Mục lục
- Câu hỏi phỏng vấn Python dành cho người làm mới
- 1. Python là gì?
- 2. Tại sao lại là Python?
- 3. Làm thế nào để cài đặt Python?
- 4. Các ứng dụng của Python là gì?
- 5. Ưu điểm của Python là gì?
- 6. Các tính năng chính của Python là gì?
- 7. Bạn hiểu nghĩa đen của Python là gì?
- 8. Python là loại ngôn ngữ nào?
- 9. Python là một ngôn ngữ thông dịch như thế nào?
- 10. pep 8 là gì?
- 11. Không gian tên trong Python là gì?
- 12. PYTHON PATH là gì?
- 13. Mô-đun Python là gì?
- 14. Biến cục bộ và biến toàn cục trong Python là gì?
- 15. Giải thích Flask là gì và lợi ích của nó?
- 16. Django có tốt hơn Flask không?
- 17. Đề cập đến sự khác biệt giữa Django, Pyramid và Flask.
- 18. Thảo luận về kiến trúc Django
- 19. Giải thích Phạm vi trong Python?
- 20. Liệt kê các kiểu dữ liệu dựng sẵn phổ biến trong Python?
- 21. Các thuộc tính toàn cầu, bảo vệ và riêng tư trong Python là gì?
- 22. Từ khóa trong Python là gì?
- 23. Sự khác biệt giữa danh sách và bộ giá trị trong Python là gì?
- 24. Làm thế nào bạn có thể nối hai bộ giá trị?
- 25. Hàm trong Python là gì?
- 26. Làm thế nào bạn có thể khởi tạo một mảng 5 * 5 numpy chỉ có các số XNUMX?
- 27. Gấu trúc là gì?
- 28. Khung dữ liệu là gì?
- 29. Chuỗi Pandas là gì?
- 30. Bạn hiểu gì về gấu trúc groupby?
- 31. Cách tạo khung dữ liệu từ danh sách?
- 32. Cách tạo khung dữ liệu từ từ điển?
- 33. Làm thế nào để kết hợp các khung dữ liệu trong gấu trúc?
- 34. Loại gia nhập nào mà gấu trúc cung cấp?
- 35. Làm thế nào để hợp nhất các khung dữ liệu trong gấu trúc?
- 36. Cho khung dữ liệu dưới đây thả tất cả các hàng có Nan.
- 37. Làm thế nào để truy cập năm mục đầu tiên của khung dữ liệu?
- 38. Làm thế nào để truy cập năm mục cuối cùng của khung dữ liệu?
- 39. Làm thế nào để tìm nạp một mục nhập dữ liệu từ khung dữ liệu gấu trúc bằng cách sử dụng một giá trị nhất định trong chỉ mục?
- 40. Nhận xét là gì và bạn có thể thêm nhận xét bằng Python như thế nào?
- 41. Từ điển trong Python là gì? Cho một ví dụ.
- 42. Sự khác biệt giữa bộ dữ liệu và từ điển là gì?
- 43. Tìm hiểu giá trị trung bình, trung vị và độ lệch chuẩn của mảng numpy này -> np.array ([1,5,3,100,4,48])
- 44. Bộ phân loại là gì?
- 45. Trong Python, làm thế nào để bạn chuyển đổi một chuỗi thành chữ thường?
- 46. Làm thế nào để bạn có được danh sách tất cả các khóa trong từ điển?
- 47. Làm thế nào bạn có thể viết hoa chữ cái đầu tiên của một chuỗi?
- 48. Làm thế nào bạn có thể chèn một phần tử tại một chỉ mục nhất định trong Python?
- 49. Làm thế nào bạn sẽ loại bỏ các phần tử trùng lặp khỏi một danh sách?
- 50. Đệ quy là gì?
- 51. Giải thích hiểu danh sách Python.
- 52. Hàm byte () là gì?
- 53. Các loại toán tử khác nhau trong Python là gì?
- 54. Câu lệnh 'with' là gì?
- 55. Hàm map () trong Python là gì?
- 56. __init__ trong Python là gì?
- 57. Các công cụ hiện có để thực hiện phân tích tĩnh?
- 58. Pass trong Python là gì?
- 59. Làm thế nào một đối tượng có thể được sao chép trong Python?
- 60. Làm thế nào một số có thể được chuyển đổi thành một chuỗi?
Bạn có phải là Nhà phát triển Python đầy tham vọng không? Sự nghiệp trong Python đã chứng kiến một xu hướng đi lên vào năm 2023 và bạn có thể là một phần của cộng đồng ngày càng phát triển. Vì vậy, nếu bạn đã sẵn sàng đắm mình trong kho kiến thức và chuẩn bị cho cuộc phỏng vấn với trăn sắp tới, thì bạn đang ở đúng nơi.
Chúng tôi đã biên soạn một danh sách đầy đủ các Câu hỏi và Câu trả lời Phỏng vấn Python sẽ hữu ích vào thời điểm cần thiết. Khi bạn đã chuẩn bị sẵn sàng cho các câu hỏi mà chúng tôi đề cập trong danh sách của mình, bạn sẽ sẵn sàng đảm nhận nhiều vai trò công việc về python như Nhà phát triển python, Nhà khoa học dữ liệu, Kỹ sư phần mềm, Quản trị viên cơ sở dữ liệu, Người kiểm tra đảm bảo chất lượng, v.v.
Lập trình Python có thể đạt được một số chức năng với một vài dòng mã và hỗ trợ tính toán mạnh mẽ bằng các thư viện mạnh mẽ. Do những yếu tố này, nhu cầu về các chuyên gia có kiến thức lập trình Python ngày càng tăng. Kiểm tra miễn phí khóa học trănđể tìm hiểu thêm
Blog này bao gồm các Câu hỏi phỏng vấn Python thường gặp nhất sẽ giúp bạn nhận được những lời mời làm việc tuyệt vời.
Các câu hỏi được chia thành nhiều loại, như được liệt kê dưới đây:
- Câu hỏi phỏng vấn Python dành cho người làm mới
- Câu hỏi phỏng vấn Python cho người có kinh nghiệm
- Câu hỏi phỏng vấn lập trình Python
- Câu hỏi thường gặp về câu hỏi phỏng vấn Python
Câu hỏi phỏng vấn Python dành cho người làm mới
Phần Câu hỏi phỏng vấn Python dành cho người mới bắt đầu này bao gồm hơn 70 câu hỏi thường được hỏi trong quá trình phỏng vấn. Là một người mới hơn, bạn có thể chưa quen với quá trình phỏng vấn; tuy nhiên, học những câu hỏi này sẽ giúp bạn trả lời người phỏng vấn một cách tự tin và vượt qua cuộc phỏng vấn sắp tới của bạn.
1. Python là gì?
Python được tạo ra và phát hành lần đầu tiên vào năm 1991 bởi Guido van Rossum. Đây là ngôn ngữ lập trình cấp cao, có mục đích chung, nhấn mạnh khả năng đọc mã và cung cấp cú pháp dễ sử dụng. Một số nhà phát triển và lập trình viên thích sử dụng Python cho nhu cầu lập trình của họ do tính đơn giản của nó. Sau 30 năm, Van Rossum từ chức lãnh đạo cộng đồng vào năm 2018.
Trình thông dịch Python có sẵn cho nhiều hệ điều hành. CPython, triển khai tham chiếu của Python, là phần mềm nguồn mở và có mô hình phát triển dựa trên cộng đồng, cũng như gần như tất cả các triển khai biến thể của nó. Tổ chức phi lợi nhuận Python Software Foundation quản lý Python và CPython.
2. Tại sao lại là Python?
Python là một ngôn ngữ lập trình cấp cao, có mục đích chung. Python là ngôn ngữ lập trình có thể được sử dụng để tạo các ứng dụng GUI, trang web và ứng dụng trực tuyến trên máy tính để bàn. Là ngôn ngữ lập trình cấp cao, Python cũng cho phép bạn tập trung vào chức năng thiết yếu của ứng dụng trong khi xử lý các nhiệm vụ lập trình thông thường. Các giới hạn ngữ pháp cơ bản của ngôn ngữ lập trình giúp dễ dàng hơn đáng kể để duy trì cơ sở mã dễ hiểu và ứng dụng có thể quản lý được.
3. Làm thế nào để cài đặt Python?
Để cài đặt Python, hãy truy cập Anaconda.org và nhấp vào “Tải xuống Anaconda”. Tại đây, bạn có thể tải xuống phiên bản Python mới nhất. Sau khi Python được cài đặt, quá trình này khá đơn giản. Bước tiếp theo là khởi động một IDE và bắt đầu viết mã bằng Python. Nếu bạn muốn tìm hiểu thêm về quy trình, hãy xem điều này Hướng dẫn Python. Kiểm tra Làm thế nào để cài đặt trăn.
Kiểm tra hình ảnh minh họa cài đặt python này.
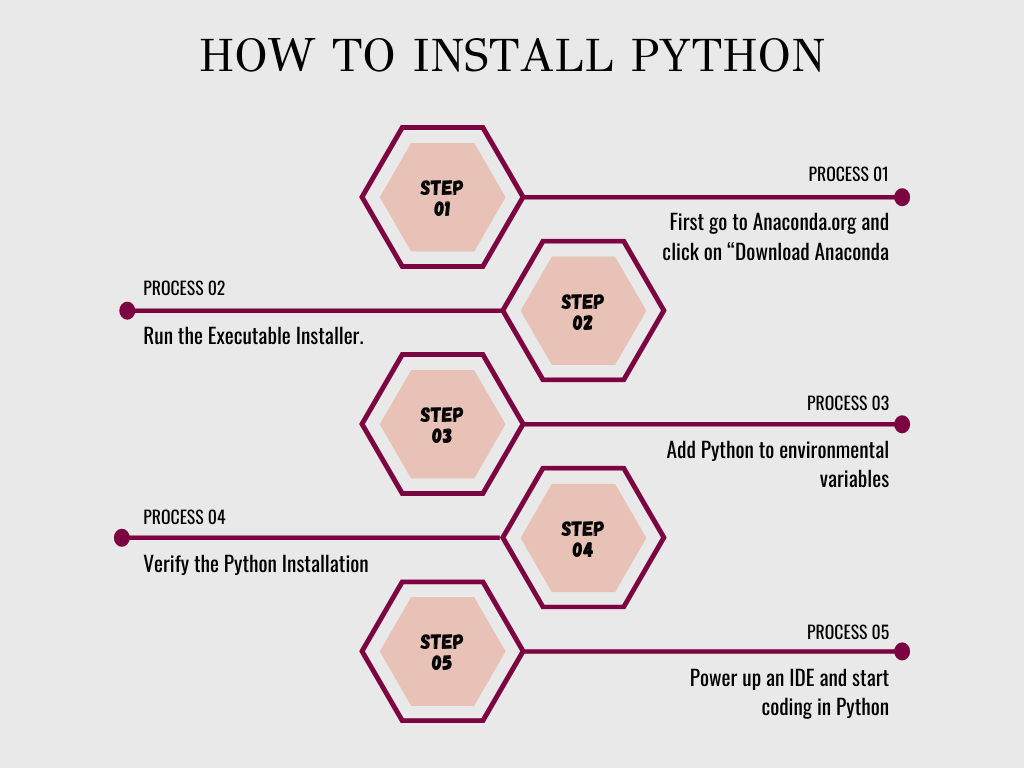
4. Các ứng dụng của Python là gì?
Python đáng chú ý vì đặc tính có mục đích chung của nó, cho phép nó được sử dụng trong thực tế bất kỳ lĩnh vực phát triển phần mềm nào. Python có thể được tìm thấy trong hầu hết mọi lĩnh vực mới. Đây là ngôn ngữ lập trình phổ biến nhất và có thể được sử dụng để tạo bất kỳ ứng dụng nào.
- Ứng dụng web
Chúng ta có thể sử dụng Python để phát triển các ứng dụng web. Nó chứa các thư viện HTML và XML, thư viện JSON, thư viện xử lý email, thư viện yêu cầu, súp đẹp thư viện, thư viện Feedparser và các giao thức internet khác. Instagram sử dụng Django, một khuôn khổ web Python.
- Ứng dụng GUI trên máy tính để bàn
Giao diện người dùng đồ họa (GUI) là giao diện người dùng cho phép tương tác dễ dàng với bất kỳ chương trình nào. Python chứa khung Tk GUI để tạo giao diện người dùng.
- Ứng dụng dựa trên bảng điều khiển
Dòng lệnh hoặc trình bao được sử dụng để thực thi các chương trình dựa trên bảng điều khiển. Đây là những chương trình máy tính được sử dụng để thực hiện các đơn đặt hàng. Loại chương trình này phổ biến hơn trong thế hệ máy tính trước. Nó nổi tiếng với REPL hay còn gọi là Read-Eval-Print Loop, lý tưởng cho các ứng dụng dòng lệnh.
Python có một số thư viện và mô-đun miễn phí giúp tạo các ứng dụng dòng lệnh. Để đọc và ghi, các thư viện IO thích hợp được sử dụng. Nó có khả năng xử lý các tham số và tạo văn bản trợ giúp bảng điều khiển được tích hợp sẵn. Có các thư viện nâng cao bổ sung có thể được sử dụng để tạo các ứng dụng bảng điều khiển độc lập.
- Phát triển phần mềm
Python rất hữu ích cho quá trình phát triển phần mềm. Đó là một ngôn ngữ hỗ trợ có thể được sử dụng để thiết lập kiểm soát và quản lý, thử nghiệm và những thứ khác.
- SCons được sử dụng để xây dựng kiểm soát.
- Quá trình biên dịch và kiểm tra liên tục được tự động hóa bằng Buildbot và Apache Gumps.
- Khoa học và Số
Đây là thời của trí tuệ nhân tạo, trong đó một cỗ máy có thể thực thi các nhiệm vụ tốt như một con người có thể. Python là một ngôn ngữ lập trình tuyệt vời cho các ứng dụng trí tuệ nhân tạo và máy học. Nó có một số thư viện khoa học và toán học giúp việc thực hiện các phép tính khó trở nên đơn giản.
Đưa các thuật toán học máy vào thực tế đòi hỏi rất nhiều phép tính số học. Numpy, Pandas, Scipy, Scikit-learning và các ứng dụng khoa học và số khác Thư viện Python có sẵn. Nếu bạn biết cách sử dụng Python, bạn sẽ có thể nhập các thư viện ở đầu mã. Một vài khung thư viện máy nổi bật được liệt kê bên dưới.
- Ứng dụng kinh doanh
Các ứng dụng tiêu chuẩn không giống như các ứng dụng kinh doanh. Loại chương trình này đòi hỏi rất nhiều khả năng mở rộng và khả năng đọc mà Python mang lại.
Oddo là một ứng dụng tất cả trong một dựa trên Python, cung cấp một loạt các ứng dụng kinh doanh. Ứng dụng thương mại được xây dựng trên nền tảng Tryton do Python cung cấp.
- Ứng dụng dựa trên âm thanh hoặc video
Python là một ngôn ngữ lập trình đa năng có thể được sử dụng để xây dựng các ứng dụng đa phương tiện. TimPlayer, cplay và các chương trình đa phương tiện khác được viết bằng Python là những ví dụ.
- Ứng dụng CAD 3D
Kiến trúc liên quan đến kỹ thuật được thiết kế bằng CAD (Thiết kế hỗ trợ máy tính). Nó được sử dụng để tạo ra một hình ảnh trực quan ba chiều của một thành phần hệ thống. Các tính năng sau trong Python có thể được sử dụng để phát triển ứng dụng CAD 3D:
- Fandango (Phổ biến)
- CAMVOX
- GótCNC
- AnyCAD
- RCAM
- Ứng dụng Doanh nghiệp
Python có thể được sử dụng để phát triển các ứng dụng để sử dụng trong một doanh nghiệp hoặc tổ chức. OpenERP, Tryton, Picalo tất cả các ứng dụng thời gian thực này là ví dụ.
- Ứng dụng xử lý hình ảnh
Python có rất nhiều thư viện để làm việc với ảnh. Hình ảnh có thể được thay đổi theo thông số kỹ thuật của chúng tôi. OpenCV, Gối và SimpleITK đều là các thư viện xử lý ảnh có trong python. Trong chủ đề này, chúng ta đã đề cập đến nhiều loại ứng dụng trong đó Python đóng vai trò quan trọng trong quá trình phát triển của chúng. Chúng ta sẽ nghiên cứu thêm về các nguyên tắc của Python trong hướng dẫn sắp tới.
5. Ưu điểm của Python là gì?
Python là một ngôn ngữ lập trình động có mục đích chung ở mức cao và được thông dịch. Khung kiến trúc của nó ưu tiên khả năng đọc mã và sử dụng thụt lề rộng rãi.
- Các mô-đun của bên thứ ba hiện diện.
- Một số thư viện hỗ trợ có sẵn (NumPy để tính toán số, Pandas để phân tích dữ liệu, v.v.)
- Phát triển cộng đồng và nguồn mở
- Thích ứng, dễ đọc, học và viết
- Cấu trúc dữ liệu khá dễ làm việc
- Ngôn ngữ cấp cao
- Ngôn ngữ được nhập động (Không cần đề cập đến kiểu dữ liệu dựa trên giá trị được gán, nó có kiểu dữ liệu)
- Ngôn ngữ lập trình hướng đối tượng
- Tương tác và có thể vận chuyển
- Lý tưởng cho các nguyên mẫu vì nó cho phép bạn thêm các tính năng bổ sung với mã tối thiểu.
- Hiệu quả cao
- Khả năng của Internet of Things (IoT)
- Ngôn ngữ thông dịch di động trên các hệ điều hành
- Vì nó là một ngôn ngữ được thông dịch nên nó thực thi bất kỳ dòng mã nào từng dòng và ném ra một lỗi nếu nó tìm thấy thứ gì đó bị thiếu.
- Python được sử dụng miễn phí và có một cộng đồng mã nguồn mở lớn.
- Python có rất nhiều hỗ trợ cho các thư viện cung cấp nhiều chức năng để thực hiện bất kỳ tác vụ nào trong tầm tay.
- Một trong những tính năng tốt nhất của Python là tính di động của nó: nó có thể và chạy trên bất kỳ nền tảng nào mà không cần phải thay đổi các yêu cầu.
- Cung cấp nhiều chức năng trong các dòng mã ít hơn so với các ngôn ngữ lập trình khác như Java, C ++, v.v.
Bẻ khóa cuộc phỏng vấn Python của bạn
6. Các tính năng chính của Python là gì?
Python là một trong những ngôn ngữ lập trình phổ biến nhất được các nhà khoa học dữ liệu và các chuyên gia AIML sử dụng. Sự phổ biến này là do các tính năng chính sau của Python:
- Python rất dễ học do cú pháp rõ ràng và dễ đọc
- Python dễ diễn giải, giúp gỡ lỗi dễ dàng
- Python miễn phí và là mã nguồn mở
- Nó có thể được sử dụng trên các ngôn ngữ khác nhau
- Nó là một ngôn ngữ hướng đối tượng hỗ trợ các khái niệm về các lớp
- Nó có thể được tích hợp dễ dàng với các ngôn ngữ khác như C ++, Java, v.v.
7. Bạn hiểu nghĩa đen của Python là gì?
Một nghĩa đen là một hình thức đơn giản và trực tiếp để thể hiện một giá trị. Chữ phản ánh các tùy chọn kiểu nguyên thủy có sẵn trong ngôn ngữ đó. Số nguyên, số dấu phẩy động, Booleans và chuỗi ký tự là một số dạng chữ phổ biến nhất. Python hỗ trợ các chữ sau:
Chữ viết trong Python liên quan đến dữ liệu được giữ trong một biến hoặc hằng số. Có một số loại chữ có trong Python
Chuỗi chữ: Đó là một chuỗi các ký tự được bao bọc trong một bộ mã. Tùy thuộc vào số lượng trích dẫn được sử dụng, có thể có chuỗi đơn, chuỗi kép hoặc chuỗi ba. Các ký tự đơn được bao quanh bởi các dấu ngoặc kép đơn hoặc kép được gọi là các ký tự ký tự.
Chữ số: Đây là những số không thay đổi được có thể được chia thành ba loại: số nguyên, số thực và số phức.
Boolean chữ: Đúng hoặc Sai, biểu thị '1' và '0' tương ứng, có thể được gán cho chúng.
Chữ viết đặc biệt: Nó được sử dụng để phân loại các trường chưa được tạo. 'Không có' là giá trị được sử dụng để đại diện cho nó.
- Chuỗi ký tự: “hào quang”, '12345'
- Các ký tự int: 0,1,2, -1, -2
- Chữ dài: 89675L
- Chữ nổi: 3.14
- Chữ phức tạp: 12j
- Các ký tự Boolean: Đúng hay Sai
- Chữ đặc biệt: Không có
- Chữ Unicode: u "xin chào"
- Liệt kê các ký tự: [], [5, 6, 7]
- Tuple chữ: (), (9,), (8, 9, 0)
- Các ký tự chính xác: {}, {'x': 1}
- Đặt các chữ: {8, 9, 10}
8. Python là loại ngôn ngữ nào?
Python là một ngôn ngữ lập trình hướng đối tượng, tương tác, được thông dịch. Tất cả các lớp, mô-đun, ngoại lệ, nhập động và kiểu dữ liệu động cấp cực cao đều có mặt.
Python là một ngôn ngữ thông dịch với kiểu gõ động. Bởi vì mã không được chuyển đổi sang dạng nhị phân, những ngôn ngữ này đôi khi được gọi là ngôn ngữ "kịch bản". Trong khi tôi nói là nhập động, tôi đang đề cập đến thực tế là các kiểu không cần phải được nêu khi viết mã; trình thông dịch tìm thấy chúng trong thời gian chạy.
Khả năng đọc cú pháp ngắn gọn, dễ học của Python được ưu tiên, giảm chi phí bảo trì phần mềm. Python cung cấp các mô-đun và gói, cho phép sử dụng lại mô-đun chương trình và mã. Trình thông dịch Python và thư viện tiêu chuẩn toàn diện của nó được tải xuống và phân phối miễn phí ở dạng nguồn hoặc nhị phân cho tất cả các nền tảng chính.
9. Python là một ngôn ngữ thông dịch như thế nào?
Trình thông dịch lấy mã của bạn và thực thi (thực hiện) các hành động bạn cung cấp, tạo ra các biến bạn chỉ định và thực hiện nhiều công việc hậu trường để đảm bảo mã hoạt động trơn tru hoặc cảnh báo bạn về các vấn đề.
Python không phải là một ngôn ngữ được thông dịch hoặc biên dịch. Thuộc tính của triển khai là liệu nó có được thông dịch hay biên dịch hay không. Python là một mã bytecode (một tập hợp các hướng dẫn có thể đọc được của trình thông dịch) có thể được diễn giải theo nhiều cách khác nhau.
Mã nguồn được lưu trong một tệp .py.
Python tạo ra một tập hợp các hướng dẫn cho một máy ảo từ mã nguồn. Định dạng trung gian này được gọi là “bytecode” và nó được tạo ra bằng cách biên dịch mã nguồn.py thành .pyc, là bytecode. Bytecode này sau đó có thể được thông dịch bởi trình thông dịch CPython tiêu chuẩn hoặc JIT (trình biên dịch Just in Time) của PyPy.
Python được biết đến như một ngôn ngữ thông dịch vì nó sử dụng trình thông dịch để chuyển đổi mã bạn viết thành ngôn ngữ mà bộ xử lý máy tính của bạn có thể hiểu được. Sau đó, bạn sẽ tải xuống và sử dụng trình thông dịch Python để có thể tạo mã Python và thực thi nó trên máy tính của riêng bạn khi làm việc trong một dự án.
10. pep 8 là gì?
PEP 8, thường được gọi là PEP8 hoặc PEP-8, là tài liệu phác thảo các phương pháp hay nhất và khuyến nghị để viết mã Python. Nó được viết vào năm 2001 bởi Guido van Rossum, Barry Warsaw và Nick Coghlan. Mục tiêu chính của PEP 8 là làm cho mã Python dễ đọc và nhất quán hơn.
Đề xuất Nâng cao Python (PEP) là từ viết tắt của Đề xuất Nâng cao Python và có rất nhiều trong số đó. Đề xuất cải tiến Python (PEP) là tài liệu giải thích các tính năng mới được đề xuất cho Python và chi tiết các yếu tố của Python cho cộng đồng, chẳng hạn như thiết kế và kiểu dáng.
11. Không gian tên trong Python là gì?
Trong Python, không gian tên là một hệ thống gán một tên duy nhất cho mỗi và mọi đối tượng. Một biến hoặc một phương thức có thể được coi là một đối tượng. Python có không gian tên riêng của nó, không gian này được giữ ở dạng một từ điển Python. Hãy xem cấu trúc hệ thống thư mục-tệp trong máy tính làm ví dụ. Không cần phải nói rằng một tệp có cùng tên có thể được tìm thấy trong nhiều thư mục. Tuy nhiên, bằng cách cung cấp đường dẫn tuyệt đối của tệp, người ta có thể chuyển đến nó nếu muốn.
Không gian tên về cơ bản là một kỹ thuật để đảm bảo rằng tất cả các tên trong một chương trình là khác biệt và có thể được sử dụng thay thế cho nhau. Bạn có thể đã biết rằng mọi thứ trong Python đều là một đối tượng, bao gồm chuỗi, danh sách, hàm, v.v. Một điều đáng chú ý khác là Python sử dụng từ điển để triển khai không gian tên. Một ánh xạ tên-đối tượng tồn tại, với các tên đóng vai trò là khóa và các đối tượng đóng vai trò là giá trị. Nhiều không gian tên có thể sử dụng cùng một tên, mỗi không gian tên ánh xạ nó tới một đối tượng riêng biệt. Dưới đây là một số ví dụ về không gian tên:
Không gian tên cục bộ: Không gian tên này lưu trữ tên cục bộ của các hàm. Không gian tên này được tạo khi một hàm được gọi và chỉ tồn tại cho đến khi hàm trả về.
Không gian tên toàn cầu: Tên từ các mô-đun đã nhập khác nhau mà bạn đang sử dụng trong một dự án được lưu trữ trong không gian tên này. Nó được hình thành khi mô-đun được thêm vào dự án và kéo dài cho đến khi hoàn thành tập lệnh.
Không gian tên tích hợp: Không gian tên này chứa tên của các hàm tích hợp sẵn và các ngoại lệ.
12. PYTHON PATH là gì?
PYTHONPATH là một biến môi trường cho phép người dùng thêm các thư mục bổ sung vào danh sách thư mục sys.path cho Python. Tóm lại, nó là một biến môi trường được đặt trước khi bắt đầu trình thông dịch Python.
13. Mô-đun Python là gì?
Mô-đun Python là một tập hợp các lệnh và định nghĩa Python trong một tệp duy nhất. Trong một mô-đun, bạn có thể chỉ định các hàm, lớp và biến. Một mô-đun cũng có thể bao gồm mã thực thi. Khi mã được tổ chức thành các mô-đun, nó sẽ dễ hiểu và dễ sử dụng hơn. Nó cũng tổ chức mã một cách hợp lý.
14. Biến cục bộ và biến toàn cục trong Python là gì?
Các biến cục bộ được khai báo bên trong một hàm và có phạm vi giới hạn cho riêng hàm đó, trong khi các biến toàn cục được định nghĩa bên ngoài bất kỳ hàm nào và có phạm vi toàn cục. Nói một cách khác, các biến cục bộ chỉ có sẵn trong hàm mà chúng được tạo ra, nhưng các biến toàn cục có thể truy cập được trong chương trình và trong mỗi hàm.
Biến cục bộ
Biến cục bộ là các biến được tạo bên trong một hàm và dành riêng cho hàm đó. Bên ngoài chức năng, nó không thể được truy cập.
Biến toàn cục
Biến toàn cục là các biến được định nghĩa bên ngoài của bất kỳ hàm nào và có sẵn trong suốt chương trình, nghĩa là cả bên trong và bên ngoài của mỗi hàm.
15. Giải thích Flask là gì và lợi ích của nó?
Flask là một khung web mã nguồn mở. bình là một bộ công cụ, khung và công nghệ để xây dựng các ứng dụng trực tuyến. Trang web, wiki, phần mềm lịch dựa trên web khổng lồ hoặc trang web thương mại được sử dụng để xây dựng ứng dụng web này. Flask là một micro-framework, có nghĩa là nó không phụ thuộc quá nhiều vào các thư viện khác.
Lợi ích:
Có một số lý do thuyết phục để sử dụng Flask làm khung ứng dụng web. Giống-
- Hỗ trợ kiểm tra đơn vị được tích hợp
- Có một máy chủ phát triển tích hợp cũng như một trình gỡ lỗi nhanh chóng.
- Gửi yêu cầu hiệu quả với cơ sở Unicode
- Việc sử dụng cookie được cho phép.
- Templating WSGI 1.0 tương thích jinja2
- Ngoài ra, bình cho phép bạn kiểm soát hoàn toàn tiến độ dự án của mình.
- Chức năng xử lý yêu cầu HTTP
- Flask là một khung công tác web nhẹ và linh hoạt, có thể dễ dàng tích hợp với một số tiện ích mở rộng.
- Bạn có thể sử dụng thiết bị yêu thích của mình để kết nối. API chính cho ORM Basic được thiết kế và tổ chức tốt.
- Cực kỳ thích nghi
- Về mặt sản xuất, bình rất dễ sử dụng.
16. Django có tốt hơn Flask không?
Django phổ biến hơn vì nó có nhiều chức năng, giúp cho việc xây dựng các ứng dụng phức tạp trở nên dễ dàng hơn. Django phù hợp nhất cho các dự án lớn hơn với rất nhiều tính năng. Các tính năng có thể quá mức cần thiết đối với các ứng dụng ít hơn.
Nếu bạn chưa quen với lập trình web, Flask là một nơi tuyệt vời để bắt đầu. Nhiều trang web được xây dựng bằng Flask và nhận được rất nhiều lưu lượng truy cập, mặc dù không nhiều bằng các trang web dựa trên Django. Nếu bạn muốn kiểm soát chính xác, bạn nên sử dụng flask, trong khi nhà phát triển Django dựa vào một cộng đồng lớn để tạo ra các trang web độc đáo.
17. Đề cập đến sự khác biệt giữa Django, Pyramid và Flask.
Flask là một “khuôn khổ vi mô” được thiết kế cho các ứng dụng nhỏ hơn với ít yêu cầu hơn. Pyramid và Django đều hướng đến các dự án lớn hơn, nhưng chúng tiếp cận tính mở rộng và tính linh hoạt theo những cách khác nhau.
Kim tự tháp được thiết kế linh hoạt, cho phép nhà phát triển sử dụng các công cụ tốt nhất cho dự án của họ. Điều này có nghĩa là nhà phát triển có thể chọn cơ sở dữ liệu, cấu trúc URL, kiểu tạo khuôn mẫu và các tùy chọn khác. Django mong muốn bao gồm tất cả các pin mà một ứng dụng web yêu cầu, vì vậy các lập trình viên chỉ cần mở hộp và bắt đầu làm việc, mang theo nhiều thành phần của Django khi chúng hoạt động.
Django bao gồm ORM theo mặc định, nhưng Pyramid và Flask cung cấp quyền kiểm soát của nhà phát triển đối với cách (và liệu) dữ liệu của họ có được lưu trữ hay không. SQLAlchemy là ORM phổ biến nhất cho các ứng dụng web không phải Django, nhưng có rất nhiều tùy chọn thay thế khác nhau, từ DynamoDB và MongoDB đến tính bền cục bộ đơn giản như LevelDB hoặc SQLite thông thường. Kim tự tháp được thiết kế để hoạt động với bất kỳ loại lớp bền bỉ nào, ngay cả những lớp chưa được hình thành.
| Django | Kim tự tháp | bình |
| Nó là một khuôn khổ python. | Nó cũng giống như Django | Nó là một khuôn khổ vi mô. |
| Nó được sử dụng để xây dựng các ứng dụng lớn. | Nó cũng giống như Django | Nó được sử dụng để tạo một ứng dụng nhỏ. |
| Nó bao gồm một ORM. | Nó cung cấp tính linh hoạt và các công cụ phù hợp. | Nó không yêu cầu thư viện bên ngoài. |
18. Thảo luận về kiến trúc Django
Django có kiến trúc MVC (Model-View-Controller), được chia thành ba phần:
1. Mô hình
Mô hình, được đại diện bởi cơ sở dữ liệu, là cấu trúc dữ liệu logic làm nền tảng cho toàn bộ chương trình (nói chung là cơ sở dữ liệu quan hệ như MySql, Postgres).
2. Xem
Chế độ xem là giao diện người dùng hoặc những gì bạn thấy khi truy cập một trang web trong trình duyệt của mình. Các tệp HTML / CSS / Javascript được sử dụng để đại diện cho chúng.
3. Bộ điều khiển
Bộ điều khiển là liên kết giữa khung nhìn và mô hình, nó có nhiệm vụ truyền dữ liệu từ mô hình sang khung nhìn.
Ứng dụng của bạn sẽ xoay quanh mô hình sử dụng MVC, hiển thị hoặc thay đổi nó.
19. Giải thích Phạm vi trong Python?
Hãy coi phạm vi như người cha của một gia đình; mọi đối tượng hoạt động trong một phạm vi. Một định nghĩa chính thức sẽ là đây là một khối mã mà theo đó, bất kể bạn khai báo bao nhiêu đối tượng, chúng vẫn có liên quan. Một vài ví dụ tương tự được đưa ra dưới đây:
- Phạm vi địa phương: Khi bạn tạo một biến bên trong một hàm thuộc phạm vi cục bộ của chính hàm đó và nó sẽ chỉ được sử dụng bên trong hàm đó.
Ví dụ:
def harshit_fun():
y = 100
print (y) harshit_func()
100
- Phạm vi toàn cầu: Khi một biến được tạo bên trong phần thân chính của mã python, nó được gọi là phạm vi toàn cục. Phần tốt nhất về phạm vi toàn cầu là chúng có thể truy cập được trong bất kỳ phần nào của mã python từ bất kỳ phạm vi nào, có thể là toàn cầu hoặc cục bộ.
Ví dụ:
y = 100 def harshit_func():
print (y)
harshit_func()
print (y)
- Hàm lồng nhau: Đây còn được gọi là một hàm bên trong một hàm, như đã nêu trong ví dụ trên trong phạm vi cục bộ, biến y không có sẵn bên ngoài hàm mà nằm trong bất kỳ hàm nào bên trong một hàm khác.
Ví dụ:
def first_func():
y = 100
def nested_func1():
print(y)
nested_func1()
first_func()
- Phạm vi cấp độ mô-đun: Điều này về cơ bản đề cập đến các đối tượng toàn cục của mô-đun hiện tại có thể truy cập được trong chương trình.
- Phạm vi ngoài cùng: Đây là tham chiếu đến tất cả các tên dựng sẵn mà bạn có thể gọi trong chương trình.
20. Liệt kê các kiểu dữ liệu dựng sẵn phổ biến trong Python?
Dưới đây là các kiểu dữ liệu tích hợp sẵn được sử dụng phổ biến nhất:
số: Bao gồm số nguyên, số dấu phẩy động và số phức.
Danh sách: Chúng ta đã biết một chút về danh sách, để đặt một định nghĩa chính thức, danh sách là một chuỗi các mục có thứ tự có thể thay đổi được, các phần tử bên trong danh sách cũng có thể thuộc các kiểu dữ liệu khác nhau.
Ví dụ:
list = [100, “Great Learning”, 30]Bộ dữ liệu: Đây cũng là một chuỗi các phần tử có thứ tự nhưng không giống như danh sách các bộ giá trị là bất biến có nghĩa là nó không thể thay đổi sau khi được khai báo.
Ví dụ:
tup_2 = (100, “Great Learning”, 20) Chuỗi: Đây được gọi là chuỗi ký tự được khai báo trong dấu ngoặc đơn hoặc dấu ngoặc kép.
Ví dụ:
“Hi, I work at great learning”
‘Hi, I work at great learning’Bộ: Bộ về cơ bản là bộ sưu tập các mặt hàng duy nhất mà thứ tự không đồng nhất.
Ví dụ:
set = {1,2,3}Từ điển: Từ điển luôn lưu trữ các giá trị trong các cặp khóa và giá trị trong đó mỗi giá trị có thể được truy cập bằng khóa cụ thể của nó.
Ví dụ:
[12] harshit = {1:’video_games’, 2:’sports’, 3:’content’} Boolean: Chỉ có hai giá trị boolean: Thật và Sai
21. Các thuộc tính toàn cầu, bảo vệ và riêng tư trong Python là gì?
Các thuộc tính của một lớp còn được gọi là các biến. Có ba công cụ sửa đổi quyền truy cập trong Python cho các biến, cụ thể là
một. công cộng - Các biến được khai báo là public có thể truy cập ở mọi nơi, bên trong hoặc bên ngoài lớp.
b. riêng - Các biến được khai báo là private chỉ có thể truy cập được trong lớp hiện tại.
c. được bảo vệ - Các biến được khai báo là được bảo vệ chỉ có thể truy cập được trong gói hiện tại.
Các thuộc tính cũng được phân loại là:
- Thuộc tính cục bộ được định nghĩa trong một khối mã / phương thức và chỉ có thể được truy cập trong khối mã / phương thức đó.
- Thuộc tính toàn cầu được định nghĩa bên ngoài khối mã / phương thức và có thể truy cập được ở mọi nơi.
class Mobile:
m1 = "Samsung Mobiles" //Global attributes
def price(self):
m2 = "Costly mobiles" //Local attributes
return m2
Sam_m = Mobile()
print(Sam_m.m1)22. Từ khóa trong Python là gì?
Từ khóa trong Python là các từ dành riêng được sử dụng làm mã định danh, tên hàm hoặc tên biến. Chúng giúp xác định cấu trúc và cú pháp của ngôn ngữ.
Có tổng cộng 33 từ khóa trong Python 3.7 có thể thay đổi trong phiên bản tiếp theo, tức là Python 3.8. Danh sách tất cả các từ khóa được cung cấp bên dưới:
Từ khóa trong Python:
| Sai | tốt nghiệp lớp XNUMX | cuối cùng | is | trở lại |
| Không áp dụng | tiếp tục | cho | lambda | thử |
| Thật | def | từ | phi địa phương | trong khi |
| và | các | toàn cầu | không | với |
| as | elif | if | or | năng suất |
| khẳng định | khác | nhập khẩu | vượt qua | |
| phá vỡ | ngoại trừ |
23. Sự khác biệt giữa danh sách và bộ giá trị trong Python là gì?
Danh sách và tuple là cấu trúc dữ liệu trong Python có thể lưu trữ một hoặc nhiều đối tượng hoặc giá trị. Sử dụng dấu ngoặc vuông, bạn có thể tạo danh sách để chứa nhiều đối tượng trong một biến. Các bộ dữ liệu, giống như mảng, có thể chứa nhiều mục trong một biến duy nhất và được xác định bằng dấu ngoặc đơn.
| Chức năng | bộ dữ liệu |
| Danh sách có thể thay đổi. | Tuples là bất biến. |
| Tác động của các lần lặp là Tiêu tốn thời gian. | Lặp lại có tác dụng làm cho mọi thứ diễn ra nhanh hơn. |
| Danh sách này thuận tiện hơn cho các hành động như chèn và xóa. | Các mục có thể được truy cập bằng kiểu dữ liệu tuple. |
| Danh sách chiếm nhiều bộ nhớ hơn. | Khi so sánh với một danh sách, một tuple sử dụng ít bộ nhớ hơn. |
| Có rất nhiều kỹ thuật được tích hợp vào danh sách. | Không có nhiều phương thức tích hợp sẵn trong Tuple. |
| Các thay đổi và lỗi không mong muốn có nhiều khả năng xảy ra hơn. | Rất khó để diễn ra trong một tuple. |
| Chúng tiêu tốn rất nhiều bộ nhớ do bản chất của cấu trúc dữ liệu này | Chúng tiêu tốn ít bộ nhớ hơn |
| Cú pháp: list = [100, “Học Hay”, 30] |
Cú pháp: tup_2 = (100, “Great Learning”, 20) |
24. Làm thế nào bạn có thể nối hai bộ giá trị?
Giả sử chúng ta có hai bộ giá trị như thế này ->
tup1 = (1, ”a”, True)
tup2 = (4,5,6)
Kết nối các bộ giá trị có nghĩa là chúng ta đang thêm các phần tử của một bộ giá trị vào cuối một bộ giá trị khác.
Bây giờ, hãy tiếp tục và nối tuple2 với tuple1:
Mã Code:
tup1=(1,"a",True)
tup2=(4,5,6)
tup1+tup2Tất cả những gì bạn phải làm là sử dụng toán tử '+' giữa hai bộ giá trị và bạn sẽ nhận được kết quả được nối.
Tương tự, hãy nối tuple1 với tuple2:
Mã Code:
tup1=(1,"a",True)
tup2=(4,5,6)
tup2+tup1
25. Hàm trong Python là gì?
Trả lời: Các hàm trong Python đề cập đến các khối đã tổ chức và mã có thể sử dụng lại để thực hiện các sự kiện đơn lẻ và có liên quan. Các chức năng rất quan trọng để tạo ra mô-đun tốt hơn cho các ứng dụng sử dụng lại mức độ mã hóa cao. Python có một số hàm tích hợp sẵn như print (). Tuy nhiên, nó cũng cho phép bạn tạo các chức năng do người dùng xác định.
26. Làm thế nào bạn có thể khởi tạo một mảng 5 * 5 numpy chỉ có các số XNUMX?
Chúng tôi sẽ sử dụng .zeros () phương pháp.
import numpy as np
n1=np.zeros((5,5))
n1
Sử dụng np.zeros () và chuyển các kích thước bên trong nó. Vì chúng ta muốn có một ma trận 5 * 5, chúng ta sẽ truyền (5,5) vào bên trong phương thức .zeros ().
27. Gấu trúc là gì?
Pandas là một thư viện python mã nguồn mở có một bộ cấu trúc dữ liệu rất phong phú cho các hoạt động dựa trên dữ liệu. Gấu trúc với các tính năng tuyệt vời của chúng phù hợp với mọi vai trò của hoạt động dữ liệu, cho dù đó là học thuật hay giải quyết các vấn đề kinh doanh phức tạp. Gấu trúc có thể xử lý nhiều loại tệp và là một trong những công cụ quan trọng nhất cần có.
Tìm hiểu thêm về Python Pandas
28. Khung dữ liệu là gì?
Khung dữ liệu gấu trúc là một cấu trúc dữ liệu ở gấu trúc có thể thay đổi được. Gấu trúc hỗ trợ dữ liệu không đồng nhất được sắp xếp theo hai trục. ( hàng và cột).
Đọc tệp thành gấu trúc: -
| 12 | Nhập gấu trúc dưới dạng pddf = p.read_csv (“mydata.csv”) |
Ở đây, df là một khung dữ liệu gấu trúc. read_csv () được sử dụng để đọc tệp được phân tách bằng dấu phẩy dưới dạng khung dữ liệu ở gấu trúc.
29. Chuỗi Pandas là gì?
Chuỗi là cấu trúc dữ liệu một chiều của gấu trúc có thể chứa hầu hết mọi loại dữ liệu. Nó giống như một cột excel. Nó hỗ trợ nhiều hoạt động và được sử dụng cho các hoạt động dữ liệu đơn chiều.
Tạo một chuỗi từ dữ liệu:
Mã Code:
import pandas as pd
data=["1",2,"three",4.0]
series=pd.Series(data)
print(series)
print(type(series))
30. Bạn hiểu gì về gấu trúc groupby?
Nhóm gấu trúc là một tính năng được hỗ trợ bởi gấu trúc được sử dụng để tách và nhóm một đối tượng. Giống như nhóm sql / mysql / oracle, nó được sử dụng để nhóm dữ liệu theo các lớp và các thực thể có thể được sử dụng thêm để tổng hợp. Một khung dữ liệu có thể được nhóm bởi một hoặc nhiều cột.
Mã Code:
df = pd.DataFrame({'Vehicle':['Etios','Lamborghini','Apache200','Pulsar200'], 'Type':["car","car","motorcycle","motorcycle"]})
df
Để thực hiện theo nhóm, hãy nhập mã sau:
df.groupby('Type').count()31. Cách tạo khung dữ liệu từ danh sách?
Để tạo khung dữ liệu từ danh sách,
1) tạo khung dữ liệu trống
2) thêm danh sách dưới dạng các cột riêng lẻ vào danh sách
Mã Code:
df=pd.DataFrame()
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
df["cars"]=cars
df["bikes"]=bikes
df
32. Cách tạo khung dữ liệu từ từ điển?
Một từ điển có thể được chuyển trực tiếp làm đối số cho hàm DataFrame () để tạo khung dữ liệu.
Mã Code:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
df
33. Làm thế nào để kết hợp các khung dữ liệu trong gấu trúc?
Hai khung dữ liệu khác nhau có thể được xếp chồng lên nhau theo chiều ngang hoặc chiều dọc bởi các hàm concat (), append () và join () trong gấu trúc.
Concat hoạt động tốt nhất khi các khung dữ liệu có các cột giống nhau và có thể được sử dụng để nối dữ liệu có các trường tương tự và về cơ bản là việc xếp chồng dọc các khung dữ liệu vào một khung dữ liệu duy nhất.
Append () được sử dụng để xếp chồng các khung dữ liệu theo chiều ngang. Nếu hai bảng (khung dữ liệu) được hợp nhất với nhau thì đây là chức năng nối tốt nhất.
Tham gia được sử dụng khi chúng ta cần trích xuất dữ liệu từ các khung dữ liệu khác nhau có một hoặc nhiều cột chung. Việc xếp chồng nằm ngang trong trường hợp này.
Trước khi xem qua các câu hỏi, đây là video nhanh để giúp bạn làm mới bộ nhớ của mình trên Python.
34. Loại gia nhập nào mà gấu trúc cung cấp?
Gấu trúc có phép nối bên trái, phép nối bên trong, phép nối bên phải và phép nối bên ngoài.
35. Làm thế nào để hợp nhất các khung dữ liệu trong gấu trúc?
Việc hợp nhất phụ thuộc vào loại và các trường của các khung dữ liệu khác nhau được hợp nhất. Nếu dữ liệu có các trường tương tự, dữ liệu sẽ được hợp nhất dọc theo trục 0, nếu không, chúng sẽ được hợp nhất dọc theo trục 1.
36. Cho khung dữ liệu dưới đây thả tất cả các hàng có Nan.
Chức năng dropna có thể được sử dụng để làm điều đó.
df.dropna(inplace=True)
df37. Làm thế nào để truy cập năm mục đầu tiên của khung dữ liệu?
Bằng cách sử dụng hàm head (5), chúng ta có thể nhận được năm mục hàng đầu của khung dữ liệu. Theo mặc định, df.head () trả về 5 hàng trên cùng. Để có được n hàng trên cùng, df.head (n) sẽ được sử dụng.
38. Làm thế nào để truy cập năm mục cuối cùng của khung dữ liệu?
Bằng cách sử dụng hàm tail (5), chúng ta có thể nhận được năm mục nhập hàng đầu của khung dữ liệu. Theo mặc định, df.tail () trả về 5 hàng trên cùng. Để lấy n hàng cuối cùng, df.tail (n) sẽ được sử dụng.
39. Làm thế nào để tìm nạp một mục nhập dữ liệu từ khung dữ liệu gấu trúc bằng cách sử dụng một giá trị nhất định trong chỉ mục?
Để tìm nạp một hàng từ khung dữ liệu đã cho chỉ số x, chúng ta có thể sử dụng loc.
Df.loc [10] trong đó 10 là giá trị của chỉ mục.
Mã Code:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
a=[10,20,30,40,50]
df.index=a
df.loc[10]
40. Nhận xét là gì và bạn có thể thêm nhận xét bằng Python như thế nào?
Nhận xét trong Python đề cập đến một đoạn văn bản dành cho thông tin. Nó đặc biệt liên quan khi có nhiều người làm việc trên một bộ mã. Nó có thể được sử dụng để phân tích mã, để lại phản hồi và gỡ lỗi. Có hai loại nhận xét bao gồm:
- Nhận xét một dòng
- Nhận xét nhiều dòng
Các mã cần thiết để thêm nhận xét
#Note –single nhận xét dòng
"""Ghi chú
Chú thích
Lưu ý ”” ”—– bình luận nhiều dòng
41. Từ điển trong Python là gì? Cho một ví dụ.
Từ điển Python là một tập hợp các mục không theo thứ tự cụ thể. Từ điển Python được viết trong dấu ngoặc nhọn với các khóa và giá trị. Từ điển được tối ưu hóa để truy xuất giá trị cho các khóa đã biết.
Ví dụ
d={“a”:1,”b”:2}42. Sự khác biệt giữa a tuple và một từ điển?
Một điểm khác biệt chính giữa tuple và từ điển là từ điển có thể thay đổi được trong khi tuple thì không. Có nghĩa là nội dung của từ điển có thể được thay đổi mà không làm thay đổi danh tính của nó, nhưng trong một bộ từ điển, điều đó là không thể.
43. Tìm hiểu giá trị trung bình, trung vị và độ lệch chuẩn của mảng numpy này -> np.array ([1,5,3,100,4,48])
import numpy as np
n1=np.array([10,20,30,40,50,60])
print(np.mean(n1))
print(np.median(n1))
print(np.std(n1))
44. Bộ phân loại là gì?
Bộ phân loại được sử dụng để dự đoán lớp của bất kỳ điểm dữ liệu nào. Bộ phân loại là các giả thuyết đặc biệt được sử dụng để gán nhãn lớp cho bất kỳ điểm dữ liệu cụ thể nào. Một bộ phân loại thường sử dụng dữ liệu huấn luyện để hiểu mối quan hệ giữa các biến đầu vào và lớp. Phân loại là một phương pháp được sử dụng trong học có giám sát trong Học máy.
45. Trong Python, làm thế nào để bạn chuyển đổi một chuỗi thành chữ thường?
Tất cả các chữ hoa trong một chuỗi có thể được chuyển đổi thành chữ thường bằng cách sử dụng phương thức: string.lower ()
ví dụ:
string = ‘GREATLEARNING’ print(string.lower())o / p: tuyệt vời
46. Làm thế nào để bạn có được danh sách tất cả các khóa trong từ điển?
Một trong những cách chúng ta có thể lấy danh sách các khóa là sử dụng: dict.keys ()
Phương thức này trả về tất cả các khóa có sẵn trong từ điển.
dict = {1:a, 2:b, 3:c} dict.keys()o / p: [1, 2, 3]
47. Làm thế nào bạn có thể viết hoa chữ cái đầu tiên của một chuỗi?
Chúng ta có thể sử dụng viết hoa () hàm viết hoa ký tự đầu tiên của một chuỗi. Nếu ký tự đầu tiên đã được viết hoa thì nó sẽ trả về chuỗi ban đầu.
Cú pháp:
string_name.capitalize()
ví dụ:
n = “greatlearning” print(n.capitalize())o / p: Greatlearning
48. Làm thế nào bạn có thể chèn một phần tử tại một chỉ mục nhất định trong Python?
Python có một hàm có sẵn được gọi là hàm insert ().
Nó có thể được sử dụng để chèn một phần tử tại một chỉ mục nhất định.
Cú pháp:
list_name.insert(index, element)
ví dụ:
list = [ 0,1, 2, 3, 4, 5, 6, 7 ]
#insert 10 at 6th index
list.insert(6, 10)o / p: [0,1,2,3,4,5,10,6,7]
49. Làm thế nào bạn sẽ loại bỏ các phần tử trùng lặp khỏi một danh sách?
Có nhiều phương pháp khác nhau để loại bỏ các phần tử trùng lặp khỏi danh sách. Tuy nhiên, cách phổ biến nhất là chuyển đổi danh sách thành một tập hợp bằng cách sử dụng hàm set () và sử dụng hàm list () để chuyển đổi nó trở lại thành một danh sách nếu được yêu cầu.
ví dụ:
list0 = [2, 6, 4, 7, 4, 6, 7, 2]
list1 = list(set(list0)) print (“The list without duplicates : ” + str(list1))
o / p: Danh sách không trùng lặp: [2, 4, 6, 7]
50. Đệ quy là gì?
Đệ quy là một hàm gọi chính nó một hoặc nhiều lần trong phần thân của nó. Một điều kiện rất quan trọng mà một hàm đệ quy cần phải được sử dụng trong một chương trình là, nó phải kết thúc, nếu không sẽ có vấn đề về một vòng lặp vô hạn.
51. Giải thích hiểu danh sách Python.
Danh sách dễ hiểu được sử dụng để chuyển đổi một danh sách này thành một danh sách khác. Các phần tử có thể được đưa vào danh sách mới một cách có điều kiện và mỗi phần tử có thể được chuyển đổi khi cần thiết. Nó bao gồm một biểu thức dẫn đến một mệnh đề for, được đặt trong dấu ngoặc vuông.
Đối với ví dụ:
list = [i for i in range(1000)]
print list52. Hàm byte () là gì?
Hàm byte () trả về một đối tượng byte. Nó được sử dụng để chuyển đổi đối tượng thành đối tượng byte hoặc tạo đối tượng byte trống có kích thước xác định.
53. Các loại toán tử khác nhau trong Python là gì?
Python có các toán tử cơ bản sau:
toán học (Phép cộng (+), Phép trừ (-), Phép nhân (*), Phép chia (/), Mô đun (%)), Quan hệ (<, >, <=, >=, ==, !=, ),
Chuyển nhượng (=. + =, - =, / =, * =,% =),
logic (và, hoặc không), Tư cách thành viên, Danh tính và Người điều hành Bitwise
54. Câu lệnh 'with' là gì?
Câu lệnh “with” trong python được sử dụng trong xử lý ngoại lệ. Một tệp có thể được mở và đóng trong khi thực thi một khối mã, chứa câu lệnh “with”., Mà không cần sử dụng hàm close (). Về cơ bản, nó làm cho mã dễ đọc hơn nhiều.
55. Hàm map () trong Python là gì?
Hàm map () trong Python được sử dụng để áp dụng một hàm trên tất cả các phần tử của một tệp có thể lặp được chỉ định. Nó bao gồm hai tham số, chức năng và có thể lặp lại. Hàm được lấy làm đối số và sau đó được áp dụng cho tất cả các phần tử của một hàm có thể lặp lại (được chuyển làm đối số thứ hai). Kết quả là một danh sách đối tượng được trả về.
def add(n):
return n + n number= (15, 25, 35, 45)
res= map(add, num)
print(list(res))
o / p: 30,50,70,90
56. __init__ trong Python là gì?
_init_ methodology là một phương thức dành riêng trong Python hay còn gọi là phương thức khởi tạo trong OOP. Khi một đối tượng được tạo từ một lớp và phương thức _init_ được gọi để truy cập các thuộc tính của lớp.
Cũng đọc: Python __init__- Tổng quan
57. Các công cụ hiện có để thực hiện phân tích tĩnh?
Hai công cụ phân tích tĩnh được sử dụng để tìm lỗi trong Python là Pychecker và Pylint. Pychecker phát hiện lỗi từ mã nguồn và cảnh báo về kiểu dáng và độ phức tạp của nó. Trong khi Pylint kiểm tra xem mô-đun có khớp với tiêu chuẩn mã hóa hay không.
58. Pass trong Python là gì?
Pass là một câu lệnh không làm gì cả khi được thực thi. Nói cách khác, nó là một câu lệnh Null. Câu lệnh này không bị trình thông dịch bỏ qua, nhưng câu lệnh không dẫn đến hoạt động nào. Nó được sử dụng khi bạn không muốn bất kỳ lệnh nào thực thi nhưng bắt buộc phải có một câu lệnh.
59. Làm thế nào một đối tượng có thể được sao chép trong Python?
Không phải tất cả các đối tượng đều có thể được sao chép bằng Python, nhưng hầu hết đều có thể. Chúng ta có thể sử dụng toán tử “=” để sao chép một đối tượng vào một biến.
ví dụ:
var=copy.copy(obj)60. Làm thế nào một số có thể được chuyển đổi thành một chuỗi?
Hàm sẵn có str () có thể được sử dụng để chuyển đổi một số thành một chuỗi.
61. Mô-đun và gói trong Python là gì?
Mô-đun là cách để cấu trúc một chương trình. Mỗi tệp chương trình Python là một mô-đun, nhập các thuộc tính và đối tượng khác. Thư mục của một chương trình là một gói các mô-đun. Một gói có thể có các mô-đun hoặc các thư mục con.
62. Hàm object () trong Python là gì?
Trong Python, hàm object () trả về một đối tượng rỗng. Các thuộc tính hoặc phương thức mới không thể được thêm vào đối tượng này.
63. Sự khác biệt giữa NumPy và SciPy là gì?
NumPy là viết tắt của Numerical Python trong khi SciPy là viết tắt của Scientific Python. NumPy là thư viện cơ bản để xác định mảng và các vấn đề toán học đơn giản, trong khi SciPy được sử dụng cho các vấn đề phức tạp hơn như tích hợp và tối ưu hóa số và học máy, v.v.
64. Len () làm gì?
len () được sử dụng để xác định độ dài của một chuỗi, một danh sách, một mảng, v.v.
ví dụ:
str = “greatlearning”
print(len(str))
o / p: 13
65. Định nghĩa tính đóng gói trong Python?
Đóng gói có nghĩa là liên kết mã và dữ liệu với nhau. Một lớp Python chẳng hạn.
66. Kiểu () trong Python là gì?
type () là một phương thức tích hợp sẵn trả về kiểu của đối tượng hoặc trả về kiểu đối tượng mới dựa trên các đối số được truyền vào.
ví dụ:
a = 100
type(a)o / p: int
67. Hàm split () dùng để làm gì?
Hàm tách được sử dụng để chia một chuỗi thành các chuỗi ngắn hơn bằng cách sử dụng các dấu phân tách được xác định.
letters= ('' A, B, C”)
n = text.split(“,”)
print(n)o / p: ['A', 'B', 'C']
68. python cung cấp các loại tích hợp nào?
Python có các kiểu dữ liệu tích hợp sau:
Số: Python xác định ba loại số:
- Số nguyên: Tất cả các số dương và âm không có phần phân số
- Float: Bất kỳ số thực nào có biểu diễn dấu phẩy động
- Số phức: Một số có thành phần thực và ảo được biểu diễn dưới dạng x + yj. x và y là số thực và j là -1 (căn bậc hai của -1 được gọi là số ảo)
Boolean: Kiểu dữ liệu Boolean là kiểu dữ liệu có một trong hai giá trị có thể có, tức là Đúng hoặc Sai. Lưu ý rằng 'T' và 'F' là các chữ cái viết hoa.
Chuỗi: Giá trị chuỗi là tập hợp một hoặc nhiều ký tự được đặt trong dấu ngoặc kép đơn, đôi hoặc ba.
Danh sách: Đối tượng danh sách là một tập hợp có thứ tự của một hoặc nhiều mục dữ liệu có thể thuộc nhiều kiểu khác nhau, được đặt trong dấu ngoặc vuông. Danh sách có thể thay đổi và do đó có thể được sửa đổi, chúng ta có thể thêm, chỉnh sửa hoặc xóa các phần tử riêng lẻ trong danh sách.
Thiết lập: Một bộ sưu tập không có thứ tự của các đối tượng duy nhất được đặt trong dấu ngoặc nhọn
Bộ đông lạnh: Chúng giống như một tập hợp nhưng không thay đổi, có nghĩa là chúng ta không thể sửa đổi các giá trị của chúng một khi chúng được tạo.
Từ điển: Một đối tượng từ điển không có thứ tự trong đó có một khóa được liên kết với mỗi giá trị và chúng ta có thể truy cập từng giá trị thông qua khóa của nó. Tập hợp các cặp như vậy được đặt trong dấu ngoặc nhọn. Ví dụ: {'First Name': 'Tom', 'last name': 'Hardy'} Lưu ý rằng giá trị Số, chuỗi và bộ giá trị là bất biến trong khi các đối tượng Danh sách hoặc Từ điển có thể thay đổi.
69. docstring trong Python là gì?
Python docstrings là các chuỗi ký tự được đặt trong dấu ngoặc kép xuất hiện ngay sau định nghĩa của một hàm, phương thức, lớp hoặc mô-đun. Chúng thường được sử dụng để mô tả chức năng của một hàm, phương thức, lớp hoặc mô-đun cụ thể. Chúng tôi có thể truy cập các docstrings này bằng cách sử dụng thuộc tính __doc__.
Đây là một ví dụ:
def square(n): '''Takes in a number n, returns the square of n''' return n**2
print(square.__doc__)
Ouput: Lấy một số n, trả về bình phương của n.
70. Làm thế nào để đảo ngược một chuỗi trong Python?
Trong Python, không có hàm dựng sẵn nào giúp chúng ta đảo ngược một chuỗi. Chúng ta cần sử dụng thao tác cắt mảng cho tương tự.
| 1 | str_reverse = string [:: - 1] |
Tìm hiểu thêm: Làm thế nào để đảo ngược một chuỗi trong Python
71. Làm thế nào để kiểm tra Phiên bản Python trong CMD?
Để kiểm tra Phiên bản Python trong CMD, hãy nhấn CMD + Dấu cách. Thao tác này sẽ mở Spotlight. Tại đây, gõ “terminal” và nhấn enter. Để thực hiện lệnh, hãy nhập python –version hoặc python -V và nhấn enter. Thao tác này sẽ trả về phiên bản python trong dòng tiếp theo bên dưới lệnh.
72. Python có phân biệt chữ hoa chữ thường khi xử lý các mã định danh không?
Đúng. Python phân biệt chữ hoa chữ thường khi xử lý số nhận dạng. Nó là một ngôn ngữ phân biệt chữ hoa chữ thường. Do đó, biến và Biến sẽ không giống nhau.
Câu hỏi phỏng vấn Python cho người có kinh nghiệm
Phần này về Câu hỏi phỏng vấn Python cho người có kinh nghiệm bao gồm hơn 20 câu hỏi thường gặp trong quá trình phỏng vấn để tìm việc làm một chuyên gia có kinh nghiệm về Python. Những câu hỏi thường gặp này có thể giúp bạn trau dồi kỹ năng của mình và biết điều gì sẽ xảy ra trong các cuộc phỏng vấn sắp tới.
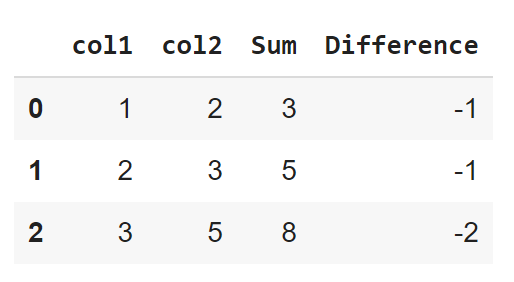
73. Làm thế nào để tạo một cột mới trong gấu trúc bằng cách sử dụng các giá trị từ các cột khác?
Chúng tôi có thể thực hiện các phép toán dựa trên cột trên khung dữ liệu gấu trúc. Các cột Pandas chứa các giá trị số có thể được vận hành bởi các toán tử.
Mã Code:
import pandas as pd
a=[1,2,3]
b=[2,3,5]
d={"col1":a,"col2":b}
df=pd.DataFrame(d)
df["Sum"]=df["col1"]+df["col2"]
df["Difference"]=df["col1"]-df["col2"]
dfĐầu ra:
74. Các chức năng khác nhau có thể được sử dụng bởi cá mó ở gấu trúc là gì?
Gooby () ở gấu trúc có thể được sử dụng với nhiều hàm tổng hợp. Một số trong số đó là sum (), mean (), count (), std ().
Dữ liệu được chia thành các nhóm dựa trên danh mục và sau đó dữ liệu trong các nhóm riêng lẻ này có thể được tổng hợp bằng các chức năng đã nói ở trên.
75. Làm thế nào để xóa một cột hoặc một nhóm cột trong gấu trúc? Với cột thả khung dữ liệu bên dưới “col1”.
Hàm drop () có thể được sử dụng để xóa các cột khỏi khung dữ liệu.
d={"col1":[1,2,3],"col2":["A","B","C"]}
df=pd.DataFrame(d)
df=df.drop(["col1"],axis=1)
df
76. Cho các hàng thả khung dữ liệu sau đây có giá trị cột là A.
Mã Code:
d={"col1":[1,2,3],"col2":["A","B","C"]}
df=pd.DataFrame(d)
df.dropna(inplace=True)
df=df[df.col1!=1]
df
77. Reindexing ở gấu trúc là gì?
Lập chỉ mục lại là quá trình chỉ định lại chỉ mục của khung dữ liệu gấu trúc.
Mã Code:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
a=[10,20,30,40,50]
df.index=a
df
78. Bạn hiểu gì về hàm lambda? Tạo một hàm lambda sẽ in ra tổng của tất cả các phần tử trong danh sách này -> [5, 8, 10, 20, 50, 100]
Các hàm Lambda là các hàm ẩn danh trong Python. Chúng được xác định bằng cách sử dụng từ khóa lambda. Các hàm lambda có thể nhận bất kỳ số lượng đối số nào, nhưng chúng chỉ có thể có một biểu thức.
from functools import reduce
sequences = [5, 8, 10, 20, 50, 100]
sum = reduce (lambda x, y: x+y, sequences)
print(sum)
79. Vstack () trong numpy là gì? Cho một ví dụ.
vstack () là một hàm để căn chỉnh các hàng theo chiều dọc. Tất cả các hàng phải có cùng số phần tử.
Mã Code:
import numpy as np
n1=np.array([10,20,30,40,50])
n2=np.array([50,60,70,80,90])
print(np.vstack((n1,n2)))
80. Làm thế nào để xóa khoảng trắng khỏi một chuỗi trong Python?
Có thể xóa dấu cách khỏi chuỗi trong python bằng cách sử dụng các hàm dải () hoặc Replace (). Hàm Strip () được sử dụng để loại bỏ các khoảng trắng đầu và cuối trong khi hàm Replace () được sử dụng để xóa tất cả các khoảng trắng trong chuỗi:
string.replace(” “,””) ex1: str1= “great learning”
print (str.strip())
o/p: great learning
ex2: str2=”great learning”
print (str.replace(” “,””))
o / p: tuyệt vời
81. Giải thích các chế độ xử lý tệp mà Python hỗ trợ.
Có ba chế độ xử lý tệp trong Python: chỉ đọc (r), chỉ ghi (w), đọc-ghi (rw) và nối thêm (a). Vì vậy, nếu bạn đang mở một tệp văn bản, hãy nói ở chế độ đọc. Các chế độ trước đó trở thành “rt” cho chỉ đọc, “wt” cho ghi, v.v. Tương tự, một tệp nhị phân có thể được mở bằng cách chỉ định “b” cùng với các cờ truy cập tệp (“r”, “w”, “rw” và “a”) trước nó.
82. Gọt và bóc tách là gì?
Pickling là quá trình chuyển đổi cấu trúc phân cấp đối tượng Python thành một luồng byte để lưu trữ nó vào cơ sở dữ liệu. Nó còn được gọi là tuần tự hóa. Không chọn lọc là mặt trái của sự kén chọn. Luồng byte được chuyển đổi trở lại thành một hệ thống phân cấp đối tượng.
83. Bộ nhớ được quản lý như thế nào trong Python?
Đây là một trong những câu hỏi phỏng vấn python phổ biến nhất
Quản lý bộ nhớ trong python bao gồm một heap riêng chứa tất cả các đối tượng và cấu trúc dữ liệu. Heap được quản lý bởi trình thông dịch và lập trình viên hoàn toàn không có quyền truy cập vào nó. Trình quản lý bộ nhớ Python thực hiện tất cả việc cấp phát bộ nhớ. Hơn nữa, có một bộ thu gom rác có sẵn giúp tái chế và giải phóng bộ nhớ cho không gian đống.
84. Điều gì là hấp dẫn nhất trong Python?
Unittest là một khung kiểm thử đơn vị bằng Python. Nó hỗ trợ chia sẻ mã thiết lập và tắt cho các bài kiểm tra, tổng hợp các bài kiểm tra thành bộ sưu tập, tự động hóa kiểm tra và tính độc lập của các bài kiểm tra khỏi khung báo cáo.
85. Làm thế nào để bạn xóa một tệp trong Python?
Các tệp có thể bị xóa bằng Python bằng cách sử dụng lệnh os.remove (tên tệp) hoặc os.unlink (tên tệp)
86. Làm thế nào để bạn tạo một lớp trống trong Python?
Để tạo một lớp trống, chúng ta có thể sử dụng lệnh vượt qua sau định nghĩa của đối tượng lớp. Vượt qua là một câu lệnh trong Python không có tác dụng gì.
87. Trình trang trí Python là gì?
Trình trang trí là các hàm lấy một chức năng khác làm đối số để sửa đổi hành vi của nó mà không thay đổi chính chức năng đó. Những điều này rất hữu ích khi chúng ta muốn tăng chức năng của một hàm mà không cần thay đổi nó.
Đây là một ví dụ:
def smart_divide(func): def inner(a, b): print("Dividing", a, "by", b) if b == 0: print("Make sure Denominator is not zero") return
return func(a, b) return inner
@smart_divide
def divide(a, b): print(a/b)
divide(1,0)
Ở đây smart_divide là một hàm trang trí được sử dụng để thêm chức năng vào hàm chia đơn giản.
88. Ngôn ngữ được gõ động là gì?
Kiểm tra kiểu là một phần quan trọng của bất kỳ ngôn ngữ lập trình nào nhằm đảm bảo lỗi kiểu tối thiểu. Kiểu được xác định cho các biến được kiểm tra tại thời điểm biên dịch hoặc thời gian chạy. Khi kiểm tra kiểu được thực hiện tại thời điểm biên dịch thì nó được gọi là ngôn ngữ định kiểu tĩnh và khi kiểm tra kiểu được thực hiện tại thời điểm chạy, nó được gọi là ngôn ngữ định kiểu động.
- Trong ngôn ngữ định kiểu động, các đối tượng được ràng buộc với kiểu bằng các phép gán tại thời gian chạy.
- Các ngôn ngữ lập trình được đánh động tạo ra mã được tối ưu hóa ít hơn so với tương đối
- Trong các ngôn ngữ được nhập động, không cần xác định kiểu cho các biến trước khi sử dụng chúng. Do đó, nó có thể được cấp phát động.
89. Cắt trong Python là gì?
Slicing trong Python đề cập đến việc truy cập các phần của một chuỗi. Chuỗi có thể là bất kỳ đối tượng có thể thay đổi và lặp lại nào. Slice () là một hàm được sử dụng trong Python để chia chuỗi đã cho thành các phân đoạn bắt buộc.
Có hai biến thể của việc sử dụng hàm lát cắt. Cú pháp để cắt trong python:
- lát (bắt đầu, dừng lại)
- silica (bắt đầu, dừng, bước)
ví dụ:
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
substr1 = slice(3, 5)
print(Str1[substr1])
//same code can be written in the following way also Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
print(Str1[3,5])
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
substr1 = slice(0, 14, 2)
print(Str1[substr1]) //same code can be written in the following way also
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
print(Str1[0,14, 2])
90. Sự khác biệt giữa Mảng Python và danh sách là gì?
Mảng và Danh sách trong Python đều là tập hợp các phần tử có thứ tự và có thể thay đổi được, nhưng sự khác biệt nằm ở cách làm việc với chúng
Mảng lưu trữ dữ liệu không đồng nhất khi được nhập từ mô-đun mảng, nhưng mảng có thể lưu trữ dữ liệu đồng nhất được nhập từ mô-đun numpy. Nhưng danh sách có thể lưu trữ dữ liệu không đồng nhất và để sử dụng danh sách, nó không phải được nhập từ bất kỳ mô-đun nào.
import array as a1
array1 = a1.array('i', [1 , 2 ,5] )
print (array1)
Hoặc,
import numpy as a2
array2 = a2.array([5, 6, 9, 2]) print(array2) - Mảng phải được khai báo trước khi sử dụng nó nhưng không cần khai báo danh sách.
- Các phép toán số dễ thực hiện hơn trên mảng so với danh sách.
91. Độ phân giải phạm vi trong Python là gì?
Khả năng truy cập của biến được định nghĩa trong python theo vị trí của khai báo biến, được gọi là phạm vi của biến trong python. Độ phân giải phạm vi đề cập đến thứ tự mà các biến này được tìm kiếm để đặt tên cho đối sánh biến. Sau đây là phạm vi được xác định trong python để khai báo biến.
một. Phạm vi cục bộ - Biến được khai báo bên trong một vòng lặp, thân hàm chỉ có thể truy cập trong hàm hoặc vòng lặp đó.
b. Phạm vi toàn cục - Biến được khai báo bên ngoài bất kỳ mã nào khác ở cấp cao nhất và có thể truy cập ở mọi nơi.
c. Phạm vi bao quanh - Biến được khai báo bên trong một hàm bao, chỉ có thể truy cập trong hàm bao đó.
d. Phạm vi tích hợp - Biến được khai báo bên trong các hàm có sẵn của các mô-đun khác nhau của python có phạm vi tích hợp và chỉ có thể truy cập trong mô-đun cụ thể đó.
Độ phân giải phạm vi cho bất kỳ biến nào được thực hiện trong java theo một thứ tự cụ thể và thứ tự đó là
Phạm vi cục bộ -> phạm vi bao quanh -> phạm vi toàn cầu -> phạm vi tích hợp
92. Đọc hiểu chính tả và liệt kê là gì?
Khả năng hiểu danh sách cung cấp một cách tạo danh sách nhỏ gọn và thanh lịch hơn so với vòng lặp for, và cũng có thể tạo danh sách mới từ danh sách hiện có.
Cú pháp được sử dụng như sau:
a for a in iterator
Hoặc,
a for a in iterator if condition
ví dụ:
list1 = [a for a in range(5)]
print(list1)
list2 = [a for a in range(5) if a < 3]
print(list2)
Tính năng hiểu từ điển cung cấp một cách nhỏ gọn và trang nhã hơn để tạo từ điển, đồng thời, có thể tạo từ điển mới từ các từ điển hiện có.
Cú pháp được sử dụng là:
{key: expression for an item in iterator}
ví dụ:
dict([(i, i*2) for i in range(5)])
93. Sự khác biệt giữa xrange và range trong Python là gì?
range () và xrange () là các hàm có sẵn trong python được sử dụng để tạo các số nguyên trong phạm vi được chỉ định. Có thể hiểu sự khác biệt giữa hai hàm này nếu python phiên bản 2.0 được sử dụng vì hàm xrange () của phiên bản python 3.0 được triển khai lại dưới dạng chính hàm range ().
Đối với python 2.0, sự khác biệt giữa hàm range và xrange như sau:
- range () chiếm nhiều bộ nhớ hơn một cách tương đối
- xrange (), tốc độ thực thi tương đối nhanh hơn
- range () trả về danh sách các số nguyên và xrange () trả về đối tượng máy phát điện.
ExPhong phú:
for i in range(1,10,2): print(i) 94. Sự khác biệt giữa tệp .py và .pyc là gì?
.py là các tệp mã nguồn trong python mà trình thông dịch python thông dịch.
.pyc là các tệp được biên dịch là các mã byte được tạo bởi trình biên dịch python, nhưng tệp .pyc chỉ được tạo cho các mô-đun / tệp có sẵn.
Câu hỏi phỏng vấn lập trình Python
Ngoài kiến thức lý thuyết, có kinh nghiệm thực tế và biết lập trình các câu hỏi phỏng vấn là một phần quan trọng trong quá trình phỏng vấn. Nó giúp nhà tuyển dụng hiểu được kinh nghiệm thực hành của bạn. Đây là 45+ câu hỏi phỏng vấn lập trình Python thường được hỏi nhất.
Dưới đây là hình ảnh đại diện về cách tạo đầu ra lập trình python.

95. Bạn có tập dữ liệu covid-19 này bên dưới:
Đây là một trong những câu hỏi phỏng vấn python phổ biến nhất
Từ tập dữ liệu này, bạn sẽ lập biểu đồ thanh cho 5 tiểu bang hàng đầu có số trường hợp được xác nhận tối đa là 17 = 07-2020 như thế nào?
sol:
#keeping only required columns df = df[[‘Date’, ‘State/UnionTerritory’,’Cured’,’Deaths’,’Confirmed’]] #renaming column names df.columns = [‘date’, ‘state’,’cured’,’deaths’,’confirmed’] #current date today = df[df.date == ‘2020-07-17’] #Sorting data w.r.t number of confirmed cases max_confirmed_cases=today.sort_values(by=”confirmed”,ascending=False) max_confirmed_cases #Getting states with maximum number of confirmed cases top_states_confirmed=max_confirmed_cases[0:5] #Making bar-plot for states with top confirmed cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”confirmed”,data=top_states_confirmed,hue=”state”) plt.show()
Giải thích mã:
Chúng tôi bắt đầu bằng cách chỉ lấy các cột bắt buộc với lệnh này:
df = df[[‘Date’, ‘State/UnionTerritory’,’Cured’,’Deaths’,’Confirmed’]]
Sau đó, chúng tôi tiếp tục và đổi tên các cột:
df.columns = [‘date’, ‘state’,’cured’,’deaths’,’confirmed’]
Sau đó, chúng tôi chỉ trích xuất các bản ghi đó, trong đó ngày bằng ngày 17 tháng XNUMX:
today = df[df.date == ‘2020-07-17’]
Sau đó, chúng tôi tiếp tục và chọn 5 tiểu bang hàng đầu có số lượng tối đa. trường hợp covid:
max_confirmed_cases=today.sort_values(by=”confirmed”,ascending=False)
max_confirmed_cases
top_states_confirmed=max_confirmed_cases[0:5]
Cuối cùng, chúng tôi tiếp tục và tạo một biểu đồ thanh với điều này:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.barplot(x=”state”,y=”confirmed”,data=top_states_confirmed,hue=”state”)
plt.show()
Ở đây, chúng tôi đang sử dụng thư viện seaborn để tạo cốt truyện cho quán bar. Cột "Trạng thái" được ánh xạ vào trục x và cột "đã xác nhận" được ánh xạ vào trục y. Màu của các thanh được xác định bởi cột "trạng thái".
96. Từ tập dữ liệu covid-19 này:
Làm thế nào bạn có thể lập một biểu đồ thanh cho 5 bang đứng đầu với số lượng người chết nhiều nhất?
max_death_cases=today.sort_values(by=”deaths”,ascending=False) max_death_cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”deaths”,data=top_states_death,hue=”state”) plt.show()
Giải thích mã:
Chúng tôi bắt đầu bằng cách sắp xếp khung dữ liệu của mình theo thứ tự giảm dần trong cột "số người chết":
max_death_cases=today.sort_values(by=”deaths”,ascending=False)
Max_death_cases
Sau đó, chúng tôi tiếp tục và thực hiện cốt truyện thanh với sự trợ giúp của thư viện seaborn:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.barplot(x=”state”,y=”deaths”,data=top_states_death,hue=”state”)
plt.show()
Ở đây, chúng tôi đang ánh xạ cột "trạng thái" lên trục x và cột "tử vong" vào trục y.
97. Từ tập dữ liệu covid-19 này:
Làm thế nào bạn có thể vẽ một biểu đồ dòng chỉ ra các trường hợp đã được xác nhận cho đến nay?
Mặt trời:
maha = df[df.state == ‘Maharashtra’] sns.set(rc={‘figure.figsize’:(15,10)}) sns.lineplot(x=”date”,y=”confirmed”,data=maha,color=”g”) plt.show()
Giải thích mã:
Chúng tôi bắt đầu bằng cách trích xuất tất cả các bản ghi có trạng thái bằng “Maharashtra”:
maha = df[df.state == ‘Maharashtra’]
Sau đó, chúng tôi tiếp tục và tạo một sơ đồ dòng bằng cách sử dụng thư viện seaborn:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.lineplot(x=”date”,y=”confirmed”,data=maha,color=”g”)
plt.show()
Ở đây, chúng tôi ánh xạ cột "ngày" lên trục x và cột "đã xác nhận" vào trục y.
98. Trên tập dữ liệu “Maharashtra” này:
Bạn sẽ triển khai thuật toán hồi quy tuyến tính như thế nào với “ngày tháng” là biến độc lập và “được xác nhận” là biến phụ thuộc? Đó là bạn phải dự đoán số trường hợp xác nhận wrt date.
from sklearn.model_selection import train_test_split maha[‘date’]=maha[‘date’].map(dt.datetime.toordinal) maha.head() x=maha[‘date’] y=maha[‘confirmed’] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(np.array(x_train).reshape(-1,1),np.array(y_train).reshape(-1,1)) lr.predict(np.array([[737630]]))
Giải pháp mã:
Chúng tôi sẽ bắt đầu bằng cách chuyển đổi ngày thành loại thứ tự:
from sklearn.model_selection import train_test_split
maha[‘date’]=maha[‘date’].map(dt.datetime.toordinal)
Điều này được thực hiện bởi vì chúng tôi không thể xây dựng thuật toán hồi quy tuyến tính trên đầu cột ngày.
Sau đó, chúng tôi tiếp tục và chia tập dữ liệu thành các tập huấn luyện và thử nghiệm:
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
Cuối cùng, chúng tôi tiếp tục và xây dựng mô hình:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(np.array(x_train).reshape(-1,1),np.array(y_train).reshape(-1,1))
lr.predict(np.array([[737630]]))
99. Trên tập dữ liệu customer_churn này:
Đây là một trong những câu hỏi phỏng vấn python phổ biến nhất
Xây dựng mô hình tuần tự Keras để tìm ra bao nhiêu khách hàng sẽ kiếm được trên cơ sở thời hạn sử dụng của khách hàng?
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(12, input_dim=1, activation=’relu’)) model.add(Dense(8, activation=’relu’)) model.add(Dense(1, activation=’sigmoid’)) model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) model.fit(x_train, y_train, epochs=150,validation_data=(x_test,y_test)) y_pred = model.predict_classes(x_test) from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_pred)
Giải thích mã:
Chúng tôi sẽ bắt đầu bằng cách nhập các thư viện được yêu cầu:
from Keras.models import Sequential
from Keras.layers import Dense
Sau đó, chúng tôi tiếp tục và xây dựng cấu trúc của mô hình tuần tự:
model = Sequential()
model.add(Dense(12, input_dim=1, activation=’relu’))
model.add(Dense(8, activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
Cuối cùng, chúng tôi sẽ tiếp tục và dự đoán các giá trị:
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
model.fit(x_train, y_train, epochs=150,validation_data=(x_test,y_test))
y_pred = model.predict_classes(x_test)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_pred)
100. Trên tập dữ liệu mống mắt này:
Xây dựng mô hình phân loại cây quyết định, trong đó biến phụ thuộc là “Species” và biến độc lập là “Sepal.Length”.
y = iris[[‘Species’]] x = iris[[‘Sepal.Length’]] from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.4) from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier() dtc.fit(x_train,y_train) y_pred=dtc.predict(x_test) from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_pred)
(22+7+9)/(22+2+0+7+7+11+1+1+9)
Giải thích mã:
Chúng ta bắt đầu bằng cách trích xuất biến độc lập và biến phụ thuộc:
y = iris[[‘Species’]]
x = iris[[‘Sepal.Length’]]
Sau đó, chúng tôi tiếp tục và chia dữ liệu thành tập huấn luyện và thử nghiệm:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.4)
Sau đó, chúng tôi tiếp tục và xây dựng mô hình:
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(x_train,y_train)
y_pred=dtc.predict(x_test)
Cuối cùng, chúng tôi xây dựng ma trận nhầm lẫn:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_pred)
(22+7+9)/(22+2+0+7+7+11+1+1+9)
101. Trên tập dữ liệu mống mắt này:
Xây dựng mô hình hồi quy cây quyết định trong đó biến độc lập là "chiều dài cánh hoa" và biến phụ thuộc là "chiều dài riêng".
x= iris[[‘Petal.Length’]] y = iris[[‘Sepal.Length’]] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25) from sklearn.tree import DecisionTreeRegressor dtr = DecisionTreeRegressor() dtr.fit(x_train,y_train) y_pred=dtr.predict(x_test) y_pred[0:5] from sklearn.metrics import mean_squared_error mean_squared_error(y_test,y_pred)
102. Bạn sẽ lấy dữ liệu từ trang web “cricbuzz” như thế nào?
import sys import time from bs4 import BeautifulSoup import requests import pandas as pd try: #use the browser to get the url. This is suspicious command that might blow up. page=requests.get(‘cricbuzz.com’) # this might throw an exception if something goes wrong. except Exception as e: # this describes what to do if an exception is thrown error_type, error_obj, error_info = sys.exc_info() # get the exception information print (‘ERROR FOR LINK:’,url) #print the link that cause the problem print (error_type, ‘Line:’, error_info.tb_lineno) #print error info and line that threw the exception #ignore this page. Abandon this and go back. time.sleep(2) soup=BeautifulSoup(page.text,’html.parser’) links=soup.find_all(‘span’,attrs={‘class’:’w_tle’}) links for i in links: print(i.text) print(“n”)
103. Viết một hàm do người dùng định nghĩa để thực hiện định lý giới hạn trung tâm. Bạn phải thực hiện định lý giới hạn trung tâm trên tập dữ liệu "bảo hiểm" này:
Bạn cũng phải xây dựng hai biểu đồ về “Phân bố BMI lấy mẫu” và “Phân bố BMI theo dân số”.
df = pd.read_csv(‘insurance.csv’) series1 = df.charges series1.dtype def central_limit_theorem(data,n_samples = 1000, sample_size = 500, min_value = 0, max_value = 1338): “”” Use this function to demonstrate Central Limit Theorem. data = 1D array, or a pd.Series n_samples = number of samples to be created sample_size = size of the individual sample min_value = minimum index of the data max_value = maximum index value of the data “”” %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns b = {} for i in range(n_samples): x = np.unique(np.random.randint(min_value, max_value, size = sample_size)) # set of random numbers with a specific size b[i] = data[x].mean() # Mean of each sample c = pd.DataFrame() c[‘sample’] = b.keys() # Sample number c[‘Mean’] = b.values() # mean of that particular sample plt.figure(figsize= (15,5)) plt.subplot(1,2,1) sns.distplot(c.Mean) plt.title(f”Sampling Distribution of bmi. n u03bc = {round(c.Mean.mean(), 3)} & SE = {round(c.Mean.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.subplot(1,2,2) sns.distplot(data) plt.title(f”population Distribution of bmi. n u03bc = {round(data.mean(), 3)} & u03C3 = {round(data.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.show() central_limit_theorem(series1,n_samples = 5000, sample_size = 500)
Giải thích mã:
Chúng tôi bắt đầu bằng cách nhập tệp bảo hiểm.csv bằng lệnh sau:
df = pd.read_csv(‘insurance.csv’)
Sau đó, chúng tôi tiếp tục và xác định phương pháp định lý giới hạn trung tâm:
def central_limit_theorem(data,n_samples = 1000, sample_size = 500, min_value = 0, max_value = 1338):
Phương thức này bao gồm các tham số sau:
- Ngày
- N_mẫu
- Cỡ mẫu
- giá trị tối thiểu
- Giá trị tối đa
Bên trong phương thức này, chúng tôi nhập tất cả các thư viện được yêu cầu:
mport pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Sau đó, chúng tôi tiếp tục và tạo tiểu đồ đầu tiên cho "Lấy mẫu phân phối bmi":
plt.subplot(1,2,1) sns.distplot(c.Mean) plt.title(f”Sampling Distribution of bmi. n u03bc = {round(c.Mean.mean(), 3)} & SE = {round(c.Mean.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’)
Cuối cùng, chúng tôi tạo tiểu đồ cho “Phân bố BMI theo dân số”:
plt.subplot(1,2,2) sns.distplot(data) plt.title(f”population Distribution of bmi. n u03bc = {round(data.mean(), 3)} & u03C3 = {round(data.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.show()
104. Viết mã để thực hiện phân tích tình cảm trên các bài đánh giá trên amazon:
Đây là một trong những câu hỏi phỏng vấn python phổ biến nhất.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from tensorflow.python.keras import models, layers, optimizers import tensorflow from tensorflow.keras.preprocessing.text import Tokenizer, text_to_word_sequence from tensorflow.keras.preprocessing.sequence import pad_sequences import bz2 from sklearn.metrics import f1_score, roc_auc_score, accuracy_score import re %matplotlib inline def get_labels_and_texts(file): labels = [] texts = [] for line in bz2.BZ2File(file): x = line.decode(“utf-8”) labels.append(int(x[9]) – 1) texts.append(x[10:].strip()) return np.array(labels), texts train_labels, train_texts = get_labels_and_texts(‘train.ft.txt.bz2’) test_labels, test_texts = get_labels_and_texts(‘test.ft.txt.bz2’) Train_labels[0] Train_texts[0] train_labels=train_labels[0:500] train_texts=train_texts[0:500] import re NON_ALPHANUM = re.compile(r'[W]’) NON_ASCII = re.compile(r'[^a-z0-1s]’) def normalize_texts(texts): normalized_texts = [] for text in texts: lower = text.lower() no_punctuation = NON_ALPHANUM.sub(r’ ‘, lower) no_non_ascii = NON_ASCII.sub(r”, no_punctuation) normalized_texts.append(no_non_ascii) return normalized_texts train_texts = normalize_texts(train_texts) test_texts = normalize_texts(test_texts) from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(binary=True) cv.fit(train_texts) X = cv.transform(train_texts) X_test = cv.transform(test_texts) from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split X_train, X_val, y_train, y_val = train_test_split( X, train_labels, train_size = 0.75) for c in [0.01, 0.05, 0.25, 0.5, 1]: lr = LogisticRegression(C=c) lr.fit(X_train, y_train) print (“Accuracy for C=%s: %s” % (c, accuracy_score(y_val, lr.predict(X_val)))) lr.predict(X_test[29])
105. Thực hiện một biểu đồ xác suất bằng cách sử dụng numpy và matplotlib:
sol:
import numpy as np import pylab import scipy.stats as stats from matplotlib import pyplot as plt n1=np.random.normal(loc=0,scale=1,size=1000) np.percentile(n1,100) n1=np.random.normal(loc=20,scale=3,size=100) stats.probplot(n1,dist=”norm”,plot=pylab) plt.show()
106. Thực hiện nhiều hồi quy tuyến tính trên tập dữ liệu mống mắt này:
Các biến độc lập phải là “Sepal.Width”, “Petal.Length”, “Petal.Width”, trong khi biến phụ thuộc phải là “Sepal.Length”.
Mặt trời:
import pandas as pd iris = pd.read_csv(“iris.csv”) iris.head() x = iris[[‘Sepal.Width’,’Petal.Length’,’Petal.Width’]] y = iris[[‘Sepal.Length’]] from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.35) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(x_train, y_train) y_pred = lr.predict(x_test) from sklearn.metrics import mean_squared_error mean_squared_error(y_test, y_pred)
Giải pháp mã:
Chúng tôi bắt đầu bằng cách nhập các thư viện được yêu cầu:
import pandas as pd
iris = pd.read_csv(“iris.csv”)
iris.head()
Sau đó, chúng ta sẽ tiếp tục và trích xuất các biến độc lập và biến phụ thuộc:
x = iris[[‘Sepal.Width’,’Petal.Length’,’Petal.Width’]]
y = iris[[‘Sepal.Length’]]
Sau đó, chúng tôi chia dữ liệu thành các tập huấn luyện và thử nghiệm:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.35)
Sau đó, chúng tôi tiếp tục và xây dựng mô hình:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x_train, y_train)
y_pred = lr.predict(x_test)
Cuối cùng, chúng ta sẽ tìm ra lỗi bình phương trung bình:
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_pred)
107. Từ tập dữ liệu gian lận tín dụng này:
Tìm tỷ lệ phần trăm giao dịch gian lận và không gian lận. Đồng thời xây dựng một mô hình hồi quy logistic, để tìm ra liệu giao dịch có gian lận hay không.
Mặt trời:
nfcount=0 notFraud=data_df[‘Class’] for i in range(len(notFraud)): if notFraud[i]==0: nfcount=nfcount+1 nfcount per_nf=(nfcount/len(notFraud))*100 print(‘percentage of total not fraud transaction in the dataset: ‘,per_nf) fcount=0 Fraud=data_df[‘Class’] for i in range(len(Fraud)): if Fraud[i]==1: fcount=fcount+1 fcount per_f=(fcount/len(Fraud))*100 print(‘percentage of total fraud transaction in the dataset: ‘,per_f) x=data_df.drop([‘Class’], axis = 1)#drop the target variable y=data_df[‘Class’] xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size = 0.2, random_state = 42) logisticreg = LogisticRegression() logisticreg.fit(xtrain, ytrain) y_pred = logisticreg.predict(xtest) accuracy= logisticreg.score(xtest,ytest) cm = metrics.confusion_matrix(ytest, y_pred) print(cm)
108. Triển khai một CNN đơn giản trên tập dữ liệu MNIST bằng Keras. Theo dõi cái này, cũng thêm vào menu thả ra các lớp.
Mặt trời:
from __future__ import absolute_import, division, print_function import numpy as np # import keras from tensorflow.keras.datasets import cifar10, mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten, Reshape from tensorflow.keras.layers import Convolution2D, MaxPooling2D from tensorflow.keras import utils import pickle from matplotlib import pyplot as plt import seaborn as sns plt.rcParams[‘figure.figsize’] = (15, 8) %matplotlib inline # Load/Prep the Data (x_train, y_train_num), (x_test, y_test_num) = mnist.load_data() x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype(‘float32’) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype(‘float32’) x_train /= 255 x_test /= 255 y_train = utils.to_categorical(y_train_num, 10) y_test = utils.to_categorical(y_test_num, 10) print(‘— THE DATA —‘) print(‘x_train shape:’, x_train.shape) print(x_train.shape[0], ‘train samples’) print(x_test.shape[0], ‘test samples’) TRAIN = False BATCH_SIZE = 32 EPOCHS = 1 # Define the Type of Model model1 = tf.keras.Sequential() # Flatten Imgaes to Vector model1.add(Reshape((784,), input_shape=(28, 28, 1))) # Layer 1 model1.add(Dense(128, kernel_initializer=’he_normal’, use_bias=True)) model1.add(Activation(“relu”)) # Layer 2 model1.add(Dense(10, kernel_initializer=’he_normal’, use_bias=True)) model1.add(Activation(“softmax”)) # Loss and Optimizer model1.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) # Store Training Results early_stopping = keras.callbacks.EarlyStopping(monitor=’val_acc’, patience=10, verbose=1, mode=’auto’) callback_list = [early_stopping]# [stats, early_stopping] # Train the model model1.fit(x_train, y_train, nb_epoch=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), callbacks=callback_list, verbose=True) #drop-out layers: # Define Model model3 = tf.keras.Sequential() # 1st Conv Layer model3.add(Convolution2D(32, (3, 3), input_shape=(28, 28, 1))) model3.add(Activation(‘relu’)) # 2nd Conv Layer model3.add(Convolution2D(32, (3, 3))) model3.add(Activation(‘relu’)) # Max Pooling model3.add(MaxPooling2D(pool_size=(2,2))) # Dropout model3.add(Dropout(0.25)) # Fully Connected Layer model3.add(Flatten()) model3.add(Dense(128)) model3.add(Activation(‘relu’)) # More Dropout model3.add(Dropout(0.5)) # Prediction Layer model3.add(Dense(10)) model3.add(Activation(‘softmax’)) # Loss and Optimizer model3.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) # Store Training Results early_stopping = tf.keras.callbacks.EarlyStopping(monitor=’val_acc’, patience=7, verbose=1, mode=’auto’) callback_list = [early_stopping] # Train the model model3.fit(x_train, y_train, batch_size=BATCH_SIZE, nb_epoch=EPOCHS, validation_data=(x_test, y_test), callbacks=callback_list)
109. Triển khai hệ thống đề xuất dựa trên mức độ phổ biến trên tập dữ liệu ống kính phim này:
import os import numpy as np import pandas as pd ratings_data = pd.read_csv(“ratings.csv”) ratings_data.head() movie_names = pd.read_csv(“movies.csv”) movie_names.head() movie_data = pd.merge(ratings_data, movie_names, on=’movieId’) movie_data.groupby(‘title’)[‘rating’].mean().head() movie_data.groupby(‘title’)[‘rating’].mean().sort_values(ascending=False).head() movie_data.groupby(‘title’)[‘rating’].count().sort_values(ascending=False).head() ratings_mean_count = pd.DataFrame(movie_data.groupby(‘title’)[‘rating’].mean()) ratings_mean_count.head() ratings_mean_count[‘rating_counts’] = pd.DataFrame(movie_data.groupby(‘title’)[‘rating’].count()) ratings_mean_count.head() 110. Thực hiện thuật toán Bayes ngây thơ trên đầu bộ dữ liệu bệnh tiểu đường:
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) import matplotlib.pyplot as plt # matplotlib.pyplot plots data %matplotlib inline import seaborn as sns pdata = pd.read_csv(“pima-indians-diabetes.csv”) columns = list(pdata)[0:-1] # Excluding Outcome column which has only pdata[columns].hist(stacked=False, bins=100, figsize=(12,30), layout=(14,2)); # Histogram of first 8 columns
Tuy nhiên, chúng tôi muốn thấy mối tương quan trong biểu diễn đồ họa vì vậy dưới đây là hàm cho điều đó:
def plot_corr(df, size=11): corr = df.corr() fig, ax = plt.subplots(figsize=(size, size)) ax.matshow(corr) plt.xticks(range(len(corr.columns)), corr.columns) plt.yticks(range(len(corr.columns)), corr.columns) plot_corr(pdata)
from sklearn.model_selection import train_test_split X = pdata.drop(‘class’,axis=1) # Predictor feature columns (8 X m) Y = pdata[‘class’] # Predicted class (1=True, 0=False) (1 X m) x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=1) # 1 is just any random seed number x_train.head() from sklearn.naive_bayes import GaussianNB # using Gaussian algorithm from Naive Bayes # creatw the model diab_model = GaussianNB() diab_model.fit(x_train, y_train.ravel()) diab_train_predict = diab_model.predict(x_train) from sklearn import metrics print(“Model Accuracy: {0:.4f}”.format(metrics.accuracy_score(y_train, diab_train_predict))) print() diab_test_predict = diab_model.predict(x_test) from sklearn import metrics print(“Model Accuracy: {0:.4f}”.format(metrics.accuracy_score(y_test, diab_test_predict))) print() print(“Confusion Matrix”) cm=metrics.confusion_matrix(y_test, diab_test_predict, labels=[1, 0]) df_cm = pd.DataFrame(cm, index = [i for i in [“1″,”0”]], columns = [i for i in [“Predict 1″,”Predict 0”]]) plt.figure(figsize = (7,5)) sns.heatmap(df_cm, annot=True)
111. Làm thế nào bạn có thể tìm thấy các giá trị nhỏ nhất và lớn nhất có trong một bộ giá trị?
Giải pháp ->
Chúng ta có thể sử dụng hàm min () trên đầu bộ tuple để tìm ra giá trị nhỏ nhất có trong bộ tuple:
tup1=(1,2,3,4,5)
min(tup1)
Đầu ra
1
Chúng ta thấy rằng giá trị nhỏ nhất hiện diện trong bộ giá trị là 1.
Tương tự với hàm min () là hàm max (), sẽ giúp chúng ta tìm ra giá trị lớn nhất có trong bộ tuple:
tup1=(1,2,3,4,5)
max(tup1)
Đầu ra
5
Chúng ta thấy rằng giá trị lớn nhất có trong bộ giá trị là 5.
112. Nếu bạn có một danh sách như thế này -> [1, ”a”, 2, ”b”, 3, ”c”]. Làm thế nào bạn có thể truy cập các yếu tố thứ 2, 4 và 5 từ danh sách này?
Giải pháp ->
Chúng ta sẽ bắt đầu bằng cách tạo một bộ tuple sẽ bao gồm các chỉ số của các phần tử mà chúng ta muốn truy cập.
Sau đó, chúng ta sẽ sử dụng vòng lặp for để đi qua các giá trị chỉ mục và in chúng ra.
Dưới đây là toàn bộ mã cho quy trình:
indices = (1,3,4)
for i in indices: print(a[i])
113. Nếu bạn có một danh sách như thế này -> [“sparta”, True, 3 + 4j, False]. Làm thế nào bạn sẽ đảo ngược các yếu tố của danh sách này?
Giải pháp ->
Chúng ta có thể sử dụng hàm reverse () trong danh sách:
a.reverse()
a
114. Nếu bạn có từ điển như thế này -> fruit = {“Apple”: 10, “Orange”: 20, “Banana”: 30, “Guava”: 40}. Bạn sẽ cập nhật giá trị của 'Apple' từ 10 lên 100 như thế nào?
Giải pháp ->
Đây là cách bạn có thể làm điều đó:
fruit["Apple"]=100
fruit
Nhập tên của khóa bên trong dấu ngoặc và gán cho nó một giá trị mới.
115. Nếu bạn có hai tập hợp như thế này -> s1 = {1,2,3,4,5,6}, s2 = {5,6,7,8,9}. Làm thế nào bạn sẽ tìm thấy các phần tử chung trong các tập hợp này.
Giải pháp ->
Bạn có thể sử dụng hàm giao () để tìm các phần tử chung giữa hai tập hợp:
s1 = {1,2,3,4,5,6}
s2 = {5,6,7,8,9}
s1.intersection(s2)
Chúng ta thấy rằng các phần tử chung giữa hai tập hợp là 5 & 6.
116. Viết chương trình in ra bảng 2 dấu bằng vòng lặp while.
Giải pháp ->
Dưới đây là mã để in ra bảng 2 cái:
Mã
i=1
n=2
while i<=10: print(n,"*", i, "=", n*i) i=i+1
Đầu ra
Chúng ta bắt đầu bằng cách khởi tạo hai biến 'i' và 'n'. 'i' được khởi tạo thành 1 và 'n' được khởi tạo thành '2'.
Bên trong vòng lặp while, vì giá trị 'i' đi từ 1 đến 10, vòng lặp lặp lại 10 lần.
Ban đầu n * i bằng 2 * 1, và chúng tôi in ra giá trị.
Sau đó, giá trị 'i' được tăng lên và n * i trở thành 2 * 2. Chúng tôi tiếp tục và in nó ra.
Quá trình này tiếp tục cho đến khi giá trị của tôi trở thành 10.
117. Viết một hàm, sẽ nhận một giá trị và in ra nếu nó là chẵn hay lẻ.
Giải pháp ->
Đoạn mã dưới đây sẽ thực hiện công việc:
def even_odd(x): if x%2==0: print(x," is even") else: print(x, " is odd")
Ở đây, chúng ta bắt đầu bằng cách tạo một phương thức, với tên 'Even_odd ()'. Hàm này nhận một tham số duy nhất và in ra nếu số được lấy là chẵn hoặc lẻ.
Bây giờ, hãy gọi hàm:
even_odd(5)
Chúng ta thấy rằng, khi 5 được truyền dưới dạng tham số vào hàm, chúng ta nhận được kết quả đầu ra -> '5 là số lẻ'.
118. Viết chương trình python để in giai thừa của một số.
Đây là một trong những câu hỏi phỏng vấn python phổ biến nhất
Giải pháp ->
Dưới đây là mã để in giai thừa của một số:
factorial = 1
#check if the number is negative, positive or zero
if num<0: print("Sorry, factorial does not exist for negative numbers")
elif num==0: print("The factorial of 0 is 1")
else for i in range(1,num+1): factorial = factorial*i print("The factorial of",num,"is",factorial)
Chúng tôi bắt đầu bằng cách lấy một đầu vào được lưu trữ trong 'num'. Sau đó, chúng tôi kiểm tra xem 'num' có nhỏ hơn không và nếu nó thực sự nhỏ hơn 0, chúng tôi in ra 'Rất tiếc, giai thừa không tồn tại cho số âm'.
Sau đó, chúng tôi kiểm tra, nếu 'num' bằng 0 và đúng như vậy, chúng tôi in ra 'Giai thừa của 1 là XNUMX'.
Mặt khác, nếu 'num' lớn hơn 1, chúng ta nhập vòng lặp for và tính giai thừa của số.
119. Viết chương trình python để kiểm tra xem số đã cho có phải là palindrome hay không
Giải pháp ->
Dưới đây là mã để Kiểm tra xem số đã cho có phải là palindrome hay không:
n=int(input("Enter number:"))
temp=n
rev=0
while(n>0) dig=n%10 rev=rev*10+dig n=n//10
if(temp==rev): print("The number is a palindrome!")
else: print("The number isn't a palindrome!")
Chúng tôi sẽ bắt đầu bằng cách lấy một đầu vào và lưu trữ nó trong 'n' và tạo một bản sao của nó trong 'tạm thời'. Chúng tôi cũng sẽ khởi tạo một biến khác 'rev' thành 0.
Sau đó, chúng ta sẽ nhập một vòng lặp while sẽ tiếp tục cho đến khi 'n' trở thành 0.
Bên trong vòng lặp, chúng ta sẽ bắt đầu bằng cách chia 'n' cho 10 và sau đó lưu trữ phần còn lại trong 'dig'.
Sau đó, chúng tôi sẽ nhân 'rev' với 10 và sau đó thêm 'dig' vào nó. Kết quả này sẽ được lưu lại trong 'rev'.
Tiếp tục, chúng ta sẽ chia 'n' cho 10 và lưu kết quả trở lại 'n'
Khi vòng lặp for kết thúc, chúng tôi sẽ so sánh các giá trị của 'rev' và 'temp'. Nếu chúng bằng nhau, chúng ta sẽ in "Số là một palindrome", nếu không, chúng ta sẽ in "Số không phải là palindrome".
120. Viết chương trình python để in mẫu sau ->
Đây là một trong những câu hỏi phỏng vấn python phổ biến nhất:
1
2 2
3 3 3
4 4 4 4
5 5 5 5 5
Giải pháp ->
Dưới đây là mã để in mẫu này:
#10 is the total number to print
for num in range(6): for i in range(num): print(num,end=" ")#print number #new line after each row to display pattern correctly print("n")
Chúng tôi đang giải quyết vấn đề với sự trợ giúp của vòng lặp for lồng nhau. Chúng ta sẽ có một vòng lặp for bên ngoài, đi từ 1 đến 5. Sau đó, chúng tôi có một vòng lặp for bên trong, sẽ in ra các số tương ứng.
121. Câu hỏi mẫu. In mẫu sau
#
# #
# # #
# # # #
# # # # #
Giải pháp ->
def pattern_1(num): # outer loop handles the number of rows # inner loop handles the number of columns # n is the number of rows. for i in range(0, n): # value of j depends on i for j in range(0, i+1): # printing hashes print("#",end="") # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_1(num)
122. In mẫu sau.
#
# #
# # #
# # # #
# # # # #
Giải pháp ->
Mã Code:
def pattern_2(num): # define the number of spaces k = 2*num - 2 # outer loop always handles the number of rows # let us use the inner loop to control the number of spaces # we need the number of spaces as maximum initially and then decrement it after every iteration for i in range(0, num): for j in range(0, k): print(end=" ") # decrementing k after each loop k = k - 2 # reinitializing the inner loop to keep a track of the number of columns # similar to pattern_1 function for j in range(0, i+1): print("# ", end="") # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_2(num)
123. In mẫu sau:
0
0 1
0 1 2
0 1 2 3
0 1 2 3 4
Giải pháp ->
Mã Code:
def pattern_3(num): # initialising starting number number = 1 # outer loop always handles the number of rows # let us use the inner loop to control the number for i in range(0, num): # re assigning number after every iteration # ensure the column starts from 0 number = 0 # inner loop to handle number of columns for j in range(0, i+1): # printing number print(number, end=" ") # increment number column wise number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_3(num)
124. In mẫu sau:
1
2 3
4 5 6
7 8 9 10
11 12 13 14 15
Giải pháp ->
Mã Code:
def pattern_4(num): # initialising starting number number = 1 # outer loop always handles the number of rows # let us use the inner loop to control the number for i in range(0, num): # commenting the reinitialization part ensure that numbers are printed continuously # ensure the column starts from 0 number = 0 # inner loop to handle number of columns for j in range(0, i+1): # printing number print(number, end=" ") # increment number column wise number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_4(num)
125. In mẫu sau:
A
BB
CCC
DDDD
Giải pháp ->
def pattern_5(num): # initializing value of A as 65 # ASCII value equivalent number = 65 # outer loop always handles the number of rows for i in range(0, num): # inner loop handles the number of columns for j in range(0, i+1): # finding the ascii equivalent of the number char = chr(number) # printing char value print(char, end=" ") # incrementing number number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_5(num)
126. In mẫu sau:
A
BC
DEF
GHIJ
KLMNO
PQRSTU
Giải pháp ->
def pattern_6(num): # initializing value equivalent to 'A' in ASCII # ASCII value number = 65 # outer loop always handles the number of rows for i in range(0, num): # inner loop to handle number of columns # values changing acc. to outer loop for j in range(0, i+1): # explicit conversion of int to char
# returns character equivalent to ASCII. char = chr(number) # printing char value print(char, end=" ") # printing the next character by incrementing number = number +1 # ending line after each row print("r") num = int(input("enter the number of rows in the pattern: "))
pattern_6(num)
127. In mẫu sau
#
# #
# # #
# # # #
# # # # #
Giải pháp ->
Mã Code:
def pattern_7(num): # number of spaces is a function of the input num k = 2*num - 2 # outer loop always handle the number of rows for i in range(0, num): # inner loop used to handle the number of spaces for j in range(0, k): print(end=" ") # the variable holding information about number of spaces # is decremented after every iteration k = k - 1 # inner loop reinitialized to handle the number of columns for j in range(0, i+1): # printing hash print("# ", end="") # ending line after each row print("r") num = int(input("Enter the number of rows: "))
pattern_7(n)
128. Nếu bạn có một từ điển như thế này -> d1 = {“k1 ″: 10,” k2 ″: 20, ”k3”: 30}. Làm thế nào bạn sẽ tăng giá trị của tất cả các khóa?
d1={"k1":10,"k2":20,"k3":30} for i in d1.keys(): d1[i]=d1[i]+1
129. Làm thế nào bạn có thể nhận được một số ngẫu nhiên trong python?
Ans. Để tạo ngẫu nhiên, chúng tôi sử dụng một mô-đun ngẫu nhiên của python. Dưới đây là một số ví dụ Để tạo một số dấu phẩy động từ 0-1
import random
n = random.random()
print(n)
To generate a integer between a certain range (say from a to b):
import random
n = random.randint(a,b)
print(n)
130. Giải thích cách bạn có thể thiết lập Cơ sở dữ liệu trong Django.
Tất cả các cài đặt của dự án, cũng như thông tin kết nối cơ sở dữ liệu, được chứa trong tệp settings.py. Django hoạt động với cơ sở dữ liệu SQLite theo mặc định, nhưng nó cũng có thể được cấu hình để hoạt động với các cơ sở dữ liệu khác.
Kết nối cơ sở dữ liệu yêu cầu thông tin kết nối đầy đủ, bao gồm tên cơ sở dữ liệu, thông tin đăng nhập người dùng, tên máy chủ và tên ổ đĩa, trong số những thứ khác.
Để kết nối với MySQL và thiết lập kết nối giữa ứng dụng và cơ sở dữ liệu, hãy sử dụng trình điều khiển django.db.backends.mysql.
Tất cả thông tin kết nối phải được bao gồm trong tệp cài đặt. Tệp settings.py trong dự án của chúng tôi có mã sau cho cơ sở dữ liệu.
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'djangoApp', 'USER':'root', 'PASSWORD':'mysql', 'HOST':'localhost', 'PORT':'3306' } } Lệnh này sẽ tạo các bảng cho admin, auth, contenttypes và session. Bây giờ bạn có thể kết nối với cơ sở dữ liệu MySQL bằng cách chọn nó từ menu thả xuống của cơ sở dữ liệu.
131. Cho một ví dụ về cách bạn có thể viết XEM trong Django?
Cấu trúc Django MVT không hoàn chỉnh nếu không có Chế độ xem Django. Hàm view là một hàm Python nhận yêu cầu Web và gửi phản hồi trên Web, theo hướng dẫn sử dụng Django. Phản hồi này có thể là nội dung HTML của trang web, chuyển hướng, lỗi 404, tài liệu XML, hình ảnh hoặc bất kỳ thứ gì khác mà trình duyệt web có thể hiển thị.
HTML / CSS / JavaScript trong các tệp Mẫu của bạn được chuyển đổi thành những gì bạn thấy trong trình duyệt của mình khi bạn hiển thị một trang web bằng các chế độ xem Django, là một phần của giao diện người dùng. (Không kết hợp lượt xem Django với lượt xem MVC nếu bạn đã sử dụng các khuôn khổ MVC (Model-View-Controller) khác.) Trong Django, các lượt xem cũng tương tự.
# import Http Response from django
from django.http import HttpResponse
# get datetime
import datetime
# create a function
def geeks_view(request): # fetch date and time now = datetime.datetime.now() # convert to string html = "Time is {}".format(now) # return response return HttpResponse(html)
132. Giải thích việc sử dụng các phiên trong khuôn khổ Django?
Django (và phần lớn Internet) sử dụng các phiên để theo dõi “trạng thái” của một trang web và trình duyệt cụ thể. Phiên cho phép bạn lưu bất kỳ lượng dữ liệu nào trên mỗi trình duyệt và cung cấp dữ liệu đó trên trang web mỗi khi trình duyệt kết nối. Các phần tử dữ liệu của phiên sau đó được biểu thị bằng một “chìa khóa”, có thể được sử dụng để lưu và khôi phục dữ liệu.
Django sử dụng cookie với một ID ký tự duy nhất để xác định bất kỳ trình duyệt nào và trang web của nó được liên kết với trang web. Dữ liệu phiên được lưu trữ trong cơ sở dữ liệu của trang web theo mặc định (điều này an toàn hơn so với việc lưu trữ dữ liệu trong cookie, nơi dữ liệu dễ bị tấn công hơn).
Django cho phép bạn lưu trữ dữ liệu phiên ở nhiều vị trí khác nhau (bộ nhớ cache, tệp, cookie “an toàn”), nhưng vị trí mặc định là một lựa chọn chắc chắn và an toàn.
Kích hoạt phiên
Khi chúng tôi xây dựng trang web khung, các phiên được bật theo mặc định.
Cấu hình được thiết lập trong tệp dự án (locallibrary / locallibrary / settings.py) trong phần INSTALLED_APPS và MIDDLEWARE, như được hiển thị bên dưới:
INSTALLED_APPS = [ ... 'django.contrib.sessions', ....
MIDDLEWARE = [ ... 'django.contrib.sessions.middleware.SessionMiddleware', …
Sử dụng phiên
Tham số yêu cầu cung cấp cho bạn quyền truy cập vào thuộc tính phiên của chế độ xem (một HttpRequest được chuyển vào làm đối số đầu tiên cho chế độ xem). Id phiên trong cookie của trình duyệt cho trang web này xác định kết nối cụ thể với người dùng hiện tại (hoặc chính xác hơn là kết nối với trình duyệt hiện tại).
Nội dung phiên là một mục giống như từ điển mà bạn có thể kiểm tra và ghi vào đó thường xuyên khi bạn cần trên chế độ xem của mình, cập nhật nó khi bạn di chuyển. Bạn có thể thực hiện tất cả các hành động từ điển chuẩn, chẳng hạn như xóa tất cả dữ liệu, kiểm tra sự hiện diện của khóa, lặp qua dữ liệu, v.v. Tuy nhiên, hầu hết thời gian, bạn sẽ chỉ lấy và đặt các giá trị bằng cách sử dụng API “từ điển” thông thường.
Các đoạn mã dưới đây trình bày cách lấy, thay đổi và xóa dữ liệu được liên kết với phiên hiện tại bằng cách sử dụng khóa “xe đạp của tôi” (trình duyệt).
Lưu ý: Một trong những điều tốt nhất về Django là bạn không phải lo lắng về các cơ chế mà bạn cho rằng đang kết nối phiên với yêu cầu hiện tại. Nếu chúng tôi sử dụng các phân đoạn bên dưới trong chế độ xem của mình, chúng tôi sẽ biết rằng thông tin về my_bike chỉ được liên kết với trình duyệt đã gửi yêu cầu hiện tại.
# Get a session value via its key (for example ‘my_bike’), raising a KeyError if the key is not present my_bike= request.session[‘my_bike’]
# Get a session value, setting a default value if it is not present ( ‘mini’)
my_bike= request.session.get(‘my_bike’, ‘mini’)
# Set a session value
request.session[‘my_bike’] = ‘mini’
# Delete a session value
del request.session[‘my_bike’]
Nhiều phương pháp khác nhau có sẵn trong API, hầu hết được sử dụng để kiểm soát cookie phiên được liên kết. Có nhiều cách để xác minh xem trình duyệt của khách hàng có hỗ trợ cookie hay không, để đặt và kiểm tra ngày hết hạn cookie và xóa các phiên đã hết hạn khỏi kho dữ liệu chẳng hạn. Cách sử dụng các phiên có thêm thông tin về toàn bộ API (tài liệu Django).
133. Liệt kê các kiểu kế thừa trong Django.
Các lớp cơ sở trừu tượng: Mẫu kế thừa này được các nhà phát triển sử dụng khi họ muốn lớp cha giữ dữ liệu mà họ không muốn gõ ra cho mỗi mô hình con.
models.py
from django.db import models # Create your models here. class ContactInfo(models.Model): name=models.CharField(max_length=20) email=models.EmailField(max_length=20) address=models.TextField(max_length=20) class Meta: abstract=True class Customer(ContactInfo): phone=models.IntegerField(max_length=15) class Staff(ContactInfo): position=models.CharField(max_length=10) admin.py
admin.site.register(Customer)
admin.site.register(Staff)
Hai bảng được hình thành trong cơ sở dữ liệu khi chúng tôi chuyển các sửa đổi này. Chúng tôi có các trường tên, email, địa chỉ và điện thoại trong Bảng khách hàng. Chúng tôi có các trường tên, email, địa chỉ và chức vụ trong Bảng Nhân viên. Bảng không phải là một lớp cơ sở được xây dựng trong Kế thừa này.
Kế thừa đa bảng: Nó được sử dụng khi bạn muốn phân lớp một mô hình hiện có và mỗi lớp con có bảng cơ sở dữ liệu riêng.
model.py
from django.db import models # Create your models here. class Place(models.Model): name=models.CharField(max_length=20) address=models.TextField(max_length=20) def __str__(self): return self.name class Restaurants(Place): serves_pizza=models.BooleanField(default=False) serves_pasta=models.BooleanField(default=False) def __str__(self): return self.serves_pasta admin.py from django.contrib import admin
from .models import Place,Restaurants
# Register your models here. admin.site.register(Place)
admin.site.register(Restaurants)
Mô hình proxy: Cách tiếp cận kế thừa này cho phép người dùng thay đổi hành vi ở mức cơ bản mà không thay đổi trường của mô hình.
Kỹ thuật này được sử dụng nếu bạn chỉ muốn thay đổi hành vi cấp Python của mô hình chứ không phải các trường của mô hình. Ngoại trừ các trường, bạn kế thừa từ lớp cơ sở và có thể thêm các thuộc tính của riêng bạn.
- Các lớp trừu tượng không nên được sử dụng như các lớp cơ sở.
- Không thể có nhiều kế thừa trong các mô hình proxy.
Mục đích chính của việc này là thay thế các chức năng chính của mô hình trước đó. Nó luôn sử dụng các phương thức được ghi đè để truy vấn mô hình ban đầu.
134. Làm cách nào bạn có thể lấy tuổi bộ đệm Google của bất kỳ URL hoặc trang web nào?
Sử dụng URL
https://webcache.googleusercontent.com/search?q=cache:<your url without “http://”>
Ví dụ:
Nó chứa một tiêu đề như thế này:
Đây là bộ nhớ cache của Google về https://stackoverflow.com/. Đó là ảnh chụp màn hình của trang khi nó nhìn vào lúc 11:33:38 GMT ngày 21 tháng 2012 năm XNUMX. Trong khi đó, trang hiện tại có thể đã thay đổi.
Mẹo: Sử dụng thanh tìm kiếm và nhấn Ctrl + F hoặc ⌘ + F (Mac) để tìm nhanh từ tìm kiếm của bạn trên trang này.
Bạn sẽ phải loại bỏ trang kết quả, tuy nhiên, trang bộ nhớ cache mới nhất có thể được tìm thấy tại URL này:
http://webcache.googleusercontent.com/search?q=cache:www.something.com/path
Div đầu tiên trong thẻ body chứa thông tin Google.
bạn có thể sử dụng trang web CachedPages
Các doanh nghiệp lớn có máy chủ web phức tạp thường bảo quản và lưu giữ các trang được lưu trong bộ nhớ cache. Bởi vì các máy chủ như vậy thường khá nhanh, một trang được lưu trong bộ nhớ cache thường có thể được truy xuất nhanh hơn so với trang web đang hoạt động:
- Bản sao hiện tại của trang thường được Google lưu giữ (từ 1 đến 15 ngày tuổi).
- Coral cũng giữ lại một bản sao hiện tại, mặc dù nó không được cập nhật như của Google.
- Bạn có thể truy cập một số phiên bản của một trang web được lưu giữ theo thời gian bằng Archive.org.
Vì vậy, lần tới khi bạn không thể truy cập một trang web nhưng vẫn muốn xem nó, phiên bản bộ nhớ cache của Google có thể là một lựa chọn tốt. Đầu tiên, hãy xác định xem tuổi tác có quan trọng hay không.
135. Giải thích ngắn gọn về không gian tên Python?
Không gian tên trong python nói về tên được gán cho từng đối tượng trong Python. Không gian tên được bảo tồn trong python giống như một từ điển trong đó khóa của từ điển là không gian tên và giá trị là địa chỉ của đối tượng đó.
các loại khác nhau như sau:
- Không gian tên tích hợp – Không gian tên chứa tất cả các đối tượng tích hợp sẵn trong python.
- Không gian tên chung – Không gian tên bao gồm tất cả các đối tượng được tạo khi bạn gọi chương trình chính của mình.
- Kèm theo không gian tên – Không gian tên ở đòn bẩy cao hơn.
- Không gian tên cục bộ – Không gian tên trong các chức năng cục bộ.
136. Giải thích ngắn gọn về câu lệnh Break, Pass và Continue trong Python?
Break: Khi chúng ta sử dụng câu lệnh break trong mã/chương trình python, nó ngay lập tức ngắt/chấm dứt vòng lặp và luồng điều khiển được đưa trở lại câu lệnh sau phần thân của vòng lặp.
Tiếp tục: Khi chúng ta sử dụng câu lệnh continue trong mã/chương trình python, nó sẽ ngay lập tức ngắt/chấm dứt lần lặp hiện tại của câu lệnh và cũng bỏ qua phần còn lại của chương trình trong lần lặp hiện tại và điều khiển chuyển sang lần lặp tiếp theo của vòng lặp.
Vượt qua: Khi chúng ta sử dụng câu lệnh vượt qua trong mã/chương trình python, nó sẽ lấp đầy các chỗ trống trong chương trình.
Ví dụ:
GL = [10, 30, 20, 100, 212, 33, 13, 50, 60, 70]
for g in GL:
pass
if (g == 0):
current = g
break
elif(g%2==0):
continue
print(g) # output => 1 3 1 3 1 print(current)
137. Hãy cho tôi một ví dụ về cách bạn có thể chuyển đổi danh sách thành chuỗi?
Ví dụ dưới đây sẽ chỉ ra cách chuyển đổi một danh sách thành một chuỗi. Khi chuyển đổi một danh sách thành một chuỗi, chúng ta có thể sử dụng hàm “.join” để làm điều tương tự.
fruits = [ ‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
listAsString = ‘ ‘.join(fruits)
print(listAsString)
táo cam xoài đu đủ ổi
138. Hãy cho tôi một ví dụ mà bạn có thể chuyển đổi một danh sách thành một bộ?
Ví dụ dưới đây sẽ chỉ ra cách chuyển đổi danh sách thành bộ dữ liệu. Khi chúng ta chuyển đổi một danh sách thành một bộ, chúng ta có thể sử dụng chức năng nhưng hãy nhớ vì các bộ dữ liệu là bất biến, chúng tôi không thể chuyển đổi nó trở lại danh sách.
fruits = [‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
listAsTuple = tuple(fruits)
print(listAsTuple)
('táo', 'cam', 'xoài', 'đu đủ', 'ổi')
139. Làm cách nào để đếm số lần xuất hiện của một phần tử cụ thể trong danh sách?
Trong cấu trúc dữ liệu danh sách của python, chúng ta đếm số lần xuất hiện của một phần tử bằng cách sử dụng hàm count().
fruits = [‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
print(fruits.count(‘apple’))
Đầu ra: 1
140. Làm cách nào để gỡ lỗi chương trình python?
Có một số cách để gỡ lỗi chương trình Python:
- Sử dụng
printcâu lệnh để in ra các biến và kết quả trung gian ra bàn điều khiển - Sử dụng trình gỡ lỗi như
pdboripdb - Thêm
assertcâu lệnh cho mã để kiểm tra các điều kiện nhất định
141. Sự khác biệt giữa danh sách và bộ trong Python là gì?
Danh sách là một kiểu dữ liệu có thể thay đổi, nghĩa là nó có thể được sửa đổi sau khi được tạo. Một tuple là bất biến, nghĩa là nó không thể được sửa đổi sau khi được tạo. Điều này làm cho bộ dữ liệu nhanh hơn và an toàn hơn so với danh sách, vì chúng không thể bị sửa đổi một cách tình cờ bởi các phần khác của mã.
142. Bạn xử lý ngoại lệ trong Python như thế nào?
Các ngoại lệ trong Python có thể được xử lý bằng cách sử dụng một try–except khối. Ví dụ:
Sao chép mãtry: # code that may raise an exception
except SomeExceptionType: # code to handle the exception
143. Làm cách nào để đảo ngược một chuỗi trong Python?
Có một số cách để đảo ngược một chuỗi trong Python:
- Sử dụng một lát cắt với bước -1:
Sao chép mãstring = "abcdefg"
reversed_string = string[::-1]
- Sử dụng
reversedchức năng:
Sao chép mãstring = "abcdefg"
reversed_string = "".join(reversed(string))
- Sử dụng vòng lặp for:
Sao chép mãstring = "abcdefg"
reversed_string = ""
for char in string: reversed_string = char + reversed_string
144. Làm cách nào để sắp xếp một danh sách trong Python?
Có một số cách để sắp xếp danh sách trong Python:
- Sử dụng
sortphương pháp:
Sao chép mãmy_list = [3, 4, 1, 2]
my_list.sort()
- Sử dụng
sortedchức năng:
Sao chép mãmy_list = [3, 4, 1, 2]
sorted_list = sorted(my_list)
- Sử dụng
sortchức năng từoperatormô-đun:
Sao chép mãfrom operator import itemgetter my_list = [{"a": 3}, {"a": 1}, {"a": 2}]
sorted_list = sorted(my_list, key=itemgetter("a"))
145. Bạn tạo từ điển bằng Python như thế nào?
Có một số cách để tạo từ điển trong Python:
- Sử dụng dấu ngoặc nhọn và dấu hai chấm để phân tách khóa và giá trị:
Sao chép mãmy_dict = {"key1": "value1", "key2": "value2"}
- Sử dụng
dictchức năng:
Sao chép mãmy_dict = dict(key1="value1", key2="value2")
- Sử dụng
dictngười xây dựng:
Sao chép mãmy_dict = dict({"key1": "value1", "key2": "value2"})
Câu hỏi 1. Làm thế nào để bạn nổi bật trong một cuộc phỏng vấn viết mã Python?
Bây giờ bạn đã sẵn sàng cho một Cuộc phỏng vấn Python về kỹ năng kỹ thuật, bạn phải tự hỏi làm thế nào để nổi bật giữa đám đông để bạn là ứng viên được chọn. Bạn phải có khả năng chứng tỏ rằng bạn có thể viết mã sản xuất sạch và có kiến thức về các thư viện và công cụ cần thiết. Nếu bạn đã từng thực hiện bất kỳ dự án nào trước đây, thì việc giới thiệu những dự án này trong cuộc phỏng vấn cũng sẽ giúp bạn nổi bật hơn so với phần còn lại của đám đông.
Cũng đọc: Các câu hỏi phỏng vấn phổ biến nhất
Câu hỏi 2. Làm cách nào để chuẩn bị cho một cuộc phỏng vấn Python?
Để chuẩn bị cho một cuộc Phỏng vấn Python, bạn phải biết cú pháp, từ khóa, hàm và lớp, kiểu dữ liệu, viết mã cơ bản và xử lý ngoại lệ. Có kiến thức cơ bản về tất cả các thư viện và IDE được sử dụng và đọc các blog liên quan đến Hướng dẫn Python sẽ giúp ích cho bạn. Giới thiệu các dự án mẫu của bạn, cải thiện các kỹ năng cơ bản của bạn về thuật toán và có thể tham gia một khóa học miễn phí về hướng dẫn cấu trúc dữ liệu python. Điều này sẽ giúp bạn chuẩn bị sẵn sàng.
Câu hỏi 3. Các cuộc phỏng vấn viết mã Python có rất khó không?
Mức độ khó của Phỏng vấn Python sẽ khác nhau tùy thuộc vào vị trí bạn đang ứng tuyển, công ty, yêu cầu của họ cũng như kỹ năng và kiến thức / kinh nghiệm làm việc của bạn. Nếu bạn là người mới bắt đầu trong lĩnh vực này và chưa tự tin về khả năng viết mã của mình, bạn có thể cảm thấy rằng cuộc phỏng vấn rất khó khăn. Chuẩn bị và biết loại câu hỏi phỏng vấn python sẽ giúp bạn chuẩn bị tốt và thành công trong cuộc phỏng vấn.
Câu hỏi 4. Làm cách nào để vượt qua cuộc phỏng vấn viết mã Python?
Có đầy đủ kiến thức về các thư viện Object Relational Mapper (ORM), Django hoặc Flask, kỹ năng gỡ lỗi và kiểm tra đơn vị, các nguyên tắc thiết kế cơ bản đằng sau một ứng dụng có thể mở rộng, các gói Python như NumPy, Scikit learning là cực kỳ quan trọng để bạn hoàn thành một cuộc phỏng vấn viết mã. Bạn có thể giới thiệu kinh nghiệm làm việc trước đây hoặc khả năng viết mã của mình thông qua các dự án, điều này đóng vai trò như một lợi thế bổ sung.
Cũng đọc: Cách xây dựng hồ sơ nhà phát triển Python
Câu hỏi 5. Làm thế nào để bạn gỡ lỗi một chương trình python?
Bằng cách sử dụng lệnh này, chúng tôi có thể gỡ lỗi chương trình trong thiết bị đầu cuối python.
$ python -m pdb python-script.py
Câu hỏi 6. Những khóa học hoặc chứng chỉ nào có thể giúp nâng cao kiến thức về Python?
Với điều này, chúng tôi đã đến cuối blog về Câu hỏi phỏng vấn Python hàng đầu. Nếu bạn muốn nâng cao kỹ năng, tham gia một khóa học chứng chỉ sẽ giúp bạn có được kiến thức cần thiết. Bạn có thể mất một khóa học lập trình python và bắt đầu sự nghiệp của bạn bằng Python.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.mygreatlearning.com/blog/python-interview-questions/

