이것은 Sportradar의 Fred Wu와 공동으로 작성한 게스트 포스트입니다.
스포츠레이더 스포츠, 미디어 및 베팅의 교차점에 있는 세계 최고의 스포츠 기술 회사입니다. 1,700개국에 걸쳐 120개 이상의 스포츠 연맹, 미디어 아울렛, 베팅 운영자 및 소비자 플랫폼이 비즈니스를 강화하기 위해 Sportradar 노하우와 기술에 의존하고 있습니다.
Sportradar는 데이터와 기술을 사용하여 다음을 수행합니다.
- 스포츠북을 관리하는 데 필요한 제품과 서비스로 베팅 운영자를 앞서가게 하십시오.
- 미디어 회사에 팬과 더 많이 소통할 수 있는 도구 제공
- 팀, 리그 및 연맹에 번성하는 데 필요한 데이터 제공
- 사기, 도핑 및 승부조작을 감지하고 방지하여 업계를 깨끗하게 유지하십시오.
이 게시물은 방법을 보여줍니다. 스포츠레이더 중고 아마존 딥 자바 라이브러리 (DJL) AWS와 함께 Amazon Elastic Kubernetes 서비스 (아마존 EKS) 및 아마존 단순 스토리지 서비스 (Amazon S3)는 Java의 필수 도구를 보존하고, 운영 효율성을 최적화하고, 로그 및 시스템 메트릭에 대한 더 나은 성능과 접근성을 제공하여 팀의 생산성을 높이는 프로덕션 준비 기계 학습(ML) 추론 솔루션을 구축합니다.
DJL은 Scala, Kotlin, Clojure와 같은 Java 및 JVM 언어 사용자를 지원하기 위해 처음부터 구축된 딥 러닝 프레임워크입니다. 현재 대부분의 딥 러닝 프레임워크는 Python용으로 구축되어 있지만 점점 더 강력해지는 딥 러닝 기능을 통합하려는 기존 Java 코드 기반을 보유한 많은 Java 개발자와 개발자를 간과하고 있습니다. DJL을 사용하면 이 딥 러닝을 간단하게 통합할 수 있습니다.
이 게시물에서 Sportradar 팀은 그들이 직면한 문제와 DJL을 사용하여 모델 추론 플랫폼을 구축하기 위해 만든 솔루션에 대해 논의합니다.
비즈니스 요구 사항
우리는 Sportradar AI 부서의 미국 분대입니다. 2018년부터 우리 팀은 NFL 및 NCAA 축구용 베팅 제품을 가능하게 하는 다양한 ML 모델을 개발해 왔습니다. 우리는 최근에 XNUMX개의 새로운 모델을 더 개발했습니다.
NFL 및 NCAA의 네 번째 다운 결정 모델은 네 번째 다운 플레이 결과의 확률을 예측합니다. 플레이 결과는 필드 골 시도, 플레이 또는 펀트가 될 수 있습니다.
NFL 및 NCAA의 운전 결과 모델은 현재 운전 결과의 확률을 예측합니다. 드라이브 결과는 전반 종료, 필드 골 시도, 터치다운, 턴오버, 턴오버 다운 또는 펀트가 될 수 있습니다.

당사의 모델은 스프레드, 합계, 승률, 다음 점수 유형, 다음 득점 팀 등을 포함하여 라이브 베팅 시장 목록을 생성하는 다른 모델의 구성 요소입니다.
우리 모델의 비즈니스 요구 사항은 다음과 같습니다.
- 모델 예측기는 사전 훈련된 모델 파일을 한 번 로드할 수 있어야 하며 여러 재생에서 예측을 수행할 수 있어야 합니다.
- 50밀리초 대기 시간 미만의 각 플레이에 대한 확률을 생성해야 합니다.
- 모델 예측기(기능 추출 및 모델 추론)는 다른 팀이 Maven 종속성으로 가져올 수 있도록 Java로 작성해야 합니다.
현장 시스템의 과제
우리가 가진 주요 과제는 Python의 모델 교육과 Java의 모델 추론 사이의 격차를 해소하는 방법입니다. 데이터 과학자는 PyTorch와 같은 도구를 사용하여 Python에서 모델을 훈련하고 모델을 PyTorch 스크립트로 저장합니다. 우리의 원래 계획은 Python에서 모델을 호스팅하고 gRPC를 활용하여 Java gRPC 클라이언트를 사용하여 요청을 보내는 다른 서비스와 통신하는 것이었습니다.
그러나 이 솔루션에는 몇 가지 문제가 있었습니다. 주로 별도의 실행 환경 또는 팟(Pod)에서 실행되는 서로 다른 두 서비스 간의 네트워크 오버헤드로 인해 대기 시간이 더 길어지는 것을 확인했습니다. 그러나 유지 관리 오버헤드는 우리가 이 솔루션을 포기한 주된 이유였습니다. gRPC 서버와 클라이언트 프로그램을 별도로 구축하고 프로토콜 버퍼 파일을 일관되고 최신 상태로 유지해야 했습니다. 그런 다음 애플리케이션을 도커화하고, 배포 YAML 파일을 작성하고, Kubernetes 클러스터에 gRPC 서버를 배포하고, 안정적이고 자동 확장 가능한지 확인해야 했습니다.
또 다른 문제는 gRPC 서버 측에서 오류가 발생할 때마다 애플리케이션 클라이언트가 자세한 오류 역추적 대신 모호한 오류 메시지만 받는 것이었습니다. 클라이언트는 gRPC 서버 관리자에게 연락하여 코드의 어느 부분에서 오류가 발생했는지 정확히 파악해야 했습니다.
이상적으로는 모델 PyTorch 스크립트를 로드하고, 모델 입력에서 기능을 추출하고, 모델 추론을 완전히 Java로 실행하려고 합니다. 그런 다음 서비스 팀이 자체 Java 프로젝트로 가져올 수 있는 내부 레지스트리에서 호스팅되는 Maven 라이브러리로 빌드하고 게시할 수 있습니다. 온라인으로 조사했을 때 Deep Java Library가 맨 위에 나타났습니다. 몇 개의 블로그 게시물과 DJL의 공식 문서를 읽은 후 DJL이 문제에 대한 최상의 솔루션을 제공할 것이라고 확신했습니다.
솔루션 개요
다음 다이어그램은 이전 아키텍처와 업데이트된 아키텍처를 비교합니다.
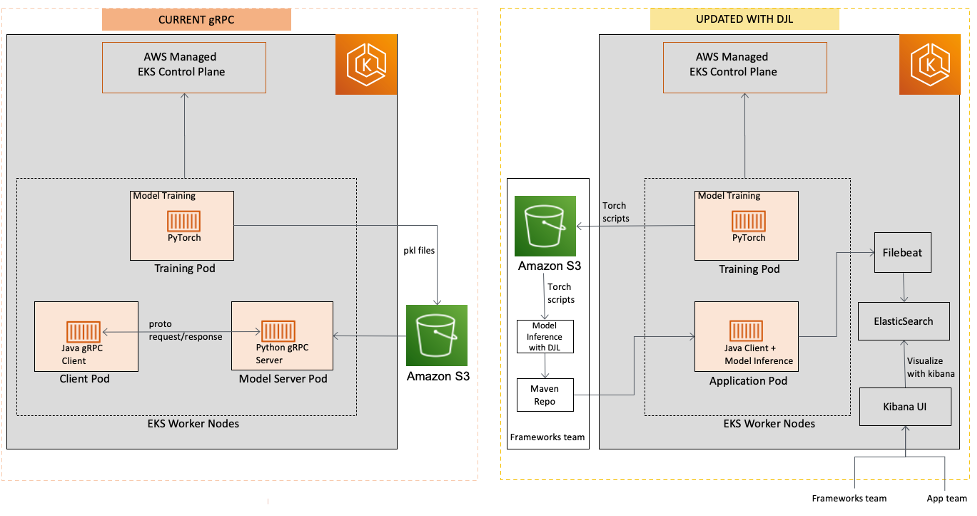
다음 다이어그램은 DJL 솔루션의 워크플로를 간략하게 보여줍니다.
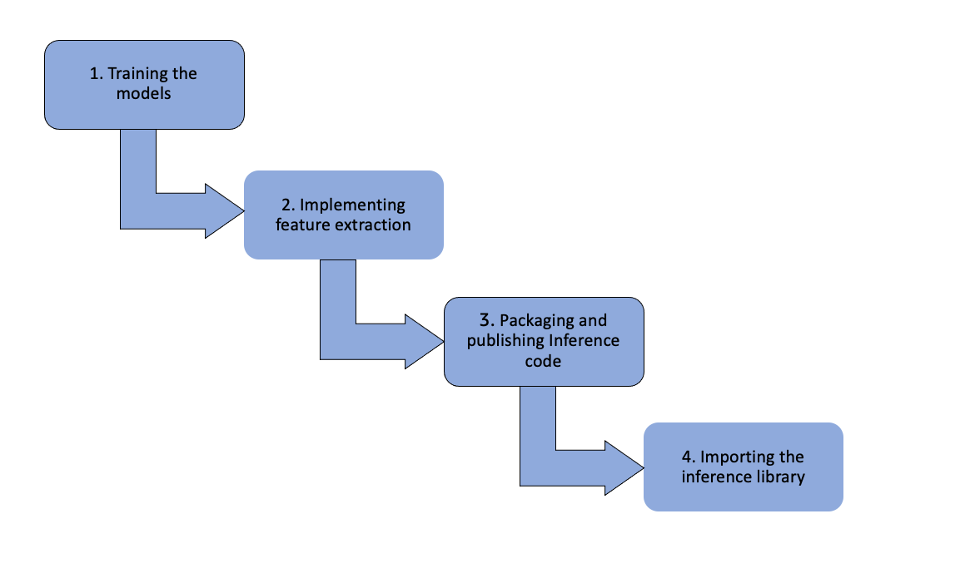
단계는 다음과 같습니다.
- 모델 훈련 – 데이터 과학자는 PyTorch를 사용하여 모델을 교육하고 모델을 토치 스크립트로 저장합니다. 이러한 모델은 다음으로 푸시됩니다. 아마존 단순 스토리지 서비스 (Amazon S3) ML 모델용 버전 제어 도구인 DVC를 사용하는 버킷.
- 기능 추출 구현 및 ML 기능 제공 – 프레임워크 팀은 Amazon S3에서 기능 추출을 구현하고 ML 기능을 예측기에 공급하는 Java 리포지토리로 모델을 가져옵니다. DJL PyTorch 엔진을 사용하여 모델 예측자를 초기화합니다.
- 추론 코드 및 모델 패키징 및 게시 – GitLab CI/CD 파이프라인은 추론 코드와 모델이 포함된 JAR 파일을 패키징하고 내부 Apache Archiva 레지스트리에 게시합니다.
- 추론 라이브러리 가져오기 및 호출하기 – Java 클라이언트는 추론 라이브러리를 Maven 종속성으로 가져옵니다. 모든 추론 호출은 동일한 Kubernetes 포드 내에서 Java 함수 호출을 통해 이루어집니다. gRPC 호출이 없기 때문에 추론 응답 시간이 향상됩니다. 또한 Java 클라이언트는 필요한 경우 추론 라이브러리를 이전 버전으로 쉽게 롤백할 수 있습니다. 반대로 서버 측 오류는 gRPC 기반 솔루션의 클라이언트 측에 투명하지 않아 오류 추적이 어렵습니다.
우리는 안정적인 추론 런타임과 신뢰할 수 있는 예측 결과를 보았습니다. DJL 솔루션은 gRPC 기반 솔루션에 비해 몇 가지 이점을 제공합니다.
- 개선된 응답 시간 – gRPC 호출이 없으므로 추론 응답 시간이 향상됩니다.
- 간편한 롤백 및 업그레이드 – Java 클라이언트는 추론 라이브러리를 이전 버전으로 쉽게 롤백하거나 새 버전으로 업그레이드할 수 있습니다.
- 투명한 오류 추적 – DJL 솔루션에서 클라이언트는 오류를 추론하는 경우 자세한 오류 트랙백 메시지를 받을 수 있습니다.
딥 자바 라이브러리 개요
DJL은 모델 구축, 데이터 세트 교육, 프로덕션 배포까지 딥 러닝 수명 주기를 지원하는 완전한 딥 러닝 프레임워크입니다. 컴퓨터 비전, 자연어 처리, 오디오, 시계열 및 표 데이터와 같은 형식을 위한 직관적인 도우미 및 유틸리티가 있습니다. DJL은 또한 즉시 사용할 수 있고 기존 시스템에 통합할 수 있는 수백 가지 사전 훈련된 모델의 쉬운 모델 동물원을 제공합니다.
또한 완전한 Apache-2 라이선스 오픈 소스 프로젝트이며 GitHub에서 찾을 수 있습니다.. DJL은 Amazon에서 만들어졌으며 2019년에 오픈 소스화되었습니다. 현재 DJL의 오픈 소스 커뮤니티는 Amazon이 주도하고 있으며 많은 국가, 회사 및 교육 기관을 포함하도록 성장했습니다. DJL은 다양한 하드웨어, 모델 및 엔진을 지원하는 능력이 계속해서 성장하고 있습니다. 또한 ARM과 같은 새로운 하드웨어에 대한 지원도 포함합니다(둘 다 다음과 같은 서버에 있음). AWS 그래비톤 및 노트북 애플 M1) and AWS 인 페렌 시아.
DJL의 아키텍처는 엔진에 구애받지 않습니다. Java 언어에서 딥 러닝이 어떤 모습일 수 있는지 설명하는 인터페이스를 목표로 하지만 다양한 기능이나 하드웨어 지원을 제공할 수 있는 다양한 구현을 위한 여지를 남겨둡니다. PyTorch 및 TensorFlow와 같은 오늘날 가장 널리 사용되는 프레임워크는 고성능 C++ 기본 백엔드에 연결되는 Python 프런트 엔드를 사용하여 구축됩니다. DJL은 이를 사용하여 동일한 기본 백엔드에 연결하여 하드웨어 지원 및 성능에 대한 작업을 활용할 수 있습니다.
이러한 이유로 많은 DJL 사용자도 추론용으로만 사용합니다. 즉, Python을 사용하여 모델을 교육한 다음 기존 Java 프로덕션 시스템의 일부로 배포하기 위해 DJL을 사용하여 로드합니다. DJL은 Python을 지원하는 동일한 엔진을 사용하기 때문에 성능 저하나 정확도 손실 없이 실행할 수 있습니다. 이것이 바로 우리가 새 모델을 지원하기 위해 찾은 전략입니다.
다음 다이어그램은 후드 아래의 워크플로우를 보여줍니다.
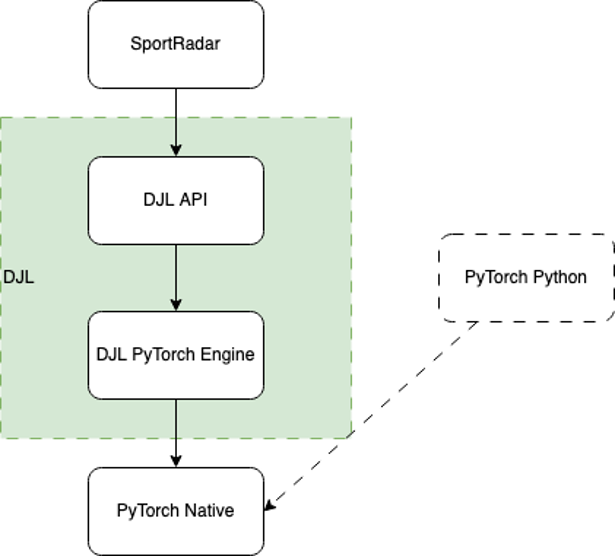
DJL이 로드되면 Java를 사용하여 클래스 경로에서 사용 가능한 모든 엔진 구현을 찾습니다. 서비스로더. 이 경우 DJL API와 PyTorch Native 간의 브리지 역할을 하는 DJL PyTorch 엔진 구현을 감지합니다.
그러면 엔진이 작동하여 PyTorch Native를 로드합니다. 기본적으로 OS, CPU 아키텍처 및 CUDA 버전을 기반으로 적절한 기본 바이너리를 다운로드하므로 거의 쉽게 사용할 수 있습니다. 보안을 위해 종종 네트워크 액세스가 제한되는 프로덕션 환경에 더 안정적인 많은 사용 가능한 기본 JAR 파일 중 하나를 사용하여 바이너리를 제공할 수도 있습니다.
일단 로드되면 DJL은 다음을 사용합니다. 자바 네이티브 인터페이스 DJL의 모든 쉬운 고수준 기능을 동등한 저수준 기본 호출로 변환합니다. DJL API의 모든 작업은 Java 규칙에 가장 잘 맞고 쉽게 액세스할 수 있도록 수작업으로 제작되었습니다. 여기에는 Java 가비지 수집기에서 지원하지 않는 네이티브 메모리 처리도 포함됩니다.
이러한 모든 세부 정보가 라이브러리 내에 있지만 사용자 관점에서 호출하는 것이 더 쉬울 수 없습니다. 다음 섹션에서는 이 프로세스를 살펴봅니다.
Sportradar가 DJL을 구현한 방법
PyTorch를 사용하여 모델을 훈련하기 때문에 모델 추론을 위해 DJL의 PyTorch 엔진을 사용합니다.
모델을 로드하는 것은 매우 쉽습니다. 로드할 모델과 모델의 출처를 설명하는 기준을 구축하기만 하면 됩니다. 그런 다음 이를 로드하고 모델을 사용하여 새 예측자 세션을 생성합니다. 다음 코드를 참조하십시오.
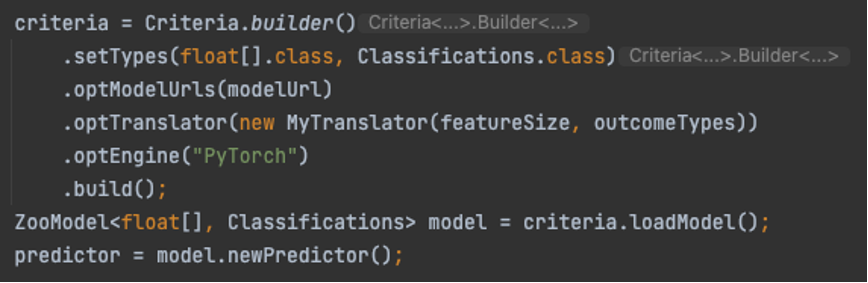
우리 모델의 경우 사용자 정의 번역기도 있습니다. MyTranslator. 번역기를 사용하여 편리한 Java 유형에서 모델이 예상하는 입력으로 변환하는 전처리 코드와 모델 출력에서 편리한 출력으로 변환하는 후처리 코드를 캡슐화합니다. 우리의 경우에는 다음을 사용하기로 했습니다. float[] 입력 유형으로, 내장 DJL 분류를 출력 유형으로 사용합니다. 다음은 번역기 코드의 스니펫입니다.

몇 줄의 코드만으로 DJL이 PyTorch 스크립트와 맞춤형 번역기를 로드하면 예측기가 예측할 준비가 된다는 것은 매우 놀라운 일입니다.
결론
DJL 솔루션을 기반으로 구축된 Sportradar의 제품은 2022-23 NFL 정규 시즌이 시작되기 전에 출시되었으며 그 이후로 원활하게 실행되고 있습니다. 앞으로 Sportradar는 gRPC 서버에서 호스팅되는 기존 모델을 DJL 솔루션으로 다시 플랫폼화할 계획입니다.
DJL은 다양한 방식으로 계속해서 성장하고 있습니다. 가장 최근에 발매된, v0.21.0, 업데이트된 엔진 지원, Spark 개선, Hugging Face 배치 토크나이저, 간편한 메모리 관리를 위한 NDScope, 시계열 API 개선 등 많은 개선 사항이 있습니다. 또한 최초의 주요 릴리스인 DJL 제로, 사전 훈련된 모델 사용과 딥 러닝에 대한 지식이 전혀 없는 사용자 지정 딥 러닝 모델 훈련을 모두 지원하는 것을 목표로 하는 새로운 API입니다.
DJL에는 다음과 같은 모델 서버도 있습니다. DJL 서빙. Python 코드를 지원하는 Python 엔진을 포함하여 지원되는 10개의 엔진에서 HTTP 서버의 모델을 간단하게 호스팅할 수 있습니다. DJL Serving의 v0.21.0에는 더 빠른 변압기 지원이 포함되어 있습니다. 아마존 세이지 메이커 다중 모델 엔드 포인트 지원, Stable Diffusion 업데이트, DeepSpeed 개선, 관리 콘솔 업데이트. 이제 사용할 수 있습니다. DeepSpeed 및 SageMaker를 사용하여 모델 병렬 추론으로 대규모 모델 배포.
DJL과 함께 할 일도 많이 있습니다. 개발 중인 가장 큰 영역은 ChatGPT 또는 Stable Diffusion과 같은 모델에 대한 대규모 언어 모델 지원입니다. DJL Serving에서 스트리밍 추론 요청을 지원하기 위한 작업도 있습니다. 셋째, Spark용 데모 및 확장 기능이 개선되었습니다. 물론 기능, 수정, 엔진 업데이트 등을 포함한 표준 연속 작업도 있습니다.
DJL 및 기타 기능에 대한 자세한 내용은 다음을 참조하십시오. 딥 자바 라이브러리.
우리를 따라 GitHub 레포, 데모 저장소, 여유 채널및 트위터 더 많은 문서와 DJL의 예를 보려면!
저자 소개
 프레드 우 Sportradar의 선임 데이터 엔지니어로서 다양한 NBA 및 NFL 제품에 대한 인프라, DevOps 및 데이터 엔지니어링 노력을 이끌고 있습니다. 현장에서의 광범위한 경험을 바탕으로 Fred는 강력하고 효율적인 데이터 파이프라인 및 시스템을 구축하여 최첨단 스포츠 분석을 지원하는 데 전념하고 있습니다.
프레드 우 Sportradar의 선임 데이터 엔지니어로서 다양한 NBA 및 NFL 제품에 대한 인프라, DevOps 및 데이터 엔지니어링 노력을 이끌고 있습니다. 현장에서의 광범위한 경험을 바탕으로 Fred는 강력하고 효율적인 데이터 파이프라인 및 시스템을 구축하여 최첨단 스포츠 분석을 지원하는 데 전념하고 있습니다.
 잭 킴버그 Amazon AI 조직의 소프트웨어 개발자입니다. 그는 딥 러닝의 개발, 훈련 및 생산 추론을 가능하게 하기 위해 노력합니다. 그곳에서 그는 DeepJavaLibrary 프로젝트를 발견하고 계속 개발하는 데 도움을 주었습니다.
잭 킴버그 Amazon AI 조직의 소프트웨어 개발자입니다. 그는 딥 러닝의 개발, 훈련 및 생산 추론을 가능하게 하기 위해 노력합니다. 그곳에서 그는 DeepJavaLibrary 프로젝트를 발견하고 계속 개발하는 데 도움을 주었습니다.
 칸월짓 쿠르미 Amazon Web Services의 수석 솔루션 아키텍트입니다. 그는 AWS 고객과 협력하여 AWS를 사용할 때 솔루션의 가치를 개선하는 데 도움이 되는 지침과 기술 지원을 제공합니다. Kanwaljit는 컨테이너화된 머신 러닝 애플리케이션으로 고객을 지원하는 것을 전문으로 합니다.
칸월짓 쿠르미 Amazon Web Services의 수석 솔루션 아키텍트입니다. 그는 AWS 고객과 협력하여 AWS를 사용할 때 솔루션의 가치를 개선하는 데 도움이 되는 지침과 기술 지원을 제공합니다. Kanwaljit는 컨테이너화된 머신 러닝 애플리케이션으로 고객을 지원하는 것을 전문으로 합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/how-sportradar-used-the-deep-java-library-to-build-production-scale-ml-platforms-for-increased-performance-and-efficiency/

