Hôm nay, chúng tôi vui mừng thông báo rằng Vùng dữ liệu Amazon hiện có thể trình bày thông tin chất lượng dữ liệu cho nội dung dữ liệu. Thông tin này trao quyền cho người dùng cuối đưa ra quyết định sáng suốt về việc có nên sử dụng các tài sản cụ thể hay không.
Nhiều tổ chức đã sử dụng Chất lượng dữ liệu keo AWS để xác định và thực thi các quy tắc chất lượng dữ liệu trên dữ liệu của họ, xác thực dữ liệu theo các quy tắc được xác định trước, theo dõi số liệu chất lượng dữ liệu và giám sát chất lượng dữ liệu theo thời gian bằng trí tuệ nhân tạo (AI). Các tổ chức khác giám sát chất lượng dữ liệu của họ thông qua các giải pháp của bên thứ ba.
Amazon DataZone hiện tích hợp trực tiếp với AWS Glue để hiển thị điểm chất lượng dữ liệu cho nội dung Danh mục dữ liệu AWS Glue. Ngoài ra, Amazon DataZone hiện cung cấp API để nhập điểm chất lượng dữ liệu từ hệ thống bên ngoài.
Trong bài đăng này, chúng tôi thảo luận về các tính năng mới nhất của Amazon DataZone về chất lượng dữ liệu, sự tích hợp giữa Amazon DataZone và Chất lượng dữ liệu AWS Glue cũng như cách bạn có thể nhập điểm chất lượng dữ liệu do hệ thống bên ngoài tạo ra vào Amazon DataZone thông qua API.
Những thách thức
Một trong những câu hỏi phổ biến nhất mà chúng tôi nhận được từ khách hàng có liên quan đến việc hiển thị điểm chất lượng dữ liệu trong Danh mục dữ liệu kinh doanh của Amazon DataZone để cho phép người dùng doanh nghiệp có cái nhìn rõ ràng về tình trạng và độ tin cậy của bộ dữ liệu.
Khi dữ liệu ngày càng trở nên quan trọng trong việc thúc đẩy các quyết định kinh doanh, người dùng Amazon DataZone rất quan tâm đến việc cung cấp các tiêu chuẩn cao nhất về chất lượng dữ liệu. Họ nhận ra tầm quan trọng của dữ liệu chính xác, đầy đủ và kịp thời trong việc hỗ trợ đưa ra quyết định sáng suốt và củng cố niềm tin vào quy trình phân tích và báo cáo của họ.
Tài sản dữ liệu Amazon DataZone có thể được cập nhật ở các tần suất khác nhau. Khi dữ liệu được làm mới và cập nhật, những thay đổi có thể xảy ra thông qua các quy trình ngược dòng khiến dữ liệu có nguy cơ không duy trì được chất lượng như mong muốn. Điểm chất lượng dữ liệu giúp bạn hiểu liệu dữ liệu có duy trì được mức chất lượng mong đợi để người tiêu dùng dữ liệu sử dụng hay không (thông qua quá trình phân tích hoặc quy trình tiếp theo).
Từ quan điểm của nhà sản xuất, người quản lý dữ liệu giờ đây có thể thiết lập Amazon DataZone để tự động nhập điểm chất lượng dữ liệu từ Chất lượng dữ liệu AWS Glue (theo lịch trình hoặc theo yêu cầu) và đưa thông tin này vào danh mục Amazon DataZone để chia sẻ với người dùng doanh nghiệp. Ngoài ra, giờ đây bạn có thể sử dụng API Amazon DataZone mới để nhập điểm chất lượng dữ liệu do hệ thống bên ngoài tạo ra vào nội dung dữ liệu.
Với cải tiến mới nhất, người dùng Amazon DataZone giờ đây có thể thực hiện những việc sau:
- Truy cập thông tin chi tiết về tiêu chuẩn chất lượng dữ liệu trực tiếp từ cổng web Amazon DataZone
- Xem điểm chất lượng dữ liệu trên các KPI khác nhau, bao gồm tính đầy đủ, tính duy nhất, độ chính xác của dữ liệu
- Đảm bảo người dùng có cái nhìn toàn diện về chất lượng và độ tin cậy của dữ liệu của họ.
Trong phần đầu tiên của bài đăng này, chúng ta sẽ tìm hiểu cách tích hợp giữa Chất lượng dữ liệu AWS Glue và Amazon DataZone. Chúng tôi thảo luận cách trực quan hóa điểm chất lượng dữ liệu trong Amazon DataZone, bật Chất lượng dữ liệu AWS Glue khi tạo nguồn dữ liệu Amazon DataZone mới và bật chất lượng dữ liệu cho nội dung dữ liệu hiện có.
Trong phần thứ hai của bài đăng này, chúng tôi thảo luận về cách bạn có thể nhập điểm chất lượng dữ liệu do hệ thống bên ngoài tạo ra vào Amazon DataZone thông qua API. Trong ví dụ này, chúng tôi sử dụng Amazon EMR không có máy chủ kết hợp với thư viện mã nguồn mở Pydeequ hoạt động như một hệ thống bên ngoài về chất lượng dữ liệu.
Trực quan hóa điểm Chất lượng dữ liệu AWS Glue trong Amazon DataZone
Giờ đây, bạn có thể trực quan hóa điểm Chất lượng dữ liệu AWS Glue trong nội dung dữ liệu đã được xuất bản trong danh mục doanh nghiệp Amazon DataZone và có thể tìm kiếm được thông qua cổng web Amazon DataZone.
Nếu nội dung đã bật Chất lượng dữ liệu AWS Glue, giờ đây bạn có thể trực quan hóa nhanh điểm chất lượng dữ liệu ngay trong ngăn tìm kiếm danh mục.

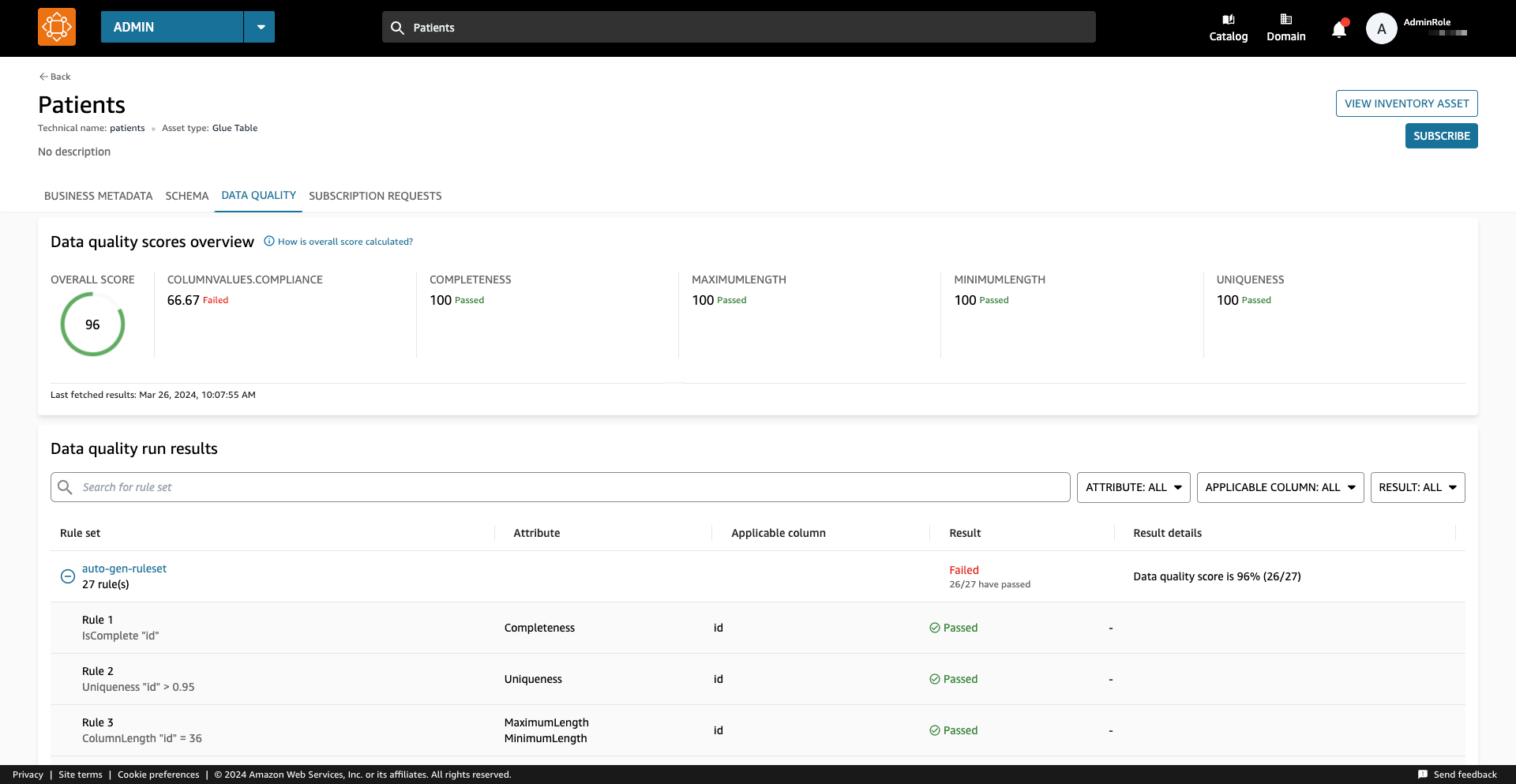
Bằng cách chọn nội dung tương ứng, bạn có thể hiểu nội dung của nó thông qua readme, thuật ngữ thuật ngữvà siêu dữ liệu kỹ thuật và kinh doanh. Ngoài ra, chỉ báo điểm chất lượng tổng thể được hiển thị trong Chi tiết tài sản phần.

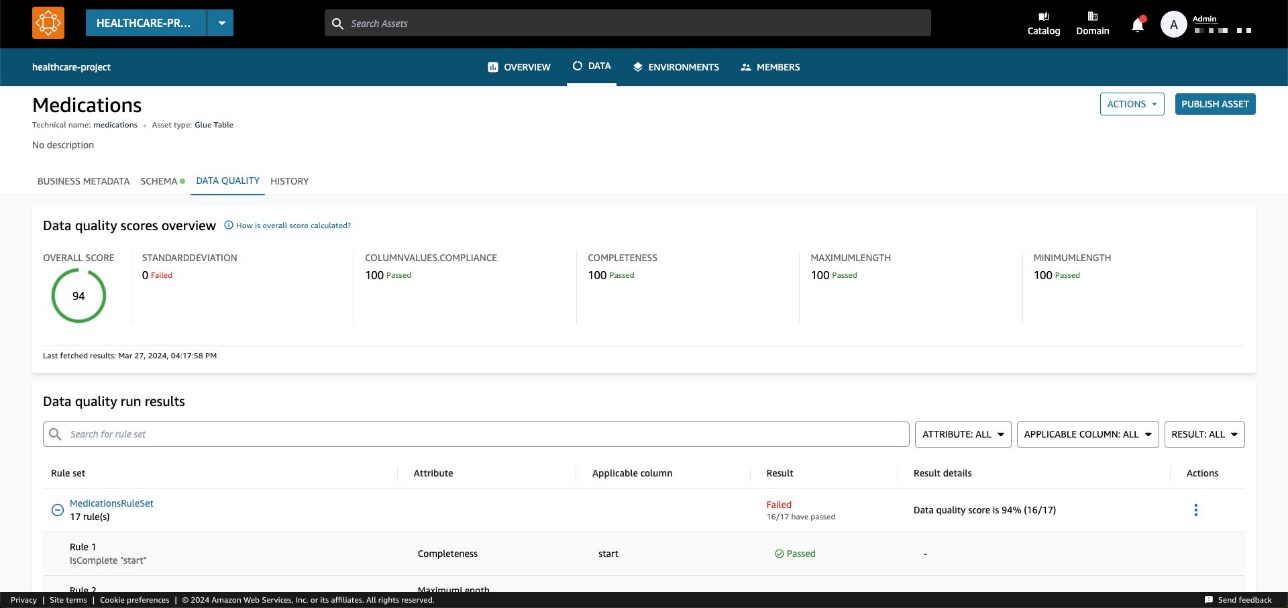
Điểm chất lượng dữ liệu đóng vai trò là chỉ báo tổng thể về chất lượng của tập dữ liệu, được tính toán dựa trên các quy tắc bạn xác định.
trên Chất lượng dữ liệu tab, bạn có thể truy cập chi tiết về các chỉ báo tổng quan về chất lượng dữ liệu và kết quả của các lần chạy chất lượng dữ liệu.
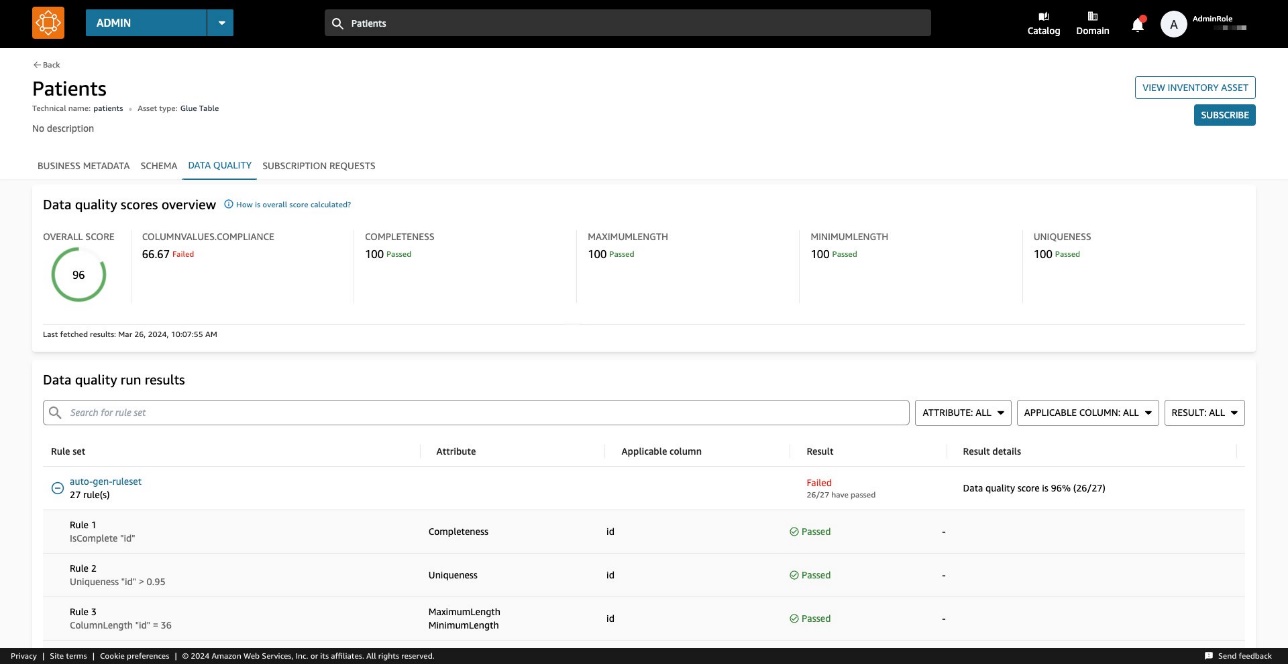
Các chỉ số thể hiện trên Giới thiệu chung tab được tính toán dựa trên kết quả của bộ quy tắc từ các lần chạy chất lượng dữ liệu.
Mỗi quy tắc được gán một thuộc tính góp phần tính toán chỉ báo. Ví dụ, các quy tắc có Completeness thuộc tính sẽ góp phần tính toán chỉ số tương ứng trên Giới thiệu chung tab.
Để lọc kết quả chất lượng dữ liệu, hãy chọn Cột áp dụng menu thả xuống và chọn tham số bộ lọc mong muốn của bạn.

Bạn cũng có thể trực quan hóa chất lượng dữ liệu ở cấp độ cột bắt đầu từ Schema tab.

Khi chất lượng dữ liệu được bật cho nội dung, kết quả chất lượng dữ liệu sẽ có sẵn, cung cấp điểm chất lượng sâu sắc phản ánh tính toàn vẹn và độ tin cậy của từng cột trong tập dữ liệu.
Khi chọn một trong các liên kết kết quả chất lượng dữ liệu, bạn sẽ được chuyển hướng đến trang chi tiết về chất lượng dữ liệu, được lọc theo cột đã chọn.

Kết quả lịch sử chất lượng dữ liệu trong Amazon DataZone
Chất lượng dữ liệu có thể thay đổi theo thời gian vì nhiều lý do:
- Định dạng dữ liệu có thể thay đổi do những thay đổi trong hệ thống nguồn
- Khi dữ liệu tích lũy theo thời gian, nó có thể trở nên lỗi thời hoặc không nhất quán
- Chất lượng dữ liệu có thể bị ảnh hưởng bởi lỗi của con người trong việc nhập dữ liệu, xử lý dữ liệu hoặc thao tác dữ liệu
Trong Amazon DataZone, giờ đây bạn có thể theo dõi chất lượng dữ liệu theo thời gian để xác nhận độ tin cậy và độ chính xác. Bằng cách phân tích ảnh chụp nhanh báo cáo lịch sử, bạn có thể xác định các lĩnh vực cần cải thiện, thực hiện các thay đổi và đo lường tính hiệu quả của những thay đổi đó.

Bật Chất lượng dữ liệu AWS Glue khi tạo nguồn dữ liệu Amazon DataZone mới
Trong phần này, chúng ta sẽ hướng dẫn các bước để bật Chất lượng dữ liệu AWS Glue khi tạo nguồn dữ liệu Amazon DataZone mới.
Điều kiện tiên quyết
Để làm theo, bạn cần có một miền cho Amazon DataZone, một dự án Amazon DataZone và một miền mới Môi trường Amazon DataZone (với một DataLakeProfile). Để biết hướng dẫn, hãy tham khảo Bắt đầu nhanh Amazon DataZone với dữ liệu AWS Glue.
Bạn cũng cần xác định và chạy bộ quy tắc đối với dữ liệu của mình, đây là bộ quy tắc chất lượng dữ liệu trong Chất lượng dữ liệu AWS Glue. Để thiết lập các quy tắc chất lượng dữ liệu và để biết thêm thông tin về chủ đề này, hãy tham khảo các bài đăng sau:
Sau khi bạn tạo quy tắc chất lượng dữ liệu, hãy đảm bảo rằng Amazon DataZone có quyền truy cập cơ sở dữ liệu AWS Glue được quản lý thông qua Sự hình thành hồ AWS. Để được hướng dẫn, xem Định cấu hình quyền Lake Formation cho Amazon DataZone.
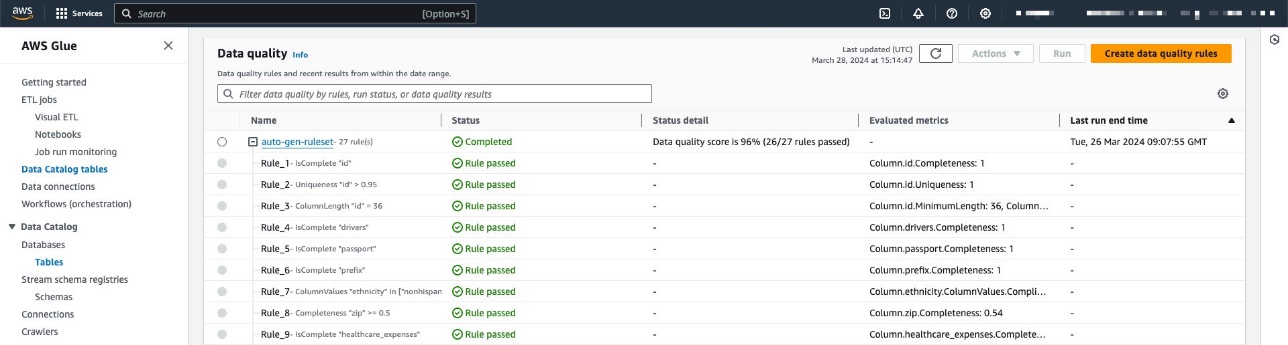
Trong ví dụ của chúng tôi, chúng tôi đã định cấu hình bộ quy tắc dựa trên bảng chứa dữ liệu bệnh nhân trong một tập dữ liệu tổng hợp chăm sóc sức khỏe được tạo ra bằng cách sử dụng tổng hợp. Synthea là một trình tạo bệnh nhân tổng hợp tạo ra dữ liệu bệnh nhân thực tế và hồ sơ y tế liên quan có thể được sử dụng để thử nghiệm các ứng dụng phần mềm chăm sóc sức khỏe.
Bộ quy tắc chứa 27 quy tắc riêng lẻ (một trong số đó không thành công), do đó điểm chất lượng dữ liệu tổng thể là 96%.
Nếu bạn sử dụng các chính sách được quản lý của Amazon DataZone thì bạn không cần thực hiện hành động nào vì những chính sách này sẽ được cập nhật tự động với các hành động cần thiết. Nếu không, bạn cần cho phép Amazon DataZone có các quyền cần thiết để liệt kê và nhận kết quả Chất lượng dữ liệu AWS Glue, như minh họa trong Hướng dẫn sử dụng Amazon DataZone.
Tạo nguồn dữ liệu đã bật chất lượng dữ liệu
Trong phần này, chúng tôi tạo nguồn dữ liệu và kích hoạt chất lượng dữ liệu. Bạn cũng có thể cập nhật nguồn dữ liệu hiện có để kích hoạt chất lượng dữ liệu. Chúng tôi sử dụng nguồn dữ liệu này để nhập thông tin siêu dữ liệu liên quan đến tập dữ liệu của chúng tôi. Amazon DataZone cũng sẽ nhập thông tin chất lượng dữ liệu liên quan đến (một hoặc nhiều) nội dung có trong nguồn dữ liệu.
- Trên bảng điều khiển Amazon DataZone, chọn Nguồn dữ liệu trong khung điều hướng.
- Chọn Tạo nguồn dữ liệu.

- Trong Họ tên, nhập tên cho nguồn dữ liệu của bạn.
- Trong Loại nguồn dữ liệu, lựa chọn Keo AWS.
- Trong Môi trường, chọn môi trường của bạn.

- Trong Tên cơ sở dữ liệu, nhập tên cho cơ sở dữ liệu.
- Trong Tiêu chí lựa chọn bảng, hãy chọn tiêu chí của bạn.
- Chọn Sau.

- Trong Chất lượng dữ liệu, lựa chọn Bật chất lượng dữ liệu cho nguồn dữ liệu này.
Nếu chất lượng dữ liệu được bật, Amazon DataZone sẽ tự động lấy điểm chất lượng dữ liệu từ AWS Glue ở mỗi lần chạy nguồn dữ liệu.
- Chọn Sau.

Bây giờ bạn có thể chạy nguồn dữ liệu.

Trong khi chạy nguồn dữ liệu, Amazon DataZone nhập 100 kết quả chạy Chất lượng dữ liệu AWS Glue gần đây nhất. Thông tin này hiện hiển thị trên trang nội dung và sẽ hiển thị với tất cả người dùng Amazon DataZone sau khi xuất bản nội dung.
Bật chất lượng dữ liệu cho nội dung dữ liệu hiện có
Trong phần này, chúng tôi kích hoạt chất lượng dữ liệu cho nội dung hiện có. Điều này có thể hữu ích cho những người dùng đã có sẵn nguồn dữ liệu và muốn bật tính năng này sau đó.
Điều kiện tiên quyết
Để làm theo, bạn phải chạy nguồn dữ liệu và tạo nội dung dữ liệu bảng AWS Glue. Ngoài ra, lẽ ra bạn phải xác định bộ quy tắc về Chất lượng dữ liệu AWS Glue trên bảng mục tiêu trong Danh mục dữ liệu.

Trong ví dụ này, chúng tôi đã chạy tác vụ chất lượng dữ liệu nhiều lần trên bảng, tạo ra điểm Chất lượng dữ liệu AWS Glue liên quan, như minh họa trong ảnh chụp màn hình sau.

Nhập điểm chất lượng dữ liệu vào nội dung dữ liệu
Hoàn thành các bước sau để nhập điểm Chất lượng dữ liệu AWS Glue hiện có vào nội dung dữ liệu trong Amazon DataZone:
- Trong dự án Amazon DataZone, hãy điều hướng đến Dữ liệu hàng tồn kho và chọn nguồn dữ liệu.
Nếu bạn chọn Chất lượng dữ liệu tab, bạn có thể thấy rằng vẫn chưa có thông tin về chất lượng dữ liệu vì tính năng tích hợp Chất lượng dữ liệu AWS Glue chưa được bật cho nội dung dữ liệu này.
- trên Chất lượng dữ liệu tab, chọn Bật chất lượng dữ liệu.

- Trong tạp chí Chất lượng dữ liệu phần, chọn Bật chất lượng dữ liệu cho nguồn dữ liệu này.
- Chọn Lưu.

Bây giờ, quay lại ngăn dữ liệu Hàng tồn kho, bạn có thể thấy một tab mới: Chất lượng dữ liệu.
trên Chất lượng dữ liệu , bạn có thể xem điểm chất lượng dữ liệu được nhập từ Chất lượng dữ liệu AWS Glue.
Nhập điểm chất lượng dữ liệu từ nguồn bên ngoài bằng API Amazon DataZone
Nhiều tổ chức đã sử dụng các hệ thống tính toán chất lượng dữ liệu bằng cách thực hiện kiểm tra và xác nhận trên bộ dữ liệu của họ. Amazon DataZone hiện hỗ trợ nhập điểm chất lượng dữ liệu có nguồn gốc của bên thứ ba thông qua API, cho phép người dùng điều hướng cổng web để xem thông tin này.
Trong phần này, chúng tôi mô phỏng hệ thống của bên thứ ba đẩy điểm chất lượng dữ liệu vào Amazon DataZone thông qua API thông qua boto3 (SDK Python cho AWS).
Đối với ví dụ này, chúng tôi sử dụng tương tự bộ dữ liệu tổng hợp như trước đó, được tạo bằng tổng hợp.
Sơ đồ sau minh họa kiến trúc giải pháp.

Quy trình làm việc bao gồm các bước sau:
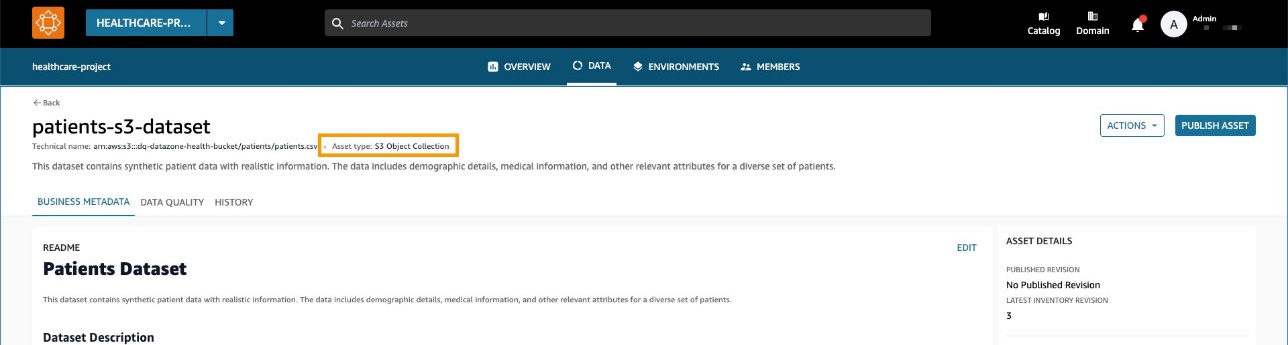
- Đọc tập dữ liệu về bệnh nhân trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) trực tiếp từ Amazon EMR bằng Spark.
Tập dữ liệu được tạo dưới dạng bộ sưu tập tài sản S3 chung trong Amazon DataZone.
- Trong Amazon EMR, thực hiện các quy tắc xác thực dữ liệu đối với tập dữ liệu.
- Các số liệu được lưu trong Amazon S3 để có kết quả đầu ra ổn định.
- Sử dụng API Amazon DataZone thông qua Boto3 để đẩy siêu dữ liệu chất lượng dữ liệu tùy chỉnh.
- Người dùng cuối có thể xem điểm chất lượng dữ liệu bằng cách điều hướng đến cổng dữ liệu.
Điều kiện tiên quyết
Chúng tôi sử dụng Amazon EMR không có máy chủ và Pydeequ để điều hành một hệ thống được quản lý hoàn toàn Spark môi trường. Để tìm hiểu thêm về Pydeequ làm khung kiểm tra dữ liệu, hãy xem Kiểm tra chất lượng dữ liệu trên quy mô lớn với Pydeequ.
Để cho phép Amazon EMR gửi dữ liệu đến miền Amazon DataZone, hãy đảm bảo rằng vai trò IAM mà Amazon EMR sử dụng có quyền thực hiện những điều sau:
- Đọc và ghi vào nhóm S3
- Gọi
post_time_series_data_pointshành động dành cho Amazon DataZone:
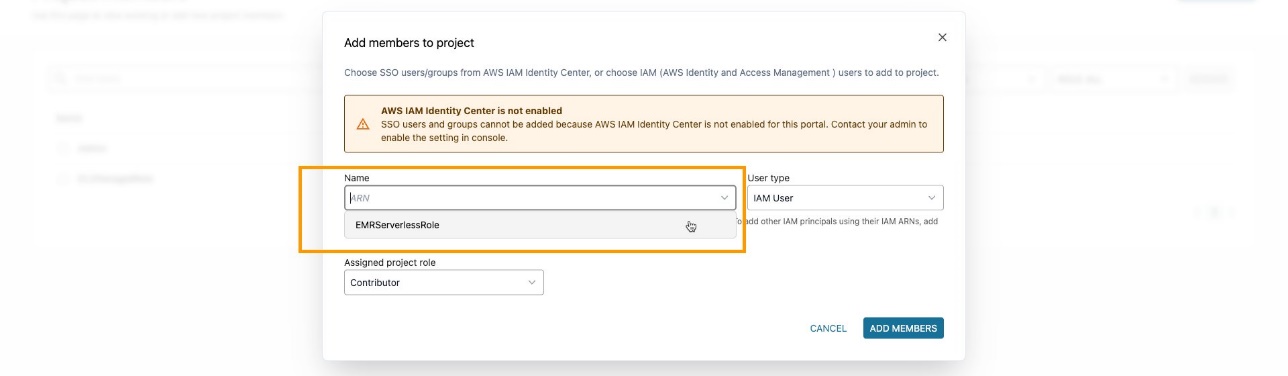
Đảm bảo rằng bạn đã thêm vai trò EMR dưới dạng thành viên dự án trong dự án Amazon DataZone. Trên bảng điều khiển Amazon DataZone, hãy điều hướng đến thành viên dự án trang và chọn Thêm thành viên.

Thêm vai trò EMR với tư cách là người đóng góp.
Nhập và phân tích mã PySpark
Trong phần này, chúng tôi phân tích mã PySpark mà chúng tôi sử dụng để thực hiện kiểm tra chất lượng dữ liệu và gửi kết quả đến Amazon DataZone. Bạn có thể tải xuống đầy đủ Tập lệnh PySpark.
Để chạy toàn bộ tập lệnh, bạn có thể gửi công việc tới EMR Serverless. Dịch vụ sẽ đảm nhiệm việc lên lịch công việc và tự động phân bổ các nguồn lực cần thiết, cho phép bạn theo dõi trạng thái chạy công việc trong suốt quá trình.
Bạn có thể gửi công việc tới EMR trong bảng điều khiển Amazon EMR bằng EMR Studio hoặc lập trình, sử dụng AWSCLI hoặc sử dụng một trong những AWS SDK.
Trong Apache Spark, một SparkSession là điểm bắt đầu để tương tác với các hàm tích hợp của DataFrames và Spark. Tập lệnh sẽ bắt đầu khởi tạo một SparkSession:
Chúng tôi đọc tập dữ liệu từ Amazon S3. Để tăng tính mô-đun, bạn có thể sử dụng đầu vào tập lệnh để tham chiếu đến đường dẫn S3:
Tiếp theo, chúng tôi thiết lập một kho lưu trữ số liệu. Điều này có thể hữu ích để duy trì kết quả chạy trong Amazon S3.
Pydeequ cho phép bạn tạo các quy tắc chất lượng dữ liệu bằng cách sử dụng mẫu xây dựng, đây là mẫu thiết kế kỹ thuật phần mềm nổi tiếng, nối hướng dẫn để khởi tạo một VerificationSuite vật:
Sau đây là đầu ra cho các quy tắc xác thực dữ liệu:
Tại thời điểm này, chúng tôi muốn chèn các giá trị chất lượng dữ liệu này vào Amazon DataZone. Để làm như vậy, chúng tôi sử dụng post_time_series_data_points hoạt động trong máy khách Boto3 Amazon DataZone.
Sản phẩm API DataZone của PostTimeSeriesDataPoints cho phép bạn chèn các điểm dữ liệu chuỗi thời gian mới cho một nội dung hoặc danh sách nhất định mà không cần tạo bản sửa đổi mới.
Tại thời điểm này, bạn cũng có thể muốn có thêm thông tin về trường nào được gửi làm đầu vào cho API. Bạn có thể dùng API để có được thông số kỹ thuật cho các loại biểu mẫu Amazon DataZone; trong trường hợp của chúng tôi, đó là amazon.datazone.DataQualityResultFormType.
Bạn cũng có thể sử dụng AWS CLI để gọi API và hiển thị cấu trúc biểu mẫu:
Đầu ra này giúp xác định các tham số API bắt buộc, bao gồm các trường và giới hạn giá trị:
Để gửi dữ liệu biểu mẫu phù hợp, chúng ta cần chuyển đổi đầu ra Pydeequ để khớp với DataQualityResultsFormType hợp đồng. Điều này có thể đạt được bằng hàm Python xử lý kết quả.
Đối với mỗi hàng DataFrame, chúng tôi trích xuất thông tin từ cột ràng buộc. Ví dụ: lấy đoạn mã sau:
Chúng tôi chuyển đổi nó thành như sau:
Đảm bảo gửi đầu ra phù hợp với KPI mà bạn muốn theo dõi. Trong trường hợp của chúng tôi, chúng tôi đang nối thêm _custom vào tên thống kê, dẫn đến định dạng sau cho KPI:
Completeness_customUniqueness_custom
Trong tình huống thực tế, bạn có thể muốn đặt một giá trị phù hợp với khung chất lượng dữ liệu của mình liên quan đến KPI mà bạn muốn theo dõi trong Amazon DataZone.
Sau khi áp dụng hàm chuyển đổi, chúng ta có một đối tượng Python cho mỗi đánh giá quy tắc:
Chúng tôi cũng sử dụng constraint_status cột để tính tổng điểm:
Trong ví dụ của chúng tôi, điều này dẫn đến tỷ lệ đậu là 85.71%.
Chúng tôi đặt giá trị này trong passingPercentage trường đầu vào cùng với các thông tin khác liên quan đến đánh giá trong đầu vào của phương pháp Boto3 post_time_series_data_points:
Boto3 gọi API Amazon DataZone. Trong các ví dụ này, chúng tôi đã sử dụng Boto3 và Python, nhưng bạn có thể chọn một trong các AWS SDK được phát triển bằng ngôn ngữ bạn thích.
Sau khi đặt miền và ID nội dung phù hợp cũng như chạy phương thức, chúng ta có thể kiểm tra trên bảng điều khiển Amazon DataZone xem chất lượng dữ liệu nội dung hiện có hiển thị trên trang nội dung hay không.
Chúng ta có thể quan sát thấy điểm tổng thể khớp với giá trị đầu vào API. Chúng tôi cũng có thể thấy rằng chúng tôi có thể thêm KPI tùy chỉnh trên tab tổng quan thông qua các giá trị thông số loại tùy chỉnh.
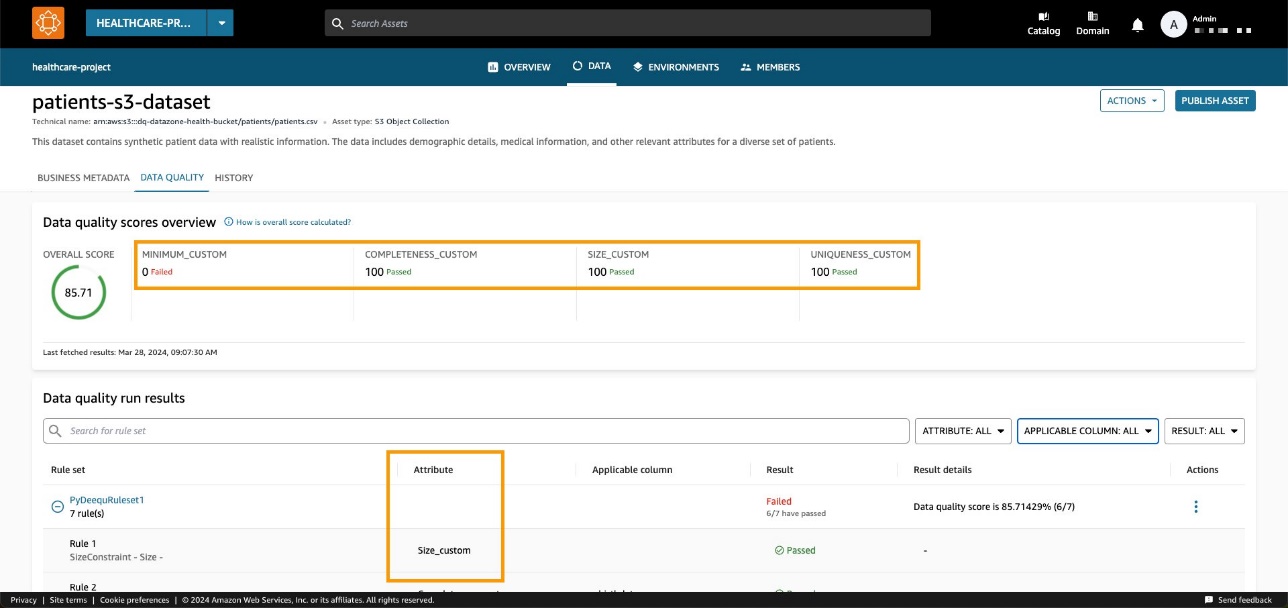
Với API Amazon DataZone mới, bạn có thể tải các quy tắc chất lượng dữ liệu từ hệ thống của bên thứ ba vào một nội dung dữ liệu cụ thể. Với khả năng này, Amazon DataZone cho phép bạn mở rộng các loại chỉ báo có trong Chất lượng dữ liệu AWS Glue (chẳng hạn như mức độ đầy đủ, mức tối thiểu và tính duy nhất) bằng các chỉ báo tùy chỉnh.
Làm sạch
Chúng tôi khuyên bạn nên xóa mọi tài nguyên có thể không được sử dụng để tránh phát sinh chi phí không mong muốn. Ví dụ, bạn có thể xóa miền Amazon DataZone và ứng dụng EMR bạn đã tạo trong quá trình này.
Kết luận
Trong bài đăng này, chúng tôi đã nêu bật các tính năng mới nhất của Amazon DataZone về chất lượng dữ liệu, trao quyền cho người dùng cuối với bối cảnh nâng cao và khả năng hiển thị đối với tài sản dữ liệu của họ. Hơn nữa, chúng tôi đã nghiên cứu sâu về khả năng tích hợp liền mạch giữa Amazon DataZone và Chất lượng dữ liệu AWS Glue. Bạn cũng có thể sử dụng API Amazon DataZone để tích hợp với các nhà cung cấp chất lượng dữ liệu bên ngoài, cho phép bạn duy trì chiến lược dữ liệu toàn diện và mạnh mẽ trong môi trường AWS của mình.
Để tìm hiểu thêm về Amazon DataZone, hãy tham khảo Hướng dẫn sử dụng Amazon DataZone.
Về các tác giả
 Andrea Filippo là Kiến trúc sư giải pháp đối tác tại AWS hỗ trợ các đối tác và khách hàng trong khu vực công ở Ý. Ông tập trung vào kiến trúc dữ liệu hiện đại và giúp khách hàng tăng tốc hành trình đám mây bằng công nghệ serverless.
Andrea Filippo là Kiến trúc sư giải pháp đối tác tại AWS hỗ trợ các đối tác và khách hàng trong khu vực công ở Ý. Ông tập trung vào kiến trúc dữ liệu hiện đại và giúp khách hàng tăng tốc hành trình đám mây bằng công nghệ serverless.
 Emanuele là Kiến trúc sư giải pháp tại AWS, có trụ sở tại Ý, sau hơn 5 năm sống và làm việc tại Tây Ban Nha. Anh ấy thích giúp đỡ các công ty lớn trong việc áp dụng công nghệ đám mây và lĩnh vực chuyên môn của anh ấy chủ yếu tập trung vào Phân tích dữ liệu và Quản lý dữ liệu. Ngoài công việc, anh thích đi du lịch và sưu tầm các nhân vật hành động.
Emanuele là Kiến trúc sư giải pháp tại AWS, có trụ sở tại Ý, sau hơn 5 năm sống và làm việc tại Tây Ban Nha. Anh ấy thích giúp đỡ các công ty lớn trong việc áp dụng công nghệ đám mây và lĩnh vực chuyên môn của anh ấy chủ yếu tập trung vào Phân tích dữ liệu và Quản lý dữ liệu. Ngoài công việc, anh thích đi du lịch và sưu tầm các nhân vật hành động.
 Varsha Velagapudi là Giám đốc sản phẩm kỹ thuật cấp cao của Amazon DataZone tại AWS. Cô tập trung vào việc cải thiện khả năng khám phá và quản lý dữ liệu cần thiết cho việc phân tích dữ liệu. Cô đam mê việc đơn giản hóa hành trình phân tích và AI/ML của khách hàng để giúp họ thành công trong các công việc hàng ngày. Ngoài công việc, cô thích thiên nhiên và các hoạt động ngoài trời, đọc sách và đi du lịch.
Varsha Velagapudi là Giám đốc sản phẩm kỹ thuật cấp cao của Amazon DataZone tại AWS. Cô tập trung vào việc cải thiện khả năng khám phá và quản lý dữ liệu cần thiết cho việc phân tích dữ liệu. Cô đam mê việc đơn giản hóa hành trình phân tích và AI/ML của khách hàng để giúp họ thành công trong các công việc hàng ngày. Ngoài công việc, cô thích thiên nhiên và các hoạt động ngoài trời, đọc sách và đi du lịch.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/amazon-datazone-now-integrates-with-aws-glue-data-quality-and-external-data-quality-solutions/

