Safety is emerging as a concern across an increasing number of industries, but standards and methodologies are not in place to ensure electronic systems attain a defined level of safety over time. Much of this falls on the shoulders of the chip industry, which provides the underlying technology, and it raises questions about what more can be done to improve safety.
A crude taxonomy recently was introduced for the verification and test of safety and security (see figure 1 below). Many issues span a total matrix. For example, an autonomous vehicle must have safe and secure hardware and software over the lifetime of the product, but it also must remain safe and secure even in the presence of hardware faults. Unfortunately, there are no tools that can determine if this abstract goal has been achieved. Instead, tools and methodologies tend to cover one or two of the boxes, and the integration of that is somewhat ad-hoc. That, in turn, allows some potential issues to fall between the cracks. In addition, the metrics used are loosely correlated with reality.
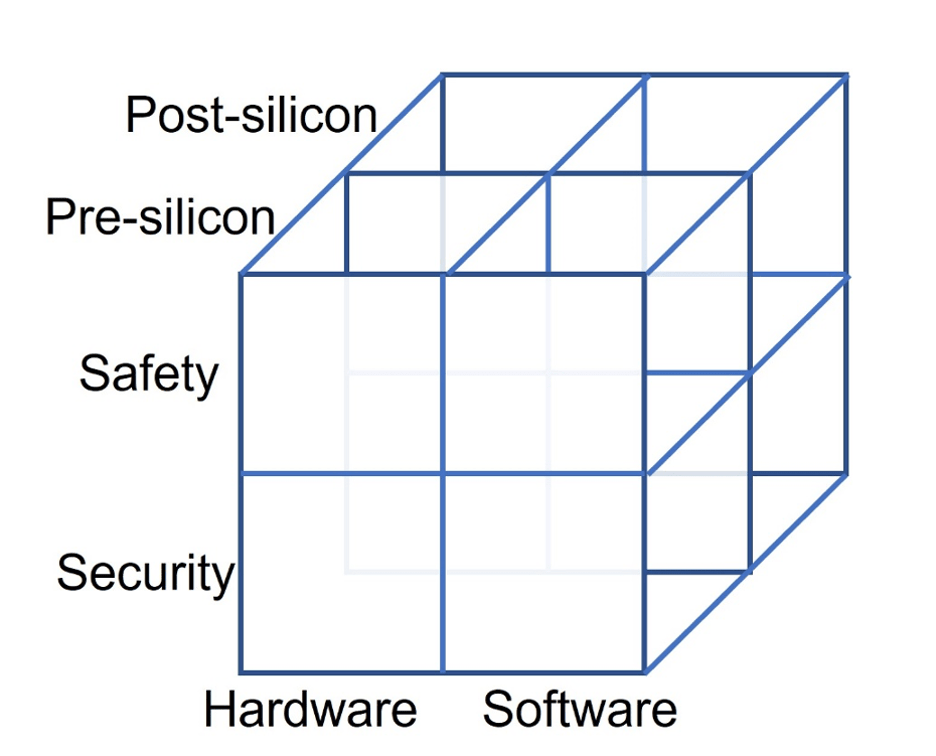
Fig. 1: Matrix of issues associated with safety and security. Source: Semiconductor Engineering
Making matters worse, not all boxes or combinations of boxes are adequately dealt with today, in part because they are viewed as being lower priority and in part because the costs are simply too high. For example, hardware safety is dealt with by standards in several fields. Software safety is also covered by different standards, but nothing defines safety of the combined hardware and software or talks about the safety of the complete system. The closest it gets is to consider fault campaigns that attempt to show the percentage of hardware errors detected by software. In addition, the more hardware is optimized for defined workloads and scenarios, the greater the possibility that software, or future software updates, will cause the hardware to operate in ways that were not originally considered. That, in turn, can cause the hardware to age prematurely, or put it into states that create unexpected vulnerabilities.
Fault models
Measuring anything requires a practical metric in the sense that something must be tractable and effective, but does not necessarily have to be based on reality. Fault models, such as the stuck-at-fault, have been around a long time and proven effective for representing hardware failures — even though there are many ways in which hardware can fail, such as open circuits, short circuits, or slow operation. Transient faults are also important because they represent possible bit-flips caused by radiation.
“There is a family of specifications that apply to functional safety across several industries,” says Pete Hardee, group director for product management at Cadence. “There is a general IEC standard, IEC 61508, which is sort of the meta standard. ISO 26262 was a derivative of that, made more specific for the automotive market. There are other derivatives of that same meta standard for railway, for medical equipment, for factory automation, for nuclear, for all kinds of things. There is DO-254, which applies to the aerospace industry. More and more people are getting into the supply chain for those areas and have to consider meeting some functional safety specs.”
We then can push into those specs. “ISO 26262, and specifically parts 5 and 11, are the guidance for semiconductors,” says Jake Wiltgen, functional safety and autonomous solutions manager at Siemens Digital Industries Software. “There are specific metrics that are being asked of by those standards, and those are coverage metrics. The term used in ISO is diagnostic coverage, but essentially that is the failure rate that is detected over the total failure rate.”
Processes needs to be established. “Achieving a high degree of confidence in safety relies on well-defined processes and their strict obedience,” says Roland Jancke, design methodology head in Fraunhofer IIS’ Engineering of Adaptive Systems Division. “One of the best methods for that is Requirements Engineering (RE). It starts with proper defined safety goals, proceeds with setting up respective requirements and transforming them into test cases. An essential ingredient is to establish requirement tracking along the entire process in order to go into the redesign loop only for the affected parts in case anything changes.”
For automotive, how safe a system needs to be depends on the degree of autonomy. “It really depends on the ASIL level that people are aiming for,” says Cadence’s Hardee. “ASIL A is no real change, but ‘I’ve got to get my process certified.’ ASIL B can be very little impact as well in some cases. But when it comes to meeting ASIL C and ASIL D levels, it can become quite challenging. This is very much allied with what people are already doing for functional verification, because the basic methodology to verify and meet the spec is to look at a good machine, and achieve good coverage with functional verification. Then I am going to compare that with a bad machine in which I’m going to introduce faults. The failure rate should be 10 to the minus eight per operating hour and I’ve got to be able to detect 99% of those failures and ensure that the system fails safe.”
How that is done is left to the designer. “It is up to the designers to come up with architectures, or technologies, or solutions, which could demonstrate that they could meet those quality goals,” says Simon Davidmann, founder and CEO for Imperas Software. “The challenge is how they review the quality of what they’ve done. They may want to run simulations, with faults injected, to see how resilient their software and hardware was to these faults. There was quite a lot of work being done on the fault models, in terms of the representing these different things that happen in the real world.”
That is where practicality comes into play. “If you take a 100 million gate design and look at the number of different fault mechanisms, there’s no way any single approach can cover that,” says Manish Pandey, vice president of engineering for the EDA Group at Synopsys. “From a formal perspective, taking all the faults and trying to propagate it is computationally infeasible. We need to get better methodologies for sampling the points, have different internal failure modes, decide safe and unsafe regions, etc. Such a safety methodology needs ways to construct appropriate fault campaigns, and this has to be done in a very conscious way. Awareness of micro-architecture is critical.”
Safety over time
It is not enough to do this on ideal hardware. “Another category is guaranteeing the expected functionality over the entire lifetime,” says Fraunhofer’s Jancke. “This is ensured by reliability simulation, which in turn depends on proper degradation models for known aging mechanisms and comprehensive lifetime extrapolation capabilities.”
Aging plays a critical role. “If you look at manufacturing test, they usually test 20% above and beyond the absolute spec, whether it’s clock frequency, power, or temperature,” says Robert Serphillips, product manager for Veloce, DFT, and functional safety at Siemens EDA. “Silicon will degrade over time, and temperature is very critical. With high heat, the device physically slows down. Things like fast path and slow path now start to become problematic. From a safety standpoint, the way the device behaves in its ambient environment is critical to how the device degrades, and how faults start showing up, and how circuits start failing. All that has to be accounted for, not just random photons shooting from outer space. Can the device behave the same way for the lifespan of what it is rated for?”
And does that support usage of the stuck-at-model? “When we consider aging, the threshold of circuitry can change,” says Hardee. “The circuitry can be more susceptible to those things and the device can outright fail, which will generally create a stuck-at fault.”
But not always. “When you go to a 5nm or 3nm geometry, there are so many weird ways in which these chips age and fail,” says Synopsys’ Pandey. “In wires, you have electromigration and this could produce an open circuit. There are some mechanisms that we don’t even know about. Another interesting thing that’s happening is how you detect faults, and how embedded sensors in the design can monitor how these chips are behaving, how they are degrading. Is there a potential fault creeping up? We will have to supplement the traditional fault campaign approaches with additional chip monitoring and chip intelligence.”
In-chip monitoring supplements other BiST techniques. “Advanced SLM monitors are upgraded through analytics to act as capable safety mechanisms against intermittent and degrading faults,” says Dan Alexandrescu, reliability core team leader within Synopsys’ Strategic System Engineering. “A multi-stage approach uses information from advanced sensors that are tightly embedded in critical design blocks. Path margin monitoring, pre-error detection, memory access time measurements, ECC, and BiST events are evaluated cohesively into relevant and timely safety and quality metrics. Actionable insights are then issued to the system actuators to promptly correct safety and reliability threats. Deep silicon data is sent to edge and cloud platforms for fleet-level monitoring. Advanced analytics at all stages provide a quick and precise understanding of very infrequent events and phenomena, helping deployed products to be used safely and enabling higher quality for future designs.”
Remote analysis places requirements on functional verification. “Lifecycle monitoring, and reporting back to the OEM that there’s something going wrong in a particular car with a defined VIN number, is something that the OEMs are looking to do,” says Johannes Stahl, senior director of product line management for the Systems Design Group at Synopsys. “From a verification perspective, at the pre-silicon stage, you have to make sure that these mechanisms work, and provide the right information.”
Extending into AI
Autonomous vehicles increasingly utilize AI, and this introduces a new set of challenges for verification and validation. Many of these are not fully understood today. Figure 2 (below) defines how verification of AI systems differs from conventional software.


Fig. 2: Contrast of conventional and machine learning algorithms from V&V perspective. Source: Reproduced with permission from a paper entitled “PolyVerif: An Open-Source Environment for Autonomous Vehicle Validation and Verification Research Acceleration,” authored by Rahul Razdan, et al. IEEE Access – 2023
How do you detect that an AI system has failed? “Artificial intelligence is a statistical system, and it will fail at some point of time,” says Pandey. “How do we ensure that these continue to be well behaved systems? There is emerging work on formally verifying some of these AI systems and making sure they stay within bounds. There is research going on to contain these systems. But if we are supplementing traditional systems with additional sensors and other fail-safe mechanisms, there is something needed to qualify and make sure the systems actually do what they are supposed to do.”
In the future, it becomes even more complex. “At a philosophical level, an AI system is by nature a learning system,” says Synopsys’ Stahl. “Software is written by a human and can contain errors. So philosophically, does AI have a higher risk than software? Is it an AI system that can learn?”
Constraining the fault space
The fault space for hardware is huge, even with a highly restricted fault model. So additional techniques must be used to limit the number of faults that actually do have to be considered.
“Failure mode effects and diagnostic analysis (FMEDA) takes into account the reliability figures of the circuitry you’re dealing with,” says Hardee. “You are looking at the modes of failure and the effects of those modes. So we’re really only looking at the subset of faults, which could occur in places that propagate to functional outputs that could cause harm.”
There is not a single best way to do this. “With fault simulation you are injecting faults into the design and seeing if they are detected and or observed,” says Siemens’ Wiltgen. “But that’s not the only way. There are other analytical methods that can be deployed to come to those metrics, as well. It takes a combination of different tools and methodologies, in both the static and formal space, as well as the simulation space, to arrive at those metrics as quickly and efficiently as possible.”
Field testing and digital twins can supplement existing tools. “Someone fiddles with a dip switch and says I’m inserting a bug right here,” says Frank Schirrmeister, vice president of marketing at Arteris. “You want to check that your test actually found this bug. This is like running a safety campaign, but running it physically in the system. Will there be more tools like this to insert safety and security items? Probably, and they will extend them into virtualization. With an electronic digital twin you insert something and figure out if the virtual representation matches the real hardware.”
Conclusion
Empirical evidence suggests that simplified fault models — rationally applied to the hardware aspect of system, coupled with software and built-in sensors to detect and sometimes correct errant behaviors — do an adequate job of ensuring the hardware is safe over its lifetime. It relies on a few experts overlooking the process to make sure that adequate consideration is given, based on the environment it is to operate in and the amount of safety that can be afforded.
The process is ad-hoc and incomplete, however, because it does not look at total system safety. That should be the goal.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- ChartPrime. Elevate your Trading Game with ChartPrime. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://semiengineering.com/why-its-so-difficult-to-ensure-system-safety-over-time/

