目次
概要
学習とは、経験を通じて特定の領域に関する知識を獲得し、習得することです。 それは人間だけのものではなく、機械にも関係しています。 コンピューティングの世界は、人工知能の出現により、効果のない機械システムから非常に自動化された技術へと劇的に変化しました。 データはこのテクノロジーを推進する原動力です。 膨大な量のデータが最近利用可能になったことで、テクノロジーの流行語になりました。 人工知能の最も単純な形は、人間の知性を機械にシミュレートして、より良い意思決定を行うことです。
人工知能 (AI) は、機械による人間の知能プロセスのシミュレーションを扱うコンピューター サイエンスの一部門です。 コグニティブ コンピューティングという用語は、人間の思考プロセスをシミュレートするためにコンピューター モデルが展開されるため、AI を指す場合にも使用されます。 現在の環境を認識し、その目標を最適化するデバイスはすべて、AI 対応であると言われています。 AI は、弱いものと強いものに大まかに分類できます。 特定のタスクを実行するように設計およびトレーニングされたシステムは、音声起動システムのように弱い AI として知られています。 質問に答えたり、プログラム コマンドに従うことはできますが、人間の介入なしでは機能しません。 強力な AI は、一般化された人間の認知能力です。 人間の介入なしにタスクを解決し、解決策を見つけることができます。 自動運転車は、コンピュータ ビジョン、画像認識、ディープ ラーニングを使用して車両を操縦する強力な AI の例です。 AI は、企業と消費者の両方に利益をもたらすさまざまな業界に参入しています。 ヘルスケア、教育、金融、法律、製造業などがその例です。 自動化、機械学習、マシン ビジョン、自然言語処理、ロボティクスなどの多くのテクノロジには、AI が組み込まれています。
自動化の必要性に対する人間の呼びかけによって実行される定型業務の劇的な増加。 精度と正確さは、手動システムとは対照的に、インテリジェントシステムの発明を要求する次の運転用語です。 意思決定とパターン認識は、関連するドメインの履歴データを集中的に学習することで得られる偏りのない決定的な結果を必要とするため、自動化を主張する魅力的なタスクです。 これは機械学習によって達成できます。予測を行うシステムは、過去のデータに基づいて大規模なトレーニングを受け、将来の正確な予測を行う必要があります。 日常生活における ML の一般的なアプリケーションには、より高速なルートを提供することによる通勤時間の推定、最適なルートの推定、および移動あたりの料金が含まれます。 そのアプリケーションは、スパム フィルター、電子メールの分類、およびスマート リプライの作成を実行する電子メール インテリジェンスで見ることができます。 銀行や個人金融の分野では、クレジットの決定、不正取引の防止に使用されます。 ヘルスケアと診断、ソーシャル ネットワーキング、Siri や Cortana などのパーソナル アシスタントで重要な役割を果たします。 AI と ML を日々の活動に採用する分野がますます増えているため、リストはほぼ無限にあり、日々増え続けています。
真の人工知能が登場するのは数十年先のことですが、今日では機械学習と呼ばれるタイプの AI があります。 コグニティブ コンピューティングとしても知られる AI は、機械学習とディープ ラーニングという XNUMX つの同種の技術に分かれています。 機械学習は、優れた自動化されたマシンを作成する研究においてかなりのスペースを占めてきました。 明示的にプログラムしなくても、データのパターンを認識できます。 機械学習は、データから、さらに重要なことにはデータの変化から学習するためのツールとテクノロジを提供します。 機械学習アルゴリズムは、多くのアプリケーションでその場所を見つけました。 選択する食べ物を決定するアプリから、サルーンの予定を予約するチャットボットを含む、次に見る映画を決定するアプリまで、情報技術業界を揺るがす素晴らしい機械学習アプリケーションのいくつかがあります. 対応するディープ ラーニング技術は、人間の脳細胞から着想を得た機能を備えており、人気が高まっています。 深層学習は、低レベルのカテゴリから高レベルのカテゴリに移動する漸進的な方法で学習する機械学習のサブセットです。 ディープ ラーニング アルゴリズムは、非常に大量のデータを使用してトレーニングすると、より正確な結果が得られます。 問題は、マジック ボックス/ブラック ボックスとして名前が付けられたエンド ツー エンドの方法を使用して解決されます。それらのパフォーマンスは、ハイエンドのマシンを使用して最適化されます。 ディープラーニングは、人間の脳細胞からヒントを得た機能を備えており、人気が高まっています。 深層学習は、実際には機械学習のサブセットであり、低レベルのカテゴリから高レベルのカテゴリに移動する漸進的な方法で学習します。 深層学習は、自動運転車、ピクセル復元、自然言語処理などのアプリケーションで好まれています。 これらのアプリケーションは単に私たちの心を驚かせますが、現実には、これらのテクノロジーの絶対的な力はまだ明らかにされていません. この記事では、これらのテクノロジの概要を説明し、その背後にある理論とそのアプリケーションをカプセル化します。
機械学習とは何ですか?
コンピュータはプログラムされた通りのことしかできません。 これは、コンピューターが人間のように操作を実行し、決定を下せるようになるまでの過去の話です。 AI のサブセットである機械学習は、コンピューターが人間を模倣できるようにする技術です。 機械学習という用語は、1952 年にアーサー サミュエルが実行時に学習できる最初のコンピューター プログラムを設計したときに発明されました。 アーサー サミュエルは、人工知能とコンピューター ゲームという XNUMX つの最も人気のある分野のパイオニアでした。 彼によると、機械学習は「コンピューターに明示的にプログラムされていなくても学習する能力を与える研究分野」です。
通常、機械学習は人工知能のサブセットであり、ソフトウェアが過去の経験からそれ自体で学習し、その知識を使用して、明示的にプログラムすることなく将来の作業でパフォーマンスを向上させることができます。 色、形、匂い、花びらのサイズなどのさまざまな属性に基づいてさまざまな花を識別する例を考えてみましょう。従来のプログラミングでは、識別プロセスで従うべきいくつかのルールですべてのタスクがハードコーディングされています。 機械学習では、プログラムせずに機械を学習させることで、このタスクを簡単に達成できます。 機械は、提供されたデータから学習します。 データは、学習プロセスを推進する燃料です。 機械学習という用語が導入されたのは 1959 年にさかのぼりますが、この技術を推進する原動力は今になって初めて利用可能になります。 機械学習には膨大なデータと計算能力が必要ですが、かつては夢でした。
従来のプログラミング対機械学習:
人間の代わりにコンピューターを使用してタスクを実行する場合、コンピューター プログラムと呼ばれる命令を提供する必要があります。 従来のプログラミングは、1800 世紀以上にわたって実践されてきました。 それらは、コンピューター プログラムがデータを使用し、コンピューター システム上で実行して出力を生成する XNUMX 年代半ばに始まりました。 たとえば、従来のプログラムされたビジネス分析は、ビジネス データとルール (コンピューター プログラム) を入力として受け取り、ルールをデータに適用することでビジネスの洞察を出力します。
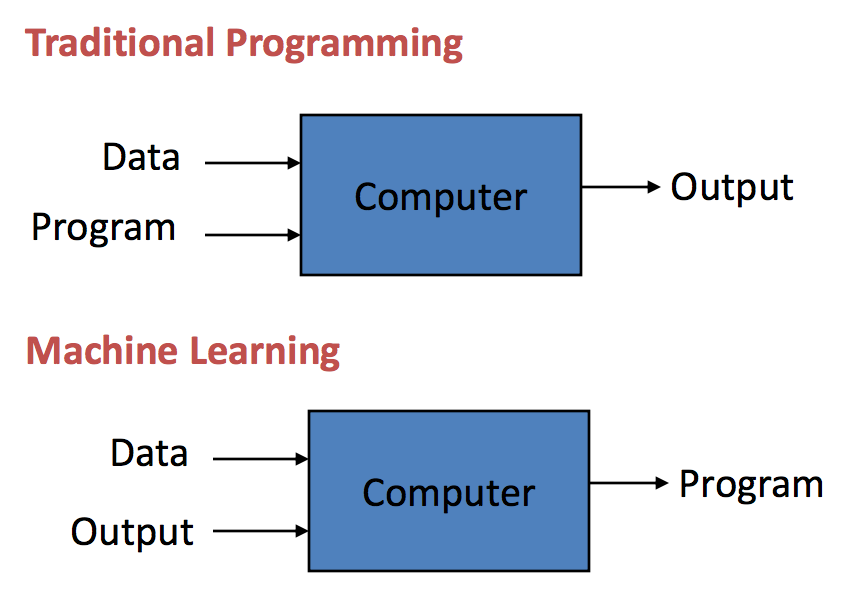
それどころか、機械学習では、ラベルとも呼ばれるデータと出力が、出力としてモデルを作成するアルゴリズムへの入力として提供されます。
たとえば、顧客の人口統計とトランザクションが入力データとして供給され、過去の顧客解約率を出力データ (ラベル) として使用する場合、アルゴリズムは、顧客が解約するかどうかを予測できるモデルを構築できます。 そのモデルは予測モデルと呼ばれます。 このような機械学習モデルは、必要な履歴データが提供されている状況を予測するために使用できます。 機械学習技術は、人間が理解するのが難しい高次元の複雑な空間でコンピューターが新しいルールを学習できるようにするため、非常に価値のある技術です。
機械学習の必要性:
機械学習が登場してからしばらく経ちますが、数学的計算を自動的かつ迅速に膨大なデータに適用する機能が勢いを増しています。 機械学習は、多くのタスクを自動化するために使用できます。特に、生まれつきの知性を持つ人間だけが実行できるタスクを自動化できます。 このインテリジェンスは、機械学習を通じてマシンに複製できます。
機械学習は、自動運転車、Facebook での友人のおすすめや Amazon からの提案などのオンライン レコメンデーション エンジン、サイバー詐欺の検出などのアプリケーションでその地位を確立しています。 機械学習は、画像認識や音声認識、言語翻訳、売上予測など、決まったルールを書き留めることができない問題に必要です。
意思決定、予測、予測の実行、偏差に関するアラートの提供、隠れた傾向や関係の発見などの操作には、機械学習パラダイムによってのみ最適に処理できる、さまざまな成果物からの多様で大量の非構造化データとリアルタイム データが必要です。
機械学習の歴史
このセクションでは、長年にわたる機械学習の発展について説明します。 今日、自動運転車、自然言語処理、処理に ML 技術を利用する顔認識システムなど、驚くべきアプリケーションがいくつか見られます。 このすべては、1943 年に、神経生理学者であるウォーレン・マカロックが、ウォルター・ピッツという名前の数学者とともに、ニューロンとその働きに光を当てた論文を執筆したときに始まりました。 彼らは電気回路でモデルを作成し、ニューラル ネットワークが誕生しました。
有名な「チューリング テスト」は、1950 年にアラン チューリングによって作成され、コンピューターに真の知性があるかどうかを確認するものでした。 テストを通過するには、コンピューターではなく人間であると人間に信じ込ませる必要があります。 アーサー サミュエルは、1952 年にチェッカー ゲームをプレイしながら学習できる最初のコンピューター プログラムを開発しました。パーセプトロンと呼ばれる最初のニューラル ネットワークは、1957 年にフランク ローゼンブラットによって設計されました。
1990 年代に大きな変化が起こりました。機械学習は、膨大な量のデータが利用できるようになったため、知識主導型からデータ主導型の手法に移行しました。 1997 年に開発された IBM の Deep Blue は、チェスのゲームで世界チャンピオンを破った最初のマシンでした。 企業は、機械学習によって複雑な計算の可能性を高めることができることを認識しています。 最新のプロジェクトには次のようなものがあります。 2012 年に開発された Google Brain は、画像や動画のパターン認識に焦点を当てたディープ ニューラル ネットワークでした。 その後、You Tube ビデオ内のオブジェクトを検出するために採用されました。 2014 年、Face book は人間と同じように人を認識できる Deep Face を作成しました。 2014 年、Deep Mind は Alpha Go と呼ばれるコンピューター プログラムを作成しました。これは、プロの囲碁プレイヤーを打ち負かすボード ゲームです。 その複雑さから、このゲームは非常に挑戦的であると言われていますが、人工知能の古典的なゲームです。 科学者のスティーブン・ホーキングとスチュアート・ラッセルは、AI が自身を再設計する力をますます加速させれば、無敵の「知性の爆発」が人類の絶滅につながる可能性があると感じています。 Musk は、AI を人類の「最大の存続にかかわる脅威」と特徴付けています。 Open AI は、2015 年に Elon Musk によって設立された組織で、人類に利益をもたらす安全で使いやすい AI を開発しています。 最近、AI の画期的な分野のいくつかは、コンピューター ビジョン、自然言語処理、強化学習です。
機械学習の特徴
近年、テクノロジー分野では、機械学習と呼ばれる非常に人気のあるトピックが目撃されています。 ほぼすべての企業がこのテクノロジーを採用しようとしています。 企業はビジネスを遂行する方法を変革しており、機械学習の影響により未来は明るく有望に見えます。 機械学習の主な機能には次のようなものがあります。
自動化: 反復タスクを自動化してビジネスの生産性を向上させる能力は、機械学習の最大の重要な要素です。 ML を利用した事務処理と電子メールの自動化は、多くの組織で使用されています。 金融部門では、ML は会計作業をより迅速かつ正確にし、有用な洞察を迅速かつ簡単に引き出します。 メールの分類は自動化の典型的な例で、迷惑メールは Gmail によって自動的に迷惑メール フォルダに分類されます。
顧客エンゲージメントの向上: 顧客にカスタマイズされたエクスペリエンスを提供し、優れたサービスを提供することは、ブランド ロイヤルティを促進し、長期にわたる顧客関係を維持するために非常に重要です。 これらは ML を通じて実現できます。 顧客のニーズに完全に合わせたレコメンデーション エンジンを作成し、会話のニュアンスを理解し、質問に適切に回答することで、人間の会話をスムーズにシミュレートできるチャット ボットを作成します。 Air Asia 航空会社の AVA は、そのようなチャット ボットの 11 つの例です。 これは、AI を搭載した仮想アシスタントであり、顧客のクエリに即座に応答します。 XNUMXの人間の言語を模倣することができ、自然言語理解技術を利用しています。
自動化されたデータの視覚化: 企業、機械、個人によって膨大な量のデータが生成されていることを認識しています。 ビジネスは、トランザクション、電子商取引、医療記録、金融システムなどからデータを生成します。機械は、衛星、センサー、カメラ、コンピューターのログ ファイル、IoT システム、カメラなどからも大量のデータを生成します。個人は、ソーシャル ネットワーク、電子メールから膨大なデータを生成します。 、ブログ、インターネットなど。データ間の関係は、視覚化によって簡単に識別できます。 データのパターンと傾向を特定することは、スプレッドシートで何千行も調べるのではなく、情報を視覚的に要約することで簡単に行うことができます。 企業は、機械学習アプリケーションによって提供されるユーザーフレンドリーな自動化されたデータ視覚化プラットフォームを通じて、ドメインの生産性を向上させるために、データ視覚化を通じて貴重な新しい洞察を得ることができます。 Auto Viz は、ビジネスの生産性を向上させる自動化されたデータ視覚化料金を提供するプラットフォームの XNUMX つです。
正確なデータ分析: データ分析の目的は、ビジネス分析とビジネス インテリジェンスを特定しようとする特定の質問に対する答えを見つけることです。 従来のデータ分析には多くの試行錯誤が必要であり、大量の構造化データと非構造化データの両方を扱う場合、これは絶対に不可能になります。 データ分析は、膨大な時間を必要とする非常に重要なタスクです。 機械学習は、リアルタイム データを完全に処理できる多くのアルゴリズムとデータ駆動型モデルを提供することで役立ちます。
ビジネス インテリジェンス: ビジネス インテリジェンスとは、合理化された収集操作を指します。 組織内のデータの処理と分析。AI を利用したビジネス インテリジェンス アプリケーションは、新しいデータを精査し、組織に関連するパターンと傾向を認識することができます。 機械学習機能をビッグデータ分析と組み合わせると、企業が成長してより多くの利益を上げるのに役立つ問題の解決策を見つけるのに役立ちます。 ML は、e コマースから金融セクター、ヘルスケアに至るまで、ビジネス オペレーションを拡大するための最も強力なテクノロジの XNUMX つになりました。
機械学習の言語
機械学習用のプログラミング言語はたくさんあります。 言語の選択と必要なプログラミングのレベルは、アプリケーションで機械学習がどのように使用されるかによって異なります。 ビジネス アプリケーションに機械学習技術を実装するには、プログラミング、ロジック、データ構造、アルゴリズム、およびメモリ管理の基礎が必要です。 この知識があれば、多くのプログラミング言語が提供するさまざまな組み込みライブラリを利用して、機械学習モデルをすぐに実装できます。 また、Orange、Big ML、Weka など、ハードコーディングせずに ML アルゴリズムを実装できるグラフィカル言語やスクリプト言語も多数あります。 必要なのは、プログラミングに関する基本的な知識だけです。
機械学習に「最適」と呼べる単一のプログラミング言語はありません。 それらのそれぞれは、適用される場所で優れています。 NLP アプリケーションに Python を使用することを好む人もいれば、感情分析アプリケーションに R または Python を使用する人もいれば、セキュリティと脅威の検出に関連する ML アプリケーションに Java を使用する人もいます。 ML プログラミングに最適な XNUMX つの異なる言語を以下に示します。

Python:
世界中で約 8 万人の開発者がコーディングに Python を使用しています。 IEEE Spectrum による年間ランキングで、最も人気のあるプログラミング言語として Python が選ばれました。 また、プログラミング言語のスタック オーバーフローの傾向は、Python が過去 2 年間で上昇していることを示しています。 機械学習用のパッケージとライブラリの広範なコレクションがあります。 Python プログラミングの基本的な知識があれば、これらのライブラリを簡単にすぐに使用できます。
テキスト データを扱うには、NLTK、SciKit、Numpy などのパッケージが便利です。 OpenCV および Sci-Kit イメージを使用してイメージを処理できます。 オーディオデータを操作しながら Librosa を使用できます。 深層学習アプリケーションの実装では、TensorFlow、Keras、および PyTorch が命の恩人として登場します。 Sci-Kit-learn は基本的な機械学習アルゴリズムの実装に使用でき、Sci-Py は科学計算の実行に使用できます。 Matplotlib、Sci-Kit、Seaborn などのパッケージは、最高のデータ視覚化に最適です。
R:
R は、統計データを使用した機械学習アプリケーション向けの優れたプログラミング言語です。 R には、機械学習モデルをトレーニングおよび評価して正確な将来予測を行うためのさまざまなツールが搭載されています。 R はオープンソースのプログラミング言語であり、非常に費用対効果が高いです。 柔軟性が高く、クロスプラットフォームとの互換性があります。 これには、データ サンプリング、データ分析、モデル評価、およびデータ視覚化操作のための幅広い手法があります。 パッケージの包括的なリストには、欠損値の処理に使用される MICE、回帰問題の分類を実行する CARET、データにパーティションを作成する PARTY および rpart、決定木を作成するためのランダム FOREST、データ操作に使用される tidyr および dplyr が含まれます。データの視覚化、Rmarkdown および Shiny を作成して、レポートの作成を通じて洞察を認識します。
Java と JavaScript:
Java は、Java のバックグラウンドを持つエンジニアから、機械学習でより多くの注目を集めています。 ビッグ データ処理に使用される Hadoop や Spark などのオープン ソース ツールのほとんどは、Java で記述されています。 機械学習アルゴリズムを実装するための JavaML などのさまざまなサードパーティ ライブラリがあります。 Arbiter Java は、ML のハイパー パラメーター チューニングに使用されます。 他には、深層学習アプリケーションで使用される Deeplearning4J と Neuroph があります。 Java のスケーラビリティは、複雑で巨大なアプリケーションの作成を可能にする ML アルゴリズムへの大きなリフトです。 Java 仮想マシンは、複数のプラットフォームでコードを作成するための追加の利点です。
ジュリア:
Julia は、複雑な数値解析と計算科学を実行できる汎用プログラミング言語です。 機械学習アルゴリズムで数学および科学演算を実行するように特別に設計されています。 Julia コードは高速で実行され、パフォーマンスに関連する問題に対処するための最適化手法は必要ありません。 TensorFlow、MLBase.jl、Flux.jl、SciKitlearn.jl などのさまざまなツールがあります。 TPU や GPU を含むすべてのタイプのハードウェアをサポートします。 Apple や Oracle などのテクノロジー大手は、Julia を機械学習アプリケーションに採用しています。
舌足らずの発音:
LIST (List Processing) は、現在も使用されている XNUMX 番目に古いプログラミング言語です。 AI中心のアプリケーション向けに開発されました。 LISP は帰納的論理プログラミングと機械学習で使用されます。 最初の AI チャット ボットである ELIZA は、LISP を使用して開発されました。 チャットボット e コマースなどの多くの機械学習アプリケーションは、LISP を使用して開発されています。 迅速なプロトタイピング機能を提供し、自動ガベージ コレクションを実行し、動的なオブジェクト作成を提供し、操作に多くの柔軟性を提供します。
機械学習の種類
高レベルの機械学習は、コンピューター プログラムまたはアルゴリズムを教えて、特定のタスクを自動的に改善する研究と定義されています。 研究の観点から、プロセス全体の働きについて、理論的および数学的モデリングの目を通して見ることができます。 人工知能と機械学習があふれている世界で、さまざまな種類の機械学習について学び、理解することは興味深いことです。 コンピューター ユーザーの観点からは、これは機械学習の種類と、それらがさまざまなアプリケーションでどのように明らかになるかを理解することと見なすことができます。 また、実践者の観点からは、特定のタスクに対してこれらのアプリケーションを作成するための機械学習の種類を知る必要があります。
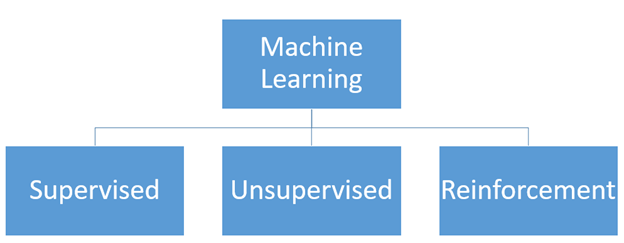
教師あり学習:
教師あり学習は、モデルを使用して入力変数とターゲット変数の間のマッピングを学習する問題のクラスです。 さまざまな入力変数を記述したトレーニング データで構成されるアプリケーションと、 ターゲット変数は、教師あり学習タスクとして知られています。
入力変数のセットを (x)、ターゲット変数を (y) とします。 教師あり学習アルゴリズムは、x の関数である式 y=f(x) によって与えられるマッピングである仮説関数を学習しようとします。
ここでの学習プロセスは、監視または監督されています。 出力はすでにわかっているため、結果を最適化するために、予測を行うたびにアルゴリズムが修正されます。 モデルは、入力変数と出力変数の両方で構成されるトレーニング データに適合し、テスト データの予測に使用されます。 テスト段階では入力のみが提供され、モデルによって生成された出力は、保持されたターゲット変数と比較され、モデルのパフォーマンスを推定するために使用されます。
教師あり問題には基本的に XNUMX つのタイプがあります。クラス ラベルの予測を含む分類と、数値の予測を含む回帰です。
MINST 手書き数字データ セットは、分類タスクの例として見ることができます。 入力は手書きの数字のイメージで、出力は 0 ~ 9 の範囲の数字をさまざまなクラスに識別するクラス ラベルです。
ボストンの住宅価格データ セットは、回帰問題の例と見なすことができます。入力は住宅の特徴であり、出力は数値である住宅価格 (ドル) です。
教師なし学習:
で 教師なし学習 モデルが自ら学習し、パターンを認識してデータ間の関係を抽出しようとする問題。 教師あり学習の場合と同様に、モデルを動かす監督者や教師はいません。 教師なし学習は、入力変数に対してのみ機能します。 学習プロセスを導くターゲット変数はありません。 ここでの目標は、データの基礎となるパターンを解釈して、基礎となるデータの習熟度を高めることです。
教師なし学習には主に XNUMX つのカテゴリがあります。 それらはクラスター化されています。タスクは、データ内のさまざまなグループを見つけることです。 そして次は、データの分布を統合しようとする密度推定です。 これらの操作は、データのパターンを理解するために実行されます。 ビジュアライゼーションとプロジェクションも、データに対するより多くの洞察を提供しようとするため、教師なしと見なされる場合があります。 視覚化にはデータのプロットとグラフの作成が含まれ、投影にはデータの次元削減が含まれます。
強化学習:
強化学習は、エージェントが存在し、エージェントが動作している環境によってエージェントに与えられたフィードバックまたは報酬に基づく環境でエージェントが動作しているタイプの問題です。 報酬は正または負のいずれかです。 エージェントは、獲得した報酬に基づいて環境内を進みます。
強化エージェントは、特定のタスクを実行する手順を決定します。 ここには固定のトレーニング データセットはなく、機械が独自に学習します。
ゲームをプレイすることは、エージェントの目標が高得点を獲得することである強化問題の典型的な例です。 報酬またはペナルティの観点から、環境によって与えられるフィードバックに基づいて、ゲーム内で連続して動きます。 強化学習は、世界一の囲碁棋士を倒したGoogleのAplhaGoで絶大な成果を上げています。
機械学習アルゴリズム
利用可能なさまざまな機械学習アルゴリズムがあり、目前の問題に最も適したアルゴリズムを選択することは非常に困難であり、時間がかかります。 これらのアルゴリズムは、XNUMX つのカテゴリに分類できます。 第一に、それらは学習パターンに基づいてグループ化でき、第二に機能の類似性によってグループ化できます。
学習スタイルに基づいて、次の XNUMX つのタイプに分類できます。
- 教師あり学習アルゴリズム: トレーニング データは、トレーニング プロセスをガイドするラベルと共に提供されます。 モデルは、トレーニング データで目的のレベルの精度が達成されるまでトレーニングされます。 このような問題の例として、分類と回帰があります。 使用されるアルゴリズムの例には、ロジスティック回帰、最近傍、単純ベイズ、決定木、線形回帰、サポート ベクター マシン (SVM)、ニューラル ネットワークが含まれます。
- 教師なし学習アルゴリズム: 入力データはラベル付けされておらず、ラベルが付いていません。 モデルは、入力データに存在するパターンを識別することによって準備されます。 このような問題の例としては、クラスタリング、次元削減、相関規則の学習などがあります。 これらのタイプの問題に使用されるアルゴリズムのリストには、アプリオリ アルゴリズム、K-Means およびアソシエーション ルールが含まれます。
- 半教師あり学習アルゴリズム: 熟練した人間の専門家の知識が必要なため、データにラベルを付けるコストは非常に高くなります。 入力データは、ラベル付きデータとラベルなしデータの両方の組み合わせです。 モデルは、基礎となるパターンを独自に学習することによって予測を行います。 これは、分類問題とクラスタリング問題の両方が混在しています。
機能の類似性に基づいて、アルゴリズムは次のようにグループ化できます。
- 回帰アルゴリズム: 回帰は、新しいデータに関する予測を行うために、ターゲット出力変数と入力機能の間の関係を特定することに関係するプロセスです。 上位 XNUMX つの回帰アルゴリズムは、単純線形回帰、投げ縄回帰、ロジスティック回帰、多変量回帰アルゴリズム、多重回帰アルゴリズムです。
- インスタンスベースのアルゴリズム: これらは、学習データ内の問題の新しいインスタンスを測定して最適な一致を見つけ、それに応じて予測を行う学習のファミリーに属します。 上位のインスタンス ベースのアルゴリズムは、k 最近傍、学習ベクトル量子化、自己組織化マップ、局所加重学習、およびサポート ベクター マシンです。
- 正則化: 正則化とは、特定の特徴セットから学習プロセスを正則化する手法を指します。 それは正常化し、緩和します。 特徴に付加された重みは正規化され、特定の特徴が予測プロセスを支配するのを防ぎます。 この手法は、機械学習におけるオーバーフィッティングの問題を防ぐのに役立ちます。 さまざまな正則化アルゴリズムは、リッジ回帰、最小絶対収縮および選択演算子 (LASSO)、および最小角度回帰 (LARS) です。
- 決定木アルゴリズム: これらのメソッドは、属性の値を調べることによって行われた決定に基づいて構築されたツリー ベースのモデルを構築します。 決定木は、分類問題と回帰問題の両方に使用されます。 よく知られている決定木アルゴリズムには、分類および回帰木、C4.5 および C5.0、条件付き決定木、カイ XNUMX 乗自動相互作用検出、決定スタンプなどがあります。
- ベイジアンアルゴリズム: これらのアルゴリズムは、分類と回帰の問題にベイズの定理を適用します。 それらには、ナイーブ ベイズ、ガウス ナイーブ ベイズ、多項式ナイーブ ベイズ、ベイジアン ビリーフ ネットワーク、ベイジアン ネットワーク、および平均 XNUMX 依存推定器が含まれます。
- クラスタリング アルゴリズム: クラスタリング アルゴリズムでは、データ ポイントをクラスタにグループ化します。 同じグループにあるすべてのデータ ポイントは同様のプロパティを共有し、異なるグループのデータ ポイントは非常に異なるプロパティを持ちます。 クラスタリングは教師なし学習アプローチであり、主に多くの分野で統計データ分析に使用されます。 k-Means、k-Medians、Expectation Maximisation、Hierarchical Clustering、Density-Based Spatial Clustering of Applications with Noise などのアルゴリズムは、このカテゴリに分類されます。
- アソシエーション ルール学習アルゴリズム: アソシエーション ルール学習は、非常に大きなデータセット内の変数間の関係を識別するためのルール ベースの学習方法です。 アソシエーション ルール学習は、主にマーケット バスケット分析で使用されます。 最も一般的なアルゴリズムは、Apriori アルゴリズムと Eclat アルゴリズムです。
- 人工ニューラル ネットワーク アルゴリズム: 人工ニューラル ネットワーク アルゴリズムは、人間の脳の生物学的ニューロンからそのベースを見つけることに依存しています。 これらは、分類および回帰問題における複雑なパターン マッチングおよび予測プロセスのクラスに属します。 一般的な人工ニューラル ネットワーク アルゴリズムには、パーセプトロン、多層パーセプトロン、確率的勾配降下法、逆伝播、ホップフィールド ネットワーク、放射基底関数ネットワークなどがあります。
- ディープ ラーニング アルゴリズム: これらは人工ニューラル ネットワークの最新バージョンであり、ラベル付けされたデータの非常に大規模で複雑なデータベースを処理できます。 ディープ ラーニング アルゴリズムは、テキスト、画像、オーディオ、およびビデオ データを処理するように調整されています。 ディープ ラーニングは、多くの隠れ層を備えた独学の学習構造を使用して、ビッグ データを処理し、より強力な計算リソースを提供します。 最も人気のあるディープ ラーニング アルゴリズムは次のとおりです。 人気のあるディープ ラーニング ミリ秒には、畳み込みニューラル ネットワーク、再帰型ニューラル ネットワーク、ディープ ボルツマン マシン、自動エンコーダー、ディープ ビリーフ ネットワーク、長期短期記憶ネットワークなどがあります。
- 次元削減アルゴリズム: 次元削減アルゴリズムは、データの固有の構造を教師なしで利用して、削減された情報セットを使用してデータを表現します。 高次元のデータを、分類や回帰などの教師あり学習方法で使用できる低次元に変換します。 よく知られている次元削減アルゴリズムには、主成分分析、主成分回帰分析、線形判別分析、二次判別分析、混合判別分析、柔軟判別分析、サモン マッピングなどがあります。
- アンサンブル アルゴリズム: アンサンブル法は、個別にトレーニングされたさまざまな弱いモデルで構成されるモデルであり、モデルの個々の予測は何らかの方法を使用して結合され、最終的な全体的な予測が得られます。 出力の品質は、個々の結果を組み合わせるために選択した方法によって異なります。 一般的な方法には、ランダム フォレスト、ブースティング、ブートストラップ集約、AdaBoost、積み上げ一般化、勾配ブースティング マシン、勾配ブースト回帰ツリー、および加重平均があります。
機械学習のライフ サイクル
機械学習は、コンピューターを明示的にプログラムする必要なく、自動的に学習する機能をコンピューターに提供します。 機械学習プロセスは、高品質のモデルを設計、開発、展開するためのいくつかの段階で構成されています。 機械学習のライフ サイクルは、次の手順で構成されます
- データ収集
- データの準備
- データラングリング
- データ解析
- モデルトレーニング
- モデルテスト
- モデルの展開
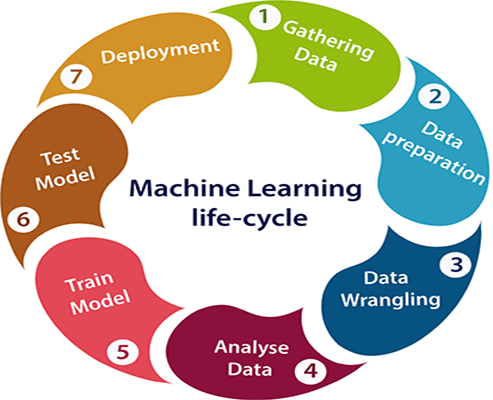
- データ収集: これは、機械学習モデルを作成する最初のステップです。 このステップの主な目的は、問題に関連するすべてのデータを特定して収集することです。 データは、ファイル、データベース、インターネット、IoT デバイスなどのさまざまなソースから収集でき、そのリストは増え続けています。 出力の効率は、収集されたデータの品質に直接依存します。 そのため、大量の品質データを収集する際には細心の注意を払う必要があります。
- データの準備: 収集されたデータは整理され、75 つの場所に配置されるか、さらに処理されます。 データ探索はこのステップの一部であり、データの特性、性質、形式、および品質にアクセスします。 これには、円グラフ、棒グラフ、ヒストグラム、歪度などの作成が含まれます。データ探索は、データに関する有用な洞察を提供し、問題の XNUMX% の解決に役立ちます。
- データラングリング: データ ラングリングでは、生データがクリーンアップされ、有用な形式に変換されます。 収集されたデータを最大限に活用するために適用される一般的な手法は次のとおりです。
- 欠損値チェックと欠損値代入
- 不要なデータと Null 値の削除
- 関心のあるドメインに基づくデータの最適化
- 外れ値の検出と除去
- データの次元を減らす
- データのバランス、アンダーサンプリングとオーバーサンプリング。
- 重複レコードの削除
- データ解析: このステップは、機能の選択とモデルの選択プロセスに関するものです。 従属変数に関連する独立変数の予測力が推定されます。 モデルにとって有益な変数のみが選択されます。 次に、分類、回帰、クラスタリング、関連付けなどの適切な機械学習手法が選択され、データを使用してモデルが構築されます。
- モデルトレーニング: モデルは基礎となるデータからさまざまなパターン、機能、ルールを理解しようとするため、トレーニングは機械学習の非常に重要なステップです。 データは、トレーニング データとテスト データに分割されます。 モデルは、パフォーマンスが許容レベルに達するまで、トレーニング データでトレーニングされます。
- モデルテスト: モデルをトレーニングした後、目に見えないテスト データでのパフォーマンスを評価するためにテストが行われます。 予測の精度とモデルのパフォーマンスは、混同行列、精度と再現率、感度と特異度、曲線下面積、F1 スコア、R XNUMX 乗、ジニ値などのさまざまな尺度を使用して測定できます。
- 展開: これは機械学習のライフ サイクルの最終ステップであり、実世界のシステムで構築されたモデルをデプロイします。 展開する前に、モデルはピクルされます。つまり、プラットフォームに依存しない実行形式に変換する必要があります。 pickled モデルは、Rest API またはマイクロサービスを使用してデプロイできます。
深層学習
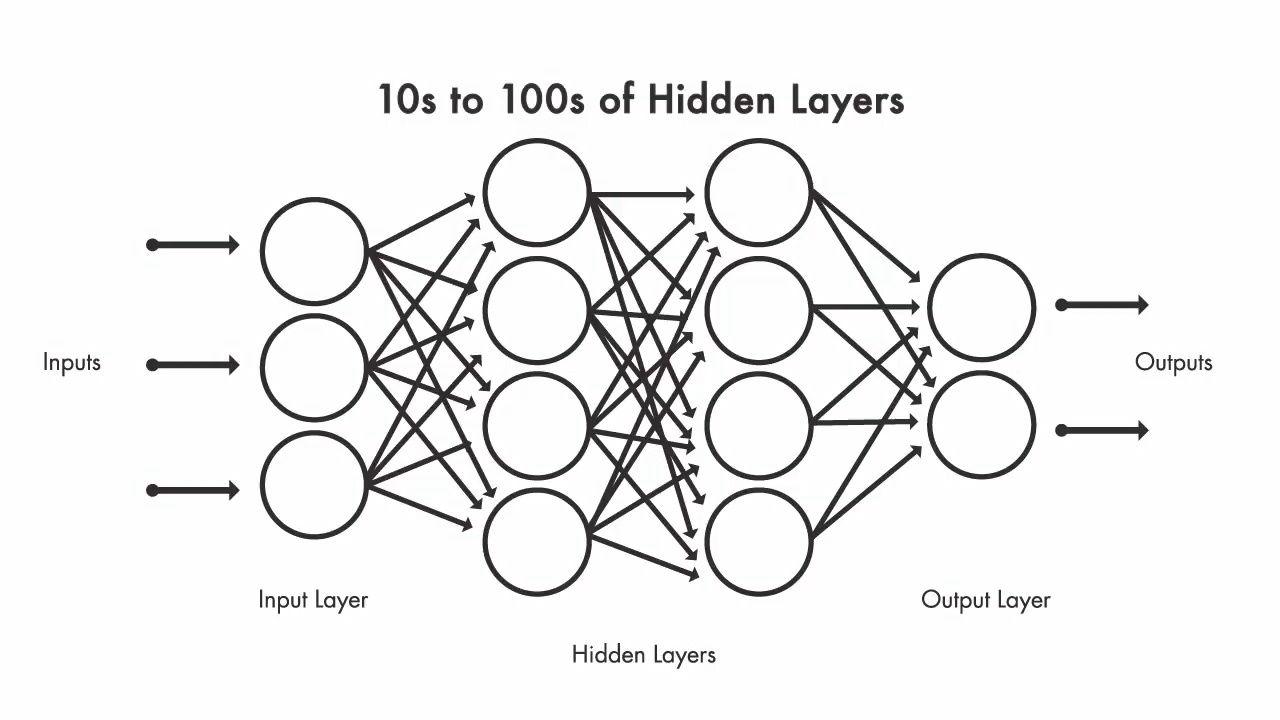
深層学習は、人間の脳内のニューロンの機能に従う機械学習のサブセットです。 深層学習ネットワークは、層状に相互接続された複数のニューロンで構成されています。 ニューラル ネットワークには、学習プロセスを可能にする多くの深い層があります。 深層学習ニューラル ネットワークは、完全なネットワークを構成する入力層、出力層、および複数の隠れ層で構成されています。 処理は、入力データ、事前に割り当てられた重み、およびネットワークを介した制御フローのパスを決定するアクティベーション関数を含む接続を介して行われます。 ネットワークは膨大な量のデータを操作し、各レベルで複雑な機能を学習することにより、各レイヤー全体にデータを伝播します。 モデルの結果が期待どおりでない場合は、重みが調整され、望ましい結果が得られるまでプロセスが繰り返されます。

ディープ ニューラル ネットワークは、明示的にプログラムしなくても自動的に機能を学習できます。 各レイヤーは、より深いレベルの情報を表します。 深層学習モデルは、各レイヤーで表される知識の階層に従います。 XNUMX 層のニューラル ネットワークは、XNUMX 層のニューラル ネットワークよりも多くのことを学習します。 ニューラル ネットワークの学習は XNUMX つのステップで行われます。 最初のステップでは、非線形変換が入力に適用され、統計モデルが作成されます。 XNUMX 番目のステップでは、派生物と呼ばれる数学的モデルを使用して、作成されたモデルが改善されます。 これらの XNUMX つのステップは、ニューラル ネットワークによって、目的の精度レベルに達するまで何千回も繰り返されます。 この XNUMX つのステップを繰り返すことを反復と呼びます。
隠れ層が XNUMX つしかないニューラル ネットワークは浅いネットワークと呼ばれ、隠れ層が複数あるニューラル ネットワークはディープ ニューラル ネットワークと呼ばれます。
ニューラル ネットワークの種類:
さまざまな種類のプロセスに使用できるさまざまな種類のニューラル ネットワークがあります。 ここでは、最も一般的に使用されるタイプについて説明します。
- パーセプトロン: パーセプトロンは、入力層と出力層のみを含む単層ニューラル ネットワークです。 隠れ層はありません。 ここで使用される活性化関数はシグモイド関数です。
- フィードフォワード: フィード フォワード ニューラル ネットワークは、情報が一方向にのみ流れる最も単純な形式のニューラル ネットワークです。 ニューラル ネットワークのパスにサイクルはありません。 レイヤー内のすべてのノードは、次のレイヤー内のすべてのノードに接続されています。 そのため、すべてのノードが完全に接続されており、バック ループはありません。
- リカレント ニューラル ネットワーク: リカレント ニューラル ネットワークは、ネットワークの出力をメモリに保存し、それをネットワークにフィードバックして、出力の予測に役立てます。 ネットワークは、XNUMX つの異なる層で構成されています。 XNUMX つ目はフィード フォワード ニューラル ネットワークで、XNUMX つ目は以前のネットワークの値と状態がメモリに記憶される再帰型ニューラル ネットワークです。 間違った予測が行われた場合、学習率を使用して、逆伝播によって正しい予測を行う方向に徐々に移動します。
- 畳み込みニューラル ネットワーク: 畳み込みニューラル ネットワークは、非構造化データから有用な情報を抽出する必要がある場合に使用されます。 シグナルの伝播は、CNN では単方向です。 最初の層は畳み込み層で、その後にプーリングが続き、その後に複数の畳み込み層とプーリング層が続きます。 これらの層の出力は、全結合層と、分類プロセスを実行するソフトマックスに供給されます。 CNN のニューロンには学習可能な重みとバイアスがあります。 畳み込みは、非線形 RELU 活性化関数を使用します。 CNN は、信号および画像処理アプリケーションで使用されます。
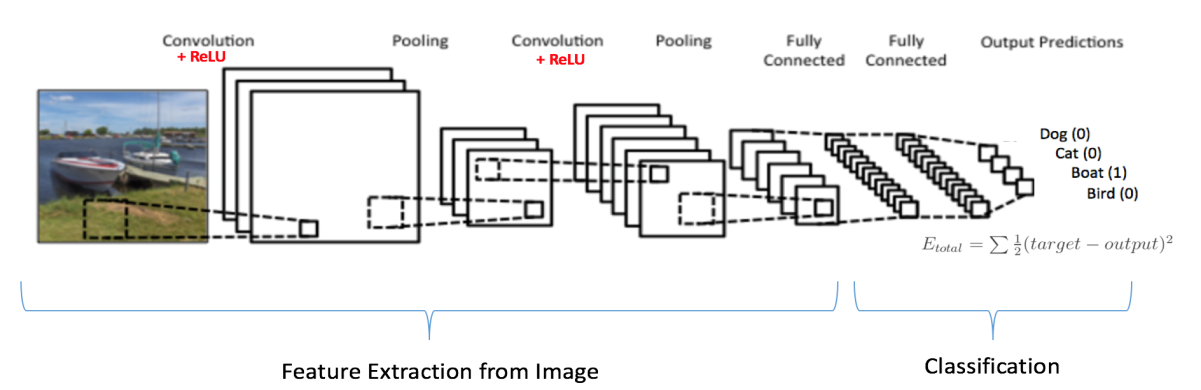
- 強化学習: 強化学習では、複雑で不確実な環境で動作するエージェントは、試行錯誤の方法で学習します。 エージェントは、そのアクションの結果として仮想的に報酬または罰を受け、生成される出力を改善するのに役立ちます。 目標は、エージェントが受け取る報酬の総数を最大化することです。 モデルは、報酬を最大化するために独自に学習します。 Google の DeepMind と自動運転車は、強化学習が活用されているアプリケーションの例です。
機械学習と深層学習の違い
ディープ ラーニングは、機械学習のサブセットです。 機械学習モデルは、ガイダンスに従って機能を学習するにつれて、徐々に改善されます。 予測が正しくない場合は、専門家がモデルを調整する必要があります。 深層学習では、モデル自体が予測が正しいかどうかを識別できます。
- 機能: ディープ ラーニングはデータを入力として受け取り、人工ニューラル ネットワークの層を重ねて自動的にインテリジェントな決定を下そうとします。 機械学習は、入力データを取得して解析し、データでトレーニングします。 トレーニング フェーズで学習した内容に基づいて、データに基づいて決定を下そうとします。
- 特徴抽出: ディープ ラーニングは、入力データから関連する特徴を抽出します。 特徴を階層的に自動的に抽出します。 特徴は層ごとに学習されます。 最初に低レベルの機能を学習し、ネットワークを下っていくにつれて、より具体的な機能を学習しようとします。 一方、機械学習モデルには、データセットから厳選された機能が必要です。 これらの特徴は、予測を行うためのモデルへの入力として提供されます。
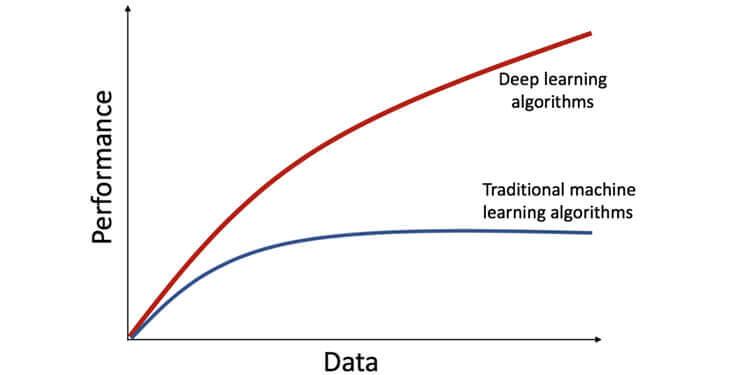
- データの依存関係: ディープ ラーニング モデルは、特徴抽出プロセスを独自に行うため、膨大な量のデータを必要とします。 しかし、機械学習モデルは、より小さなデータセットで完全に機能します。 ディープ ラーニング モデルのネットワークの深さはデータとともに増加するため、ディープ ラーニング モデルの複雑さも増します。 次の図は、深層学習モデルのパフォーマンスがデータの増加に伴って向上することを示していますが、機械学習モデルは一定期間後に曲線を平坦化します。
- 計算能力: 深層学習ネットワークは、通常の CPU ではなく GPU のサポートを必要とする巨大なデータに大きく依存しています。 GPU は複数の計算を同時に処理できるため、深層学習モデルの処理を最大化できます。 GPU の高いメモリ帯域幅により、GPU はディープ ラーニング モデルに適しています。 一方、機械学習モデルは CPU 上に実装できます。
- 実行時間: 通常、深層学習アルゴリズムは、多数のパラメーターが関係するため、トレーニングに時間がかかります。 深層学習アルゴリズムの一例である ResNet アーキテクチャは、ゼロからトレーニングするのにほぼ XNUMX 週間かかります。 しかし、機械学習アルゴリズムはトレーニングにかかる時間が短くなります (数分から数時間)。 これはテスト時間に関して完全に逆です。 ディープ ラーニング アルゴリズムは、実行にかかる時間が短くなります。
- 解釈可能性: 機械学習アルゴリズムを解釈し、各ステップで何が行われているか、なぜ行われているかを理解するのは簡単です。 しかし、ディープ ラーニング アルゴリズムはブラック ボックスと呼ばれ、ディープ ラーニング アーキテクチャの内部で何が起こっているかを実際に知ることはできません。 どのニューロンが活性化され、どの程度出力に寄与するか。 したがって、機械学習モデルの解釈は、深層学習モデルよりもはるかに簡単です。
機械学習の応用
- 交通アシスタント: 私たちは皆、旅行の際に交通アシスタントを使用しています。 Google マップは、目的地までのルートを教えてくれるだけでなく、交通量の少ないルートも表示してくれます。 マップを使用するすべての人が、自分の位置、通ったルート、運転速度を Google マップに提供しています。 交通状況に関するこれらの詳細は Google マップによって収集され、ルートの交通状況を予測して、それに応じてルートを調整しようとします。
- ソーシャルメディア: 機械学習の最も一般的なアプリケーションは、自動的な友達のタグ付けと友達の提案で見ることができます. Facebook は Deep Face を使用して、デジタル画像の画像認識と顔検出を行います。
- 製品の推奨事項: Amazon で特定の製品をブラウジングして購入しなかった場合、翌日 YouTube や Facebook を開くと、それに関連する広告が表示されます。 検索履歴は Google によって追跡されており、検索履歴に基づいて製品が推奨されます。 これは機械学習技術の応用です。
- パーソナル アシスタント: パーソナル アシスタントは、役立つ情報を見つけるのに役立ちます。 パーソナル アシスタントへの入力は、音声またはテキストのいずれかです。 SiriとAlexaについて知らないと言える人はいません。 パーソナル アシスタントは、電話への応答、会議のスケジュール設定、メモの取り方、メールの送信などに役立ちます。
- 感情分析: 人の意見を理解できるリアルタイム機械学習アプリです。 そのアプリケーションは、レビュー ベースの Web サイトや意思決定アプリケーションで表示できます。
- 言語翻訳: 言語を翻訳することは、もはや難しい作業ではありません。現在、多数の言語翻訳者が利用可能です。 Google の GNMT は効率的なニューラル機械翻訳ツールであり、何千もの辞書や言語にアクセスして、自然言語処理テクノロジを使用して文や単語を正確に翻訳できます。
- オンライン詐欺検出: ML アルゴリズムは、過去の不正パターンから学習し、将来の不正取引を認識することができます。ML アルゴリズムは、情報処理の速度において人間よりも効率的であることが証明されています。 ML を利用した不正検出システムは、人間が検出できない不正を見つけることができます。
- ヘルスケアサービス: AI はヘルスケア業界の未来になりつつあります。 AI は臨床上の意思決定において重要な役割を果たし、それによって病気の早期発見と患者の治療のカスタマイズを可能にします。 機械学習を利用した PathAI は、病理学者が病気を正確に診断するために使用されます。 Quantitative Insights は、乳がんの診断の速度と精度を向上させる AI 対応ソフトウェアです。 放射線科医による診断が改善され、患者により良い結果がもたらされます。
深層学習の応用
- 自動運転車: 自動運転車は、ディープラーニング技術によって実現されています。 Ai Labs では、食品配達などの機能を自動運転車に統合するための研究も行われています。 データはセンサーやカメラから収集され、ジオ マッピングは、トラフィックをシームレスに移動できる、より洗練されたモデルの作成に役立ちます。
- 詐欺ニュースの検出: 今日の世界では、詐欺ニュースを検出することは非常に重要です。 インターネットは、本物と偽物の両方のあらゆる種類のニュースの情報源になっています。 フェイク ニュースを特定することは、非常に困難な作業です。 ディープ ラーニングの助けを借りて、フェイク ニュースを検出し、ニュース フィードから削除することができます。
- 自然言語処理: 言語の構文、セマンティクス、トーン、またはニュアンスを理解しようとすることは、人間にとって非常に困難で複雑な作業です。 自然言語処理技術の助けを借りて、言語のニュアンスを識別し、それに応じて応答を構成するように機械を訓練することができます。 ディープ ラーニングは、テキストの分類、Twitter 分析、言語モデリング、感情分析など、自然言語処理を使用するアプリケーションで人気を集めています。
- 仮想アシスタント: バーチャル アシスタントは、ディープ ラーニング技術を使用して、人々の外食の好みからお気に入りの曲まで、主題に関する幅広い知識を持っています。 仮想アシスタントは、話されている言語を理解し、タスクを実行しようとします。 Google は、自然言語理解、ディープ ラーニング、テキスト読み上げを使用して、人々が週の途中でどこでも予約できるようにする Google デュプレックスと呼ばれるこのテクノロジに長年取り組んできました。 そして、アシスタントが仕事を終えると、予約が処理されたことを示す確認通知が表示されます。 通話は期待どおりに進みませんが、アシスタントはコンテキストをニュアンスまで理解し、会話を適切に処理します。
- 視覚認識: 古い写真を探すのは懐かしく感じるかもしれませんが、特定の写真を探すのは、分類や分離に時間がかかるため、退屈なプロセスになる可能性があります。 ディープラーニングを画像に適用して、写真の場所、人々の組み合わせ、イベントや日付に基づいて画像を並べ替えることができるようになりました。 写真の検索は、面倒で複雑ではありません。 Vision AI は、AutoML Vision または事前トレーニング済みの Vision API モデルを使用してクラウド内の画像から分析情報を引き出し、テキストを識別し、画像内の感情を理解します。
- 白黒画像のカラーリング: 白黒の画像に色を付けるのは、コンピューター ビジョン アルゴリズムの助けを借りて、子供の遊びのようなものです。コンピューター ビジョン アルゴリズムは、ディープ ラーニング技術を使用して、適切な色のトーンで色を付けることで写真に命を吹き込みます。 Colorful Image Colorization マイクロ サービスは、コンピュータ ビジョン技術とディープ ラーニング アルゴリズムを使用するアルゴリズムであり、Imagenet データベースでトレーニングされ、白黒の画像に色を付けます。
- 無声映画にサウンドを追加する: AI は、サイレント ビデオ用のリアルなサウンド トラックを作成できるようになりました。 CNN とリカレント ニューラル ネットワークを使用して、特徴抽出と予測プロセスを実行します。 調査によると、音を予測することを学習したこれらのアルゴリズムは、古い映画の効果音を改善し、ロボットが周囲の物体を理解するのに役立つことが示されています。
- 画像から言語への翻訳: これは、深層学習のもう XNUMX つの興味深いアプリケーションです。 Google 翻訳アプリは、選択したリアルタイムの言語に画像を自動的に翻訳できます。 深層学習ネットワークが画像を読み取り、テキストを必要な言語に翻訳します。
- ピクセルの復元: Google Brain の研究者は、人の顔の非常に低解像度の画像を取得し、それを通じて人の顔を予測するディープ ラーニング ネットワークをトレーニングしました。 この方法は、Pixel Recursive Super Resolution として知られています。 この方法は、人物の個性を識別するのに十分な顕著な特徴を識別することによって、写真の解像度を高めます。
まとめ
この章では、人工知能の現在および将来の機能についてより明確なアイデアを提供するために、機械学習と深層学習のアプリケーションを発見しました。 近い将来、人工知能の多くのアプリケーションが私たちの生活に影響を与えると予測されています。 予測分析と 人工知能 将来、コンテンツ作成やソフトウェア開発において基本的な役割を果たすことになります。 実際、彼らはすでに影響を与えているという事実があります。 今後数年以内に、AI 開発ツール、ライブラリ、および言語は、あらゆるソフトウェア開発ツールキットの標準コンポーネントとして広く受け入れられるようになるでしょう。 人工知能の技術は、健康、ビジネス、環境、公共の安全とセキュリティを含むすべての領域で未来になります。
参考文献
[1] Aditya Sharma(2018)、「機械学習と深層学習の違い」
【2] キスレイ・ケシャリ(2020)、「機械学習の応用トップ 10 : 日常生活における機械学習の応用」
[3] Brett Grossfeld (2020)、「深層学習と機械学習: 違いを理解する簡単な方法」
[4] Nikita Duggal (2020)、「あなたの心を吹き飛ばす実世界の機械学習アプリケーション」
[5] PP Shinde and S. Shah, “A Review of Machine Learning and Deep Learning Applications,” 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 2018, pp. 1-6
[6] https://www.javatpoint.com/machine-learning-life-cycle
【7] https://medium.com/app-affairs/9-applications-of-machine-learning-from-day-to-day-life-112a47a429d0
【8] ダン・シェワン(2019)、「機械学習をクールな方法で使用している 10 社」
【9] マリーナ・チャタジー(2019)、「業界全体での 20 年のディープ ラーニングのトップ 2020 アプリケーション
【10] による機械学習アルゴリズムのツアー ジェイソン・ブラウンリー in 機械学習アルゴリズム
[11] Jaderberg、マックス、他。 「空間変換ネットワーク」。 神経情報処理システムの進歩 (2015): 2017-2025.
[12] Van Veen, F. & Leijnen, S. (2019). ニューラル ネットワーク動物園。 から取得 https://www.asimovinstitute.org/neural-network-zoo
[13] Alex Krizhevsky、Ilya Sutskever、Geoffrey E. Hinton、深層畳み込みニューラル ネットワークによる ImageNet 分類、[pdf]、2012
[14] Yadav, Neha, Anupam, Kumar, Manoj, An Introduction to Neural Networks for Differential Equations (ISBN: 978-94-017-9815-0)
[15] Hugo Mayo、Hashan Punchihewa、Julie Emile、Jackson Morrison 機械学習の歴史、2018
[16] ペドロ・ドミンゴス、2012 年、機械学習アプリケーションの進歩に必要な「民間知識」を利用する。 A Few Useful 著、doi:10.1145/2347736.2347755
[17] Alex Smola と SVN Vishwanathan、機械学習入門、Cambridge University Press 2008
[18] アントニオ・ギリとスジット・パル、 Keras を使用したディープ ラーニング: Python の機能を使用してディープ ラーニング モデルとニューラル ネットワークを実装する、リリース年: 2017; 株式会社パックト出版
[19] オーレリアン・ジェロンScikit-Learn と Tensor Flow を使用した実践的な機械学習: インテリジェント システムを構築するための概念、ツール、および手法, リリース年: 2017. オライリー
[20] 機械学習に最適な言語: 学ぶべきプログラミング言語、31 年 2020 月 XNUMX 日、Springboard India。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.mygreatlearning.com/blog/machine-learning-and-deep-learning/

