Bài đăng trên blog này được đồng viết với Chaoyang He và Salman Avestimehr từ FedML.
Phân tích dữ liệu khoa học đời sống và chăm sóc sức khỏe trong thế giới thực (HCLS) đặt ra một số thách thức thực tế, chẳng hạn như kho dữ liệu phân tán, thiếu dữ liệu đầy đủ tại bất kỳ trang web nào cho các sự kiện hiếm gặp, hướng dẫn quy định cấm chia sẻ dữ liệu, yêu cầu cơ sở hạ tầng và chi phí phát sinh khi tạo một kho lưu trữ dữ liệu tập trung. Bởi vì họ đang ở trong một miền được quản lý chặt chẽ, các đối tác và khách hàng của HCLS tìm kiếm các cơ chế bảo vệ quyền riêng tư để quản lý và phân tích dữ liệu nhạy cảm, phân tán và quy mô lớn.
Để giảm thiểu những thách thức này, chúng tôi đề xuất sử dụng khung học tập liên kết (FL) mã nguồn mở được gọi là FedML, cho phép bạn phân tích dữ liệu HCLS nhạy cảm bằng cách huấn luyện mô hình máy học toàn cầu từ dữ liệu phân tán được lưu trữ cục bộ tại các địa điểm khác nhau. FL không yêu cầu di chuyển hoặc chia sẻ dữ liệu giữa các trang web hoặc với máy chủ tập trung trong quá trình đào tạo mô hình.
Trong loạt bài gồm hai phần này, chúng tôi trình bày cách bạn có thể triển khai khung FL dựa trên đám mây trên AWS. Trong bài đăng đầu tiên, chúng tôi đã mô tả các khái niệm FL và khuôn khổ FedML. bên trong bài đăng thứ hai, chúng tôi trình bày các trường hợp sử dụng và bộ dữ liệu để cho thấy tính hiệu quả của nó trong việc phân tích các bộ dữ liệu chăm sóc sức khỏe trong thế giới thực, chẳng hạn như dữ liệu eICU, bao gồm cơ sở dữ liệu chăm sóc tích cực đa trung tâm được thu thập từ hơn 200 bệnh viện.
Tiểu sử
Mặc dù khối lượng dữ liệu do HCLS tạo ra chưa bao giờ lớn hơn, nhưng những thách thức và hạn chế liên quan đến việc truy cập dữ liệu đó sẽ hạn chế tiện ích của nó cho nghiên cứu trong tương lai. Học máy (ML) mang đến cơ hội giải quyết một số mối quan tâm này và đang được áp dụng để nâng cao phân tích dữ liệu và rút ra những hiểu biết có ý nghĩa từ dữ liệu HCLS đa dạng cho các trường hợp sử dụng như cung cấp dịch vụ chăm sóc, hỗ trợ quyết định lâm sàng, thuốc chính xác, phân loại và chẩn đoán cũng như bệnh mãn tính quản lý chăm sóc. Do các thuật toán ML thường không đủ để bảo vệ quyền riêng tư của dữ liệu ở cấp độ bệnh nhân, nên các đối tác và khách hàng của HCLS ngày càng quan tâm đến việc sử dụng các cơ chế và cơ sở hạ tầng bảo vệ quyền riêng tư để quản lý và phân tích dữ liệu nhạy cảm, phân tán và quy mô lớn. [1]
Chúng tôi đã phát triển một khung FL trên AWS cho phép phân tích dữ liệu sức khỏe nhạy cảm và phân tán theo cách bảo vệ quyền riêng tư. Nó liên quan đến việc đào tạo một mô hình ML dùng chung mà không cần di chuyển hoặc chia sẻ dữ liệu giữa các trang web hoặc với một máy chủ tập trung trong quá trình đào tạo mô hình và có thể được triển khai trên nhiều tài khoản AWS. Người tham gia có thể chọn duy trì dữ liệu của họ trong hệ thống tại chỗ hoặc trong tài khoản AWS mà họ kiểm soát. Do đó, nó mang phân tích đến dữ liệu, thay vì chuyển dữ liệu sang phân tích.
Trong bài đăng này, chúng tôi đã chỉ ra cách bạn có thể triển khai khung FedML mã nguồn mở trên AWS. Chúng tôi thử nghiệm khuôn khổ trên dữ liệu eICU, cơ sở dữ liệu chăm sóc tích cực đa trung tâm được thu thập từ hơn 200 bệnh viện, để dự đoán tỷ lệ tử vong của bệnh nhân trong bệnh viện. Chúng tôi có thể sử dụng khung FL này để phân tích các bộ dữ liệu khác, bao gồm dữ liệu khoa học đời sống và bộ gen. Nó cũng có thể được áp dụng bởi các lĩnh vực khác có nhiều dữ liệu phân tán và nhạy cảm, bao gồm cả lĩnh vực tài chính và giáo dục.
Học liên tục
Những tiến bộ trong công nghệ đã dẫn đến sự tăng trưởng bùng nổ của dữ liệu trong các ngành, bao gồm cả HCLS. Các tổ chức HCLS thường lưu trữ dữ liệu trong silo. Điều này đặt ra một thách thức lớn trong học tập dựa trên dữ liệu, đòi hỏi các bộ dữ liệu lớn để khái quát hóa tốt và đạt được mức hiệu suất mong muốn. Hơn nữa, việc thu thập, quản lý và duy trì các bộ dữ liệu chất lượng cao gây tốn thời gian và chi phí đáng kể.
Học liên kết giảm thiểu những thách thức này bằng cách đào tạo cộng tác các mô hình ML sử dụng dữ liệu phân tán mà không cần chia sẻ hoặc tập trung hóa chúng. Nó cho phép các trang web khác nhau được thể hiện trong mô hình cuối cùng, giảm rủi ro tiềm ẩn đối với xu hướng dựa trên trang web. Khung tuân theo kiến trúc máy khách-máy chủ, trong đó máy chủ chia sẻ mô hình toàn cầu với máy khách. Máy khách đào tạo mô hình dựa trên dữ liệu cục bộ và chia sẻ các tham số (chẳng hạn như độ dốc hoặc trọng số mô hình) với máy chủ. Máy chủ tổng hợp các thông số này để cập nhật mô hình toàn cầu, sau đó được chia sẻ với khách hàng cho vòng đào tạo tiếp theo, như thể hiện trong hình dưới đây. Quá trình đào tạo mô hình lặp đi lặp lại này tiếp tục cho đến khi mô hình toàn cầu hội tụ.
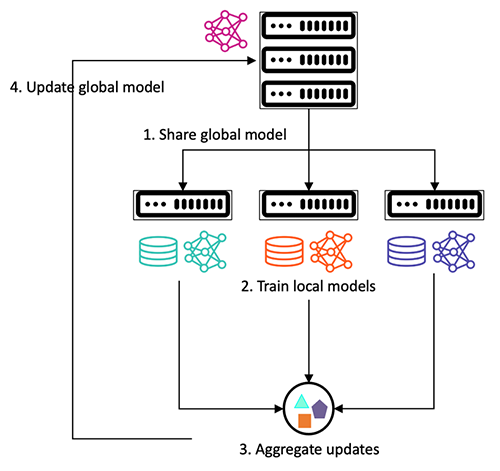
Quá trình lặp đi lặp lại của đào tạo mô hình
Trong những năm gần đây, mô hình học tập mới này đã được áp dụng thành công để giải quyết mối quan tâm về quản trị dữ liệu trong các mô hình ML đào tạo. Một trong những nỗ lực như vậy là MELLODDY, một tập đoàn do Sáng kiến Thuốc đổi mới (IMI) dẫn đầu, được cung cấp bởi AWS. Đây là chương trình kéo dài 3 năm với sự tham gia của 10 công ty dược phẩm, 2 tổ chức học thuật và 3 đối tác công nghệ. Mục tiêu chính của nó là phát triển khung FL đa tác vụ để cải thiện hiệu suất dự đoán và khả năng ứng dụng hóa học của các mô hình dựa trên khám phá thuốc. Nền tảng này bao gồm nhiều tài khoản AWS, với mỗi đối tác dược phẩm giữ toàn quyền kiểm soát các tài khoản tương ứng của họ để duy trì bộ dữ liệu riêng tư của họ và một tài khoản ML trung tâm điều phối các nhiệm vụ đào tạo mô hình.
Hiệp hội đã đào tạo các mô hình trên hàng tỷ điểm dữ liệu, bao gồm hơn 20 triệu phân tử nhỏ trong hơn 40,000 thử nghiệm sinh học. Dựa trên các kết quả thử nghiệm, các mô hình hợp tác đã chứng minh sự cải thiện 4% trong việc phân loại các phân tử là hoạt động hoặc không hoạt động về mặt dược lý hoặc độc tính. Nó cũng giúp tăng 10% khả năng đưa ra những dự đoán chắc chắn khi áp dụng cho các loại phân tử mới. Cuối cùng, các mô hình hợp tác thường tốt hơn 2% trong việc ước tính giá trị của các hoạt động độc tính và dược lý.
FedML
FedML là một thư viện mã nguồn mở để hỗ trợ phát triển thuật toán FL. Nó hỗ trợ ba mô hình điện toán: đào tạo trên thiết bị cho các thiết bị biên, điện toán phân tán và mô phỏng một máy. Nó cũng cung cấp nghiên cứu thuật toán đa dạng với thiết kế API chung và linh hoạt cũng như triển khai đường cơ sở tham chiếu toàn diện (trình tối ưu hóa, mô hình và bộ dữ liệu). Để biết mô tả chi tiết về thư viện FedML, hãy tham khảo FedML.
Hình dưới đây trình bày kiến trúc thư viện mã nguồn mở của FedML.
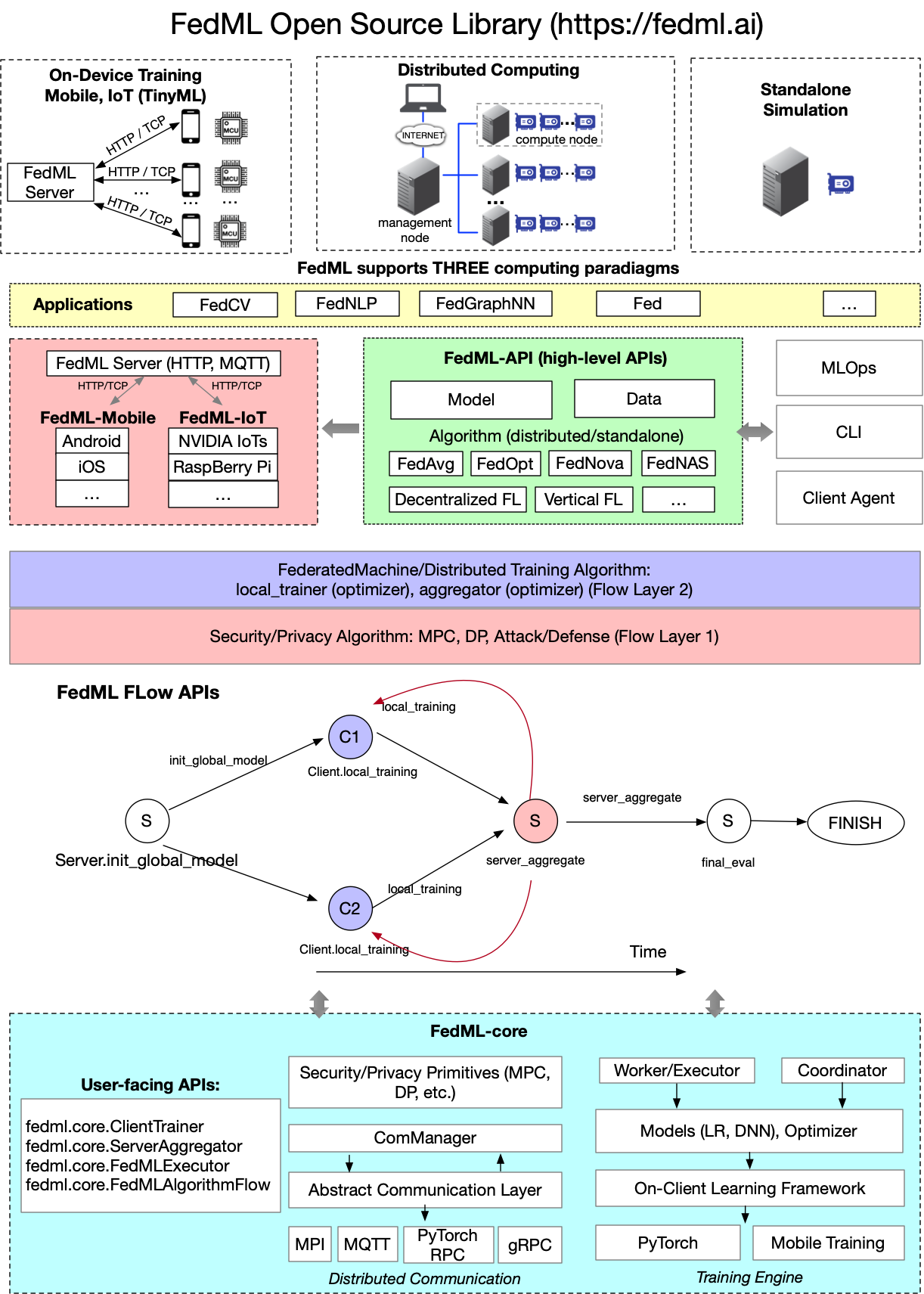
Kiến trúc thư viện mã nguồn mở của FedML
Như đã thấy trong hình trước, từ quan điểm ứng dụng, FedML che chắn các chi tiết của mã cơ bản và các cấu hình phức tạp của đào tạo phân tán. Ở cấp độ ứng dụng, chẳng hạn như thị giác máy tính, xử lý ngôn ngữ tự nhiên và khai thác dữ liệu, các nhà khoa học và kỹ sư dữ liệu chỉ cần viết mô hình, dữ liệu và huấn luyện viên theo cách giống như một chương trình độc lập rồi chuyển nó tới đối tượng FedMLRunner để hoàn thành tất cả các quy trình, như được hiển thị trong đoạn mã sau. Điều này làm giảm đáng kể chi phí cho các nhà phát triển ứng dụng để thực hiện FL.
Thuật toán FedML vẫn đang trong quá trình hoàn thiện và không ngừng được cải thiện. Cuối cùng, FedML tóm tắt trình huấn luyện và trình tổng hợp cốt lõi và cung cấp cho người dùng hai đối tượng trừu tượng, FedML.core.ClientTrainer và FedML.core.ServerAggregator, chỉ cần kế thừa các giao diện của hai đối tượng trừu tượng này và chuyển chúng cho FedMLRunner. Việc tùy chỉnh như vậy cung cấp cho các nhà phát triển ML sự linh hoạt tối đa. Bạn có thể xác định cấu trúc mô hình tùy ý, trình tối ưu hóa, hàm mất mát, v.v. Các tùy chỉnh này cũng có thể được kết nối liền mạch với cộng đồng nguồn mở, nền tảng mở và hệ sinh thái ứng dụng đã đề cập trước đó với sự trợ giúp của FedMLRunner, giải quyết hoàn toàn vấn đề độ trễ lâu dài từ các thuật toán đổi mới đến thương mại hóa.
Cuối cùng, như thể hiện trong hình trước, FedML hỗ trợ các quy trình tính toán phân tán, chẳng hạn như các giao thức bảo mật phức tạp và đào tạo phân tán dưới dạng quy trình tính toán luồng Đồ thị theo chu kỳ có hướng (DAG), khiến việc viết các giao thức phức tạp tương tự như các chương trình độc lập. Dựa trên ý tưởng này, giao thức bảo mật Flow Layer 1 và quy trình thuật toán ML Flow Layer 2 có thể dễ dàng tách biệt để các kỹ sư bảo mật và kỹ sư ML có thể vận hành trong khi vẫn duy trì kiến trúc mô-đun.
Thư viện mã nguồn mở FedML hỗ trợ các trường hợp sử dụng ML được liên kết cho biên cũng như đám mây. Ngoài ra, khung này tạo điều kiện đào tạo và triển khai các mô hình biên cho điện thoại di động và thiết bị kết nối vạn vật (IoT). Trong đám mây, nó cho phép ML cộng tác toàn cầu, bao gồm các máy chủ tổng hợp đám mây công cộng nhiều khu vực và nhiều bên thuê, cũng như triển khai đám mây riêng trong chế độ Docker. Khung giải quyết các mối quan tâm chính liên quan đến FL bảo vệ quyền riêng tư như bảo mật, quyền riêng tư, hiệu quả, giám sát yếu và công bằng.
Kết luận
Trong bài đăng này, chúng tôi đã chỉ ra cách bạn có thể triển khai khung FedML mã nguồn mở trên AWS. Điều này cho phép bạn đào tạo một mô hình ML trên dữ liệu phân tán mà không cần chia sẻ hoặc di chuyển nó. Chúng tôi thiết lập một kiến trúc nhiều tài khoản, trong đó trong một tình huống thực tế, các tổ chức có thể tham gia hệ sinh thái để hưởng lợi từ việc học tập cộng tác trong khi vẫn duy trì quản trị dữ liệu. bên trong bài tiếp theo, chúng tôi sử dụng bộ dữ liệu eICU đa bệnh viện để chứng minh tính hiệu quả của nó trong tình huống thực tế.
Vui lòng xem lại phần trình bày tại re:MARS 2022 tập trung vào “Managed Federated Learning trên AWS: Nghiên cứu điển hình về chăm sóc sức khỏe” để có hướng dẫn chi tiết về giải pháp này.
Tài liệu tham khảo
[1] Kaissis, GA, Makowski, MR, Rückert, D. et al. Học máy an toàn, bảo vệ quyền riêng tư và được liên kết trong hình ảnh y tế. Nat Mach Intell 2, 305–311 (2020). https://doi.org/10.1038/s42256-020-0186-1
[2] FedML https://fedml.ai
Về các tác giả
 Olivia Choudhury, Tiến sĩ, là Kiến trúc sư giải pháp đối tác cấp cao tại AWS. Cô giúp các đối tác, trong lĩnh vực Chăm sóc sức khỏe và Khoa học Đời sống, thiết kế, phát triển và mở rộng quy mô các giải pháp tiên tiến tận dụng AWS. Cô ấy có kiến thức nền tảng về bộ gen, phân tích chăm sóc sức khỏe, học tập liên kết và học máy bảo vệ quyền riêng tư. Ngoài giờ làm việc, cô ấy chơi board game, vẽ tranh phong cảnh và sưu tầm truyện tranh.
Olivia Choudhury, Tiến sĩ, là Kiến trúc sư giải pháp đối tác cấp cao tại AWS. Cô giúp các đối tác, trong lĩnh vực Chăm sóc sức khỏe và Khoa học Đời sống, thiết kế, phát triển và mở rộng quy mô các giải pháp tiên tiến tận dụng AWS. Cô ấy có kiến thức nền tảng về bộ gen, phân tích chăm sóc sức khỏe, học tập liên kết và học máy bảo vệ quyền riêng tư. Ngoài giờ làm việc, cô ấy chơi board game, vẽ tranh phong cảnh và sưu tầm truyện tranh.
 Vidya Sagar Ravipati là Quản lý tại Phòng thí nghiệm giải pháp Amazon ML, nơi anh ấy tận dụng kinh nghiệm rộng lớn của mình trong các hệ thống phân tán quy mô lớn và niềm đam mê học máy của mình để giúp khách hàng AWS trên các ngành dọc khác nhau đẩy nhanh việc áp dụng AI và đám mây của họ. Trước đây, anh ấy là Kỹ sư Máy học trong Dịch vụ Kết nối tại Amazon, người đã giúp xây dựng các nền tảng bảo trì dự đoán và cá nhân hóa.
Vidya Sagar Ravipati là Quản lý tại Phòng thí nghiệm giải pháp Amazon ML, nơi anh ấy tận dụng kinh nghiệm rộng lớn của mình trong các hệ thống phân tán quy mô lớn và niềm đam mê học máy của mình để giúp khách hàng AWS trên các ngành dọc khác nhau đẩy nhanh việc áp dụng AI và đám mây của họ. Trước đây, anh ấy là Kỹ sư Máy học trong Dịch vụ Kết nối tại Amazon, người đã giúp xây dựng các nền tảng bảo trì dự đoán và cá nhân hóa.
 Wajahat Aziz là Kiến trúc sư giải pháp HPC và Machine Learning chính tại AWS, nơi ông tập trung vào việc giúp các khách hàng chăm sóc sức khỏe và khoa học đời sống tận dụng các công nghệ AWS để phát triển các giải pháp ML và HPC tiên tiến nhất cho nhiều trường hợp sử dụng khác nhau như Phát triển thuốc, Thử nghiệm lâm sàng và Học máy bảo vệ quyền riêng tư. Ngoài công việc, Wajahat thích khám phá thiên nhiên, đi bộ đường dài và đọc sách.
Wajahat Aziz là Kiến trúc sư giải pháp HPC và Machine Learning chính tại AWS, nơi ông tập trung vào việc giúp các khách hàng chăm sóc sức khỏe và khoa học đời sống tận dụng các công nghệ AWS để phát triển các giải pháp ML và HPC tiên tiến nhất cho nhiều trường hợp sử dụng khác nhau như Phát triển thuốc, Thử nghiệm lâm sàng và Học máy bảo vệ quyền riêng tư. Ngoài công việc, Wajahat thích khám phá thiên nhiên, đi bộ đường dài và đọc sách.
 Divya Bhargavi là Nhà khoa học dữ liệu và Trưởng nhóm ngành truyền thông và giải trí tại Phòng thí nghiệm giải pháp máy học của Amazon, nơi cô giải quyết các vấn đề kinh doanh có giá trị cao cho khách hàng AWS bằng Machine Learning. Cô ấy nghiên cứu về hiểu biết hình ảnh/video, hệ thống đề xuất sơ đồ tri thức, các trường hợp sử dụng quảng cáo dự đoán.
Divya Bhargavi là Nhà khoa học dữ liệu và Trưởng nhóm ngành truyền thông và giải trí tại Phòng thí nghiệm giải pháp máy học của Amazon, nơi cô giải quyết các vấn đề kinh doanh có giá trị cao cho khách hàng AWS bằng Machine Learning. Cô ấy nghiên cứu về hiểu biết hình ảnh/video, hệ thống đề xuất sơ đồ tri thức, các trường hợp sử dụng quảng cáo dự đoán.
 Ujjwal Ratan là lãnh đạo về AI/ML và Khoa học dữ liệu trong Đơn vị kinh doanh khoa học đời sống và chăm sóc sức khỏe của AWS, đồng thời cũng là Kiến trúc sư giải pháp AI/ML chính. Trong những năm qua, Ujjwal là nhà lãnh đạo có tư tưởng trong ngành chăm sóc sức khỏe và khoa học đời sống, giúp nhiều tổ chức trong danh sách Fortune 500 toàn cầu đạt được các mục tiêu đổi mới của họ bằng cách áp dụng máy học. Công việc của anh liên quan đến phân tích hình ảnh y tế, văn bản lâm sàng phi cấu trúc và bộ gen đã giúp AWS xây dựng các sản phẩm và dịch vụ cung cấp chẩn đoán và điều trị nhắm mục tiêu chính xác và được cá nhân hóa ở mức độ cao. Trong thời gian rảnh rỗi, anh ấy thích nghe (và chơi) nhạc và tham gia các chuyến du lịch ngoài dự kiến cùng gia đình.
Ujjwal Ratan là lãnh đạo về AI/ML và Khoa học dữ liệu trong Đơn vị kinh doanh khoa học đời sống và chăm sóc sức khỏe của AWS, đồng thời cũng là Kiến trúc sư giải pháp AI/ML chính. Trong những năm qua, Ujjwal là nhà lãnh đạo có tư tưởng trong ngành chăm sóc sức khỏe và khoa học đời sống, giúp nhiều tổ chức trong danh sách Fortune 500 toàn cầu đạt được các mục tiêu đổi mới của họ bằng cách áp dụng máy học. Công việc của anh liên quan đến phân tích hình ảnh y tế, văn bản lâm sàng phi cấu trúc và bộ gen đã giúp AWS xây dựng các sản phẩm và dịch vụ cung cấp chẩn đoán và điều trị nhắm mục tiêu chính xác và được cá nhân hóa ở mức độ cao. Trong thời gian rảnh rỗi, anh ấy thích nghe (và chơi) nhạc và tham gia các chuyến du lịch ngoài dự kiến cùng gia đình.
 Triều Dương Hà là Đồng sáng lập và CTO của FedML, Inc., một công ty khởi nghiệp đang hoạt động vì một cộng đồng xây dựng AI mở và hợp tác từ mọi nơi ở mọi quy mô. Nghiên cứu của ông tập trung vào các thuật toán, hệ thống và ứng dụng học máy phân tán/liên kết. Anh ấy đã nhận bằng Tiến sĩ. trong Khoa học máy tính từ Đại học Nam California, Los Angeles, Mỹ.
Triều Dương Hà là Đồng sáng lập và CTO của FedML, Inc., một công ty khởi nghiệp đang hoạt động vì một cộng đồng xây dựng AI mở và hợp tác từ mọi nơi ở mọi quy mô. Nghiên cứu của ông tập trung vào các thuật toán, hệ thống và ứng dụng học máy phân tán/liên kết. Anh ấy đã nhận bằng Tiến sĩ. trong Khoa học máy tính từ Đại học Nam California, Los Angeles, Mỹ.
 Salman Avestimehr là Giáo sư, giám đốc đầu tiên của Trung tâm USC-Amazon về Máy học An toàn và Đáng tin cậy (Trí tuệ nhân tạo Đáng tin cậy), đồng thời là giám đốc phòng thí nghiệm nghiên cứu Lý thuyết Thông tin và Máy học (vITAL) tại Khoa Kỹ thuật Điện và Máy tính và Khoa Khoa học Máy tính của Đại học Nam California. Ông cũng là người đồng sáng lập và CEO của FedML. Anh ấy đã nhận bằng tiến sĩ của tôi. bằng Kỹ thuật Điện và Khoa học Máy tính của UC Berkeley năm 2008. Nghiên cứu của ông tập trung vào các lĩnh vực lý thuyết thông tin, học máy phi tập trung và liên kết, học tập và điện toán bảo mật và bảo vệ quyền riêng tư.
Salman Avestimehr là Giáo sư, giám đốc đầu tiên của Trung tâm USC-Amazon về Máy học An toàn và Đáng tin cậy (Trí tuệ nhân tạo Đáng tin cậy), đồng thời là giám đốc phòng thí nghiệm nghiên cứu Lý thuyết Thông tin và Máy học (vITAL) tại Khoa Kỹ thuật Điện và Máy tính và Khoa Khoa học Máy tính của Đại học Nam California. Ông cũng là người đồng sáng lập và CEO của FedML. Anh ấy đã nhận bằng tiến sĩ của tôi. bằng Kỹ thuật Điện và Khoa học Máy tính của UC Berkeley năm 2008. Nghiên cứu của ông tập trung vào các lĩnh vực lý thuyết thông tin, học máy phi tập trung và liên kết, học tập và điện toán bảo mật và bảo vệ quyền riêng tư.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/part-1-federated-learning-on-aws-with-fedml-health-analytics-without-sharing-sensitive-data/

