Duy trì quy trình làm việc của máy học (ML) trong sản xuất là một nhiệm vụ đầy thách thức vì nó đòi hỏi phải tạo ra các quy trình tích hợp liên tục và phân phối liên tục (CI/CD) cho mã và mô hình ML, lập phiên bản mô hình, giám sát sự trôi dạt của dữ liệu và khái niệm, đào tạo lại mô hình và hướng dẫn sử dụng. quy trình phê duyệt để đảm bảo các phiên bản mới của mô hình đáp ứng cả yêu cầu về hiệu suất và tuân thủ.
Trong bài đăng này, chúng tôi mô tả cách tạo quy trình làm việc MLOps để suy luận hàng loạt nhằm tự động lập kế hoạch công việc, giám sát mô hình, đào tạo lại và đăng ký cũng như xử lý lỗi và thông báo bằng cách sử dụng Amazon SageMaker, Sự kiện Amazon, AWS Lambda, Dịch vụ thông báo đơn giản của Amazon (Amazon SNS), HashiCorp Terraform và GitLab CI/CD. Quy trình làm việc MLOps được trình bày cung cấp một mẫu có thể tái sử dụng để quản lý vòng đời ML thông qua tự động hóa, giám sát, khả năng kiểm tra và khả năng mở rộng, từ đó giảm sự phức tạp và chi phí của việc duy trì khối lượng công việc suy luận hàng loạt trong sản xuất.
Tổng quan về giải pháp
Hình dưới đây minh họa kiến trúc MLOps mục tiêu được đề xuất cho suy luận hàng loạt của doanh nghiệp dành cho các tổ chức sử dụng cơ sở hạ tầng GitLab CI/CD và Terraform dưới dạng mã (IaC) kết hợp với các công cụ và dịch vụ AWS. GitLab CI/CD đóng vai trò là người điều phối vĩ mô, điều phối model build và model deploy các đường ống, bao gồm tìm nguồn cung ứng, xây dựng và cung cấp Đường ống Amazon SageMaker và các tài nguyên hỗ trợ bằng SDK SageMaker Python và Terraform. SageMaker Python SDK được sử dụng để tạo hoặc cập nhật quy trình SageMaker cho hoạt động đào tạo, đào tạo với tính năng tối ưu hóa siêu tham số (HPO) và suy luận hàng loạt. Terraform được sử dụng để tạo các tài nguyên bổ sung như quy tắc EventBridge, hàm Lambda và chủ đề SNS để giám sát quy trình SageMaker và gửi thông báo (ví dụ: khi một bước quy trình thất bại hoặc thành công). SageMaker Pipelines đóng vai trò là người điều phối quy trình suy luận và đào tạo mô hình ML.
Thiết kế kiến trúc này thể hiện chiến lược nhiều tài khoản trong đó các mô hình ML được xây dựng, đào tạo và đăng ký trong sổ đăng ký mô hình trung tâm trong tài khoản phát triển khoa học dữ liệu (có nhiều quyền kiểm soát hơn tài khoản phát triển ứng dụng thông thường). Sau đó, quy trình suy luận được triển khai đến các tài khoản dàn dựng và sản xuất bằng cách sử dụng tính năng tự động hóa từ các công cụ DevOps như GitLab CI/CD. Tùy chọn đăng ký mô hình trung tâm cũng có thể được đặt trong tài khoản dịch vụ dùng chung. tham khảo Mô hình hoạt động để biết các phương pháp hay nhất về chiến lược nhiều tài khoản cho ML.
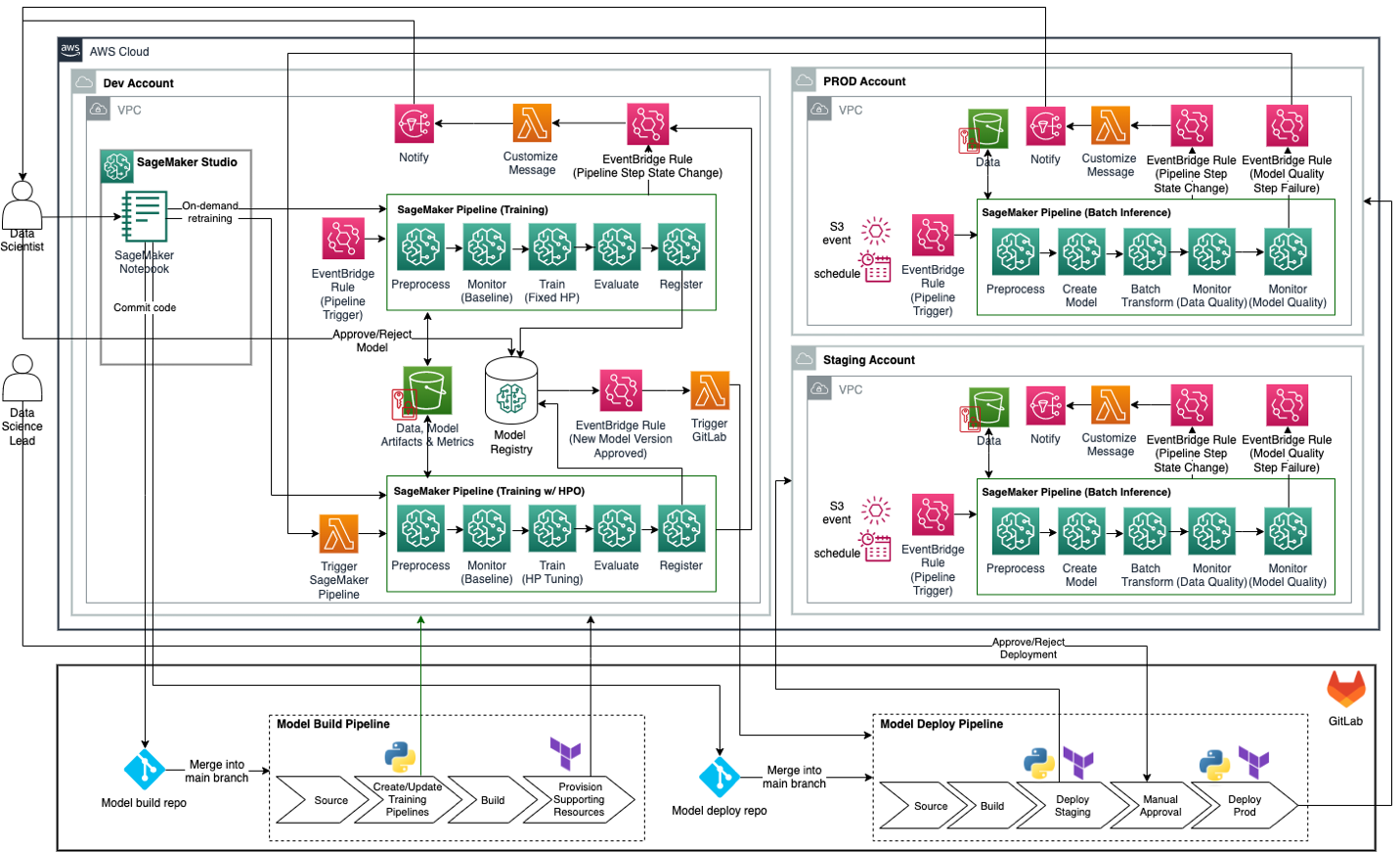
Trong các phần phụ sau đây, chúng ta thảo luận chi tiết về các khía cạnh khác nhau của thiết kế kiến trúc.
Cơ sở hạ tầng như mã
IaC cung cấp cách quản lý cơ sở hạ tầng CNTT thông qua các tệp có thể đọc được bằng máy, đảm bảo kiểm soát phiên bản hiệu quả. Trong bài đăng này và mẫu mã đi kèm, chúng tôi trình bày cách sử dụng Địa hình HashiCorp với GitLab CI/CD để quản lý tài nguyên AWS một cách hiệu quả. Cách tiếp cận này nhấn mạnh lợi ích chính của IaC, mang lại quy trình minh bạch và có thể lặp lại trong quản lý cơ sở hạ tầng CNTT.
Đào tạo và đào tạo lại người mẫu
Trong thiết kế này, quy trình đào tạo SageMaker chạy theo lịch trình (thông qua EventBridge) hoặc dựa trên Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) trình kích hoạt sự kiện (ví dụ: khi tệp kích hoạt hoặc dữ liệu huấn luyện mới, trong trường hợp chỉ có một đối tượng dữ liệu huấn luyện, được đặt trong Amazon S3) để thường xuyên hiệu chỉnh lại mô hình bằng dữ liệu mới. Quy trình này không đưa ra các thay đổi về cấu trúc hoặc vật liệu cho mô hình vì nó sử dụng các siêu tham số cố định đã được phê duyệt trong quá trình xem xét mô hình doanh nghiệp.
Đường dẫn đào tạo đăng ký phiên bản mô hình mới được đào tạo trong Cơ quan đăng ký mô hình Amazon SageMaker nếu mô hình vượt quá ngưỡng hiệu suất mô hình được xác định trước (ví dụ: RMSE cho hồi quy và điểm F1 cho phân loại). Khi một phiên bản mới của mô hình được đăng ký trong sổ đăng ký mô hình, nó sẽ kích hoạt thông báo tới nhà khoa học dữ liệu chịu trách nhiệm thông qua Amazon SNS. Sau đó, nhà khoa học dữ liệu cần xem xét và phê duyệt thủ công phiên bản mới nhất của mô hình trong Xưởng sản xuất Amazon SageMaker UI hoặc thông qua lệnh gọi API bằng cách sử dụng Giao diện dòng lệnh AWS (AWS CLI) hoặc AWS SDK cho Python (Boto3) trước khi phiên bản mới của mô hình có thể được sử dụng để suy luận.
Quy trình đào tạo SageMaker và các tài nguyên hỗ trợ của nó được tạo bởi GitLab model build đường dẫn, thông qua việc chạy thủ công đường dẫn GitLab hoặc tự động khi mã được hợp nhất vào main chi nhánh của model build Kho lưu trữ Git.
Suy luận hàng loạt
Quy trình suy luận hàng loạt của SageMaker chạy theo lịch trình (thông qua EventBridge) hoặc dựa trên trình kích hoạt sự kiện S3. Đường dẫn suy luận hàng loạt tự động lấy phiên bản mô hình được phê duyệt mới nhất từ sổ đăng ký mô hình và sử dụng nó để suy luận. Quy trình suy luận hàng loạt bao gồm các bước để kiểm tra chất lượng dữ liệu so với đường cơ sở do quy trình đào tạo tạo ra, cũng như chất lượng mô hình (hiệu suất mô hình) nếu có nhãn sự thật cơ bản.
Nếu quy trình suy luận hàng loạt phát hiện các vấn đề về chất lượng dữ liệu, quy trình sẽ thông báo cho nhà khoa học dữ liệu chịu trách nhiệm thông qua Amazon SNS. Nếu phát hiện ra vấn đề về chất lượng mô hình (ví dụ: RMSE lớn hơn ngưỡng được chỉ định trước), bước quy trình để kiểm tra chất lượng mô hình sẽ không thành công, điều này sẽ kích hoạt sự kiện EventBridge để bắt đầu đào tạo với quy trình HPO.
Quy trình suy luận hàng loạt của SageMaker và các tài nguyên hỗ trợ của nó được tạo bởi GitLab model deploy đường dẫn, thông qua việc chạy thủ công đường dẫn GitLab hoặc tự động khi mã được hợp nhất vào main chi nhánh của model deploy Kho lưu trữ Git.
Điều chỉnh và điều chỉnh mô hình
Quá trình đào tạo SageMaker với quy trình HPO được kích hoạt khi bước kiểm tra chất lượng mô hình của quy trình suy luận hàng loạt không thành công. Việc kiểm tra chất lượng mô hình được thực hiện bằng cách so sánh các dự đoán của mô hình với các nhãn chân lý thực tế. Nếu chỉ số chất lượng mô hình (ví dụ: RMSE cho hồi quy và điểm F1 cho phân loại) không đáp ứng tiêu chí được chỉ định trước thì bước kiểm tra chất lượng mô hình sẽ được đánh dấu là không thành công. Nhà khoa học dữ liệu chịu trách nhiệm cũng có thể kích hoạt chương trình đào tạo SageMaker với quy trình HPO theo cách thủ công (trong giao diện người dùng SageMaker Studio hoặc thông qua lệnh gọi API bằng AWS CLI hoặc SageMaker Python SDK) nếu cần. Vì các siêu tham số của mô hình đang thay đổi nên nhà khoa học dữ liệu chịu trách nhiệm cần phải nhận được sự chấp thuận từ hội đồng đánh giá mô hình doanh nghiệp trước khi phiên bản mô hình mới có thể được phê duyệt trong cơ quan đăng ký mô hình.
Chương trình đào tạo SageMaker với quy trình HPO và các tài nguyên hỗ trợ của nó được tạo bởi GitLab model build đường dẫn, thông qua việc chạy thủ công đường dẫn GitLab hoặc tự động khi mã được hợp nhất vào main chi nhánh của model build Kho lưu trữ Git.
Giám sát mô hình
Thống kê dữ liệu và các đường cơ sở ràng buộc được tạo ra như một phần của quá trình đào tạo và đào tạo về quy trình HPO. Chúng được lưu vào Amazon S3 và cũng được đăng ký với mô hình đã đào tạo trong sổ đăng ký mô hình nếu mô hình đó vượt qua quá trình đánh giá. Kiến trúc đề xuất cho việc sử dụng đường dẫn suy luận hàng loạt Giám sát mô hình Amazon SageMaker để kiểm tra chất lượng dữ liệu trong khi sử dụng tùy chỉnh Chế biến Amazon SageMaker các bước kiểm tra chất lượng mô hình Thiết kế này tách riêng dữ liệu và kiểm tra chất lượng mô hình, từ đó cho phép bạn chỉ gửi thông báo cảnh báo khi phát hiện thấy dữ liệu trôi dạt; và kích hoạt quá trình đào tạo với quy trình HPO khi phát hiện vi phạm về chất lượng mô hình.
Phê duyệt mô hình
Sau khi một mô hình mới được đào tạo được đăng ký vào sổ đăng ký mô hình, nhà khoa học dữ liệu chịu trách nhiệm sẽ nhận được thông báo. Nếu mô hình đã được đào tạo theo quy trình đào tạo (hiệu chỉnh lại với dữ liệu đào tạo mới trong khi siêu tham số đã được sửa) thì không cần phải có sự phê duyệt của hội đồng đánh giá mô hình doanh nghiệp. Nhà khoa học dữ liệu có thể xem xét và phê duyệt phiên bản mới của mô hình một cách độc lập. Mặt khác, nếu mô hình đã được huấn luyện bằng đường ống HPO (trở lại bằng cách thay đổi siêu tham số), phiên bản mô hình mới cần phải trải qua quá trình đánh giá của doanh nghiệp trước khi có thể sử dụng để suy luận trong sản xuất. Khi quá trình xem xét hoàn tất, nhà khoa học dữ liệu có thể tiến hành và phê duyệt phiên bản mới của mô hình trong sổ đăng ký mô hình. Thay đổi trạng thái của gói mô hình thành Approved sẽ kích hoạt chức năng Lambda thông qua EventBridge, từ đó sẽ kích hoạt GitLab model deploy đường dẫn thông qua lệnh gọi API. Thao tác này sẽ tự động cập nhật quy trình suy luận hàng loạt của SageMaker để sử dụng phiên bản mô hình được phê duyệt mới nhất cho hoạt động suy luận.
Có hai cách chính để phê duyệt hoặc từ chối phiên bản mô hình mới trong sổ đăng ký mô hình: sử dụng AWS SDK cho Python (Boto3) hoặc từ giao diện người dùng SageMaker Studio. Theo mặc định, cả quy trình đào tạo và quy trình đào tạo với bộ quy trình HPO ModelApprovalStatus đến PendingManualApproval. Nhà khoa học dữ liệu chịu trách nhiệm có thể cập nhật trạng thái phê duyệt cho mô hình bằng cách gọi update_model_package API từ Boto3. tham khảo Cập nhật Trạng thái Phê duyệt của Mô hình để biết thông tin chi tiết về cách cập nhật trạng thái phê duyệt của mô hình thông qua giao diện người dùng SageMaker Studio.
Thiết kế vào/ra dữ liệu
SageMaker tương tác trực tiếp với Amazon S3 để đọc đầu vào và lưu trữ đầu ra của các bước riêng lẻ trong quy trình đào tạo và suy luận. Sơ đồ sau minh họa sự khác nhau của các tập lệnh Python, dữ liệu đào tạo thô và đã xử lý, dữ liệu suy luận thô và đã xử lý, kết quả suy luận và nhãn sự thật cơ bản (nếu có để giám sát chất lượng mô hình), tạo tác mô hình, số liệu đánh giá đào tạo và suy luận (giám sát chất lượng mô hình), cũng như các đường cơ sở về chất lượng dữ liệu và báo cáo vi phạm (để giám sát chất lượng dữ liệu) có thể được sắp xếp trong bộ chứa S3. Hướng mũi tên trong sơ đồ cho biết tệp nào là đầu vào hoặc đầu ra từ các bước tương ứng trong quy trình SageMaker. Các mũi tên đã được mã hóa màu dựa trên loại bước quy trình để giúp chúng dễ đọc hơn. Quy trình sẽ tự động tải lên các tập lệnh Python từ kho lưu trữ GitLab và lưu trữ các tệp đầu ra hoặc các tạo phẩm mô hình từ mỗi bước trong đường dẫn S3 thích hợp.
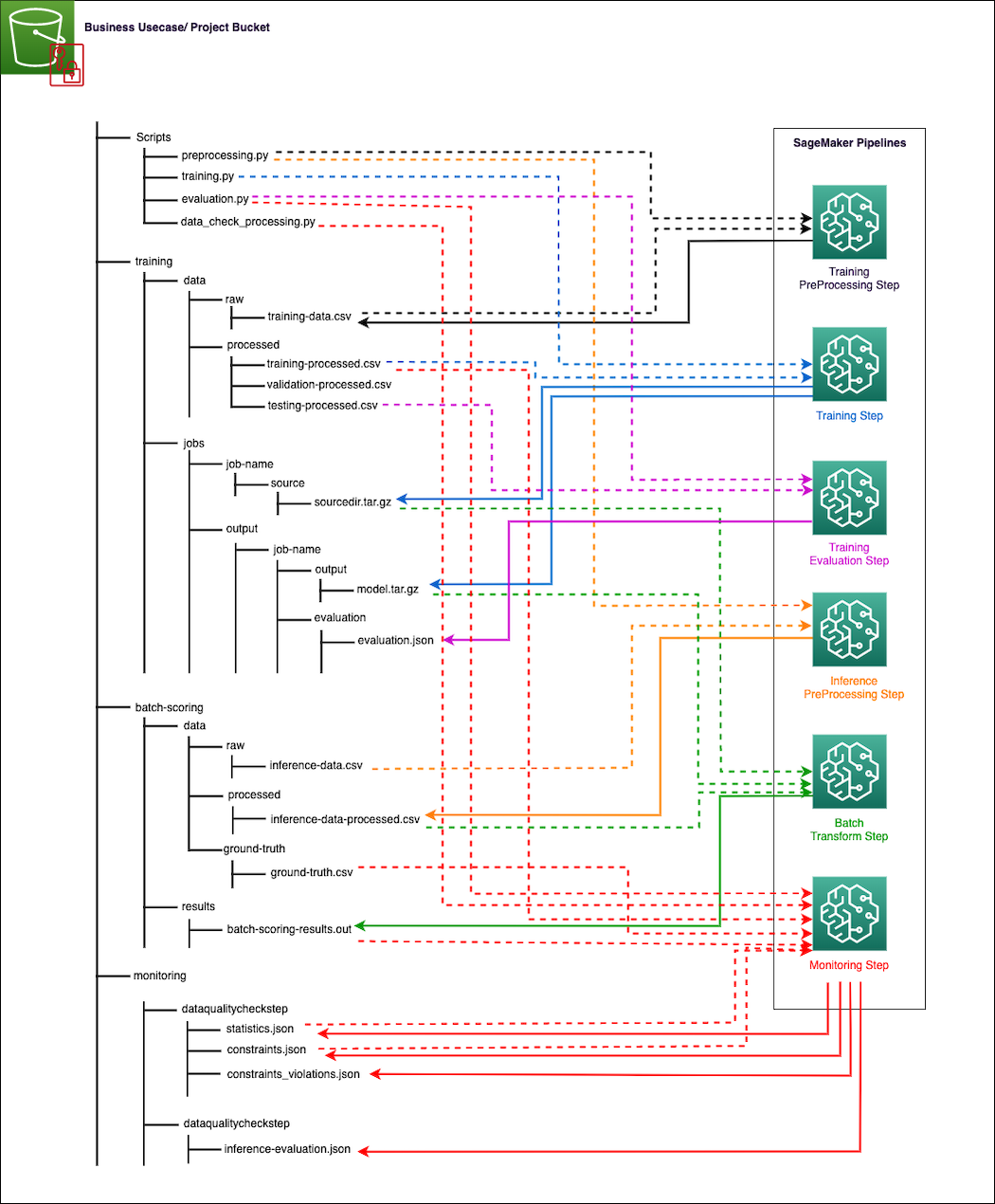
Kỹ sư dữ liệu chịu trách nhiệm về những việc sau:
- Tải dữ liệu đào tạo được gắn nhãn lên đường dẫn thích hợp trong Amazon S3. Điều này bao gồm việc bổ sung dữ liệu đào tạo mới thường xuyên để đảm bảo quy trình đào tạo và quy trình đào tạo với quy trình HPO có quyền truy cập vào dữ liệu đào tạo gần đây để đào tạo lại và điều chỉnh lại mô hình tương ứng.
- Tải dữ liệu đầu vào để suy luận lên đường dẫn thích hợp trong nhóm S3 trước khi chạy quy trình suy luận theo kế hoạch.
- Tải nhãn sự thật cơ bản lên đường dẫn S3 thích hợp để giám sát chất lượng mô hình.
Nhà khoa học dữ liệu chịu trách nhiệm về những việc sau:
- Chuẩn bị nhãn sự thật cơ bản và cung cấp chúng cho nhóm kỹ thuật dữ liệu để tải lên Amazon S3.
- Đưa các phiên bản mô hình được đào tạo qua quy trình đào tạo của HPO thông qua quy trình đánh giá của doanh nghiệp và đạt được các phê duyệt cần thiết.
- Phê duyệt hoặc từ chối các phiên bản mô hình mới được đào tạo theo cách thủ công trong sổ đăng ký mô hình.
- Phê duyệt cổng sản xuất cho đường dẫn suy luận và các nguồn lực hỗ trợ để phát huy vào sản xuất.
Mã mẫu
Trong phần này, chúng tôi trình bày mã mẫu cho các hoạt động suy luận hàng loạt với thiết lập một tài khoản như được hiển thị trong sơ đồ kiến trúc sau. Mã mẫu có thể được tìm thấy trong Kho GitHubvà có thể đóng vai trò là điểm khởi đầu cho suy luận hàng loạt với việc giám sát mô hình và đào tạo lại tự động bằng cách sử dụng các cổng chất lượng thường được yêu cầu đối với các doanh nghiệp. Mã mẫu khác với kiến trúc đích ở những điểm sau:
- Nó sử dụng một tài khoản AWS duy nhất để xây dựng và triển khai mô hình ML cũng như các tài nguyên hỗ trợ. tham khảo Tổ chức môi trường AWS của bạn bằng nhiều tài khoản để được hướng dẫn về thiết lập nhiều tài khoản trên AWS.
- Nó sử dụng một đường dẫn GitLab CI/CD duy nhất để xây dựng và triển khai mô hình ML cũng như các tài nguyên hỗ trợ.
- Khi phiên bản mới của mô hình được đào tạo và phê duyệt, quy trình GitLab CI/CD không được kích hoạt tự động và cần được nhà khoa học dữ liệu chịu trách nhiệm chạy thủ công để cập nhật quy trình suy luận hàng loạt của SageMaker với phiên bản mới nhất được phê duyệt của mô hình.
- Nó chỉ hỗ trợ các trình kích hoạt dựa trên sự kiện S3 để chạy quy trình đào tạo và suy luận của SageMaker.
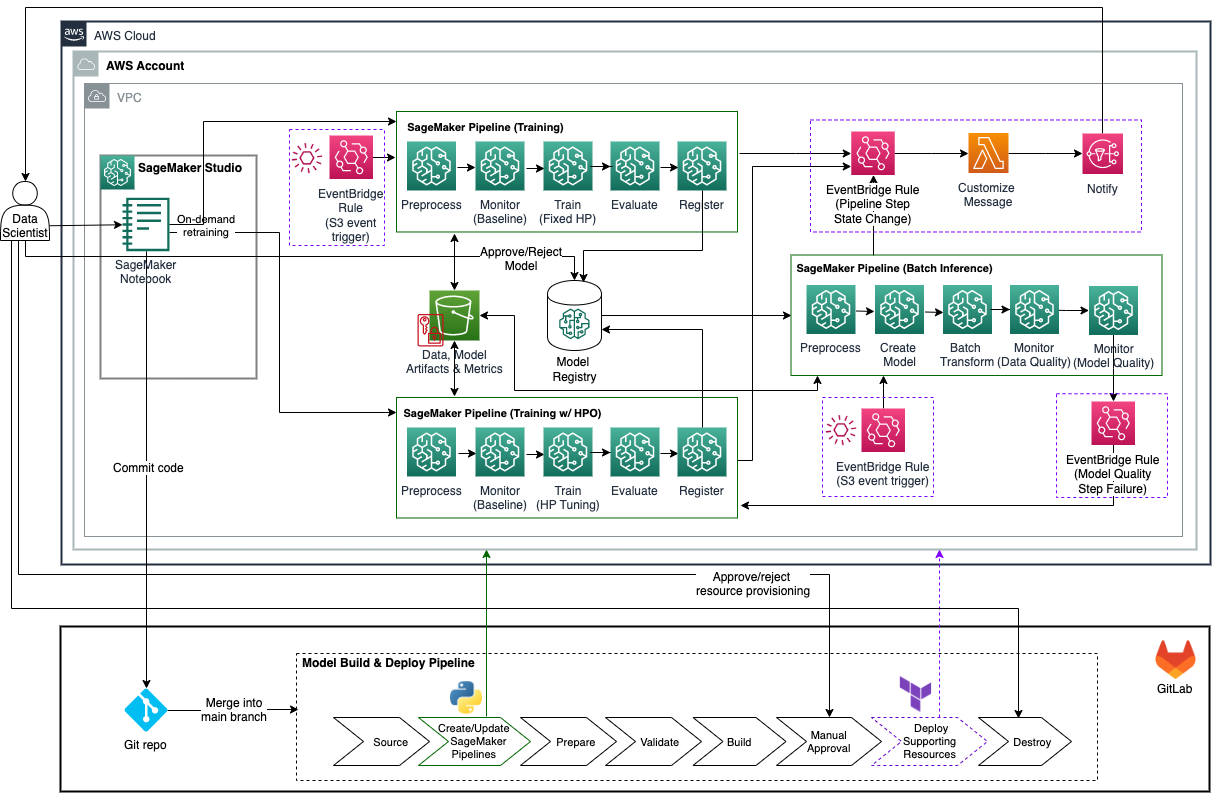
Điều kiện tiên quyết
Bạn cần có các điều kiện tiên quyết sau trước khi triển khai giải pháp này:
- Tài khoản AWS
- Studio SageMaker
- Vai trò thực thi SageMaker với chức năng đọc/ghi của Amazon S3 Dịch vụ quản lý khóa AWS (AWS KMS) quyền mã hóa/giải mã
- Bộ chứa S3 để lưu trữ dữ liệu, tập lệnh và thành phần mô hình
- Terraform phiên bản 0.13.5 trở lên
- GitLab với trình chạy Docker đang hoạt động để chạy các đường ống
- AWSCLI
- jq
- giải nén
- Python3 (Python 3.7 trở lên) và các gói Python sau:
- boto3
- nhà làm hiền triết
- gấu trúc
- pyyaml
Cấu trúc kho lưu trữ
Sản phẩm Kho GitHub chứa các thư mục và tập tin sau:
/code/lambda_function/– Thư mục này chứa tệp Python cho hàm Lambda chuẩn bị và gửi thông báo (thông qua Amazon SNS) về các thay đổi trạng thái bước của quy trình SageMaker/data/– Thư mục này bao gồm các tệp dữ liệu thô (đào tạo, suy luận và dữ liệu thực tế)/env_files/– Thư mục này chứa file biến đầu vào Terraform/pipeline_scripts/– Thư mục này chứa ba tập lệnh Python để tạo và cập nhật hoạt động đào tạo, suy luận và đào tạo với các đường dẫn HPO SageMaker, cũng như các tệp cấu hình để chỉ định các tham số của từng đường dẫn/scripts/– Thư mục này chứa các tập lệnh Python bổ sung (chẳng hạn như tiền xử lý và đánh giá) được tham chiếu trong quá trình đào tạo, suy luận và đào tạo với đường ống HPO.gitlab-ci.yml– Tệp này chỉ định cấu hình đường ống GitLab CI/CD/events.tf– Tệp này xác định tài nguyên EventBridge/lambda.tf– Tệp này xác định chức năng thông báo Lambda và các chức năng liên quan Quản lý truy cập và nhận dạng AWS (IAM) tài nguyên/main.tf– Tệp này xác định nguồn dữ liệu Terraform và các biến cục bộ/sns.tf– Tệp này xác định tài nguyên Amazon SNS/tags.json– Tệp JSON này cho phép bạn khai báo các cặp khóa-giá trị thẻ tùy chỉnh và nối chúng vào tài nguyên Terraform của bạn bằng cách sử dụng biến cục bộ/variables.tf– File này khai báo tất cả các biến Terraform
Các biến và cấu hình
Bảng sau đây hiển thị các biến được sử dụng để tham số hóa giải pháp này. Tham khảo đến ./env_files/dev_env.tfvars để biết thêm chi tiết.
| Họ tên | Mô tả |
bucket_name |
Bộ chứa S3 dùng để lưu trữ dữ liệu, tập lệnh và thành phần mô hình |
bucket_prefix |
Tiền tố S3 cho dự án ML |
bucket_train_prefix |
Tiền tố S3 cho dữ liệu đào tạo |
bucket_inf_prefix |
Tiền tố S3 cho dữ liệu suy luận |
notification_function_name |
Tên của hàm Lambda chuẩn bị và gửi thông báo về các thay đổi trạng thái bước của quy trình SageMaker |
custom_notification_config |
Cấu hình để tùy chỉnh thông báo thông báo cho các bước quy trình SageMaker cụ thể khi phát hiện trạng thái chạy quy trình cụ thể |
email_recipient |
Danh sách địa chỉ email để nhận thông báo thay đổi trạng thái bước của quy trình SageMaker |
pipeline_inf |
Tên của quy trình suy luận SageMaker |
pipeline_train |
Tên của quy trình đào tạo SageMaker |
pipeline_trainwhpo |
Tên khóa đào tạo SageMaker với đường ống HPO |
recreate_pipelines |
Nếu được đặt thành true, ba quy trình SageMaker hiện có (đào tạo, suy luận, đào tạo với HPO) sẽ bị xóa và các quy trình mới sẽ được tạo khi chạy GitLab CI/CD |
model_package_group_name |
Tên nhóm gói mô hình |
accuracy_mse_threshold |
Giá trị tối đa của MSE trước khi yêu cầu cập nhật mô hình |
role_arn |
Vai trò IAM ARN của vai trò thực thi quy trình SageMaker |
kms_key |
Khóa KMS ARN dành cho mã hóa Amazon S3 và SageMaker |
subnet_id |
ID mạng con cho cấu hình mạng SageMaker |
sg_id |
ID nhóm bảo mật cho cấu hình mạng SageMaker |
upload_training_data |
Nếu được đặt thành true, dữ liệu đào tạo sẽ được tải lên Amazon S3 và thao tác tải lên này sẽ kích hoạt quá trình chạy quy trình đào tạo |
upload_inference_data |
Nếu được đặt thành true, dữ liệu suy luận sẽ được tải lên Amazon S3 và thao tác tải lên này sẽ kích hoạt quá trình chạy quy trình suy luận |
user_id |
ID nhân viên của người dùng SageMaker được thêm dưới dạng thẻ vào tài nguyên SageMaker |
Triển khai giải pháp
Hoàn thành các bước sau để triển khai giải pháp trong tài khoản AWS của bạn:
- Sao chép kho GitHub vào thư mục làm việc của bạn.
- Xem lại và sửa đổi cấu hình quy trình GitLab CI/CD cho phù hợp với môi trường của bạn. Cấu hình được chỉ định trong
./gitlab-ci.ymltập tin. - Tham khảo tệp README để cập nhật các biến giải pháp chung trong
./env_files/dev_env.tfvarstài liệu. Tệp này chứa các biến cho cả tập lệnh Python và tự động hóa Terraform.- Kiểm tra các tham số Quy trình SageMaker bổ sung được xác định trong tệp YAML bên dưới
./batch_scoring_pipeline/pipeline_scripts/. Xem lại và cập nhật các thông số nếu cần thiết.
- Kiểm tra các tham số Quy trình SageMaker bổ sung được xác định trong tệp YAML bên dưới
- Xem lại các tập lệnh tạo quy trình SageMaker trong
./pipeline_scripts/cũng như các tập lệnh được họ tham chiếu trong./scripts/thư mục. Các tập lệnh mẫu được cung cấp trong kho GitHub dựa trên Bộ dữ liệu bào ngư. Nếu bạn định sử dụng một tập dữ liệu khác, hãy đảm bảo bạn cập nhật tập lệnh cho phù hợp với vấn đề cụ thể của mình. - Đặt các tập tin dữ liệu của bạn vào
./data/thư mục bằng cách sử dụng quy ước đặt tên sau. Nếu bạn đang sử dụng tập dữ liệu Abalone cùng với các tập lệnh mẫu được cung cấp, hãy đảm bảo tệp dữ liệu không có tiêu đề, dữ liệu huấn luyện bao gồm cả biến độc lập và biến mục tiêu với thứ tự cột ban đầu được giữ nguyên, dữ liệu suy luận chỉ bao gồm các biến độc lập và sự thật cơ bản tập tin chỉ bao gồm biến mục tiêu.training-data.csvinference-data.csvground-truth.csv
- Cam kết và đẩy mã vào kho lưu trữ để kích hoạt quá trình chạy quy trình GitLab CI/CD (lần chạy đầu tiên). Lưu ý rằng lần chạy quy trình đầu tiên sẽ thất bại trên
pipelinestage vì chưa có phiên bản mô hình nào được phê duyệt để sử dụng tập lệnh đường dẫn suy luận. Xem lại nhật ký bước và xác minh quy trình SageMaker mới có tênTrainingPipelineđã được tạo thành công.

-
- Mở giao diện người dùng SageMaker Studio, sau đó xem xét và chạy quy trình đào tạo.
- Sau khi chạy thành công quy trình đào tạo, hãy phê duyệt phiên bản mô hình đã đăng ký trong sổ đăng ký mô hình, sau đó chạy lại toàn bộ quy trình GitLab CI/CD.
- Xem lại đầu ra của kế hoạch Terraform trong
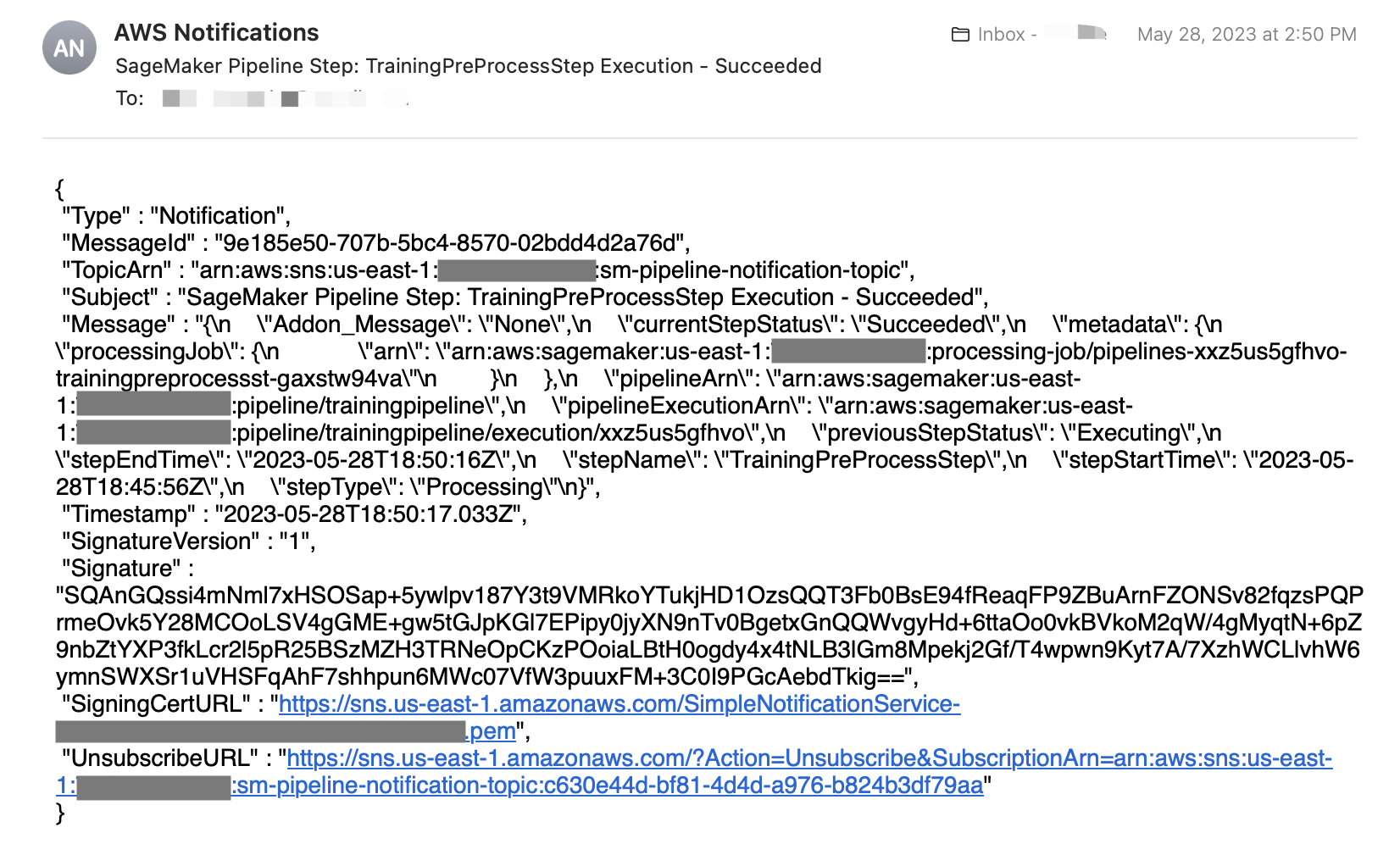
buildsân khấu. Phê duyệt hướng dẫnapplygiai đoạn trong quy trình GitLab CI/CD để tiếp tục chạy quy trình và ủy quyền cho Terraform tạo tài nguyên giám sát và thông báo trong tài khoản AWS của bạn. - Cuối cùng, hãy xem lại trạng thái chạy và đầu ra của quy trình SageMaker trong giao diện người dùng SageMaker Studio và kiểm tra email của bạn để biết thông báo thông báo, như minh họa trong ảnh chụp màn hình sau. Nội dung thư mặc định có định dạng JSON.
Đường dẫn SageMaker
Trong phần này, chúng tôi mô tả ba quy trình SageMaker trong quy trình làm việc MLOps.
Quy trình đào tạo
Quy trình đào tạo bao gồm các bước sau:
- Bước tiền xử lý, bao gồm chuyển đổi tính năng và mã hóa
- Bước kiểm tra chất lượng dữ liệu để tạo số liệu thống kê dữ liệu và đường cơ sở ràng buộc bằng cách sử dụng dữ liệu huấn luyện
- Bước đào tạo
- Bước đánh giá đào tạo
- Bước điều kiện để kiểm tra xem mô hình được đào tạo có đáp ứng ngưỡng hiệu suất được chỉ định trước hay không
- Bước đăng ký mô hình để đăng ký mô hình mới được đào tạo vào sổ đăng ký mô hình nếu mô hình được đào tạo đáp ứng ngưỡng hiệu suất yêu cầu
Cả hai skip_check_data_quality và register_new_baseline_data_quality các thông số được thiết lập để True trong lộ trình đào tạo. Các tham số này hướng dẫn quy trình bỏ qua việc kiểm tra chất lượng dữ liệu và chỉ tạo và đăng ký số liệu thống kê dữ liệu mới hoặc các đường cơ sở ràng buộc bằng cách sử dụng dữ liệu huấn luyện. Hình dưới đây mô tả quá trình chạy thành công của quy trình đào tạo.

Đường dẫn suy luận hàng loạt
Đường dẫn suy luận hàng loạt bao gồm các bước sau:
- Tạo mô hình từ phiên bản mô hình được phê duyệt mới nhất trong sổ đăng ký mô hình
- Bước tiền xử lý, bao gồm chuyển đổi tính năng và mã hóa
- Bước suy luận hàng loạt
- Bước tiền xử lý kiểm tra chất lượng dữ liệu, tạo một tệp CSV mới chứa cả dữ liệu đầu vào và dự đoán mô hình sẽ được sử dụng để kiểm tra chất lượng dữ liệu
- Bước kiểm tra chất lượng dữ liệu, kiểm tra dữ liệu đầu vào dựa trên số liệu thống kê cơ sở và các ràng buộc liên quan đến mô hình đã đăng ký
- Bước điều kiện để kiểm tra xem dữ liệu thực tế có sẵn hay không. Nếu có sẵn dữ liệu thực tế thì bước kiểm tra chất lượng mô hình sẽ được thực hiện
- Bước tính toán chất lượng mô hình, tính toán hiệu suất mô hình dựa trên nhãn chân lý cơ bản
Cả hai skip_check_data_quality và register_new_baseline_data_quality các thông số được thiết lập để False trong đường dẫn suy luận. Các tham số này hướng dẫn quy trình thực hiện kiểm tra chất lượng dữ liệu bằng cách sử dụng đường cơ sở ràng buộc hoặc thống kê dữ liệu được liên kết với mô hình đã đăng ký (supplied_baseline_statistics_data_quality và supplied_baseline_constraints_data_quality) và bỏ qua việc tạo hoặc đăng ký số liệu thống kê dữ liệu mới và các đường cơ sở ràng buộc trong quá trình suy luận. Hình dưới đây minh họa quá trình chạy quy trình suy luận hàng loạt trong đó bước kiểm tra chất lượng dữ liệu không thành công do hiệu suất của mô hình trên dữ liệu suy luận kém. Trong trường hợp cụ thể này, quá trình đào tạo với quy trình HPO sẽ được kích hoạt tự động để tinh chỉnh mô hình.

Đào tạo với đường ống HPO
Quá trình đào tạo với đường ống HPO bao gồm các bước sau:
- Bước tiền xử lý (chuyển đổi và mã hóa tính năng)
- Bước kiểm tra chất lượng dữ liệu để tạo số liệu thống kê dữ liệu và đường cơ sở ràng buộc bằng cách sử dụng dữ liệu huấn luyện
- Bước điều chỉnh siêu tham số
- Bước đánh giá đào tạo
- Bước điều kiện để kiểm tra xem mô hình được đào tạo có đáp ứng ngưỡng chính xác được chỉ định trước hay không
- Bước đăng ký mô hình nếu mô hình được đào tạo tốt nhất đáp ứng ngưỡng chính xác yêu cầu
Cả hai skip_check_data_quality và register_new_baseline_data_quality các thông số được thiết lập để True trong quá trình đào tạo với đường ống HPO. Hình dưới đây mô tả quá trình đào tạo thành công với quy trình HPO.

Làm sạch
Hoàn thành các bước sau để dọn sạch tài nguyên của bạn:
- Sử dụng
destroygiai đoạn trong quy trình GitLab CI/CD để loại bỏ tất cả tài nguyên do Terraform cung cấp. - Sử dụng AWS CLI để và tẩy mọi quy trình còn lại được tạo bởi tập lệnh Python.
- Tùy chọn xóa các tài nguyên AWS khác như nhóm S3 hoặc vai trò IAM được tạo bên ngoài quy trình CI/CD.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách doanh nghiệp có thể tạo quy trình làm việc MLOps cho công việc suy luận hàng loạt bằng Amazon SageMaker, Amazon EventBridge, AWS Lambda, Amazon SNS, HashiCorp Terraform và GitLab CI/CD. Quy trình làm việc được trình bày tự động hóa việc giám sát dữ liệu và mô hình, đào tạo lại mô hình cũng như chạy công việc hàng loạt, lập phiên bản mã và cung cấp cơ sở hạ tầng. Điều này có thể dẫn đến giảm đáng kể độ phức tạp và chi phí duy trì công việc suy luận hàng loạt trong sản xuất. Để biết thêm thông tin về chi tiết triển khai, hãy xem lại Repo GitHub.
Về các tác giả
 Hasan Shojaei là Nhà khoa học dữ liệu cấp cao của Dịch vụ chuyên nghiệp AWS, nơi ông giúp khách hàng thuộc các ngành khác nhau như thể thao, bảo hiểm và dịch vụ tài chính giải quyết các thách thức kinh doanh của họ thông qua việc sử dụng dữ liệu lớn, máy học và công nghệ đám mây. Trước vai trò này, Hasan đã lãnh đạo nhiều sáng kiến phát triển các kỹ thuật lập mô hình dựa trên dữ liệu và dựa trên vật lý mới cho các công ty năng lượng hàng đầu. Ngoài công việc, Hasan đam mê sách, đi bộ đường dài, chụp ảnh và lịch sử.
Hasan Shojaei là Nhà khoa học dữ liệu cấp cao của Dịch vụ chuyên nghiệp AWS, nơi ông giúp khách hàng thuộc các ngành khác nhau như thể thao, bảo hiểm và dịch vụ tài chính giải quyết các thách thức kinh doanh của họ thông qua việc sử dụng dữ liệu lớn, máy học và công nghệ đám mây. Trước vai trò này, Hasan đã lãnh đạo nhiều sáng kiến phát triển các kỹ thuật lập mô hình dựa trên dữ liệu và dựa trên vật lý mới cho các công ty năng lượng hàng đầu. Ngoài công việc, Hasan đam mê sách, đi bộ đường dài, chụp ảnh và lịch sử.
 Lưu Văn Tâm là Kiến trúc sư cơ sở hạ tầng đám mây cấp cao. Wenxin tư vấn cho các công ty doanh nghiệp về cách đẩy nhanh việc áp dụng đám mây và hỗ trợ những đổi mới của họ trên đám mây. Anh ấy là người yêu thú cưng và đam mê trượt tuyết và du lịch.
Lưu Văn Tâm là Kiến trúc sư cơ sở hạ tầng đám mây cấp cao. Wenxin tư vấn cho các công ty doanh nghiệp về cách đẩy nhanh việc áp dụng đám mây và hỗ trợ những đổi mới của họ trên đám mây. Anh ấy là người yêu thú cưng và đam mê trượt tuyết và du lịch.
 Vivek Lakshmanan là Kỹ sư máy học tại Amazon. Anh có bằng Thạc sĩ về Kỹ thuật phần mềm với chuyên ngành Khoa học dữ liệu và có nhiều năm kinh nghiệm làm MLE. Vivek rất hào hứng với việc áp dụng các công nghệ tiên tiến và xây dựng các giải pháp AI/ML cho khách hàng trên đám mây. Anh ấy đam mê Thống kê, NLP và Khả năng giải thích mô hình trong AI/ML. Trong thời gian rảnh rỗi, anh thích chơi cricket và tham gia các chuyến đi đường trường.
Vivek Lakshmanan là Kỹ sư máy học tại Amazon. Anh có bằng Thạc sĩ về Kỹ thuật phần mềm với chuyên ngành Khoa học dữ liệu và có nhiều năm kinh nghiệm làm MLE. Vivek rất hào hứng với việc áp dụng các công nghệ tiên tiến và xây dựng các giải pháp AI/ML cho khách hàng trên đám mây. Anh ấy đam mê Thống kê, NLP và Khả năng giải thích mô hình trong AI/ML. Trong thời gian rảnh rỗi, anh thích chơi cricket và tham gia các chuyến đi đường trường.
 Andy Cracchiolo là Kiến trúc sư cơ sở hạ tầng đám mây. Với hơn 15 năm kinh nghiệm trong lĩnh vực cơ sở hạ tầng CNTT, Andy là một chuyên gia CNTT thành đạt và hướng đến kết quả. Ngoài việc tối ưu hóa cơ sở hạ tầng, hoạt động và tự động hóa CNTT, Andy còn có thành tích đã được chứng minh trong việc phân tích hoạt động CNTT, xác định những điểm không nhất quán và triển khai các cải tiến quy trình nhằm tăng hiệu quả, giảm chi phí và tăng lợi nhuận.
Andy Cracchiolo là Kiến trúc sư cơ sở hạ tầng đám mây. Với hơn 15 năm kinh nghiệm trong lĩnh vực cơ sở hạ tầng CNTT, Andy là một chuyên gia CNTT thành đạt và hướng đến kết quả. Ngoài việc tối ưu hóa cơ sở hạ tầng, hoạt động và tự động hóa CNTT, Andy còn có thành tích đã được chứng minh trong việc phân tích hoạt động CNTT, xác định những điểm không nhất quán và triển khai các cải tiến quy trình nhằm tăng hiệu quả, giảm chi phí và tăng lợi nhuận.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- ChartPrime. Nâng cao trò chơi giao dịch của bạn với ChartPrime. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/mlops-for-batch-inference-with-model-monitoring-and-retraining-using-amazon-sagemaker-hashicorp-terraform-and-gitlab-ci-cd/

