이 블로그 게시물은 Veoneer의 Caroline Chung과 공동으로 작성되었습니다.
Veoneer는 글로벌 자동차 전자 회사이자 자동차 전자 안전 시스템 분야의 세계적인 선두 기업입니다. 그들은 동급 최고의 구속 제어 시스템을 제공하고 전 세계 자동차 제조업체에 1억 개가 넘는 전자 제어 장치와 충돌 센서를 공급했습니다. 이 회사는 70년 간의 자동차 안전 개발 역사를 바탕으로 교통 사고를 예방하고 사고를 완화하는 최첨단 하드웨어 및 시스템을 전문으로 하고 있습니다.
자동차 실내 센싱(ICS)은 카메라, 레이더 등 여러 종류의 센서와 인공지능(AI), 머신러닝(ML) 기반 알고리즘을 결합해 안전성을 높이고 승차감을 향상시키는 신흥 공간이다. 그러한 시스템을 구축하는 것은 복잡한 작업이 될 수 있습니다. 개발자는 교육 및 테스트 목적으로 대량의 이미지에 수동으로 주석을 달아야 합니다. 이는 시간이 많이 걸리고 리소스 집약적입니다. 이러한 작업의 처리 시간은 몇 주입니다. 또한 기업은 사람의 실수로 인해 라벨이 일관되지 않는 등의 문제를 처리해야 합니다.
AWS는 ML과 같은 고급 분석을 통해 개발 속도를 높이고 이러한 시스템을 구축하는 데 드는 비용을 낮추는 데 중점을 두고 있습니다. 우리의 비전은 자동화된 주석에 ML을 사용하여 안전 모델의 재교육을 지원하고 일관되고 안정적인 성능 지표를 보장하는 것입니다. 이 게시물에서는 Amazon의 Worldwide Specialist Organization 및 제너레이티브 AI 혁신 센터, 우리는 객실 내 이미지 헤드 경계 상자 및 핵심 포인트 주석을 위한 능동 학습 파이프라인을 개발했습니다. 이 솔루션은 비용을 90% 이상 절감하고 처리 시간 측면에서 주석 프로세스를 몇 주에서 몇 시간으로 가속화하며 유사한 ML 데이터 라벨링 작업에 대한 재사용성을 지원합니다.
솔루션 개요
능동 학습은 모델을 훈련하기 위해 가장 유용한 데이터를 선택하고 주석을 추가하는 반복적인 프로세스를 포함하는 ML 접근 방식입니다. 레이블이 지정된 소규모 데이터 세트와 레이블이 지정되지 않은 대규모 데이터 세트가 있는 경우 능동 학습은 모델 성능을 향상하고 레이블 지정 작업을 줄이며 인간의 전문 지식을 통합하여 강력한 결과를 제공합니다. 이 게시물에서는 AWS 서비스를 사용하여 이미지 주석을 위한 활성 학습 파이프라인을 구축합니다.
다음 다이어그램은 활성 학습 파이프라인의 전체 프레임워크를 보여줍니다. 라벨링 파이프라인은 다음에서 이미지를 가져옵니다. 아마존 단순 스토리지 서비스 (Amazon S3) ML 모델과 인간 전문 지식의 협력을 통해 주석이 달린 이미지를 버킷하고 출력합니다. 훈련 파이프라인은 데이터를 사전 처리하고 이를 사용하여 ML 모델을 훈련합니다. 초기 모델은 수동으로 레이블이 지정된 소규모 데이터 세트에 대해 설정 및 학습되며 레이블 지정 파이프라인에서 사용됩니다. 레이블 지정 파이프라인과 훈련 파이프라인은 더 많은 레이블이 지정된 데이터를 사용하여 점진적으로 반복되어 모델 성능을 향상시킬 수 있습니다.
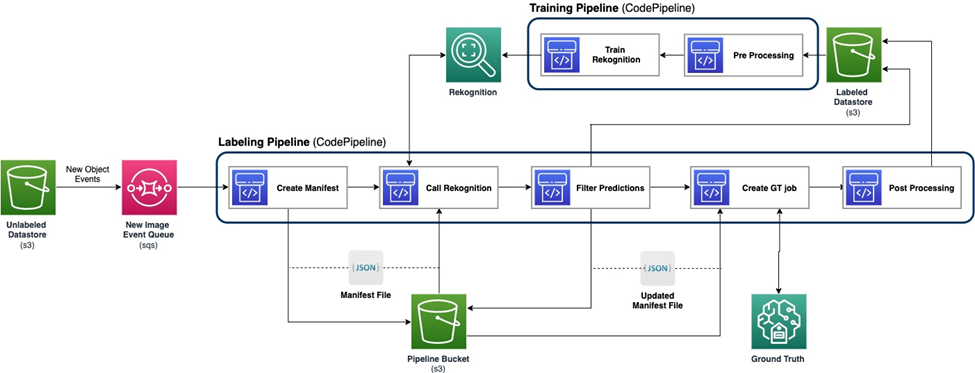
라벨링 파이프라인에서는 Amazon S3 이벤트 알림 새로운 이미지 배치가 레이블이 지정되지 않은 데이터 저장소 S3 버킷에 들어오면 호출되어 레이블 지정 파이프라인을 활성화합니다. 모델은 새 이미지에 대한 추론 결과를 생성합니다. 맞춤형 판단 기능은 추론 신뢰도 점수 또는 기타 사용자 정의 기능을 기반으로 데이터의 일부를 선택합니다. 추론 결과와 함께 이 데이터는 수동 라벨링 작업을 위해 전송됩니다. 아마존 세이지 메이커 그라운드 진실 파이프라인에 의해 생성됩니다. 사람이 라벨링하는 프로세스는 데이터에 주석을 추가하는 데 도움이 되며, 수정된 결과는 나중에 학습 파이프라인에서 사용할 수 있는 나머지 자동 주석 데이터와 결합됩니다.
모델 재훈련은 훈련 파이프라인에서 이루어지며, 여기에서 사람이 레이블을 지정한 데이터가 포함된 데이터 세트를 사용하여 모델을 재훈련합니다. 파일이 저장되는 위치를 설명하기 위해 매니페스트 파일이 생성되고 동일한 초기 모델이 새 데이터에 대해 재교육됩니다. 재학습 후 새 모델이 초기 모델을 대체하고 활성 학습 파이프라인의 다음 반복이 시작됩니다.
모델 배포
라벨링 파이프라인과 학습 파이프라인은 모두 다음에 배포됩니다. AWS 코드 파이프라인. AWS 코드빌드 인스턴스를 사용하여 소량의 데이터를 유연하고 빠르게 구현합니다. 속도가 필요할 때 우리는 아마존 세이지 메이커 GPU 인스턴스 기반 엔드포인트를 사용하여 프로세스를 지원하고 가속화하기 위해 더 많은 리소스를 할당합니다.
모델 재훈련 파이프라인은 새로운 데이터 세트가 있거나 모델 성능을 개선해야 할 때 호출될 수 있습니다. 재훈련 파이프라인에서 중요한 작업 중 하나는 훈련 데이터와 모델 모두에 대한 버전 제어 시스템을 갖추는 것입니다. 다음과 같은 AWS 서비스가 있지만 아마존 인식 파이프라인을 구현하기 쉽게 만드는 통합 버전 제어 기능이 있는 경우, 맞춤형 모델에는 메타데이터 로깅 또는 추가 버전 제어 도구가 필요합니다.
전체 워크플로는 다음을 사용하여 구현됩니다. AWS 클라우드 개발 키트 (AWS CDK) 다음을 포함하여 필요한 AWS 구성 요소를 생성합니다.
- CodePipeline 및 SageMaker 작업에 대한 두 가지 역할
- 워크플로를 조정하는 두 개의 CodePipeline 작업
- 파이프라인의 코드 아티팩트용 S3 버킷 XNUMX개
- 작업 매니페스트, 데이터 세트 및 모델에 라벨을 지정하기 위한 S3 버킷 XNUMX개
- 전처리 및 후처리 AWS 람다 SageMaker Ground Truth 라벨링 작업을 위한 기능
AWS CDK 스택은 고도로 모듈화되어 있으며 다양한 작업에서 재사용이 가능합니다. 훈련, 추론 코드 및 SageMaker Ground Truth 템플릿은 유사한 활성 학습 시나리오에 대해 대체될 수 있습니다.
모델 훈련
모델 훈련에는 머리 경계 상자 주석과 사람의 주요 지점 주석이라는 두 가지 작업이 포함됩니다. 이 섹션에서는 두 가지를 모두 소개합니다.
머리 경계 상자 주석
머리 경계 상자 주석은 이미지에서 사람 머리의 경계 상자 위치를 예측하는 작업입니다. 우리는 Amazon Rekognition 사용자 지정 레이블 머리 경계 상자 주석을 위한 모델입니다. 다음과 같은 샘플 노트 SageMaker를 통해 Rekognition Custom Labels 모델을 교육하는 방법에 대한 단계별 자습서를 제공합니다.
훈련을 시작하려면 먼저 데이터를 준비해야 합니다. 훈련용 매니페스트 파일과 테스트 데이터세트용 매니페스트 파일을 생성합니다. 매니페스트 파일에는 여러 항목이 포함되어 있으며 각 항목은 이미지용입니다. 다음은 이미지 경로, 크기, 주석 정보를 포함하는 매니페스트 파일의 예입니다.
매니페스트 파일을 사용하여 훈련 및 테스트를 위해 Rekognition Custom Labels 모델에 데이터세트를 로드할 수 있습니다. 우리는 다양한 양의 훈련 데이터로 모델을 반복하고 동일한 239개의 보이지 않는 이미지에서 테스트했습니다. 이번 테스트에서는 mAP_50 점수는 0.33개의 훈련 이미지에서 114에서 0.95개의 훈련 이미지에서 957로 증가했습니다. 다음 스크린샷은 F1 점수, 정밀도 및 재현율 측면에서 뛰어난 성능을 제공하는 최종 Rekognition Custom Labels 모델의 성능 지표를 보여줍니다.

우리는 1,128개의 이미지가 있는 보류된 데이터 세트에서 모델을 추가로 테스트했습니다. 모델은 보이지 않는 데이터에 대한 정확한 경계 상자 예측을 일관되게 예측하여 높은 결과를 산출합니다. mAP_50 94.9%이다. 다음 예는 머리 경계 상자가 있는 자동 주석이 달린 이미지를 보여줍니다.

핵심 포인트 주석
핵심 포인트 주석은 눈, 귀, 코, 입, 목, 어깨, 팔꿈치, 손목, 엉덩이, 발목 등 핵심 포인트의 위치를 생성합니다. 위치 예측 외에도 이 특정 작업을 예측하려면 각 지점의 가시성이 필요하며 이를 위해 새로운 방법을 설계합니다.
핵심 포인트 주석의 경우 Yolo 8 포즈 모델 SageMaker를 초기 모델로 사용합니다. 먼저 Yolo의 요구 사항에 따라 레이블 파일 및 구성 .yaml 파일 생성을 포함하여 훈련용 데이터를 준비합니다. 데이터를 준비한 후 모델을 훈련하고 모델 가중치 파일을 포함한 아티팩트를 저장합니다. 훈련된 모델 가중치 파일을 사용하여 새 이미지에 주석을 달 수 있습니다.
훈련 단계에서는 보이는 지점과 가려진 지점을 포함하여 위치가 표시된 모든 레이블이 있는 지점이 훈련에 사용됩니다. 따라서 이 모델은 기본적으로 예측의 위치와 신뢰도를 제공합니다. 다음 그림에서 0.6에 가까운 큰 신뢰도 임계값(주 임계값)은 카메라 시점 외부에 대해 보이거나 가려진 점을 나눌 수 있습니다. 그러나 가려진 점과 보이는 점은 신뢰도로 구분되지 않습니다. 이는 예측된 신뢰도가 가시성을 예측하는 데 유용하지 않음을 의미합니다.

가시성에 대한 예측을 얻기 위해 우리는 가려진 점과 카메라 시점 외부를 모두 제외하고 가시적인 점만 포함하는 데이터 세트에 대해 훈련된 추가 모델을 도입합니다. 다음 그림은 가시성이 다른 점의 분포를 보여줍니다. 추가 모델에서는 보이는 점과 다른 점을 분리할 수 있습니다. 눈에 보이는 점을 얻기 위해 0.6 근처의 임계값(추가 임계값)을 사용할 수 있습니다. 이 두 모델을 결합하여 위치와 가시성을 예측하는 방법을 설계합니다.

주요 지점은 먼저 위치 및 주요 신뢰도를 사용하여 기본 모델에 의해 예측된 다음 추가 모델에서 추가 신뢰도 예측을 얻습니다. 가시성은 다음과 같이 분류됩니다.
- 표시(기본 신뢰도가 기본 임계값보다 크고 추가 신뢰도가 추가 임계값보다 큰 경우)
- 차단됨(주 신뢰도가 기본 임계값보다 크고 추가 신뢰도가 추가 임계값보다 작거나 같은 경우)
- 카메라 검토 이외의 경우(그렇지 않은 경우)
다음 이미지에는 주요 점 주석의 예가 나와 있습니다. 여기서 실선 마크는 보이는 점이고 속이 빈 마크는 가려진 점입니다. 카메라의 리뷰 포인트 외부는 표시되지 않습니다.

표준에 따라 OKS MS-COCO 데이터세트에 대한 정의에 따르면, 우리의 방법은 보이지 않는 테스트 데이터세트에서 50%의 mAP_98.4을 달성할 수 있습니다. 가시성 측면에서 이 방법은 동일한 데이터세트에서 79.2%의 분류 정확도를 제공합니다.
수동 라벨링 및 재교육
모델이 테스트 데이터에서 뛰어난 성능을 달성하더라도 새로운 실제 데이터에서는 실수할 가능성이 여전히 있습니다. 휴먼 라벨링은 재교육을 통해 모델 성능을 향상하기 위해 이러한 실수를 수정하는 프로세스입니다. 모든 머리 경계 상자 또는 핵심 포인트의 출력에 대해 ML 모델에서 출력되는 신뢰도 값을 결합한 판단 기능을 설계했습니다. 우리는 최종 점수를 사용하여 이러한 실수와 그에 따른 잘못된 라벨링 이미지를 식별하고, 이를 인간 라벨링 프로세스로 보내야 합니다.
라벨이 잘못 지정된 이미지 외에도 사람이 라벨링하기 위해 이미지의 작은 부분이 무작위로 선택됩니다. 이러한 사람이 레이블을 붙인 이미지는 재훈련을 위해 현재 버전의 훈련 세트에 추가되어 모델 성능과 전반적인 주석 정확도를 향상시킵니다.
구현에서는 SageMaker Ground Truth를 사용합니다. 인간 라벨링 프로세스. SageMaker Ground Truth는 데이터 라벨링을 위한 사용자 친화적이고 직관적인 UI를 제공합니다. 다음 스크린샷은 머리 경계 상자 주석에 대한 SageMaker Ground Truth 레이블 지정 작업을 보여줍니다.

다음 스크린샷은 핵심 포인트 주석에 대한 SageMaker Ground Truth 라벨링 작업을 보여줍니다.

비용, 속도 및 재사용성
다음 표에 표시된 것처럼 수동 라벨링에 비해 비용과 속도는 당사 솔루션을 사용할 때의 주요 이점입니다. 우리는 비용 절감과 속도 가속화를 나타내기 위해 이 표를 사용합니다. 가속화된 GPU SageMaker 인스턴스 ml.g4dn.xlarge를 사용하면 100,000개의 이미지에 대한 전체 수명 훈련 및 추론 비용이 인간 라벨링 비용보다 99% 저렴하며, 속도는 인간 라벨링보다 10~10,000배 빠릅니다. 일.
첫 번째 표에는 비용 성능 지표가 요약되어 있습니다.
| 모델 | 50개의 테스트 이미지를 기반으로 한 mAP_1,128 | 이미지 100,000개 기준 학습 비용 | 100,000개의 이미지를 기준으로 한 추론 비용 | 사람이 주석을 달 때보다 비용 절감 | 100,000개의 이미지를 기반으로 한 추론 시간 | 인간 주석과 비교한 시간 가속 |
| 인식 헤드 경계 상자 | 0.949 | $4 | $22 | 99 % 이하 | 5.5의 오후 | 일 |
| 욜로 핵심 포인트 | 0.984 | $27.20 | * $ 10 | 99.9 % 이하 | 분 | 주 |
다음 표에는 성능 지표가 요약되어 있습니다.
| 주석 작업 | mAP_50 (%) | 훈련비용($) | 추론 비용($) | 추론 시간 |
| 머리 경계 상자 | 94.9 | 4 | 22 | 5.5 시간 |
| 키 포인트 | 98.4 | 27 | 10 | 5 분 |
또한 당사의 솔루션은 유사한 작업에 대한 재사용성을 제공합니다. ADAS(첨단 운전자 보조 시스템) 및 실내 시스템과 같은 다른 시스템을 위한 카메라 인식 개발에도 당사의 솔루션을 채택할 수 있습니다.
요약
이 게시물에서는 AWS 서비스를 활용하여 기내 이미지에 자동 주석을 추가하기 위한 활성 학습 파이프라인을 구축하는 방법을 보여주었습니다. 주석 프로세스를 자동화하고 신속하게 처리할 수 있는 ML의 강력한 기능과 AWS 서비스에서 지원되거나 SageMaker에서 사용자 정의된 모델을 사용하는 프레임워크의 유연성을 보여줍니다. Amazon S3, SageMaker, Lambda 및 SageMaker Ground Truth를 사용하면 데이터 저장, 주석, 훈련 및 배포를 간소화하고 재사용성을 달성하는 동시에 비용을 크게 절감할 수 있습니다. 이 솔루션을 구현함으로써 자동차 회사는 자동화된 이미지 주석과 같은 ML 기반 고급 분석을 사용하여 더욱 민첩하고 비용 효율성을 높일 수 있습니다.
지금 시작하여 다음의 기능을 활용해 보세요. AWS 서비스 자동차 실내 감지 사용 사례를 위한 기계 학습!
저자에 관하여
 유 옌샹 Amazon Generative AI Innovation Center의 응용 과학자입니다. 산업용 애플리케이션을 위한 AI 및 기계 학습 솔루션을 구축한 9년 이상의 경험을 보유한 그는 생성 AI, 컴퓨터 비전 및 시계열 모델링을 전문으로 합니다.
유 옌샹 Amazon Generative AI Innovation Center의 응용 과학자입니다. 산업용 애플리케이션을 위한 AI 및 기계 학습 솔루션을 구축한 9년 이상의 경험을 보유한 그는 생성 AI, 컴퓨터 비전 및 시계열 모델링을 전문으로 합니다.
 마오 티안이 그는 시카고 지역에 거주하는 AWS의 응용 과학자입니다. 그는 기계 학습 및 딥 러닝 솔루션 구축 분야에서 5년 이상의 경험을 보유하고 있으며 인간 피드백을 통한 컴퓨터 비전 및 강화 학습에 중점을 두고 있습니다. 그는 고객과 협력하여 AWS 서비스를 사용하여 혁신적인 솔루션을 만들어 고객의 문제를 이해하고 해결하는 것을 즐깁니다.
마오 티안이 그는 시카고 지역에 거주하는 AWS의 응용 과학자입니다. 그는 기계 학습 및 딥 러닝 솔루션 구축 분야에서 5년 이상의 경험을 보유하고 있으며 인간 피드백을 통한 컴퓨터 비전 및 강화 학습에 중점을 두고 있습니다. 그는 고객과 협력하여 AWS 서비스를 사용하여 혁신적인 솔루션을 만들어 고객의 문제를 이해하고 해결하는 것을 즐깁니다.
 샤오 얀루 그는 Amazon Generative AI 혁신 센터의 응용 과학자로서 고객의 실제 비즈니스 문제에 대한 AI/ML 솔루션을 구축하고 있습니다. 그는 제조, 에너지, 농업 등 여러 분야에서 일했습니다. Yanru는 박사 학위를 취득했습니다. Old Dominion University에서 컴퓨터 과학을 전공했습니다.
샤오 얀루 그는 Amazon Generative AI 혁신 센터의 응용 과학자로서 고객의 실제 비즈니스 문제에 대한 AI/ML 솔루션을 구축하고 있습니다. 그는 제조, 에너지, 농업 등 여러 분야에서 일했습니다. Yanru는 박사 학위를 취득했습니다. Old Dominion University에서 컴퓨터 과학을 전공했습니다.
 폴 조지 자동차 기술 분야에서 15년 이상의 경험을 보유한 뛰어난 제품 리더입니다. 그는 제품 관리, 전략, 시장 진출 및 시스템 엔지니어링 팀을 이끄는 데 능숙합니다. 그는 전 세계적으로 여러 가지 새로운 감지 및 인식 제품을 육성하고 출시했습니다. AWS에서 그는 자율주행차 워크로드에 대한 전략과 시장 진출을 주도하고 있습니다.
폴 조지 자동차 기술 분야에서 15년 이상의 경험을 보유한 뛰어난 제품 리더입니다. 그는 제품 관리, 전략, 시장 진출 및 시스템 엔지니어링 팀을 이끄는 데 능숙합니다. 그는 전 세계적으로 여러 가지 새로운 감지 및 인식 제품을 육성하고 출시했습니다. AWS에서 그는 자율주행차 워크로드에 대한 전략과 시장 진출을 주도하고 있습니다.
 캐롤라인 정 Veoneer(Magna International에 인수됨)의 엔지니어링 관리자이며 감지 및 인식 시스템 개발에 14년 이상의 경험을 갖고 있습니다. 그녀는 현재 Magna International에서 컴퓨팅 비전 엔지니어와 데이터 과학자로 구성된 팀을 관리하면서 인테리어 감지 사전 개발 프로그램을 이끌고 있습니다.
캐롤라인 정 Veoneer(Magna International에 인수됨)의 엔지니어링 관리자이며 감지 및 인식 시스템 개발에 14년 이상의 경험을 갖고 있습니다. 그녀는 현재 Magna International에서 컴퓨팅 비전 엔지니어와 데이터 과학자로 구성된 팀을 관리하면서 인테리어 감지 사전 개발 프로그램을 이끌고 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

