LLM(대형 언어 모델)의 인기가 높아지고 있으며 새로운 사용 사례가 지속적으로 탐색되고 있습니다. 일반적으로 프롬프트 엔지니어링을 코드에 통합하여 LLM으로 구동되는 애플리케이션을 구축할 수 있습니다. 그러나 기존 LLM을 유도하는 것이 부족한 경우가 있습니다. 이것이 바로 모델 미세 조정이 도움이 될 수 있는 부분입니다. 프롬프트 엔지니어링은 입력 프롬프트를 작성하여 모델의 출력을 안내하는 반면, 미세 조정은 특정 작업이나 도메인에 더 적합하도록 사용자 지정 데이터 세트에서 모델을 훈련하는 것입니다.
모델을 미세 조정하려면 먼저 작업별 데이터 세트를 찾아야 합니다. 일반적으로 사용되는 데이터 세트 중 하나는 일반적인 크롤링 데이터세트. Common Crawl 자료에는 2008년부터 정기적으로 수집된 페타바이트 규모의 데이터가 포함되어 있으며 원시 웹페이지 데이터, 메타데이터 추출 및 텍스트 추출이 포함되어 있습니다. 어떤 데이터 세트를 사용해야 하는지 결정하는 것 외에도 미세 조정의 특정 요구에 맞게 데이터를 정리하고 처리하는 것이 필요합니다.
우리는 최근 최신 Common Crawl 데이터 세트의 하위 집합을 사전 처리한 다음 정리된 데이터로 LLM을 미세 조정하기를 원하는 고객과 협력했습니다. 고객은 AWS에서 가장 비용 효율적인 방법으로 이를 달성할 수 있는 방법을 찾고 있었습니다. 요구 사항을 논의한 후 사용을 권장했습니다. Amazon EMR 서버리스 데이터 전처리를 위한 플랫폼으로 사용됩니다. EMR Serverless는 대규모 데이터 처리에 적합하며 인프라 유지 관리가 필요하지 않습니다. 비용 측면에서는 각 작업에 사용된 리소스와 기간을 기준으로만 요금이 청구됩니다. 고객은 EMR Serverless를 사용하여 일주일 내에 수백 TB의 데이터를 전처리할 수 있었습니다. 그들은 데이터를 전처리한 후 다음을 사용했습니다. 아마존 세이지 메이커 LLM을 미세 조정합니다.
이 게시물에서는 고객의 사용 사례와 사용된 아키텍처를 안내합니다.
다음 섹션에서는 먼저 Common Crawl 데이터 세트와 필요한 데이터를 탐색하고 필터링하는 방법을 소개합니다. 아마존 아테나 스캔한 데이터 크기에 대해서만 비용이 청구되며 비용 효율적이면서 데이터를 빠르게 탐색하고 필터링하는 데 사용됩니다. EMR 서버리스는 Spark 데이터 처리를 위한 비용 효율적이고 유지 관리가 필요 없는 옵션을 제공하며 필터링된 데이터를 처리하는 데 사용됩니다. 다음으로 우리는 Amazon SageMaker 점프스타트 미세 조정하기 위해 라마 2 모델 전처리된 데이터세트로 SageMaker JumpStart는 몇 번의 클릭만으로 배포할 수 있는 가장 일반적인 사용 사례에 대한 솔루션 세트를 제공합니다. Llama 2와 같은 LLM을 미세 조정하기 위해 코드를 작성할 필요가 없습니다. 마지막으로 다음을 사용하여 미세 조정된 모델을 배포합니다. 아마존 세이지 메이커 원본 모델과 미세 조정된 Llama 2 모델 간에 동일한 질문에 대한 텍스트 출력의 차이를 비교합니다.
다음 다이어그램은이 솔루션의 아키텍처를 보여줍니다.
솔루션 세부 사항을 자세히 알아보기 전에 다음 전제 조건 단계를 완료하세요.
Common Crawl은 50억 개가 넘는 웹페이지를 크롤링하여 얻은 공개 코퍼스 데이터세트입니다. 여기에는 2008년부터 페타바이트 수준에 달하는 다양한 언어로 된 방대한 양의 구조화되지 않은 데이터가 포함되어 있습니다. 지속적으로 업데이트됩니다.
다음 다이어그램에 표시된 것처럼 GPT-3 교육에서 Common Crawl 데이터 세트는 교육 데이터의 60%를 차지합니다(출처: 언어 모델은 몇 번의 학습자입니다).
언급할 가치가 있는 또 다른 중요한 데이터세트는 C4 데이터세트. Colossal Clean Crawled Corpus의 약자인 C4는 Common Crawl 데이터세트를 후처리하여 파생된 데이터세트입니다. Meta의 LLaMA 논문에서는 Common Crawl이 67%(3.3TB의 데이터 활용)를 차지하고 C4가 15%(783GB의 데이터 활용)를 차지하는 데이터 세트를 간략하게 설명했습니다. 이 논문에서는 모델 성능을 향상시키기 위해 다르게 전처리된 데이터를 통합하는 것의 중요성을 강조합니다. 원본 C4 데이터가 Common Crawl의 일부임에도 불구하고 Meta는 이 데이터의 재처리된 버전을 선택했습니다.
이 섹션에서는 일반 크롤링 데이터 세트와 상호 작용, 필터링 및 처리하는 일반적인 방법을 다룹니다.
Common Crawl 원시 데이터 세트에는 원시 웹페이지 데이터(WARC), 메타데이터(WAT) 및 텍스트 추출(WET)의 세 가지 유형의 데이터 파일이 포함되어 있습니다.
2013년 이후 수집된 데이터는 WARC 형식으로 저장되며 해당 메타데이터(WAT)와 텍스트 추출 데이터(WET)가 포함됩니다. 데이터 세트는 Amazon S3에 있으며 매월 업데이트되며 다음을 통해 직접 액세스할 수 있습니다. AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gz일반 크롤링 데이터세트는 데이터 필터링을 위한 cc-index-table이라는 인덱스 테이블도 제공합니다.
cc-index-table은 기존 데이터의 인덱스로, WARC 파일의 테이블 기반 인덱스를 제공합니다. 특정 URL에 해당하는 WARC 파일과 같은 정보를 쉽게 조회할 수 있습니다.
예를 들어 다음 코드를 사용하여 Athena 테이블을 생성하여 cc-index 데이터를 매핑할 수 있습니다.
앞의 SQL 문은 Athena 테이블을 생성하고, 파티션을 추가하고, 쿼리를 실행하는 방법을 보여줍니다.
일반 크롤링 데이터세트의 데이터 필터링
create table SQL 문에서 볼 수 있듯이 데이터를 필터링하는 데 도움이 되는 여러 필드가 있습니다. 예를 들어 특정 기간 동안 중국 문서 수를 가져오려는 경우 SQL 문은 다음과 같을 수 있습니다.
추가 처리를 원할 경우 결과를 다른 S3 버킷에 저장할 수 있습니다.
필터링된 데이터 분석
XNUMXD덴탈의 일반 크롤링 GitHub 저장소 원시 데이터 처리를 위한 여러 PySpark 예제를 제공합니다.
실행 예시를 살펴보겠습니다. server_count.py (Common Crawl GitHub 저장소에서 제공하는 예제 스크립트) s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
먼저 EMR Spark와 같은 Spark 환경이 필요합니다. 예를 들어 EC2 클러스터에서 Amazon EMR을 시작할 수 있습니다. us-east-1 (데이터세트가 다음 위치에 있기 때문에 us-east-1). EC2 클러스터에서 EMR을 사용하면 프로덕션 환경에 작업을 제출하기 전에 테스트를 수행하는 데 도움이 될 수 있습니다.
EC2 클러스터에서 EMR을 시작한 후 클러스터의 기본 노드에 SSH 로그인을 수행해야 합니다. 그런 다음 Python 환경을 패키징하고 스크립트를 제출합니다(참조: 콘다 문서 Miniconda를 설치하려면):
warc.path의 모든 참조를 처리하는 데 시간이 걸릴 수 있습니다. 데모 목적으로 다음 전략을 사용하여 처리 시간을 향상시킬 수 있습니다.
- 파일 다운로드
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gz로컬 머신에 업로드하고 압축을 푼 다음 HDFS 또는 Amazon S3에 업로드하세요. 이는 .gzip 파일을 분할할 수 없기 때문입니다. 이 파일을 병렬로 처리하려면 압축을 풀어야 합니다. - 을 수정
warc.path파일을 삭제하고 대부분의 줄을 삭제하고 작업을 훨씬 빠르게 실행하려면 두 줄만 유지하세요.
작업이 완료되면 결과를 확인할 수 있습니다. s3://xxxx-common-crawl/output/, 쪽모이 세공 마루 형식.
맞춤형 보유 로직 구현
Common Crawl GitHub 저장소는 WARC 파일을 처리하는 일반적인 접근 방식을 제공합니다. 일반적으로 기간을 연장할 수 있습니다. CCSparkJob 단일 메서드를 재정의하려면(process_record), 많은 경우에 충분합니다.
최근 영화에 대한 IMDB 리뷰를 얻는 예를 살펴보겠습니다. 먼저 IMDB 사이트에서 파일을 필터링해야 합니다.
그런 다음 IMDB 리뷰 데이터가 포함된 WARC 파일 목록을 가져오고 WARC 파일 이름을 텍스트 파일의 목록으로 저장할 수 있습니다.
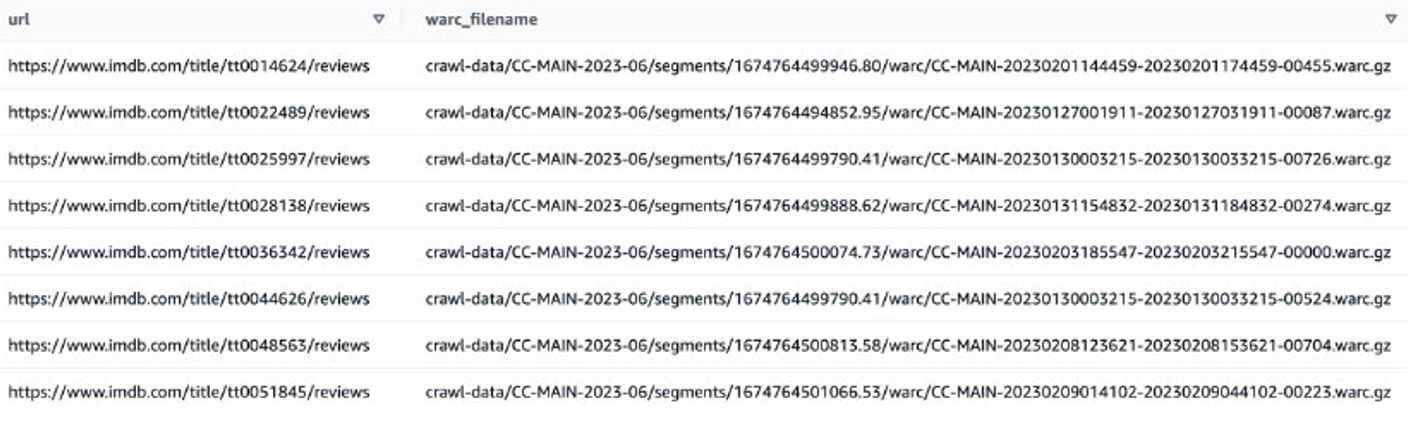
또는 EMR Spark를 사용하여 WARC 파일 목록을 가져와 Amazon S3에 저장할 수 있습니다. 예를 들어:
출력 파일은 다음과 유사해야 합니다. s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
다음 단계는 이러한 WARC 파일에서 사용자 리뷰를 추출하는 것입니다. 연장할 수 있습니다. CCSparkJob 재정의하다 process_record() 방법:
이전 스크립트를 다음 단계에서 사용할 imdb_extractor.py로 저장할 수 있습니다. 데이터와 스크립트를 준비한 후 EMR Serverless를 사용하여 필터링된 데이터를 처리할 수 있습니다.
EMR 서버리스
EMR 서버리스는 클러스터나 서버를 구성, 관리, 확장하지 않고도 Apache Spark 및 Hive와 같은 오픈 소스 프레임워크를 사용하여 빅 데이터 분석 애플리케이션을 실행하는 서버리스 배포 옵션입니다.
EMR 서버리스를 사용하면 변화하는 데이터 볼륨 및 처리 요구 사항을 충족하기 위해 몇 초 만에 리소스 크기를 조정하는 자동 조정을 통해 모든 규모의 분석 워크로드를 실행할 수 있습니다. EMR Serverless는 리소스를 자동으로 확장 및 축소하여 애플리케이션에 적합한 용량을 제공하며 사용한 만큼만 비용을 지불합니다.
Common Crawl 데이터 세트 처리는 일반적으로 일회성 처리 작업이므로 EMR 서버리스 워크로드에 적합합니다.
EMR 서버리스 애플리케이션 생성
EMR Studio 콘솔에서 EMR 서버리스 애플리케이션을 생성할 수 있습니다. 다음 단계를 완료하세요.
- EMR Studio 콘솔에서 다음을 선택합니다. 어플리케이션 아래에 서버리스 탐색 창에서
- 왼쪽 메뉴에서 응용 프로그램 만들기.

- 애플리케이션 이름을 제공하고 Amazon EMR 버전을 선택합니다.
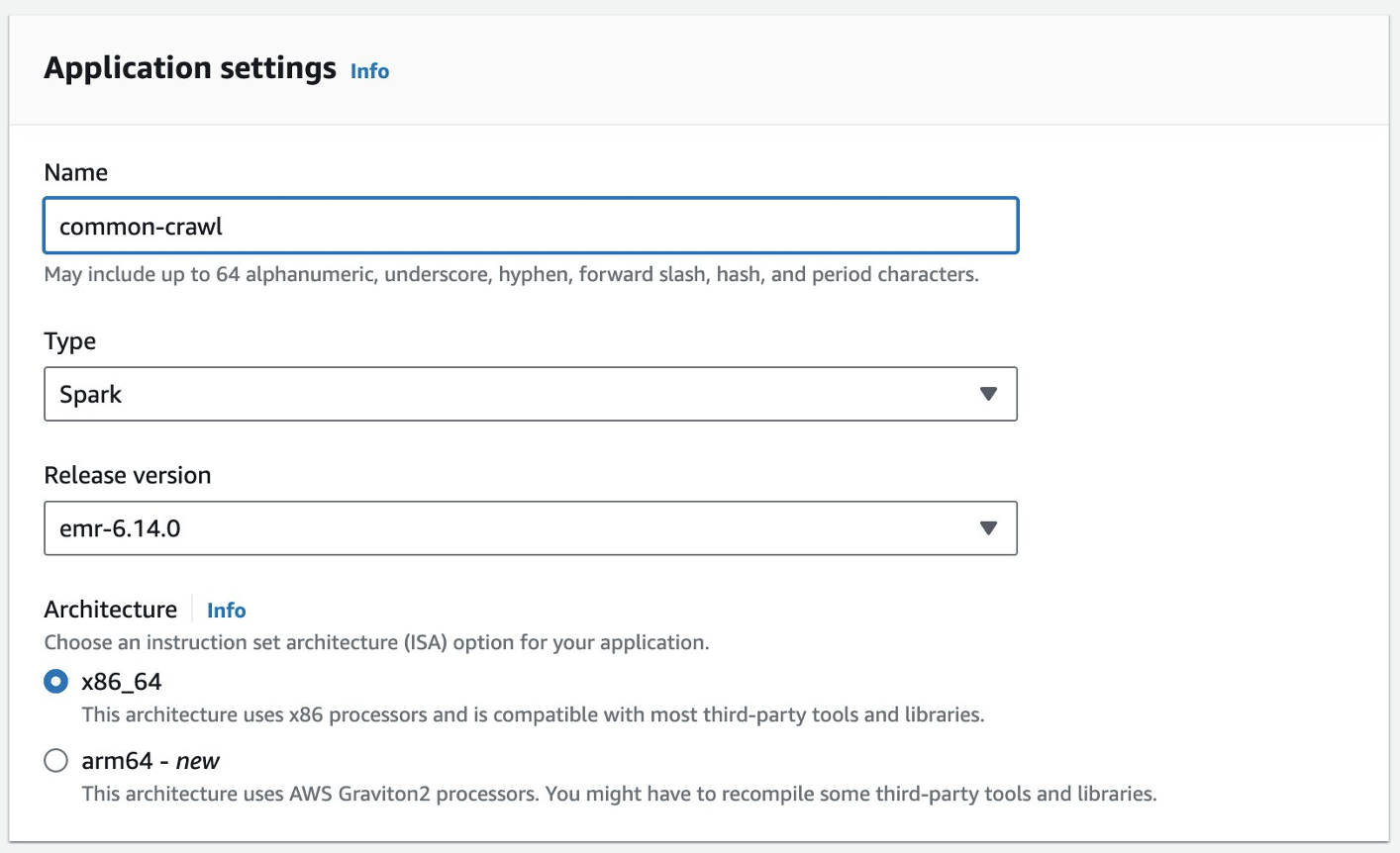
- VPC 리소스에 대한 액세스가 필요한 경우 사용자 정의된 네트워크 설정을 추가하십시오.

- 왼쪽 메뉴에서 응용 프로그램 만들기.
그러면 Spark 서버리스 환경이 준비됩니다.
EMR Spark Serverless에 작업을 제출하려면 먼저 실행 역할을 생성해야 합니다. 인용하다 Amazon EMR 서버리스 시작하기 자세한 내용은.
EMR 서버리스로 일반 크롤링 데이터 처리
EMR Spark 서버리스 애플리케이션이 준비되면 다음 단계를 완료하여 데이터를 처리하십시오.
- Conda 환경을 준비하고 EMR Spark Serverless에서 환경으로 사용할 Amazon S3에 업로드합니다.
- S3 버킷에 실행할 스크립트를 업로드합니다. 다음 예에는 두 개의 스크립트가 있습니다.
- imbd_extractor.py – 데이터세트에서 콘텐츠를 추출하는 맞춤형 로직. 해당 내용은 본 포스팅 앞부분에서 확인하실 수 있습니다.
- cc-pyspark/sparkcc.py – 예제 PySpark 프레임워크 일반 크롤링 GitHub 저장소, 반드시 포함되어야 합니다.
- PySpark 작업을 EMR Serverless Spark에 제출합니다. 사용자 환경에서 이 예제를 실행하려면 다음 매개변수를 정의하십시오.
- 애플리케이션 ID – EMR 서버리스 애플리케이션의 애플리케이션 ID입니다.
- 실행 역할 아른 – EMR 서버리스 실행 역할. 생성하려면 다음을 참조하세요. 작업 런타임 역할 생성.
- WARC 파일 위치 – WARC 파일의 위치.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt이 게시물의 앞부분에서 얻은 필터링된 WARC 파일 목록이 포함되어 있습니다. - Spark.sql.warehouse.dir – 기본 창고 위치(S3 디렉터리 사용)
- 스파크 아카이브 – 준비된 Conda 환경의 S3 위치.
- Spark.submit.py파일 – 준비된 PySpark 스크립트 Sparkcc.py.
다음 코드를 참조하십시오.
작업이 완료되면 추출된 리뷰가 Amazon S3에 저장됩니다. 내용을 확인하려면 다음 스크린샷과 같이 Amazon S3 Select를 사용할 수 있습니다.
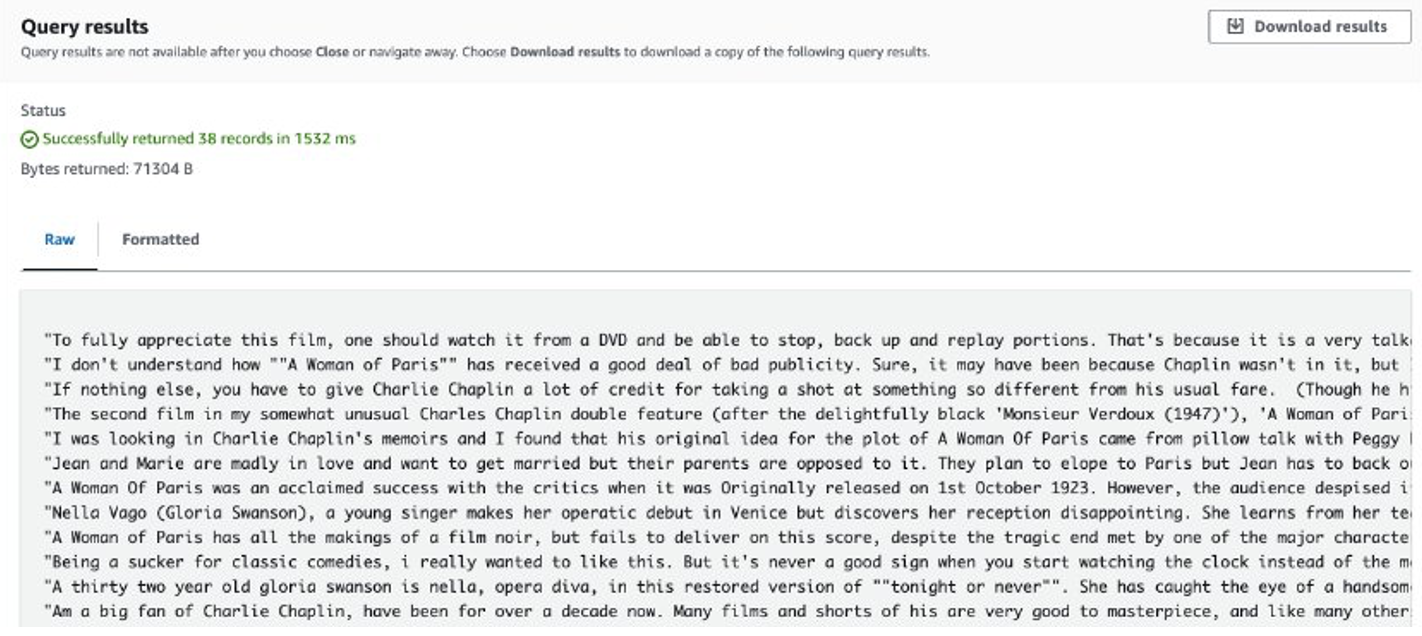
고려
맞춤형 코드로 대용량 데이터를 처리할 때 고려해야 할 사항은 다음과 같습니다.
- 일부 타사 Python 라이브러리는 Conda에서 사용하지 못할 수 있습니다. 이러한 경우 Python 가상 환경으로 전환하여 PySpark 런타임 환경을 구축할 수 있습니다.
- 처리할 데이터의 양이 많은 경우 여러 EMR Serverless Spark 애플리케이션을 생성하고 사용하여 병렬화해 보세요. 각 응용 프로그램은 파일 목록의 하위 집합을 처리합니다.
- Common Crawl 데이터를 필터링하거나 처리할 때 Amazon S3에서 속도 저하 문제가 발생할 수 있습니다. 이는 데이터를 저장하는 S3 버킷이 공개적으로 액세스 가능하고 다른 사용자가 동시에 데이터에 액세스할 수 있기 때문입니다. 이 문제를 완화하려면 재시도 메커니즘을 추가하거나 Common Crawl S3 버킷의 특정 데이터를 자체 버킷에 동기화하면 됩니다.
SageMaker로 Llama 2를 미세 조정하세요
데이터가 준비되면 이를 사용하여 Llama 2 모델을 미세 조정할 수 있습니다. 코드를 작성하지 않고도 SageMaker JumpStart를 사용하여 그렇게 할 수 있습니다. 자세한 내용은 다음을 참조하세요. Amazon SageMaker JumpStart에서 텍스트 생성을 위해 Llama 2 미세 조정.
이 시나리오에서는 도메인 적응 미세 조정을 수행합니다. 이 데이터 세트를 사용하면 입력이 CSV, JSON 또는 TXT 파일로 구성됩니다. 모든 리뷰 데이터를 TXT 파일에 넣어야 합니다. 이를 위해 간단한 Spark 작업을 EMR Spark Serverless에 제출할 수 있습니다. 다음 샘플 코드 조각을 참조하세요.
학습 데이터를 준비한 후 데이터 위치를 입력하세요. 훈련 데이터 세트다음을 선택 Train .
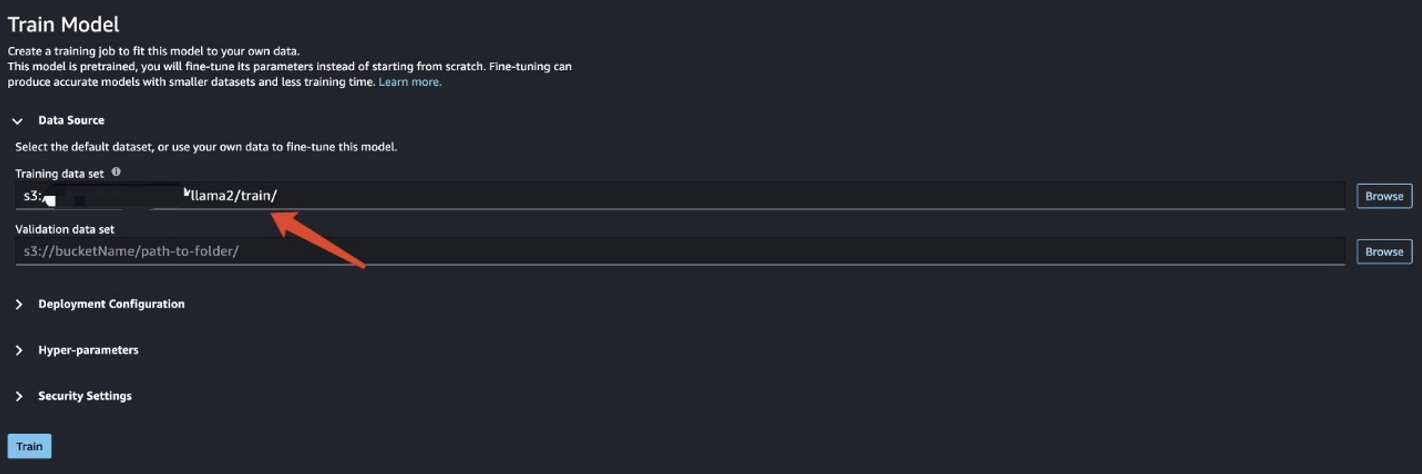
훈련 작업 상태를 추적할 수 있습니다.
미세 조정된 모델 평가
교육이 완료된 후 다음을 선택하세요. 배포 SageMaker JumpStart에서 미세 조정된 모델을 배포할 수 있습니다.

모델이 성공적으로 배포된 후 다음을 선택합니다. 노트북 열기, Python 코드를 실행할 수 있는 준비된 Jupyter Notebook으로 리디렉션됩니다.

노트북에 Data Science 2.0 이미지와 Python 3 커널을 사용할 수 있습니다.

그런 다음 이 노트북에서 미세 조정된 모델과 원본 모델을 평가할 수 있습니다.
다음은 동일한 질문에 대해 원본 모델과 미세 조정 모델에서 반환된 두 가지 응답입니다.
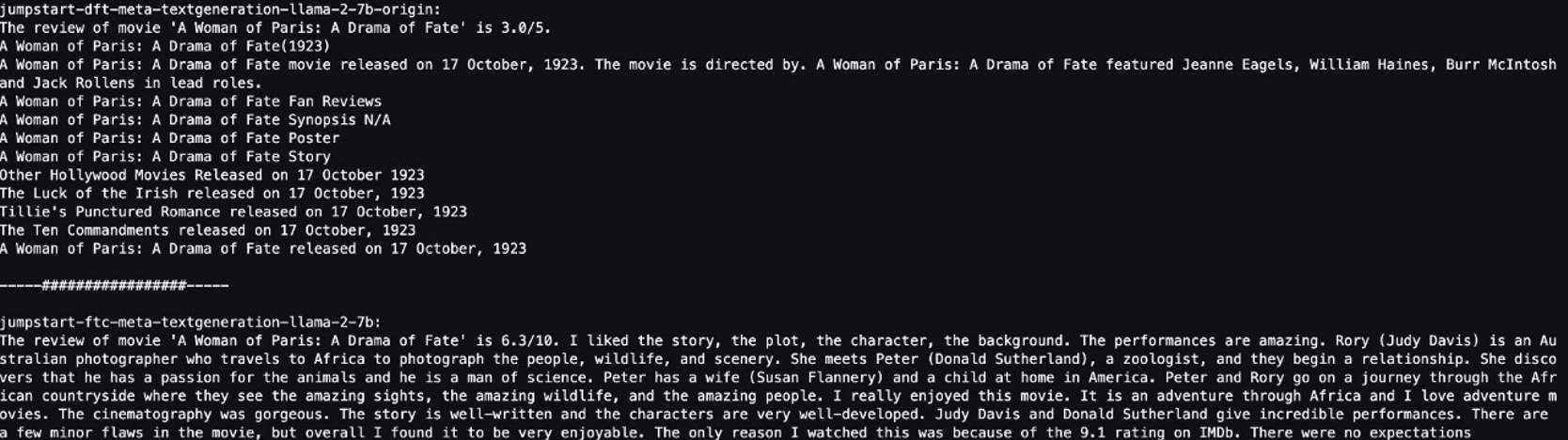
우리는 두 모델 모두에게 "영화 '파리의 여인: 운명의 드라마'에 대한 리뷰는 다음과 같습니다"라는 동일한 문장을 제공하고 문장을 완성하도록 했습니다.
원래 모델은 의미 없는 문장을 출력합니다.
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
대조적으로, 미세 조정된 모델의 출력은 영화 리뷰와 비슷합니다.
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
분명히 미세 조정된 모델은 이 특정 시나리오에서 더 나은 성능을 발휘합니다.
정리
이 연습을 마친 후 다음 단계를 완료하여 리소스를 정리하십시오.
- S3 버킷 삭제 정리된 데이터 세트를 저장합니다.
- EMR 서버리스 환경 중지.
- SageMaker 엔드포인트 삭제 LLM 모델을 호스팅하는 곳입니다.
- SageMaker 도메인 삭제 노트북을 실행하는 것입니다.
생성한 애플리케이션은 기본적으로 15분 동안 활동이 없으면 자동으로 중지되어야 합니다.
일반적으로 Athena 환경을 사용하지 않을 때 요금이 부과되지 않으므로 정리할 필요가 없습니다.
결론
이 게시물에서는 Common Crawl 데이터 세트와 EMR Serverless를 사용하여 LLM 미세 조정을 위한 데이터를 처리하는 방법을 소개했습니다. 그런 다음 SageMaker JumpStart를 사용하여 LLM을 미세 조정하고 코드 없이 배포하는 방법을 시연했습니다. EMR 서버리스의 추가 사용 사례는 다음을 참조하세요. Amazon EMR 서버리스. Amazon SageMaker JumpStart의 호스팅 및 모델 미세 조정에 대한 자세한 내용은 다음을 참조하십시오. Sagemaker JumpStart 문서.
저자에 관하여
 시지안 탕 Amazon Web Services의 분석 전문가 솔루션 설계자입니다.
시지안 탕 Amazon Web Services의 분석 전문가 솔루션 설계자입니다.
 매튜 림 Amazon Web Services의 수석 솔루션 아키텍처 관리자입니다.
매튜 림 Amazon Web Services의 수석 솔루션 아키텍처 관리자입니다.
 달리 쉬 Amazon Web Services의 분석 전문가 솔루션 설계자입니다.
달리 쉬 Amazon Web Services의 분석 전문가 솔루션 설계자입니다.
 샤오 위안준 Amazon Web Services의 수석 솔루션 설계자입니다.
샤오 위안준 Amazon Web Services의 수석 솔루션 설계자입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/

