아마존 세이지 메이커 다중 모델 엔드포인트(MME) 단일 엔드포인트에 수천 개의 모델을 배포할 수 있는 SageMaker 추론의 완전 관리형 기능입니다. 이전에는 MME가 다음을 사용하여 모델 트래픽 부하에 관계없이 모델에 CPU 컴퓨팅 성능을 미리 결정하여 정적으로 할당했습니다. 다중 모델 서버(MMS) 모델 서버로 사용됩니다. 이 게시물에서는 MME가 모델의 트래픽 패턴을 기반으로 각 모델에 할당된 컴퓨팅 성능을 동적으로 조정할 수 있는 솔루션에 대해 논의합니다. 이 솔루션을 사용하면 MME의 기본 컴퓨팅을 보다 효율적으로 사용하고 비용을 절감할 수 있습니다.
MME는 엔드포인트로 들어오는 트래픽을 기반으로 모델을 동적으로 로드 및 언로드합니다. MMS를 모델 서버로 활용하는 경우 MME는 각 모델에 고정된 수의 모델 작업자를 할당합니다. 자세한 내용은 다음을 참조하세요. Amazon SageMaker의 모델 호스팅 패턴, 3부: Amazon SageMaker 다중 모델 엔드포인트로 다중 모델 추론 실행 및 최적화.
그러나 트래픽 패턴이 가변적일 경우 이로 인해 몇 가지 문제가 발생할 수 있습니다. 많은 양의 트래픽을 수신하는 단일 또는 소수의 모델이 있다고 가정해 보겠습니다. 이러한 모델에 대해 많은 수의 작업자를 할당하도록 MMS를 구성할 수 있지만 이는 정적 구성이기 때문에 MME 뒤의 모든 모델에 할당됩니다. 이로 인해 하드웨어 컴퓨팅을 사용하는 작업자가 많아지고 심지어 유휴 모델도 사용하게 됩니다. 작업자 수에 작은 값을 설정하면 반대의 문제가 발생할 수 있습니다. 인기 있는 모델에는 해당 모델의 엔드포인트 뒤에 충분한 하드웨어를 적절하게 할당할 수 있는 모델 서버 수준의 작업자가 충분하지 않습니다. 주요 문제는 필요한 컴퓨팅 양을 할당하기 위해 모델 서버 수준에서 작업자를 동적으로 확장할 수 없는 경우 트래픽 패턴에 구애받지 않는 상태를 유지하기 어렵다는 것입니다.
이 게시물에서 논의하는 솔루션은 다음을 사용합니다. DJL서빙 모델 서버로서 우리가 논의한 문제 중 일부를 완화하고 모델별 확장을 활성화하며 MME가 트래픽 패턴에 구애받지 않도록 할 수 있습니다.
MME 아키텍처
SageMaker MME를 사용하면 하나 이상의 인스턴스를 포함할 수 있는 단일 추론 엔드포인트 뒤에 여러 모델을 배포할 수 있습니다. 각 인스턴스는 메모리 및 CPU/GPU 용량까지 여러 모델을 로드하고 제공하도록 설계되었습니다. 이 아키텍처를 사용하면 SaaS(Software as a Service) 비즈니스는 여러 모델을 호스팅하는 데 따른 선형적으로 증가하는 비용을 줄이고 애플리케이션 스택의 다른 곳에 적용되는 다중 테넌트 모델과 일치하는 인프라를 재사용할 수 있습니다. 다음 다이어그램은 이 아키텍처를 보여줍니다.
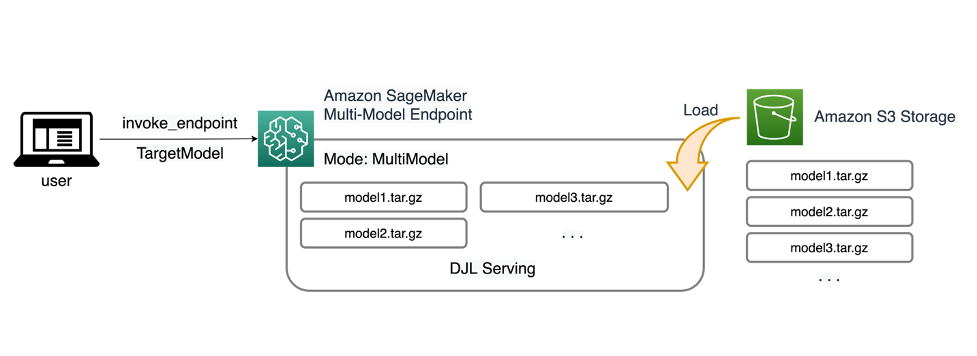
SageMaker MME는 다음에서 모델을 동적으로 로드합니다. 아마존 단순 스토리지 서비스 (Amazon S3) 호출 시 엔드포인트가 처음 생성될 때 모든 모델을 다운로드하는 대신. 결과적으로 모델에 대한 초기 호출은 짧은 대기 시간으로 완료되는 후속 추론보다 추론 대기 시간이 더 길 수 있습니다. 호출 시 모델이 이미 컨테이너에 로드되어 있는 경우 다운로드 단계를 건너뛰고 모델은 짧은 지연 시간으로 추론을 반환합니다. 예를 들어, 하루에 몇 번만 사용되는 모델이 있다고 가정해 보겠습니다. 요청 시 자동으로 로드되는 반면 자주 액세스되는 모델은 메모리에 유지되고 일관되게 짧은 대기 시간으로 호출됩니다.
다음 다이어그램에 설명된 것처럼 각 MME 뒤에는 모델 호스팅 인스턴스가 있습니다. 이러한 인스턴스는 모델에 대한 트래픽 패턴을 기반으로 메모리에서 여러 모델을 로드하고 메모리에서 제거합니다.
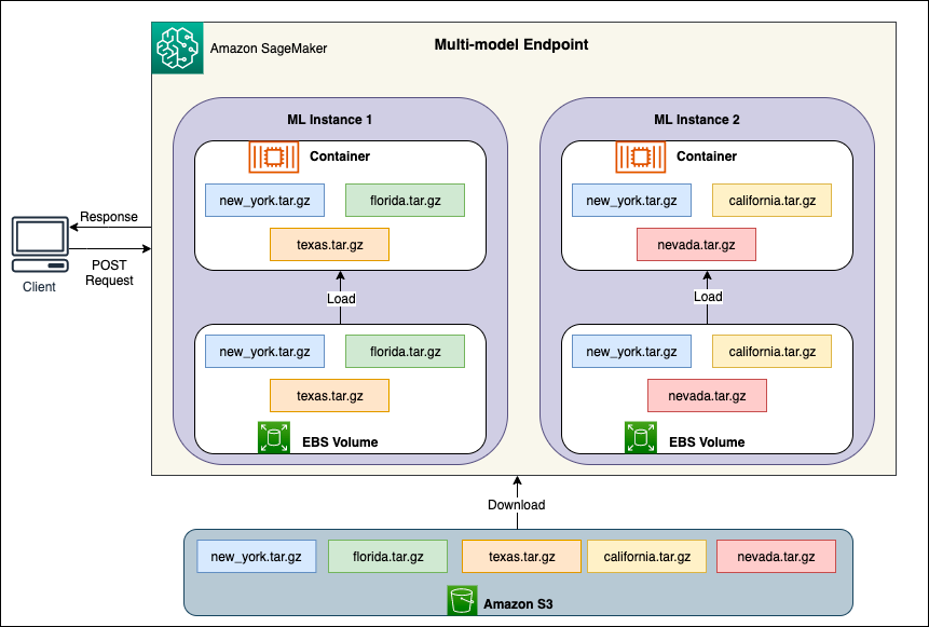
SageMaker는 요청이 캐시된 모델 복사본에서 제공되도록 모델에 대한 추론 요청을 모델이 이미 로드된 인스턴스로 계속 라우팅합니다(첫 번째 예측 요청과 캐시된 예측에 대한 요청 경로를 보여주는 다음 다이어그램 참조). 요청 경로). 그러나 모델이 많은 호출 요청을 받고 MME에 대한 추가 인스턴스가 있는 경우 SageMaker는 증가를 수용하기 위해 일부 요청을 다른 인스턴스로 라우팅합니다. SageMaker에서 자동화된 모델 확장을 활용하려면 인스턴스 Auto Scaling 설정 추가 인스턴스 용량을 프로비저닝합니다. 사용자 지정 파라미터 또는 분당 호출(권장)을 사용하여 엔드포인트 수준 조정 정책을 설정하여 엔드포인트 집합에 더 많은 인스턴스를 추가합니다.

모델 서버 개요
모델 서버는 기계 학습(ML) 모델을 배포하고 제공하기 위한 런타임 환경을 제공하는 소프트웨어 구성 요소입니다. 이는 학습된 모델과 해당 모델을 사용하여 예측을 수행하려는 클라이언트 애플리케이션 간의 인터페이스 역할을 합니다.
모델 서버의 주요 목적은 ML 모델을 프로덕션 시스템에 손쉽게 통합하고 효율적으로 배포하는 것입니다. 모델을 애플리케이션이나 특정 프레임워크에 직접 포함하는 대신 모델 서버는 여러 모델을 배포, 관리 및 제공할 수 있는 중앙 집중식 플랫폼을 제공합니다.
모델 서버는 일반적으로 다음 기능을 제공합니다.
- 모델 로딩 – 서버는 훈련된 ML 모델을 메모리에 로드하여 예측을 제공할 수 있도록 준비합니다.
- 추론 API – 서버는 클라이언트 애플리케이션이 입력 데이터를 보내고 배포된 모델로부터 예측을 받을 수 있도록 하는 API를 노출합니다.
- 스케일링 – 모델 서버는 여러 클라이언트의 동시 요청을 처리하도록 설계되었습니다. 이는 높은 처리량과 짧은 대기 시간을 보장하기 위해 병렬 처리 및 리소스 관리를 위한 메커니즘을 제공합니다.
- 백엔드 엔진과 통합 – 모델 서버는 DeepSpeed 및 FasterTransformer와 같은 백엔드 프레임워크와 통합되어 대규모 모델을 분할하고 고도로 최적화된 추론을 실행합니다.
DJL 아키텍처
DJL 서빙 오픈 소스, 고성능, 범용 모델 서버입니다. DJL Serving은 다음을 기반으로 구축되었습니다. Djl, Java 프로그래밍 언어로 작성된 딥 러닝 라이브러리입니다. 딥 러닝 모델, 여러 모델 또는 워크플로를 가져와 HTTP 엔드포인트를 통해 사용할 수 있게 만들 수 있습니다. DJL Serving은 PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer 등과 같은 여러 프레임워크에서 모델 배포를 지원합니다.
DJL Serving은 모델을 고성능으로 배포할 수 있는 다양한 기능을 제공합니다.
- 사용 용이성 – DJL Serving은 대부분의 모델에 즉시 서비스를 제공할 수 있습니다. 모델 아티팩트만 가져오면 DJL Serving이 이를 호스팅할 수 있습니다.
- 다중 장치 및 가속기 지원 – DJL Serving은 CPU, GPU 및 모델 배포를 지원합니다. AWS 인 페렌 시아.
- 퍼포먼스 – DJL Serving은 처리량을 높이기 위해 단일 JVM에서 멀티스레드 추론을 실행합니다.
- 동적 일괄 처리 – DJL Serving은 처리량을 높이기 위해 동적 일괄 처리를 지원합니다.
- 자동 스케일링 – DJL Serving은 트래픽 부하에 따라 작업자를 자동으로 확장 및 축소합니다.
- 다중 엔진 지원 – DJL Serving은 다양한 프레임워크(예: PyTorch 및 TensorFlow)를 사용하여 모델을 동시에 호스팅할 수 있습니다.
- 앙상블 및 워크플로우 모델 – DJL Serving은 여러 모델로 구성된 복잡한 워크플로 배포를 지원하고 워크플로의 일부는 CPU에서, 일부는 GPU에서 실행합니다. 워크플로 내의 모델은 다양한 프레임워크를 사용할 수 있습니다.
특히 DJL Serving의 자동 크기 조정 기능을 사용하면 모델이 들어오는 트래픽에 맞게 적절하게 크기 조정되도록 간단하게 수행할 수 있습니다. 기본적으로 DJL Serving은 사용 가능한 하드웨어(CPU 코어, GPU 장치)를 기반으로 지원할 수 있는 모델의 최대 작업자 수를 결정합니다. 최소 트래픽 수준이 항상 제공될 수 있고 단일 모델이 사용 가능한 모든 리소스를 소비하지 않도록 각 모델에 대해 하한 및 상한을 설정할 수 있습니다.
DJL Serving은 그물코 백엔드 작업자 스레드 풀 위에 프런트엔드가 있습니다. 프런트엔드는 여러 개의 단일 Netty 설정을 사용합니다. HttpRequestHandlers. 다양한 요청 핸들러가 다음을 지원합니다. 추론 API, 관리 API, 또는 다양한 플러그인에서 사용할 수 있는 기타 API.
백엔드는 다음을 기반으로 합니다. 워크로드 매니저 (WLM) 모듈. WLM은 일괄 처리 및 요청 라우팅과 함께 각 모델에 대한 여러 작업자 스레드를 관리합니다. 여러 모델이 제공되는 경우 WLM은 먼저 각 모델의 추론 요청 대기열 크기를 확인합니다. 대기열 크기가 모델 배치 크기의 2배보다 큰 경우 WLM은 해당 모델에 할당된 작업자 수를 확장합니다.
솔루션 개요
MME를 통한 DJL 구현은 기본 MMS 설정과 다릅니다. MME를 사용한 DJL 서비스의 경우 SageMaker 추론이 예상하는 model.tar.gz 형식으로 다음 파일을 압축합니다.
- 모델.joblib – 이 구현을 위해 모델 메타데이터를 tarball에 직접 푸시합니다. 이 경우 우리는 다음과 같이 작업하고 있습니다.
.joblib파일이므로 추론 스크립트가 읽을 수 있도록 tarball에 해당 파일을 제공합니다. 아티팩트가 너무 크면 이를 Amazon S3에 푸시하고 DJL에 대해 정의한 제공 구성에서 이를 가리킬 수도 있습니다. - 서빙.속성 – 여기서는 서버와 관련된 모든 모델을 구성할 수 있습니다. 환경 변수. 여기서 DJL의 장점은 구성이 가능하다는 것입니다.
minWorkers과maxWorkers각 모델 타르볼마다. 이를 통해 각 모델을 모델 서버 수준에서 확장 및 축소할 수 있습니다. 예를 들어 단일 모델이 MME에 대한 트래픽의 대부분을 수신하는 경우 모델 서버는 작업자를 동적으로 확장합니다. 이 예에서는 이러한 변수를 구성하지 않으며 DJL이 트래픽 패턴에 따라 필요한 작업자 수를 결정하도록 합니다. - 모델.py – 구현하려는 사용자 정의 전처리 또는 후처리를 위한 추론 스크립트입니다. model.py는 기본적으로 논리가 핸들 메소드에 캡슐화될 것으로 예상합니다.
- 요구 사항.txt(선택 사항) – 기본적으로 DJL은 PyTorch와 함께 설치되지만 필요한 추가 종속성은 여기에 푸시할 수 있습니다.
이 예에서는 샘플 SKLearn 모델을 사용하여 MME와 함께 DJL의 강력한 기능을 보여줍니다. 우리는 이 모델을 사용하여 훈련 작업을 실행한 다음 MME를 지원하기 위해 이 모델 아티팩트의 복사본 1,000개를 생성합니다. 그런 다음 MME가 수신할 수 있는 모든 유형의 트래픽 패턴을 처리하기 위해 DJL이 어떻게 동적으로 확장할 수 있는지 보여줍니다. 여기에는 모든 모델 또는 트래픽의 대부분을 수신하는 몇 가지 인기 모델 전반에 걸쳐 트래픽을 균등하게 분배하는 것이 포함될 수 있습니다. 다음에서 모든 코드를 찾을 수 있습니다. GitHub 레포.
사전 조건
이 예에서는 conda_python3 커널 및 ml.c5.xlarge 인스턴스와 함께 SageMaker 노트북 인스턴스를 사용합니다. 부하 테스트를 수행하려면 아마존 엘라스틱 컴퓨트 클라우드 (Amazon EC2) 인스턴스 또는 더 큰 SageMaker 노트북 인스턴스. 이 예에서는 TPS(초당 트랜잭션 수)가 2개 이상으로 확장되므로 더 많은 컴퓨팅을 사용할 수 있도록 ml.c5.18xlarge와 같은 더 무거운 ECXNUMX 인스턴스에서 테스트하는 것이 좋습니다.
모델 아티팩트 만들기
먼저 이 예에서 사용하는 모델 아티팩트와 데이터를 생성해야 합니다. 이 경우 NumPy로 인공 데이터를 생성하고 다음 코드 조각과 함께 SKLearn 선형 회귀 모델을 사용하여 학습합니다.
앞의 코드를 실행한 후에는 model.joblib 로컬 환경에서 생성된 파일입니다.
DJL Docker 이미지 가져오기
Docker 이미지 djl-inference:0.23.0-cpu-full-v1.0은 이 예에서 사용된 DJL 제공 컨테이너입니다. 지역에 따라 다음 URL을 조정할 수 있습니다.
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
선택적으로 이 이미지를 기본 이미지로 사용하고 이를 확장하여 자체 Docker 이미지를 구축할 수도 있습니다. Amazon Elastic Container Registry (Amazon ECR)에 필요한 다른 종속성을 포함합니다.
모델 파일 생성
먼저 라는 파일을 생성합니다. serving.properties. 이는 DJLServing에 Python 엔진을 사용하도록 지시합니다. 우리는 또한 max_idle_time 작업자의 시간은 600초입니다. 이렇게 하면 모델당 작업자 수를 축소하는 데 시간이 더 오래 걸립니다. 우리는 조정하지 않습니다 minWorkers 과 maxWorkers 정의할 수 있으며 DJL이 각 모델이 수신하는 트래픽에 따라 필요한 작업자 수를 동적으로 계산하도록 합니다. Serving.properties는 다음과 같습니다. 구성 옵션의 전체 목록을 보려면 다음을 참조하세요. 엔진 구성.
다음으로 모델 로딩 및 추론 논리를 정의하는 model.py 파일을 만듭니다. MME의 경우 각 model.py 파일은 모델마다 다릅니다. 모델은 모델 저장소 아래의 자체 경로에 저장됩니다(일반적으로 /opt/ml/model/). 모델을 로드할 때 해당 디렉터리의 모델 저장소 경로 아래에 로드됩니다. 이 데모의 전체 model.py 예제는 다음에서 볼 수 있습니다. GitHub 레포.
우리는 model.tar.gz 모델을 포함하는 파일(model.joblib), model.py및 serving.properties:
데모 목적으로 동일한 사본을 1,000개 만듭니다. model.tar.gz 호스팅할 많은 수의 모델을 나타내는 파일입니다. 프로덕션에서는 model.tar.gz 각 모델에 대한 파일입니다.
마지막으로 이러한 모델을 Amazon S3에 업로드합니다.
SageMaker 모델 생성
우리는 이제 세이지메이커 모델. 앞서 정의한 ECR 이미지와 이전 단계의 모델 아티팩트를 사용하여 SageMaker 모델을 생성합니다. 모델 설정에서는 모드를 MultiModel로 구성합니다. 이는 DJLServing에게 MME를 생성 중임을 알려줍니다.
SageMaker 엔드포인트 생성
이 데모에서는 20개의 ml.c5d.18xlarge 인스턴스를 사용하여 수천 범위의 TPS로 확장합니다. 목표로 하는 TPS를 달성하려면 필요한 경우 인스턴스 유형에 대한 한도를 늘려야 합니다.
부하 테스트
이 글을 쓰는 시점에는 SageMaker 내부 부하 테스트 도구가 사용되었습니다. Amazon SageMaker 추론 추천자 기본적으로 MME에 대한 테스트를 지원하지 않습니다. 따라서 우리는 오픈 소스 Python 도구를 사용합니다. 메뚜기. Locust는 설정이 간단하며 TPS 및 엔드투엔드 대기 시간과 같은 지표를 추적할 수 있습니다. SageMaker를 사용하여 설정하는 방법을 완전히 이해하려면 다음을 참조하세요. 부하 테스트를 위한 모범 사례 Amazon SageMaker 실시간 추론 엔드포인트.
이 사용 사례에는 MME로 시뮬레이션하려는 세 가지 트래픽 패턴이 있으므로 각 패턴에 맞는 다음 세 가지 Python 스크립트가 있습니다. 여기서 우리의 목표는 트래픽 패턴에 관계없이 동일한 목표 TPS를 달성하고 적절하게 확장할 수 있음을 증명하는 것입니다.
Locust 스크립트에 가중치를 지정하여 모델의 여러 부분에 트래픽을 할당할 수 있습니다. 예를 들어 단일 핫 모델을 사용하면 다음과 같은 두 가지 방법을 구현합니다.
그런 다음 각 방법에 특정 가중치를 할당할 수 있는데, 이는 특정 방법이 트래픽의 특정 비율을 수신하는 경우입니다.
20개의 ml.c5d.18xlarge 인스턴스의 경우 다음 호출 지표가 표시됩니다. 아마존 클라우드 워치 콘솔. 이러한 값은 세 가지 트래픽 패턴 모두에서 상당히 일관되게 유지됩니다. SageMaker 실시간 추론 및 MME에 대한 CloudWatch 지표를 더 잘 이해하려면 다음을 참조하십시오. SageMaker 끝점 호출 메트릭.
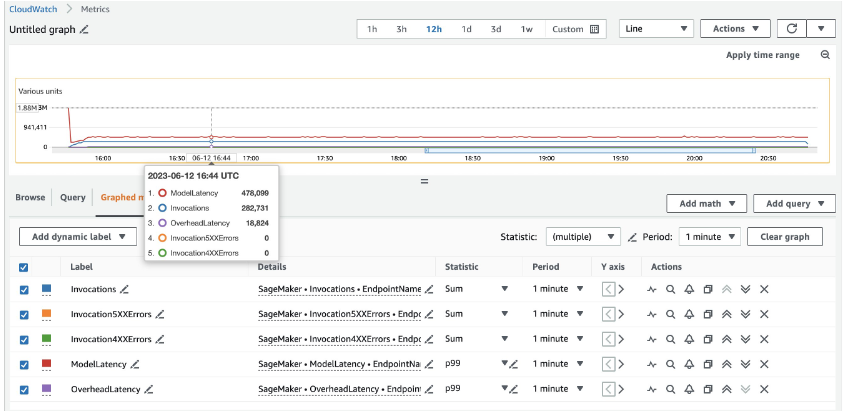
Locust 스크립트의 나머지 부분은 다음에서 찾을 수 있습니다. locust-utils 디렉토리 GitHub 저장소에 있습니다.
요약
이 게시물에서는 MME가 모델의 트래픽 패턴을 기반으로 각 모델에 할당된 컴퓨팅 성능을 동적으로 조정하는 방법에 대해 논의했습니다. 새로 출시된 이 기능은 SageMaker를 사용할 수 있는 모든 AWS 리전에서 사용할 수 있습니다. 발표 시점에는 CPU 인스턴스만 지원됩니다. 자세한 내용은 다음을 참조하세요. 지원되는 알고리즘, 프레임워크 및 인스턴스.
저자에 관하여
 램 베기라주 SageMaker 서비스 팀의 ML 설계자입니다. 그는 고객이 Amazon SageMaker에서 AI/ML 솔루션을 구축하고 최적화하도록 돕는 데 중점을 두고 있습니다. 여가 시간에는 여행과 글쓰기를 좋아합니다.
램 베기라주 SageMaker 서비스 팀의 ML 설계자입니다. 그는 고객이 Amazon SageMaker에서 AI/ML 솔루션을 구축하고 최적화하도록 돕는 데 중점을 두고 있습니다. 여가 시간에는 여행과 글쓰기를 좋아합니다.
 칭 웨이 리 Amazon Web Services의 기계 학습 전문가입니다. 그는 박사 학위를 받았습니다. 그는 고문의 연구 보조금 계좌를 깨고 그가 약속 한 노벨상을 전달하지 못한 후 Operations Research에서 현재 그는 금융 서비스 및 보험 업계의 고객이 AWS에서 기계 학습 솔루션을 구축하도록 돕습니다. 여가 시간에는 읽기와 가르치기를 좋아합니다.
칭 웨이 리 Amazon Web Services의 기계 학습 전문가입니다. 그는 박사 학위를 받았습니다. 그는 고문의 연구 보조금 계좌를 깨고 그가 약속 한 노벨상을 전달하지 못한 후 Operations Research에서 현재 그는 금융 서비스 및 보험 업계의 고객이 AWS에서 기계 학습 솔루션을 구축하도록 돕습니다. 여가 시간에는 읽기와 가르치기를 좋아합니다.
 제임스 우 AWS의 수석 AI/ML 전문가 솔루션 아키텍트입니다. 고객이 AI/ML 솔루션을 설계하고 구축할 수 있도록 지원합니다. James의 작업은 컴퓨터 비전, 딥 러닝, 기업 전반에 걸친 ML 확장에 대한 주요 관심과 함께 광범위한 ML 사용 사례를 다룹니다. AWS에 합류하기 전에 James는 엔지니어링 분야에서 10년, 마케팅 및 광고 산업 분야에서 6년을 포함하여 4년 넘게 건축가, 개발자 및 기술 리더였습니다.
제임스 우 AWS의 수석 AI/ML 전문가 솔루션 아키텍트입니다. 고객이 AI/ML 솔루션을 설계하고 구축할 수 있도록 지원합니다. James의 작업은 컴퓨터 비전, 딥 러닝, 기업 전반에 걸친 ML 확장에 대한 주요 관심과 함께 광범위한 ML 사용 사례를 다룹니다. AWS에 합류하기 전에 James는 엔지니어링 분야에서 10년, 마케팅 및 광고 산업 분야에서 6년을 포함하여 4년 넘게 건축가, 개발자 및 기술 리더였습니다.
 사우라브 트리칸데 Amazon SageMaker Inference의 수석 제품 관리자입니다. 그는 고객과 함께 일하는 데 열정적이며 기계 학습의 민주화라는 목표에 동기를 부여합니다. 그는 복잡한 ML 애플리케이션, 다중 테넌트 ML 모델 배포, 비용 최적화 및 딥 러닝 모델 배포의 접근성 향상과 관련된 핵심 과제에 중점을 둡니다. 여가 시간에 Saurabh는 하이킹, 혁신적인 기술 학습, TechCrunch 팔로우, 가족과 함께 시간 보내기를 즐깁니다.
사우라브 트리칸데 Amazon SageMaker Inference의 수석 제품 관리자입니다. 그는 고객과 함께 일하는 데 열정적이며 기계 학습의 민주화라는 목표에 동기를 부여합니다. 그는 복잡한 ML 애플리케이션, 다중 테넌트 ML 모델 배포, 비용 최적화 및 딥 러닝 모델 배포의 접근성 향상과 관련된 핵심 과제에 중점을 둡니다. 여가 시간에 Saurabh는 하이킹, 혁신적인 기술 학습, TechCrunch 팔로우, 가족과 함께 시간 보내기를 즐깁니다.
 쉬 덩 SageMaker 팀의 소프트웨어 엔지니어 관리자입니다. 그는 고객이 Amazon SageMaker에서 AI/ML 추론 경험을 구축하고 최적화하도록 돕는 데 중점을 두고 있습니다. 여가 시간에는 여행과 스노보드 타기를 좋아합니다.
쉬 덩 SageMaker 팀의 소프트웨어 엔지니어 관리자입니다. 그는 고객이 Amazon SageMaker에서 AI/ML 추론 경험을 구축하고 최적화하도록 돕는 데 중점을 두고 있습니다. 여가 시간에는 여행과 스노보드 타기를 좋아합니다.
 싯다르트 벤카테산 AWS Deep Learning의 소프트웨어 엔지니어입니다. 그는 현재 대규모 모델 추론을 위한 솔루션 구축에 집중하고 있습니다. AWS에 합류하기 전에는 Amazon Grocery 조직에서 전 세계 고객을 위한 새로운 결제 기능을 구축하는 일을 했습니다. 일 외에는 스키, 야외 활동, 스포츠 관전을 즐깁니다.
싯다르트 벤카테산 AWS Deep Learning의 소프트웨어 엔지니어입니다. 그는 현재 대규모 모델 추론을 위한 솔루션 구축에 집중하고 있습니다. AWS에 합류하기 전에는 Amazon Grocery 조직에서 전 세계 고객을 위한 새로운 결제 기능을 구축하는 일을 했습니다. 일 외에는 스키, 야외 활동, 스포츠 관전을 즐깁니다.
 로히스 날라마디 AWS의 소프트웨어 개발 엔지니어입니다. 그는 GPU에서 딥 러닝 워크로드를 최적화하고 고성능 ML 추론을 구축하고 솔루션을 제공하는 일을 합니다. 그 전에는 Amazon F3 비즈니스를 위해 AWS를 기반으로 마이크로서비스를 구축하는 일을 했습니다. 직장 밖에서는 스포츠 경기와 관람을 즐깁니다.
로히스 날라마디 AWS의 소프트웨어 개발 엔지니어입니다. 그는 GPU에서 딥 러닝 워크로드를 최적화하고 고성능 ML 추론을 구축하고 솔루션을 제공하는 일을 합니다. 그 전에는 Amazon F3 비즈니스를 위해 AWS를 기반으로 마이크로서비스를 구축하는 일을 했습니다. 직장 밖에서는 스포츠 경기와 관람을 즐깁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

