Hôm nay, chúng tôi vui mừng thông báo khả năng tinh chỉnh các mô hình Code Llama của Meta bằng cách sử dụng Khởi động Amazon SageMaker. Nhóm mô hình ngôn ngữ lớn (LLM) Code Llama là tập hợp các mô hình tạo mã được đào tạo trước và tinh chỉnh có quy mô từ 7 tỷ đến 70 tỷ tham số. Các mô hình Code Llama được tinh chỉnh mang lại độ chính xác và khả năng giải thích tốt hơn so với các mô hình Code Llama cơ bản, thể hiện rõ qua thử nghiệm của nó đối với con người và bộ dữ liệu MBPP. Bạn có thể tinh chỉnh và triển khai các mô hình Code Llama bằng SageMaker JumpStart bằng cách sử dụng Xưởng sản xuất Amazon SageMaker Giao diện người dùng với một vài cú nhấp chuột hoặc sử dụng SDK Python của SageMaker. Việc tinh chỉnh các mô hình Llama dựa trên các tập lệnh được cung cấp trong công thức nấu ăn llama GitHub repo từ Meta bằng cách sử dụng các kỹ thuật lượng tử hóa PyTorch FSDP, PEFT/LoRA và Int8.
Trong bài đăng này, chúng tôi sẽ hướng dẫn cách tinh chỉnh các mô hình được đào tạo trước Code Llama thông qua SageMaker JumpStart thông qua trải nghiệm SDK và giao diện người dùng chỉ bằng một cú nhấp chuột có sẵn trong phần sau Kho GitHub.
Khởi động SageMaker là gì
Với SageMaker JumpStart, những người thực hành máy học (ML) có thể chọn từ rất nhiều mô hình nền tảng có sẵn công khai. Những người thực hành ML có thể triển khai các mô hình nền tảng cho các mục đích chuyên dụng Amazon SageMaker các phiên bản từ môi trường cách ly mạng và tùy chỉnh các mô hình bằng SageMaker để đào tạo và triển khai mô hình.
Mã Llama là gì
Code Llama là phiên bản chuyên biệt về mã của lạc đà không bướu 2 được tạo bằng cách đào tạo thêm Llama 2 về các tập dữ liệu dành riêng cho mã của nó và lấy mẫu nhiều dữ liệu hơn từ cùng một tập dữ liệu đó trong thời gian dài hơn. Code Llama có khả năng mã hóa nâng cao. Nó có thể tạo mã và ngôn ngữ tự nhiên về mã, từ cả mã và lời nhắc ngôn ngữ tự nhiên (ví dụ: “Viết cho tôi một hàm xuất ra chuỗi Fibonacci”). Bạn cũng có thể sử dụng nó để hoàn thành và gỡ lỗi mã. Nó hỗ trợ nhiều ngôn ngữ lập trình phổ biến nhất được sử dụng hiện nay, bao gồm Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash, v.v.
Tại sao phải tinh chỉnh các mô hình Code Llama
Meta đã công bố điểm chuẩn hiệu suất Code Llama trên HumanEval và MBPP dành cho các ngôn ngữ mã hóa phổ biến như Python, Java và JavaScript. Hiệu suất của các mô hình Code Llama Python trên HumanEval đã chứng minh hiệu suất khác nhau giữa các ngôn ngữ và tác vụ mã hóa khác nhau, từ 38% trên mô hình Python 7B đến 57% trên các mô hình Python 70B. Ngoài ra, các mô hình Code Llama được tinh chỉnh trên ngôn ngữ lập trình SQL đã cho kết quả tốt hơn, thể hiện rõ trong các tiêu chuẩn đánh giá SQL. Các điểm chuẩn được công bố này nêu bật những lợi ích tiềm năng của việc tinh chỉnh các mô hình Code Llama, cho phép thực hiện, tùy chỉnh và thích ứng tốt hơn với các miền và tác vụ mã hóa cụ thể.
Tinh chỉnh không cần mã thông qua giao diện người dùng SageMaker Studio
Để bắt đầu tinh chỉnh các mô hình Llama của bạn bằng SageMaker Studio, hãy hoàn thành các bước sau:
- Trên bảng điều khiển SageMaker Studio, chọn Khởi động trong khung điều hướng.
Bạn sẽ tìm thấy danh sách hơn 350 mô hình, từ các mô hình nguồn mở và độc quyền.
- Tìm kiếm các mô hình Code Llama.

Nếu không thấy các mẫu Code Llama, bạn có thể cập nhật phiên bản SageMaker Studio bằng cách tắt và khởi động lại. Để biết thêm thông tin về các bản cập nhật phiên bản, hãy tham khảo Tắt và cập nhật ứng dụng Studio. Bạn cũng có thể tìm thấy các biến thể mô hình khác bằng cách chọn Khám phá tất cả các mô hình tạo mã hoặc tìm kiếm Code Llama trong hộp tìm kiếm.
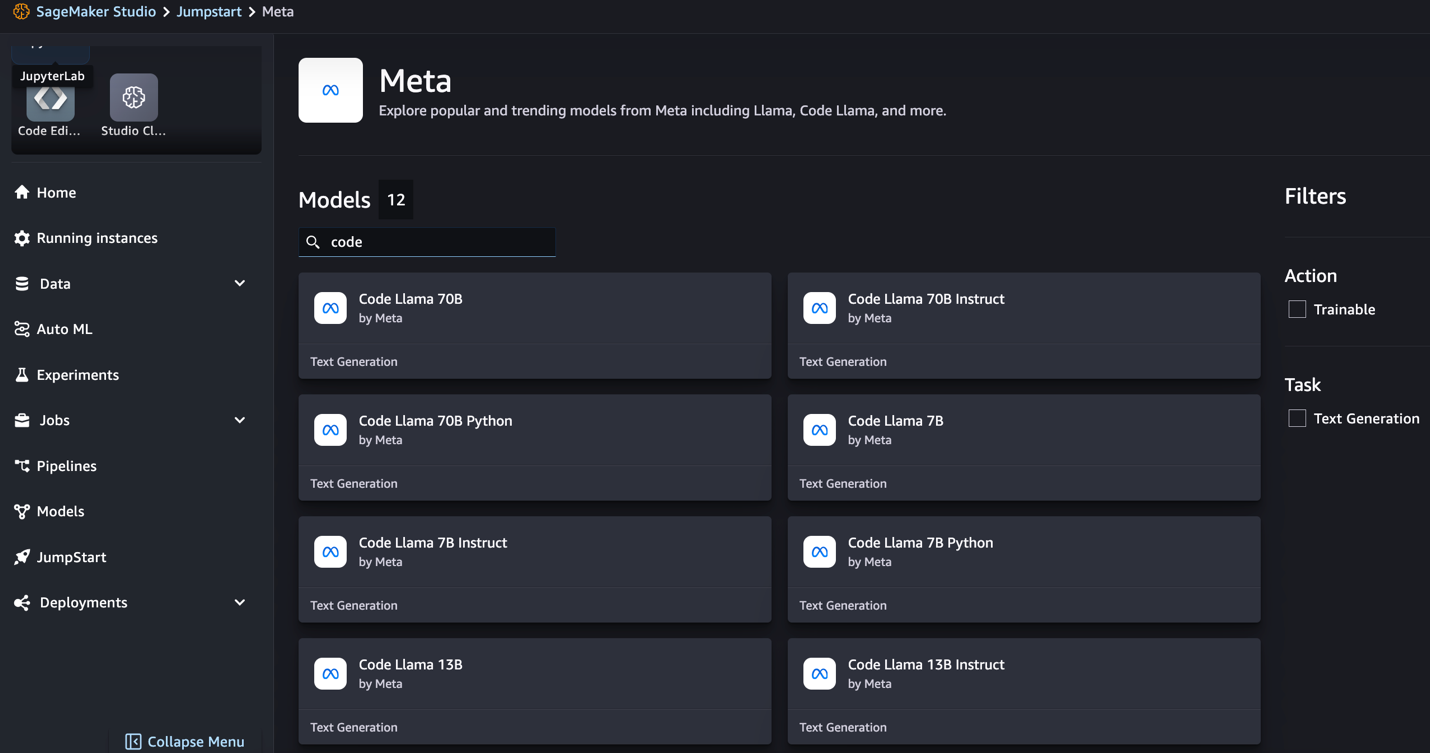
SageMaker JumpStart hiện hỗ trợ tinh chỉnh hướng dẫn cho các mô hình Code Llama. Ảnh chụp màn hình sau đây hiển thị trang tinh chỉnh cho mẫu Code Llama 2 70B.
- Trong Vị trí tập dữ liệu huấn luyện, bạn có thể trỏ đến Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) chứa tập dữ liệu huấn luyện và xác thực để tinh chỉnh.
- Đặt cấu hình triển khai, siêu tham số và cài đặt bảo mật của bạn để tinh chỉnh.
- Chọn Train để bắt đầu công việc tinh chỉnh trên phiên bản SageMaker ML.
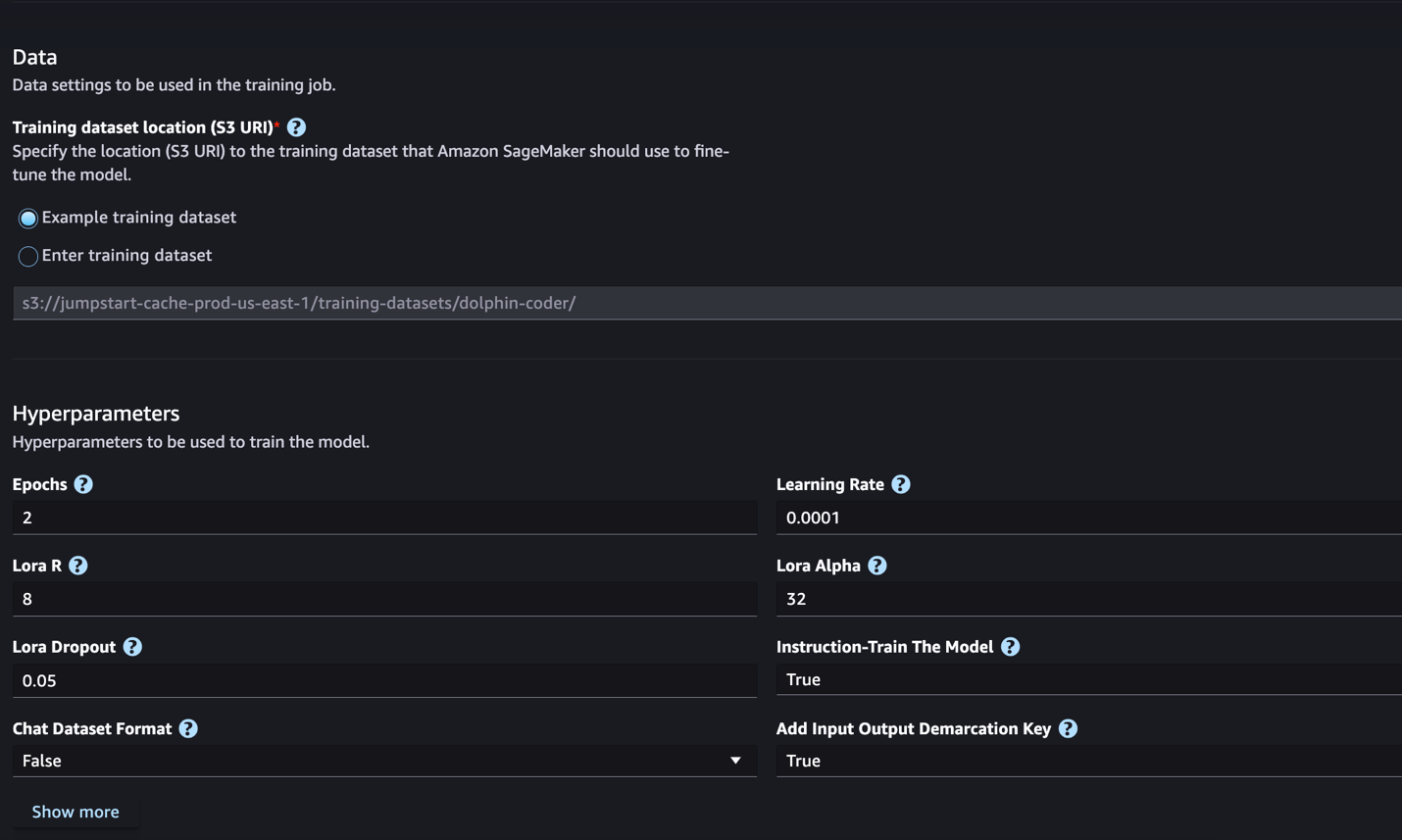
Chúng tôi thảo luận về định dạng tập dữ liệu mà bạn cần chuẩn bị cho việc tinh chỉnh hướng dẫn trong phần tiếp theo.
- Sau khi tinh chỉnh mô hình, bạn có thể triển khai nó bằng trang mô hình trên SageMaker JumpStart.
Tùy chọn triển khai mô hình tinh chỉnh sẽ xuất hiện khi quá trình tinh chỉnh hoàn tất, như minh họa trong ảnh chụp màn hình sau.

Tinh chỉnh thông qua SageMaker Python SDK
Trong phần này, chúng tôi trình bày cách tinh chỉnh các mô hình Code LIama bằng SageMaker Python SDK trên tập dữ liệu có định dạng hướng dẫn. Cụ thể, mô hình được tinh chỉnh cho một tập hợp các tác vụ xử lý ngôn ngữ tự nhiên (NLP) được mô tả bằng các hướng dẫn. Điều này giúp cải thiện hiệu suất của mô hình đối với các tác vụ không nhìn thấy được với lời nhắc không chụp.
Hoàn thành các bước sau để hoàn thành công việc tinh chỉnh của bạn. Bạn có thể lấy toàn bộ mã tinh chỉnh từ Kho GitHub.
Trước tiên, hãy xem định dạng tập dữ liệu cần thiết để tinh chỉnh hướng dẫn. Dữ liệu huấn luyện phải được định dạng ở định dạng dòng JSON (.jsonl), trong đó mỗi dòng là một từ điển biểu thị một mẫu dữ liệu. Tất cả dữ liệu đào tạo phải nằm trong một thư mục duy nhất. Tuy nhiên, nó có thể được lưu trong nhiều tệp .jsonl. Sau đây là mẫu ở định dạng dòng JSON:
Thư mục đào tạo có thể chứa một template.json tập tin mô tả các định dạng đầu vào và đầu ra. Sau đây là một mẫu ví dụ:
Để khớp với mẫu, mỗi mẫu trong tệp dòng JSON phải bao gồm system_prompt, questionvà response lĩnh vực. Trong phần trình diễn này, chúng tôi sử dụng Bộ dữ liệu Dolphin Coder từ Ôm Mặt.
Sau khi chuẩn bị tập dữ liệu và tải lên vùng lưu trữ S3, bạn có thể bắt đầu tinh chỉnh bằng cách sử dụng mã sau:
Bạn có thể triển khai mô hình tinh chỉnh trực tiếp từ công cụ ước tính, như minh họa trong đoạn mã sau. Để biết chi tiết, xem sổ ghi chép trong Kho GitHub.
Kỹ thuật tinh chỉnh
Các mô hình ngôn ngữ như Llama có kích thước hơn 10 GB hoặc thậm chí 100 GB. Việc tinh chỉnh các mô hình lớn như vậy đòi hỏi các phiên bản có bộ nhớ CUDA cao đáng kể. Hơn nữa, việc đào tạo các mô hình này có thể rất chậm do kích thước của mô hình. Do đó, để tinh chỉnh hiệu quả, chúng tôi sử dụng các phương pháp tối ưu hóa sau:
- Thích ứng cấp thấp (LoRA) – Đây là loại tinh chỉnh hiệu quả tham số (PEFT) dùng để tinh chỉnh hiệu quả các mô hình lớn. Với phương pháp này, bạn đóng băng toàn bộ mô hình và chỉ thêm một tập hợp nhỏ các tham số hoặc lớp có thể điều chỉnh vào mô hình. Chẳng hạn, thay vì đào tạo tất cả 7 tỷ tham số cho Llama 2 7B, bạn có thể tinh chỉnh ít hơn 1% tham số. Điều này giúp giảm đáng kể yêu cầu bộ nhớ vì bạn chỉ cần lưu trữ độ dốc, trạng thái tối ưu hóa và các thông tin liên quan đến đào tạo khác chỉ cho 1% tham số. Hơn nữa, điều này giúp giảm thời gian đào tạo cũng như chi phí. Để biết thêm chi tiết về phương pháp này, hãy tham khảo LoRA: Thích ứng cấp thấp của các mô hình ngôn ngữ lớn.
- Lượng tử hóa Int8 – Ngay cả với những tối ưu hóa như LoRA, những mô hình như Llama 70B vẫn quá lớn để đào tạo. Để giảm dung lượng bộ nhớ trong quá trình đào tạo, bạn có thể sử dụng lượng tử hóa Int8 trong quá trình đào tạo. Lượng tử hóa thường làm giảm độ chính xác của các kiểu dữ liệu dấu phẩy động. Mặc dù điều này làm giảm bộ nhớ cần thiết để lưu trữ trọng lượng mô hình nhưng nó làm giảm hiệu suất do mất thông tin. Lượng tử hóa Int8 chỉ sử dụng độ chính xác một phần tư nhưng không làm giảm hiệu suất vì nó không chỉ loại bỏ các bit. Nó làm tròn dữ liệu từ loại này sang loại khác. Để tìm hiểu về lượng tử hóa Int8, hãy tham khảo LLM.int8(): Phép nhân ma trận 8 bit cho máy biến áp ở quy mô.
- Dữ liệu song song được phân chia hoàn toàn (FSDP) – Đây là một loại thuật toán đào tạo song song dữ liệu giúp phân chia các tham số của mô hình giữa các nhân viên song song dữ liệu và có thể tùy ý giảm tải một phần tính toán đào tạo cho CPU. Mặc dù các tham số được phân chia trên các GPU khác nhau nhưng việc tính toán từng microbatch là cục bộ đối với nhân viên GPU. Nó phân chia các tham số một cách đồng nhất hơn và đạt được hiệu suất tối ưu thông qua sự chồng chéo về giao tiếp và tính toán trong quá trình đào tạo.
Bảng dưới đây tóm tắt chi tiết từng model với các cài đặt khác nhau.
| Mô hình | Cài đặt mặc định | LORA + FSDP | LORA + Không có FSDP | Lượng tử hóa Int8 + LORA + Không FSDP |
| Mã Llama 2 7B | LORA + FSDP | Có | Có | Có |
| Mã Llama 2 13B | LORA + FSDP | Có | Có | Có |
| Mã Llama 2 34B | INT8 + LORA + KHÔNG FSDP | Không | Không | Có |
| Mã Llama 2 70B | INT8 + LORA + KHÔNG FSDP | Không | Không | Có |
Việc tinh chỉnh các mô hình Llama dựa trên các tập lệnh được cung cấp sau đây Repo GitHub.
Siêu tham số được hỗ trợ cho đào tạo
Tinh chỉnh Code Llama 2 hỗ trợ một số siêu tham số, mỗi siêu tham số có thể tác động đến yêu cầu bộ nhớ, tốc độ đào tạo và hiệu suất của mô hình tinh chỉnh:
- kỷ nguyên – Số bước mà thuật toán tinh chỉnh thực hiện qua tập dữ liệu huấn luyện. Phải là số nguyên lớn hơn 1. Mặc định là 5.
- tỷ lệ học – Tốc độ cập nhật trọng số của mô hình sau khi làm việc qua từng đợt mẫu huấn luyện. Phải là số float dương lớn hơn 0. Mặc định là 1e-4.
- hướng dẫn_điều chỉnh – Có hướng dẫn đào tạo mô hình hay không. Cần phải
TrueorFalse. Mặc định làFalse. - per_device_train_batch_size – Kích thước lô trên mỗi lõi GPU/CPU để đào tạo. Phải là số nguyên dương. Mặc định là 4.
- per_device_eval_batch_size – Kích thước lô trên mỗi lõi GPU/CPU để đánh giá. Phải là số nguyên dương. Mặc định là 1.
- max_train_samples – Với mục đích gỡ lỗi hoặc đào tạo nhanh hơn, hãy cắt bớt số lượng ví dụ đào tạo về giá trị này. Giá trị -1 có nghĩa là sử dụng tất cả các mẫu huấn luyện. Phải là số nguyên dương hoặc -1. Mặc định là -1.
- max_val_samples – Để phục vụ mục đích gỡ lỗi hoặc đào tạo nhanh hơn, hãy cắt bớt số lượng ví dụ xác thực về giá trị này. Giá trị -1 có nghĩa là sử dụng tất cả các mẫu xác thực. Phải là số nguyên dương hoặc -1. Mặc định là -1.
- max_input_length – Tổng độ dài chuỗi đầu vào tối đa sau khi mã hóa. Các chuỗi dài hơn sẽ bị cắt bớt. Nếu -1,
max_input_lengthđược đặt ở mức tối thiểu là 1024 và độ dài mô hình tối đa được xác định bởi trình mã thông báo. Nếu được đặt thành giá trị dương,max_input_lengthđược đặt ở mức tối thiểu của giá trị được cung cấp vàmodel_max_lengthđược xác định bởi tokenizer. Phải là số nguyên dương hoặc -1. Mặc định là -1. - xác thực_split_ratio – Nếu kênh xác thực là
none, tỷ lệ phân tách xác thực tàu khỏi dữ liệu tàu phải nằm trong khoảng 0–1. Mặc định là 0.2. - train_data_split_seed – Nếu không có dữ liệu xác thực, thao tác này sẽ khắc phục sự phân chia ngẫu nhiên của dữ liệu huấn luyện đầu vào thành dữ liệu huấn luyện và dữ liệu xác thực được thuật toán sử dụng. Phải là số nguyên. Mặc định là 0.
- tiền xử lý_num_workers – Số lượng tiến trình được sử dụng cho quá trình tiền xử lý. Nếu như
None, quy trình chính được sử dụng để tiền xử lý. Mặc định làNone. - lora_r – Lora R. Phải là số nguyên dương. Mặc định là 8.
- lora_alpha – Lora Alpha. Phải là số nguyên dương. Mặc định là 32
- lora_dropout – Lora bỏ học. phải là số float dương trong khoảng từ 0 đến 1. Mặc định là 0.05.
- int8_quantization - Nếu
True, mô hình được tải với độ chính xác 8 bit để huấn luyện. Mặc định cho 7B và 13B làFalse. Mặc định cho 70B làTrue. - kích hoạt_fsdp – Nếu đúng, việc huấn luyện sử dụng FSDP. Mặc định cho 7B và 13B là True. Mặc định cho 70B là Sai. Lưu ý rằng
int8_quantizationkhông được hỗ trợ với FSDP.
Khi chọn siêu tham số, hãy cân nhắc những điều sau:
- Cài đặt
int8_quantization=Truegiảm yêu cầu về trí nhớ và dẫn đến việc luyện tập nhanh hơn. - Giảm
per_device_train_batch_sizevàmax_input_lengthgiảm yêu cầu bộ nhớ và do đó có thể chạy trên các phiên bản nhỏ hơn. Tuy nhiên, việc đặt giá trị rất thấp có thể làm tăng thời gian huấn luyện. - Nếu bạn không sử dụng lượng tử hóa Int8 (
int8_quantization=False), hãy sử dụng FSDP (enable_fsdp=True) để đào tạo nhanh hơn và hiệu quả hơn.
Các loại phiên bản được hỗ trợ để đào tạo
Bảng sau đây tóm tắt các loại phiên bản được hỗ trợ để đào tạo các mô hình khác nhau.
| Mô hình | Loại phiên bản mặc định | Các loại phiên bản được hỗ trợ |
| Mã Llama 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Mã Llama 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Mã Llama 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
Khi chọn loại phiên bản, hãy cân nhắc những điều sau:
- Phiên bản G5 cung cấp hoạt động đào tạo hiệu quả nhất trong số các loại phiên bản được hỗ trợ. Do đó, nếu bạn có sẵn phiên bản G5, bạn nên sử dụng chúng.
- Thời gian đào tạo phần lớn phụ thuộc vào số lượng GPU và bộ nhớ CUDA có sẵn. Do đó, việc đào tạo trên các phiên bản có cùng số lượng GPU (ví dụ: ml.g5.2xlarge và ml.g5.4xlarge) gần như giống nhau. Do đó, bạn có thể sử dụng phiên bản rẻ hơn để đào tạo (ml.g5.2xlarge).
- Khi sử dụng phiên bản p3, quá trình đào tạo sẽ được thực hiện với độ chính xác 32 bit vì bfloat16 không được hỗ trợ trên các phiên bản này. Do đó, công việc đào tạo sẽ tiêu tốn gấp đôi dung lượng bộ nhớ CUDA khi đào tạo trên phiên bản p3 so với phiên bản g5.
Để tìm hiểu về chi phí đào tạo cho mỗi phiên bản, hãy tham khảo Phiên bản Amazon EC2 G5.
Đánh giá
Đánh giá là một bước quan trọng để đánh giá hiệu suất của các mô hình được tinh chỉnh. Chúng tôi trình bày cả đánh giá định tính và định lượng để cho thấy sự cải thiện của các mô hình được tinh chỉnh so với các mô hình không được tinh chỉnh. Trong đánh giá định tính, chúng tôi đưa ra một phản hồi mẫu từ cả mô hình được tinh chỉnh và không tinh chỉnh. Trong đánh giá định lượng, chúng tôi sử dụng con người, một bộ thử nghiệm do OpenAI phát triển để tạo mã Python nhằm kiểm tra khả năng tạo ra kết quả chính xác và chính xác. Kho lưu trữ HumanEval theo giấy phép MIT. Chúng tôi đã tinh chỉnh các biến thể Python của tất cả các mô hình Code LIama theo các kích cỡ khác nhau (Mã LIama Python 7B, 13B, 34B và 70B trên Bộ dữ liệu Dolphin Coder) và trình bày kết quả đánh giá ở các phần sau.
Đánh giá định tính
Khi mô hình tinh chỉnh được triển khai, bạn có thể bắt đầu sử dụng điểm cuối để tạo mã. Trong ví dụ sau, chúng tôi trình bày phản hồi từ cả biến thể Mã LIama 34B Python cơ bản và đã được tinh chỉnh trên mẫu thử nghiệm trong Bộ dữ liệu Dolphin Coder:
Mô hình Code Llama được tinh chỉnh, ngoài việc cung cấp mã cho truy vấn trước đó, còn tạo ra phần giải thích chi tiết về cách tiếp cận và mã giả.
Mã Llama 34b Python Phản hồi không tinh chỉnh:
Mã Llama 34B Python Phản hồi tinh chỉnh
Thực địa
Điều thú vị là phiên bản tinh chỉnh của Code Llama 34B Python của chúng tôi cung cấp giải pháp dựa trên lập trình động cho chuỗi con palindromic dài nhất, khác với giải pháp được cung cấp trong sự thật cơ bản từ ví dụ thử nghiệm đã chọn. Lý do mô hình được tinh chỉnh của chúng tôi và giải thích chi tiết giải pháp dựa trên lập trình động. Mặt khác, mô hình không tinh chỉnh sẽ gây ảo giác về kết quả đầu ra tiềm năng ngay sau khi print câu lệnh (hiển thị ở ô bên trái) vì đầu ra axyzzyx không phải là palindrome dài nhất trong chuỗi đã cho. Xét về độ phức tạp về thời gian, giải pháp lập trình động nhìn chung tốt hơn so với phương pháp ban đầu. Giải pháp lập trình động có độ phức tạp về thời gian là O(n^2), trong đó n là độ dài của chuỗi đầu vào. Điều này hiệu quả hơn giải pháp ban đầu từ mô hình không tinh chỉnh, cũng có độ phức tạp thời gian bậc hai là O(n^2) nhưng với cách tiếp cận kém tối ưu hơn.
Điều này có vẻ đầy hứa hẹn! Hãy nhớ rằng, chúng tôi chỉ tinh chỉnh biến thể Code LIama Python với 10% Bộ dữ liệu Dolphin Coder. Còn rất nhiều điều nữa để khám phá!
Mặc dù có hướng dẫn kỹ lưỡng trong phản hồi, chúng tôi vẫn cần kiểm tra tính chính xác của mã Python được cung cấp trong giải pháp. Tiếp theo, chúng tôi sử dụng một khung đánh giá được gọi là Đánh giá con người để chạy thử nghiệm tích hợp trên phản hồi được tạo từ Mã LIama nhằm kiểm tra chất lượng của nó một cách có hệ thống.
Đánh giá định lượng bằng HumanEval
HumanEval là một công cụ khai thác đánh giá để đánh giá khả năng giải quyết vấn đề của LLM đối với các vấn đề mã hóa dựa trên Python, như được mô tả trong bài báo Đánh giá các mô hình ngôn ngữ lớn được đào tạo về mã. Cụ thể, nó bao gồm 164 bài toán lập trình dựa trên Python gốc để đánh giá khả năng tạo mã của mô hình ngôn ngữ dựa trên thông tin được cung cấp như chữ ký hàm, chuỗi tài liệu, nội dung và kiểm tra đơn vị.
Đối với mỗi câu hỏi lập trình dựa trên Python, chúng tôi gửi câu hỏi đó đến mô hình Code LIama được triển khai trên điểm cuối SageMaker để nhận được k câu trả lời. Tiếp theo, chúng tôi chạy từng phản hồi trong số k phản hồi trong các thử nghiệm tích hợp trong kho lưu trữ HumanEval. Nếu bất kỳ phản hồi nào trong số k phản hồi vượt qua các bài kiểm tra tích hợp, chúng tôi coi trường hợp kiểm thử đó thành công; nếu không thì đã thất bại. Sau đó ta lặp lại quá trình tính tỷ lệ các trường hợp thành công là điểm đánh giá cuối cùng được đặt tên pass@k. Theo thông lệ tiêu chuẩn, chúng tôi đặt k là 1 trong đánh giá của mình để chỉ tạo một câu trả lời cho mỗi câu hỏi và kiểm tra xem nó có vượt qua bài kiểm tra tích hợp hay không.
Sau đây là mã mẫu để sử dụng kho HumanEval. Bạn có thể truy cập tập dữ liệu và tạo một phản hồi duy nhất bằng điểm cuối SageMaker. Để biết chi tiết, xem sổ ghi chép trong Kho GitHub.
Bảng sau đây cho thấy những cải tiến của các mô hình Code LIama Python được tinh chỉnh so với các mô hình không được tinh chỉnh ở các kích thước mô hình khác nhau. Để đảm bảo tính chính xác, chúng tôi cũng triển khai các mô hình Code LIama chưa được tinh chỉnh trong các điểm cuối của SageMaker và chạy qua các đánh giá Đánh giá con người. Các qua@1 các số (hàng đầu tiên trong bảng sau) khớp với các số được báo cáo trong Tài liệu nghiên cứu của Code Llama. Các tham số suy luận được đặt nhất quán là "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Như chúng ta có thể thấy từ kết quả, tất cả các biến thể Code LIama Python được tinh chỉnh đều cho thấy sự cải thiện đáng kể so với các mô hình không được tinh chỉnh. Đặc biệt, Code LIama Python 70B vượt trội hơn mô hình chưa tinh chỉnh khoảng 12%.
| . | Python 7B | Python 13B | 34B | Python 34B | Python 70B |
| Hiệu suất mô hình được đào tạo trước (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Hiệu suất mô hình được tinh chỉnh (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Bây giờ bạn có thể thử tinh chỉnh các mô hình Code LIama trên tập dữ liệu của riêng mình.
Làm sạch
Nếu bạn quyết định không muốn tiếp tục chạy điểm cuối SageMaker nữa, bạn có thể xóa nó bằng cách sử dụng AWS SDK cho Python (Boto3), Giao diện dòng lệnh AWS (AWS CLI) hoặc bảng điều khiển SageMaker. Để biết thêm thông tin, xem Xóa điểm cuối và tài nguyên. Ngoài ra, bạn có thể tắt tài nguyên SageMaker Studio điều đó không còn cần thiết nữa.
Kết luận
Trong bài đăng này, chúng tôi đã thảo luận về việc tinh chỉnh các mô hình Code Llama 2 của Meta bằng SageMaker JumpStart. Chúng tôi đã chỉ ra rằng bạn có thể sử dụng bảng điều khiển SageMaker JumpStart trong SageMaker Studio hoặc SageMaker Python SDK để tinh chỉnh và triển khai các mô hình này. Chúng tôi cũng thảo luận về kỹ thuật tinh chỉnh, loại phiên bản và siêu tham số được hỗ trợ. Ngoài ra, chúng tôi đã đưa ra các đề xuất để tối ưu hóa quá trình đào tạo dựa trên nhiều bài kiểm tra khác nhau mà chúng tôi đã thực hiện. Như chúng ta có thể thấy từ các kết quả tinh chỉnh ba mô hình trên hai tập dữ liệu, việc tinh chỉnh sẽ cải thiện khả năng tóm tắt so với các mô hình không tinh chỉnh. Bước tiếp theo, bạn có thể thử tinh chỉnh các mô hình này trên tập dữ liệu của riêng mình bằng cách sử dụng mã được cung cấp trong kho GitHub để kiểm tra và đánh giá kết quả cho các trường hợp sử dụng của bạn.
Về các tác giả
 Tiến sĩ Xin Huang là Nhà khoa học ứng dụng cấp cao cho Amazon SageMaker JumpStart và các thuật toán tích hợp sẵn của Amazon SageMaker. Anh ấy tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số. Ông đã xuất bản nhiều bài báo tại các hội nghị ACL, ICDM, KDD và Hiệp hội Thống kê Hoàng gia: Series A.
Tiến sĩ Xin Huang là Nhà khoa học ứng dụng cấp cao cho Amazon SageMaker JumpStart và các thuật toán tích hợp sẵn của Amazon SageMaker. Anh ấy tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số. Ông đã xuất bản nhiều bài báo tại các hội nghị ACL, ICDM, KDD và Hiệp hội Thống kê Hoàng gia: Series A.
 Vishaal Yalamanchali là Kiến trúc sư Giải pháp Khởi nghiệp làm việc với các công ty AI, robot và xe tự hành ở giai đoạn đầu. Vishaal làm việc với khách hàng của mình để cung cấp các giải pháp ML tiên tiến và cá nhân quan tâm đến việc học tăng cường, đánh giá LLM và tạo mã. Trước AWS, Vishaal là sinh viên đại học tại UCI, tập trung vào tin sinh học và hệ thống thông minh.
Vishaal Yalamanchali là Kiến trúc sư Giải pháp Khởi nghiệp làm việc với các công ty AI, robot và xe tự hành ở giai đoạn đầu. Vishaal làm việc với khách hàng của mình để cung cấp các giải pháp ML tiên tiến và cá nhân quan tâm đến việc học tăng cường, đánh giá LLM và tạo mã. Trước AWS, Vishaal là sinh viên đại học tại UCI, tập trung vào tin sinh học và hệ thống thông minh.
 Meenakshisundaram Thandavarayan làm việc cho AWS với tư cách là Chuyên gia AI/ML. Anh ấy có niềm đam mê thiết kế, sáng tạo và thúc đẩy trải nghiệm phân tích và dữ liệu lấy con người làm trung tâm. Meena tập trung phát triển các hệ thống bền vững mang lại lợi thế cạnh tranh có thể đo lường được cho khách hàng chiến lược của AWS. Meena là một nhà kết nối và nhà tư tưởng thiết kế, đồng thời nỗ lực thúc đẩy các doanh nghiệp tìm ra những cách làm việc mới thông qua đổi mới, ươm tạo và dân chủ hóa.
Meenakshisundaram Thandavarayan làm việc cho AWS với tư cách là Chuyên gia AI/ML. Anh ấy có niềm đam mê thiết kế, sáng tạo và thúc đẩy trải nghiệm phân tích và dữ liệu lấy con người làm trung tâm. Meena tập trung phát triển các hệ thống bền vững mang lại lợi thế cạnh tranh có thể đo lường được cho khách hàng chiến lược của AWS. Meena là một nhà kết nối và nhà tư tưởng thiết kế, đồng thời nỗ lực thúc đẩy các doanh nghiệp tìm ra những cách làm việc mới thông qua đổi mới, ươm tạo và dân chủ hóa.
 Tiến sĩ Ashish Khetan là Nhà khoa học ứng dụng cấp cao với các thuật toán tích hợp Amazon SageMaker và giúp phát triển các thuật toán máy học. Ông lấy bằng Tiến sĩ tại Đại học Illinois Urbana-Champaign. Ông là một nhà nghiên cứu tích cực về học máy và suy luận thống kê, đồng thời đã xuất bản nhiều bài báo tại các hội nghị NeurIPS, ICML, ICLR, JMLR, ACL và EMNLP.
Tiến sĩ Ashish Khetan là Nhà khoa học ứng dụng cấp cao với các thuật toán tích hợp Amazon SageMaker và giúp phát triển các thuật toán máy học. Ông lấy bằng Tiến sĩ tại Đại học Illinois Urbana-Champaign. Ông là một nhà nghiên cứu tích cực về học máy và suy luận thống kê, đồng thời đã xuất bản nhiều bài báo tại các hội nghị NeurIPS, ICML, ICLR, JMLR, ACL và EMNLP.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

