Looking back, then forward, is a traditional exercise by year-end. Which data concerns are important enough to worry about in 2024? Which of those do we stand a chance of doing something good for in 2024? Needless to say, money (budget and costs) is an issue. But even more needless to say, solving real business challenges is probably more important. Remember that costs accumulate, and benefits can be annoyingly late in showing up. Some benefits even make it to the “Win or die trying” category.
It is, admittedly, not easy:
So, encouraged, what can we learn from the past?
I put these five concerns forward as being seriously interesting in 2024:
- Business results
- Subjects vs. processes
- Modeling: Reality or data?
- Informatics – why is that a European thing?
- Improving data modeling by improved cognition???
Business Results, Now or Never
Computing applied to business concerns goes back to the late 1960s. Data entry was initially Flexowriter paper tape (on an electric typewriter) and on punched cards. Complex algorithms were performed as multi-step sort/merge algorithms on magnetic tape to be replaced by direct access devices (disks) during the seventies.
Business use cases were pretty straightforward, and people like myself were quite busy over 10 to 15 years implementing bill-of-materials and materials requirement handling applications; on computers, which were purchased for those use cases. At prices from half a million dollars and up.
Invoicing was quickly added as a use case, but it started to prove difficult because of data quality issues (yes, already back then; customers are a difficult bunch).
Integration started to become an issue, which proved to be a heavy concern, because the early database systems were mostly used as point solutions for the domain applications. However, the vision of enterprise databases led to the triumph of SQL over network and indexed (ISAM/VSAM databases), because of the perceived flexibility of normalized databases over too-physical datamodels in older DBMSs.
In the seventies the so-called “DIKW Pyramid” started to appear everywhere:

The enterprise modeling visions also entered the code layers leading to object-oriented models (UML, OO) as well as OODBMS, which, however, failed to enter the mainline paths.
The hypothesis for this kind of construction and implementation of information systems was based on disciplines such as planning, governance, methods, involvement of business experts, and some technology (relational modeling, OO, etc.).
However, during the ’80s and ’90s, a realization spread itself around that these “siloes” were too difficult and too costly. New technologies such as mini-computers and personal computers, as well as OLAP and data warehousing, were thrown on the table to provide some relief for real business requirements.
Subjects Rather Than Processes
Well into the new century, ERP systems (like Oracle, SAP, and others) and huge data warehouses supported by analytics such as OLAP, SAS, and many more were, indeed, running most large enterprises. At a high cost, yes. And difficult to change, yes. However, the benefits of the high costs were defendable, if you ask me. Externalities happened in the beginning of this century, such as the growth of market-based investment thinking (new liberalism), a new macropolitical situation with a strong European Union, and key roles for China.
Globalization of enterprise activities happened quickly and continues today. This made the enterprises a whole lot more complex, coming out of mergers and acquisitions, conflicting product lines, contradictory business rules, etc. There was/is high pressure from investors requesting significantly shorter ROI cycles. Politics, ideology, and tumultuary dynamics all influenced what was traditionally conceived as (management/computer) science.
The success of large tech companies like Yahoo, Google, etc. in handling “big data” created ambitious expectations of “technology to the rescue.”
Consequently, technology was where people looked for solutions – think NoSQL, functional programming, and the “modern data stack.” Storage was now easy and cheap, whereas “computing” was just as cumbersome as before. AI became more powerful (yet still very expensive in computing costs and environmental consequences).
In 2024, there will (continue to) be a tremendous focus on the flow of data into the environment(s) where it is going to be used. (Both with and without AI, etc.) Under an umbrella such as “the modern data stack” and using tech newspeak such as “data engineering,” “data fabric,” “data mesh,” etc., data are being moved and transformed into mostly physical structures, suitable for algorithmic and statistical processing (aka AI).
The energy is intense, and tools are acquired and applied in numbers, which begins to match a shopping list for newlyweds for what you need in your kitchen. (Sorry, I couldn’t help it.) Have a look at this (coming from a very informative site called Our West Nest):

And the above is just the gadgets and tools category that you are recommended to have. Consult their site for the remainder of stuff that you need. So, now you know what it takes to be a “food engineer.” As for data engineering tooling, just check this overwhelming site!
Unfortunately, as any good cook will happily tell you, the tricks of the trade are in knowing your materials (the food) and how to combine and match tastes of good products, which you know where to find and how to treat. Translated to our realm, that means that you can apply lots and lots of engineering tools, but the job will only be done if you know the subjects of the business domains, know the business concerns, and solve the issues together with the businesspeople in federated scenarios.
Otherwise, you will probably not be a cost-effective solution provider. This is a business issue, not rocket (nor computer) science.
And knowing what the business is about is our next subject.
Modeling Reality: Knowledge, Not Data
Reality can be brutal: One of my favorite (real) horror stories is about a multinational B2C company that wanted to implement a new sales reporting scheme. We built it by collecting data from several ERP systems running in different countries – only to discover that the consolidated database was missing product category hierarchy information in more than 50% of the sales report lines! That delayed the project by several months, where young, tough controllers took turns visiting the different daughter companies … If they had known that beforehand, the project would probably have looked different.
Generative AI (GenAI) seems to appear on all front pages today. And on page 2 many people argue that in order to stop GenAI’s tendencies to hallucinate (make things up), you will have to help it along with a knowledge graph. That is a very good idea because graphs are close to business semantics.
Mike Dillinger has a very direct take on the need for knowledge graphs to make AI work somewhat better:
“For computer and data scientists, one way to motivate the use of knowledge graphs is to position them as a way to overcome the many shortcomings of representing data and knowledge in relational databases and manipulating it with linear machine learning models.
One big, bad, and dramatic simplifying assumption of databases is that columns are treated as independent or orthogonal. Machine learning techniques like classifiers make the same assumption: there are weights for each feature/variable but there are no terms to represent the covariance or interdependence between two or more features. The target classes for classifiers are also assumed to be disjoint or uncorrelated, which is why classifiers perform poorly in deciding between hierarchically related classes – they’re not disjoint, rather one subsumes the other. Making believe that variables are unrelated when they actually are related simply inflates error variance to intolerable levels.”
Also, from one of Dillinger’s slides: “Why use knowledge graphs? Because math is literally, intentionally, absolutely meaningless. And logic is, too.”
Making business impact is where it starts and where it ends.
AI must produce reliable propositions. Why not ask for certification?
More Informatics, Less Tech
The following is not a big issue, but unprecise terminology seems to have infected our “guild.”
I started at the University of Copenhagen in 1969. My professor was Peter Naur, who is best known for things like:
- Co-author with Edsger Dijkstra et al. on the Algol-60 programming language
- The “N” in BNF, the Backus-Naur-Form used in a lot of language definitions
- He did not want to be called a “computer scientist,” he preferred “Datalogy” instead of “Computer Science” – the reason being that the two domains (computers and human knowing) are very different and his interest was in data, which is created and described by us as humans
- In his book “Computing: A Human Activity” (1992), a collection of his contributions to computer science, he rejected the school of programming that views programming as a branch of mathematics
- Computer Pioneer Award of the IEEE Computer Society (1986)
- 2005 Turing Award winner, the title of his award lecture was “Computing Versus Human Thinking”
(See more background here.)
In reality, we have three competing terms:
- Computer science
- Informatics
- Information science
“Information science” classically means the kind of information handling that librarians and archivists do. Today it is all digital …
“Informatics” is used instead of computer science in large parts of Europe and other countries. In the U.S. et al., informatics is frequently used as dealing with information in healthcare.
And then there is “computer science.” Academically, today, it is very mathematical and abstract, founded on logic and functions. However, it is frequently described as a set of skills, which are used in handling data. But the direct semantics, “how to construct computers,” is not in scope anymore; I would expect engineers and physicists to take care of that.
If I construct highways, I may use special highway-relevant skills. But does that make me a “highway scientist”? Not so.
In Communications of the ACM (Association for Computing Machinery, login required), Peter Denning, former president of the ACM, argues for and against computer “science” in an article titled “Is Computer Science Science? Computer science meets every criterion for being a science, but it has a self-inflicted credibility problem,” 2005, as he concludes:
“Validate Computer Science Claims
There you have us. We have allowed the hype of advertising departments to infiltrate our laboratories. In a sample of 400 computer science papers published before 1995, Walter Tichy found that approximately 50% of those proposing models or hypotheses did not test them [12]. In other fields of science the fraction of papers with untested hypotheses was about 10%. Tichy concluded that our failure to test more allowed many unsound ideas to be tried in practice and lowered the credibility of our field as a science. …
The perception of our field seems to be a generational issue. The older members tend to identify with one of the three roots of the field—science, engineering, or mathematics. The science paradigm is largely invisible within the other two groups.
The younger generation, much less awed than the older one once was with new computing technologies, is more open to critical thinking. Computer science has always been part of their world; they do not question its validity. In their research, they are increasingly following the science paradigm.”
The reference to Tichy is: Tichy, W. Should computer scientists experiment more. IEEE Computer 1998.
Makes you wonder: Are we still allowing ”the hype of advertising departments to infiltrate our laboratories”?
I think “informatics” is the most general, and precise, term for what we do. Computing is a human activity and informatics describes the human activities of handling information for and by humans.
Yes, I do feel better now, thank you!
Looking Ahead: Improving Cognition
Data Modeling in the Future?
As some of my readers will remember, I am a (graph) data modeler by heart, with many years of modeling behind me. I am also a stout advocate for applying informatics to business concerns – making business problem resolution the key thing that we do. We have suffered from the cost/benefit discussions of the last 15 to 25 years.
People also tend to believe that data modeling is at the end of the road, say no more. What could possibly be done to make it more productive and produce higher quality? It was developed in the 1970s, mind you. How much else from the ’70s has survived? (Well, just teasing: Relational modeling survived …)
As for any theory, you will have to challenge the assumptions. Data modeling, as we know it now, is very engineering-oriented with complex diagrams, which are not too intimate with the best wishes of its consumers. In many ways, it is still “blueprints” based on axiomatic paradigms such as database normalization, etc. – meant for the construction of physical constructs such as databases. The exception is on the informatics side of the house, where semantic models (graphs) have quite some success because of expressiveness, precision, and relative ease of use (read: “knowledge graphs”).
Strong, Forward-Looking Research Exists
So, is this the end of the journey? Will JSON take over the whole gamut of data models?
I think not. Data modeling, with semantics, is an open-ended research area. Traditional computer science-based data modeling was based on rather narrow axioms and paradigms – supposedly strengthened by logic and abstractions.
But semantics and cognition open the door to a very large universe of discourse. In fact, what data modeling tried to do over the years was to get into the realms of cognitive science (psychology, clinical, and philosophical).
Data models are interpretations of the world as perceived by our senses, forming the cognition of everything that we see and experience. This is the open road forward!
And what are we looking at, then? Let us, for the fun of it, call it a “Cognitive Positioning System” (CPS). Have a look:

Experienced CPS users who travel will note that the photo is from Paris, France. Some will even know that the river is known by the name The Seine.
Survival by Visual Cognition
The basic cognitive capabilities of most animals, including me, aim to understand, first and foremost, situations like this:

Oops, a lion! (male), not really trying to hide in the grass – you got that right! But not a rich context to make decisions from. Follow your instincts (running back to the car is a fine idea).
And here is another context:

Oops – another lion! This time a female, and she probably has a full stomach. A little more context to work with. The beast (wildebeest?) has almost been eaten already. Inference: She is not hungry at this time. Take a picture and back off, nice and quiet – seems safe enough for a world-class photographer like you …
There is a rich portfolio of academic research on these matters. We evolved to deal with on-the-spot, now-and-here understanding of the context, as presented to us by a continuing flow of senses (perception) arriving in our cognitive processing units in the brain. It goes from basic psychology over neuropsychology over cognitive neuroscience over even, intelligence, consciousness, and philosophy.
I have been following various researchers and writers over the last 10 years, and here we will look at a small cavalcade of interesting observations.
Maps
Clearly, maps are parts of this quest for easing attention and understanding. Here is (the centre of) the London Underground map:
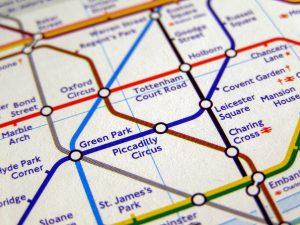
Now, first of all, maps have a number of qualia, as illustrated above:
- Locations are mapped
- Relationships or paths, if you will, are mapped
- Maps are graphs, graphs are maps!
- Maps make intutitive sense
Notice also that on the map, locations/landmarkers are noted. However, if you have forgotten what is close to the Sloane Square tube station, you can always get up into the daylight and see if your CPS will recognize the surroundings (= context) for you. Something like “Oh, yes, over there in the little shop in the yellow house is where we bought the red bandana for Ellen on our honeymoon.”
Thinking in map allegories when you create data models is simple and powerful. That is why I abandoned ER-diagrams and UML class diagrams years ago.
On Placeholders/Location Marks/Names of Places
Finding your way is a bit more than maps and cognitive intuitions. In his excellent book, “Wayfinding,” Picador MacMillan 2020, Michael Bond (science journalist, previous senior editor of New Scientist), has some astonishing observations and revelations.
He quotes anthropologist Ariane Burke for saying that there is archaeological evidence that early modern humans had extensive social networks. “Those far-flung networks were essential to our culture,” she explained in a phone call. “Remember that during the Palaeolithic, there were comparatively few people around. … Maintaining a spatially extensive social network was a way of ensuring your continued survival. You would need a very dynamic cognitive map, which you would constantly have to update with information about your contacts and what they were telling you about the landscape.”
Bond also mentions the use of topographical place names – toponyms. For example, if you head north-west from his parents’ farm in Scotland, you meet “confluence of the bright and shining streams,” and follow the old cattle trail “rock of the birds.” A mile or so farther you meet “great black hill,” and crossing the “red stream.” Directly ahead is the “hillock of the battle.” After a climb you’ll find yourself on the “hill of the cloudberries” (they still grow there).
Historians believe that topographical place names gave early settlers a geographical reference system, a precursor of latitude and longitude. A descriptive name prompts a mental image – you’ll recognize that “grassy eminence on a knoll” (Funtulich, in Gaelic) when you see it. A sequence of place names constitutes a set of directions: so equipped, you can make your journey.
Farther north, to the Iniut people of northern Canada, Alaska, and Greenland. When the explorer George Francis Lyon passed through the hamlet of Igloolik in the Canadian Arctic in 1822, in search of the North-west Passage, he noted that “every streamlet, lake, bay, point, or island has a name, and even certain piles of stones.“
To an outsider, the Arctic can look featureless and monotonous. … on the southern heel of Baffin Island you will find Nuluujaak, or “two islands that look like buttocks.“ Hard to miss. Farther up the coast, you’ll know exactly where you are when you see Qumanguaq, “the shrugging hill (no neck).“
This approach to naming places is very different to the one taken by the first European explorers of the Americas, who tended to celebrate friends, backers, or notables from their homeland rather than local topography or culture.
How We Navigate
Before we leave Michael Bond, here are some remarks that are worth thinking about:
“Humans are blessed with an inner navigator that is immeasurably more sophisticated and capable than any artificial system. How do we use it?
Psychologists have found that, when finding their way through unfamiliar terrain, people follow one of two strategies: either they relate everything to their own position in space, the ‘egocentric’ approach, or they rely on the features of the landscape and how they relate to each other to tell them where they are, the ‘spatial’ approach.”
Another set of observations that I find interesting is how we actually go about in landscapes and follow routes. Seems that boundaries are just as important as locations. And I suspect that that can be generalized into constructed “landscapes,” where boundaries might ease navigation considerably (and intuitively).
I highly recommend ”Wayfinding” by Michael Bond.
Motion, Spatial
The next book I will mention is ”Mind in Motion: How Action Shapes Thought” by Barbara Tversky (prof. emerita in psychology at Stanford) from 2019.
In many ways, it is framed by the same findings as Michael Bond reported on.
People, like most creatures, move from place to place. As they move, they leave traces, on the ground, in the brain, paths and places. The Hippocampus records movements as routes, strings of places and paths. This is, in fact, The Nobel Prize in Physiology or Medicine 2014, which was awarded one half to John O’Keefe, the other half jointly to May-Britt Moser and Edvard I. Moser “for their discoveries of cells that constitute a positioning system in the brain.” The cells are called grid cells and are used as markers working with the hippocampi in creating spatial constructs in the brain.
Barbara Tversky has a broader perspective – she wants to prove that motion recorded spatially in the mind is the platform for thought. Not only graphs, but also words, gestures, and graphics. They also promote inference and discovery, allow creation, revision, and inference by community. Categorization is a mental simplification across the complete picture perceived. Certainly prof. Tversky has researched many aspects of these things in her psychology lab at Stanford and at Columbia University.
Space has meaning, proximity means closeness on any dimension. Vertical: up, everything good, horizontal: neutral. Space is special, supra-modal and essential to survival, basis for other knowledge. Supported by gestures.
In other words, the communication from the mind is easily recognizable and it should be obvious to the consumer, how it (the communication) can help with the tasks that are important in the context. Sounds like good recommendations for how to enhance data models in the future!
“Mind in Motion: How Action Shapes Thought” is a seminal work in the cognitive science space. There is an excellent YouTube video (Spatial Thinking is the Foundation of Thought) with her from 2022, here.
Cognition in the Brain (Left and Right)
One of the most important, carefully researched books on cognitive matters is “The Matter with Things: Our Brains, Our Delusions, and the Unmaking of the World” by psychiatrist, neuroscience researcher, philosopher, and literary scholar Dr. Ian McGilchrist, Perspectiva, 2021.
In his own words:
”Effectively, there aren’t parts. Parts are an artefact of a certain way of attending to the world. There are only wholes. And things that we think of as parts, are wholes at another level, and things that we think of as wholes, can be seen as parts of an even bigger whole.
But this business of carving things up into parts is an artefact of the left hemisphere’s piecemeal attention. So because it’s trying to focus on this small detail, it’s homing in on a certain little tiny bit, perhaps three out of the 360 degrees arc of attention, and that leads to a different take on the world from that of the right hemisphere.”
The Pedantic Left Hemisphere and the Intuitive Right Hemisphere
The division of labor between our two brain hemispheres can be summarized by a few examples:
| Left | Right |
| known | new |
| certainty | possibility |
| fixity | flow |
| parts | whole |
| explicit | implicit |
| abstracted | contextual |
| general | unique |
| quantification | qualification |
| inanimate | animate |
| optimistic | realistic |
| re-presented | present |
The reasons for the dichotomy are evolutionary. The simplified explanation roughly corresponds to the two lion photos up above. One is “Oh, I know what that is,” and the other is, “Help, I’d better run!” Both reactions are quite useful.
Here is a very interesting YouTube lecture: Dr. Iain McGilchrist spoke at the IdeaSquare innovation space of CERN to discuss the nature of reality from the perspective of the human brain and philosophy. The event was hosted in conjunction with a pilot course equipping students with big-scale systems thinking abilities and how to induce societal change. He also maintains a website here.
His latest book, “The Matter with Things,” is two volumes, 1,300 pages in all. Should keep you busy for a while!
I hope that I have convinced you that we have several opportunities to get better at understanding what data models are about? Keep your eyes open! Communicate using intuition! May 2024 be the year where innovative evolution makes all that data stuff easier!
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.dataversity.net/handling-data-concerns-in-2024-and-onwards/

