Xưởng sản xuất Amazon SageMaker cung cấp giải pháp được quản lý hoàn toàn cho các nhà khoa học dữ liệu để xây dựng, đào tạo và triển khai các mô hình học máy (ML) một cách tương tác. Trong quá trình thực hiện các nhiệm vụ ML của mình, các nhà khoa học dữ liệu thường bắt đầu quy trình làm việc của mình bằng cách khám phá các nguồn dữ liệu có liên quan và kết nối với chúng. Sau đó, họ sử dụng SQL để khám phá, phân tích, trực quan hóa và tích hợp dữ liệu từ nhiều nguồn khác nhau trước khi sử dụng dữ liệu đó trong quá trình đào tạo và suy luận ML của mình. Trước đây, các nhà khoa học dữ liệu thường phải sử dụng nhiều công cụ để hỗ trợ SQL trong quy trình làm việc của họ, điều này cản trở năng suất.
Chúng tôi vui mừng thông báo rằng sổ ghi chép JupyterLab trong SageMaker Studio hiện có hỗ trợ tích hợp sẵn cho SQL. Các nhà khoa học dữ liệu hiện có thể:
- Kết nối với các dịch vụ dữ liệu phổ biến bao gồm amazon Athena, Amazon RedShift, Vùng dữ liệu Amazonvà Bông tuyết trực tiếp trong sổ ghi chép
- Duyệt và tìm kiếm cơ sở dữ liệu, lược đồ, bảng và dạng xem cũng như xem trước dữ liệu trong giao diện sổ ghi chép
- Trộn mã SQL và Python trong cùng một sổ ghi chép để khám phá và chuyển đổi dữ liệu hiệu quả để sử dụng trong các dự án ML
- Sử dụng các tính năng nâng cao năng suất dành cho nhà phát triển như hoàn thành lệnh SQL, hỗ trợ định dạng mã và tô sáng cú pháp để giúp tăng tốc quá trình phát triển mã và cải thiện năng suất tổng thể của nhà phát triển
Ngoài ra, quản trị viên có thể quản lý an toàn các kết nối đến các dịch vụ dữ liệu này, cho phép các nhà khoa học dữ liệu truy cập vào dữ liệu được ủy quyền mà không cần quản lý thông tin xác thực theo cách thủ công.
Trong bài đăng này, chúng tôi sẽ hướng dẫn bạn cách thiết lập tính năng này trong SageMaker Studio và hướng dẫn bạn các khả năng khác nhau của tính năng này. Sau đó, chúng tôi sẽ trình bày cách bạn có thể nâng cao trải nghiệm SQL trong sổ tay bằng cách sử dụng khả năng Chuyển văn bản sang SQL do các mô hình ngôn ngữ lớn (LLM) nâng cao cung cấp để viết các truy vấn SQL phức tạp bằng cách sử dụng văn bản ngôn ngữ tự nhiên làm đầu vào. Cuối cùng, để cho phép nhiều đối tượng người dùng hơn tạo truy vấn SQL từ đầu vào ngôn ngữ tự nhiên trong sổ ghi chép của họ, chúng tôi sẽ chỉ cho bạn cách triển khai các mô hình Chuyển văn bản sang SQL này bằng cách sử dụng Amazon SageMaker điểm cuối.
Tổng quan về giải pháp
Với tính năng tích hợp SQL của sổ ghi chép SageMaker Studio JupyterLab, giờ đây bạn có thể kết nối với các nguồn dữ liệu phổ biến như Snowflake, Athena, Amazon Redshift và Amazon DataZone. Tính năng mới này cho phép bạn thực hiện nhiều chức năng khác nhau.
Ví dụ: bạn có thể khám phá trực quan các nguồn dữ liệu như cơ sở dữ liệu, bảng và lược đồ trực tiếp từ hệ sinh thái JupyterLab của mình. Nếu môi trường sổ ghi chép của bạn đang chạy trên SageMaker Distribution 1.6 trở lên, hãy tìm tiện ích mới ở bên trái giao diện JupyterLab của bạn. Sự bổ sung này giúp tăng cường khả năng truy cập và quản lý dữ liệu trong môi trường phát triển của bạn.
Nếu bạn hiện không sử dụng Bản phân phối SageMaker được đề xuất (1.5 trở xuống) hoặc trong môi trường tùy chỉnh, hãy tham khảo phụ lục để biết thêm thông tin.
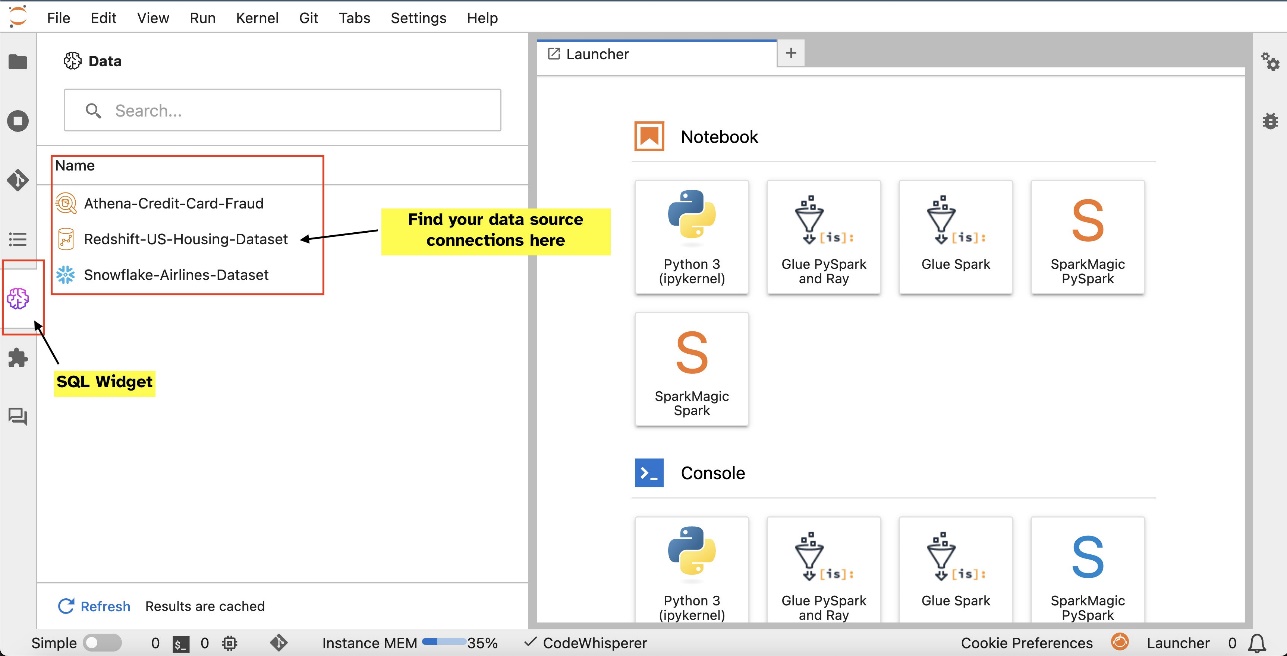
Sau khi thiết lập kết nối (được minh họa trong phần tiếp theo), bạn có thể liệt kê các kết nối dữ liệu, duyệt cơ sở dữ liệu và bảng cũng như kiểm tra lược đồ.
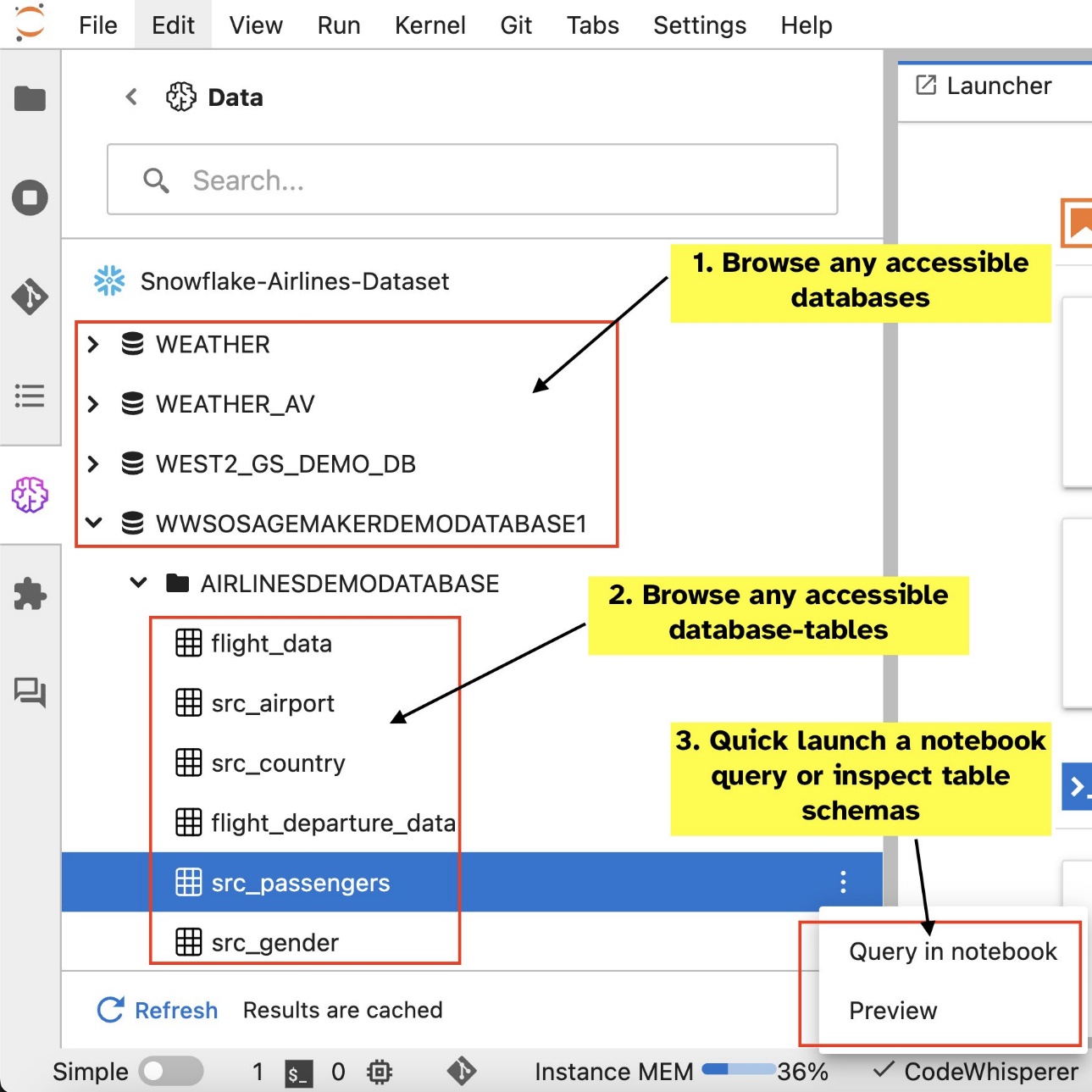
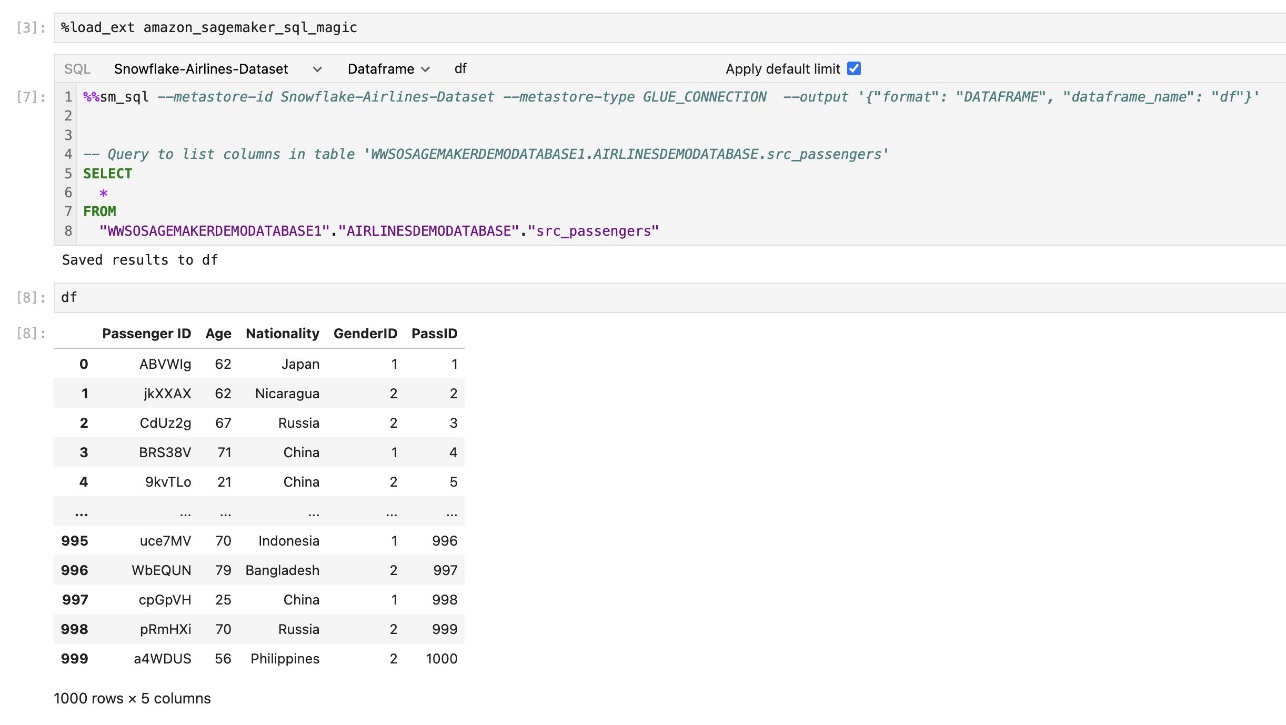
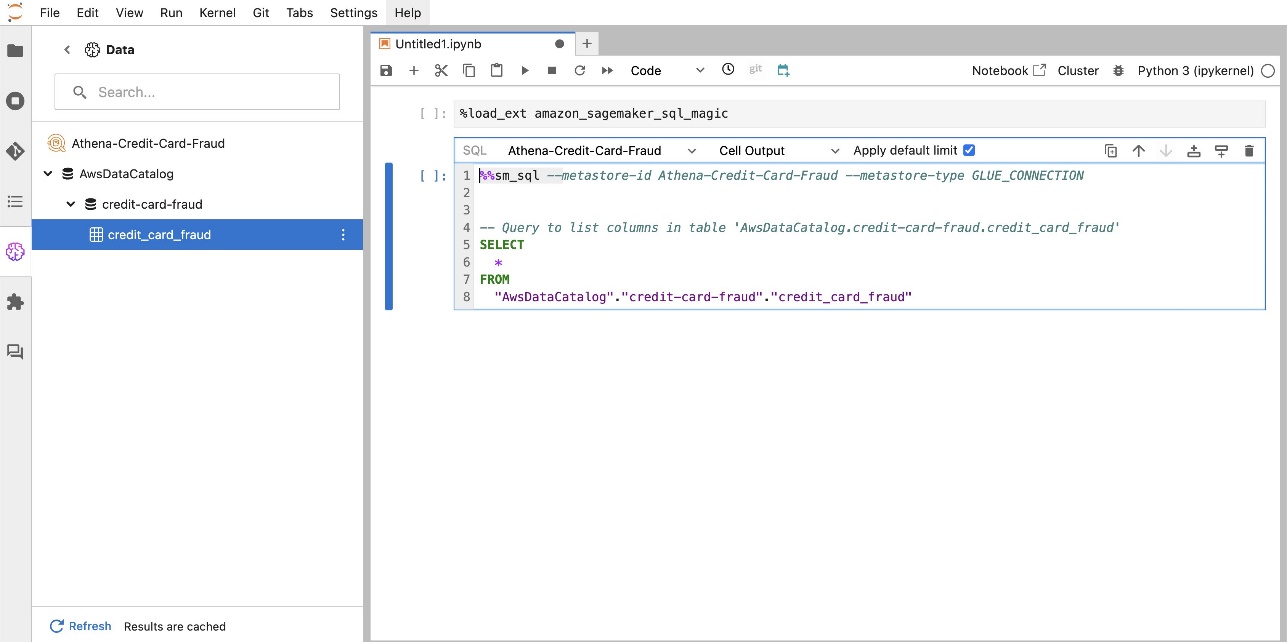
Tiện ích mở rộng SQL tích hợp của SageMaker Studio JupyterLab cũng cho phép bạn chạy các truy vấn SQL trực tiếp từ sổ ghi chép. Sổ ghi chép Jupyter có thể phân biệt giữa mã SQL và Python bằng cách sử dụng %%sm_sql lệnh ma thuật, phải được đặt ở đầu bất kỳ ô nào chứa mã SQL. Lệnh này báo hiệu cho JupyterLab rằng các hướng dẫn sau đây là lệnh SQL chứ không phải mã Python. Đầu ra của truy vấn có thể được hiển thị trực tiếp trong sổ ghi chép, tạo điều kiện tích hợp liền mạch các quy trình làm việc SQL và Python trong phân tích dữ liệu của bạn.
Đầu ra của truy vấn có thể được hiển thị trực quan dưới dạng bảng HTML, như minh họa trong ảnh chụp màn hình sau.

Chúng cũng có thể được viết vào một gấu trúc DataFrame.
Điều kiện tiên quyết
Đảm bảo bạn đã đáp ứng các điều kiện tiên quyết sau để sử dụng trải nghiệm SQL của sổ ghi chép SageMaker Studio:
- SageMaker Studio V2 – Đảm bảo bạn đang chạy phiên bản cập nhật nhất của Hồ sơ người dùng và miền SageMaker Studio. Nếu bạn hiện đang sử dụng SageMaker Studio Classic, hãy tham khảo Di chuyển từ Amazon SageMaker Studio Classic.
- Vai trò IAM – SageMaker yêu cầu một Quản lý truy cập và nhận dạng AWS (IAM) được chỉ định cho miền SageMaker Studio hoặc hồ sơ người dùng để quản lý quyền một cách hiệu quả. Có thể cần phải cập nhật vai trò thực thi để đưa vào tính năng duyệt dữ liệu và chạy SQL. Chính sách mẫu sau đây cho phép người dùng cấp, liệt kê và chạy Keo AWS, Athena, Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), Quản lý bí mật AWSvà tài nguyên Amazon Redshift:
- Không gian JupyterLab – Bạn cần quyền truy cập vào SageMaker Studio và JupyterLab Space đã cập nhật với Phân phối SageMaker phiên bản hình ảnh v1.6 trở lên. Nếu bạn đang sử dụng hình ảnh tùy chỉnh cho JupyterLab Spaces hoặc các phiên bản cũ hơn của SageMaker Distribution (v1.5 trở xuống), hãy tham khảo phụ lục để biết hướng dẫn cài đặt các gói và mô-đun cần thiết nhằm kích hoạt tính năng này trong môi trường của bạn. Để tìm hiểu thêm về SageMaker Studio JupyterLab Spaces, hãy tham khảo Tăng năng suất trên Amazon SageMaker Studio: Giới thiệu JupyterLab Spaces và các công cụ AI tổng hợp.
- Thông tin xác thực truy cập nguồn dữ liệu – Tính năng sổ ghi chép SageMaker Studio này yêu cầu quyền truy cập bằng tên người dùng và mật khẩu vào các nguồn dữ liệu như Snowflake và Amazon Redshift. Tạo quyền truy cập dựa trên tên người dùng và mật khẩu vào các nguồn dữ liệu này nếu bạn chưa có. Quyền truy cập dựa trên OAuth vào Snowflake không phải là một tính năng được hỗ trợ tại thời điểm viết bài này.
- Tải ma thuật SQL – Trước khi bạn chạy các truy vấn SQL từ ô sổ ghi chép Jupyter, điều cần thiết là phải tải tiện ích mở rộng ma thuật SQL. Sử dụng lệnh
%load_ext amazon_sagemaker_sql_magicđể kích hoạt tính năng này. Ngoài ra, bạn có thể chạy%sm_sql?lệnh để xem danh sách đầy đủ các tùy chọn được hỗ trợ để truy vấn từ một ô SQL. Các tùy chọn này bao gồm đặt giới hạn truy vấn mặc định là 1,000, chạy trích xuất đầy đủ và chèn các tham số truy vấn, cùng nhiều tùy chọn khác. Thiết lập này cho phép thao tác dữ liệu SQL linh hoạt và hiệu quả trực tiếp trong môi trường máy tính xách tay của bạn.
Tạo kết nối cơ sở dữ liệu
Khả năng duyệt và thực thi SQL tích hợp của SageMaker Studio được nâng cao nhờ các kết nối AWS Glue. Kết nối AWS Glue là đối tượng Danh mục dữ liệu AWS Glue lưu trữ dữ liệu cần thiết như thông tin xác thực đăng nhập, chuỗi URI và thông tin đám mây riêng ảo (VPC) cho các kho dữ liệu cụ thể. Các kết nối này được trình thu thập thông tin, công việc và điểm cuối phát triển của AWS Glue sử dụng để truy cập vào nhiều loại kho dữ liệu khác nhau. Bạn có thể sử dụng các kết nối này cho cả dữ liệu nguồn và dữ liệu đích, thậm chí sử dụng lại cùng một kết nối trên nhiều trình thu thập thông tin hoặc các công việc trích xuất, chuyển đổi và tải (ETL).
Để khám phá các nguồn dữ liệu SQL ở khung bên trái của SageMaker Studio, trước tiên bạn cần tạo đối tượng kết nối AWS Glue. Các kết nối này tạo điều kiện truy cập vào các nguồn dữ liệu khác nhau và cho phép bạn khám phá các thành phần dữ liệu sơ đồ của chúng.
Trong các phần sau, chúng ta sẽ tìm hiểu quy trình tạo trình kết nối AWS Glue dành riêng cho SQL. Điều này sẽ cho phép bạn truy cập, xem và khám phá các tập dữ liệu trên nhiều kho dữ liệu khác nhau. Để biết thêm thông tin chi tiết về kết nối AWS Glue, hãy tham khảo Kết nối với dữ liệu.
Tạo kết nối AWS Glue
Cách duy nhất để đưa nguồn dữ liệu vào SageMaker Studio là sử dụng kết nối AWS Glue. Bạn cần tạo kết nối AWS Glue với các loại kết nối cụ thể. Theo văn bản này, cơ chế được hỗ trợ duy nhất để tạo các kết nối này là sử dụng Giao diện dòng lệnh AWS (AWS CLI).
Tệp JSON định nghĩa kết nối
Khi kết nối với các nguồn dữ liệu khác nhau trong AWS Glue, trước tiên bạn phải tạo tệp JSON xác định thuộc tính kết nối—được gọi là tập tin định nghĩa kết nối. Tệp này rất quan trọng để thiết lập kết nối AWS Glue và phải nêu chi tiết tất cả các cấu hình cần thiết để truy cập nguồn dữ liệu. Để có các phương pháp bảo mật tốt nhất, bạn nên sử dụng Trình quản lý bí mật để lưu trữ thông tin nhạy cảm như mật khẩu một cách an toàn. Trong khi đó, các thuộc tính kết nối khác có thể được quản lý trực tiếp thông qua kết nối AWS Glue. Cách tiếp cận này đảm bảo rằng thông tin xác thực nhạy cảm được bảo vệ trong khi vẫn giúp cấu hình kết nối có thể truy cập và quản lý được.
Sau đây là ví dụ về định nghĩa kết nối JSON:
Khi thiết lập kết nối AWS Glue cho nguồn dữ liệu của bạn, có một số nguyên tắc quan trọng cần tuân theo để cung cấp cả chức năng và bảo mật:
- Chuỗi thuộc tính - Trong
PythonPropertieskey, hãy đảm bảo tất cả các thuộc tính đều được cặp khóa-giá trị được xâu chuỗi. Điều quan trọng là phải thoát dấu ngoặc kép đúng cách bằng cách sử dụng ký tự dấu gạch chéo ngược () khi cần thiết. Điều này giúp duy trì định dạng chính xác và tránh lỗi cú pháp trong JSON của bạn. - Xử lý thông tin nhạy cảm – Mặc dù có thể bao gồm tất cả các thuộc tính kết nối bên trong
PythonProperties, bạn không nên đưa trực tiếp các chi tiết nhạy cảm như mật khẩu vào các thuộc tính này. Thay vào đó, hãy sử dụng Trình quản lý bí mật để xử lý thông tin nhạy cảm. Cách tiếp cận này bảo vệ dữ liệu nhạy cảm của bạn bằng cách lưu trữ dữ liệu đó trong môi trường được kiểm soát và mã hóa, cách xa các tệp cấu hình chính.
Tạo kết nối AWS Glue bằng AWS CLI
Sau khi đưa tất cả các trường cần thiết vào tệp JSON định nghĩa kết nối, bạn đã sẵn sàng thiết lập kết nối AWS Glue cho nguồn dữ liệu của mình bằng AWS CLI và lệnh sau:
Lệnh này khởi tạo kết nối AWS Glue mới dựa trên thông số kỹ thuật được nêu chi tiết trong tệp JSON của bạn. Sau đây là bảng phân tích nhanh về các thành phần lệnh:
- -vùng đất – Phần này chỉ định Khu vực AWS nơi kết nối AWS Glue của bạn sẽ được tạo. Điều quan trọng là chọn Khu vực nơi đặt nguồn dữ liệu và các dịch vụ khác của bạn để giảm thiểu độ trễ và tuân thủ các yêu cầu về nơi lưu trữ dữ liệu.
- –cli-input-json file:///path/to/file/connection/def định/file.json – Tham số này hướng dẫn AWS CLI đọc cấu hình đầu vào từ tệp cục bộ chứa định nghĩa kết nối của bạn ở định dạng JSON.
Bạn sẽ có thể tạo kết nối AWS Glue bằng lệnh AWS CLI trước đó từ thiết bị đầu cuối Studio JupyterLab của mình. trên Tập tin menu, chọn Mới và Thiết bị đầu cuối.

Nếu create-connection lệnh chạy thành công, bạn sẽ thấy nguồn dữ liệu của mình được liệt kê trong ngăn trình duyệt SQL. Nếu bạn không thấy nguồn dữ liệu của mình được liệt kê, hãy chọn Refresh để cập nhật bộ đệm.

Tạo kết nối Bông tuyết
Trong phần này, chúng tôi tập trung vào việc tích hợp nguồn dữ liệu Snowflake với SageMaker Studio. Việc tạo tài khoản, cơ sở dữ liệu và kho hàng của Snowflake nằm ngoài phạm vi của bài đăng này. Để bắt đầu với Snowflake, hãy tham khảo Hướng dẫn sử dụng bông tuyết. Trong bài đăng này, chúng tôi tập trung vào việc tạo tệp JSON định nghĩa Bông tuyết và thiết lập kết nối nguồn dữ liệu Bông tuyết bằng AWS Glue.
Tạo bí mật Trình quản lý bí mật
Bạn có thể kết nối với tài khoản Snowflake của mình bằng cách sử dụng ID người dùng và mật khẩu hoặc sử dụng khóa riêng. Để kết nối bằng ID người dùng và mật khẩu, bạn cần lưu trữ an toàn thông tin xác thực của mình trong Trình quản lý bí mật. Như đã đề cập trước đây, mặc dù có thể nhúng thông tin này trong PythonProperties nhưng không nên lưu trữ thông tin nhạy cảm ở định dạng văn bản thuần túy. Luôn đảm bảo rằng dữ liệu nhạy cảm được xử lý an toàn để tránh các rủi ro bảo mật tiềm ẩn.
Để lưu trữ thông tin trong Trình quản lý bí mật, hãy hoàn thành các bước sau:
- Trên bảng điều khiển Secrets Manager, chọn Lưu trữ một bí mật mới.
- Trong Loại bí mật, chọn Loại bí mật khác.
- Đối với cặp khóa-giá trị, chọn Văn bản thô và nhập như sau:
- Nhập tên cho bí mật của bạn, chẳng hạn như
sm-sql-snowflake-secret. - Các cài đặt khác để mặc định hoặc tùy chỉnh nếu cần.
- Tạo bí mật.
Tạo kết nối AWS Glue cho Snowflake
Như đã thảo luận trước đó, kết nối AWS Glue rất cần thiết để truy cập mọi kết nối từ SageMaker Studio. Bạn có thể tìm thấy một danh sách tất cả các thuộc tính kết nối được hỗ trợ cho Snowflake. Sau đây là định nghĩa kết nối mẫu JSON cho Snowflake. Thay thế các giá trị giữ chỗ bằng các giá trị thích hợp trước khi lưu vào đĩa:
Để tạo đối tượng kết nối AWS Glue cho nguồn dữ liệu Snowflake, hãy sử dụng lệnh sau:
Lệnh này tạo kết nối nguồn dữ liệu Snowflake mới trong ngăn trình duyệt SQL có thể duyệt được và bạn có thể chạy truy vấn SQL dựa trên kết nối đó từ ô sổ ghi chép JupyterLab của mình.
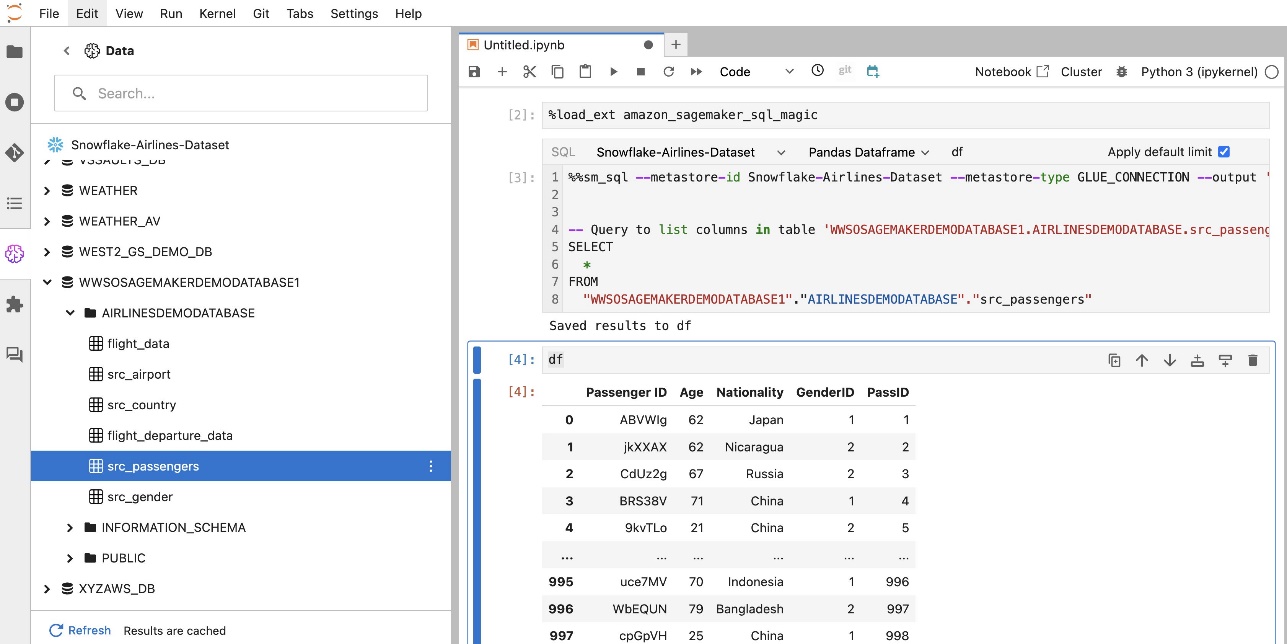
Tạo kết nối Amazon Redshift
Amazon Redshift là dịch vụ kho dữ liệu quy mô petabyte, được quản lý toàn phần, giúp đơn giản hóa và giảm chi phí phân tích tất cả dữ liệu của bạn bằng SQL tiêu chuẩn. Quy trình tạo kết nối Amazon Redshift phản ánh chặt chẽ quy trình đối với kết nối Snowflake.
Tạo bí mật Trình quản lý bí mật
Tương tự như thiết lập Snowflake, để kết nối với Amazon Redshift bằng ID người dùng và mật khẩu, bạn cần lưu trữ an toàn thông tin bí mật trong Secrets Manager. Hoàn thành các bước sau:
- Trên bảng điều khiển Secrets Manager, chọn Lưu trữ một bí mật mới.
- Trong Loại bí mật, chọn Thông tin xác thực cho cụm Amazon Redshift.
- Nhập thông tin xác thực được sử dụng để đăng nhập nhằm truy cập Amazon Redshift dưới dạng nguồn dữ liệu.
- Chọn cụm Redshift được liên kết với các bí mật.
- Nhập tên cho bí mật, chẳng hạn như
sm-sql-redshift-secret. - Các cài đặt khác để mặc định hoặc tùy chỉnh nếu cần.
- Tạo bí mật.
Bằng cách làm theo các bước này, bạn đảm bảo thông tin đăng nhập kết nối của mình được xử lý an toàn, sử dụng các tính năng bảo mật mạnh mẽ của AWS để quản lý dữ liệu nhạy cảm một cách hiệu quả.
Tạo kết nối AWS Glue cho Amazon Redshift
Để thiết lập kết nối với Amazon Redshift bằng định nghĩa JSON, hãy điền vào các trường cần thiết và lưu cấu hình JSON sau vào đĩa:
Để tạo đối tượng kết nối AWS Glue cho nguồn dữ liệu Redshift, hãy sử dụng lệnh AWS CLI sau:
Lệnh này tạo kết nối trong AWS Glue được liên kết với nguồn dữ liệu Redshift của bạn. Nếu lệnh chạy thành công, bạn sẽ có thể xem nguồn dữ liệu Redshift của mình trong sổ ghi chép SageMaker Studio JupyterLab, sẵn sàng để chạy truy vấn SQL và thực hiện phân tích dữ liệu.

Tạo kết nối Athena
Athena là dịch vụ truy vấn SQL được quản lý hoàn toàn của AWS, cho phép phân tích dữ liệu được lưu trữ trong Amazon S3 bằng SQL tiêu chuẩn. Để thiết lập kết nối Athena làm nguồn dữ liệu trong trình duyệt SQL của sổ ghi chép JupyterLab, bạn cần tạo JSON định nghĩa kết nối mẫu Athena. Cấu trúc JSON sau đây định cấu hình các chi tiết cần thiết để kết nối với Athena, chỉ định danh mục dữ liệu, thư mục chạy thử S3 và Khu vực:
Để tạo đối tượng kết nối AWS Glue cho nguồn dữ liệu Athena, hãy sử dụng lệnh AWS CLI sau:
Nếu lệnh thành công, bạn sẽ có thể truy cập danh mục và bảng dữ liệu Athena trực tiếp từ trình duyệt SQL trong sổ ghi chép SageMaker Studio JupyterLab của mình.
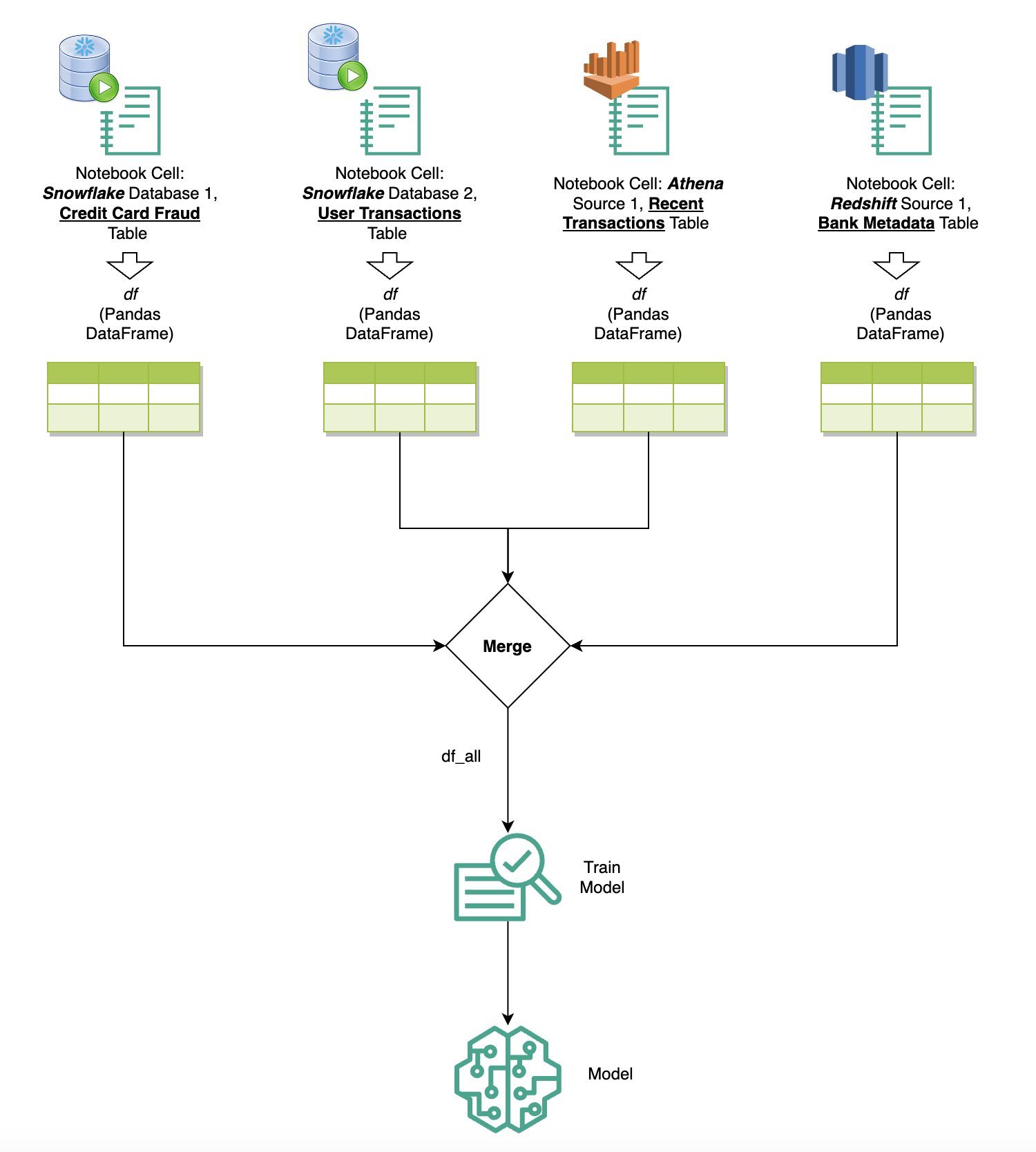
Truy vấn dữ liệu từ nhiều nguồn
Nếu bạn có nhiều nguồn dữ liệu được tích hợp vào SageMaker Studio thông qua trình duyệt SQL tích hợp và tính năng SQL của sổ ghi chép, bạn có thể nhanh chóng chạy truy vấn và chuyển đổi dễ dàng giữa các phần phụ trợ nguồn dữ liệu trong các ô tiếp theo trong sổ ghi chép. Khả năng này cho phép chuyển đổi liền mạch giữa các cơ sở dữ liệu hoặc nguồn dữ liệu khác nhau trong quy trình phân tích của bạn.
Bạn có thể chạy truy vấn dựa trên bộ sưu tập phụ trợ nguồn dữ liệu đa dạng và đưa kết quả trực tiếp vào không gian Python để phân tích hoặc trực quan hóa thêm. Điều này được tạo điều kiện thuận lợi bởi %%sm_sql lệnh ma thuật có sẵn trong sổ ghi chép SageMaker Studio. Để xuất kết quả truy vấn SQL của bạn vào DataFrame của gấu trúc, có hai tùy chọn:
- Từ thanh công cụ ô sổ ghi chép của bạn, chọn loại đầu ra Khung dữ liệu và đặt tên cho biến DataFrame của bạn
- Nối tham số sau vào
%%sm_sqlchỉ huy:
Sơ đồ sau đây minh họa quy trình công việc này và trình bày cách bạn có thể dễ dàng chạy truy vấn trên nhiều nguồn khác nhau trong các ô sổ ghi chép tiếp theo, cũng như huấn luyện mô hình SageMaker bằng cách sử dụng các công việc đào tạo hoặc trực tiếp trong sổ ghi chép bằng điện toán cục bộ. Ngoài ra, sơ đồ nêu bật cách tích hợp SQL tích hợp của SageMaker Studio giúp đơn giản hóa các quy trình trích xuất và xây dựng trực tiếp trong môi trường quen thuộc của ô sổ ghi chép JupyterLab.
Chuyển văn bản sang SQL: Sử dụng ngôn ngữ tự nhiên để nâng cao khả năng soạn thảo truy vấn
SQL là một ngôn ngữ phức tạp đòi hỏi sự hiểu biết về cơ sở dữ liệu, bảng, cú pháp và siêu dữ liệu. Ngày nay, trí tuệ nhân tạo tổng quát (AI) có thể cho phép bạn viết các truy vấn SQL phức tạp mà không yêu cầu trải nghiệm SQL chuyên sâu. Sự tiến bộ của LLM đã tác động đáng kể đến việc tạo SQL dựa trên xử lý ngôn ngữ tự nhiên (NLP), cho phép tạo các truy vấn SQL chính xác từ các mô tả ngôn ngữ tự nhiên—một kỹ thuật được gọi là Chuyển văn bản sang SQL. Tuy nhiên, điều cần thiết là phải thừa nhận sự khác biệt cố hữu giữa ngôn ngữ của con người và SQL. Ngôn ngữ của con người đôi khi có thể mơ hồ hoặc không chính xác, trong khi SQL có cấu trúc, rõ ràng và rõ ràng. Việc thu hẹp khoảng cách này và chuyển đổi chính xác ngôn ngữ tự nhiên thành các truy vấn SQL có thể là một thách thức ghê gớm. Khi được cung cấp những lời nhắc thích hợp, LLM có thể giúp thu hẹp khoảng cách này bằng cách hiểu ý định đằng sau ngôn ngữ của con người và tạo ra các truy vấn SQL chính xác tương ứng.
Với việc phát hành tính năng truy vấn SQL trong sổ ghi chép của SageMaker Studio, SageMaker Studio giúp việc kiểm tra cơ sở dữ liệu và lược đồ cũng như tạo, chạy và gỡ lỗi các truy vấn SQL trở nên đơn giản mà không cần rời khỏi IDE sổ ghi chép Jupyter. Phần này khám phá cách khả năng Chuyển văn bản sang SQL của LLM nâng cao có thể tạo điều kiện thuận lợi cho việc tạo truy vấn SQL bằng ngôn ngữ tự nhiên trong sổ ghi chép Jupyter. Chúng tôi sử dụng mô hình Chuyển văn bản thành SQL tiên tiến defog/sqlcoder-7b-2 kết hợp với Jupyter AI, một trợ lý AI tổng quát được thiết kế đặc biệt cho sổ ghi chép Jupyter, để tạo các truy vấn SQL phức tạp từ ngôn ngữ tự nhiên. Bằng cách sử dụng mô hình nâng cao này, chúng tôi có thể tạo các truy vấn SQL phức tạp một cách dễ dàng và hiệu quả bằng ngôn ngữ tự nhiên, từ đó nâng cao trải nghiệm SQL của chúng tôi trong sổ ghi chép.
Tạo mẫu máy tính xách tay bằng cách sử dụng Hugging Face Hub
Để bắt đầu tạo mẫu, bạn cần những điều sau:
- Mã GitHub – Mã được trình bày trong phần này có sẵn ở phần sau Repo GitHub và bằng cách tham khảo ví dụ máy tính xách tay.
- Không gian JupyterLab – Quyền truy cập vào SageMaker Studio JupyterLab Space được hỗ trợ bởi các phiên bản dựa trên GPU là điều cần thiết. Cho
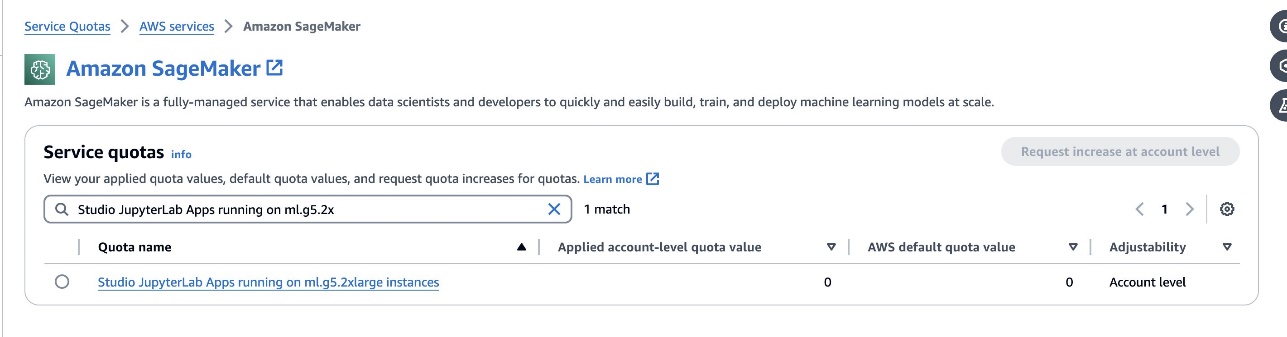
defog/sqlcoder-7b-2mô hình, nên sử dụng mô hình tham số 7B, sử dụng phiên bản ml.g5.2xlarge. Các lựa chọn thay thế nhưdefog/sqlcoder-70b-alpha hoặcdefog/sqlcoder-34b-alphacũng khả thi để chuyển đổi ngôn ngữ tự nhiên sang SQL, nhưng có thể cần các loại phiên bản lớn hơn để tạo nguyên mẫu. Đảm bảo bạn có hạn ngạch để khởi chạy một phiên bản được GPU hỗ trợ bằng cách điều hướng đến bảng điều khiển Định mức dịch vụ, tìm kiếm SageMaker và tìm kiếmStudio JupyterLab Apps running on <instance type>.
Khởi chạy Không gian JupyterLab được hỗ trợ bởi GPU mới từ SageMaker Studio của bạn. Bạn nên tạo Không gian JupyterLab mới có ít nhất 75 GB dung lượng Cửa hàng đàn hồi Amazon (Amazon EBS) lưu trữ cho mô hình tham số 7B.

- Trung tâm khuôn mặt ôm – Nếu miền SageMaker Studio của bạn có quyền truy cập để tải xuống các mô hình từ Trung tâm khuôn mặt ôm, bạn có thể dùng
AutoModelForCausalLMlớp học từ ôm mặt/máy biến áp để tự động tải xuống các mô hình và ghim chúng vào GPU cục bộ của bạn. Trọng số mô hình sẽ được lưu trữ trong bộ đệm của máy cục bộ của bạn. Xem đoạn mã sau:
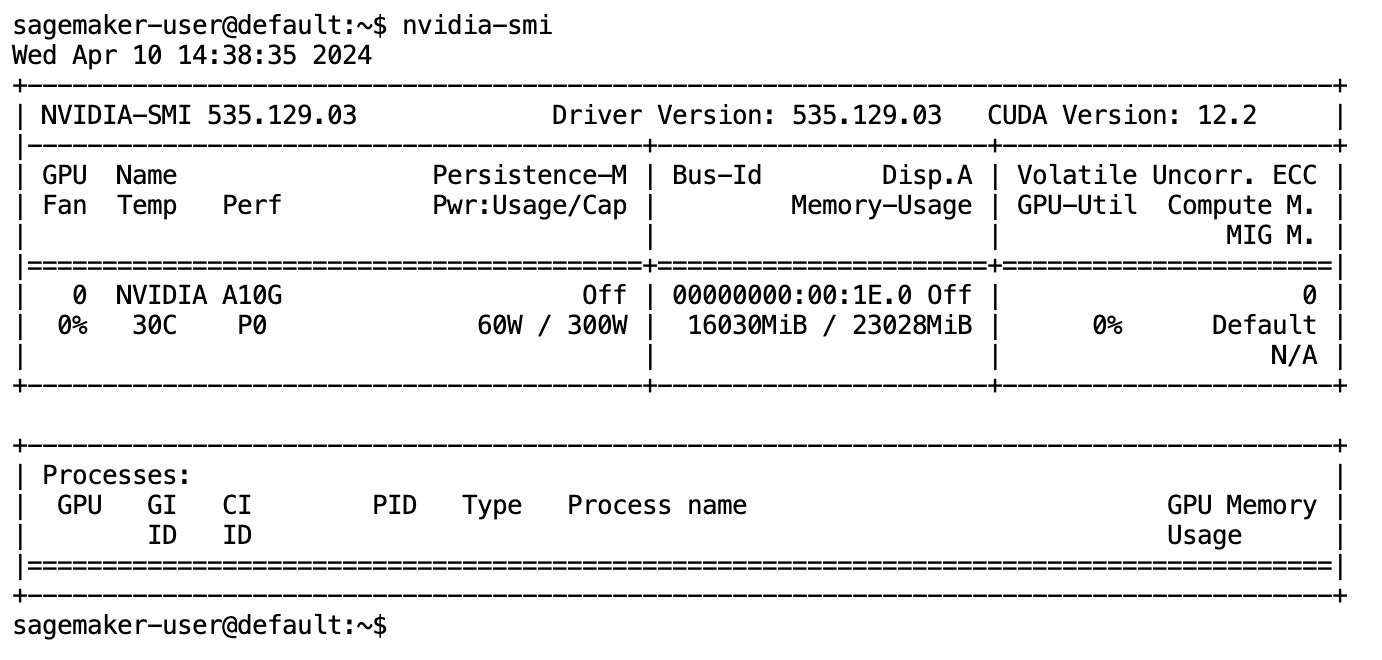
Sau khi mô hình đã được tải xuống đầy đủ và tải vào bộ nhớ, bạn sẽ thấy mức sử dụng GPU trên máy cục bộ của mình tăng lên. Điều này cho thấy mô hình đang tích cực sử dụng tài nguyên GPU cho các tác vụ tính toán. Bạn có thể xác minh điều này trong không gian JupyterLab của riêng mình bằng cách chạy nvidia-smi (để hiển thị một lần) hoặc nvidia-smi —loop=1 (lặp lại mỗi giây) từ thiết bị đầu cuối JupyterLab của bạn.
Các mô hình chuyển văn bản sang SQL vượt trội trong việc hiểu ý định và ngữ cảnh yêu cầu của người dùng, ngay cả khi ngôn ngữ được sử dụng là ngôn ngữ đàm thoại hoặc mơ hồ. Quá trình này bao gồm việc dịch các đầu vào ngôn ngữ tự nhiên thành các thành phần lược đồ cơ sở dữ liệu chính xác, chẳng hạn như tên bảng, tên cột và điều kiện. Tuy nhiên, mô hình Chuyển văn bản sang SQL sẵn có về bản chất sẽ không biết cấu trúc kho dữ liệu của bạn, các lược đồ cơ sở dữ liệu cụ thể hoặc có thể diễn giải chính xác nội dung của bảng chỉ dựa trên tên cột. Để sử dụng hiệu quả các mô hình này nhằm tạo ra các truy vấn SQL thực tế và hiệu quả từ ngôn ngữ tự nhiên, cần phải điều chỉnh mô hình tạo văn bản SQL cho phù hợp với lược đồ cơ sở dữ liệu kho cụ thể của bạn. Sự thích ứng này được tạo điều kiện thông qua việc sử dụng lời nhắc LLM. Sau đây là mẫu lời nhắc được đề xuất cho mô hình Chuyển văn bản thành SQL defog/sqlcode-7b-2, được chia thành bốn phần:
- Nhiệm vụ – Phần này cần chỉ rõ một nhiệm vụ cấp cao mà mô hình sẽ hoàn thành. Nó phải bao gồm loại chương trình phụ trợ cơ sở dữ liệu (chẳng hạn như Amazon RDS, PostgreSQL hoặc Amazon Redshift) để giúp mô hình nhận biết mọi khác biệt về sắc thái cú pháp có thể ảnh hưởng đến việc tạo truy vấn SQL cuối cùng.
- Hướng Dẫn – Phần này sẽ xác định ranh giới nhiệm vụ và nhận thức miền cho mô hình và có thể bao gồm một vài ví dụ ngắn gọn để hướng dẫn mô hình tạo các truy vấn SQL được tinh chỉnh.
- Lược đồ cơ sở dữ liệu – Phần này sẽ nêu chi tiết các lược đồ cơ sở dữ liệu kho của bạn, phác thảo mối quan hệ giữa các bảng và cột để hỗ trợ mô hình hiểu cấu trúc cơ sở dữ liệu.
- Trả lời – Phần này dành riêng cho mô hình xuất phản hồi truy vấn SQL sang đầu vào ngôn ngữ tự nhiên.
Một ví dụ về lược đồ cơ sở dữ liệu và lời nhắc được sử dụng trong phần này có sẵn trong Kho lưu trữ GitHub.
Kỹ thuật nhắc nhở không chỉ là hình thành các câu hỏi hoặc tuyên bố; đó là một nghệ thuật và khoa học mang nhiều sắc thái có tác động đáng kể đến chất lượng tương tác với mô hình AI. Cách bạn tạo lời nhắc có thể ảnh hưởng sâu sắc đến bản chất và tính hữu ích của phản hồi của AI. Kỹ năng này đóng vai trò then chốt trong việc tối đa hóa tiềm năng tương tác của AI, đặc biệt là trong các nhiệm vụ phức tạp đòi hỏi sự hiểu biết chuyên sâu và phản hồi chi tiết.
Điều quan trọng là phải có tùy chọn để nhanh chóng xây dựng và kiểm tra phản hồi của mô hình cho một lời nhắc nhất định và tối ưu hóa lời nhắc dựa trên phản hồi. Sổ ghi chép JupyterLab cung cấp khả năng nhận phản hồi mô hình tức thì từ một mô hình chạy trên máy tính cục bộ và tối ưu hóa lời nhắc cũng như điều chỉnh phản hồi của mô hình hơn nữa hoặc thay đổi hoàn toàn mô hình. Trong bài đăng này, chúng tôi sử dụng sổ ghi chép SageMaker Studio JupyterLab được hỗ trợ bởi GPU NVIDIA A5.2G 10 GB của ml.g24xlarge để chạy suy luận mô hình Chuyển văn bản thành SQL trên sổ ghi chép và xây dựng lời nhắc mô hình của chúng tôi một cách tương tác cho đến khi phản hồi của mô hình được điều chỉnh đủ để cung cấp các phản hồi có thể thực thi trực tiếp trong các ô SQL của JupyterLab. Để chạy suy luận mô hình và truyền phát đồng thời các phản hồi của mô hình, chúng tôi sử dụng kết hợp model.generate và TextIteratorStreamer như được định nghĩa trong đoạn mã sau:
Đầu ra của mô hình có thể được trang trí bằng phép thuật SageMaker SQL %%sm_sql ..., cho phép sổ ghi chép JupyterLab xác định ô đó là ô SQL.
Lưu trữ các mô hình Chuyển văn bản sang SQL làm điểm cuối SageMaker
Ở cuối giai đoạn tạo mẫu, chúng tôi đã chọn LLM chuyển văn bản sang SQL ưa thích, định dạng lời nhắc hiệu quả và loại phiên bản thích hợp để lưu trữ mô hình (GPU đơn hoặc nhiều GPU). SageMaker tạo điều kiện cho việc lưu trữ các mô hình tùy chỉnh có thể mở rộng thông qua việc sử dụng điểm cuối SageMaker. Các điểm cuối này có thể được xác định theo tiêu chí cụ thể, cho phép triển khai LLM làm điểm cuối. Khả năng này cho phép bạn mở rộng giải pháp cho nhiều đối tượng hơn, cho phép người dùng tạo truy vấn SQL từ đầu vào ngôn ngữ tự nhiên bằng cách sử dụng LLM được lưu trữ tùy chỉnh. Sơ đồ sau minh họa kiến trúc này.

Để lưu trữ LLM của bạn dưới dạng điểm cuối SageMaker, bạn tạo một số tạo phẩm.
Hiện vật đầu tiên là trọng lượng mô hình. Cung cấp Thư viện Java sâu (DJL) của SageMaker vùng chứa cho phép bạn thiết lập cấu hình thông qua meta phục vụ.properties tệp, cho phép bạn chỉ dẫn cách lấy nguồn mô hình—trực tiếp từ Hugging Face Hub hoặc bằng cách tải xuống các tạo phẩm mô hình từ Amazon S3. Nếu bạn chỉ định model_id=defog/sqlcoder-7b-2, DJL Serve sẽ cố gắng tải xuống trực tiếp mô hình này từ Hugging Face Hub. Tuy nhiên, bạn có thể phải chịu phí vào/ra mạng mỗi khi điểm cuối được triển khai hoặc thay đổi quy mô linh hoạt. Để tránh những khoản phí này và có khả năng tăng tốc độ tải xuống các tạo phẩm mô hình, bạn nên bỏ qua việc sử dụng model_id in serving.properties và lưu trọng số mô hình dưới dạng tạo phẩm S3 và chỉ chỉ định chúng bằng s3url=s3://path/to/model/bin.
Việc lưu một mô hình (với mã thông báo của nó) vào đĩa và tải nó lên Amazon S3 có thể được thực hiện chỉ bằng một vài dòng mã:
Bạn cũng sử dụng tệp nhắc cơ sở dữ liệu. Trong thiết lập này, dấu nhắc cơ sở dữ liệu bao gồm Task, Instructions, Database Schemavà Answer sections. Đối với kiến trúc hiện tại, chúng tôi phân bổ một tệp nhắc nhở riêng cho từng lược đồ cơ sở dữ liệu. Tuy nhiên, có thể linh hoạt mở rộng thiết lập này để bao gồm nhiều cơ sở dữ liệu trên mỗi tệp nhắc nhở, cho phép mô hình chạy các kết nối tổng hợp trên các cơ sở dữ liệu trên cùng một máy chủ. Trong giai đoạn tạo mẫu, chúng tôi lưu lời nhắc cơ sở dữ liệu dưới dạng tệp văn bản có tên <Database-Glue-Connection-Name>.prompt, Nơi Database-Glue-Connection-Name tương ứng với tên kết nối hiển thị trong môi trường JupyterLab của bạn. Chẳng hạn, bài đăng này đề cập đến kết nối Bông tuyết có tên Airlines_Dataset, vì vậy tệp nhắc cơ sở dữ liệu được đặt tên Airlines_Dataset.prompt. Sau đó, tệp này được lưu trữ trên Amazon S3, sau đó được đọc và lưu vào bộ đệm bằng logic phân phát mô hình của chúng tôi.
Hơn nữa, kiến trúc này cho phép bất kỳ người dùng được ủy quyền nào của điểm cuối này xác định, lưu trữ và tạo ngôn ngữ tự nhiên cho các truy vấn SQL mà không cần phải triển khai lại mô hình nhiều lần. Chúng tôi sử dụng như sau ví dụ về lời nhắc cơ sở dữ liệu để minh họa chức năng Chuyển văn bản thành SQL.
Tiếp theo, bạn tạo logic dịch vụ mô hình tùy chỉnh. Trong phần này, bạn phác thảo một logic suy luận tùy chỉnh có tên model.py. Tập lệnh này được thiết kế để tối ưu hóa hiệu suất và tích hợp các dịch vụ Chuyển văn bản sang SQL của chúng tôi:
- Xác định logic lưu trữ tệp nhắc nhở cơ sở dữ liệu – Để giảm thiểu độ trễ, chúng tôi triển khai logic tùy chỉnh để tải xuống và lưu các tệp nhắc cơ sở dữ liệu vào bộ đệm. Cơ chế này đảm bảo rằng các lời nhắc luôn sẵn có, giảm chi phí liên quan đến việc tải xuống thường xuyên.
- Xác định logic suy luận mô hình tùy chỉnh – Để nâng cao tốc độ suy luận, mô hình chuyển văn bản sang SQL của chúng tôi được tải ở định dạng chính xác float16 và sau đó được chuyển đổi thành mô hình DeepSpeed. Bước này cho phép tính toán hiệu quả hơn. Ngoài ra, trong logic này, bạn chỉ định những tham số nào người dùng có thể điều chỉnh trong các lệnh gọi suy luận để điều chỉnh chức năng theo nhu cầu của họ.
- Xác định logic đầu vào và đầu ra tùy chỉnh – Việc thiết lập các định dạng đầu vào/đầu ra rõ ràng và tùy chỉnh là điều cần thiết để tích hợp trơn tru với các ứng dụng hạ nguồn. Một ứng dụng như vậy là JupyterAI, ứng dụng mà chúng ta sẽ thảo luận trong phần tiếp theo.
Ngoài ra, chúng tôi bao gồm một serving.properties tệp này hoạt động như một tệp cấu hình chung cho các mô hình được lưu trữ bằng cách phân phối DJL. Để biết thêm thông tin, hãy tham khảo Cấu hình và cài đặt.
Cuối cùng, bạn cũng có thể bao gồm một requirements.txt để xác định các mô-đun bổ sung cần thiết cho việc suy luận và đóng gói mọi thứ vào một tarball để triển khai.
Xem mã sau đây:
Tích hợp điểm cuối của bạn với trợ lý AI SageMaker Studio Jupyter
Jupyter trí tuệ nhân tạo là một công cụ nguồn mở mang AI sáng tạo vào máy tính xách tay Jupyter, cung cấp nền tảng mạnh mẽ và thân thiện với người dùng để khám phá các mô hình AI sáng tạo. Nó nâng cao năng suất trong sổ ghi chép JupyterLab và Jupyter bằng cách cung cấp các tính năng như phép thuật %%ai để tạo sân chơi AI tổng quát bên trong sổ ghi chép, giao diện người dùng trò chuyện gốc trong JupyterLab để tương tác với AI với tư cách là trợ lý đàm thoại và hỗ trợ nhiều loại LLM từ nhà cung cấp như người khổng lồ Amazon, AI21, Anthropic, Cohere và Hugging Face hoặc các dịch vụ được quản lý như nền tảng Amazon và điểm cuối SageMaker. Đối với bài đăng này, chúng tôi sử dụng tính năng tích hợp sẵn có của Jupyter AI với các điểm cuối SageMaker để đưa khả năng Chuyển văn bản sang SQL vào sổ ghi chép JupyterLab. Công cụ Jupyter AI được cài đặt sẵn trong tất cả các không gian SageMaker Studio JupyterLab được hỗ trợ bởi Hình ảnh phân phối SageMaker; người dùng cuối không bắt buộc phải thực hiện bất kỳ cấu hình bổ sung nào để bắt đầu sử dụng tiện ích mở rộng Jupyter AI nhằm tích hợp với điểm cuối được lưu trữ trên SageMaker. Trong phần này, chúng tôi thảo luận về hai cách sử dụng công cụ Jupyter AI tích hợp.
Jupyter AI bên trong một cuốn sổ sử dụng phép thuật
AI của Jupyter %%ai lệnh ma thuật cho phép bạn chuyển đổi sổ ghi chép SageMaker Studio JupyterLab của mình thành môi trường AI có khả năng tái tạo. Để bắt đầu sử dụng phép thuật AI, hãy đảm bảo bạn đã tải tiện ích mở rộng jupyter_ai_magics để sử dụng %%ai ma thuật, và tải thêm amazon_sagemaker_sql_magic sử dụng %%sm_sql ma thuật:
Để thực hiện cuộc gọi đến điểm cuối SageMaker từ sổ ghi chép của bạn bằng cách sử dụng %%ai lệnh magic, cung cấp các tham số sau và cấu trúc lệnh như sau:
- –tên vùng – Chỉ định Khu vực nơi điểm cuối của bạn được triển khai. Điều này đảm bảo rằng yêu cầu được chuyển đến đúng vị trí địa lý.
- –lược đồ yêu cầu – Bao gồm lược đồ của dữ liệu đầu vào. Lược đồ này phác thảo định dạng dự kiến và loại dữ liệu đầu vào mà mô hình của bạn cần để xử lý yêu cầu.
- –đường dẫn phản hồi – Xác định đường dẫn bên trong đối tượng phản hồi nơi đặt đầu ra của mô hình của bạn. Đường dẫn này được sử dụng để trích xuất dữ liệu liên quan từ phản hồi do mô hình của bạn trả về.
- -f (tùy chọn) - Đây là định dạng đầu ra cờ cho biết loại đầu ra được mô hình trả về. Trong ngữ cảnh của sổ ghi chép Jupyter, nếu đầu ra là mã, thì cờ này phải được đặt tương ứng để định dạng đầu ra dưới dạng mã thực thi ở đầu ô sổ ghi chép Jupyter, theo sau là vùng nhập văn bản miễn phí để người dùng tương tác.
Ví dụ: lệnh trong ô sổ ghi chép Jupyter có thể trông giống như đoạn mã sau:
Cửa sổ trò chuyện Jupyter AI
Ngoài ra, bạn có thể tương tác với điểm cuối SageMaker thông qua giao diện người dùng tích hợp, đơn giản hóa quá trình tạo truy vấn hoặc tham gia đối thoại. Trước khi bắt đầu trò chuyện với điểm cuối SageMaker của bạn, hãy định cấu hình cài đặt có liên quan trong Jupyter AI cho điểm cuối SageMaker, như minh họa trong ảnh chụp màn hình sau.
 |
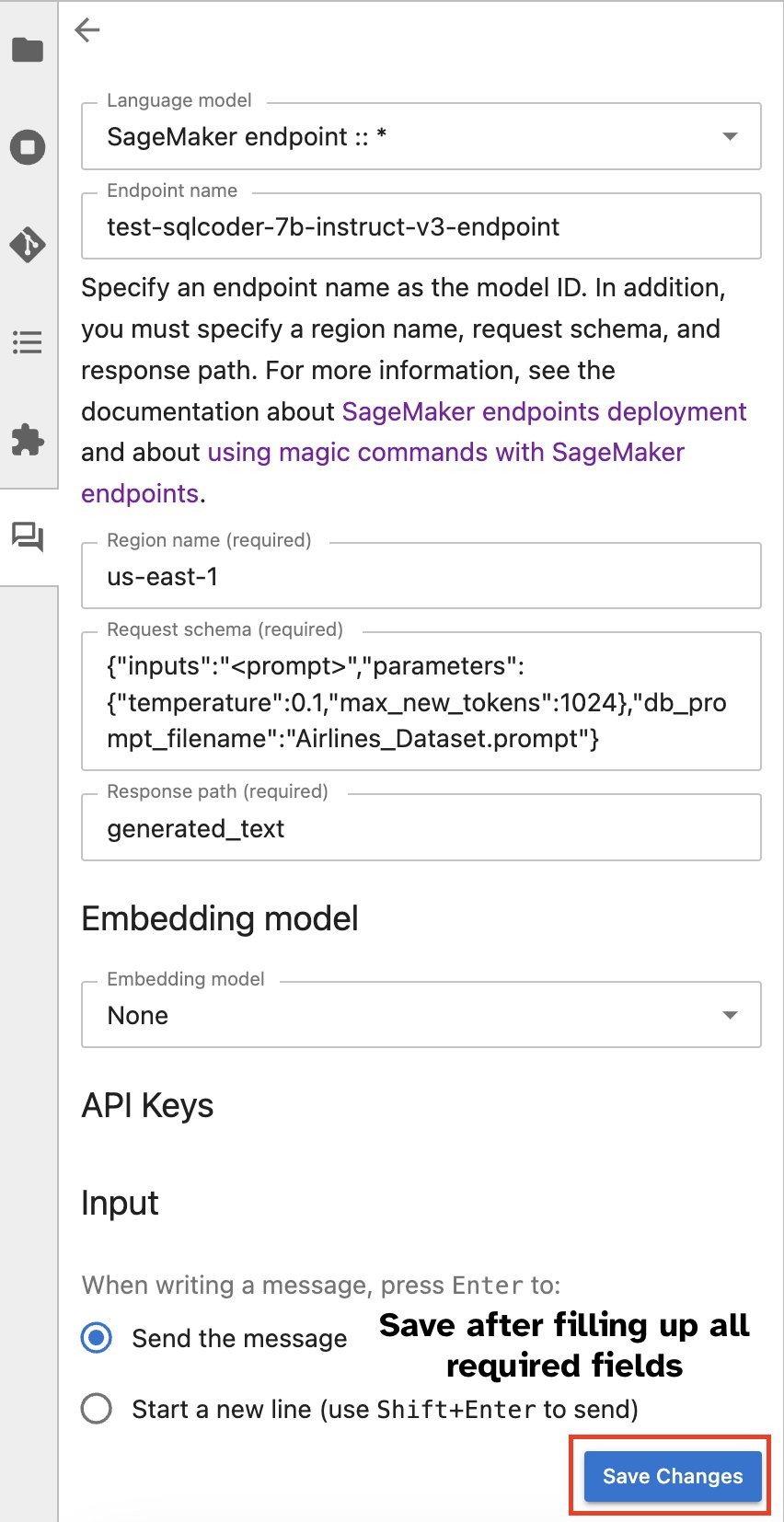 |
Kết luận
SageMaker Studio hiện đơn giản hóa và hợp lý hóa quy trình làm việc của nhà khoa học dữ liệu bằng cách tích hợp hỗ trợ SQL vào sổ ghi chép JupyterLab. Điều này cho phép các nhà khoa học dữ liệu tập trung vào nhiệm vụ của họ mà không cần quản lý nhiều công cụ. Hơn nữa, tính năng tích hợp SQL tích hợp mới trong SageMaker Studio cho phép các cá nhân dữ liệu dễ dàng tạo các truy vấn SQL bằng cách sử dụng văn bản ngôn ngữ tự nhiên làm đầu vào, từ đó đẩy nhanh quy trình làm việc của họ.
Chúng tôi khuyến khích bạn khám phá những tính năng này trong SageMaker Studio. Để biết thêm thông tin, hãy tham khảo Chuẩn bị dữ liệu với SQL trong Studio.
Phụ lục
Kích hoạt trình duyệt SQL và ô SQL sổ ghi chép trong môi trường tùy chỉnh
Nếu bạn không sử dụng hình ảnh Phân phối SageMaker hoặc sử dụng Hình ảnh phân phối 1.5 trở xuống, hãy chạy các lệnh sau để bật tính năng duyệt SQL bên trong môi trường JupyterLab của bạn:
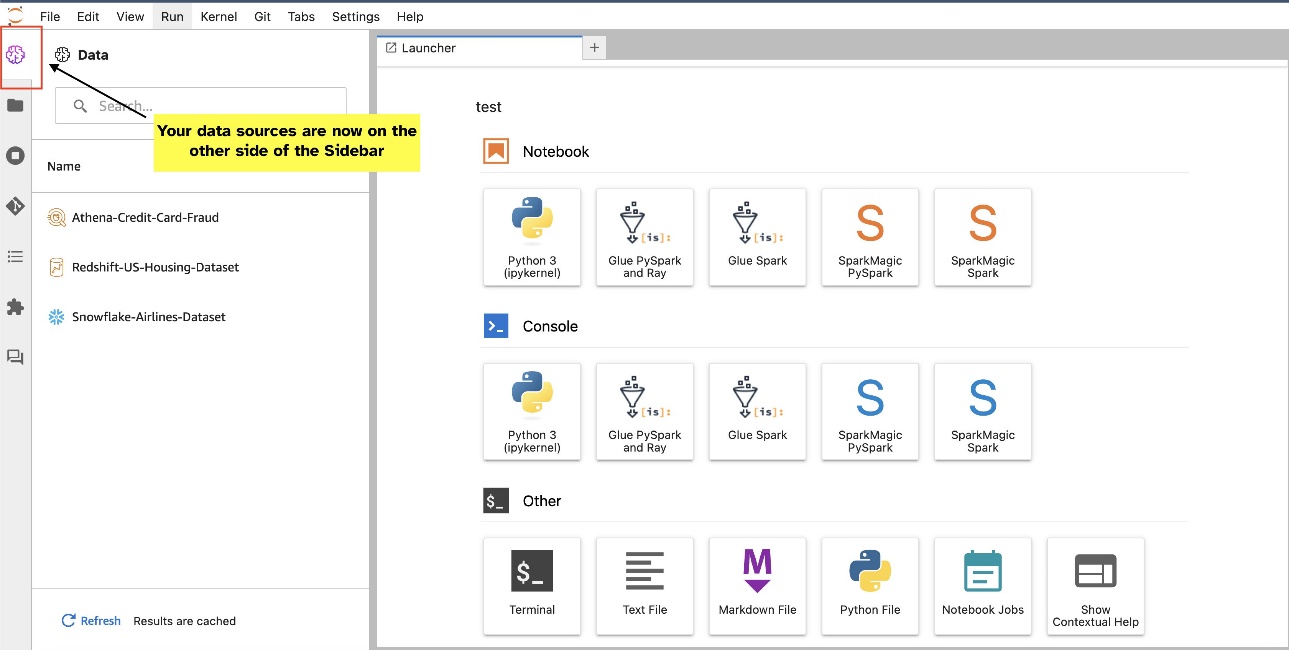
Di chuyển tiện ích trình duyệt SQL
Các tiện ích JupyterLab cho phép di dời. Tùy thuộc vào sở thích của bạn, bạn có thể di chuyển các tiện ích sang hai bên của ngăn tiện ích JupyterLab. Nếu muốn, bạn có thể di chuyển hướng của tiện ích SQL sang phía đối diện (phải sang trái) của thanh bên bằng cách nhấp chuột phải đơn giản vào biểu tượng tiện ích và chọn Chuyển đổi bên thanh bên.
 |
 |
Giới thiệu về tác giả
 Pranav Murthy là Kiến trúc sư giải pháp chuyên gia AI/ML tại AWS. Anh tập trung vào việc giúp khách hàng xây dựng, đào tạo, triển khai và di chuyển khối lượng công việc máy học (ML) sang SageMaker. Trước đây, anh đã làm việc trong ngành bán dẫn, phát triển các mô hình thị giác máy tính (CV) lớn và xử lý ngôn ngữ tự nhiên (NLP) để cải thiện quy trình bán dẫn bằng cách sử dụng các kỹ thuật ML hiện đại. Khi rảnh rỗi, anh thích chơi cờ và đi du lịch. Bạn có thể tìm thấy Pranav trên LinkedIn.
Pranav Murthy là Kiến trúc sư giải pháp chuyên gia AI/ML tại AWS. Anh tập trung vào việc giúp khách hàng xây dựng, đào tạo, triển khai và di chuyển khối lượng công việc máy học (ML) sang SageMaker. Trước đây, anh đã làm việc trong ngành bán dẫn, phát triển các mô hình thị giác máy tính (CV) lớn và xử lý ngôn ngữ tự nhiên (NLP) để cải thiện quy trình bán dẫn bằng cách sử dụng các kỹ thuật ML hiện đại. Khi rảnh rỗi, anh thích chơi cờ và đi du lịch. Bạn có thể tìm thấy Pranav trên LinkedIn.
 Varun Shah là Kỹ sư phần mềm làm việc trên Amazon SageMaker Studio tại Amazon Web Services. Anh ấy tập trung vào việc xây dựng các giải pháp ML tương tác giúp đơn giản hóa quá trình xử lý dữ liệu và chuẩn bị dữ liệu . Trong thời gian rảnh rỗi, Varun thích các hoạt động ngoài trời bao gồm đi bộ đường dài và trượt tuyết, đồng thời luôn sẵn sàng khám phá những địa điểm mới, thú vị.
Varun Shah là Kỹ sư phần mềm làm việc trên Amazon SageMaker Studio tại Amazon Web Services. Anh ấy tập trung vào việc xây dựng các giải pháp ML tương tác giúp đơn giản hóa quá trình xử lý dữ liệu và chuẩn bị dữ liệu . Trong thời gian rảnh rỗi, Varun thích các hoạt động ngoài trời bao gồm đi bộ đường dài và trượt tuyết, đồng thời luôn sẵn sàng khám phá những địa điểm mới, thú vị.
 Sumedha Swamy là Giám đốc sản phẩm chính tại Amazon Web Services, nơi ông lãnh đạo nhóm SageMaker Studio trong sứ mệnh phát triển IDE được lựa chọn cho khoa học dữ liệu và học máy. Ông đã cống hiến 15 năm qua để xây dựng các sản phẩm dành cho người tiêu dùng và doanh nghiệp dựa trên Machine Learning.
Sumedha Swamy là Giám đốc sản phẩm chính tại Amazon Web Services, nơi ông lãnh đạo nhóm SageMaker Studio trong sứ mệnh phát triển IDE được lựa chọn cho khoa học dữ liệu và học máy. Ông đã cống hiến 15 năm qua để xây dựng các sản phẩm dành cho người tiêu dùng và doanh nghiệp dựa trên Machine Learning.
 Bosco Albuquerque là Kiến trúc sư Giải pháp Đối tác Cấp cao tại AWS và có hơn 20 năm kinh nghiệm làm việc với cơ sở dữ liệu và các sản phẩm phân tích từ các nhà cung cấp cơ sở dữ liệu doanh nghiệp và nhà cung cấp đám mây. Ông đã giúp các công ty công nghệ thiết kế và triển khai các giải pháp và sản phẩm phân tích dữ liệu.
Bosco Albuquerque là Kiến trúc sư Giải pháp Đối tác Cấp cao tại AWS và có hơn 20 năm kinh nghiệm làm việc với cơ sở dữ liệu và các sản phẩm phân tích từ các nhà cung cấp cơ sở dữ liệu doanh nghiệp và nhà cung cấp đám mây. Ông đã giúp các công ty công nghệ thiết kế và triển khai các giải pháp và sản phẩm phân tích dữ liệu.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

