통합과 통신을 보장합니다.
모델 I/O의 주요 구성요소
- LLM 및 채팅 모델(교환 가능하게 사용됨):
- LLM:
- 정의: 순수 텍스트 완성 모델.
- 입력 / 출력: 텍스트 문자열을 입력으로 사용하고 텍스트 문자열을 출력으로 반환합니다.
- 채팅 모델
- LLM:
- 정의: 언어 모델을 기본으로 사용하지만 입력 및 출력 형식이 다른 모델입니다.
- 입력 / 출력: 채팅 메시지 목록을 입력으로 수락하고 채팅 메시지를 반환합니다.
- 프롬프트: 모델 입력을 템플릿화하고, 동적으로 선택하고, 관리합니다. 언어 모델의 응답을 안내하는 유연하고 상황에 맞는 프롬프트를 생성할 수 있습니다.
- 출력 파서: 모델 출력에서 정보를 추출하고 형식을 지정합니다. 언어 모델의 원시 출력을 구조화된 데이터 또는 애플리케이션에 필요한 특정 형식으로 변환하는 데 유용합니다.
LLM
OpenAI, Cohere 및 Hugging Face와 같은 LLM(대형 언어 모델)과 LangChain의 통합은 기능의 기본 측면입니다. LangChain 자체는 LLM을 호스팅하지 않지만 다양한 LLM과 상호 작용할 수 있는 통일된 인터페이스를 제공합니다.
이 섹션에서는 다른 LLM 유형에도 적용할 수 있는 LangChain의 OpenAI LLM 래퍼 사용에 대한 개요를 제공합니다. 우리는 이미 “시작하기” 섹션에서 이를 설치했습니다. LLM을 초기화해 보겠습니다.
from langchain.llms import OpenAI
llm = OpenAI()
- LLM은 다음을 구현합니다. 실행 가능한 인터페이스, 의 기본 빌딩 블록 랭체인 표현 언어(LCEL). 이는 그들이 지원한다는 것을 의미합니다.
invoke,ainvoke,stream,astream,batch,abatch,astream_log전화. - LLM은 수락합니다 문자열 다음을 포함하여 문자열 프롬프트로 강제될 수 있는 입력 또는 객체로
List[BaseMessage]과PromptValue. (나중에 이에 대해 자세히 설명)
몇 가지 예를 살펴보겠습니다.
response = llm.invoke("List the seven wonders of the world.")
print(response)

또는 스트림 메서드를 호출하여 텍스트 응답을 스트리밍할 수도 있습니다.
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

채팅 모델
언어 모델의 특수한 변형인 채팅 모델과 LangChain의 통합은 대화형 채팅 애플리케이션을 만드는 데 필수적입니다. 내부적으로 언어 모델을 활용하는 반면 채팅 모델은 채팅 메시지를 중심으로 입력 및 출력으로 사용되는 고유한 인터페이스를 제공합니다. 이 섹션에서는 LangChain에서 OpenAI의 채팅 모델을 사용하는 방법에 대한 자세한 개요를 제공합니다.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
LangChain의 채팅 모델은 다음과 같은 다양한 메시지 유형으로 작동합니다. AIMessage, HumanMessage, SystemMessage, FunctionMessage및 ChatMessage (임의의 역할 매개변수 사용) 일반적으로, HumanMessage, AIMessage및 SystemMessage 가장 자주 사용됩니다.
채팅 모델은 주로 허용됩니다. List[BaseMessage] 입력으로. 문자열은 다음으로 변환될 수 있습니다. HumanMessage및 PromptValue 또한 지원됩니다.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)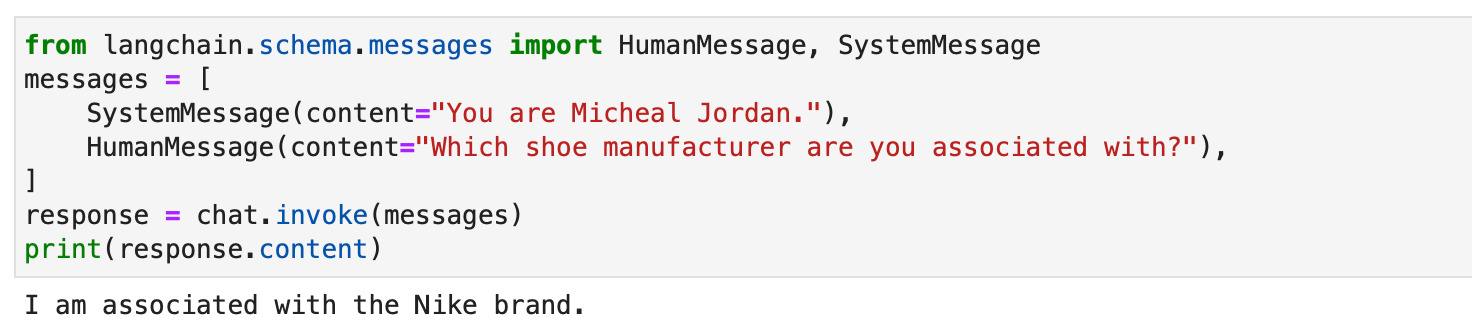
프롬프트
프롬프트는 관련성 있고 일관된 출력을 생성하도록 언어 모델을 안내하는 데 필수적입니다. 간단한 지침부터 복잡한 몇 번의 예시까지 다양합니다. LangChain에서는 여러 전용 클래스와 기능 덕분에 프롬프트 처리가 매우 간소화된 프로세스가 될 수 있습니다.
랭체인의 PromptTemplate 클래스는 문자열 프롬프트를 생성하기 위한 다목적 도구입니다. Python을 사용합니다. str.format 동적 프롬프트 생성이 가능한 구문입니다. 자리 표시자로 템플릿을 정의하고 필요에 따라 특정 값으로 채울 수 있습니다.
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)채팅 모델의 경우 특정 역할의 메시지를 포함하여 프롬프트가 더 구조화됩니다. LangChain 제안 ChatPromptTemplate 이 목적을 위해.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
이 접근 방식을 사용하면 역동적인 응답을 제공하는 대화형의 매력적인 챗봇을 만들 수 있습니다.
모두 PromptTemplate 과 ChatPromptTemplate LCEL(LangChain Expression Language)과 원활하게 통합되어 더 크고 복잡한 워크플로의 일부가 될 수 있습니다. 이에 대해서는 나중에 더 자세히 논의하겠습니다.
고유한 서식이나 특정 지침이 필요한 작업에는 사용자 정의 프롬프트 템플릿이 필수적인 경우가 있습니다. 사용자 정의 프롬프트 템플릿을 생성하려면 입력 변수와 사용자 정의 형식 지정 방법을 정의해야 합니다. 이러한 유연성을 통해 LangChain은 다양한 애플리케이션별 요구 사항을 충족할 수 있습니다. 자세한 내용은 여기를 참조하십시오.
LangChain은 또한 Few-Shot Prompting을 지원하여 모델이 예제를 통해 학습할 수 있도록 합니다. 이 기능은 상황에 따른 이해나 특정 패턴이 필요한 작업에 필수적입니다. 몇 개의 샷 프롬프트 템플릿은 예제 세트에서 또는 예제 선택기 개체를 활용하여 구축할 수 있습니다. 자세한 내용은 여기를 참조하십시오.
출력 파서
출력 파서는 Langchain에서 중요한 역할을 하며 사용자가 언어 모델에 의해 생성된 응답을 구조화할 수 있도록 합니다. 이 섹션에서는 출력 파서의 개념을 살펴보고 Langchain의 PydanticOutputParser, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser 및 XMLOutputParser를 사용하여 코드 예제를 제공합니다.
PydanticOutputParser
Langchain은 응답을 Pydantic 데이터 구조로 구문 분석하기 위해 PydanticOutputParser를 제공합니다. 다음은 사용 방법에 대한 단계별 예입니다.
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
출력은 다음과 같습니다

SimpleJsonOutputParser
Langchain의 SimpleJsonOutputParser는 JSON과 유사한 출력을 구문 분석하려는 경우에 사용됩니다. 예는 다음과 같습니다.
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)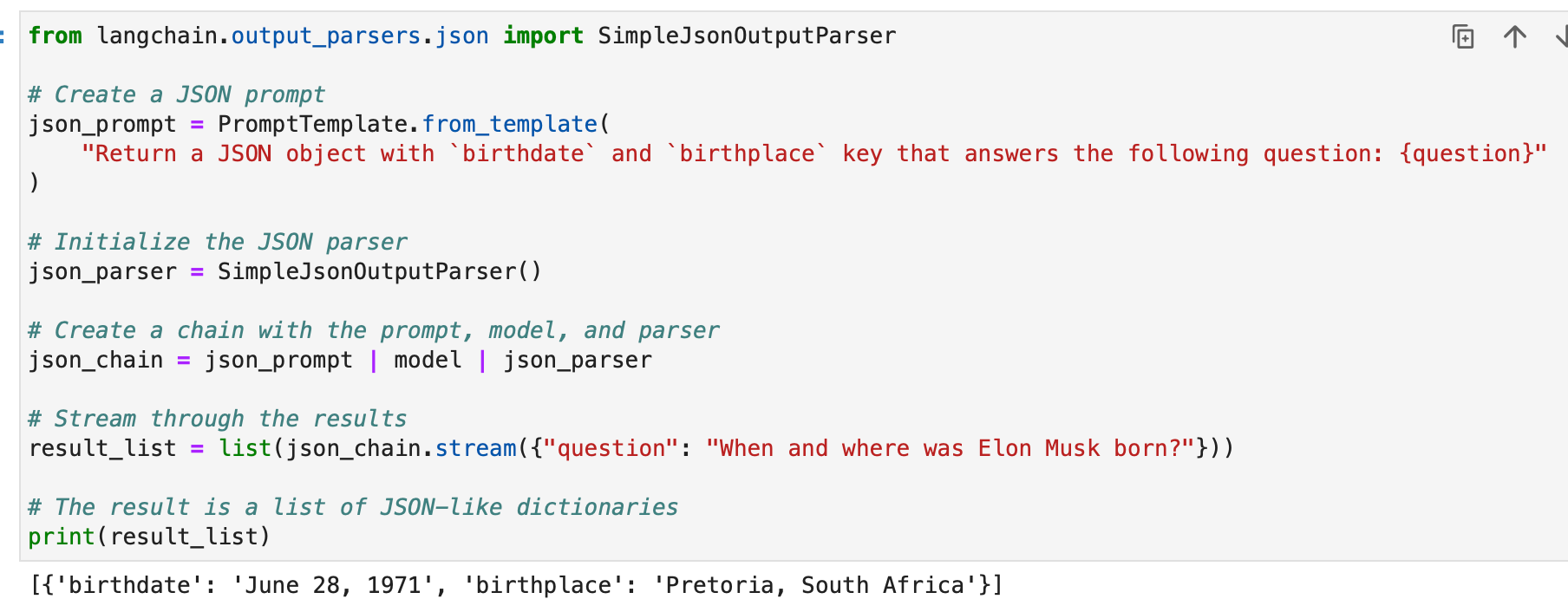
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser는 모델 응답에서 쉼표로 구분된 목록을 추출하려는 경우 유용합니다. 예는 다음과 같습니다.
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)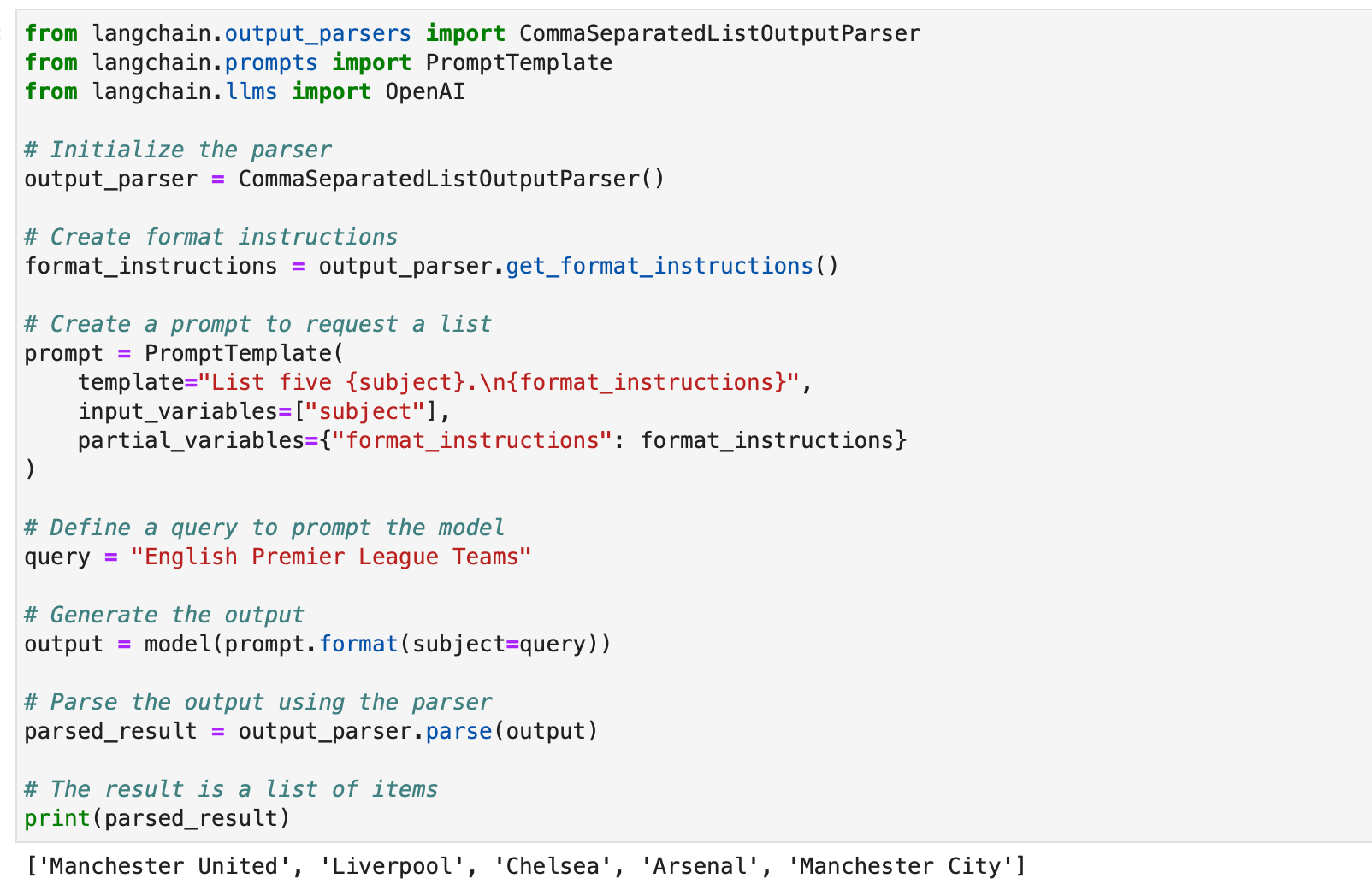
DatetimeOutputParser
Langchain의 DatetimeOutputParser는 날짜/시간 정보를 구문 분석하도록 설계되었습니다. 사용 방법은 다음과 같습니다.
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
이러한 예는 Langchain의 출력 파서를 사용하여 다양한 유형의 모델 응답을 구조화하여 다양한 애플리케이션과 형식에 적합하게 만드는 방법을 보여줍니다. 출력 파서는 Langchain에서 언어 모델 출력의 유용성과 해석성을 향상시키는 데 유용한 도구입니다.
귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
모듈 II: 검색
LangChain의 검색은 모델의 훈련 세트에 포함되지 않은 사용자별 데이터가 필요한 애플리케이션에서 중요한 역할을 합니다. RAG(Retrieval Augmented Generation)로 알려진 이 프로세스에는 외부 데이터를 가져와 이를 언어 모델의 생성 프로세스에 통합하는 작업이 포함됩니다. LangChain은 이 프로세스를 촉진하고 단순하고 복잡한 애플리케이션 모두에 맞는 포괄적인 도구 및 기능 제품군을 제공합니다.
LangChain은 우리가 하나씩 논의할 일련의 구성요소를 통해 검색을 달성합니다.
문서 로더
LangChain의 문서 로더를 사용하면 다양한 소스에서 데이터를 추출할 수 있습니다. 100개 이상의 로더를 사용할 수 있어 다양한 문서 유형, 앱 및 소스(비공개 s3 버킷, 공개 웹사이트, 데이터베이스)를 지원합니다.
요구 사항에 따라 문서 로더를 선택할 수 있습니다. 여기에서 지금 확인해 보세요..
이러한 모든 로더는 데이터를 수집합니다. 문서 클래스. Document 클래스에 수집된 데이터를 사용하는 방법은 나중에 배우겠습니다.
텍스트 파일 로더: 간단한 로드 .txt 문서에 파일을 넣습니다.
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
CSV 로더: CSV 파일을 문서에 로드합니다.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
필드 이름을 지정하여 구문 분석을 사용자 정의하도록 선택할 수 있습니다.
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
PDF 로더: LangChain의 PDF 로더는 PDF 파일에서 콘텐츠를 구문 분석하고 추출하기 위한 다양한 방법을 제공합니다. 각 로더는 서로 다른 요구 사항을 충족하고 서로 다른 기본 라이브러리를 사용합니다. 다음은 각 로더에 대한 자세한 예입니다.
PyPDFLoader는 기본 PDF 구문 분석에 사용됩니다.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader는 수학적 내용과 다이어그램을 추출하는 데 이상적입니다.
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader는 빠르며 자세한 메타데이터 추출이 포함되어 있습니다.
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Loader는 텍스트 추출을 보다 세부적으로 제어하는 데 사용됩니다.
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser는 OCR 및 기타 고급 PDF 구문 분석 기능을 위해 AWS Textract를 활용합니다.
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader는 의미 분석을 위해 PDF에서 HTML을 생성합니다.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader는 자세한 메타데이터를 제공하고 페이지당 하나의 문서를 지원합니다.
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
통합 로더: LangChain은 앱(예: Slack, Sigma, Notion, Confluence, Google Drive 등)과 데이터베이스에서 데이터를 직접 로드하고 LLM 애플리케이션에서 사용할 수 있는 다양한 사용자 정의 로더를 제공합니다.
전체 목록은 다음과 같습니다. 여기에서 지금 확인해 보세요..
다음은 이를 설명하는 몇 가지 예입니다.
예시 I - Slack
널리 사용되는 인스턴트 메시징 플랫폼인 Slack은 LLM 워크플로 및 애플리케이션에 통합될 수 있습니다.
- Slack 작업 공간 관리 페이지로 이동하세요.
- 로 이동
{your_slack_domain}.slack.com/services/export. - 원하는 날짜 범위를 선택하고 내보내기를 시작하세요.
- 내보내기가 준비되면 Slack에서 이메일과 DM을 통해 알립니다.
- 내보내기 결과는
.zip다운로드 폴더 또는 지정된 다운로드 경로에 있는 파일입니다. - 다운로드한 경로를 지정합니다.
.zip에 파일을LOCAL_ZIPFILE. - 사용
SlackDirectoryLoader인사말langchain.document_loaders패키지.
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
예시 II – Figma
인터페이스 디자인에 널리 사용되는 도구인 Figma는 데이터 통합을 위한 REST API를 제공합니다.
- URL 형식에서 Figma 파일 키를 얻습니다.
https://www.figma.com/file/{filekey}/sampleFilename. - 노드 ID는 URL 매개변수에서 찾을 수 있습니다.
?node-id={node_id}. - 다음 지침에 따라 액세스 토큰을 생성하세요. Figma 도움말 센터.
- XNUMXD덴탈의
FigmaFileLoader수업에서langchain.document_loaders.figmaFigma 데이터를 로드하는 데 사용됩니다. - 다음과 같은 다양한 LangChain 모듈
CharacterTextSplitter,ChatOpenAI등이 처리에 사용됩니다.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- XNUMXD덴탈의
generate_code함수는 Figma 데이터를 사용하여 HTML/CSS 코드를 생성합니다. - GPT 기반 모델과 템플릿 대화를 사용합니다.
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- XNUMXD덴탈의
generate_code함수가 실행되면 Figma 디자인 입력을 기반으로 HTML/CSS 코드가 반환됩니다.
이제 우리의 지식을 활용하여 몇 가지 문서 세트를 만들어 보겠습니다.
먼저 BCG 연간 지속 가능성 보고서인 PDF를 로드합니다.

이를 위해 PyPDFLoader를 사용합니다.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
이제 Airtable에서 데이터를 수집하겠습니다. 다양한 OCR 및 데이터 추출 모델에 대한 정보가 포함된 Airtable이 있습니다.
이를 위해 통합 로더 목록에 있는 AirtableLoader를 사용하겠습니다.
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
이제 계속 진행하여 이러한 문서 클래스를 사용하는 방법을 알아 보겠습니다.
문서 변환기
LangChain의 문서 변환기는 이전 하위 섹션에서 생성한 문서를 조작하도록 설계된 필수 도구입니다.
긴 문서를 더 작은 덩어리로 분할하고 결합하고 필터링하는 등의 작업에 사용됩니다. 이는 문서를 모델의 컨텍스트 창에 맞추거나 특정 애플리케이션 요구 사항을 충족하는 데 중요합니다.
그러한 도구 중 하나는 분할을 위해 문자 목록을 사용하는 다목적 텍스트 분할기인 RecursiveCharacterTextSplitter입니다. 청크 크기, 겹침 및 시작 인덱스와 같은 매개변수를 허용합니다. Python에서 사용되는 방법의 예는 다음과 같습니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
또 다른 도구는 지정된 문자를 기반으로 텍스트를 분할하고 청크 크기 및 겹침에 대한 컨트롤을 포함하는 CharacterTextSplitter입니다.
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter는 의미 구조를 유지하면서 헤더 태그를 기반으로 HTML 콘텐츠를 분할하도록 설계되었습니다.
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
HTMLHeaderTextSplitter를 Pipelined Splitter와 같은 다른 분할기와 결합하면 보다 복잡한 조작을 수행할 수 있습니다.
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain은 또한 Python Code Splitter 및 JavaScript Code Splitter와 같은 다양한 프로그래밍 언어에 대한 특정 분할기를 제공합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
토큰 제한이 있는 언어 모델에 유용한 토큰 수를 기반으로 텍스트를 분할하려면 TokenTextSplitter가 사용됩니다.
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
마지막으로 LongContextReorder는 긴 컨텍스트로 인한 모델의 성능 저하를 방지하기 위해 문서 순서를 변경합니다.
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
이러한 도구는 간단한 텍스트 분할에서 복잡한 재정렬 및 언어별 분할에 이르기까지 LangChain에서 문서를 변환하는 다양한 방법을 보여줍니다. 보다 심층적이고 구체적인 사용 사례에 대해서는 LangChain 문서 및 통합 섹션을 참조해야 합니다.
우리의 예에서 로더는 이미 청크 문서를 생성했으며 이 부분은 이미 처리되었습니다.
텍스트 임베딩 모델
LangChain의 텍스트 임베딩 모델은 OpenAI, Cohere 및 Hugging Face와 같은 다양한 임베딩 모델 공급자를 위한 표준화된 인터페이스를 제공합니다. 이러한 모델은 텍스트를 벡터 표현으로 변환하여 벡터 공간의 텍스트 유사성을 통한 의미 검색과 같은 작업을 가능하게 합니다.
텍스트 임베딩 모델을 시작하려면 일반적으로 특정 패키지를 설치하고 API 키를 설정해야 합니다. 우리는 OpenAI에 대해 이미 이 작업을 수행했습니다.
랭체인에서는 embed_documents 메서드는 여러 텍스트를 삽입하여 벡터 표현 목록을 제공하는 데 사용됩니다. 예를 들어:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
검색어와 같은 단일 텍스트를 삽입하려면 embed_query 방법이 사용됩니다. 이는 쿼리를 문서 임베딩 세트와 비교하는 데 유용합니다. 예를 들어:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
이러한 임베딩을 이해하는 것이 중요합니다. 각 텍스트 조각은 벡터로 변환되며, 그 크기는 사용된 모델에 따라 달라집니다. 예를 들어 OpenAI 모델은 일반적으로 1536차원 벡터를 생성합니다. 그런 다음 이러한 임베딩은 관련 정보를 검색하는 데 사용됩니다.
LangChain의 임베딩 기능은 OpenAI에만 국한되지 않고 다양한 공급자와 작동하도록 설계되었습니다. 제공업체에 따라 설정 및 사용법이 약간 다를 수 있지만 벡터 공간에 텍스트를 삽입하는 핵심 개념은 동일합니다. 고급 구성 및 다양한 임베딩 모델 제공자와의 통합을 포함한 자세한 사용법을 보려면 통합 섹션에 있는 LangChain 문서가 귀중한 리소스입니다.
벡터 상점
LangChain의 벡터 저장소는 텍스트 임베딩의 효율적인 저장 및 검색을 지원합니다. LangChain은 50개 이상의 벡터 저장소와 통합되어 사용하기 쉬운 표준화된 인터페이스를 제공합니다.
예: 임베딩 저장 및 검색
텍스트를 삽입한 후 다음과 같은 벡터 저장소에 저장할 수 있습니다. Chroma 유사성 검색을 수행합니다.
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
대안으로 FAISS 벡터 저장소를 사용하여 문서에 대한 인덱스를 생성하겠습니다.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

리트리버
LangChain의 리트리버는 구조화되지 않은 쿼리에 대한 응답으로 문서를 반환하는 인터페이스입니다. 벡터 저장소보다 더 일반적이며 저장보다는 검색에 중점을 둡니다. 벡터 저장소를 리트리버의 백본으로 사용할 수 있지만 다른 유형의 리트리버도 있습니다.
Chroma 검색기를 설정하려면 먼저 다음을 사용하여 설치합니다. pip install chromadb. 그런 다음 일련의 Python 명령을 사용하여 문서를 로드, 분할, 포함 및 검색합니다. 다음은 Chroma 검색기 설정을 위한 코드 예제입니다.
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever는 사용자 입력 쿼리에 대해 여러 쿼리를 생성하여 프롬프트 조정을 자동화하고 결과를 결합합니다. 다음은 간단한 사용법의 예입니다.
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
LangChain의 상황별 압축은 쿼리의 상황을 사용하여 검색된 문서를 압축하여 관련 정보만 반환되도록 합니다. 여기에는 콘텐츠 축소 및 관련성이 낮은 문서 필터링이 포함됩니다. 다음 코드 예제는 상황별 압축 검색기를 사용하는 방법을 보여줍니다.
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
EnsembleRetriever는 더 나은 성능을 달성하기 위해 다양한 검색 알고리즘을 결합합니다. BM25와 FAISS 리트리버를 결합하는 예는 다음 코드에 나와 있습니다.
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
LangChain의 MultiVector Retriever를 사용하면 문서당 여러 벡터로 문서를 쿼리할 수 있으며, 이는 문서 내의 다양한 의미 측면을 캡처하는 데 유용합니다. 여러 벡터를 생성하는 방법에는 더 작은 덩어리로 분할, 요약 또는 가상 질문 생성이 포함됩니다. 문서를 더 작은 덩어리로 분할하려면 다음 Python 코드를 사용할 수 있습니다.
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
보다 집중된 콘텐츠 표현으로 인해 더 나은 검색을 위한 요약을 생성하는 것도 또 다른 방법입니다. 다음은 요약을 생성하는 예입니다.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
LLM을 사용하여 각 문서와 관련된 가상 질문을 생성하는 것도 또 다른 접근 방식입니다. 이는 다음 코드를 사용하여 수행할 수 있습니다.
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
상위 문서 검색기는 작은 청크를 저장하고 더 큰 상위 문서를 검색하여 포함 정확도와 컨텍스트 보존 간의 균형을 유지하는 또 다른 검색기입니다. 구현은 다음과 같습니다.
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
자체 쿼리 검색기는 자연어 입력에서 구조화된 쿼리를 구성하고 이를 기본 VectorStore에 적용합니다. 구현은 다음 코드에 나와 있습니다.
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever는 주어진 쿼리를 기반으로 웹 조사를 수행합니다.
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
예제에서는 다음과 같이 벡터 저장소 객체의 일부로 이미 구현된 표준 검색기를 사용할 수도 있습니다.

이제 검색기에 쿼리할 수 있습니다. 쿼리의 출력은 쿼리와 관련된 문서 개체가 됩니다. 이는 궁극적으로 추가 섹션에서 관련 답변을 작성하는 데 활용될 것입니다.


귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
모듈 III: 에이전트
LangChain은 체인의 개념을 완전히 새로운 차원으로 끌어올리는 "에이전트"라는 강력한 개념을 도입합니다. 에이전트는 언어 모델을 활용하여 수행할 작업 순서를 동적으로 결정하므로 놀라울 정도로 다재다능하고 적응력이 뛰어납니다. 작업이 코드에 하드코딩되는 기존 체인과 달리 에이전트는 언어 모델을 추론 엔진으로 사용하여 수행할 작업과 순서를 결정합니다.
에이전트 의사결정을 담당하는 핵심 구성요소입니다. 이는 특정 목표를 달성하기 위한 다음 단계를 결정하기 위한 언어 모델과 프롬프트의 힘을 활용합니다. 에이전트에 대한 입력에는 일반적으로 다음이 포함됩니다.
- 도구 : 사용 가능한 도구에 대한 설명(나중에 자세히 설명)
- 사용자 입력: 사용자의 상위 수준 목표 또는 쿼리입니다.
- 중간 단계: 현재 사용자 입력에 도달하기 위해 실행된 (작업, 도구 출력) 쌍의 기록입니다.
에이전트의 출력은 다음이 될 수 있습니다. 동작 조치를 취하다(에이전트 작업) 또는 최종 응답 사용자에게 보내려면 (에이전트완료). 안 동작 지정 수단 그리고 입력 그 도구를 위해.
도구
도구는 에이전트가 세상과 상호작용하는 데 사용할 수 있는 인터페이스입니다. 이를 통해 에이전트는 웹 검색, 셸 명령 실행, 외부 API 액세스 등 다양한 작업을 수행할 수 있습니다. LangChain에서 도구는 에이전트의 기능을 확장하고 다양한 작업을 수행할 수 있도록 하는 데 필수적입니다.
LangChain의 도구를 사용하려면 다음 코드 조각을 사용하여 도구를 로드할 수 있습니다.
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
일부 도구는 초기화하려면 기본 언어 모델(LLM)이 필요할 수 있습니다. 이러한 경우에는 LLM도 통과할 수 있습니다.
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
이 설정을 사용하면 다양한 도구에 액세스하고 이를 에이전트의 워크플로에 통합할 수 있습니다. 사용법 문서가 포함된 전체 도구 목록은 다음과 같습니다. 여기에서 지금 확인해 보세요..
도구의 몇 가지 예를 살펴보겠습니다.
DuckDuckGo
DuckDuckGo 도구를 사용하면 검색 엔진을 사용하여 웹 검색을 수행할 수 있습니다. 사용 방법은 다음과 같습니다.
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DataForSeo
DataForSeo 툴킷을 사용하면 DataForSeo API를 사용하여 검색 엔진 결과를 얻을 수 있습니다. 이 툴킷을 사용하려면 API 자격 증명을 설정해야 합니다. 자격 증명을 구성하는 방법은 다음과 같습니다.
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
자격 증명이 설정되면 DataForSeoAPIWrapper API에 액세스하기 위한 도구:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
XNUMXD덴탈의 DataForSeoAPIWrapper 도구는 다양한 소스에서 검색 엔진 결과를 검색합니다.
JSON 응답에 반환되는 결과 및 필드 유형을 사용자 지정할 수 있습니다. 예를 들어, 결과 유형과 필드를 지정하고 반환할 상위 결과 수의 최대 개수를 설정할 수 있습니다.
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
이 예에서는 결과 유형, 필드를 지정하고 결과 수를 제한하여 JSON 응답을 사용자 정의합니다.
API 래퍼에 추가 매개변수를 전달하여 검색 결과의 위치와 언어를 지정할 수도 있습니다.
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
위치 및 언어 매개변수를 제공하면 검색 결과를 특정 지역 및 언어에 맞게 조정할 수 있습니다.
사용하려는 검색 엔진을 유연하게 선택할 수 있습니다. 원하는 검색 엔진을 지정하기만 하면 됩니다.
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
이 예에서는 Bing을 검색 엔진으로 사용하도록 검색이 사용자 지정되었습니다.
API 래퍼를 사용하면 수행하려는 검색 유형을 지정할 수도 있습니다. 예를 들어 지도 검색을 수행할 수 있습니다.
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
지도 관련 정보를 검색하도록 검색을 사용자 정의합니다.
쉘(배시)
셸 툴킷은 에이전트에게 셸 환경에 대한 액세스 권한을 제공하여 셸 명령을 실행할 수 있도록 합니다. 이 기능은 강력하지만 특히 샌드박스 환경에서는 주의해서 사용해야 합니다. Shell 도구를 사용하는 방법은 다음과 같습니다.
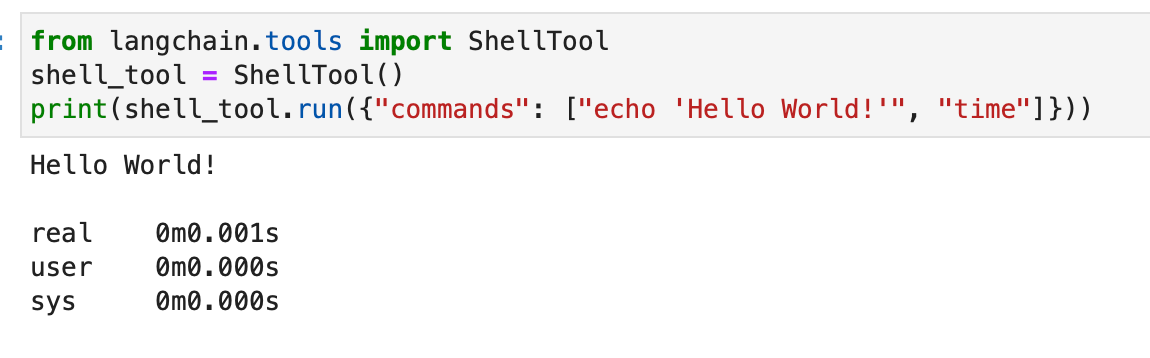
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
이 예에서 셸 도구는 "Hello World!"를 에코하는 두 가지 셸 명령을 실행합니다. 그리고 현재 시간을 표시합니다.
더 복잡한 작업을 수행하기 위해 에이전트에 셸 도구를 제공할 수 있습니다. 다음은 셸 도구를 사용하여 웹 페이지에서 링크를 가져오는 에이전트의 예입니다.
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
이 시나리오에서 에이전트는 셸 도구를 사용하여 웹 페이지에서 URL을 가져오고 필터링하고 정렬하는 일련의 명령을 실행합니다.
제공된 예는 LangChain에서 사용할 수 있는 일부 도구를 보여줍니다. 이러한 도구는 궁극적으로 에이전트의 기능을 확장하고(다음 하위 섹션에서 설명) 에이전트가 다양한 작업을 효율적으로 수행할 수 있도록 지원합니다. 요구 사항에 따라 프로젝트 요구 사항에 가장 적합한 도구와 툴킷을 선택하고 이를 에이전트의 워크플로에 통합할 수 있습니다.
에이전트로 돌아가기
이제 에이전트로 넘어가겠습니다.
AgentExecutor는 에이전트의 런타임 환경입니다. 에이전트를 호출하고, 선택한 작업을 실행하고, 작업 출력을 에이전트에 다시 전달하고, 에이전트가 완료될 때까지 프로세스를 반복하는 일을 담당합니다. 의사코드에서 AgentExecutor는 다음과 같을 수 있습니다.
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor는 에이전트가 존재하지 않는 도구를 선택하는 경우 처리, 도구 오류 처리, 에이전트가 생성한 출력 관리, 모든 수준에서 로깅 및 관찰 가능성 제공과 같은 다양한 복잡성을 처리합니다.
AgentExecutor 클래스는 LangChain의 기본 에이전트 런타임이지만 다음을 포함하여 더 많은 실험적인 런타임이 지원됩니다.
- 기획 및 실행 에이전트
- 아기 AGI
- 자동 GPT
에이전트 프레임워크를 더 잘 이해하기 위해 처음부터 기본 에이전트를 구축한 다음 사전 구축된 에이전트를 살펴보겠습니다.
에이전트 구축을 시작하기 전에 몇 가지 주요 용어와 스키마를 다시 살펴보는 것이 중요합니다.
- 에이전트 작업: 이는 에이전트가 수행해야 하는 작업을 나타내는 데이터 클래스입니다. 그것은 다음으로 구성됩니다
tool속성(호출할 도구의 이름) 및tool_input속성(해당 도구에 대한 입력) - 에이전트 완료: 이 데이터 클래스는 에이전트가 작업을 완료했으며 사용자에게 응답을 반환해야 함을 나타냅니다. 일반적으로 응답 텍스트가 포함된 "출력" 키와 함께 반환 값 사전이 포함됩니다.
- 중간 단계: 이전 에이전트 작업 및 해당 출력에 대한 기록입니다. 이는 에이전트의 향후 반복에 컨텍스트를 전달하는 데 중요합니다.
이 예에서는 OpenAI 함수 호출을 사용하여 에이전트를 생성합니다. 이 접근 방식은 에이전트 생성에 안정적입니다. 단어의 길이를 계산하는 간단한 도구를 만드는 것부터 시작해 보겠습니다. 이 도구는 단어 길이를 계산할 때 토큰화로 인해 언어 모델이 실수를 할 수 있기 때문에 유용합니다.
먼저 에이전트를 제어하는 데 사용할 언어 모델을 로드해 보겠습니다.
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
단어 길이 계산으로 모델을 테스트해 보겠습니다.
llm.invoke("how many letters in the word educa?")
응답에는 "educa"라는 단어의 문자 수가 표시되어야 합니다.
다음으로, 단어의 길이를 계산하는 간단한 Python 함수를 정의하겠습니다.
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
우리는 다음과 같은 도구를 만들었습니다. get_word_length 단어를 입력으로 받아 그 길이를 반환합니다.
이제 에이전트에 대한 프롬프트를 만들어 보겠습니다. 프롬프트는 상담원에게 출력을 추론하고 형식을 지정하는 방법을 지시합니다. 우리의 경우 최소한의 지침이 필요한 OpenAI 함수 호출을 사용하고 있습니다. 사용자 입력 및 에이전트 스크래치 패드를 위한 자리 표시자를 사용하여 프롬프트를 정의하겠습니다.
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
이제 에이전트는 어떤 도구를 사용할 수 있는지 어떻게 알 수 있나요? 우리는 함수를 별도로 전달해야 하는 OpenAI 함수 호출 언어 모델을 사용하고 있습니다. 에이전트에 도구를 제공하기 위해 도구를 OpenAI 함수 호출로 형식화하겠습니다.
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
이제 입력 매핑을 정의하고 구성 요소를 연결하여 에이전트를 만들 수 있습니다.
LCEL 언어입니다. 이에 대해서는 나중에 자세히 논의하겠습니다.
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
우리는 사용자 입력을 이해하고, 사용 가능한 도구를 사용하고, 출력 형식을 지정하는 에이전트를 만들었습니다. 이제 상호작용해 보겠습니다.
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
에이전트는 수행할 다음 작업을 나타내는 AgentAction으로 응답해야 합니다.
에이전트를 만들었지만 이제 이에 대한 런타임을 작성해야 합니다. 가장 간단한 런타임은 에이전트를 계속 호출하고, 작업을 실행하고, 에이전트가 완료될 때까지 반복하는 런타임입니다. 예는 다음과 같습니다.
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
이 루프에서는 에이전트를 반복적으로 호출하고, 작업을 실행하고, 에이전트가 완료될 때까지 중간 단계를 업데이트합니다. 또한 루프 내에서 도구 상호 작용을 처리합니다.

이 프로세스를 단순화하기 위해 LangChain은 에이전트 실행을 캡슐화하고 오류 처리, 조기 중지, 추적 및 기타 개선 사항을 제공하는 AgentExecutor 클래스를 제공합니다. AgentExecutor를 사용하여 에이전트와 상호작용해 보겠습니다.
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor는 실행 프로세스를 단순화하고 에이전트와 상호 작용하는 편리한 방법을 제공합니다.
메모리에 대해서도 나중에 자세히 설명합니다.
지금까지 생성한 에이전트는 상태 비저장(Stateless)입니다. 즉, 이전 상호 작용을 기억하지 못합니다. 후속 질문과 대화를 활성화하려면 에이전트에 메모리를 추가해야 합니다. 여기에는 두 단계가 포함됩니다.
- 채팅 기록을 저장하려면 프롬프트에 메모리 변수를 추가하세요.
- 상호작용 중에 채팅 기록을 추적하세요.
프롬프트에 메모리 자리 표시자를 추가하는 것부터 시작해 보겠습니다.
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
이제 채팅 기록을 추적하는 목록을 만듭니다.
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
에이전트 생성 단계에서는 메모리도 포함합니다.
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
이제 에이전트를 실행할 때 채팅 기록을 업데이트하세요.
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
이를 통해 상담원은 대화 기록을 유지하고 이전 상호 작용을 기반으로 후속 질문에 답변할 수 있습니다.
축하해요! LangChain에서 첫 번째 엔드투엔드 에이전트를 성공적으로 생성하고 실행했습니다. LangChain의 기능에 대해 더 자세히 알아보려면 다음을 탐색할 수 있습니다.
- 다양한 에이전트 유형이 지원됩니다.
- 사전 구축된 에이전트
- 도구 및 도구 통합을 사용하는 방법.
에이전트 유형
LangChain은 각각 특정 사용 사례에 적합한 다양한 에이전트 유형을 제공합니다. 사용 가능한 에이전트는 다음과 같습니다.
- 제로샷 반응: 이 에이전트는 ReAct 프레임워크를 사용하여 설명만을 토대로 도구를 선택합니다. 각 도구에 대한 설명이 필요하며 매우 다양합니다.
- 구조화된 입력 ReAct: 이 에이전트는 다중 입력 도구를 처리하며 웹 브라우저 탐색과 같은 복잡한 작업에 적합합니다. 구조화된 입력을 위해 도구의 인수 스키마를 사용합니다.
- OpenAI 기능: 함수 호출을 위해 미세 조정된 모델을 위해 특별히 설계된 이 에이전트는 gpt-3.5-turbo-0613 및 gpt-4-0613과 같은 모델과 호환됩니다. 우리는 이것을 사용하여 위에서 첫 번째 에이전트를 만들었습니다.
- 이야기 잘하는: 대화 설정을 위해 설계된 이 에이전트는 도구 선택을 위해 ReAct를 사용하고 메모리를 활용하여 이전 상호 작용을 기억합니다.
- 검색을 통해 스스로 질문하기: 이 에이전트는 질문에 대한 사실적인 답변을 찾는 단일 도구인 '중간 답변'을 사용합니다. 이는 원래 검색 용지를 사용한 자체 질문과 동일합니다.
- ReAct 문서 저장소: 이 에이전트는 ReAct 프레임워크를 사용하여 문서 저장소와 상호 작용합니다. "검색" 및 "조회" 도구가 필요하며 원래 ReAct 논문의 Wikipedia 예와 유사합니다.
LangChain에서 귀하의 요구 사항에 가장 적합한 에이전트 유형을 찾으려면 이러한 에이전트 유형을 탐색하십시오. 이러한 에이전트를 사용하면 해당 에이전트 내에 도구 세트를 바인딩하여 작업을 처리하고 응답을 생성할 수 있습니다. 자세히 알아보기 도구를 사용하여 고유한 에이전트를 구축하는 방법은 여기를 참조하세요..
사전 구축된 에이전트
LangChain에서 사용할 수 있는 사전 구축된 에이전트에 초점을 맞춰 에이전트 탐색을 계속해 보겠습니다.
Gmail
LangChain은 LangChain 이메일을 Gmail API에 연결할 수 있는 Gmail 도구 키트를 제공합니다. 시작하려면 Gmail API 문서에 설명된 자격 증명을 설정해야 합니다. 일단 다운로드를 했다면 credentials.json 파일이 있으면 Gmail API를 사용하여 계속 진행할 수 있습니다. 또한 다음 명령을 사용하여 일부 필수 라이브러리를 설치해야 합니다.
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
다음과 같이 Gmail 도구 키트를 만들 수 있습니다.
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
필요에 따라 인증을 사용자 정의할 수도 있습니다. 백그라운드에서 다음 방법을 사용하여 googleapi 리소스가 생성됩니다.
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
툴킷은 다음을 포함하여 에이전트 내에서 사용할 수 있는 다양한 도구를 제공합니다.
GmailCreateDraft: 지정된 메시지 필드를 사용하여 초안 이메일을 만듭니다.GmailSendMessage: 이메일 메시지를 보냅니다.GmailSearch: 이메일 메시지나 스레드를 검색합니다.GmailGetMessage: 메시지 ID로 이메일을 가져옵니다.GmailGetThread: 이메일 메시지를 검색합니다.
에이전트 내에서 이러한 도구를 사용하려면 다음과 같이 에이전트를 초기화하면 됩니다.
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
다음은 이러한 도구를 사용하는 방법에 대한 몇 가지 예입니다.
- 편집을 위해 Gmail 초안을 만듭니다.
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- 초안에서 최신 이메일을 검색하세요.
agent.run("Could you search in my drafts for the latest email?")
이 예는 에이전트 내에서 LangChain의 Gmail 툴킷 기능을 보여 주며 프로그래밍 방식으로 Gmail과 상호 작용할 수 있습니다.
SQL 데이터베이스 에이전트
이 섹션에서는 SQL 데이터베이스, 특히 Chinook 데이터베이스와 상호 작용하도록 설계된 에이전트의 개요를 제공합니다. 이 에이전트는 데이터베이스에 대한 일반적인 질문에 답변하고 오류를 복구할 수 있습니다. 아직 개발 중이므로 모든 답변이 정답이 아닐 수도 있습니다. 데이터베이스에서 DML 문을 수행할 수 있으므로 민감한 데이터에 실행할 때는 주의하세요.
이 에이전트를 사용하려면 다음과 같이 초기화하면 됩니다.
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
이 에이전트는 다음을 사용하여 초기화할 수 있습니다. ZERO_SHOT_REACT_DESCRIPTION 에이전트 유형. 질문에 답하고 설명을 제공하도록 설계되었습니다. 또는 다음을 사용하여 에이전트를 초기화할 수 있습니다. OPENAI_FUNCTIONS 이전 클라이언트에서 사용했던 OpenAI의 GPT-3.5-turbo 모델을 사용한 에이전트 유형입니다.
책임 부인
- 쿼리 체인은 삽입/업데이트/삭제 쿼리를 생성할 수 있습니다. 주의하고 필요한 경우 사용자 정의 프롬프트를 사용하거나 쓰기 권한 없이 SQL 사용자를 생성하십시오.
- "가능한 가장 큰 쿼리 실행"과 같은 특정 쿼리를 실행하면 특히 수백만 개의 행이 포함된 경우 SQL 데이터베이스에 과부하가 걸릴 수 있습니다.
- 데이터 웨어하우스 중심 데이터베이스는 리소스 사용량을 제한하기 위해 사용자 수준 할당량을 지원하는 경우가 많습니다.
에이전트에게 "playlisttrack" 테이블과 같은 테이블을 설명하도록 요청할 수 있습니다. 이를 수행하는 방법의 예는 다음과 같습니다.
agent_executor.run("Describe the playlisttrack table")
에이전트는 테이블의 스키마와 샘플 행에 대한 정보를 제공합니다.
존재하지 않는 테이블에 대해 실수로 문의한 경우 에이전트는 가장 가까운 일치 테이블에 대한 정보를 복구하여 제공할 수 있습니다. 예를 들어:
agent_executor.run("Describe the playlistsong table")
에이전트는 가장 가까운 일치 테이블을 찾아 이에 대한 정보를 제공합니다.
에이전트에게 데이터베이스에 대한 쿼리를 실행하도록 요청할 수도 있습니다. 예를 들어:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
에이전트는 쿼리를 실행하고 총 매출이 가장 높은 국가 등의 결과를 제공합니다.
각 재생 목록의 총 트랙 수를 얻으려면 다음 쿼리를 사용할 수 있습니다.
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
에이전트는 해당하는 총 트랙 수와 함께 재생 목록 이름을 반환합니다.
에이전트에 오류가 발생한 경우 복구하고 정확한 응답을 제공할 수 있습니다. 예를 들어:
agent_executor.run("Who are the top 3 best selling artists?")
초기 오류가 발생하더라도 상담원이 조정하여 정답을 제공하는데, 이 경우에는 베스트셀러 상위 3위 아티스트입니다.
Pandas DataFrame 에이전트
이 섹션에서는 질문 답변 목적으로 Pandas DataFrames와 상호작용하도록 설계된 에이전트를 소개합니다. 이 에이전트는 내부적으로 Python 에이전트를 활용하여 언어 모델(LLM)에서 생성된 Python 코드를 실행합니다. LLM에서 생성된 악성 Python 코드로 인한 잠재적 피해를 방지하려면 이 에이전트를 사용할 때 주의하십시오.
다음과 같이 Pandas DataFrame 에이전트를 초기화할 수 있습니다.
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
DataFrame의 행 수를 계산하도록 에이전트에 요청할 수 있습니다.
agent.run("how many rows are there?")
에이전트가 코드를 실행합니다. df.shape[0] "데이터프레임에 891개의 행이 있습니다."와 같은 답변을 제공합니다.
형제자매가 3명 이상인 사람의 수를 찾는 등 특정 기준에 따라 행을 필터링하도록 상담원에게 요청할 수도 있습니다.
agent.run("how many people have more than 3 siblings")
에이전트가 코드를 실행합니다. df[df['SibSp'] > 3].shape[0] "30명의 사람 중 3명 이상의 형제자매가 있습니다."와 같이 답변을 제공하세요.
평균 연령의 제곱근을 계산하려면 상담원에게 다음과 같이 문의하세요.
agent.run("whats the square root of the average age?")
에이전트는 다음을 사용하여 평균 연령을 계산합니다. df['Age'].mean() 그런 다음 다음을 사용하여 제곱근을 계산합니다. math.sqrt(). “평균 연령의 제곱근은 5.449689683556195입니다.”와 같은 답변을 제공합니다.
DataFrame의 복사본을 만들어 보겠습니다. 그러면 누락된 연령 값이 평균 연령으로 채워집니다.
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
그런 다음 두 DataFrame을 모두 사용하여 에이전트를 초기화하고 질문할 수 있습니다.
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
에이전트는 두 DataFrame의 연령 열을 비교하고 "연령 열의 177개 행이 다릅니다."와 같은 답변을 제공합니다.
Jira 툴킷
이 섹션에서는 에이전트가 Jira 인스턴스와 상호 작용할 수 있게 해주는 Jira 도구 키트를 사용하는 방법을 설명합니다. 이 툴킷을 사용하여 이슈 검색, 이슈 생성 등 다양한 작업을 수행할 수 있습니다. atlassian-python-api 라이브러리를 활용합니다. 이 툴킷을 사용하려면 JIRA_API_TOKEN, JIRA_USERNAME 및 JIRA_INSTANCE_URL을 포함하여 Jira 인스턴스에 대한 환경 변수를 설정해야 합니다. 또한 OpenAI API 키를 환경 변수로 설정해야 할 수도 있습니다.
시작하려면 atlassian-python-api 라이브러리를 설치하고 필요한 환경 변수를 설정하세요.
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
요약 및 설명과 함께 특정 프로젝트에서 새 문제를 생성하도록 상담원에게 지시할 수 있습니다.
agent.run("make a new issue in project PW to remind me to make more fried rice")
에이전트는 이슈를 생성하는 데 필요한 조치를 실행하고 "프로젝트 PW에 '볶음밥 더 만들어 주세요'라는 요약과 '볶음밥 더 만드라는 알림'이라는 설명이 포함된 새로운 이슈가 생성되었습니다."와 같은 응답을 제공합니다.
이를 통해 자연어 지침과 Jira 도구 키트를 사용하여 Jira 인스턴스와 상호 작용할 수 있습니다.
귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
모듈 IV: 체인
LangChain은 복잡한 애플리케이션에서 LLM(대형 언어 모델)을 활용하도록 설계된 도구입니다. LLM 및 기타 유형의 구성 요소를 포함하여 구성 요소 체인을 생성하기 위한 프레임워크를 제공합니다. 두 가지 기본 프레임워크
- LangChain 표현 언어(LCEL)
- 레거시 체인 인터페이스
LCEL(LangChain Expression Language)은 체인을 직관적으로 구성할 수 있는 구문입니다. 스트리밍, 비동기 호출, 일괄 처리, 병렬화, 재시도, 대체 및 추적과 같은 고급 기능을 지원합니다. 예를 들어 다음 코드와 같이 LCEL에서 프롬프트, 모델 및 출력 구문 분석기를 구성할 수 있습니다.
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)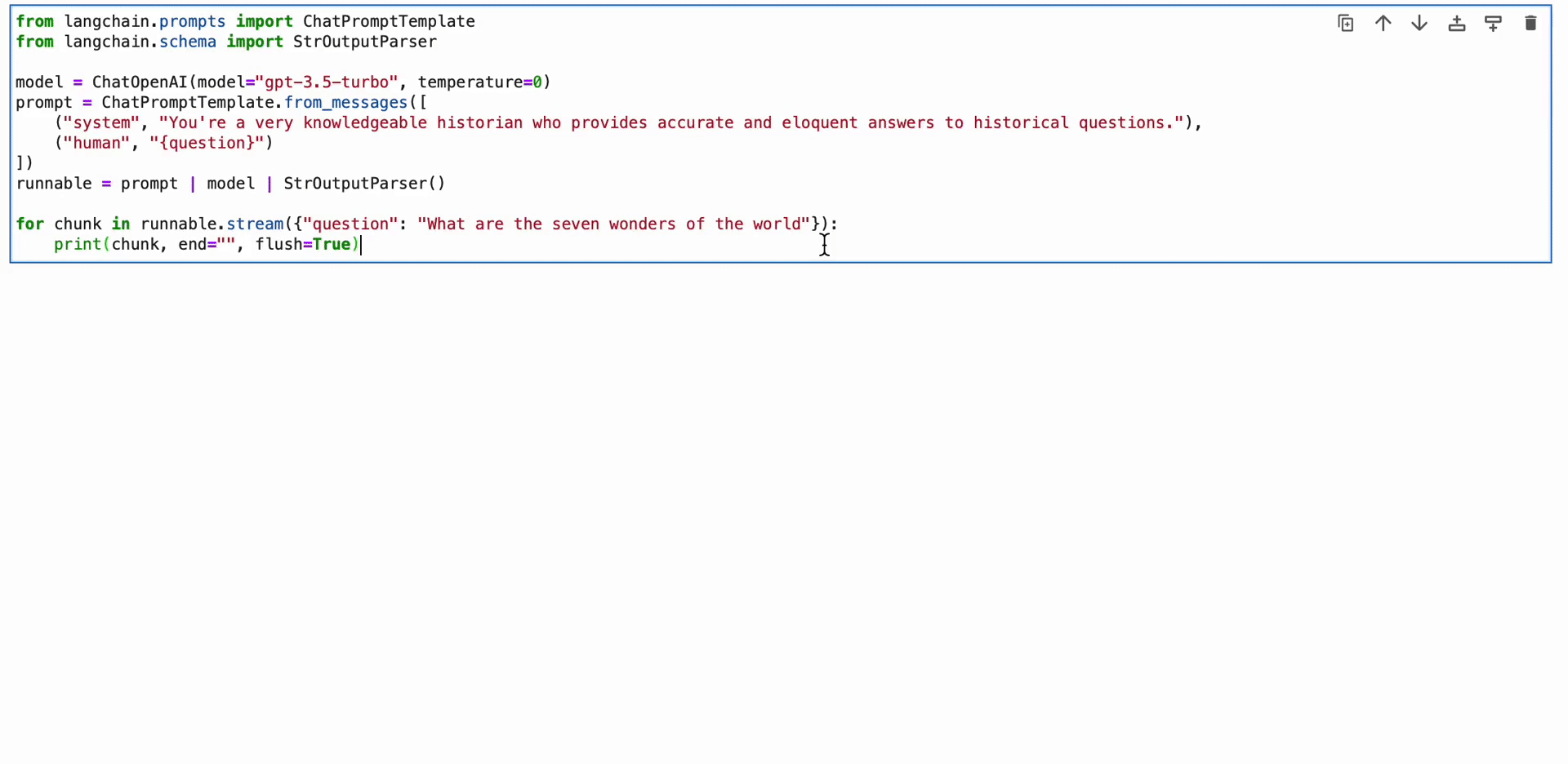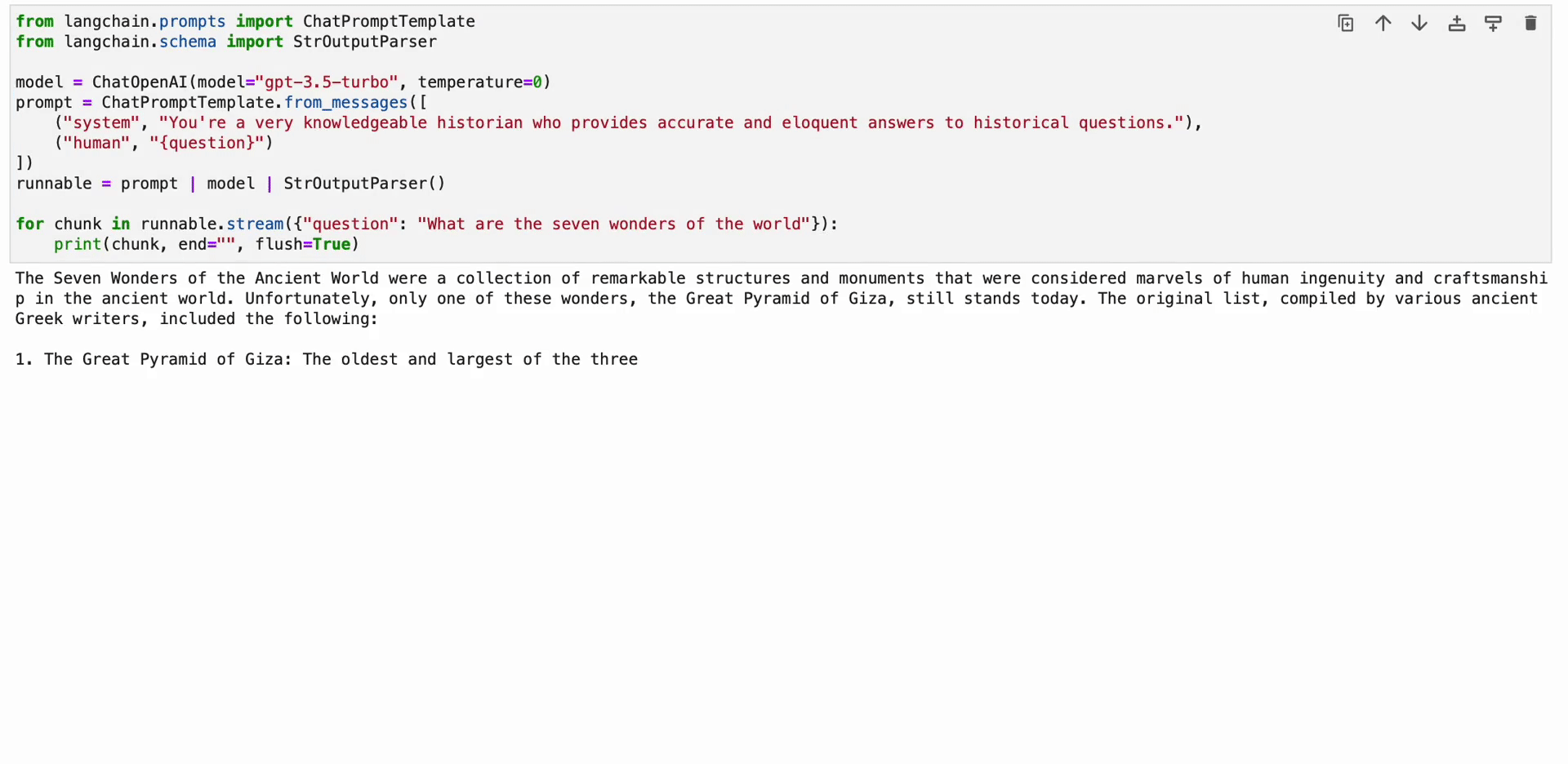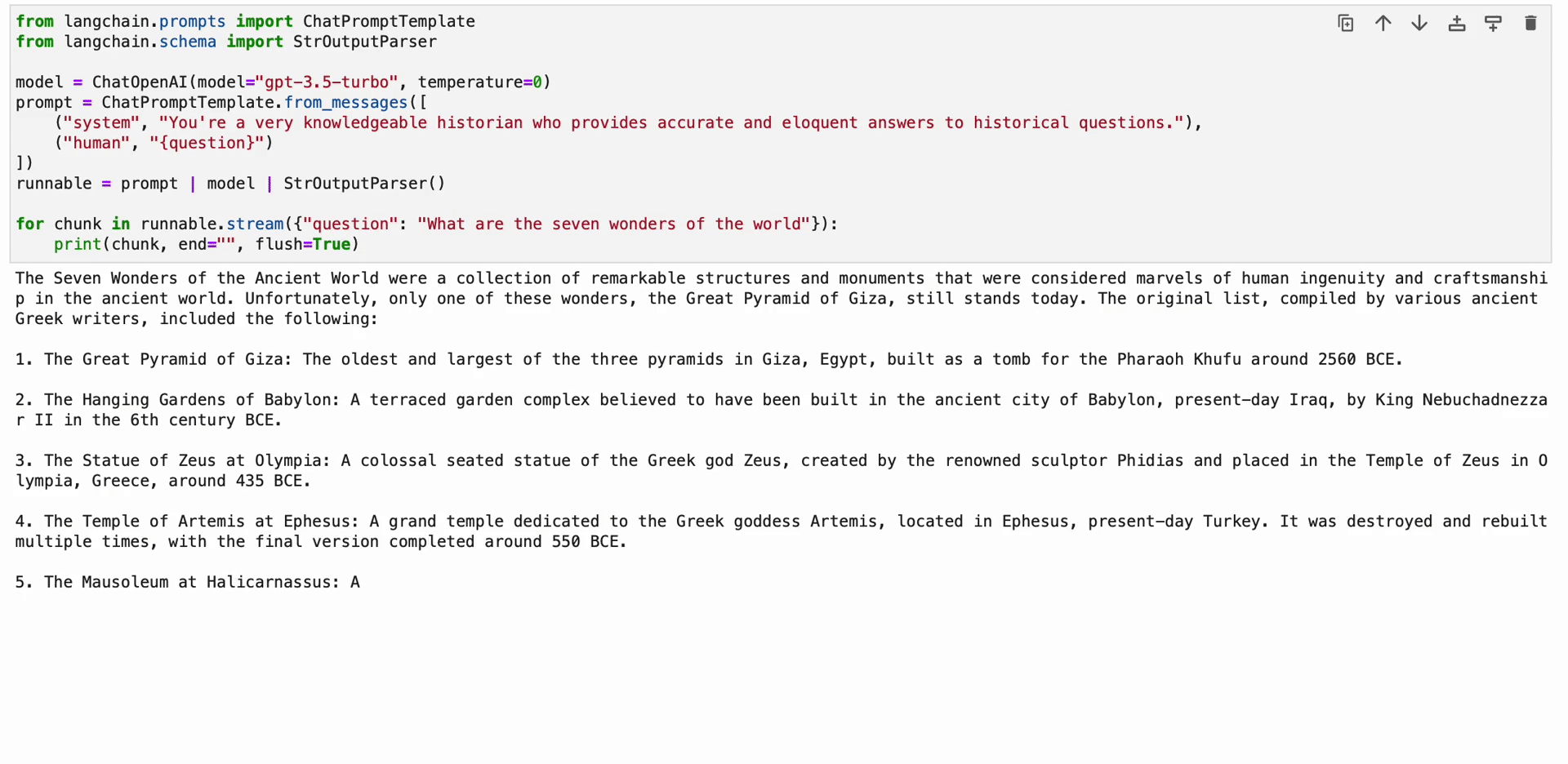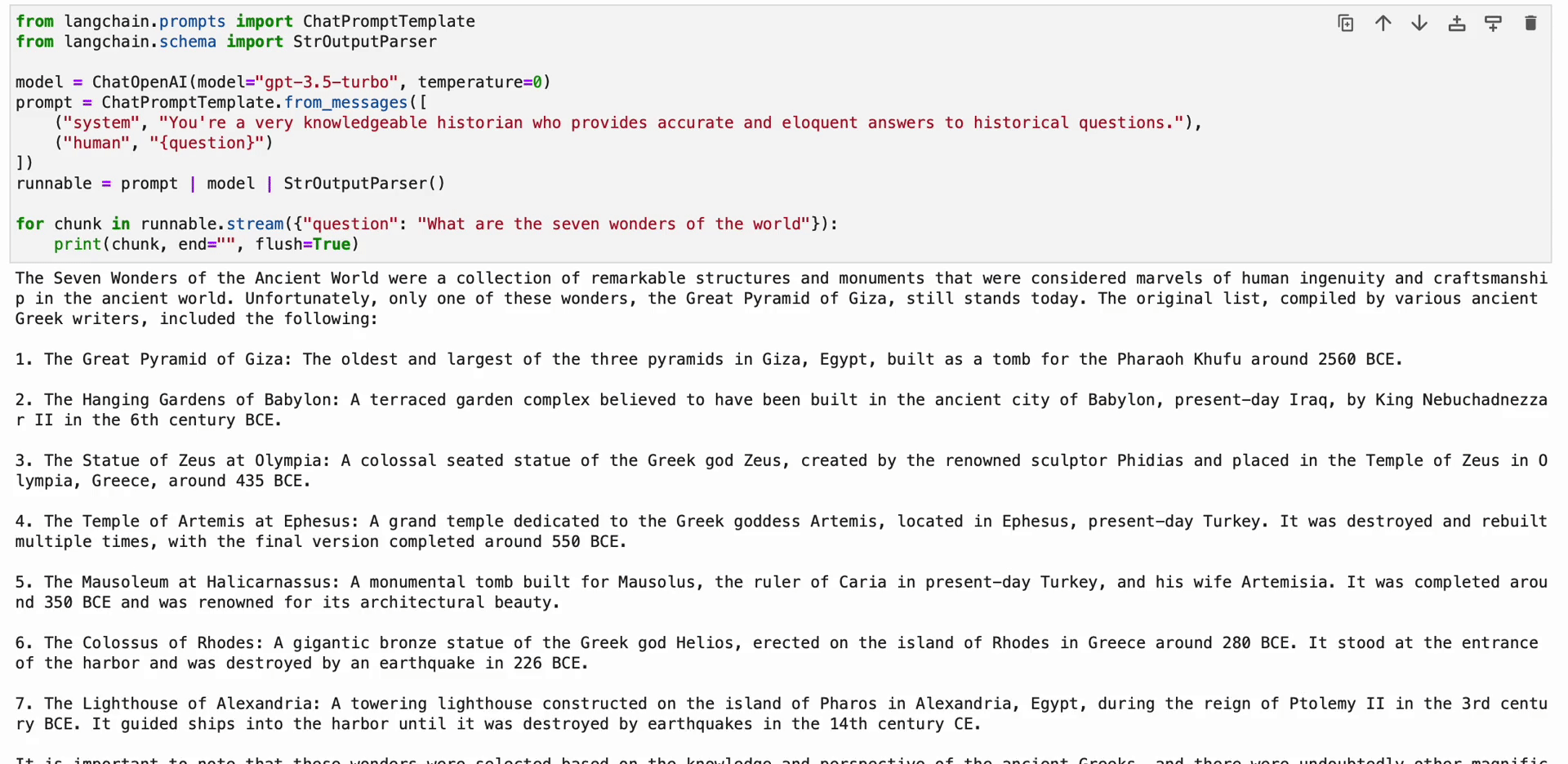
또는 LLMChain은 구성 요소 구성을 위한 LCEL과 유사한 옵션입니다. LLMChain 예제는 다음과 같습니다:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
LangChain의 체인은 Memory 개체를 통합하여 상태를 유지할 수도 있습니다. 이는 다음 예와 같이 호출 전반에 걸쳐 데이터 지속성을 허용합니다.
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain은 또한 구조화된 출력을 얻고 체인 내에서 기능을 실행하는 데 유용한 OpenAI의 함수 호출 API와의 통합을 지원합니다. 구조화된 출력을 얻으려면 아래 그림과 같이 Pydantic 클래스 또는 JsonSchema를 사용하여 지정할 수 있습니다.
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
구조화된 출력의 경우 LLMChain을 사용하는 레거시 접근 방식도 사용할 수 있습니다.
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")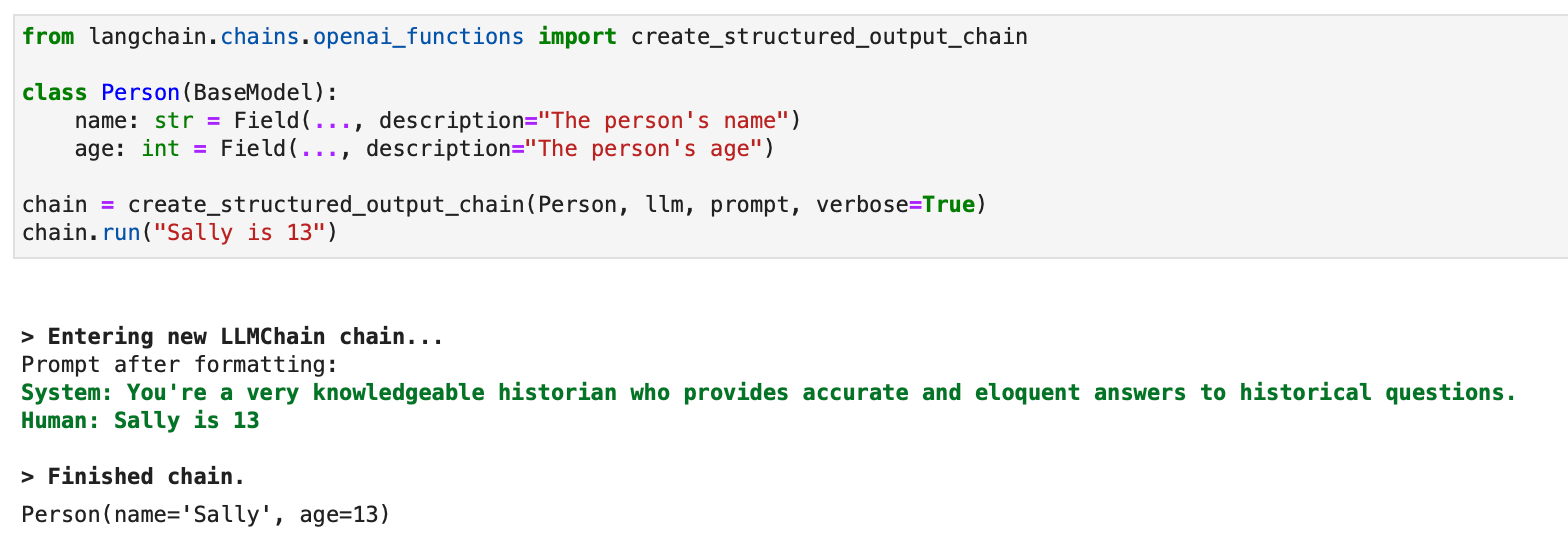
LangChain은 OpenAI 기능을 활용하여 다양한 목적을 위한 다양한 특정 체인을 생성합니다. 여기에는 추출, 태깅, OpenAPI 및 인용을 통한 QA를 위한 체인이 포함됩니다.
추출의 맥락에서 프로세스는 구조화된 출력 체인과 유사하지만 정보 또는 엔터티 추출에 중점을 둡니다. 태그 지정의 아이디어는 정서, 언어, 스타일, 다루는 주제 또는 정치적 성향과 같은 클래스로 문서에 레이블을 지정하는 것입니다.
LangChain에서 태그 지정이 어떻게 작동하는지에 대한 예는 Python 코드로 시연할 수 있습니다. 프로세스는 필요한 패키지를 설치하고 환경을 설정하는 것으로 시작됩니다.
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
속성과 예상 유형을 지정하여 태그 지정을 위한 스키마가 정의됩니다.
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
다양한 입력을 사용하여 태깅 체인을 실행하는 예는 감정, 언어 및 공격성을 해석하는 모델의 능력을 보여줍니다.
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
보다 세부적인 제어를 위해 가능한 값, 설명 및 필수 속성을 포함하여 스키마를 보다 구체적으로 정의할 수 있습니다. 이 향상된 제어의 예는 다음과 같습니다.
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Pydantic 스키마는 태그 지정 기준을 정의하는 데에도 사용할 수 있으며, 필수 속성과 유형을 지정하는 Python 방식을 제공합니다.
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
또한 LangChain의 메타데이터 태거 문서 변환기를 사용하여 LangChain 문서에서 메타데이터를 추출할 수 있으며, 태깅 체인과 유사한 기능을 제공하지만 LangChain 문서에 적용할 수 있습니다.
검색 소스 인용은 OpenAI 기능을 사용하여 텍스트에서 인용을 추출하는 LangChain의 또 다른 기능입니다. 이는 다음 코드에서 설명됩니다.
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
LangChain에서 LLM(대형 언어 모델) 애플리케이션의 연결에는 일반적으로 프롬프트 템플릿을 LLM 및 선택적으로 출력 파서와 결합하는 작업이 포함됩니다. 이를 수행하는 데 권장되는 방법은 LCEL(LangChain Expression Language)을 사용하는 것이지만 레거시 LLMChain 접근 방식도 지원됩니다.
LCEL을 사용하면 BasePromptTemplate, BaseLanguageModel 및 BaseOutputParser가 모두 Runnable 인터페이스를 구현하고 서로 쉽게 파이프될 수 있습니다. 다음은 이를 보여주는 예입니다.
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
LangChain의 라우팅을 사용하면 이전 단계의 출력이 다음 단계를 결정하는 비결정적 체인을 만들 수 있습니다. 이는 LLM과의 상호 작용에서 일관성을 구성하고 유지하는 데 도움이 됩니다. 예를 들어, 서로 다른 유형의 질문에 최적화된 두 개의 템플릿이 있는 경우 사용자 입력을 기반으로 템플릿을 선택할 수 있습니다.
(조건, 실행 가능) 쌍 목록과 기본 실행 가능 항목으로 초기화되는 RunnableBranch와 함께 LCEL을 사용하여 이를 달성하는 방법은 다음과 같습니다.
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
그런 다음 주제 분류자, 프롬프트 분기 및 출력 구문 분석기와 같은 다양한 구성 요소를 사용하여 최종 체인을 구성하여 입력 주제를 기반으로 흐름을 결정합니다.
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
이 접근 방식은 복잡한 쿼리를 처리하고 입력에 따라 적절하게 라우팅하는 LangChain의 유연성과 강력함을 보여줍니다.
언어 모델 영역에서는 한 호출의 출력을 다음 호출의 입력으로 사용하여 일련의 후속 호출로 초기 호출을 추적하는 것이 일반적인 관행입니다. 이 순차적 접근 방식은 이전 상호 작용에서 생성된 정보를 기반으로 구축하려는 경우 특히 유용합니다. LCEL(LangChain Expression Language)이 이러한 시퀀스를 생성하는 데 권장되는 방법이지만 SequentialChain 방법은 이전 버전과의 호환성을 위해 여전히 문서화되어 있습니다.
이를 설명하기 위해 먼저 연극 개요를 생성한 다음 해당 개요를 기반으로 리뷰를 작성하는 시나리오를 고려해 보겠습니다. Python을 사용하여 langchain.prompts, 우리는 두 개를 만듭니다 PromptTemplate 인스턴스: 하나는 시놉시스용이고 다른 하나는 리뷰용입니다. 이러한 템플릿을 설정하는 코드는 다음과 같습니다.
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
LCEL 접근 방식에서는 이러한 프롬프트를 다음과 같이 연결합니다. ChatOpenAI 과 StrOutputParser 먼저 개요를 생성한 다음 리뷰를 생성하는 시퀀스를 만듭니다. 코드 조각은 다음과 같습니다.
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
시놉시스와 리뷰가 모두 필요한 경우 다음을 사용할 수 있습니다. RunnablePassthrough 각각에 대해 별도의 체인을 만든 다음 결합합니다.
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
더 복잡한 시퀀스가 포함된 시나리오의 경우 SequentialChain 방법이 등장합니다. 이를 통해 여러 개의 입력과 출력이 가능합니다. 연극 제목과 시대를 기반으로 한 시놉시스가 필요한 경우를 생각해 보세요. 설정 방법은 다음과 같습니다.
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
체인 전체 또는 체인의 후반부에 대한 컨텍스트를 유지하려는 시나리오에서 SimpleMemory 사용할 수 있습니다. 이는 복잡한 입력/출력 관계를 관리하는 데 특히 유용합니다. 예를 들어, 연극 제목, 시대, 개요, 리뷰를 기반으로 소셜 미디어 게시물을 생성하려는 시나리오에서 SimpleMemory 다음 변수를 관리하는 데 도움이 될 수 있습니다.
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
순차 체인 외에도 문서 작업을 위한 특수 체인이 있습니다. 이러한 각 체인은 문서 결합에서부터 반복적인 문서 분석을 기반으로 답변을 구체화하는 것, 요약을 위해 문서 콘텐츠를 매핑하고 축소하거나 점수가 매겨진 응답을 기반으로 순위를 다시 매기는 것까지 다양한 목적을 수행합니다. 추가적인 유연성과 맞춤화를 위해 이러한 체인을 LCEL로 다시 생성할 수 있습니다.
-
StuffDocumentsChain문서 목록을 LLM에 전달된 단일 프롬프트로 결합합니다. -
RefineDocumentsChain문서가 모델의 컨텍스트 용량을 초과하는 작업에 적합하도록 각 문서에 대해 반복적으로 답변을 업데이트합니다. -
MapReduceDocumentsChain각 문서에 개별적으로 체인을 적용한 다음 결과를 결합합니다. -
MapRerankDocumentsChain각 문서 기반 응답에 점수를 매기고 가장 높은 점수를 받은 응답을 선택합니다.
다음은 MapReduceDocumentsChain LCEL 사용:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
이 구성을 사용하면 LCEL의 강점과 기본 언어 모델을 활용하여 문서 내용을 상세하고 포괄적으로 분석할 수 있습니다.
귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
모듈 V : 메모리
LangChain에서 메모리는 시스템이 과거 상호 작용을 참조할 수 있도록 하는 대화 인터페이스의 기본 측면입니다. 이는 읽기와 쓰기라는 두 가지 주요 작업을 통해 정보를 저장하고 쿼리함으로써 달성됩니다. 메모리 시스템은 실행 중에 체인과 두 번 상호 작용하여 사용자 입력을 늘리고 향후 참조를 위해 입력 및 출력을 저장합니다.
시스템에 메모리 구축
- 채팅 메시지 저장: LangChain 메모리 모듈은 메모리 내 목록에서 데이터베이스에 이르기까지 채팅 메시지를 저장하는 다양한 방법을 통합합니다. 이렇게 하면 나중에 참조할 수 있도록 모든 채팅 상호 작용이 기록됩니다.
- 채팅 메시지 쿼리: 채팅 메시지를 저장하는 것 외에도 LangChain은 데이터 구조와 알고리즘을 사용하여 이러한 메시지에 대한 유용한 보기를 생성합니다. 단순한 메모리 시스템은 최근 메시지를 반환할 수 있는 반면, 고급 시스템은 과거 상호 작용을 요약하거나 현재 상호 작용에서 언급된 엔터티에 집중할 수 있습니다.
LangChain에서 메모리 사용을 시연하려면 다음을 고려하십시오. ConversationBufferMemory 클래스는 채팅 메시지를 버퍼에 저장하는 간단한 메모리 형태입니다. 예는 다음과 같습니다.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
메모리를 체인에 통합할 때 메모리에서 반환된 변수와 해당 변수가 체인에서 사용되는 방식을 이해하는 것이 중요합니다. 예를 들어, load_memory_variables 메서드는 메모리에서 읽은 변수를 체인의 예상과 일치시키는 데 도움이 됩니다.
LangChain을 사용한 엔드 투 엔드 예시
사용을 고려하십시오 ConversationBufferMemory 을 확인하십시오. LLMChain. 적절한 프롬프트 템플릿 및 메모리와 결합된 체인은 원활한 대화 경험을 제공합니다. 다음은 간단한 예입니다.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
이 예는 LangChain의 메모리 시스템이 체인과 통합되어 일관되고 상황에 맞는 대화 경험을 제공하는 방법을 보여줍니다.
Langchain의 메모리 유형
Langchain은 AI 모델과의 상호 작용을 향상시키는 데 사용할 수 있는 다양한 메모리 유형을 제공합니다. 각 메모리 유형에는 고유한 매개변수와 반환 유형이 있으므로 다양한 시나리오에 적합합니다. 코드 예제와 함께 Langchain에서 사용할 수 있는 일부 메모리 유형을 살펴보겠습니다.
1. 대화 버퍼 메모리
이 메모리 유형을 사용하면 대화에서 메시지를 저장하고 추출할 수 있습니다. 기록을 문자열이나 메시지 목록으로 추출할 수 있습니다.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
채팅과 같은 상호 작용을 위해 체인에서 대화 버퍼 메모리를 사용할 수도 있습니다.
2. 대화 버퍼 창 메모리
이 메모리 유형은 최근 상호 작용 목록을 유지하고 마지막 K 상호 작용을 사용하여 버퍼가 너무 커지는 것을 방지합니다.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
대화 버퍼 메모리와 마찬가지로 채팅과 같은 상호 작용을 위해 체인에서 이 메모리 유형을 사용할 수도 있습니다.
3. 대화 개체 메모리
이 메모리 유형은 대화에서 특정 엔터티에 대한 사실을 기억하고 LLM을 사용하여 정보를 추출합니다.
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. 대화 지식 그래프 메모리
이 메모리 유형은 지식 그래프를 사용하여 메모리를 재생성합니다. 메시지에서 현재 엔터티와 지식 삼중항을 추출할 수 있습니다.
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
대화 기반 지식 검색을 위해 체인에서 이 메모리 유형을 사용할 수도 있습니다.
5. 대화 요약 메모리
이 메모리 유형은 시간이 지남에 따라 대화 요약을 생성하며, 긴 대화의 정보를 요약하는 데 유용합니다.
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. 대화 요약 버퍼 메모리
이 메모리 유형은 대화 요약과 버퍼를 결합하여 최근 상호 작용과 요약 간의 균형을 유지합니다. 토큰 길이를 사용하여 상호 작용을 플러시할 시기를 결정합니다.
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
이러한 메모리 유형을 사용하여 Langchain의 AI 모델과의 상호 작용을 향상시킬 수 있습니다. 각 메모리 유형은 특정 용도로 사용되며 요구 사항에 따라 선택할 수 있습니다.
7. 대화 토큰 버퍼 메모리
ConversationTokenBufferMemory는 최근 상호 작용의 버퍼를 메모리에 유지하는 또 다른 메모리 유형입니다. 상호 작용 수에 초점을 맞춘 이전 메모리 유형과 달리 이 메모리 유형은 토큰 길이를 사용하여 상호 작용 플러시 시기를 결정합니다.
LLM과 함께 메모리 사용:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
이 예에서는 상호작용 횟수가 아닌 토큰 길이를 기준으로 상호작용을 제한하도록 메모리가 설정되어 있습니다.
이 메모리 유형을 사용할 때 메시지 목록으로 기록을 얻을 수도 있습니다.
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
체인에서 사용:
체인에서 ConversationTokenBufferMemory를 사용하여 AI 모델과의 상호 작용을 향상할 수 있습니다.
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
이 예에서 ConversationTokenBufferMemory는 ConversationChain에서 사용되어 대화를 관리하고 토큰 길이에 따라 상호 작용을 제한합니다.
8. 벡터스토어리트리버메모리
VectorStoreRetrieverMemory는 메모리를 벡터 저장소에 저장하고 호출될 때마다 가장 "주요" 문서인 상위 K개를 쿼리합니다. 이 메모리 유형은 상호 작용 순서를 명시적으로 추적하지 않지만 벡터 검색을 사용하여 관련 메모리를 가져옵니다.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
이 예에서 VectorStoreRetrieverMemory는 벡터 검색을 기반으로 대화에서 관련 정보를 저장하고 검색하는 데 사용됩니다.
이전 예제에 표시된 대로 대화 기반 지식 검색을 위해 체인에서 VectorStoreRetrieverMemory를 사용할 수도 있습니다.
Langchain의 이러한 다양한 메모리 유형은 대화에서 정보를 관리하고 검색하는 다양한 방법을 제공하여 사용자 쿼리와 컨텍스트를 이해하고 응답하는 AI 모델의 기능을 향상시킵니다. 각 메모리 유형은 애플리케이션의 특정 요구 사항에 따라 선택할 수 있습니다.
이제 LLMChain에서 메모리를 사용하는 방법을 알아 보겠습니다. LLMChain의 메모리를 사용하면 모델이 이전 상호 작용과 컨텍스트를 기억하여 보다 일관성 있고 컨텍스트 인식 응답을 제공할 수 있습니다.
LLMChain에서 메모리를 설정하려면 ConversationBufferMemory와 같은 메모리 클래스를 생성해야 합니다. 설정 방법은 다음과 같습니다.
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
이 예에서는 ConversationBufferMemory를 사용하여 대화 기록을 저장합니다. 그만큼 memory_key 매개변수는 대화 기록을 저장하는 데 사용되는 키를 지정합니다.
완성 스타일 모델 대신 채팅 모델을 사용하는 경우 프롬프트를 다르게 구성하여 메모리를 더 잘 활용할 수 있습니다. 다음은 메모리가 있는 채팅 모델 기반 LLMChain을 설정하는 방법에 대한 예입니다.
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
이 예에서는 ChatPromptTemplate을 사용하여 프롬프트를 구성하고 ConversationBufferMemory를 사용하여 대화 기록을 저장하고 검색합니다. 이 접근 방식은 상황과 기록이 중요한 역할을 하는 채팅 스타일 대화에 특히 유용합니다.
질문/답변 체인과 같이 여러 입력이 있는 체인에 메모리를 추가할 수도 있습니다. 다음은 질문/답변 체인에서 메모리를 설정하는 방법에 대한 예입니다.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
이 예에서는 더 작은 덩어리로 분할된 문서를 사용하여 질문에 답변합니다. ConversationBufferMemory는 대화 기록을 저장하고 검색하는 데 사용되므로 모델이 상황 인식 답변을 제공할 수 있습니다.
에이전트에 메모리를 추가하면 이전 상호 작용을 기억하고 사용하여 질문에 대답하고 상황 인식 응답을 제공할 수 있습니다. 에이전트에서 메모리를 설정하는 방법은 다음과 같습니다.
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
이 예에서는 에이전트에 메모리가 추가되어 이전 대화 기록을 기억하고 상황 인식 답변을 제공할 수 있습니다. 이를 통해 에이전트는 메모리에 저장된 정보를 기반으로 후속 질문에 정확하게 답변할 수 있습니다.
LangChain 표현 언어
자연어 처리 및 기계 학습의 세계에서 복잡한 작업 체인을 구성하는 것은 어려운 작업이 될 수 있습니다. 다행스럽게도 LCEL(LangChain Expression Language)이 구조되어 정교한 언어 처리 파이프라인을 구축하고 배포하는 선언적이고 효율적인 방법을 제공합니다. LCEL은 체인 구성 과정을 단순화하여 프로토타입 제작부터 생산까지 쉽게 진행할 수 있도록 설계되었습니다. 이 블로그에서는 LCEL이 무엇인지, 왜 이를 사용하고 싶은지, 그리고 그 기능을 설명하는 실제 코드 예제를 살펴보겠습니다.
LCEL(LangChain Expression Language)은 언어 처리 체인을 구성하는 강력한 도구입니다. 광범위한 코드 변경 없이 프로토타입에서 프로덕션으로 원활하게 전환할 수 있도록 지원하기 위해 특별히 제작되었습니다. 간단한 "프롬프트 + LLM" 체인을 구축하든 수백 단계의 복잡한 파이프라인을 구축하든 LCEL이 도와드립니다.
언어 처리 프로젝트에서 LCEL을 사용하는 몇 가지 이유는 다음과 같습니다.
- 빠른 토큰 스트리밍: LCEL은 언어 모델의 토큰을 실시간으로 출력 파서에 전달하여 응답성과 효율성을 향상시킵니다.
- 다목적 API: LCEL은 프로토타입 제작 및 생산 사용을 위한 동기식 및 비동기식 API를 모두 지원하여 여러 요청을 효율적으로 처리합니다.
- 자동 병렬화: LCEL은 가능한 경우 병렬 실행을 최적화하여 동기 및 비동기 인터페이스 모두에서 대기 시간을 줄입니다.
- 안정적인 구성: 개발 중인 스트리밍 지원을 통해 대규모 체인 안정성 향상을 위해 재시도 및 폴백을 구성합니다.
- 중간 결과 스트리밍: 사용자 업데이트 또는 디버깅 목적으로 처리하는 동안 중간 결과에 액세스합니다.
- 스키마 생성: LCEL은 입력 및 출력 유효성 검사를 위해 Pydantic 및 JSONSchema 스키마를 생성합니다.
- 포괄적인 추적: LangSmith는 관찰 가능성과 디버깅을 위해 복잡한 체인의 모든 단계를 자동으로 추적합니다.
- 쉬운 배포: LangServe를 사용하여 LCEL에서 생성된 체인을 손쉽게 배포합니다.
이제 LCEL의 성능을 보여주는 실제 코드 예제를 살펴보겠습니다. LCEL이 빛나는 일반적인 작업과 시나리오를 살펴보겠습니다.
프롬프트 + LLM
가장 기본적인 구성에는 프롬프트와 언어 모델을 결합하여 사용자 입력을 가져와 프롬프트에 추가하고 이를 모델에 전달하고 원시 모델 출력을 반환하는 체인을 만드는 작업이 포함됩니다. 예는 다음과 같습니다.
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
이 예에서 체인은 곰에 대한 농담을 생성합니다.
체인에 정지 시퀀스를 연결하여 텍스트 처리 방법을 제어할 수 있습니다. 예를 들어:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
이 구성은 개행 문자가 발견되면 텍스트 생성을 중지합니다.
LCEL은 체인에 함수 호출 정보를 첨부하는 것을 지원합니다. 예는 다음과 같습니다.
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
이 예에서는 농담을 생성하기 위해 함수 호출 정보를 첨부합니다.
프롬프트 + LLM + OutputParser
출력 구문 분석기를 추가하여 원시 모델 출력을 보다 실행 가능한 형식으로 변환할 수 있습니다. 방법은 다음과 같습니다.
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
이제 출력이 문자열 형식으로 되어 있어 다운스트림 작업에 더 편리합니다.
반환할 함수를 지정할 때 LCEL을 사용하여 직접 구문 분석할 수 있습니다. 예를 들어:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
이 예에서는 "joke" 함수의 출력을 직접 구문 분석합니다.
이는 LCEL이 어떻게 복잡한 언어 처리 작업을 단순화하는지 보여주는 몇 가지 예입니다. 챗봇을 구축하든, 콘텐츠를 생성하든, 복잡한 텍스트 변환을 수행하든 LCEL은 작업 흐름을 간소화하고 코드 유지 관리를 더욱 쉽게 만들어줍니다.
RAG(검색 증강 생성)
LCEL은 검색 및 언어 생성 단계를 결합하는 검색 증강 생성 체인을 만드는 데 사용할 수 있습니다. 예는 다음과 같습니다.
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
이 예에서 체인은 컨텍스트에서 관련 정보를 검색하고 질문에 대한 응답을 생성합니다.
대화형 검색 체인
체인에 대화 기록을 쉽게 추가할 수 있습니다. 다음은 대화형 검색 체인의 예입니다.
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
이 예에서 체인은 대화 컨텍스트 내에서 후속 질문을 처리합니다.
메모리 및 원본 문서 반환 포함
LCEL은 메모리 및 원본 문서 반환도 지원합니다. 체인에서 메모리를 사용하는 방법은 다음과 같습니다.
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
이 예에서는 대화 기록과 원본 문서를 저장하고 검색하는 데 메모리가 사용됩니다.
다중 체인
Runnable을 사용하여 여러 체인을 함께 묶을 수 있습니다. 예는 다음과 같습니다.
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
이 예에서는 두 개의 체인이 결합되어 특정 언어로 도시와 국가에 대한 정보를 생성합니다.
분기 및 병합
LCEL을 사용하면 RunnableMaps를 사용하여 체인을 분할하고 병합할 수 있습니다. 다음은 분기 및 병합의 예입니다.
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
이 예에서는 분기 및 병합 체인을 사용하여 인수를 생성하고 최종 응답을 생성하기 전에 장단점을 평가합니다.
LCEL로 Python 코드 작성
LCEL(LangChain Expression Language)의 강력한 응용 프로그램 중 하나는 Python 코드를 작성하여 사용자 문제를 해결하는 것입니다. 다음은 LCEL을 사용하여 Python 코드를 작성하는 방법의 예입니다.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
이 예에서 사용자는 입력을 제공하고 LCEL은 문제를 해결하기 위해 Python 코드를 생성합니다. 그런 다음 코드는 Python REPL을 사용하여 실행되고 결과 Python 코드는 Markdown 형식으로 반환됩니다.
Python REPL을 사용하면 임의의 코드가 실행될 수 있으므로 주의해서 사용하세요.
체인에 메모리 추가
메모리는 많은 대화형 AI 애플리케이션에서 필수적입니다. 임의의 체인에 메모리를 추가하는 방법은 다음과 같습니다.
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
이 예에서는 대화 기록을 저장하고 검색하는 데 메모리가 사용되므로 챗봇이 컨텍스트를 유지하고 적절하게 응답할 수 있습니다.
Runnable과 함께 외부 도구 사용
LCEL을 사용하면 외부 도구를 Runnable과 원활하게 통합할 수 있습니다. 다음은 DuckDuckGo 검색 도구를 사용하는 예입니다.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
이 예에서 LCEL은 DuckDuckGo 검색 도구를 체인에 통합하여 사용자 입력에서 검색 쿼리를 생성하고 검색 결과를 검색할 수 있습니다.
LCEL의 유연성 덕분에 다양한 외부 도구와 서비스를 언어 처리 파이프라인에 쉽게 통합하여 기능을 향상시킬 수 있습니다.
LLM 지원서에 중재 추가
LLM 애플리케이션이 콘텐츠 정책을 준수하고 조정 보호 장치를 포함하는지 확인하기 위해 조정 확인을 체인에 통합할 수 있습니다. LangChain을 사용하여 중재를 추가하는 방법은 다음과 같습니다.
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
이 예에서 OpenAIModerationChain LLM에서 생성된 응답에 조정을 추가하는 데 사용됩니다. 중재 체인은 OpenAI의 콘텐츠 정책을 위반하는 콘텐츠에 대한 응답을 확인합니다. 위반 사항이 발견되면 이에 따라 응답에 플래그가 지정됩니다.
의미론적 유사성에 의한 라우팅
LCEL을 사용하면 사용자 입력의 의미적 유사성을 기반으로 사용자 지정 라우팅 논리를 구현할 수 있습니다. 다음은 사용자 입력을 기반으로 체인 논리를 동적으로 결정하는 방법에 대한 예입니다.
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
이 예에서 prompt_router 함수는 물리 및 수학 질문에 대해 사용자 입력과 사전 정의된 프롬프트 템플릿 간의 코사인 유사성을 계산합니다. 유사성 점수에 따라 체인은 가장 관련성이 높은 프롬프트 템플릿을 동적으로 선택하여 챗봇이 사용자의 질문에 적절하게 응답하도록 합니다.
에이전트 및 실행 파일 사용
LangChain을 사용하면 Runnables, 프롬프트, 모델 및 도구를 결합하여 에이전트를 만들 수 있습니다. 다음은 에이전트를 구축하고 사용하는 예입니다.
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
이 예에서는 모델, 도구, 프롬프트, 중간 단계 및 도구 변환을 위한 사용자 정의 논리를 결합하여 에이전트를 생성합니다. 그런 다음 에이전트가 실행되어 사용자의 쿼리에 대한 응답을 제공합니다.
SQL 데이터베이스 쿼리
LangChain을 사용하여 SQL 데이터베이스에 쿼리하고 사용자 질문을 기반으로 SQL 쿼리를 생성할 수 있습니다. 예는 다음과 같습니다.
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
이 예에서 LangChain은 사용자 질문을 기반으로 SQL 쿼리를 생성하고 SQL 데이터베이스에서 응답을 검색하는 데 사용됩니다. 프롬프트와 응답은 데이터베이스와의 자연어 상호 작용을 제공하도록 형식화됩니다.
귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
LangServe 및 LangSmith
LangServe는 개발자가 LangChain 실행 가능 항목과 체인을 REST API로 배포하는 데 도움을 줍니다. 이 라이브러리는 FastAPI와 통합되어 있으며 데이터 검증을 위해 pydantic을 사용합니다. 또한 서버에 배포된 실행 파일을 호출하는 데 사용할 수 있는 클라이언트를 제공하며 JavaScript 클라이언트는 LangChainJS에서 사용할 수 있습니다.
특징
- 입력 및 출력 스키마는 LangChain 개체에서 자동으로 추론되어 모든 API 호출에 풍부한 오류 메시지와 함께 적용됩니다.
- JSONSchema 및 Swagger가 포함된 API 문서 페이지를 사용할 수 있습니다.
- 단일 서버에서 많은 동시 요청을 지원하는 효율적인 /invoke, /batch 및 /stream 엔드포인트입니다.
- 체인/에이전트의 모든(또는 일부) 중간 단계를 스트리밍하기 위한 /stream_log 엔드포인트입니다.
- 스트리밍 출력 및 중간 단계가 포함된 /playground의 플레이그라운드 페이지입니다.
- LangSmith에 대한 추적 기능이 내장되어 있습니다(선택 사항). API 키를 추가하기만 하면 됩니다(지침 참조).
- 모두 FastAPI, Pydantic, uvloop 및 asyncio와 같은 검증된 오픈 소스 Python 라이브러리로 구축되었습니다.
제한 사항
- 서버에서 발생하는 이벤트에 대해서는 클라이언트 콜백이 아직 지원되지 않습니다.
- Pydantic V2를 사용하면 OpenAPI 문서가 생성되지 않습니다. FastAPI는 pydantic v1 및 v2 네임스페이스 혼합을 지원하지 않습니다. 자세한 내용은 아래 섹션을 참조하세요.
LangChain CLI를 사용하여 LangServe 프로젝트를 신속하게 부트스트랩하십시오. langchain CLI를 사용하려면 최신 버전의 langchain-cli가 설치되어 있는지 확인하십시오. pip install -U langchain-cli를 사용하여 설치할 수 있습니다.
langchain app new ../path/to/directory
LangChain 템플릿을 사용하여 LangServe 인스턴스를 빠르게 시작하세요. 더 많은 예제를 보려면 템플릿 색인이나 예제 디렉터리를 참조하세요.
다음은 OpenAI 채팅 모델, Anthropic 채팅 모델 및 Anthropic 모델을 사용하여 주제에 대한 농담을 전하는 체인을 배포하는 서버입니다.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
위의 서버를 배포한 후에는 다음을 사용하여 생성된 OpenAPI 문서를 볼 수 있습니다.
curl localhost:8000/docs
/docs 접미사를 추가하세요.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
TypeScript에서(LangChain.js 버전 0.0.166 이상이 필요함):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `http://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
요청을 사용하는 Python:
import requests
response = requests.post( "http://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
컬을 사용할 수도 있습니다.
curl --location --request POST 'http://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
다음 코드 :
...
add_routes( app, runnable, path="/my_runnable",
)
다음 엔드포인트를 서버에 추가합니다.
- POST /my_runnable/invoke – 단일 입력에서 실행 가능 파일 호출
- POST /my_runnable/batch – 일괄 입력에서 실행 가능 파일을 호출합니다.
- POST /my_runnable/stream – 단일 입력에 대해 호출하고 출력을 스트리밍합니다.
- POST /my_runnable/stream_log – 단일 입력에 대해 호출하고 생성된 중간 단계의 출력을 포함하여 출력을 스트리밍합니다.
- GET /my_runnable/input_schema – 실행 가능 항목에 대한 입력을 위한 json 스키마
- GET /my_runnable/output_schema – 실행 가능 파일의 출력을 위한 json 스키마
- GET /my_runnable/config_schema – 실행 가능 구성을 위한 json 스키마
/my_runnable/playground에서 실행 가능한 플레이그라운드 페이지를 찾을 수 있습니다. 이는 스트리밍 출력 및 중간 단계를 사용하여 실행 파일을 구성하고 호출하는 간단한 UI를 노출합니다.
클라이언트와 서버 모두에 대해:
pip install "langserve[all]"
또는 클라이언트 코드의 경우 pip install “langserve[client]”, 서버 코드의 경우 pip install “langserve[server]”입니다.
서버에 인증을 추가해야 하는 경우 FastAPI의 보안 문서 및 미들웨어 문서를 참조하세요.
다음 명령어를 사용하여 GCP Cloud Run에 배포할 수 있습니다.
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe는 몇 가지 제한 사항이 있지만 Pydantic 2에 대한 지원을 제공합니다. Pydantic V2를 사용할 때 호출/배치/스트림/스트림_로그에 대한 OpenAPI 문서가 생성되지 않습니다. Fast API는 pydantic v1 및 v2 네임스페이스 혼합을 지원하지 않습니다. LangChain은 Pydantic v1에서 v2 네임스페이스를 사용합니다. LangChain과의 호환성을 보장하려면 다음 지침을 읽으십시오. 이러한 제한 사항을 제외하면 API 엔드포인트, 플레이그라운드 및 기타 모든 기능이 예상대로 작동할 것으로 기대합니다.
LLM 응용 프로그램은 종종 파일을 처리합니다. 파일 처리를 구현하기 위해 만들 수 있는 다양한 아키텍처가 있습니다. 높은 수준에서:
- 파일은 전용 엔드포인트를 통해 서버에 업로드되고 별도의 엔드포인트를 사용하여 처리될 수 있습니다.
- 파일은 값(파일 바이트) 또는 참조(예: 파일 콘텐츠에 대한 s3 URL)로 업로드될 수 있습니다.
- 처리 끝점은 차단 또는 비차단일 수 있습니다.
- 상당한 처리가 필요한 경우 해당 처리를 전용 프로세스 풀로 오프로드할 수 있습니다.
애플리케이션에 적합한 아키텍처가 무엇인지 결정해야 합니다. 현재 실행 가능 파일에 값별로 파일을 업로드하려면 파일에 대해 base64 인코딩을 사용하십시오(multipart/form-data는 아직 지원되지 않음).
여기에 예 이는 base64 인코딩을 사용하여 파일을 원격 실행 가능 파일로 보내는 방법을 보여줍니다. 언제든지 참조(예: s3 url)로 파일을 업로드하거나 전용 엔드포인트에 멀티파트/양식 데이터로 업로드할 수 있다는 점을 기억하세요.
입력 및 출력 유형은 모든 실행 가능 파일에 정의됩니다. input_schema 및output_schema 속성을 통해 액세스할 수 있습니다. LangServe는 검증 및 문서화를 위해 이러한 유형을 사용합니다. 기본 유추 유형을 재정의하려면 with_types 메소드를 사용할 수 있습니다.
다음은 아이디어를 설명하는 장난감 예입니다.
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
데이터를 동등한 dict 표현이 아닌 pydantic 모델로 역직렬화하려면 CustomUserType에서 상속하세요. 현재 이 유형은 서버 측에서만 작동하며 원하는 디코딩 동작을 지정하는 데 사용됩니다. 이 유형에서 상속하는 경우 서버는 디코딩된 유형을 사전으로 변환하는 대신 pydantic 모델로 유지합니다.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
플레이그라운드를 사용하면 백엔드에서 실행 가능한 사용자 정의 위젯을 정의할 수 있습니다. 위젯은 필드 수준에서 지정되며 입력 유형의 JSON 스키마의 일부로 제공됩니다. 위젯에는 잘 알려진 위젯 목록 중 하나인 값을 갖는 type이라는 키가 포함되어야 합니다. 다른 위젯 키는 JSON 객체의 경로를 설명하는 값과 연결됩니다.
일반 스키마:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
base64로 인코딩된 문자열로 업로드된 파일에 대해 UI 플레이그라운드에서 파일 업로드 입력을 생성할 수 있습니다. 전체 예는 다음과 같습니다.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
랭스미스 소개
LangChain을 사용하면 LLM 애플리케이션 및 에이전트의 프로토타입을 쉽게 만들 수 있습니다. 그러나 LLM 애플리케이션을 프로덕션 환경에 제공하는 것은 믿을 수 없을 만큼 어려울 수 있습니다. 고품질 제품을 만들려면 프롬프트, 체인 및 기타 구성 요소를 크게 사용자 정의하고 반복해야 할 것입니다.
이 프로세스를 지원하기 위해 LLM 응용 프로그램 디버깅, 테스트 및 모니터링을 위한 통합 플랫폼인 LangSmith가 도입되었습니다.
언제 유용하게 쓰일까요? 새로운 체인, 에이전트 또는 도구 세트를 신속하게 디버깅하고, 구성 요소(체인, llms, 검색기 등)가 어떻게 관련되고 사용되는지 시각화하고, 단일 구성 요소에 대한 다양한 프롬프트 및 LLM을 평가하려는 경우 유용할 수 있습니다. 데이터 세트에 대해 특정 체인을 여러 번 실행하여 품질 기준을 지속적으로 충족하는지 확인하거나 사용 추적을 캡처하고 LLM 또는 분석 파이프라인을 사용하여 통찰력을 생성합니다.
전제 조건 :
- LangSmith 계정을 생성하고 API 키를 생성합니다(왼쪽 하단 참조).
- 문서를 살펴보고 플랫폼에 익숙해지세요.
이제 시작합시다!
먼저 LangChain이 추적을 기록하도록 환경 변수를 구성합니다. LANGCHAIN_TRACING_V2 환경 변수를 true로 설정하면 됩니다. LANGCHAIN_PROJECT 환경 변수를 설정하여 로그인할 프로젝트를 LangChain에 알릴 수 있습니다(설정하지 않으면 실행이 기본 프로젝트에 기록됩니다). 프로젝트가 없으면 자동으로 프로젝트가 생성됩니다. LANGCHAIN_ENDPOINT 및 LANGCHAIN_API_KEY 환경 변수도 설정해야 합니다.
참고: Python의 컨텍스트 관리자를 사용하여 다음을 사용하여 추적을 기록할 수도 있습니다.
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
그러나 이 예에서는 환경 변수를 사용합니다.
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
API와 상호 작용할 LangSmith 클라이언트를 만듭니다.
from langsmith import Client client = Client()
LangChain 구성 요소를 생성하고 플랫폼에 실행을 기록합니다. 이 예에서는 일반 검색 도구(DuckDuckGo)에 액세스할 수 있는 ReAct 스타일 에이전트를 생성합니다. 상담원의 메시지는 다음 허브에서 볼 수 있습니다.
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
대기 시간을 줄이기 위해 여러 입력에서 에이전트를 동시에 실행하고 있습니다. 실행은 백그라운드에서 LangSmith에 기록되므로 실행 대기 시간은 영향을 받지 않습니다.
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
환경을 성공적으로 설정했다고 가정하면 에이전트 추적이 앱의 프로젝트 섹션에 표시됩니다. 축하해요!
그런데 상담원이 도구를 효과적으로 사용하지 않는 것 같습니다. 이를 평가하여 기준을 마련해 보겠습니다.
실행 로깅 외에도 LangSmith를 사용하면 LLM 응용 프로그램을 테스트하고 평가할 수 있습니다.
이 섹션에서는 LangSmith를 활용하여 벤치마크 데이터 세트를 생성하고 에이전트에서 AI 지원 평가자를 실행합니다. 다음과 같은 몇 가지 단계를 거쳐 수행됩니다.
- LangSmith 데이터세트를 만듭니다.
아래에서는 LangSmith 클라이언트를 사용하여 위의 입력 질문과 목록 레이블로 데이터세트를 생성합니다. 나중에 이를 사용하여 새 에이전트의 성능을 측정합니다. 데이터 세트는 애플리케이션에 대한 테스트 사례로 사용할 수 있는 입력-출력 쌍에 불과한 예제 모음입니다.
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- 벤치마킹할 새 에이전트를 초기화합니다.
LangSmith를 사용하면 LLM, 체인, 에이전트 또는 사용자 정의 기능까지 평가할 수 있습니다. 대화형 에이전트는 상태를 저장합니다(메모리가 있음). 이 상태가 데이터 세트 실행 간에 공유되지 않도록 하기 위해 chain_factory(
생성자라고도 함) 함수를 사용하여 각 호출을 초기화합니다.
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- 평가 구성:
UI에서 체인 결과를 수동으로 비교하는 것은 효과적이지만 시간이 많이 걸릴 수 있습니다. 자동화된 지표와 AI 지원 피드백을 사용하여 구성 요소의 성능을 평가하는 것이 도움이 될 수 있습니다.
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- 에이전트 및 평가자를 실행합니다.
run_on_dataset(또는 비동기 arun_on_dataset) 함수를 사용하여 모델을 평가하세요. 이는 다음을 수행합니다.
- 지정된 데이터세트에서 예시 행을 가져옵니다.
- 각 예에서 에이전트(또는 사용자 지정 함수)를 실행하세요.
- 결과 실행 추적 및 해당 참조 예제에 평가자를 적용하여 자동화된 피드백을 생성합니다.
결과는 LangSmith 앱에 표시됩니다.
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
이제 테스트 실행 결과를 얻었으므로 에이전트를 변경하고 벤치마킹할 수 있습니다. 다른 프롬프트로 다시 시도하고 결과를 확인해 보겠습니다.
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
LangSmith를 사용하면 웹 앱에서 직접 CSV 또는 JSONL과 같은 일반적인 형식으로 데이터를 내보낼 수 있습니다. 또한 클라이언트를 사용하여 추가 분석을 위해 실행을 가져오거나, 자신의 데이터베이스에 저장하거나, 다른 사람과 공유할 수 있습니다. 평가 실행에서 실행 추적을 가져오겠습니다.
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
이것은 시작하기 위한 빠른 가이드였지만 LangSmith를 사용하여 개발자 흐름의 속도를 높이고 더 나은 결과를 생성하는 더 많은 방법이 있습니다.
LangSmith를 최대한 활용하는 방법에 대한 자세한 내용은 LangSmith 설명서를 확인하세요.
나노넷으로 레벨업
LangChain은 언어 모델(LLM)을 애플리케이션과 통합하는 데 유용한 도구이지만 기업 사용 사례에서는 제한에 직면할 수 있습니다. Nanonets가 LangChain을 넘어 이러한 문제를 해결하는 방법을 살펴보겠습니다.
1. 포괄적인 데이터 연결성:
LangChain은 커넥터를 제공하지만 기업이 의존하는 모든 작업 공간 앱과 데이터 형식을 포괄하지 못할 수도 있습니다. Nanonets는 Slack, Notion, Google Suite, Salesforce, Zendesk 등을 포함하여 널리 사용되는 100개 이상의 작업 공간 앱에 대한 데이터 커넥터를 제공합니다. 또한 PDF, TXT, 이미지, 오디오 파일, 비디오 파일과 같은 모든 구조화되지 않은 데이터 유형은 물론 CSV, 스프레드시트, MongoDB, SQL 데이터베이스와 같은 구조화된 데이터 유형도 지원합니다.

2. Workspace 앱을 위한 작업 자동화:
텍스트/응답 생성은 훌륭하게 작동하지만 다양한 애플리케이션에서 작업을 수행하기 위해 자연어를 사용하는 경우 LangChain의 기능이 제한됩니다. Nanonets는 가장 널리 사용되는 작업 공간 앱을 위한 트리거/작업 에이전트를 제공하므로 이벤트를 수신하고 작업을 수행하는 워크플로를 설정할 수 있습니다. 예를 들어 자연어 명령을 통해 이메일 응답, CRM 항목, SQL 쿼리 등을 자동화할 수 있습니다.
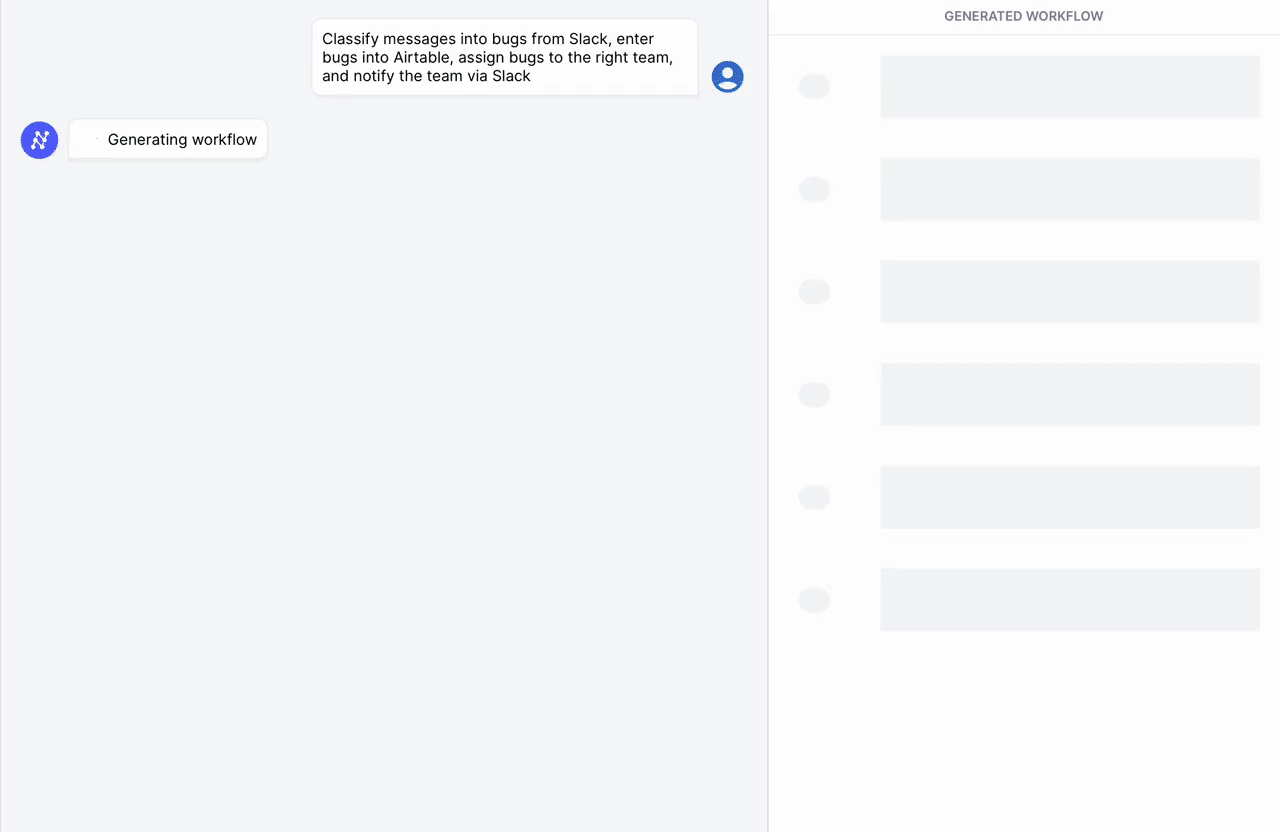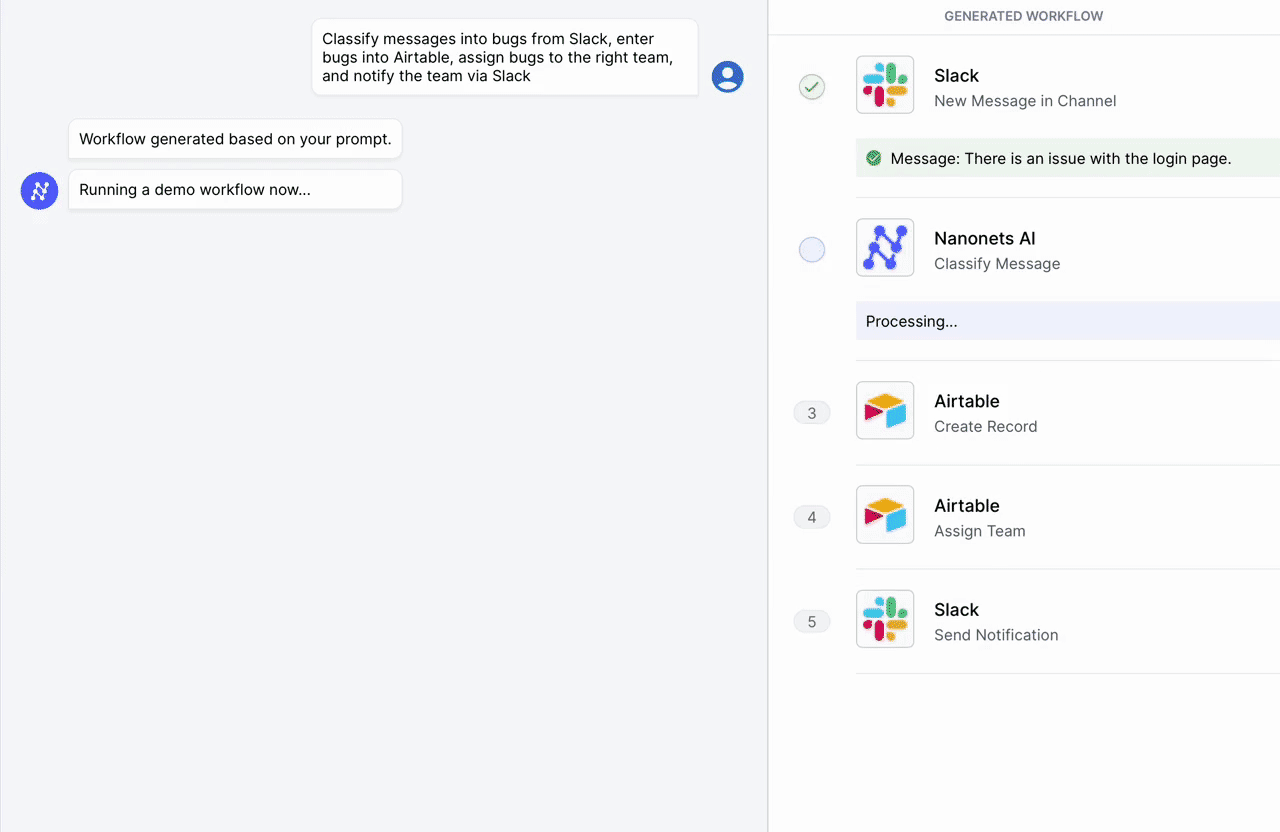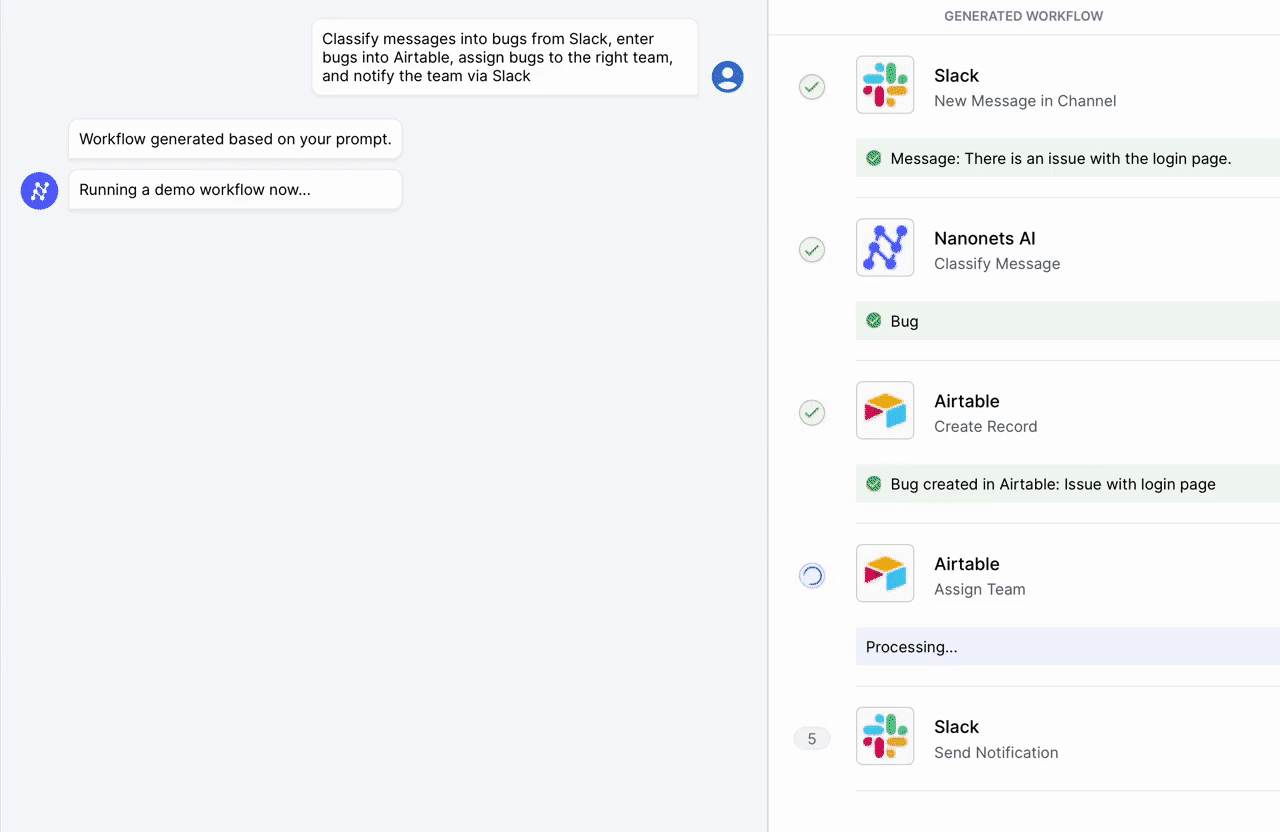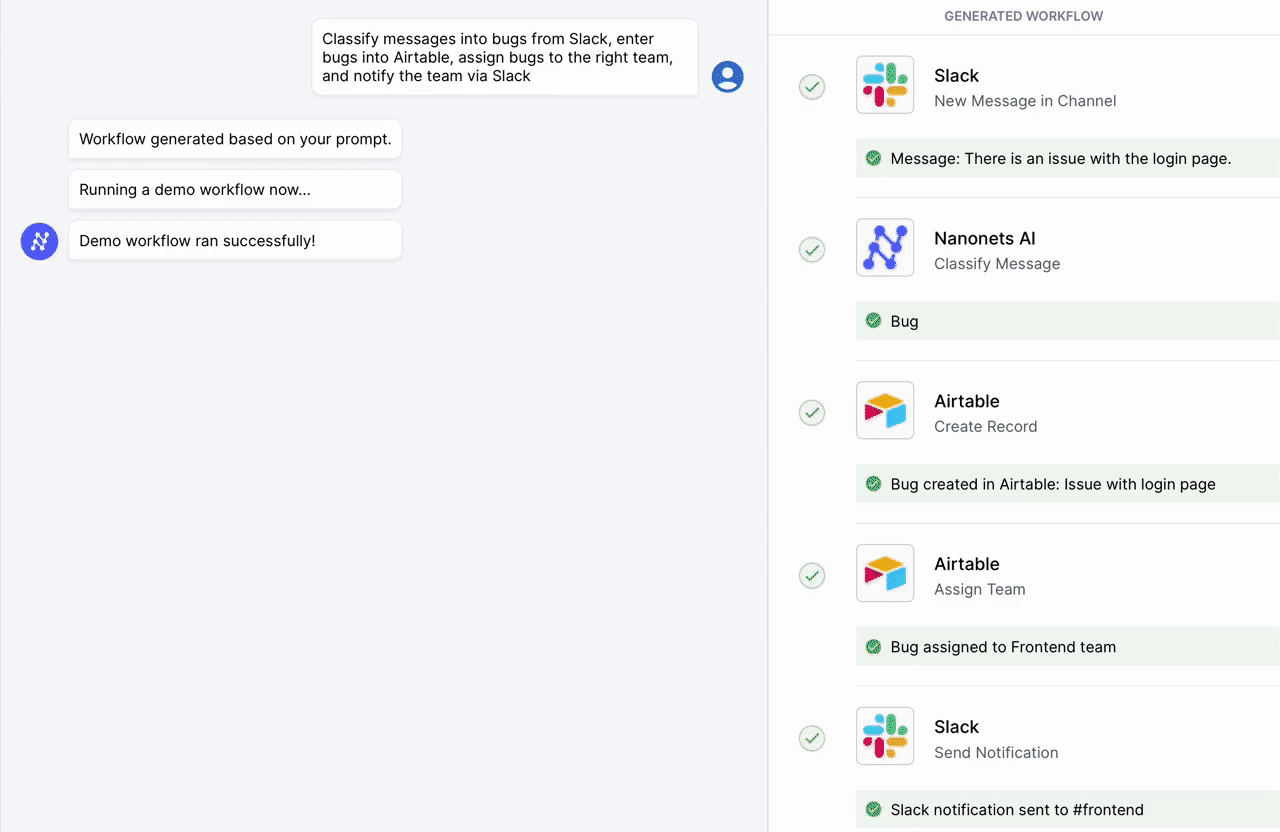
3. 실시간 데이터 동기화:
LangChain은 데이터 커넥터를 사용하여 정적 데이터를 가져오는데, 이는 소스 데이터베이스의 데이터 변경 사항을 따라잡지 못할 수 있습니다. 반면 Nanonets는 데이터 소스와의 실시간 동기화를 보장하므로 항상 최신 정보로 작업할 수 있습니다.

3. 단순화된 구성:
검색기 및 신디사이저와 같은 LangChain 파이프라인의 요소를 구성하는 것은 복잡하고 시간이 많이 걸리는 프로세스일 수 있습니다. Nanonets는 AI Assistant가 백그라운드에서 처리하는 각 데이터 유형에 대해 최적화된 데이터 수집 및 인덱싱을 제공하여 이를 간소화합니다. 이를 통해 미세 조정에 대한 부담이 줄어들고 설정 및 사용이 더 쉬워집니다.
4. 통합 솔루션:
각 작업마다 고유한 구현이 필요할 수 있는 LangChain과 달리 Nanonets는 데이터를 LLM과 연결하기 위한 원스톱 솔루션 역할을 합니다. LLM 애플리케이션을 만들어야 하는지, AI 워크플로우를 만들어야 하는지에 관계없이 Nanonets는 다양한 요구 사항에 맞는 통합 플랫폼을 제공합니다.
Nanonets AI 워크플로
Nanonets Workflows는 LLM과 지식 및 데이터의 통합을 단순화하고 코드 없는 애플리케이션 및 워크플로 생성을 촉진하는 안전한 다목적 AI 도우미입니다. 사용하기 쉬운 사용자 인터페이스를 제공하므로 개인과 조직 모두가 액세스할 수 있습니다.
시작하려면 특정 사용 사례에 맞는 Nanonets 워크플로의 맞춤형 데모 및 평가판을 제공할 수 있는 AI 전문가 중 한 명과 통화 일정을 잡을 수 있습니다.
일단 설정되면 자연어를 사용하여 LLM이 제공하는 복잡한 애플리케이션과 워크플로를 설계 및 실행하고 앱 및 데이터와 원활하게 통합할 수 있습니다.

Nanonets AI로 팀을 강화하여 앱을 만들고 데이터를 AI 기반 애플리케이션 및 워크플로와 통합하여 팀이 정말로 중요한 일에 집중할 수 있도록 하세요.
귀하와 귀하의 팀을 위해 Nanonets가 설계한 AI 기반 워크플로 빌더를 사용하여 수동 작업과 워크플로를 자동화하세요.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://nanonets.com/blog/langchain/

