Name entity recognition (NER) is the process of extracting information of interest, called entities, from structured or unstructured text. Manually identifying all mentions of specific types of information in documents is extremely time-consuming and labor-intensive. Some examples include extracting players and positions in an NFL game summary, products mentioned in an AWS keynote transcript, or key names from an article on a favorite tech company. This process must be repeated for every new document and entity type, making it impractical for processing large volumes of documents at scale. With more access to vast amounts of reports, books, articles, journals, and research papers than ever before, swiftly identifying desired information in large bodies of text is becoming invaluable.
Traditional neural network models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. This makes adopting and scaling these approaches burdensome for many applications. However, new capabilities of large language models (LLMs) enable high-accuracy NER across diverse entity types without the need for entity-specific fine-tuning. By using the model’s broad linguistic understanding, you can perform NER on the fly for any specified entity type. This capability is called zero-shot NER and enables the rapid deployment of NER across documents and many other use cases. This ability to extract specified entity mentions without costly tuning unlocks scalable entity extraction and downstream document understanding.
In this post, we cover the end-to-end process of using LLMs on Amazon Bedrock for the NER use case. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. In particular, we show how to use Amazon Textract to extract text from documents such PDFs or image files, and use the extracted text along with user-defined custom entities as input to Amazon Bedrock to conduct zero-shot NER. We also touch on the usefulness of text truncation for prompts using Amazon Comprehend, along with the challenges, opportunities, and future work with LLMs and NER.
Solution overview
In this solution, we implement zero-shot NER with LLMs using the following key services:
- Amazon Textract – Extracts textual information from the input document.
- Amazon Comprehend (optional) – Identifies predefined entities such as names of people, dates, and numeric values. You can use this feature to limit the context over which the entities of interest are detected.
- Amazon Bedrock – Calls an LLM to identify entities of interest from the given context.
The following diagram illustrates the solution architecture.
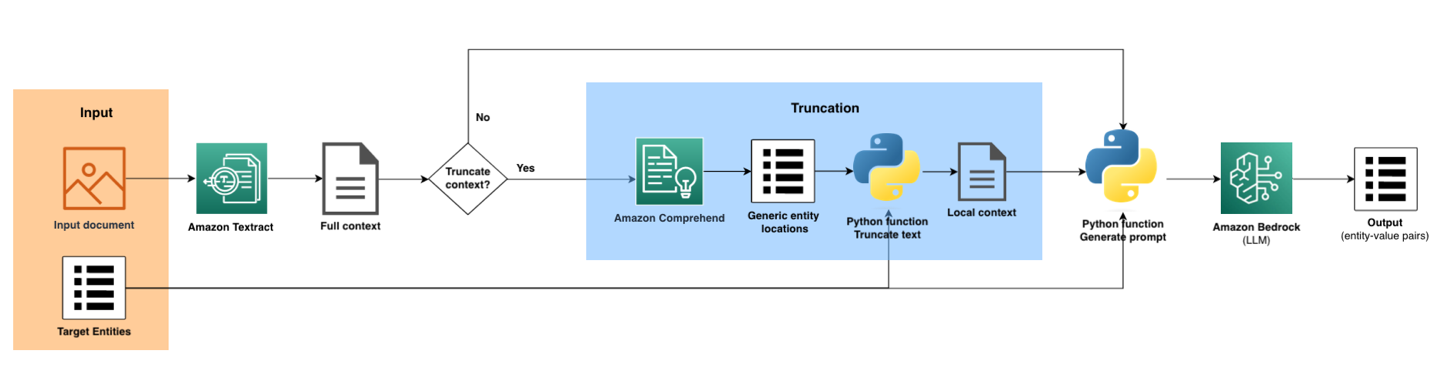
The main inputs are the document image and target entities. The objective is to find values of the target entities within the document. If the truncation path is chosen, the pipeline uses Amazon Comprehend to reduce the context. The output of LLM is postprocessed to generate the output as entity-value pairs.
For example, if given the AWS Wikipedia page as the input document, and the target entities as AWS service names and geographic locations, then the desired output format would be as follows:
- AWS service names: <all AWS service names mentioned in the Wikipedia page>
- Geographic locations: <all geographic location names within the Wikipedia page>
In the following sections, we describe the three main modules to accomplish this task. For this post, we used Amazon SageMaker notebooks with ml.t3.medium instances along with Amazon Textract, Amazon Comprehend, and Amazon Bedrock.
Extract context
Context is the information that is taken from the document and where the values to the queried entities are found. When consuming a full document (full context), context significantly increases the input token count to the LLM. We provide an option of using the entire document or local context around relevant parts of the document, as defined by the user.
First, we extract context from the entire document using Amazon Textract. The code below uses the amazon-textract-caller library as a wrapper for the Textract API calls. You need to install the library first:
Then, for a single page document such as a PNG or JPEG file use the following code to extract the full context:
Note that PDF input documents have to be on a S3 bucket when using call_textract function. For multi-page TIFF files make sure to set force_async_api=True.
Truncate context (optional)
When the user-defined custom entities to be extracted are sparse compared to the full context, we provide an option to identify relevant local context and then look for the custom entities within the local context. To do so, we use generic entity extraction with Amazon Comprehend. This is assuming that the user-defined custom entity is a child of one of the default Amazon Comprehend entities, such as "name", "location", "date", or "organization". For example, "city" is a child of "location". We extract the default generic entities through the AWS SDK for Python (Boto3) as follows:
It outputs a list of dictionaries containing the entity as “Type”, the value as “Text”, along with other information such as “Score”, “BeginOffset”, and “EndOffset”. For more details, see DetectEntities. The following is an example output of Amazon Comprehend entity extraction, which provides the extracted generic entity-value pairs and location of the value within the text.
The extracted list of generic entities may be more exhaustive than the queried entities, so a filtering step is necessary. For example, a queried entity is “AWS revenue” and generic entities contain “quantity”, “location”, “person”, and so on. To only retain the relevant generic entity, we define the mapping and apply the filter as follows:
After we identify a subset of generic entity-value pairs, we want to preserve the local context around each pair and mask out everything else. We do this by applying a buffer to “BeginOffset” and “EndOffset” to add extra context around the offsets identified by Amazon Comprehend:
We also merge any overlapping offsets to avoid duplicating context:
Finally, we truncate the full context using the buffered and merged offsets:
An additional step for truncation is to use the Amazon Textract Layout feature to narrow the context to a relevant text block within the document. Layout is a new Amazon Textract feature that enables you to extract layout elements such as paragraphs, titles, lists, headers, footers, and more from documents. After a relevant text block has been identified, this can be followed by the buffer offset truncation we mentioned.
Extract entity-value pairs
Given either the full context or the local context as input, the next step is customized entity-value extraction using LLM. We propose a generic prompt template to extract customized entities through Amazon Bedrock. Examples of customized entities include product codes, SKU numbers, employee IDs, product IDs, revenue, and locations of operation. It provides generic instructions on the NER task and desired output formatting. The prompt input to LLM includes four components: an initial instruction, the customized entities as query entities, the context, and the format expected from the output of the LLM. The following is an example of the baseline prompt. The customized entities are incorporated as a list in query entities. This process is flexible to handle a variable number of entities.
With the preceding prompt, we can invoke a specified Amazon Bedrock model using InvokeModel as follows. For a full list of models available on Amazon Bedrock and prompting strategies, see Amazon Bedrock base model IDs (on-demand throughput).
Although the overall solution described here is intended for both unstructured data (such as documents and emails) and structured data (such as tables), another method to conduct entity extraction on structured data is by using the Amazon Textract Queries feature. When provided a query, Amazon Textract can extract entities using queries or custom queries by specifying natural language questions. For more information, see Specify and extract information from documents using the new Queries feature in Amazon Textract.
Use case
To demonstrate an example use case, we use Anthropic Claude-V2 on Amazon Bedrock to generate some text about AWS (as shown in the following figure), saved it as an image to simulate a scanned document, and then used the proposed solution to identify some entities within the text. Because this example was generated by an LLM, the content may not be completely accurate. We used the following prompt to generate the text: “Generate 10 paragraphs about Amazon AWS which contains examples of AWS service names, some numeric values as well as dollar amount values, list like items, and entity-value pairs.”

Let’s extract values for the following target entities:
- Countries where AWS operates
- AWS annual revenue
As shown in the solution architecture, the image is first sent to Amazon Textract to extract the contents as text. Then there are two options:
- No truncation – You can use the whole text along with the target entities to create a prompt for the LLM
- With truncation – You can use Amazon Comprehend to detect generic entities, identify candidate positions of the target entities, and truncate the text to the proximities of the entities
In this example, we ask Amazon Comprehend to identify "location" and "quantity" entities, and we postprocess the output to restrict the text to the neighborhood of identified entities. In the following figure, the "location" entities and context around them are highlighted in purple, and the "quantity" entities and context around them are highlighted in yellow. Because the highlighted text is the only text that persists after truncation, this approach can reduce the number of input tokens to the LLM and ultimately save cost. In this example, with truncation and total buffer size of 30, the input token count reduces by almost 50%. Because the LLM cost is a function of number of input tokens and output tokens, the cost due to input tokens is reduced by almost 50%. See Amazon Bedrock Pricing for more details.

Given the entities and (optionally truncated) context, the following prompt is sent to the LLM:
The following table shows the response of Anthropic Claude-V2 on Amazon Bedrock for different text inputs (again, the document used as input was generated by an LLM and may not be completely accurate). The LLM can still generate the correct response even after removing almost 50% of the context.
| Input text | LLM response |
| Full context |
Countries where AWS operates in: us-east-1 in Northern Virginia, eu-west-1 in Ireland, ap-southeast-1 in Singapore AWS annual revenue: $62 billion |
| Truncated context |
Countries where AWS operates in: us-east-1 in Northern Virginia, eu-west-1 in Ireland, ap-southeast-1 in Singapore AWS annual revenue: $62 billion in annual revenue |
Conclusion
In this post, we discussed the potential for LLMs to conduct NER without being specifically fine-tuned to do so. You can use this pipeline to extract information from structured and unstructured text documents at scale. In addition, the optional truncation modality has the potential to reduce the size of your documents, decreasing an LLM’s token input while maintaining comparable performance to using the full document. Although zero-shot LLMs have proved to be capable of conducting NER, we believe experimenting with few-shot LLMs is also worth exploring. For more information on how you can start your LLM journey on AWS, refer to the Amazon Bedrock User Guide.
About the Authors
 Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems.
Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems.
 Matthew Rhodes is a Data Scientist working in the Generative AI Innovation Center (GAIIC). He specializes in building machine learning pipelines that involve concepts such as natural language processing and computer vision.
Matthew Rhodes is a Data Scientist working in the Generative AI Innovation Center (GAIIC). He specializes in building machine learning pipelines that involve concepts such as natural language processing and computer vision.
 Amin Tajgardoon is an Applied Scientist in the Generative AI Innovation Center (GAIIC). He has an extensive background in computer science and machine learning. In particular, Amin’s focus has been on deep learning and forecasting, prediction explanation methods, model drift detection, probabilistic generative models, and applications of AI in the healthcare domain.
Amin Tajgardoon is an Applied Scientist in the Generative AI Innovation Center (GAIIC). He has an extensive background in computer science and machine learning. In particular, Amin’s focus has been on deep learning and forecasting, prediction explanation methods, model drift detection, probabilistic generative models, and applications of AI in the healthcare domain.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/use-zero-shot-large-language-models-on-amazon-bedrock-for-custom-named-entity-recognition/

