
A graph database (GDB) models data as a combination of nodes (vertices) and edges (relationships) with equal importance. Businesspeople query these structures to reveal patterns and insights within the data and their associations. These would be difficult to discern from other data visualizations, such as tables, charts, and documents.
Since humans naturally think by associating one concept with another, people find graph databases intuitive and handy tools for understanding complex problems. Additionally, some AI systems learn best from graph databases because their architectures resemble human minds.
Graph databases get their capabilities by leveraging nonrelational technologies. Their infrastructures efficiently handle multiple types and large volumes of data ingested in real time.
Consequently, GDBs have flexible structures and the scalability to present as many related scenarios as a user would like and remain performant. Furthermore, those querying graphs can quickly discover new concepts through associations among the data.
Graph Database Defined
In addition to the main definition discussed earlier, alternative definitions include the concept of properties. These components describe attributes of nodes and relationships.
While graph representations can include properties, they are not a mandatory component. Other descriptions elaborate on the capabilities that graph databases bring. Neo4j describes it as a whiteboard where people may sketch ideas, leading to a better understanding.
Some meanings of GDBs emphasize either of two types of construction, as described below:
- Native Graph Databases: Native GBDs, an important distinction emphasized in some definitions, store and process data using graph architecture, providing all its benefits. In this definition, graph applications retrieve data directly from the nodes. Plus, the application can prune nodes or relationships when they are no longer relevant.
- Non-native/Multi-modal Graph Databases: Non-native or multi-modal GBDs have an infrastructure with a graphing functionality on top of another database system’s architecture. Although non-native graph architectures provide some flexibility and strengths found in native applications, they do not have the same level of performance. This slowness occurs due to the translation between different data models between non-graphical and graphical database systems. Although non-native graph databases differ from native ones in their construction, they follow the same rules when displaying information.
What Are the Rules of a Graph Database?
Graph database components follow specific rules. Graph relationships have a specific direction. The edge, a line with an arrow, originates at a starting node and ends at a different node.
Multiple edges can exist between the same entities. See the diagram below, where the teacher John and the student Ann follow each other.
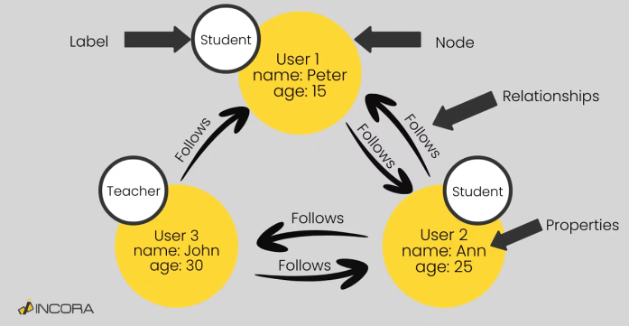
As shown above, nodes appear as dots and can contain labels to provide additional information about their roles. Additionally, nodes and edges can have properties that provide additional context. In the diagram above, each entity has either the property of a student or teacher.
Additionally, properties can carry quantitative values. For example, they assign distances, weights, or costs. In some cases, one entity carries higher importance in the relationship. While these rules enable graph databases to handle complex data relationships, they also reveal certain constraints, such as the difficulty in enforcing consistent hierarchies across nodes. This task is better executed from a relational database.
How Do Graph Databases Differ from Relational Databases?
A graph database processes information using BASE principles:
- Basically available: It is failure resistant.
- Soft state: The data schema could change without any interaction with the database.
- Eventually consistent: The data will be replicated to different nodes and will eventually reach a consistent state. But the consistency is not guaranteed at a transaction level.
However, adhering to these principles can lead to challenges such as data inconsistency across nodes, potential duplication, and delayed updates from different input versions. These issues can impact the overall Data Quality in a graph database, potentially resulting in the inclusion of incorrect information.
In contrast, a relational database processes information using ACID principles:
- Atomicity: Each database action must succeed for the entire transaction to go through.
- Consistency: A transaction must be valid before and after the next data action occurs.
- Isolated: A transaction in transition cannot interfere with another one or vice versa.
- Durability: Once a transaction finishes and is committed, it persists in the database.
By adhering to these principles, relational databases provide a stable and consistent environment that yields more precise query results and maintains reliable Data Quality.
Also, a relational database organizes data into a schema through tables, joins, and constraints with key attributes. This rigid structure handles standardized data transactions, like sales and purchases well. However, a relational architecture performs less efficiently than a graph or vector infrastructure when dealing with complex use cases and multiple data relationships.
Is a Vector Database the Same as a Graph Database?
A vector database stores, manages, and indexes high volumes of high-dimensional values characterized by magnitude and direction. These vectors cluster according to their similarity to a concept.
Consequently, high-performance querying delivers results speedily. This kind of architecture supports AI-driven applications.
While a vector database uses a structure called graph embeddings, which transform nodes into a vector space, it is not a graph database. A vector database represents complex objects, like images, video, and audio.
Instead, a graph database consists of entities and complex relationships. So, both vector and graph databases can identify patterns of fraudulent transactions.
However, a graph database will uncover connections among individuals engaged in fraudulent or suspicious transactions. The GDB provides more details according to its type.
Graph Database Types
While graph databases remain distinct from relational and vector databases, they differ slightly in format. Organizations can choose from at least four kinds of graph databases, and each has unique strengths and weaknesses.
Property Graphs
Property graphs focus on user-friendly presentations with faster querying and efficient storage. They use easily recognizable labels attached to the nodes and relationships.
Thanks to graphing query language (GQL), a standardized framework, users can search, interact, and use property graphs effectively.
Resource Description Framework (RDF)
A resource description framework (RDF) graph provides a richer understanding of nodes and edges through additional context. It accomplishes this result by representing vertices and edges as statements, containing a subject, predicate, and object.
Predicates play essential roles because they help make entities useful through organized systems called ontologies. To retrieve and manipulate ontologies presented in the RDF format, users write SPARQL queries.
Knowledge Graphs (KG)
Knowledge graphs (KGs), as Juan Sequeda says, represent collections of real-world concepts (nodes) and their associations among each other (edges). Knowledge graphs can take either property or RDF formats. Knowledge graphs assist in enhancing AI training.
Graph-based Artificial Intelligence (Graph AI)
Graph-based artificial intelligence (Graph AI) describes the graphical models that AI algorithms, such as machine learning (ML) and deep learning (DL), build and use. Graph programs focus on relationships and can find structures and reveal patterns there through graph mining.
Also, this technology can use ML and DL to process and leverage graph databases. This graph AI handles predictive, modeling, and analytical tasks.
Graph Database Use Cases
Organizations might use a graph database for a variety of reasons. Examples are below:
- Supply Chain Management: Lockheed Martin Space uses graph technologies for supply chain management, making it easier for them to uncover potential weaknesses and boost supply chain resilience. Their CDAO, Tobin Thomas, stated in an interview, “We … connect the relationships together, so we can see the lifecycle based on selected parts or components and the relationships between every element.”
- Preventive Maintenance: Caterpillar, a construction equipment manufacturer, uses a knowledge graph and generative AI to predict maintenance issues. The tool detects hidden trends and predicts outcomes.
- Discover New Resources: DeepMind Gnome discovered 380,000 stable crystal structures, which are arrangements of atoms in a crystal that are thermodynamically stable. This result enabled clean energy and information processing breakthroughs.
- Weather Forecasting: Google’s DeepMind improved the efficiency of making medium-range weather forecasts. It predicts conditions up to 10 days in advance more accurately and quickly.
- Detect Infections: The New York Presbyterian Hospital uses a graph database to track infections and recommend actions in response. The graphing tool helps an analytics team to analyze everything in its facilities: “It proactively identifies and contains diseases before they spread.”
- Detecting Financial Fraud: A financial institution used graph databases to analyze transaction data and identify fraudulent patterns. The organization found its fraud detection accuracy increased by 25%.
- Customer Recommendations: Amazon applies an item-to-item collaborative filtering capability using graph analytics. Recommendation systems are responsible for 35% of Amazon purchases.
- Power Search Results: A major e-commerce platform included a Knowledge Graph to improve how search engines understood the business, products, categories, and user intent. The “platform experienced a 35% increase in click-through rates from search engine results pages, as well as a 20% uplift in organic traffic, according to their internal analytics.”
- Regulatory compliance: A global bank, facing increasing regulatory obligations, used a knowledge graph-based solution to better alert the company of suspicious activity.” The graph structure enabled data scientists to further develop statistical models for analyzing strange patterns of information or subsets of information.”
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.dataversity.net/what-is-a-graph-database/

