Thực tiễn chuyên môn về Analytics của Dịch vụ chuyên nghiệp của AWS (AWS ProServe) giúp khách hàng trên toàn cầu với kiến trúc dữ liệu hiện đại triển khai trên Đám mây AWS. Kiến trúc dữ liệu hiện đại là một mẫu kiến trúc tiến hóa được thiết kế để tích hợp hồ dữ liệu, kho dữ liệu và các cửa hàng được xây dựng theo mục đích với mô hình quản trị thống nhất. Nó tập trung vào việc xác định các tiêu chuẩn và mẫu để tích hợp người tạo và người tiêu dùng dữ liệu, đồng thời di chuyển dữ liệu giữa các hồ dữ liệu và kho lưu trữ dữ liệu được xây dựng có mục đích một cách an toàn và hiệu quả. Trong số nhiều hệ thống sản xuất dữ liệu cung cấp dữ liệu cho hồ dữ liệu, cơ sở dữ liệu hoạt động phổ biến nhất, nơi dữ liệu vận hành được lưu trữ, chuyển đổi, phân tích và cuối cùng được sử dụng để nâng cao hoạt động kinh doanh của một tổ chức. Với sự xuất hiện của các định dạng lưu trữ mở như Apache Hudi và của mình hỗ trợ bản địa từ Keo AWS đối với Apache Spark, nhiều khách hàng AWS đã bắt đầu bổ sung khả năng xử lý dữ liệu gia tăng và mang tính giao dịch vào hồ dữ liệu của họ.
AWS đã đầu tư vào việc tích hợp dịch vụ gốc với Apache Hudi và xuất bản nội dung kỹ thuật để cho phép bạn sử dụng Apache Hudi với AWS Glue (ví dụ: tham khảo Giới thiệu hỗ trợ riêng cho Apache Hudi, Delta Lake và Apache Iceberg trên AWS Glue cho Apache Spark, Phần 1: Bắt đầu). Trong các hoạt động tương tác với khách hàng do AWS ProServe dẫn dắt, các trường hợp sử dụng mà chúng tôi xử lý thường đi kèm với các yêu cầu về độ phức tạp về mặt kỹ thuật và khả năng mở rộng. Trong bài đăng này, chúng tôi thảo luận về một trường hợp sử dụng phổ biến liên quan đến xử lý dữ liệu vận hành và giải pháp chúng tôi xây dựng bằng Apache Hudi và AWS Glue.
Tổng quan về ca sử dụng
AnyCompany Travel and Hospitality muốn xây dựng một khung xử lý dữ liệu để nhập và xử lý liền mạch dữ liệu đến từ cơ sở dữ liệu vận hành (được sử dụng bởi hệ thống đặt chỗ và đặt chỗ) trong hồ dữ liệu trước khi áp dụng kỹ thuật máy học (ML) để cung cấp trải nghiệm cá nhân hóa cho người dùng. Do số lượng lớn các kênh bán hàng trực tiếp và gián tiếp mà công ty có, dữ liệu đặt chỗ và khuyến mãi của công ty được sắp xếp trong hàng trăm cơ sở dữ liệu hoạt động với hàng nghìn bảng. Trong số các bảng đó, một số bảng lớn hơn (chẳng hạn như về khối lượng bản ghi) so với các bảng khác và một số bảng được cập nhật thường xuyên hơn các bảng khác. Trong hồ dữ liệu, dữ liệu được sắp xếp theo các vùng lưu trữ sau:
- Bộ dữ liệu phù hợp với nguồn – Chúng có cấu trúc giống hệt với các đối tác của chúng tại nguồn
- Bộ dữ liệu tổng hợp – Các bộ dữ liệu này được tạo dựa trên một hoặc nhiều bộ dữ liệu phù hợp với nguồn
- Bộ dữ liệu phù hợp với người tiêu dùng – Chúng có nguồn gốc từ sự kết hợp của các bộ dữ liệu tham chiếu, tổng hợp và liên kết với nguồn được làm phong phú bằng logic chuyển đổi và kinh doanh có liên quan, thường được cung cấp làm đầu vào cho đường ống ML hoặc bất kỳ ứng dụng tiêu dùng nào
Sau đây là các yêu cầu nhập và xử lý dữ liệu:
- Sao chép dữ liệu từ cơ sở dữ liệu vận hành sang hồ dữ liệu, bao gồm các thao tác chèn, cập nhật và xóa.
- Luôn cập nhật các tập dữ liệu phù hợp với nguồn (thường trong khoảng 10 phút đến một ngày) so với các tập dữ liệu tương ứng trong cơ sở dữ liệu vận hành, đảm bảo quy trình phân tích làm mới kịp thời các tập dữ liệu phù hợp với người tiêu dùng cho quy trình ML xuôi dòng. Hơn nữa, khung nên tiêu thụ tài nguyên điện toán một cách tối ưu nhất có thể tùy theo kích thước của bảng vận hành.
- Để giảm thiểu DevOps và chi phí vận hành, công ty muốn tạo khuôn mẫu cho mã nguồn bất cứ khi nào có thể. Ví dụ: để tạo các tập dữ liệu phù hợp với nguồn trong hồ dữ liệu cho 3,000 bảng hoạt động, công ty không muốn triển khai 3,000 công việc xử lý dữ liệu riêng biệt. Số lượng công việc và tập lệnh càng nhỏ thì càng tốt.
- Công ty muốn có khả năng tiếp tục xử lý dữ liệu vận hành ở Khu vực thứ cấp trong trường hợp hiếm hoi xảy ra lỗi ở Khu vực chính.
Như bạn có thể đoán, khung Apache Hudi có thể giải quyết yêu cầu đầu tiên. Vì vậy, chúng tôi sẽ nhấn mạnh vào các yêu cầu khác. Chúng tôi bắt đầu với kiến trúc tham chiếu Hồ dữ liệu, sau đó là tổng quan về khung xử lý dữ liệu vận hành. Bằng cách hiển thị cho bạn giải pháp nguồn mở của chúng tôi trên GitHub, chúng tôi đi sâu vào các thành phần khung và tìm hiểu các khía cạnh thiết kế và triển khai của chúng. Cuối cùng, bằng cách kiểm tra khung, chúng tôi tóm tắt cách nó đáp ứng các yêu cầu nói trên.
Kiến trúc tham chiếu hồ dữ liệu
Hãy bắt đầu với một bức tranh lớn: hồ dữ liệu giải quyết nhiều trường hợp phân tích và sử dụng ML khác nhau liên quan đến người sản xuất và người tiêu dùng dữ liệu nội bộ và bên ngoài. Sơ đồ sau đây thể hiện kiến trúc hồ dữ liệu chung. Để nhập dữ liệu từ cơ sở dữ liệu hoạt động vào một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) nhóm tổ chức của hồ dữ liệu Dịch vụ di chuyển cơ sở dữ liệu AWS (AWS DMS) hoặc bất kỳ giải pháp đối tác AWS nào từ AWS Marketplace có hỗ trợ cho thay đổi dữ liệu chụp (CDC) có thể đáp ứng được yêu cầu. AWS Glue được sử dụng để tạo các tập dữ liệu phù hợp với nguồn và phù hợp với người tiêu dùng cũng như các công việc AWS Glue riêng biệt để thực hiện phần kỹ thuật tính năng của kỹ thuật và vận hành ML. amazon Athena được sử dụng để truy vấn tương tác và Sự hình thành hồ AWS được sử dụng để kiểm soát truy cập.
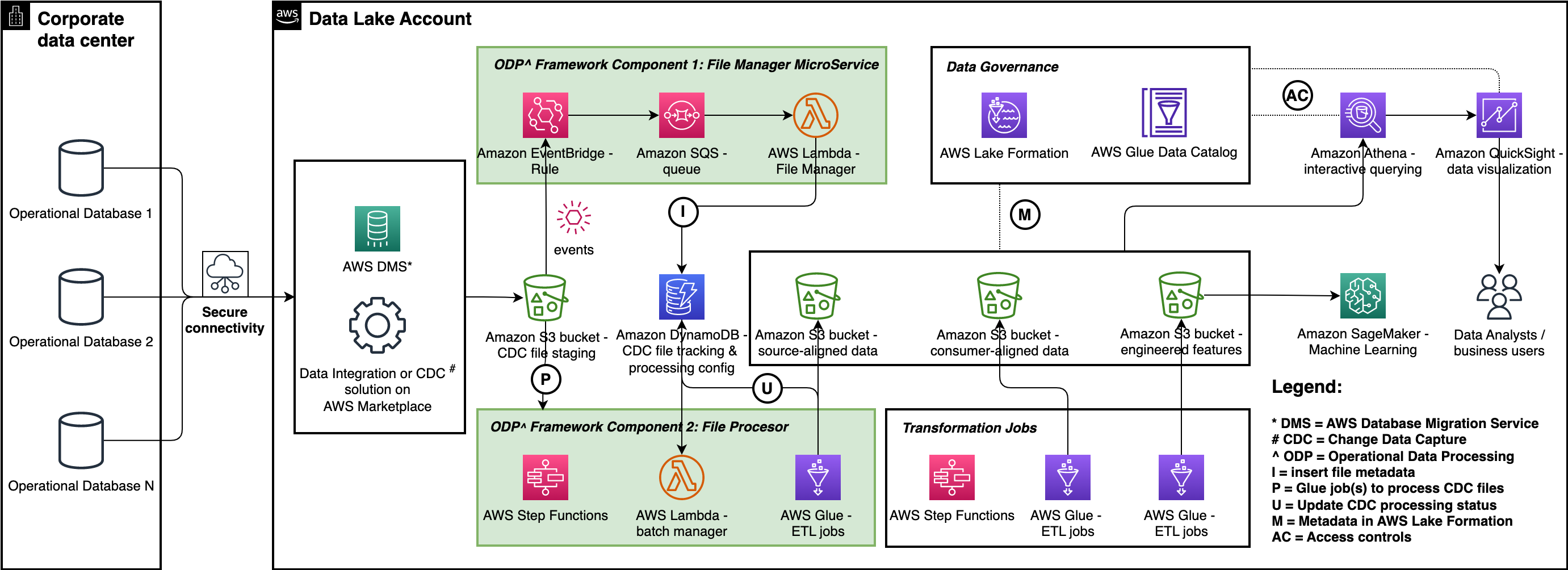
Khung xử lý dữ liệu hoạt động
Khung xử lý dữ liệu vận hành (ODP) chứa ba thành phần: Trình quản lý tệp, Bộ xử lý tệp và Trình quản lý cấu hình. Mỗi thành phần chạy độc lập để giải quyết một phần trường hợp sử dụng xử lý dữ liệu vận hành. Chúng tôi đã mã nguồn mở này khuôn khổ trên GitHub—bạn có thể sao chép kho lưu trữ mã và kiểm tra nó trong khi chúng tôi hướng dẫn bạn cách thiết kế và triển khai các thành phần khung. Mã nguồn được tổ chức thành ba thư mục, một thư mục cho mỗi thành phần và nếu bạn tùy chỉnh và áp dụng khung này cho trường hợp sử dụng của mình, chúng tôi khuyên bạn nên quảng bá các thư mục này dưới dạng kho lưu trữ mã riêng biệt trong hệ thống kiểm soát phiên bản của mình. Hãy cân nhắc sử dụng các tên kho lưu trữ sau:
aws-glue-hudi-odp-framework-file-manageraws-glue-hudi-odp-framework-file-processoraws-glue-hudi-odp-framework-config-manager
Với phương pháp mô-đun này, bạn có thể triển khai độc lập các thành phần vào môi trường hồ dữ liệu của mình bằng cách làm theo các yêu cầu ưu tiên của bạn. Quy trình CI / CD. Như được minh họa trong sơ đồ trước, các thành phần này được triển khai cùng với giải pháp CDC.
Thành phần 1: Trình quản lý tệp
Trình quản lý tệp phát hiện các tệp do quy trình CDC như AWS DMS phát ra và theo dõi chúng theo cách Máy phát điện Amazon bàn. Như thể hiện trong sơ đồ sau, nó bao gồm một Sự kiện Amazon quy tắc sự kiện, một Dịch vụ xếp hàng đơn giản trên Amazon hàng đợi (Amazon SQS), một AWS Lambda hàm và bảng DynamoDB. Quy tắc EventBridge sử dụng Thông báo sự kiện của Amazon S3 để phát hiện sự xuất hiện của các tệp CDC trong nhóm S3. Quy tắc sự kiện chuyển tiếp thông báo sự kiện của đối tượng đến hàng đợi SQS dưới dạng tin nhắn. Hàm Lambda Trình quản lý tệp sử dụng các thông báo đó, phân tích cú pháp siêu dữ liệu và chèn siêu dữ liệu vào bảng DynamoDB odpf_file_tracker. Sau đó, những bản ghi này sẽ được xử lý bởi Bộ xử lý tệp mà chúng ta sẽ thảo luận trong phần tiếp theo.
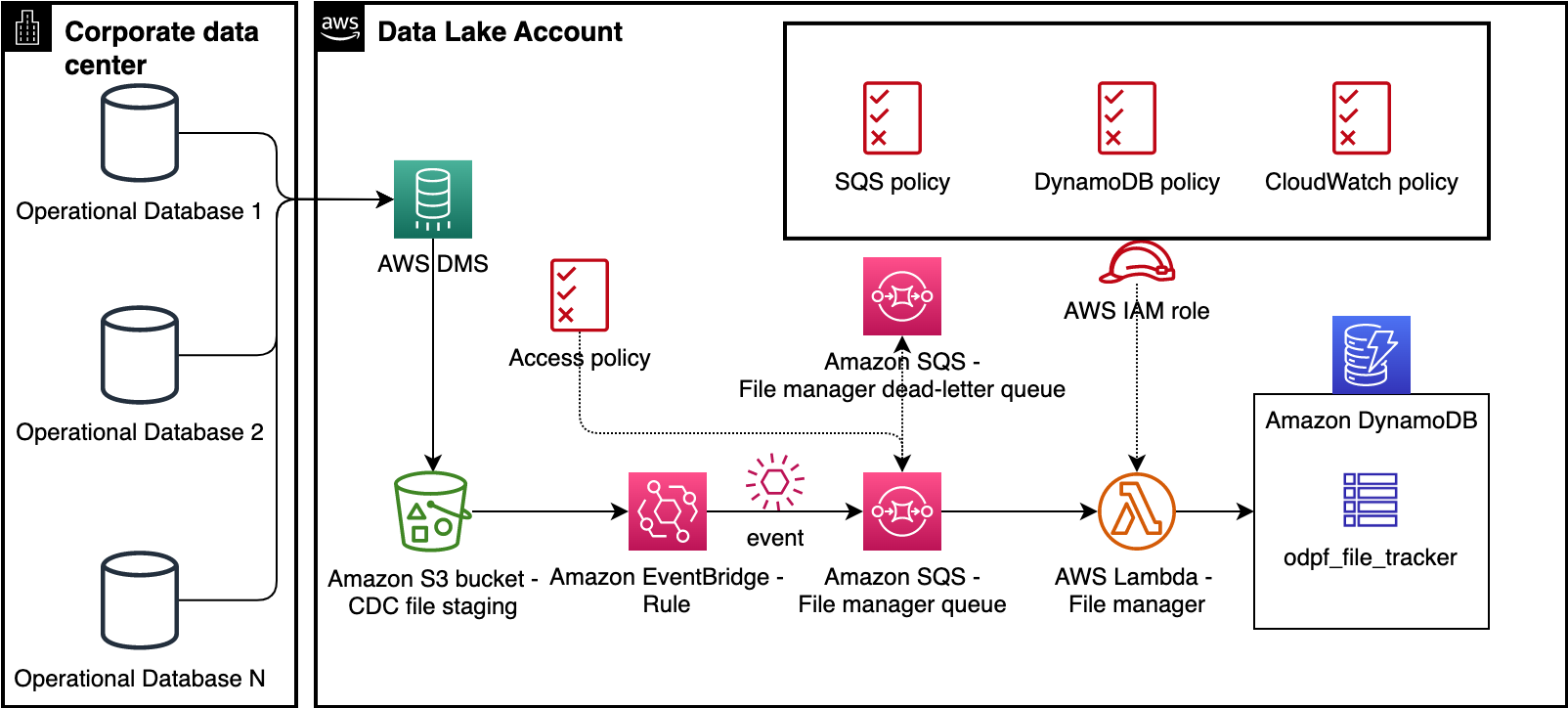
Thành phần 2: Bộ xử lý tệp
Bộ xử lý tệp là đặc điểm của khung ODP. Nó xử lý các tệp từ vùng lưu trữ S3, tạo các tập dữ liệu phù hợp với nguồn trong vùng lưu trữ S3 thô và thêm hoặc cập nhật siêu dữ liệu cho các tập dữ liệu (bảng AWS Glue) trong Danh mục dữ liệu AWS Glue.
Chúng tôi sử dụng thuật ngữ sau khi thảo luận về Bộ xử lý tệp:
- Làm mới nhịp – Điều này thể hiện tần suất nhập dữ liệu (ví dụ: 10 phút). Nó thường đi kèm với loại nhân viên AWS Glue (một trong các loại G.1X, G.2X, G.4X, G.8X, G.025X, v.v.) và kích thước lô.
- Cấu hình bảng – Điều này bao gồm cấu hình Hudi (khóa chính, khóa phân vùng, khóa kết hợp sẵn và loại bảng (Sao chép trên Viết or Hợp nhất khi đọc)), chế độ lưu trữ dữ liệu bảng (ảnh chụp nhanh lịch sử hoặc hiện tại), bộ chứa S3 dùng để lưu trữ các tập dữ liệu căn chỉnh theo nguồn, tên cơ sở dữ liệu AWS Glue, tên bảng AWS Glue và nhịp làm mới.
- Kích thước lô – Giá trị số này dùng để chia các bảng thành các lô nhỏ hơn và xử lý song song các tệp CDC tương ứng của chúng. Ví dụ: cấu hình gồm 50 bảng với nhịp làm mới là 10 phút và kích thước lô 5 bảng sẽ tạo ra tổng cộng 10 lần chạy tác vụ AWS Glue, mỗi lần xử lý tệp CDC cho 5 bảng.
- Chế độ lưu trữ dữ liệu bảng – Có hai lựa chọn:
- Lịch sử – Bảng này trong hồ dữ liệu lưu trữ các cập nhật lịch sử cho các bản ghi (luôn nối thêm).
- Ảnh chụp nhanh hiện tại – Bảng này trong hồ dữ liệu lưu trữ các bản ghi (upsert) phiên bản mới nhất có khả năng sử dụng Hudi du hành thời gian để cập nhật lịch sử.
- Máy trạng thái xử lý tập tin – Nó xử lý các tệp CDC thuộc các bảng có chung nhịp làm mới.
- Liên kết quy tắc EventBridge với máy trạng thái xử lý tệp – Chúng tôi sử dụng quy tắc EventBridge dành riêng cho từng nhịp làm mới với máy trạng thái xử lý tệp làm mục tiêu.
- Công việc xử lý tệp AWS Glue – Đây là công việc trích xuất, chuyển đổi và tải (ETL) AWS Glue dựa trên cấu hình để xử lý các tệp CDC cho một hoặc nhiều bảng.
Bộ xử lý tệp được triển khai như một máy trạng thái sử dụng Chức năng bước AWS. Hãy sử dụng một ví dụ để hiểu điều này. Sơ đồ sau đây minh họa máy trạng thái Bộ xử lý tệp đang chạy với cấu hình bao gồm 18 bảng vận hành, nhịp làm mới là 10 phút, kích thước lô là 5 và loại nhân viên AWS Glue là G.1X.
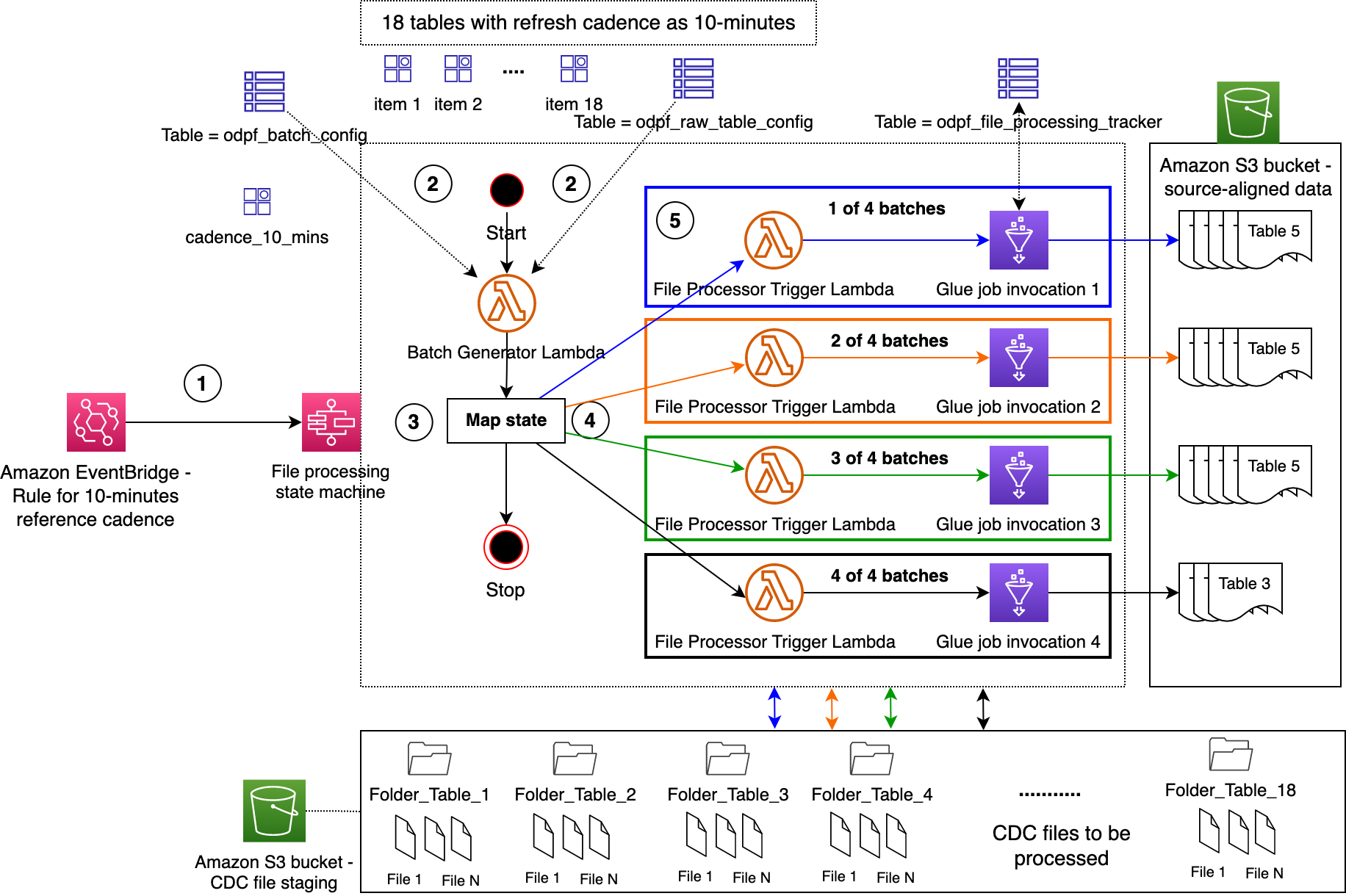
Quy trình làm việc bao gồm các bước sau:
- Quy tắc EventBridge kích hoạt máy trạng thái Bộ xử lý tệp 10 phút một lần.
- Là trạng thái đầu tiên trong máy trạng thái, hàm Lambda Batch Manager đọc cấu hình từ các bảng DynamoDB.
- Hàm Lambda tạo bốn lô: ba trong số đó sẽ được ánh xạ tới năm bảng hoạt động, mỗi lô và lô thứ tư được ánh xạ tới ba bảng hoạt động. Sau đó, nó cung cấp các lô cho Step Functions Bản đồ nhà nước.
- Đối với mỗi mục ở trạng thái Bản đồ, hàm Lambda Trình kích hoạt bộ xử lý tệp sẽ được gọi, từ đó chạy tác vụ AWS Glue của Bộ xử lý tệp.
- Mỗi tác vụ AWS Glue thực hiện các hành động sau:
- Kiểm tra trạng thái của một bảng vận hành và lấy khóa khi nó không được xử lý bởi bất kỳ công việc nào khác. Các
odpf_file_processing_trackerBảng DynamoDB được sử dụng cho mục đích này. Khi có được khóa, nó sẽ chèn một bản ghi vào bảng DynamoDB với trạng tháiupdating_tablelần đầu tiên; nếu không, nó sẽ cập nhật bản ghi. - Xử lý các tệp CDC cho bảng vận hành nhất định từ bộ chứa tổ chức S3 và tạo tập dữ liệu phù hợp với nguồn trong bộ chứa thô S3. Nó cũng cập nhật siêu dữ liệu kỹ thuật trong Danh mục dữ liệu AWS Glue.
- Cập nhật trạng thái của bảng vận hành thành
completedtrongodpf_file_processing_trackerbàn. Trong trường hợp xảy ra lỗi xử lý, nó sẽ cập nhật trạng thái thành Refresh_error và ghi lại dấu vết ngăn xếp. - Nó cũng chèn bản ghi này vào
odpf_file_processing_tracker_historyBảng DynamoDB cùng với các chi tiết bổ sung như chèn, cập nhật và xóa số lượng hàng. - Di chuyển các bản ghi thuộc về các tệp CDC đã được xử lý thành công từ
odpf_file_trackerđếnodpf_file_tracker_historybàn vớifile_ingestion_statusđặt thànhraw_file_processed. - Di chuyển đến bảng hoạt động tiếp theo trong lô nhất định.
- Lưu ý: việc không xử lý các tệp CDC cho một trong các bảng hoạt động của một lô nhất định không ảnh hưởng đến việc xử lý các bảng hoạt động khác.
- Kiểm tra trạng thái của một bảng vận hành và lấy khóa khi nó không được xử lý bởi bất kỳ công việc nào khác. Các
Thành phần 3: Trình quản lý cấu hình
Trình quản lý cấu hình được sử dụng để chèn chi tiết cấu hình vào odpf_batch_config và odpf_raw_table_config những cái bàn. Để bài viết này ngắn gọn, chúng tôi cung cấp hai mẫu kiến trúc trong kho mã và để lại chi tiết triển khai cho bạn.
Tổng quan về giải pháp
Hãy kiểm tra khung ODP bằng cách sao chép dữ liệu từ 18 bảng vận hành sang hồ dữ liệu và tạo các bộ dữ liệu phù hợp với nguồn với nhịp làm mới 10 phút. Chúng tôi sử dụng Dịch vụ cơ sở dữ liệu quan hệ của Amazon (Amazon RDS) dành cho MySQL để thiết lập cơ sở dữ liệu hoạt động với 18 bảng, tải lên tập dữ liệu New York City Taxi – Yellow Trip Data, thiết lập AWS DMS để sao chép dữ liệu sang Amazon S3, xử lý các tệp bằng khung và cuối cùng xác thực dữ liệu bằng Amazon Athena.
Tạo nhóm S3
Để biết hướng dẫn về cách tạo nhóm S3, hãy tham khảo Tạo một thùng. Đối với bài đăng này, chúng tôi tạo các nhóm sau:
odpf-demo-staging-EXAMPLE-BUCKET– Bạn sẽ sử dụng điều này để di chuyển dữ liệu vận hành bằng AWS DMSodpf-demo-raw-EXAMPLE-BUCKET– Bạn sẽ sử dụng điều này để lưu trữ các tập dữ liệu phù hợp với nguồnodpf-demo-code-artifacts-EXAMPLE-BUCKET– Bạn sẽ sử dụng điều này để lưu trữ các tạo phẩm mã
Triển khai Trình quản lý tệp và Bộ xử lý tệp
Triển khai Trình quản lý tệp và Bộ xử lý tệp bằng cách làm theo hướng dẫn từ điều này README và điều này README, tương ứng.
Thiết lập Amazon RDS cho MySQL
Hoàn thành các bước sau để thiết lập Amazon RDS cho MySQL làm nguồn dữ liệu vận hành:
- Cung cấp Amazon RDS cho MySQL. Để biết hướng dẫn, hãy tham khảo Tạo và kết nối với cơ sở dữ liệu MySQL bằng Amazon RDS.
- Kết nối với phiên bản cơ sở dữ liệu bằng cách sử dụng Bàn làm việc MySQL or thợ lặn.
- Tạo cơ sở dữ liệu (lược đồ) bằng cách chạy lệnh SQL
CREATE DATABASE taxi_trips;. - Tạo 18 bảng bằng cách chạy lệnh SQL trong ops_table_sample_ddl.sql kịch bản.
Điền dữ liệu vào nguồn dữ liệu vận hành
Hoàn thành các bước sau để điền dữ liệu vào nguồn dữ liệu vận hành:
- Để tải xuống tập dữ liệu Taxi Thành phố New York – Dữ liệu chuyến đi màu vàng cho tháng 2021 năm XNUMX (tệp Parquet), hãy điều hướng đến Dữ liệu ghi lại chuyến đi NYC TLC, mở rộng 2021, và lựa chọn Hồ sơ chuyến đi Taxi màu vàng. Một tập tin có tên
yellow_tripdata_2021-01.parquetsẽ được tải xuống máy tính của bạn. - Trên bảng điều khiển Amazon S3, hãy mở nhóm
odpf-demo-staging-EXAMPLE-BUCKETvà tạo một thư mục có tên lànyc_yellow_trip_data. - Tải lên
yellow_tripdata_2021-01.parquettập tin vào thư mục. - Điều hướng đến nhóm
odpf-demo-code-artifacts-EXAMPLE-BUCKETvà tạo một thư mục có tên làglue_scripts. - Tải xuống tệp tin Load_nyc_taxi_data_to_rds_mysql.py từ repo GitHub và tải nó lên thư mục.
- Tạo chính sách AWS Identity and Access Management (IAM) có tên
load_nyc_taxi_data_to_rds_mysql_s3_policy. Để được hướng dẫn, hãy tham khảo Tạo chính sách bằng trình soạn thảo JSON. Sử dụng odpf_setup_test_data_glue_job_s3_policy.json định nghĩa chính sách - Tạo vai trò IAM gọi là
load_nyc_taxi_data_to_rds_mysql_glue_role. Đính kèm chính sách đã tạo ở bước trước. - Trên bảng điều khiển AWS Glue, tạo kết nối cho Amazon RDS for MySQL. Để biết hướng dẫn, hãy tham khảo Thêm kết nối JDBC bằng trình điều khiển JDBC của riêng bạn và Thiết lập VPC để kết nối với kho dữ liệu Amazon RDS qua JDBC cho AWS Glue. Đặt tên kết nối là
odpf_demo_rds_connection. - Trong ngăn điều hướng của bảng điều khiển AWS Glue, chọn Việc làm keo ETL, Trình chỉnh sửa tập lệnh Python Shellvà Tải lên và chỉnh sửa tập lệnh hiện có Dưới Các lựa chọn.
- Chọn tập tin
load_nyc_taxi_data_to_rds_mysql.pyVà chọn Tạo. - Hoàn thành các bước sau để tạo công việc của bạn:
- Cung cấp một tên cho công việc, chẳng hạn như
load_nyc_taxi_data_to_rds_mysql. - Trong Vai trò IAM, chọn
load_nyc_taxi_data_to_rds_mysql_glue_role. - Thiết lập Đơn vị xử lý dữ liệu đến
1/16 DPU. - Theo Thuộc tính nâng cao, Kết nối, hãy chọn kết nối bạn đã tạo trước đó.
- Theo Thông số công việc, thêm các tham số sau:
input_sample_data_path=s3://odpf-demo-staging-EXAMPLE-BUCKET/nyc_yellow_trip_data/yellow_tripdata_2021-01.parquetschema_name=taxi_tripstable_name=table_1rds_connection_name=odpf_demo_rds_connection
- Chọn Lưu.
- Cung cấp một tên cho công việc, chẳng hạn như
- trên Hoạt động menu, chạy công việc.
- Quay lại MySQL Workbench hoặc DBeaver của bạn và xác thực số lượng bản ghi bằng cách chạy lệnh SQL
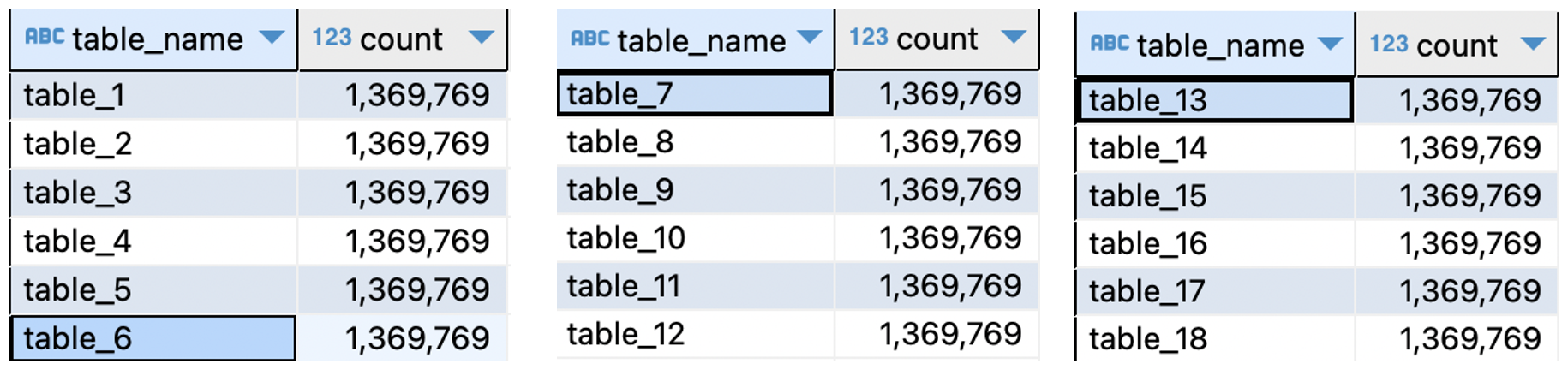
select count(1) row_count from taxi_trips.table_1. Bạn sẽ nhận được một đầu ra của1369769. - Điền vào 17 bảng còn lại bằng cách chạy các lệnh SQL từ populate_17_ops_tables_rds_mysql.sql kịch bản.
- Lấy số hàng từ 18 bảng bằng cách chạy các lệnh SQL từ ops_data_validation_query_rds_mysql.sql kịch bản. Ảnh chụp màn hình sau đây hiển thị đầu ra.
Định cấu hình bảng DynamoDB
Hoàn thành các bước sau để định cấu hình bảng DynamoDB:
- Tải tập tin Load_ops_table_configs_to_ddb.py từ repo GitHub và tải nó lên thư mục
glue_scriptstrong nhóm S3odpf-demo-code-artifacts-EXAMPLE-BUCKET. - Tạo một chính sách IAM có tên là
load_ops_table_configs_to_ddb_ddb_policy. Sử dụng odpf_setup_test_data_glue_job_ddb_policy.json định nghĩa chính sách - Tạo vai trò IAM có tên
load_ops_table_configs_to_ddb_glue_role. Đính kèm chính sách đã tạo ở bước trước. - Trên bảng điều khiển AWS Glue, hãy chọn Việc làm keo ETL, Trình chỉnh sửa tập lệnh Python Shellvà Tải lên và chỉnh sửa tập lệnh hiện có Dưới Các lựa chọn.
- Chọn tập tin
load_ops_table_configs_to_ddb.pyVà chọn Tạo. - Hoàn thành các bước sau để tạo công việc:
- Cung cấp một tên, Chẳng hạn như
load_ops_table_configs_to_ddb. - Trong Vai trò IAM, chọn
load_ops_table_configs_to_ddb_glue_role. - Thiết lập Đơn vị xử lý dữ liệu đến
1/16 DPU. - Theo Thông số công việc, thêm các tham số sau
batch_config_ddb_table_name=odpf_batch_configraw_table_config_ddb_table_name=odpf_demo_taxi_trips_rawaws_region= ví dụ,us-west-1
- Chọn Lưu.
- Cung cấp một tên, Chẳng hạn như
- trên Hoạt động menu, chạy công việc.
- Trên bảng điều khiển DynamoDB, lấy số lượng mục từ các bảng. Bạn sẽ tìm thấy 1 mục trong
odpf_batch_configbảng và 18 mục trongodpf_demo_taxi_trips_rawbảng.
Thiết lập cơ sở dữ liệu trong AWS Glue
Hoàn thành các bước sau để tạo cơ sở dữ liệu:
- Trên bảng điều khiển AWS Keo, bên dưới Danh mục dữ liệu trong ngăn điều hướng, chọn Cơ sở dữ liệu.
- Tạo một cơ sở dữ liệu có tên
odpf_demo_taxi_trips_raw.
Thiết lập AWS DMS cho CDC
Hoàn thành các bước sau để thiết lập AWS DMS cho CDC:
- Tạo phiên bản sao chép AWS DMS. Đối với Lớp sơ thẩm, chọn dms.t3.medium.
- Tạo điểm cuối nguồn cho Amazon RDS cho MySQL.
- Tạo điểm cuối mục tiêu cho Amazon S3. Để định cấu hình cài đặt điểm cuối S3, hãy sử dụng định nghĩa JSON từ dms_s3_endpoint_setting.json.
- Tạo tác vụ AWS DMS.
- Sử dụng điểm cuối nguồn và đích được tạo ở các bước trước.
- Để tạo quy tắc ánh xạ tác vụ AWS DMS, hãy sử dụng định nghĩa JSON từ dms_task_mapping_rules.json.
- Theo Cấu hình khởi động tác vụ di chuyển, lựa chọn Tự động tạo.
- Khi tác vụ AWS DMS bắt đầu chạy, bạn sẽ thấy bản tóm tắt tác vụ tương tự như ảnh chụp màn hình sau.

- Trong phần Thống kê bảng, bạn sẽ thấy kết quả tương tự như ảnh chụp màn hình sau. Ở đây, các hàng Toàn tải và Tổng số hàng là những số liệu quan trọng có số lượng phải khớp với khối lượng bản ghi của 18 bảng trong nguồn dữ liệu vận hành.
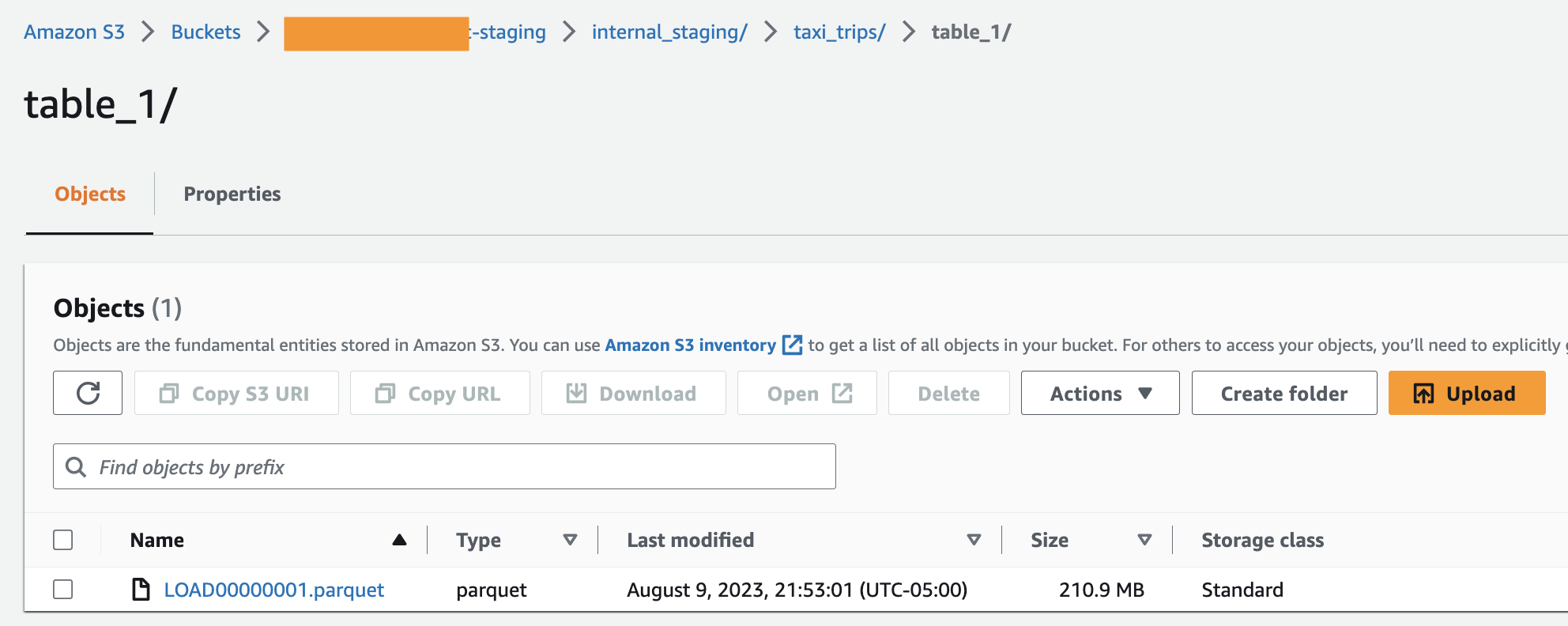
- Sau khi hoàn thành tải đầy đủ thành công, bạn sẽ tìm thấy các tệp Parquet trong nhóm lưu trữ S3—một tệp Parquet trên mỗi bảng trong một thư mục chuyên dụng, tương tự như ảnh chụp màn hình sau. Tương tự, bạn sẽ tìm thấy 17 thư mục như vậy trong nhóm.
Đầu ra của Trình quản lý tệp
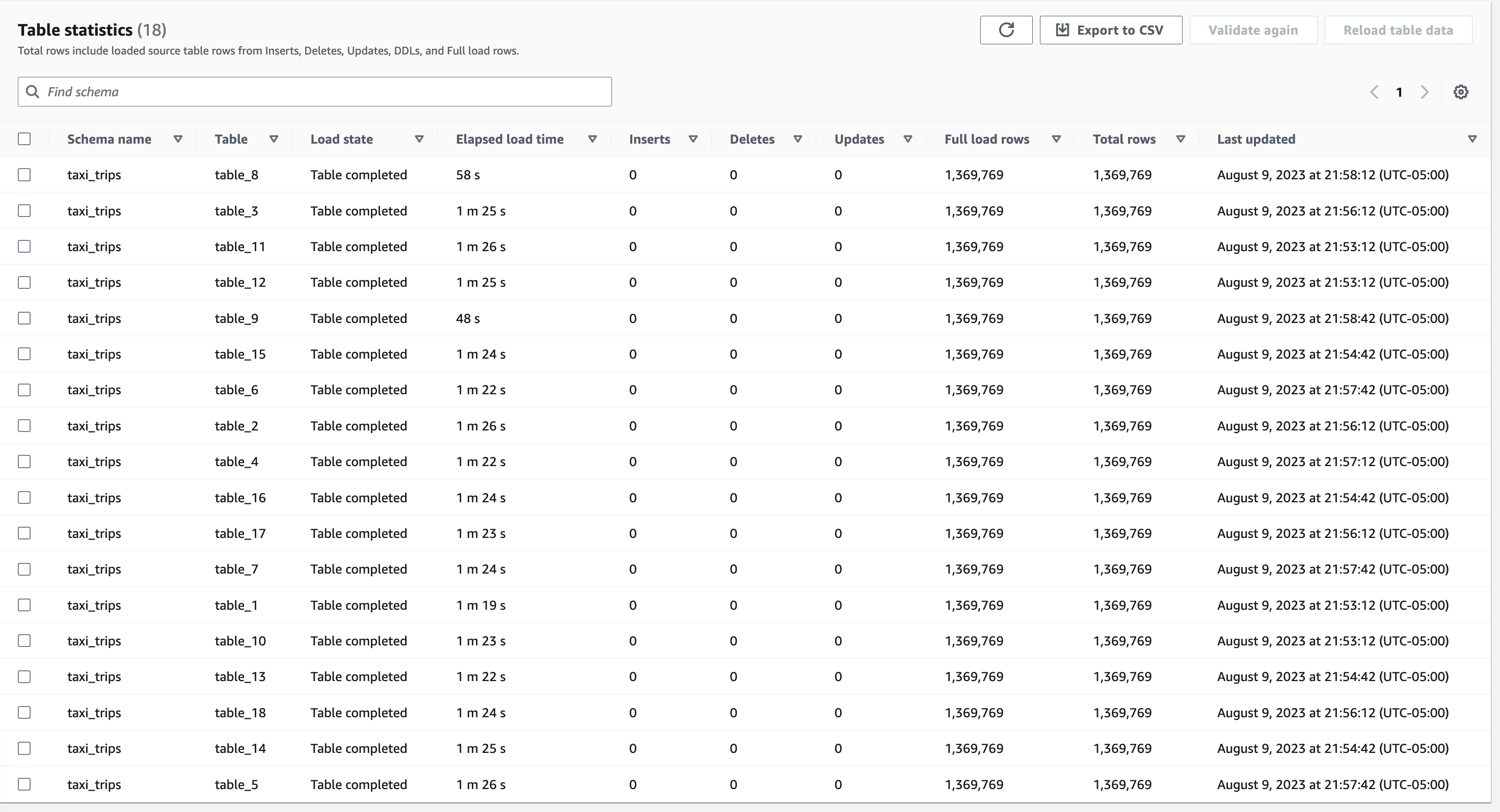
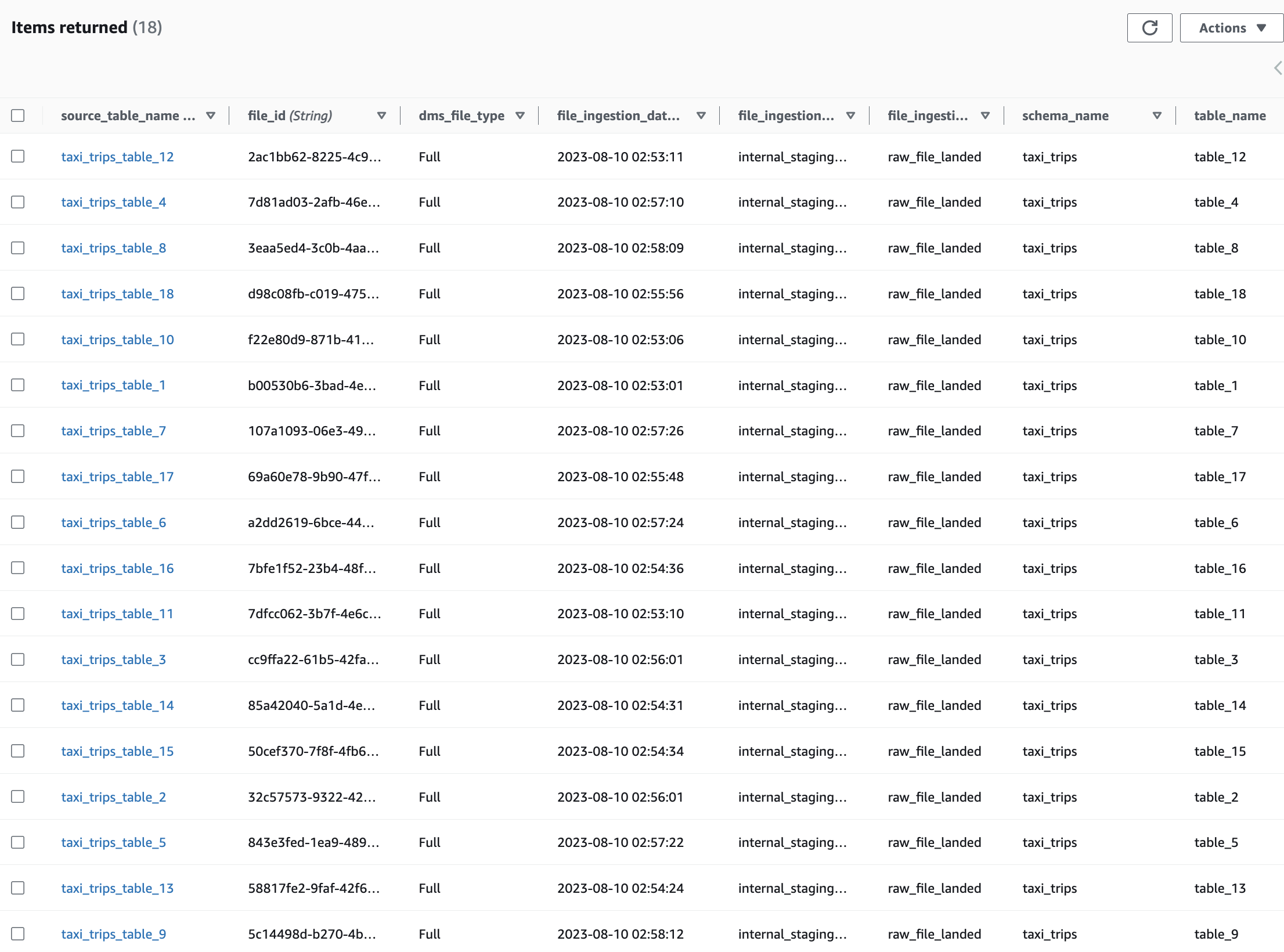
Hàm Lambda Trình quản lý tệp sử dụng các thông báo từ hàng đợi SQS, trích xuất siêu dữ liệu cho các tệp CDC và chèn một mục trên mỗi tệp vào odpf_file_tracker Bảng DynamoDB. Khi bạn kiểm tra các mục, bạn sẽ tìm thấy 18 mục có file_ingestion_status đặt thành raw_file_landed, như thể hiện trong ảnh chụp màn hình sau đây.
Đầu ra của bộ xử lý tệp
- Vào phút thứ mười tiếp theo (kể từ khi kích hoạt quy tắc EventBridge), quy tắc sự kiện sẽ kích hoạt máy trạng thái Bộ xử lý tệp. Trên bảng điều khiển Step Functions, bạn sẽ nhận thấy máy trạng thái được gọi, như minh họa trong ảnh chụp màn hình sau.

- Như minh họa trong ảnh chụp màn hình sau, hàm Lambda của Trình tạo hàng loạt tạo bốn lô và xây dựng trạng thái Bản đồ để chạy song song hàm Lambda Trình kích hoạt bộ xử lý tệp.

- Sau đó, hàm Lambda Trình kích hoạt bộ xử lý tệp sẽ chạy Công việc keo của bộ xử lý tệp, như minh họa trong ảnh chụp màn hình sau.

- Sau đó, bạn sẽ nhận thấy rằng Công việc dán bộ xử lý tệp sẽ tạo các tập dữ liệu căn chỉnh theo nguồn ở định dạng Hudi trong nhóm thô S3. Đối với Bảng 1, bạn sẽ thấy kết quả đầu ra tương tự như ảnh chụp màn hình sau. Sẽ có 17 thư mục như vậy trong nhóm thô S3.

- Cuối cùng, trong Danh mục dữ liệu AWS Glue, bạn sẽ thấy 18 bảng được tạo trong
odpf_demo_taxi_trips_rawcơ sở dữ liệu, tương tự như ảnh chụp màn hình sau.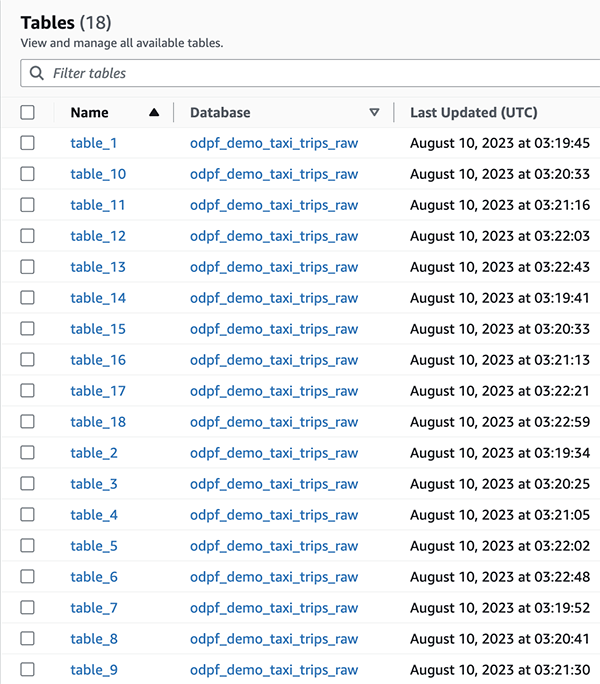
Xác nhận dữ liệu
Hoàn thành các bước sau để xác thực dữ liệu:
- Trên bảng điều khiển Amazon Athena, hãy mở trình soạn thảo truy vấn và chọn một nhóm làm việc hoặc tạo một nhóm làm việc mới.
- Chọn
AwsDataCatalogcho Nguồn dữ liệu vàodpf_demo_taxi_trips_rawcho Cơ sở dữ liệu. - Chạy raw_data_validation_query_athena.sql Truy vấn SQL. Bạn sẽ nhận được kết quả tương tự như ảnh chụp màn hình sau.

Tóm tắt xác nhận: Số lượng trong Amazon Athena khớp với số lượng của các bảng vận hành và điều đó chứng tỏ rằng khung ODP đã xử lý thành công tất cả các tệp và bản ghi. Điều này kết thúc bản demo. Để kiểm tra các kịch bản bổ sung, hãy tham khảo Thử nghiệm mở rộng trong kho mã.
Kết quả
Hãy xem lại cách khung ODP giải quyết các yêu cầu nói trên.
- Như đã thảo luận trước đó trong bài đăng này, bằng cách nhóm các bảng một cách hợp lý theo nhịp làm mới và liên kết chúng với các quy tắc EventBridge, chúng tôi đảm bảo rằng các bảng căn chỉnh nguồn được làm mới bằng các tác vụ AWS Glue của Bộ xử lý tệp. Với cài đặt cấu hình loại nhân viên AWS Glue, chúng tôi đã chọn các tài nguyên điện toán phù hợp trong khi chạy các tác vụ AWS Glue (các phiên bản của tác vụ AWS Glue).
- Bằng cách áp dụng các cấu hình dành riêng cho bảng (từ
odpf_batch_configvàodpf_raw_table_config) một cách linh hoạt, chúng tôi có thể sử dụng một tác vụ AWS Glue để xử lý các tệp CDC cho 18 bảng. - Bạn có thể sử dụng khung này để hỗ trợ nhiều trường hợp sử dụng di chuyển dữ liệu yêu cầu di chuyển dữ liệu nhanh hơn từ hệ thống lưu trữ tại chỗ sang kho dữ liệu hoặc nền tảng phân tích trên AWS. Bạn có thể sử dụng lại Trình quản lý tệp như hiện tại và tùy chỉnh Bộ xử lý tệp để hoạt động với các khung lưu trữ khác như tảng băng Apache, Hồ Deltavà các kho lưu trữ dữ liệu được xây dựng có mục đích như Amazon cực quang và Amazon RedShift.
- Để hiểu làm thế nào khung ODP đáp ứng tiêu chí thiết kế khắc phục thảm họa (DR) của công ty, trước tiên chúng ta cần hiểu chiến lược kiến trúc DR ở mức cao. Chiến lược kiến trúc DR có các khía cạnh sau:
- Một tài khoản AWS và hai Khu vực AWS được sử dụng cho môi trường chính và phụ.
- Cơ sở hạ tầng hồ dữ liệu ở Khu vực thứ cấp được giữ đồng bộ với cơ sở hạ tầng ở Khu vực chính.
- Dữ liệu được lưu trữ trong các nhóm S3, dữ liệu siêu dữ liệu được lưu trữ trong Danh mục dữ liệu AWS Glue và các biện pháp kiểm soát quyền truy cập trong Lake Formation được sao chép từ Khu vực chính sang Khu vực phụ.
- Các hệ thống nguồn và đích hồ dữ liệu có môi trường DR tương ứng.
- Công cụ CI/CD (kiểm soát phiên bản, máy chủ CI, v.v.) phải được cung cấp ở mức độ sẵn sàng cao.
- Nhóm DevOps cần có khả năng triển khai Đường ống CI / CD của các khung phân tích (chẳng hạn như khung ODP này) sang Khu vực chính hoặc Khu vực phụ.
- Như bạn có thể tưởng tượng, khắc phục thảm họa trên AWS là một chủ đề rộng lớn, vì vậy chúng tôi tiếp tục thảo luận đến khía cạnh thiết kế cuối cùng.
Bằng cách thiết kế khung ODP với ba thành phần và cấu hình bên ngoài bảng vận hành để Bảng toàn cầu của DynamoDB, công ty đã có thể triển khai các thành phần khung cho Khu vực phụ (trong trường hợp hiếm hoi xảy ra lỗi ở một Khu vực) và tiếp tục xử lý các tệp CDC từ thời điểm được xử lý lần cuối ở Khu vực chính. Do dữ liệu kiểm tra xử lý và theo dõi tệp CDC được sao chép sang các bảng bản sao DynamoDB ở Khu vực phụ nên vi dịch vụ Trình quản lý tệp và Bộ xử lý tệp có thể chạy liền mạch.
Làm sạch
Khi kiểm tra xong khung này, bạn có thể xóa tài nguyên AWS được cung cấp để tránh phải trả thêm phí.
Kết luận
Trong bài đăng này, chúng tôi đã lấy một trường hợp sử dụng xử lý dữ liệu vận hành trong thế giới thực và giới thiệu cho bạn khung mà chúng tôi đã phát triển tại AWS ProServe. Chúng tôi hy vọng bài viết này và framework xử lý dữ liệu vận hành bằng AWS Glue và Apache Hudi sẽ đẩy nhanh hành trình tích hợp cơ sở dữ liệu vận hành vào nền tảng dữ liệu hiện đại được xây dựng trên AWS của bạn.
Giới thiệu về tác giả
 Ravi Itha là Cố vấn chính tại AWS Professional Services với chuyên môn về dữ liệu và phân tích, đồng thời có kiến thức tổng quát về phát triển ứng dụng. Ravi giúp khách hàng thực hiện các sáng kiến chiến lược dữ liệu doanh nghiệp trong các ngành bảo hiểm, hàng không, dược phẩm và dịch vụ tài chính. Trong nhiệm kỳ 6 năm của mình tại Amazon, Ravi đã giúp cộng đồng nhà xây dựng AWS bằng cách xuất bản khoảng 15 giải pháp nguồn mở (có thể truy cập qua Xử lý GitHub), bốn blog và kiến trúc tham khảo. Ngoài công việc, anh ấy đam mê đọc Hệ thống Kiến thức Ấn Độ và thực hành các tư thế Yoga.
Ravi Itha là Cố vấn chính tại AWS Professional Services với chuyên môn về dữ liệu và phân tích, đồng thời có kiến thức tổng quát về phát triển ứng dụng. Ravi giúp khách hàng thực hiện các sáng kiến chiến lược dữ liệu doanh nghiệp trong các ngành bảo hiểm, hàng không, dược phẩm và dịch vụ tài chính. Trong nhiệm kỳ 6 năm của mình tại Amazon, Ravi đã giúp cộng đồng nhà xây dựng AWS bằng cách xuất bản khoảng 15 giải pháp nguồn mở (có thể truy cập qua Xử lý GitHub), bốn blog và kiến trúc tham khảo. Ngoài công việc, anh ấy đam mê đọc Hệ thống Kiến thức Ấn Độ và thực hành các tư thế Yoga.
 Srinivas Kandi là Kiến trúc sư dữ liệu tại AWS Professional Services. Ông dẫn đầu các hoạt động tương tác với khách hàng liên quan đến hồ dữ liệu, phân tích và hiện đại hóa kho dữ liệu. Anh ấy thích đọc lịch sử và các nền văn minh.
Srinivas Kandi là Kiến trúc sư dữ liệu tại AWS Professional Services. Ông dẫn đầu các hoạt động tương tác với khách hàng liên quan đến hồ dữ liệu, phân tích và hiện đại hóa kho dữ liệu. Anh ấy thích đọc lịch sử và các nền văn minh.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- ChartPrime. Nâng cao trò chơi giao dịch của bạn với ChartPrime. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/simplify-operational-data-processing-in-data-lakes-using-aws-glue-and-apache-hudi/

