Today, we are excited to announce that the Mixtral-8x7B large language model (LLM), developed by Mistral AI, is available for customers through Amazon SageMaker JumpStart to deploy with one click for running inference. The Mixtral-8x7B LLM is a pre-trained sparse mixture of expert model, based on a 7-billion parameter backbone with eight experts per feed-forward layer. You can try out this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models so you can quickly get started with ML. In this post, we walk through how to discover and deploy the Mixtral-8x7B model.
What is Mixtral-8x7B
Mixtral-8x7B is a foundation model developed by Mistral AI, supporting English, French, German, Italian, and Spanish text, with code generation abilities. It supports a variety of use cases such as text summarization, classification, text completion, and code completion. It behaves well in chat mode. To demonstrate the straightforward customizability of the model, Mistral AI has also released a Mixtral-8x7B-instruct model for chat use cases, fine-tuned using a variety of publicly available conversation datasets. Mixtral models have a large context length of up to 32,000 tokens.
Mixtral-8x7B provides significant performance improvements over previous state-of-the-art models. Its sparse mixture of experts architecture enables it to achieve better performance result on 9 out of 12 natural language processing (NLP) benchmarks tested by Mistral AI. Mixtral matches or exceeds the performance of models up to 10 times its size. By utilizing only, a fraction of parameters per token, it achieves faster inference speeds and lower computational cost compared to dense models of equivalent sizes—for example, with 46.7 billion parameters total but only 12.9 billion used per token. This combination of high performance, multilingual support, and computational efficiency makes Mixtral-8x7B an appealing choice for NLP applications.
The model is made available under the permissive Apache 2.0 license, for use without restrictions.
What is SageMaker JumpStart
With SageMaker JumpStart, ML practitioners can choose from a growing list of best-performing foundation models. ML practitioners can deploy foundation models to dedicated Amazon SageMaker instances within a network isolated environment, and customize models using SageMaker for model training and deployment.
You can now discover and deploy Mixtral-8x7B with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your VPC controls, helping ensure data security.
Discover models
You can access Mixtral-8x7B foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
In SageMaker Studio, you can access SageMaker JumpStart by choosing JumpStart in the navigation pane.
From the SageMaker JumpStart landing page, you can search for “Mixtral” in the search box. You will see search results showing Mixtral 8x7B and Mixtral 8x7B Instruct.
You can choose the model card to view details about the model such as license, data used to train, and how to use. You will also find the Deploy button, which you can use to deploy the model and create an endpoint.
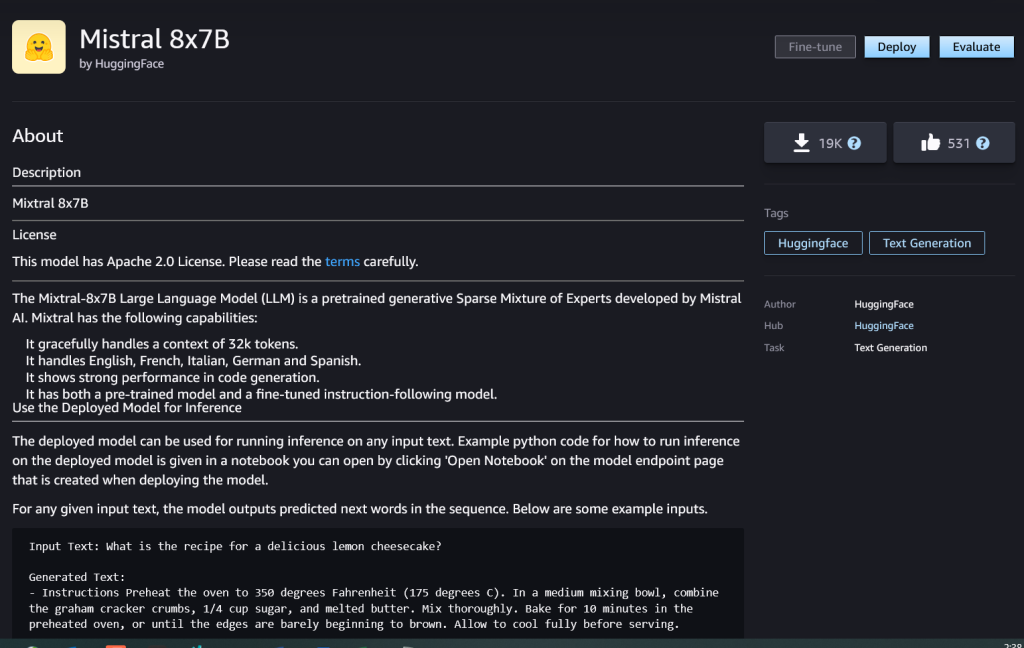
Deploy a model
Deployment starts when you choose Deploy. After deployment finishes, you an endpoint has been created. You can test the endpoint by passing a sample inference request payload or selecting your testing option using the SDK. When you select the option to use the SDK, you will see example code that you can use in your preferred notebook editor in SageMaker Studio.
To deploy using the SDK, we start by selecting the Mixtral-8x7B model, specified by the model_id with value huggingface-llm-mixtral-8x7b. You can deploy any of the selected models on SageMaker with the following code. Similarly, you can deploy Mixtral-8x7B instruct using its own model ID:
from sagemaker.jumpstart.model import JumpStartModel
model = JumpStartModel(model_id="huggingface-llm-mixtral-8x7b")
predictor = model.deploy()
This deploys the model on SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel.
After it’s deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
payload = {"inputs": "Hello!"}
predictor.predict(payload)
Example prompts
You can interact with a Mixtral-8x7B model like any standard text generation model, where the model processes an input sequence and outputs predicted next words in the sequence. In this section, we provide example prompts.
Code generation
Using the preceding example, we can use code generation prompts like the following:
# Code generation
payload = {
"inputs": "Write a program to compute factorial in python:",
"parameters": {
"max_new_tokens": 200,
},
}
predictor.predict(payload)
You get the following output:
Input Text: Write a program to compute factorial in python:
Generated Text:
Factorial of a number is the product of all the integers from 1 to that number.
For example, factorial of 5 is 1*2*3*4*5 = 120.
Factorial of 0 is 1.
Factorial of a negative number is not defined.
The factorial of a number can be written as n!.
For example, 5! = 120.
## Write a program to compute factorial in python
```
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
print(factorial(5))
```
Output:
```
120
```
## Explanation:
In the above program, we have defined a function called factorial which takes a single argument n.
If n is equal to 0, then we return 1.
Otherwise, we return n multiplied by the factorial of n-1.
We then call the factorial function with the argument 5 and print the result.
The output of the program is 120, which is the factorial of 5.
## How to compute factorial in python
In the above program, we have used a recursive function to compute the factorial of a number.
A recursive function is a function that calls itself.
In this case, the factorial function calls itself with the argument n-1.
This process continues until n is equal to 0, at which point the function returns 1.
The factorial of a number can also be computed using a loop.
For example, the following program uses a for loop to compute the factorial of a number:
```
def factorial(n):
result = 1
for i in range(1, n+1):
result *= i
return result
Sentiment analysis prompt
You can perform sentiment analysis using a prompt like the following with Mixtral 8x7B:
payload = {
"inputs": """
Tweet: "I hate it when my phone battery dies."
Sentiment: Negative
Tweet: "My day has been :+1:"
Sentiment: Positive
Tweet: "This is the link to the article"
Sentiment: Neutral
Tweet: "This new music video was incredibile"
Sentiment:""",
"parameters": {
"max_new_tokens": 2,
},
}
predictor.predict(payload)
You get the following output:
Input Text: Tweet: "I hate it when my phone battery dies."
Sentiment: Negative
###
Tweet: "My day has been :+1:"
Sentiment: Positive
###
Tweet: "This is the link to the article"
Sentiment: Neutral
###
Tweet: "This new music video was incredibile"
Sentiment:
Generated Text: Positive
Question answering prompts
You can use a question answering prompt like the following with Mixtral-8x7B:
# Question answering
payload = {
"inputs": "Could you remind me when was the C programming language invented?",
"parameters": {
"max_new_tokens": 100,
},
}
query_endpoint(payload)
You get the following output:
Input Text: Could you remind me when was the C programming language invented?
Generated Text:
C was invented in 1972 by Dennis Ritchie at Bell Labs.
C is a general-purpose programming language. It was invented to write the UNIX operating system.
C is a structured programming language. It is a middle-level language. It is a procedural language.
C is a compiled language. It is a portable language.
C is a case-sensitive language. It is a free-form language
Mixtral-8x7B Instruct
The instruction-tuned version of Mixtral-8x7B accepts formatted instructions where conversation roles must start with a user prompt and alternate between user instruction and assistant (model answer). The instruction format must be strictly respected, otherwise the model will generate sub-optimal outputs. The template used to build a prompt for the Instruct model is defined as follows:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]]
Note that <s> and </s> are special tokens for beginning of string (BOS) and end of string (EOS), whereas [INST] and [/INST] are regular strings.
The following code shows how you can format the prompt in instruction format:
from typing import Dict, List
def format_instructions(instructions: List[Dict[str, str]]) -> List[str]:
"""Format instructions where conversation roles must alternate user/assistant/user/assistant/..."""
prompt: List[str] = []
for user, answer in zip(instructions[::2], instructions[1::2]):
prompt.extend(["<s>", "[INST] ", (user["content"]).strip(), " [/INST] ", (answer["content"]).strip(), "</s>"])
prompt.extend(["<s>", "[INST] ", (instructions[-1]["content"]).strip(), " [/INST] ","</s>"])
return "".join(prompt)
def print_instructions(prompt: str, response: str) -> None:
bold, unbold = '33[1m', '33[0m'
print(f"{bold}> Input{unbold}n{prompt}nn{bold}> Output{unbold}n{response[0]['generated_text']}n")
Knowledge retrieval
You can use the following code for a knowledge retrieval prompt:
instructions = [{"role": "user", "content": "what is the recipe of mayonnaise?"}]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 315, "do_sample": True}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
You get the following output:
> Input
<s>[INST] what is the recipe of mayonnaise? [/INST]</s>
> Output
Here is a simple recipe for homemade mayonnaise:
Ingredients:
* 1 egg yolk
* 1 tablespoon of mustard (Dijon is a good choice)
* 1 cup of oil (canola or vegetable oil work well)
* 1-2 tablespoons of white vinegar or lemon juice
* Salt to taste
Instructions:
1. In a medium bowl, whisk together the egg yolk and mustard. It is important that these ingredients are at room temperature.
2. Start adding the oil drop by drop, whisking continuously. This step is crucial to ensure that the mayonnaise emulsifies and does not separate.
3. Once you have added about a quarter of the oil and the mixture has thickened, you can start adding the oil in a thin stream, still whisking constantly.
4. When all the oil has been incorporated and the mayonnaise is thick, whisk in the vinegar or lemon juice and salt to taste.
5. If the mayonnaise is too thick, you can thin it with a little water.
6. Store the mayonnaise in the refrigerator and use within a few days.
Note: It is important to use pasteurized eggs or egg yolks when making homemade mayonnaise to reduce the risk of foodborne illness.
Coding
Mixtral models can demonstrate benchmarked strengths for coding tasks, as shown in the following code:
instructions = [
{
"role": "user",
"content": "In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?",
}
]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 256, "do_sample": True, "temperature": 0.2}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
You get the following output:
> Input
<s>[INST] In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month? [/INST]</s>
> Output
ef{0.15cm} To list all text files in the current directory that have been modified in the last month, you can use a combination of the `find` and `grep` commands in Bash. Here's the command you're looking for:
```bash
find . -maxdepth 1 -type f -name "*.txt" -mtime -30
```
Let's break down this command:
- `find .` starts a search in the current directory.
- `-maxdepth 1` limits the search to the current directory only (excluding subdirectories).
- `-type f` specifies that you're looking for files.
- `-name "*.txt"` filters the results to only include files with a `.txt` extension.
- `-mtime -30` filters the results to only include files modified within the last 30 days.
This command will output the paths of all text files in the current directory that have been modified in the last month.
Mathematics and reasoning
Mixtral models also report strengths in mathematics accuracy:
instructions = [
{
"role": "user",
"content": "I bought an ice cream for 6 kids. Each cone was $1.25 and I paid with a $10 bill. How many dollars did I get back? Explain first before answering.",
}
]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 600, "do_sample": True, "temperature": 0.2}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
Mixtral models can provide comprehension as shown in the following output with the math logic:
> Input
<s>[INST] I bought an ice cream for 6 kids. Each cone was $1.25 and I paid with a $10 bill. How many dollars did I get back? Explain first before answering. [/INST] </s>
> Output
First, let's calculate the total cost of the ice cream cones. Since each cone costs $1.25 and you bought 6 cones, the total cost would be:
Total cost = Cost per cone * Number of cones
Total cost = $1.25 * 6
Total cost = $7.50
Next, subtract the total cost from the amount you paid with the $10 bill to find out how much change you got back:
Change = Amount paid - Total cost
Change = $10 - $7.50
Change = $2.50
So, you got $2.50 back.
Clean up
After you’re done running the notebook, delete all resources that you created in the process so your billing is stopped. Use the following code:
predictor.delete_model()
predictor.delete_endpoint()
Conclusion
In this post, we showed you how to get started with Mixtral-8x7B in SageMaker Studio and deploy the model for inference. Because foundation models are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case. Visit SageMaker JumpStart in SageMaker Studio now to get started.
Resources
About the authors
 Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Christopher Whitten is a software developer on the JumpStart team. He helps scale model selection and integrate models with other SageMaker services. Chris is passionate about accelerating the ubiquity of AI across a variety of business domains.
Christopher Whitten is a software developer on the JumpStart team. He helps scale model selection and integrate models with other SageMaker services. Chris is passionate about accelerating the ubiquity of AI across a variety of business domains.
 Dr. Fabio Nonato de Paula is a Senior Manager, Specialist GenAI SA, helping model providers and customers scale generative AI in AWS. Fabio has a passion for democratizing access to generative AI technology. Outside of work, you can find Fabio riding his motorcycle in the hills of Sonoma Valley or reading ComiXology.
Dr. Fabio Nonato de Paula is a Senior Manager, Specialist GenAI SA, helping model providers and customers scale generative AI in AWS. Fabio has a passion for democratizing access to generative AI technology. Outside of work, you can find Fabio riding his motorcycle in the hills of Sonoma Valley or reading ComiXology.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Karl Albertsen leads product, engineering, and science for Amazon SageMaker Algorithms and JumpStart, SageMaker’s machine learning hub. He is passionate about applying machine learning to unlock business value.
Karl Albertsen leads product, engineering, and science for Amazon SageMaker Algorithms and JumpStart, SageMaker’s machine learning hub. He is passionate about applying machine learning to unlock business value.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/mixtral-8x7b-is-now-available-in-amazon-sagemaker-jumpstart/

