Backtesting là một quy trình được sử dụng trong tài chính định lượng để đánh giá các chiến lược giao dịch bằng cách sử dụng dữ liệu lịch sử. Điều này giúp các nhà giao dịch xác định khả năng sinh lời tiềm năng của một chiến lược và xác định bất kỳ rủi ro nào liên quan đến chiến lược đó, cho phép họ tối ưu hóa chiến lược đó để có hiệu suất tốt hơn.
Arbitrage tái cân bằng chỉ số tận dụng chênh lệch giá ngắn hạn do nỗ lực của các nhà quản lý ETF nhằm giảm thiểu lỗi theo dõi chỉ số của các nhà quản lý quỹ ETF. Các chỉ số thị trường chính, chẳng hạn như S&P 500, có thể bao gồm và loại trừ định kỳ vì những lý do nằm ngoài phạm vi của bài đăng này (ví dụ: tham khảo Tập đoàn CoStar, Các ngôi nhà được mời tham gia S&P 500; Những người khác tham gia S&P 100, S&P MidCap 400 và S&P SmallCap 600). Giao dịch chênh lệch giá có vẻ kiếm được lợi nhuận từ việc mua các cổ phiếu được thêm vào một chỉ số và bán khống những cổ phiếu bị loại bỏ, với mục đích tạo ra lợi nhuận từ những chênh lệch giá này.
Trong bài đăng này, chúng tôi xem xét quá trình sử dụng kiểm tra ngược để đánh giá hiệu suất của chiến lược sinh lời chênh lệch chỉ số. Chúng tôi đặc biệt khám phá cách Amazon EMR và mới phát triển Apache Iceberg phân nhánh và gắn thẻ tính năng có thể giải quyết thách thức về xu hướng nhìn trước trong quá trình kiểm tra lại. Điều này sẽ cho phép đánh giá chính xác hơn về hiệu suất của chiến lược sinh lời chênh lệch chỉ số.
Thuật ngữ
Trước tiên chúng ta hãy thảo luận về một số thuật ngữ được sử dụng trong bài đăng này:
- Nghiên cứu hồ dữ liệu trên Amazon S3 - A hồ dữ liệu là một kho lưu trữ lớn, tập trung cho phép bạn quản lý tất cả dữ liệu có cấu trúc và phi cấu trúc của mình ở bất kỳ quy mô nào. Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) là dịch vụ lưu trữ đối tượng dựa trên đám mây phổ biến có thể được sử dụng làm nền tảng để xây dựng kho dữ liệu.
- tảng băng Apache – tảng băng Apache là một định dạng bảng nguồn mở được thiết kế để cung cấp khả năng truy cập hiệu quả, có thể mở rộng và an toàn vào các bộ dữ liệu lớn. Dịch vụ này cung cấp các tính năng như giao dịch ACID trên các kho dữ liệu dựa trên Amazon S3, tiến hóa lược đồ, tiến hóa phân vùng và lập phiên bản dữ liệu. Với tính năng lập chỉ mục siêu dữ liệu có thể mở rộng, Apache Iceberg có thể cung cấp các truy vấn hiệu quả cho nhiều công cụ khác nhau như Spark và Athena bằng cách giảm thời gian lập kế hoạch.
- Xem–xu hướng trước – Đây là một thách thức phổ biến trong quá trình kiểm tra lại, xảy ra khi thông tin trong tương lai vô tình được đưa vào dữ liệu lịch sử được sử dụng để kiểm tra chiến lược giao dịch, dẫn đến kết quả quá lạc quan.
- thẻ tảng băng trôi – Tảng băng trôi tính năng phân nhánh và gắn thẻ cho phép người dùng gắn thẻ các ảnh chụp nhanh cụ thể của bảng dữ liệu của họ bằng các nhãn có ý nghĩa bằng cách sử dụng cú pháp SQL hoặc thư viện Iceberg, tương ứng với các sự kiện cụ thể đáng chú ý đối với các nhóm đầu tư nội bộ. Điều này, kết hợp với Iceberg du hành thời gian chức năng, đảm bảo rằng dữ liệu chính xác được đưa vào quy trình nghiên cứu và bảo vệ nó khỏi các vấn đề khó phát hiện, chẳng hạn như thành kiến nhìn trước ngó sau.
Phạm vi kiểm tra
Đối với mục đích thử nghiệm của chúng tôi, hãy xem xét những điều sau đây ví dụ, trong đó thay đổi đối với Chỉ số S&P Dow Jones được công bố vào ngày 2 tháng 2022 năm 19, có hiệu lực vào ngày 2022 tháng 30 năm 2022 và không thể quan sát được trong dữ liệu nắm giữ ETF mà chúng tôi sẽ sử dụng trong thử nghiệm cho đến ngày XNUMX tháng XNUMX năm XNUMX. Chúng tôi sử dụng thẻ Iceberg để gắn nhãn ảnh chụp nhanh dữ liệu thị trường nhằm tránh sai lệch nhìn trước trong hồ dữ liệu nghiên cứu, điều này sẽ cho phép chúng tôi thử nghiệm các kịch bản vào và thoát giao dịch khác nhau cũng như đánh giá khả năng sinh lời tương ứng của từng kịch bản.
Thử nghiệm
Là một phần trong thử nghiệm của mình, chúng tôi sử dụng nhà cung cấp dữ liệu bên thứ ba có trả phí API để xác định SPY ETF nắm giữ thay đổi và xây dựng một danh mục đầu tư. Danh mục đầu tư mô hình của chúng tôi sẽ mua các cổ phiếu được thêm vào chỉ mục, được gọi là sẽ mua và sẽ bán một lượng cổ phiếu tương đương bị loại khỏi chỉ mục, được gọi là đi ngắn.
Chúng tôi sẽ kiểm tra các khoảng thời gian nắm giữ ngắn hạn, chẳng hạn như 1 ngày và 1, 2, 3 hoặc 4 tuần, bởi vì chúng tôi giả định rằng hiệu ứng tái cân bằng là rất ngắn và thông tin mới, chẳng hạn như kinh tế vĩ mô, sẽ thúc đẩy hiệu suất vượt ra ngoài phạm vi thời gian đã nghiên cứu. Cuối cùng, chúng tôi mô phỏng các điểm vào khác nhau cho giao dịch này:
- Thị trường mở cửa vào ngày sau ngày thông báo (AD+1)
- Ngày đóng cửa thị trường có hiệu lực (ED0)
- Thị trường mở cửa vào ngày sau khi ETF nắm giữ đăng ký thay đổi (MD+1)
Hồ dữ liệu nghiên cứu
Để chạy thử nghiệm của chúng tôi, chúng tôi đã sử dụng môi trường hồ dữ liệu nghiên cứu sau đây.

Như thể hiện trong sơ đồ kiến trúc, hồ dữ liệu nghiên cứu được xây dựng trên Amazon S3 và được quản lý bằng Apache Iceberg, đây là một định dạng bảng mở mang lại độ tin cậy và tính đơn giản của các bảng dịch vụ quản lý cơ sở dữ liệu quan hệ (RDBMS) cho các hồ dữ liệu. Để tránh thiên vị nhìn trước khi kiểm tra lại, điều cần thiết là tạo ảnh chụp nhanh dữ liệu tại các thời điểm khác nhau. Tuy nhiên, việc quản lý và sắp xếp các ảnh chụp nhanh này có thể là một thách thức, đặc biệt là khi xử lý một lượng lớn dữ liệu.
Đây là lúc tính năng gắn thẻ trong Apache Iceberg trở nên hữu ích. Với việc gắn thẻ, các nhà nghiên cứu có thể tạo các ảnh chụp nhanh dữ liệu thị trường được đặt tên khác nhau và theo dõi các thay đổi theo thời gian. Ví dụ: họ có thể tạo ảnh chụp nhanh dữ liệu vào cuối mỗi ngày giao dịch và gắn thẻ ngày và bất kỳ điều kiện thị trường có liên quan nào cho dữ liệu đó.
Bằng cách sử dụng các thẻ để sắp xếp ảnh chụp nhanh, các nhà nghiên cứu có thể dễ dàng truy vấn và phân tích dữ liệu dựa trên các điều kiện hoặc sự kiện thị trường cụ thể mà không phải lo lắng về ngày cụ thể của dữ liệu. Điều này có thể đặc biệt hữu ích khi tiến hành nghiên cứu không nhạy cảm với thời gian hoặc khi tìm kiếm các xu hướng trong thời gian dài.
Hơn nữa, tính năng gắn thẻ cũng có thể trợ giúp với các khía cạnh khác của quản lý dữ liệu, chẳng hạn như lưu giữ dữ liệu để tuân thủ GDPR và duy trì dòng của bảng thông qua các nhánh khác nhau. Các nhà nghiên cứu có thể sử dụng gắn thẻ Apache Iceberg để đảm bảo tính toàn vẹn và chính xác của dữ liệu của họ đồng thời đơn giản hóa việc quản lý dữ liệu.
Điều kiện tiên quyết
Để làm theo hướng dẫn này, bạn phải có những điều sau:
- An Tài khoản AWS với vai trò IAM có đủ quyền truy cập để cung cấp các tài nguyên cần thiết.
- Để tuân thủ các cân nhắc về cấp phép, chúng tôi không thể cung cấp mẫu dữ liệu cấu thành ETF. Do đó, nó phải được mua riêng cho mục đích giới thiệu tập dữ liệu.
Tổng quan về giải pháp
Để thiết lập và thử nghiệm thử nghiệm này, chúng tôi hoàn thành các bước cấp cao sau:
- Tạo một nhóm S3.
- Tải tập dữ liệu vào Amazon S3. Đối với bài đăng này, dữ liệu ETF được đề cập đến được lấy thông qua lệnh gọi API thông qua nhà cung cấp bên thứ ba, nhưng bạn cũng có thể xem xét các tùy chọn sau:
- Bạn có thể sử dụng như sau hướng dẫn kê đơn, mô tả cách tự động hóa quá trình nhập dữ liệu từ nhiều nhà cung cấp dữ liệu khác nhau vào kho dữ liệu trong Amazon S3 bằng cách sử dụng Trao đổi dữ liệu AWS.
- Bạn cũng có thể sử dụng AWS Data Exchange để chọn từ nhiều nhà cung cấp tập dữ liệu bên thứ ba. Nó đơn giản hóa việc sử dụng các tệp dữ liệu, bảng và API cho các nhu cầu cụ thể của bạn.
- Cuối cùng, bạn cũng có thể tham khảo bài viết sau về cách sử dụng AWS Data Exchange cho Amazon S3 để truy cập dữ liệu từ bộ chứa nhà cung cấp: Phân tích tác động của cải cách quy định đối với thị trường chứng khoán bằng dữ liệu AWS và Refinitiv.
- Tạo một cụm EMR. Bạn có thể sử dụng cái này Bắt đầu với hướng dẫn EMR hoặc chúng tôi đã sử dụng CDK để triển khai EMR trên môi trường EKS với điểm cuối được quản lý tùy chỉnh.
- Tạo sổ ghi chép EMR bằng EMR Studio. Đối với môi trường thử nghiệm của chúng tôi, chúng tôi đã sử dụng một hình ảnh Docker xây dựng tùy chỉnh, chứa Iceberg v1.3. Để biết hướng dẫn về cách đính kèm một cụm vào Không gian làm việc, hãy tham khảo Đính kèm một cụm vào Không gian làm việc.
- Định cấu hình phiên Spark. Bạn có thể theo dõi qua thông tin sau mẫu máy tính xách tay.
- Tạo bảng Iceberg và tải dữ liệu thử nghiệm từ Amazon S3 vào bảng.
- Gắn thẻ dữ liệu này để lưu ảnh chụp nhanh của nó.
- Thực hiện cập nhật dữ liệu thử nghiệm của chúng tôi và gắn thẻ tập dữ liệu được cập nhật.
- Chạy kiểm tra ngược mô phỏng trên dữ liệu thử nghiệm của chúng tôi để tìm điểm vào có lợi nhất cho giao dịch.
Tạo môi trường thí nghiệm
Chúng ta có thể bắt đầu và chạy với Iceberg bằng cách tạo bảng qua Spark SQL từ chế độ xem hiện có, như được hiển thị trong đoạn mã sau:
Bây giờ chúng ta đã tạo bảng Iceberg, chúng ta có thể sử dụng nó để nghiên cứu đầu tư. Một trong những tính năng chính của Iceberg là hỗ trợ phiên bản dữ liệu có thể mở rộng. Điều này có nghĩa là chúng tôi có thể dễ dàng theo dõi các thay đổi đối với dữ liệu của mình và quay lại các phiên bản trước mà không cần tạo thêm bản sao. Do dữ liệu này được cập nhật định kỳ nên chúng tôi muốn có thể tạo các ảnh chụp nhanh dữ liệu có tên để các nhà giao dịch định lượng có thể dễ dàng truy cập vào các ảnh chụp nhanh dữ liệu nhất quán có chính sách lưu giữ của riêng họ. Trong trường hợp này, hãy gắn thẻ tập dữ liệu để cho biết rằng tập dữ liệu đó đại diện cho dữ liệu nắm giữ ETF kể từ Q1 năm 2022:
Khi chúng tôi tiến về phía trước và dữ liệu mới sẽ có sẵn vào Quý 3, chúng tôi có thể cần cập nhật các bộ dữ liệu hiện có để phản ánh những thay đổi này. Trong ví dụ sau, trước tiên chúng tôi sử dụng câu lệnh CẬP NHẬT để đánh dấu các cổ phiếu đã hết hạn trong bộ dữ liệu nắm giữ ETF hiện có. Sau đó, chúng tôi sử dụng câu lệnh MERGE INTO dựa trên các điều kiện phù hợp, chẳng hạn như mã ISIN. Nếu không tìm thấy sự trùng khớp giữa tập dữ liệu hiện tại và tập dữ liệu mới, thì dữ liệu mới sẽ được chèn dưới dạng bản ghi mới trong bảng và mã trạng thái sẽ được đặt thành 'mới' cho những bản ghi này. Tương tự, nếu tập dữ liệu hiện tại có hàng tồn kho không có trong tập dữ liệu mới, những bản ghi đó sẽ vẫn hết hạn với mã trạng thái là 'đã hết hạn'. Cuối cùng, đối với các bản ghi tìm thấy kết quả trùng khớp, dữ liệu trong tập dữ liệu hiện có sẽ được cập nhật bằng dữ liệu từ tập dữ liệu mới và bản ghi sẽ có mã trạng thái không thay đổi. Với sự hỗ trợ của Iceberg để lập phiên bản dữ liệu hiệu quả và tính nhất quán trong giao dịch, chúng tôi có thể tin tưởng rằng các cập nhật dữ liệu của chúng tôi sẽ được áp dụng chính xác và không làm hỏng dữ liệu.
Bởi vì chúng tôi hiện có phiên bản dữ liệu mới, nên chúng tôi sử dụng gắn thẻ Iceberg để cung cấp sự cô lập cho từng phiên bản dữ liệu mới. Trong trường hợp này, chúng tôi gắn thẻ này là Q3_2022 và cho phép các nhà giao dịch định lượng và những người dùng khác làm việc trên ảnh chụp nhanh dữ liệu này mà không bị ảnh hưởng bởi các bản cập nhật liên tục cho quy trình:
Điều này giúp dễ dàng xem cổ phiếu nào đang được thêm và xóa. Chúng ta có thể sử dụng tính năng du hành thời gian của Iceberg để đọc dữ liệu tại một thẻ hàng quý nhất định. Trước tiên, hãy xem cổ phiếu nào được thêm vào chỉ mục; đây là những hàng có trong ảnh chụp nhanh Q3 nhưng không có trong ảnh chụp nhanh Q1. Sau đó, chúng tôi sẽ xem xét cổ phiếu nào bị loại bỏ; đây là những hàng có trong ảnh chụp nhanh Q1 nhưng không có trong ảnh chụp nhanh Q3:
Bây giờ chúng tôi sử dụng delta thu được trong đoạn mã trước để kiểm tra lại chiến lược sau. Là một phần của quy trình chênh lệch tái cân bằng chỉ số, chúng ta sẽ mua các cổ phiếu mua được thêm vào chỉ mục và các cổ phiếu bán khống bị xóa khỏi chỉ mục và chúng ta sẽ kiểm tra chiến lược này cho cả ngày có hiệu lực và ngày thông báo. Để chứng minh khái niệm từ hai danh sách khác nhau, chúng tôi đã chọn PVH và PENN là cổ phiếu bị loại bỏ và CSGP và INVH là cổ phiếu được thêm vào.
Để làm theo các ví dụ bên dưới, bạn sẽ cần sử dụng sổ ghi chép được cung cấp trong Ví dụ Quant Research Kho lưu trữ GitHub.
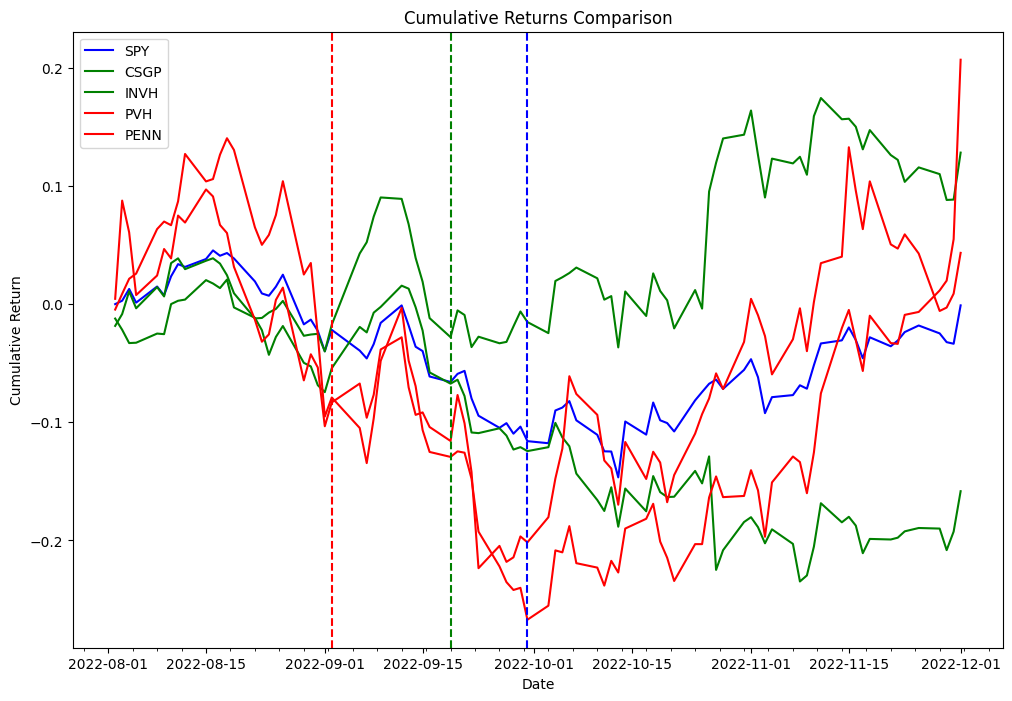
Bảng sau đây thể hiện các bản ghi đơn đặt hàng danh mục đầu tư:
| Mã đơn đặt hàng | Cột | Dấu thời gian | Kích thước máy | Giá cả | Lệ Phí | Bên |
|---|---|---|---|---|---|---|
| 0 | (PENN, PENN) | 2022-09-06 | 31948.881789 | 31.66 | 0.0 | Bán |
| 1 | (PVH, PVH) | 2022-09-06 | 18321.729571 | 55.15 | 0.0 | Bán |
| 2 | (INVH, INVH) | 2022-09-06 | 27419.797094 | 38.20 | 0.0 | Mua |
| 3 | (CSGP, CSGP) | 2022-09-06 | 14106.361969 | 75.00 | 0.0 | Mua |
| 4 | (CSGP, CSGP) | 2022-11-01 | 14106.361969 | 83.70 | 0.0 | Bán |
| 5 | (INVH, INVH) | 2022-11-01 | 27419.797094 | 31.94 | 0.0 | Bán |
| 6 | (PVH, PVH) | 2022-11-01 | 18321.729571 | 52.95 | 0.0 | Mua |
| 7 | (PENN, PENN) | 2022-11-01 | 31948.881789 | 34.09 | 0.0 | Mua |
Kết quả thí nghiệm
Bảng sau đây cho thấy Tỷ lệ Sharpe trong các khoảng thời gian nắm giữ khác nhau và hai điểm tham gia giao dịch khác nhau: thông báo và ngày có hiệu lực.

Dữ liệu cho thấy rằng ngày có hiệu lực là điểm vào có lợi nhất trong hầu hết các khoảng thời gian nắm giữ, trong khi ngày thông báo là điểm vào hiệu quả cho các khoảng thời gian nắm giữ ngắn hạn (5 ngày theo lịch, 2 ngày làm việc). Bởi vì kết quả thu được từ việc thử nghiệm một sự kiện duy nhất nên điều này không có ý nghĩa thống kê để chấp nhận hoặc bác bỏ giả thuyết rằng các sự kiện tái cân bằng chỉ số có thể được sử dụng để tạo alpha nhất quán. Cơ sở hạ tầng mà chúng tôi đã sử dụng cho thử nghiệm của mình có thể được sử dụng để chạy cùng một thử nghiệm cần thiết để thực hiện thử nghiệm giả thuyết trên quy mô lớn, nhưng dữ liệu cấu thành chỉ số không có sẵn.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách sử dụng kiểm tra ngược và tính năng gắn thẻ Apache Iceberg có thể cung cấp thông tin chi tiết có giá trị về hiệu suất của các chiến lược sinh lời chênh lệch chỉ số. Bằng cách sử dụng một khả năng mở rộng Amazon EMR trên Amazon EKS ngăn xếp, các nhà nghiên cứu có thể dễ dàng xử lý toàn bộ vòng đời nghiên cứu đầu tư, từ thu thập dữ liệu đến kiểm tra lại. Ngoài ra, tính năng gắn thẻ Iceberg có thể giúp giải quyết thách thức về xu hướng nhìn trước, đồng thời mang lại các lợi ích như kiểm soát lưu giữ dữ liệu để tuân thủ GDPR và duy trì dòng truyền thống của bảng thông qua các cách khác nhau. chi nhánh. Kết quả thử nghiệm chứng minh tính hiệu quả của phương pháp này trong việc đánh giá hiệu suất của các chiến lược chênh lệch chỉ số và có thể đóng vai trò là hướng dẫn hữu ích cho các nhà nghiên cứu trong ngành tài chính.
Về các tác giả
 Boris Litvin là Kiến trúc sư giải pháp chính, chịu trách nhiệm đổi mới ngành dịch vụ tài chính. Anh ấy là cựu người sáng lập Quant và FinTech, đồng thời đam mê đầu tư có hệ thống.
Boris Litvin là Kiến trúc sư giải pháp chính, chịu trách nhiệm đổi mới ngành dịch vụ tài chính. Anh ấy là cựu người sáng lập Quant và FinTech, đồng thời đam mê đầu tư có hệ thống.
 Chàng Bachar là Kiến trúc sư giải pháp tại AWS, có trụ sở tại New York. Anh đồng hành cùng các khách hàng mới và giúp họ bắt đầu hành trình trên đám mây với AWS. Anh ấy đam mê danh tính, bảo mật và truyền thông hợp nhất.
Chàng Bachar là Kiến trúc sư giải pháp tại AWS, có trụ sở tại New York. Anh đồng hành cùng các khách hàng mới và giúp họ bắt đầu hành trình trên đám mây với AWS. Anh ấy đam mê danh tính, bảo mật và truyền thông hợp nhất.
 Noam Ouaknine là Người quản lý tài khoản kỹ thuật tại AWS và có trụ sở tại Florida. Ông giúp các khách hàng doanh nghiệp phát triển và đạt được chiến lược dài hạn của họ thông qua hướng dẫn kỹ thuật và lập kế hoạch chủ động.
Noam Ouaknine là Người quản lý tài khoản kỹ thuật tại AWS và có trụ sở tại Florida. Ông giúp các khách hàng doanh nghiệp phát triển và đạt được chiến lược dài hạn của họ thông qua hướng dẫn kỹ thuật và lập kế hoạch chủ động.
 Sercan Karaoglu là Kiến trúc sư Giải pháp Cấp cao, chuyên về thị trường vốn. Anh ấy là cựu kỹ sư dữ liệu và đam mê nghiên cứu đầu tư định lượng.
Sercan Karaoglu là Kiến trúc sư Giải pháp Cấp cao, chuyên về thị trường vốn. Anh ấy là cựu kỹ sư dữ liệu và đam mê nghiên cứu đầu tư định lượng.
 Jack Ye là kỹ sư phần mềm trong nhóm Lưu trữ và Hồ dữ liệu Athena. Anh ấy là Thành viên của Apache Iceberg và là thành viên PMC.
Jack Ye là kỹ sư phần mềm trong nhóm Lưu trữ và Hồ dữ liệu Athena. Anh ấy là Thành viên của Apache Iceberg và là thành viên PMC.
 Amgh Jahagirdar là Kỹ sư phần mềm trong nhóm Athena Data Lake. Anh ấy là Người chỉ huy tảng băng trôi Apache.
Amgh Jahagirdar là Kỹ sư phần mềm trong nhóm Athena Data Lake. Anh ấy là Người chỉ huy tảng băng trôi Apache.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/backtesting-index-rebalancing-arbitrage-with-amazon-emr-and-apache-iceberg/

