Dữ liệu không gian địa lý là dữ liệu về các vị trí cụ thể trên bề mặt trái đất. Nó có thể đại diện cho toàn bộ khu vực địa lý hoặc có thể đại diện cho một sự kiện liên quan đến một khu vực địa lý. Phân tích dữ liệu không gian địa lý được tìm kiếm trong một số ngành. Nó liên quan đến việc hiểu dữ liệu tồn tại ở đâu từ góc độ không gian và tại sao nó tồn tại ở đó.
Có hai loại dữ liệu không gian địa lý: dữ liệu vectơ và dữ liệu raster. Dữ liệu raster là một ma trận các ô được biểu diễn dưới dạng lưới, chủ yếu thể hiện các bức ảnh và hình ảnh vệ tinh. Trong bài đăng này, chúng tôi tập trung vào dữ liệu vectơ, được biểu thị dưới dạng tọa độ địa lý của vĩ độ và kinh độ cũng như các đường và đa giác (khu vực) kết nối hoặc bao quanh chúng. Dữ liệu vectơ có vô số trường hợp sử dụng trong việc rút ra những hiểu biết sâu sắc về di động. Dữ liệu di động của người dùng là một trong những thành phần như vậy và nó chủ yếu xuất phát từ vị trí địa lý của thiết bị di động sử dụng GPS hoặc nhà xuất bản ứng dụng sử dụng SDK hoặc tích hợp tương tự. Với mục đích của bài đăng này, chúng tôi gọi dữ liệu này là dữ liệu di động.
Đây là một loạt bài gồm hai phần. Trong bài đăng đầu tiên này, chúng tôi giới thiệu dữ liệu di động, nguồn của nó và sơ đồ điển hình của dữ liệu này. Sau đó, chúng tôi thảo luận về các trường hợp sử dụng khác nhau và khám phá cách bạn có thể sử dụng dịch vụ AWS để làm sạch dữ liệu, cách học máy (ML) có thể hỗ trợ nỗ lực này và cách bạn có thể sử dụng dữ liệu một cách có đạo đức trong việc tạo ra hình ảnh và thông tin chi tiết. Bài đăng thứ hai sẽ mang tính chất kỹ thuật hơn và trình bày chi tiết các bước này cùng với mã mẫu. Bài đăng này không có tập dữ liệu mẫu hoặc mã mẫu mà chỉ trình bày cách sử dụng dữ liệu sau khi được mua từ công cụ tổng hợp dữ liệu.
Bạn có thể sử dụng Khả năng không gian địa lý của Amazon SageMaker để phủ dữ liệu di động lên bản đồ cơ sở và cung cấp hình ảnh trực quan theo lớp để giúp việc cộng tác trở nên dễ dàng hơn. Trình hiển thị tương tác được hỗ trợ bởi GPU và sổ ghi chép Python cung cấp một cách liền mạch để khám phá hàng triệu điểm dữ liệu trong một cửa sổ duy nhất cũng như chia sẻ thông tin chi tiết và kết quả.
Nguồn và lược đồ
Có rất ít nguồn dữ liệu di động. Ngoài ping GPS và nhà xuất bản ứng dụng, các nguồn khác được sử dụng để tăng cường tập dữ liệu, chẳng hạn như điểm truy cập Wi-Fi, dữ liệu luồng giá thầu thu được thông qua việc phân phát quảng cáo trên thiết bị di động và các bộ phát phần cứng cụ thể do doanh nghiệp đặt (ví dụ: trong các cửa hàng thực tế). ). Các doanh nghiệp thường khó tự thu thập dữ liệu này nên họ có thể mua dữ liệu từ các công ty tổng hợp dữ liệu. Trình tổng hợp dữ liệu thu thập dữ liệu di động từ nhiều nguồn khác nhau, làm sạch dữ liệu, thêm tiếng ồn và cung cấp dữ liệu hàng ngày cho các khu vực địa lý cụ thể. Do tính chất của dữ liệu và vì khó thu thập nên độ chính xác và chất lượng của dữ liệu này có thể thay đổi đáng kể và doanh nghiệp phải đánh giá và xác minh điều này bằng cách sử dụng các số liệu như số người dùng hoạt động hàng ngày, tổng số ping hàng ngày, và số ping trung bình hàng ngày trên mỗi thiết bị. Bảng sau đây cho biết sơ đồ điển hình của nguồn cấp dữ liệu hàng ngày do các công cụ tổng hợp dữ liệu gửi có thể trông như thế nào.
| đặc tính | Mô tả |
| Id hoặc MAID | ID quảng cáo trên thiết bị di động (MAID) của thiết bị (được băm) |
| trễ | Vĩ độ của thiết bị |
| lng | Kinh độ của thiết bị |
| geohash | Vị trí Geohash của thiết bị |
| loại thiết bị | Hệ điều hành của thiết bị = IDFA hoặc GAID |
| ngang_chính xác | Độ chính xác của tọa độ GPS ngang (tính bằng mét) |
| dấu thời gian | Dấu thời gian của sự kiện |
| ip | Địa chỉ IP |
| alt | Độ cao của thiết bị (tính bằng mét) |
| tốc độ | Tốc độ của thiết bị (m/giây) |
| đất nước | Mã ISO hai chữ số của nước xuất xứ |
| nhà nước | Mã đại diện cho trạng thái |
| thành phố | Mã đại diện cho thành phố |
| Mã Bưu Chính | Mã zip nơi nhìn thấy ID thiết bị |
| nhà cung cấp dịch vụ | Nhà cung cấp thiết bị |
| nhà sản xuất thiết bị | Nhà sản xuất thiết bị |
Trường hợp sử dụng
Dữ liệu di động có ứng dụng rộng rãi trong nhiều ngành công nghiệp khác nhau. Sau đây là một số trường hợp sử dụng phổ biến nhất:
- Số liệu mật độ – Phân tích lưu lượng người đi bộ có thể được kết hợp với mật độ dân số để quan sát các hoạt động và lượt ghé thăm các điểm ưa thích (POI). Các số liệu này trình bày bức tranh về số lượng thiết bị hoặc người dùng đang tích cực dừng lại và tương tác với một doanh nghiệp, số liệu này có thể được sử dụng thêm để lựa chọn địa điểm hoặc thậm chí phân tích các mô hình chuyển động xung quanh một sự kiện (ví dụ: những người đi du lịch trong một ngày thi đấu). Để có được những hiểu biết sâu sắc như vậy, dữ liệu thô đến sẽ trải qua quá trình trích xuất, chuyển đổi và tải (ETL) để xác định các hoạt động hoặc hoạt động tương tác từ luồng ping vị trí thiết bị liên tục. Chúng tôi có thể phân tích các hoạt động bằng cách xác định các điểm dừng do người dùng hoặc thiết bị di động thực hiện bằng cách phân cụm các ping bằng mô hình ML trong Amazon SageMaker.
- Những chuyến đi và quỹ đạo – Nguồn cấp dữ liệu vị trí hàng ngày của thiết bị có thể được biểu thị dưới dạng tập hợp các hoạt động (điểm dừng) và chuyến đi (chuyển động). Một cặp hoạt động có thể đại diện cho một chuyến đi giữa chúng và việc theo dõi chuyến đi bằng thiết bị di chuyển trong không gian địa lý có thể dẫn đến việc lập bản đồ quỹ đạo thực tế. Mô hình quỹ đạo di chuyển của người dùng có thể dẫn đến những hiểu biết thú vị như mô hình giao thông, mức tiêu thụ nhiên liệu, quy hoạch thành phố, v.v. Nó cũng có thể cung cấp dữ liệu để phân tích tuyến đường lấy từ các điểm quảng cáo như bảng quảng cáo, xác định các tuyến giao hàng hiệu quả nhất để tối ưu hóa hoạt động của chuỗi cung ứng hoặc phân tích các tuyến đường sơ tán trong thiên tai (ví dụ: sơ tán do bão).
- Phân tích diện tích lưu vực - A vùng có nước mưa rơi xuống đề cập đến những địa điểm mà một khu vực nhất định thu hút du khách, họ có thể là khách hàng hoặc khách hàng tiềm năng. Các doanh nghiệp bán lẻ có thể sử dụng thông tin này để xác định vị trí tối ưu để mở một cửa hàng mới hoặc xác định xem hai vị trí cửa hàng có quá gần nhau với diện tích lưu vực chồng chéo và đang cản trở hoạt động kinh doanh của nhau hay không. Họ cũng có thể tìm hiểu khách hàng thực tế đến từ đâu, xác định khách hàng tiềm năng đi ngang qua khu vực để đi làm hoặc về nhà, phân tích các số liệu ghé thăm tương tự của đối thủ cạnh tranh, v.v. Các công ty Công nghệ tiếp thị (MarTech) và Công nghệ quảng cáo (AdTech) cũng có thể sử dụng phân tích này để tối ưu hóa các chiến dịch tiếp thị bằng cách xác định đối tượng ở gần cửa hàng của thương hiệu hoặc xếp hạng các cửa hàng theo hiệu suất cho quảng cáo ngoài trời.
Có một số trường hợp sử dụng khác, bao gồm tạo thông tin vị trí thông minh cho bất động sản thương mại, tăng cường dữ liệu hình ảnh vệ tinh với số lượng khách đến, xác định trung tâm giao hàng cho nhà hàng, xác định khả năng sơ tán khu vực lân cận, khám phá mô hình di chuyển của mọi người trong thời kỳ đại dịch, v.v.
Những thách thức và sử dụng có đạo đức
Việc sử dụng dữ liệu di động một cách có đạo đức có thể mang lại nhiều hiểu biết thú vị có thể giúp các tổ chức cải thiện hoạt động, thực hiện tiếp thị hiệu quả hoặc thậm chí đạt được lợi thế cạnh tranh. Để sử dụng dữ liệu này một cách có đạo đức, cần phải tuân theo một số bước.
Nó bắt đầu với việc thu thập dữ liệu. Mặc dù hầu hết dữ liệu di động vẫn không có thông tin nhận dạng cá nhân (PII) như tên và địa chỉ, nhưng người thu thập và tổng hợp dữ liệu phải có sự đồng ý của người dùng để thu thập, sử dụng, lưu trữ và chia sẻ dữ liệu của họ. Cần phải tuân thủ các luật về quyền riêng tư dữ liệu như GDPR và CCPA vì chúng trao quyền cho người dùng xác định cách doanh nghiệp có thể sử dụng dữ liệu của họ. Bước đầu tiên này là một bước tiến đáng kể hướng tới việc sử dụng dữ liệu di động có đạo đức và có trách nhiệm, nhưng vẫn còn có thể làm được nhiều việc hơn nữa.
Mỗi thiết bị được gán một ID quảng cáo di động (MAID) đã băm, được sử dụng để neo các ping riêng lẻ. Điều này có thể được làm xáo trộn hơn nữa bằng cách sử dụng Macie Amazon, Đối tượng Amazon S3 Lambda, Amazon hiểu, hoặc thậm chí Xưởng keo AWS Phát hiện biến đổi PII. Để biết thêm thông tin, hãy tham khảo Các kỹ thuật phổ biến để phát hiện dữ liệu PHI và PII bằng Dịch vụ AWS.
Ngoài PII, cần cân nhắc việc che giấu vị trí nhà của người dùng cũng như các vị trí nhạy cảm khác như căn cứ quân sự hoặc nơi thờ cúng.
Bước cuối cùng để sử dụng có đạo đức là chỉ lấy và xuất các số liệu tổng hợp ra khỏi Amazon SageMaker. Điều này có nghĩa là lấy các số liệu như số lượng trung bình hoặc tổng số khách truy cập thay vì các mô hình du lịch riêng lẻ; nhận được xu hướng hàng ngày, hàng tuần, hàng tháng hoặc hàng năm; hoặc lập chỉ mục các hoạt động di chuyển dựa trên dữ liệu có sẵn công khai, chẳng hạn như dữ liệu điều tra dân số.
Tổng quan về giải pháp
Như đã đề cập trước đó, các dịch vụ AWS mà bạn có thể sử dụng để phân tích dữ liệu di động là Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend và khả năng không gian địa lý của Amazon SageMaker. Khả năng không gian địa lý của Amazon SageMaker giúp các nhà khoa học dữ liệu và kỹ sư ML dễ dàng xây dựng, đào tạo và triển khai các mô hình bằng cách sử dụng dữ liệu không gian địa lý. Bạn có thể chuyển đổi hoặc làm phong phú các bộ dữ liệu không gian địa lý quy mô lớn một cách hiệu quả, tăng tốc xây dựng mô hình bằng các mô hình ML được đào tạo trước và khám phá các dự đoán mô hình cũng như dữ liệu không gian địa lý trên bản đồ tương tác bằng đồ họa tăng tốc 3D và các công cụ trực quan tích hợp.
Kiến trúc tham chiếu sau đây mô tả quy trình làm việc sử dụng ML với dữ liệu không gian địa lý.
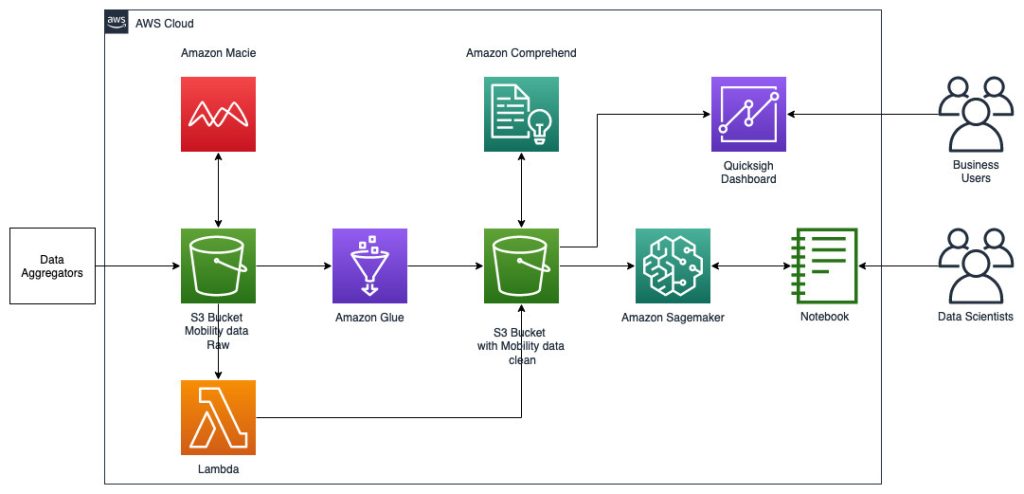
Trong quy trình làm việc này, dữ liệu thô được tổng hợp từ nhiều nguồn dữ liệu khác nhau và được lưu trữ trong một Dịch vụ lưu trữ đơn giản của Amazon (S3) xô. Amazon Macie được sử dụng trên bộ chứa S3 này để xác định, sắp xếp lại và PII. Sau đó, AWS Glue được sử dụng để làm sạch và chuyển đổi dữ liệu thô sang định dạng được yêu cầu, sau đó dữ liệu đã sửa đổi và làm sạch sẽ được lưu trữ trong một bộ chứa S3 riêng biệt. Đối với những chuyển đổi dữ liệu không thể thực hiện được thông qua AWS Glue, bạn sử dụng AWS Lambda để sửa đổi và làm sạch dữ liệu thô. Khi dữ liệu được làm sạch, bạn có thể sử dụng Amazon SageMaker để xây dựng, huấn luyện và triển khai các mô hình ML trên dữ liệu không gian địa lý được chuẩn bị sẵn. Bạn cũng có thể sử dụng Việc làm xử lý không gian địa lý tính năng không gian địa lý của Amazon SageMaker để xử lý trước dữ liệu—ví dụ: sử dụng hàm Python và câu lệnh SQL để xác định các hoạt động từ dữ liệu di động thô. Các nhà khoa học dữ liệu có thể thực hiện quá trình này bằng cách kết nối thông qua sổ ghi chép Amazon SageMaker. Bạn cũng có thể dùng Amazon QuickSight để trực quan hóa kết quả kinh doanh và các số liệu quan trọng khác từ dữ liệu.
Khả năng không gian địa lý của Amazon SageMaker và công việc Xử lý không gian địa lý
Sau khi dữ liệu được lấy và đưa vào Amazon S3 bằng nguồn cấp dữ liệu hàng ngày cũng như được làm sạch để loại bỏ mọi dữ liệu nhạy cảm, dữ liệu đó có thể được nhập vào Amazon SageMaker bằng cách sử dụng một Xưởng sản xuất Amazon SageMaker sổ ghi chép có hình ảnh không gian địa lý. Ảnh chụp màn hình sau đây hiển thị mẫu ping thiết bị hàng ngày được tải lên Amazon S3 dưới dạng tệp CSV, sau đó được tải vào khung dữ liệu gấu trúc. Sổ ghi chép Amazon SageMaker Studio với hình ảnh không gian địa lý được tải sẵn các thư viện không gian địa lý như GDAL, GeoPandas, Fiona và Shapely, đồng thời giúp việc xử lý và phân tích dữ liệu này trở nên đơn giản.
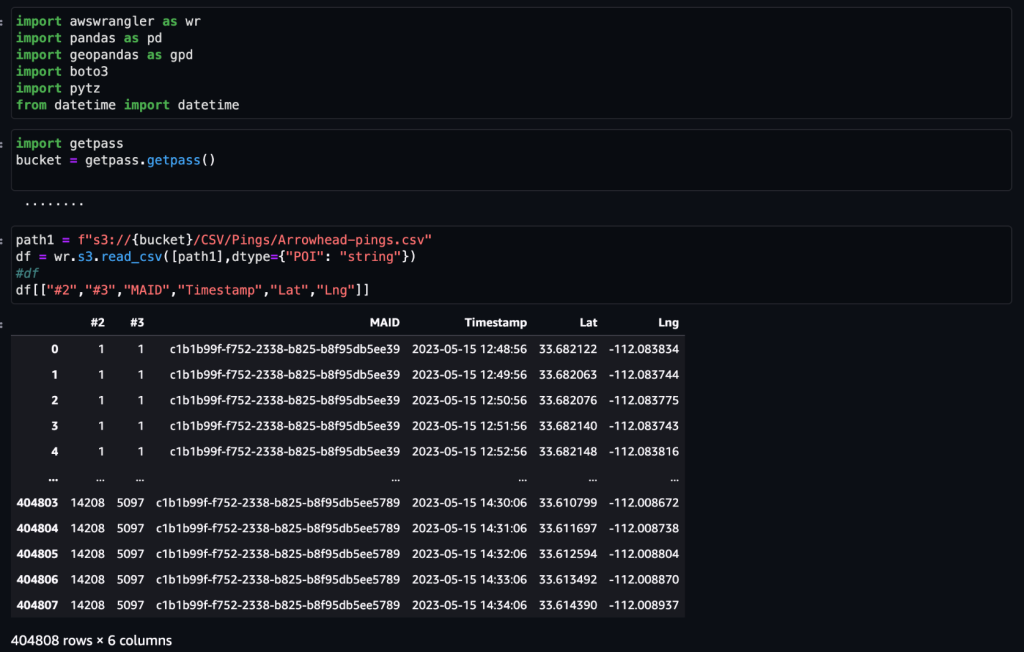
Tập dữ liệu mẫu này chứa khoảng 400,000 ping thiết bị hàng ngày từ 5,000 thiết bị từ 14,000 địa điểm riêng biệt được ghi lại từ những người dùng ghé thăm Arrowhead Mall, một khu phức hợp trung tâm mua sắm nổi tiếng ở Phoenix, Arizona, vào ngày 15 tháng 2023 năm XNUMX. Ảnh chụp màn hình trước đó hiển thị một tập hợp con các cột trong lược đồ dữ liệu. Các MAID cột biểu thị ID thiết bị và mỗi MAID tạo ping mỗi phút để chuyển tiếp vĩ độ và kinh độ của thiết bị, được ghi trong tệp mẫu dưới dạng Lat và Lng cột.
Sau đây là ảnh chụp màn hình từ công cụ trực quan hóa bản đồ về khả năng không gian địa lý của Amazon SageMaker do Foursquare Studio cung cấp, mô tả bố cục của ping từ các thiết bị ghé thăm trung tâm mua sắm trong khoảng thời gian từ 7:00 sáng đến 6:00 chiều.
Ảnh chụp màn hình sau đây hiển thị các ping từ trung tâm mua sắm và các khu vực xung quanh.

Phần sau đây hiển thị các tín hiệu ping từ bên trong nhiều cửa hàng khác nhau trong trung tâm mua sắm.
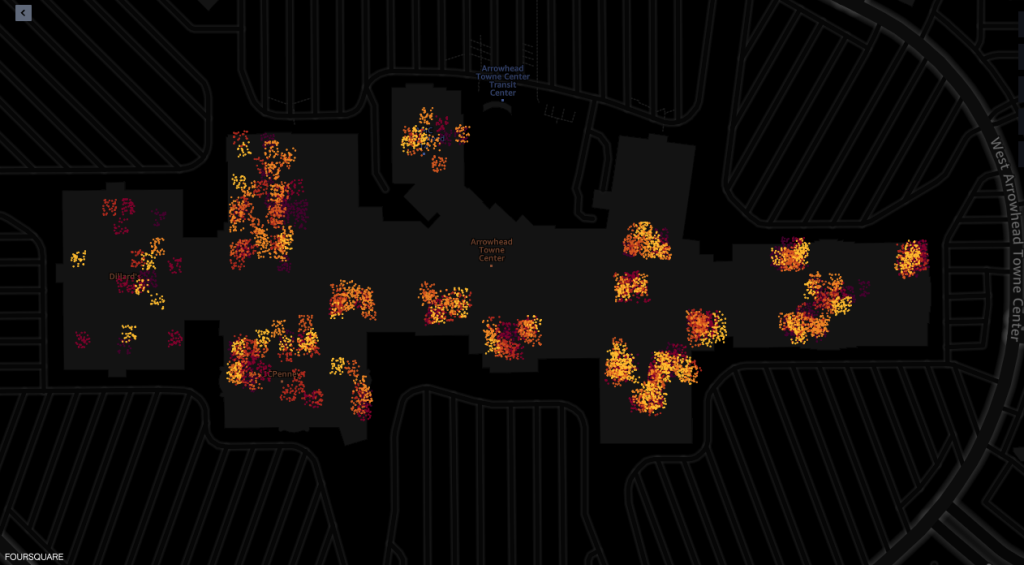
Mỗi dấu chấm trong ảnh chụp màn hình mô tả một ping từ một thiết bị nhất định tại một thời điểm nhất định. Một cụm ping biểu thị các địa điểm phổ biến nơi các thiết bị tập trung hoặc dừng lại, chẳng hạn như cửa hàng hoặc nhà hàng.
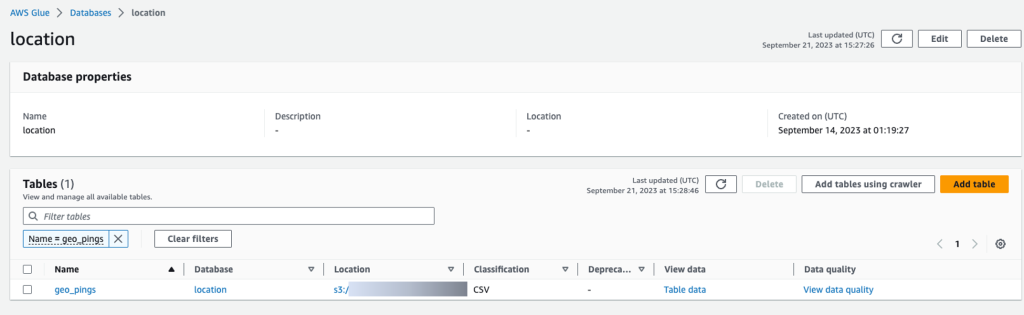
Là một phần của ETL ban đầu, dữ liệu thô này có thể được tải lên các bảng bằng AWS Glue. Bạn có thể tạo trình thu thập thông tin AWS Glue để xác định sơ đồ của bảng dữ liệu và biểu mẫu bằng cách trỏ tới vị trí dữ liệu thô trong Amazon S3 làm nguồn dữ liệu.

Như đã đề cập ở trên, dữ liệu thô (ping thiết bị hàng ngày), ngay cả sau ETL ban đầu, sẽ biểu thị một luồng ping GPS liên tục cho biết vị trí thiết bị. Để trích xuất những hiểu biết sâu sắc có thể hành động từ dữ liệu này, chúng tôi cần xác định các điểm dừng và chuyến đi (quỹ đạo). Điều này có thể đạt được bằng cách sử dụng Việc làm xử lý không gian địa lý tính năng của khả năng không gian địa lý của SageMaker. Chế biến Amazon SageMaker sử dụng trải nghiệm được quản lý, đơn giản hóa trên SageMaker để chạy khối lượng công việc xử lý dữ liệu với vùng chứa không gian địa lý được xây dựng có mục đích. Cơ sở hạ tầng cơ bản cho công việc Xử lý SageMaker được quản lý hoàn toàn bởi SageMaker. Tính năng này cho phép mã tùy chỉnh chạy trên dữ liệu không gian địa lý được lưu trữ trên Amazon S3 bằng cách chạy bộ chứa ML không gian địa lý trong công việc Xử lý SageMaker. Bạn có thể chạy các thao tác tùy chỉnh trên dữ liệu không gian địa lý mở hoặc riêng tư bằng cách viết mã tùy chỉnh bằng các thư viện nguồn mở và chạy thao tác trên quy mô lớn bằng cách sử dụng các công việc Xử lý SageMaker. Cách tiếp cận dựa trên container giải quyết các nhu cầu xung quanh việc tiêu chuẩn hóa môi trường phát triển với các thư viện nguồn mở được sử dụng phổ biến.
Để chạy khối lượng công việc quy mô lớn như vậy, bạn cần một cụm điện toán linh hoạt có thể mở rộng quy mô từ hàng chục phiên bản để xử lý một khối thành phố đến hàng nghìn phiên bản để xử lý ở quy mô hành tinh. Việc quản lý thủ công cụm điện toán DIY rất chậm và tốn kém. Tính năng này đặc biệt hữu ích khi tập dữ liệu di động liên quan đến nhiều thành phố đến nhiều tiểu bang hoặc thậm chí quốc gia và có thể được sử dụng để chạy phương pháp ML hai bước.
Bước đầu tiên là sử dụng phân cụm không gian dựa trên mật độ của các ứng dụng có thuật toán nhiễu (DBSCAN) để phân cụm các điểm dừng từ ping. Bước tiếp theo là sử dụng phương pháp máy vectơ hỗ trợ (SVM) để cải thiện hơn nữa độ chính xác của các điểm dừng đã xác định và cũng để phân biệt các điểm dừng có tương tác với POI so với các điểm dừng không có (chẳng hạn như ở nhà hoặc cơ quan). Bạn cũng có thể sử dụng công việc Xử lý SageMaker để tạo các chuyến đi và quỹ đạo từ các ping thiết bị hàng ngày bằng cách xác định các điểm dừng liên tiếp và ánh xạ đường đi giữa các điểm dừng nguồn và đích.
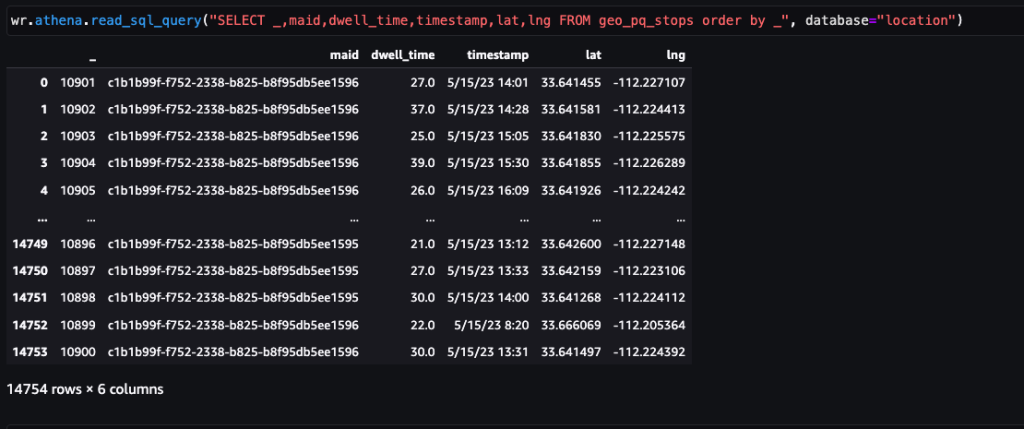
Sau khi xử lý dữ liệu thô (ping thiết bị hàng ngày) trên quy mô lớn với các công việc Xử lý không gian địa lý, tập dữ liệu mới có tên là điểm dừng sẽ có lược đồ sau.
| đặc tính | Mô tả |
| Id hoặc MAID | ID quảng cáo trên thiết bị di động của thiết bị (được băm) |
| trễ | Vĩ độ tâm của cụm dừng |
| lng | Kinh độ tâm của cụm dừng |
| geohash | Vị trí Geohash của POI |
| loại thiết bị | Hệ điều hành của thiết bị (IDFA hoặc GAID) |
| dấu thời gian | Thời điểm bắt đầu điểm dừng |
| thời gian chờ | Thời gian dừng của điểm dừng (tính bằng giây) |
| ip | Địa chỉ IP |
| alt | Độ cao của thiết bị (tính bằng mét) |
| đất nước | Mã ISO hai chữ số của nước xuất xứ |
| nhà nước | Mã đại diện cho trạng thái |
| thành phố | Mã đại diện cho thành phố |
| Mã Bưu Chính | Mã zip nơi nhìn thấy ID thiết bị |
| nhà cung cấp dịch vụ | Nhà cung cấp thiết bị |
| nhà sản xuất thiết bị | Nhà sản xuất thiết bị |
Các điểm dừng được hợp nhất bằng cách nhóm các ping trên mỗi thiết bị. Phân cụm dựa trên mật độ được kết hợp với các tham số như ngưỡng dừng là 300 giây và khoảng cách tối thiểu giữa các điểm dừng là 50 mét. Các thông số này có thể được điều chỉnh theo trường hợp sử dụng của bạn.
Ảnh chụp màn hình sau đây hiển thị khoảng 15,000 điểm dừng được xác định từ 400,000 ping. Một tập hợp con của lược đồ trước đó cũng xuất hiện, trong đó cột Dwell Time đại diện cho thời gian dừng và Lat và Lng các cột biểu thị vĩ độ và kinh độ của tâm của cụm điểm dừng trên mỗi thiết bị trên mỗi vị trí.
Hậu ETL, dữ liệu được lưu trữ ở định dạng tệp Parquet, đây là định dạng lưu trữ theo cột giúp xử lý lượng lớn dữ liệu dễ dàng hơn.
Ảnh chụp màn hình sau đây hiển thị các điểm dừng được tổng hợp từ ping trên mỗi thiết bị bên trong trung tâm mua sắm và các khu vực xung quanh.

Sau khi xác định các điểm dừng, tập dữ liệu này có thể được kết hợp với dữ liệu POI có sẵn công khai hoặc dữ liệu POI tùy chỉnh cụ thể cho trường hợp sử dụng để xác định các hoạt động, chẳng hạn như tương tác với thương hiệu.
Ảnh chụp màn hình sau đây hiển thị các điểm dừng được xác định tại POI (cửa hàng và thương hiệu) chính bên trong Trung tâm thương mại Arrowhead.
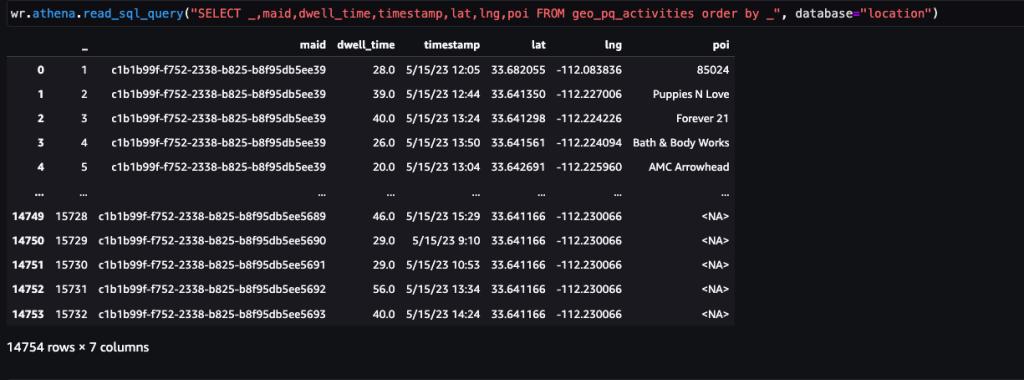
Mã zip tại nhà đã được sử dụng để che giấu vị trí nhà của mỗi khách truy cập nhằm duy trì quyền riêng tư trong trường hợp đó là một phần trong chuyến đi của họ trong tập dữ liệu. Vĩ độ và kinh độ trong những trường hợp như vậy là tọa độ tương ứng của tâm của mã zip.
Ảnh chụp màn hình sau đây là hình ảnh minh họa trực quan về các hoạt động đó. Hình ảnh bên trái ánh xạ các điểm dừng tới các cửa hàng và hình ảnh bên phải đưa ra ý tưởng về cách bố trí của chính trung tâm mua sắm.

Tập dữ liệu kết quả này có thể được hiển thị theo một số cách mà chúng tôi sẽ thảo luận trong các phần sau.
Số liệu mật độ
Chúng ta có thể tính toán và hình dung mật độ hoạt động và lượt ghé thăm.
Ví dụ 1 – Ảnh chụp màn hình sau đây hiển thị 15 cửa hàng được ghé thăm nhiều nhất trong trung tâm thương mại.

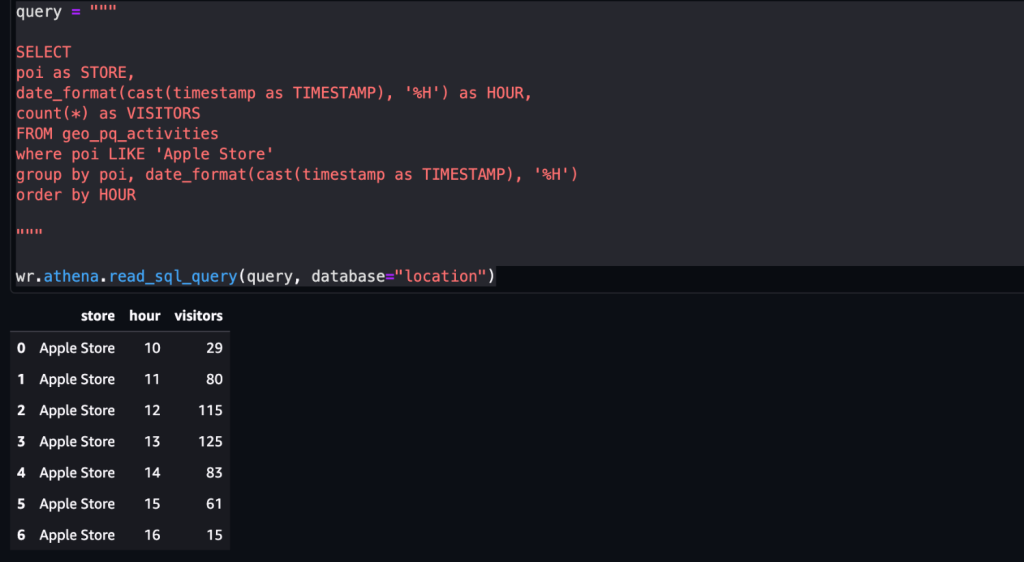
Ví dụ 2 – Ảnh chụp màn hình sau hiển thị số lượt truy cập vào Apple Store mỗi giờ.
Những chuyến đi và quỹ đạo
Như đã đề cập trước đó, một cặp hoạt động liên tiếp tượng trưng cho một chuyến đi. Chúng ta có thể sử dụng phương pháp sau để rút ra các chuyến đi từ dữ liệu hoạt động. Ở đây, các hàm cửa sổ được sử dụng với SQL để tạo ra trips bảng, như được hiển thị trong ảnh chụp màn hình.
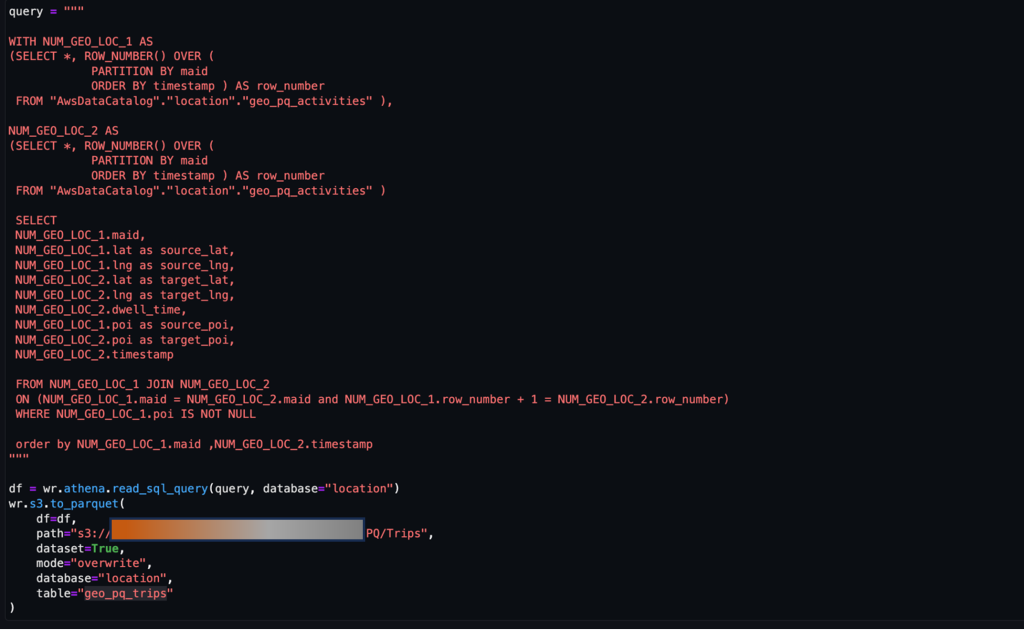
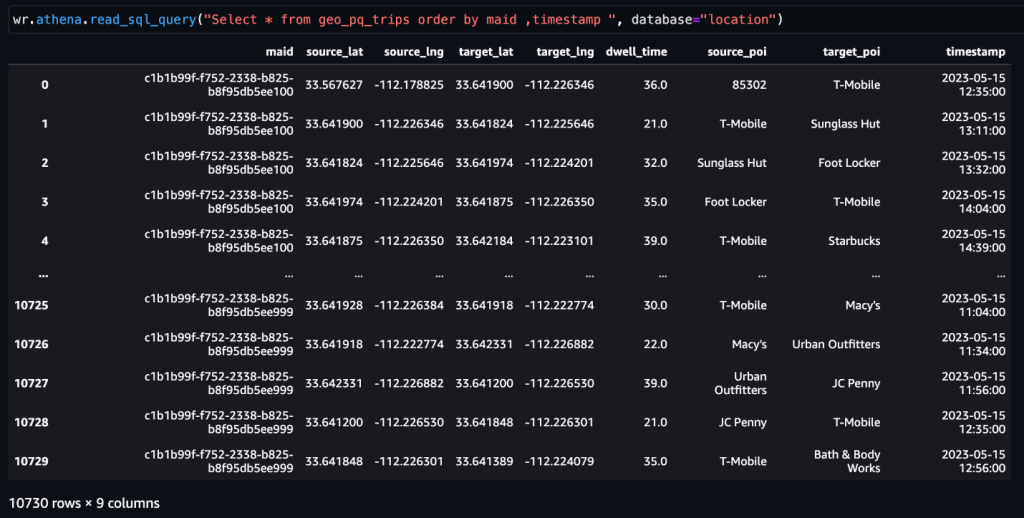
Sau trips bảng được tạo, các chuyến đi tới POI có thể được xác định.
Ví dụ 1 - Ảnh chụp màn hình sau đây hiển thị 10 cửa hàng hàng đầu hướng lượng người ghé thăm Apple Store.

Ví dụ 2 – Ảnh chụp màn hình sau đây hiển thị tất cả các chuyến đi đến Trung tâm thương mại Arrowhead.

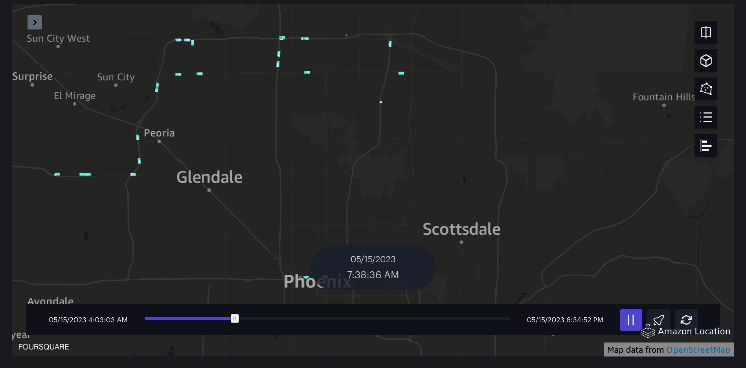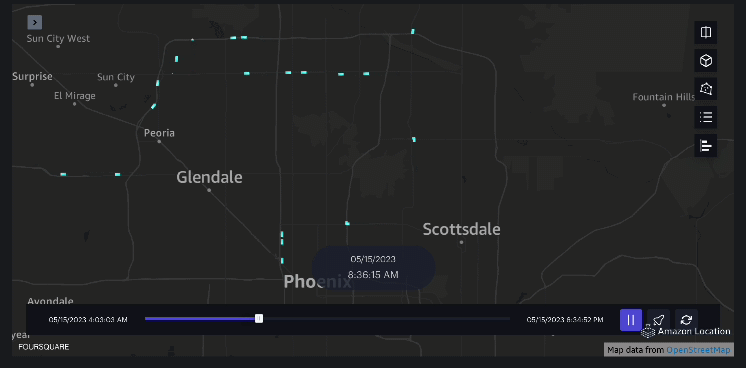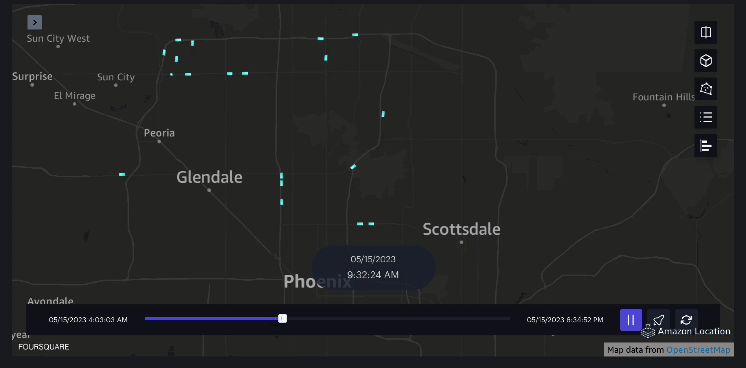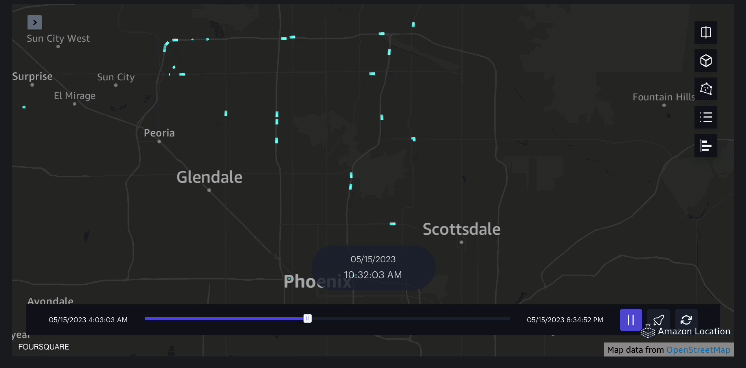
Ví dụ 3 – Video sau đây trình bày các kiểu chuyển động bên trong trung tâm thương mại.

Ví dụ 4 – Video sau đây cho thấy các kiểu di chuyển bên ngoài trung tâm thương mại.
Phân tích diện tích lưu vực
Chúng tôi có thể phân tích tất cả các lượt truy cập vào POI và xác định khu vực lưu vực.
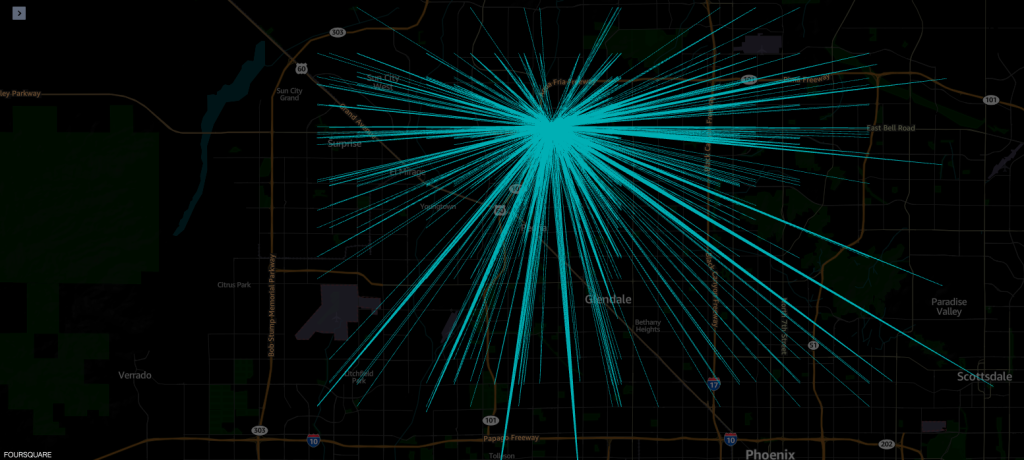
Ví dụ 1 - Ảnh chụp màn hình sau đây hiển thị tất cả các lượt ghé thăm cửa hàng Macy.
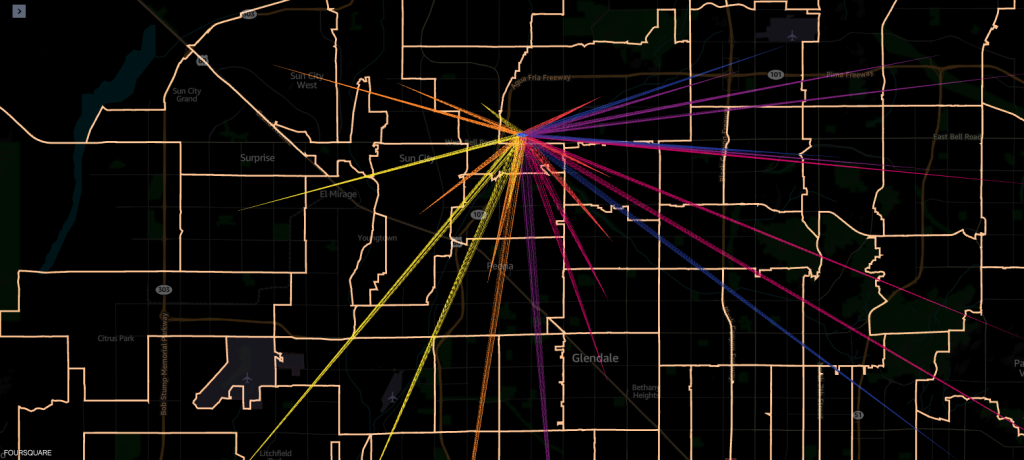
Ví dụ 2 – Ảnh chụp màn hình sau đây hiển thị 10 mã zip khu vực nhà hàng đầu (ranh giới được đánh dấu) từ nơi xảy ra các chuyến thăm.
Kiểm tra chất lượng dữ liệu
Chúng tôi có thể kiểm tra chất lượng của nguồn cấp dữ liệu đến hàng ngày và phát hiện các điểm bất thường bằng cách sử dụng bảng điều khiển QuickSight và phân tích dữ liệu. Ảnh chụp màn hình sau đây hiển thị một bảng thông tin mẫu.
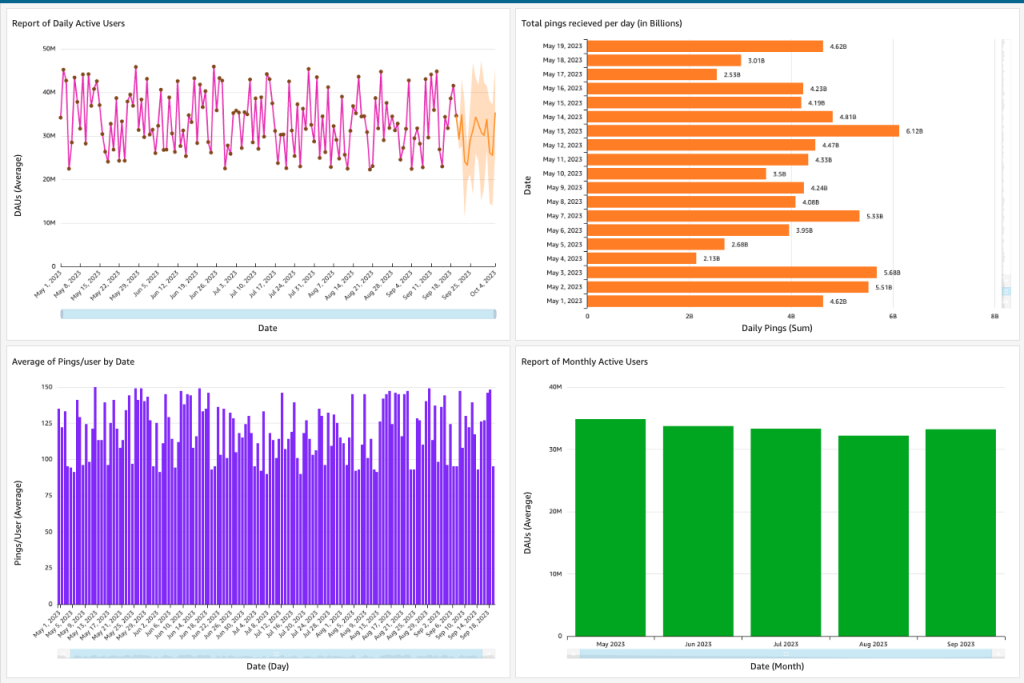
Kết luận
Dữ liệu di động và phân tích của nó để hiểu rõ hơn về khách hàng và đạt được lợi thế cạnh tranh vẫn là một lĩnh vực thích hợp vì rất khó để có được bộ dữ liệu nhất quán và chính xác. Tuy nhiên, dữ liệu này có thể giúp các tổ chức thêm bối cảnh vào phân tích hiện có và thậm chí tạo ra những hiểu biết mới về mô hình chuyển động của khách hàng. Khả năng không gian địa lý và công việc Xử lý không gian địa lý của Amazon SageMaker có thể giúp triển khai các trường hợp sử dụng này và rút ra thông tin chuyên sâu theo cách trực quan và dễ tiếp cận.
Trong bài đăng này, chúng tôi đã trình bày cách sử dụng dịch vụ AWS để làm sạch dữ liệu di động, sau đó sử dụng khả năng không gian địa lý của Amazon SageMaker để tạo các tập dữ liệu phái sinh như điểm dừng, hoạt động và chuyến đi bằng mô hình ML. Sau đó, chúng tôi sử dụng bộ dữ liệu phái sinh để trực quan hóa các mô hình chuyển động và tạo ra thông tin chi tiết.
Bạn có thể bắt đầu với khả năng không gian địa lý của Amazon SageMaker theo hai cách:
Để tìm hiểu thêm, hãy truy cập Khả năng không gian địa lý của Amazon SageMaker và Bắt đầu với không gian địa lý của Amazon SageMaker. Ngoài ra, hãy truy cập của chúng tôi Repo GitHub, trong đó có một số sổ ghi chép mẫu về khả năng không gian địa lý của Amazon SageMaker.
Về các tác giả
 Jim Matthews là Kiến trúc sư giải pháp AWS, có chuyên môn về công nghệ AI/ML. Jimy có trụ sở tại Boston và làm việc với các khách hàng doanh nghiệp khi họ chuyển đổi hoạt động kinh doanh bằng cách áp dụng đám mây và giúp họ xây dựng các giải pháp hiệu quả và bền vững. Anh ấy đam mê gia đình, xe hơi và võ thuật tổng hợp.
Jim Matthews là Kiến trúc sư giải pháp AWS, có chuyên môn về công nghệ AI/ML. Jimy có trụ sở tại Boston và làm việc với các khách hàng doanh nghiệp khi họ chuyển đổi hoạt động kinh doanh bằng cách áp dụng đám mây và giúp họ xây dựng các giải pháp hiệu quả và bền vững. Anh ấy đam mê gia đình, xe hơi và võ thuật tổng hợp.
 Girish Keshav là Kiến trúc sư giải pháp tại AWS, hỗ trợ khách hàng trong hành trình di chuyển sang đám mây nhằm hiện đại hóa và chạy khối lượng công việc một cách an toàn và hiệu quả. Anh làm việc với các nhà lãnh đạo nhóm công nghệ để hướng dẫn họ về bảo mật ứng dụng, học máy, tối ưu hóa chi phí và tính bền vững. Anh ấy sống ở San Francisco và thích đi du lịch, đi bộ đường dài, xem thể thao và khám phá các nhà máy bia thủ công.
Girish Keshav là Kiến trúc sư giải pháp tại AWS, hỗ trợ khách hàng trong hành trình di chuyển sang đám mây nhằm hiện đại hóa và chạy khối lượng công việc một cách an toàn và hiệu quả. Anh làm việc với các nhà lãnh đạo nhóm công nghệ để hướng dẫn họ về bảo mật ứng dụng, học máy, tối ưu hóa chi phí và tính bền vững. Anh ấy sống ở San Francisco và thích đi du lịch, đi bộ đường dài, xem thể thao và khám phá các nhà máy bia thủ công.
 Cầu tàu Ramesh là Lãnh đạo cấp cao của Kiến trúc giải pháp tập trung vào việc giúp khách hàng doanh nghiệp AWS kiếm tiền từ tài sản dữ liệu của họ. Ông tư vấn cho các giám đốc điều hành và kỹ sư thiết kế và xây dựng các giải pháp đám mây có khả năng mở rộng cao, đáng tin cậy và tiết kiệm chi phí, đặc biệt tập trung vào học máy, dữ liệu và phân tích. Trong thời gian rảnh rỗi, anh ấy tận hưởng những hoạt động ngoài trời tuyệt vời, đạp xe và đi bộ đường dài cùng gia đình.
Cầu tàu Ramesh là Lãnh đạo cấp cao của Kiến trúc giải pháp tập trung vào việc giúp khách hàng doanh nghiệp AWS kiếm tiền từ tài sản dữ liệu của họ. Ông tư vấn cho các giám đốc điều hành và kỹ sư thiết kế và xây dựng các giải pháp đám mây có khả năng mở rộng cao, đáng tin cậy và tiết kiệm chi phí, đặc biệt tập trung vào học máy, dữ liệu và phân tích. Trong thời gian rảnh rỗi, anh ấy tận hưởng những hoạt động ngoài trời tuyệt vời, đạp xe và đi bộ đường dài cùng gia đình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/

