동물원 디지털 원본 TV 및 영화 콘텐츠를 다양한 언어, 지역 및 문화에 맞게 조정할 수 있는 엔드투엔드 현지화 및 미디어 서비스를 제공합니다. 이는 세계 최고의 콘텐츠 제작자를 위한 세계화를 더 쉽게 만듭니다. 엔터테인먼트 분야의 유명 기업들이 신뢰하는 ZOO Digital은 더빙, 자막, 스크립팅 및 규정 준수를 포함하여 대규모로 고품질 현지화 및 미디어 서비스를 제공합니다.
일반적인 현지화 워크플로에는 화자의 신원을 기준으로 오디오 스트림이 분할되는 수동 화자 분할이 필요합니다. 콘텐츠를 다른 언어로 더빙하려면 시간이 많이 걸리는 이 프로세스를 완료해야 합니다. 수동 방법을 사용하면 30분짜리 에피소드를 현지화하는 데 1~3시간이 걸릴 수 있습니다. ZOO Digital은 자동화를 통해 30분 이내에 현지화를 달성하는 것을 목표로 하고 있습니다.
이 게시물에서는 다음을 사용하여 미디어 콘텐츠를 분할하기 위한 확장 가능한 기계 학습(ML) 모델 배포에 대해 논의합니다. 아마존 세이지 메이커, 에 중점을 두고 속삭임X 모델입니다.
배경
ZOO Digital의 비전은 현지화된 콘텐츠의 더 빠른 처리 시간을 제공하는 것입니다. 이 목표는 콘텐츠를 수동으로 현지화할 수 있는 숙련된 인력으로 구성된 소규모 인력으로 인해 발생하는 수동 집약적 성격으로 인해 병목 현상이 발생합니다. ZOO Digital은 11,000명이 넘는 프리랜서와 협력하고 있으며 600년에만 2022억 단어가 넘는 단어를 현지화했습니다. 그러나 컨텐츠에 대한 수요 증가로 인해 숙련된 인력의 공급이 부족해 현지화 워크플로우를 지원하기 위한 자동화가 필요합니다.
기계 학습을 통해 콘텐츠 워크플로의 현지화를 가속화하려는 목표로 ZOO Digital은 고객과 워크로드를 공동 구축하기 위한 AWS의 투자 프로그램인 AWS Prototyping을 활용했습니다. 이 계약은 현지화 프로세스를 위한 기능적 솔루션을 제공하는 동시에 SageMaker에서 ZOO Digital 개발자에게 실습 교육을 제공하는 데 중점을 두었습니다. 아마존 전사및 아마존 번역.
고객의 과제
제목(영화 또는 TV 시리즈의 에피소드)이 전사된 후 캐릭터를 연기하기 위해 캐스팅된 성우에게 올바르게 할당될 수 있도록 각 음성 세그먼트에 화자를 할당해야 합니다. 이 프로세스를 화자 분할이라고 합니다. ZOO Digital은 경제적으로 실행 가능하면서도 대규모로 콘텐츠를 분할해야 하는 과제에 직면해 있습니다.
솔루션 개요
이 프로토타입에서는 원본 미디어 파일을 지정된 위치에 저장했습니다. 아마존 단순 스토리지 서비스 (Amazon S3) 버킷. 이 S3 버킷은 새 파일이 감지되면 이벤트를 내보내도록 구성되어 있습니다. AWS 람다 기능. 이 트리거 구성에 대한 지침은 튜토리얼을 참조하세요. Amazon S3 트리거를 사용하여 Lambda 함수 호출. 그 후 Lambda 함수는 추론을 위해 SageMaker 엔드포인트를 호출했습니다. Boto3 SageMaker 런타임 클라이언트.
XNUMXD덴탈의 속삭임X 모델, 기반 OpenAI의 속삭임, 미디어 자산에 대한 전사 및 분할을 수행합니다. 그것은 기반으로 구축되었습니다 더 빠른 속삭임 다시 구현하여 Whisper에 비해 향상된 단어 수준 타임스탬프 정렬로 최대 4배 더 빠른 전사를 제공합니다. 또한 원래 Whisper 모델에는 없었던 스피커 분할 기능을 도입했습니다. WhisperX는 전사를 위해 Whisper 모델을 활용합니다. Wav2Vec2 타임스탬프 정렬을 강화하는 모델(오디오 타임스탬프와 녹음된 텍스트의 동기화 보장) 피아니노트 분할 모델. 는 FFmpeg 소스 미디어에서 오디오를 로드하는 데 사용되며 다양한 지원 미디어 형식. 투명한 모듈식 모델 아키텍처는 향후 필요에 따라 모델의 각 구성 요소를 교체할 수 있으므로 유연성을 허용합니다. 그러나 WhisperX에는 전체 관리 기능이 부족하며 엔터프라이즈 수준의 제품이 아니라는 점에 유의하는 것이 중요합니다. 유지 관리 및 지원이 없으면 프로덕션 배포에 적합하지 않을 수 있습니다.
이번 협업에서 우리는 다음을 사용하여 SageMaker에 WhisperX를 배포하고 평가했습니다. 비동기 추론 엔드포인트 모델을 호스팅합니다. SageMaker 비동기 엔드포인트는 최대 1GB의 업로드 크기를 지원하고 트래픽 급증을 효율적으로 완화하고 사용량이 적은 시간 동안 비용을 절감하는 자동 조정 기능을 통합합니다. 비동기 엔드포인트는 우리 사용 사례에서 영화 및 TV 시리즈와 같은 대용량 파일을 처리하는 데 특히 적합합니다.
다음 다이어그램은 이번 협력에서 우리가 수행한 실험의 핵심 요소를 보여줍니다.

다음 섹션에서는 SageMaker에 WhisperX 모델을 배포하는 방법을 자세히 살펴보고 분할 성능을 평가합니다.
모델 및 해당 구성요소 다운로드
WhisperX는 전사, 강제 정렬 및 분할을 위한 여러 모델을 포함하는 시스템입니다. 추론 중에 모델 아티팩트를 가져올 필요 없이 원활한 SageMaker 작업을 위해서는 모든 모델 아티팩트를 사전 다운로드하는 것이 중요합니다. 그런 다음 이러한 아티팩트는 시작 중에 SageMaker 제공 컨테이너에 로드됩니다. 이러한 모델은 직접 액세스할 수 없기 때문에 WhisperX 소스의 설명과 샘플 코드를 제공하여 모델과 해당 구성 요소를 다운로드하는 방법에 대한 지침을 제공합니다.
WhisperX는 6가지 모델을 사용합니다:
이러한 모델의 대부분은 다음에서 얻을 수 있습니다. 포옹하는 얼굴 Huggingface_hub 라이브러리를 사용합니다. 우리는 다음을 사용합니다 download_hf_model() 이러한 모델 아티팩트를 검색하는 함수입니다. 다음 pyannote 모델에 대한 사용자 계약을 수락한 후 생성된 Hugging Face의 액세스 토큰이 필요합니다.
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
VAD 모델은 Amazon S3에서 가져오고 Wav2Vec2 모델은 torchaudio.pipelines 모듈에서 검색됩니다. 다음 코드를 기반으로 Hugging Face의 아티팩트를 포함하여 모든 모델의 아티팩트를 검색하여 지정된 로컬 모델 디렉터리에 저장할 수 있습니다.
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
모델 제공에 적합한 AWS Deep Learning Container를 선택하세요.
이전 샘플 코드를 사용하여 모델 아티팩트를 저장한 후 사전 빌드된 항목을 선택할 수 있습니다. AWS 딥 러닝 컨테이너 (DLC) 다음 중 GitHub 레포. Docker 이미지를 선택할 때 프레임워크(Hugging Face), 작업(추론), Python 버전, 하드웨어(예: GPU) 설정을 고려하세요. 다음 이미지를 사용하는 것이 좋습니다. 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 이 이미지에는 ffmpeg와 같은 필요한 모든 시스템 패키지가 사전 설치되어 있습니다. [REGION]을 사용 중인 AWS 리전으로 바꿔야 합니다.
기타 필수 Python 패키지의 경우 requirements.txt 패키지 및 해당 버전 목록이 포함된 파일입니다. 이러한 패키지는 AWS DLC가 구축될 때 설치됩니다. 다음은 SageMaker에서 WhisperX 모델을 호스팅하는 데 필요한 추가 패키지입니다.
모델을 로드하고 추론을 실행하는 추론 스크립트 만들기
다음으로 사용자 정의를 만듭니다. inference.py WhisperX 모델과 해당 구성 요소가 컨테이너에 로드되는 방법과 추론 프로세스가 실행되는 방법을 설명하는 스크립트입니다. 스크립트에는 두 가지 기능이 포함되어 있습니다. model_fn 과 transform_fn. 그만큼 model_fn 해당 위치에서 모델을 로드하기 위해 함수가 호출됩니다. 그 후, 이 모델은 다음으로 전달됩니다. transform_fn 전사, 정렬 및 분할 프로세스가 수행되는 추론 중에 기능합니다. 다음은 코드 샘플입니다. inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
모델 디렉토리 내에서 requirements.txt 파일이 있는지 확인하십시오. inference.py 코드 하위 디렉터리에 있습니다. 그만큼 models 디렉터리는 다음과 유사해야 합니다.
모델의 타르볼 생성
모델과 코드 디렉터리를 생성한 후 다음 명령줄을 사용하여 모델을 tarball(.tar.gz 파일)로 압축하고 Amazon S3에 업로드할 수 있습니다. 이 글을 쓰는 시점에서는 속도가 더 빠른 Large V2 모델을 사용하여 SageMaker 모델을 나타내는 결과 타르볼의 크기가 3GB입니다. 자세한 내용은 다음을 참조하세요. Amazon SageMaker의 모델 호스팅 패턴, 2부: SageMaker에서 실시간 모델 배포 시작하기.
SageMaker 모델을 생성하고 비동기 예측기를 사용하여 엔드포인트 배포
이제 다음을 사용하여 SageMaker 모델, 엔드포인트 구성 및 비동기 엔드포인트를 생성할 수 있습니다. 비동기 예측기 이전 단계에서 생성된 모델 tarball을 사용합니다. 지침은 다음을 참조하세요. 비동기 추론 끝점 만들기.
분할 성능 평가
다양한 시나리오에서 WhisperX 모델의 분할 성능을 평가하기 위해 두 개의 영어 제목에서 각각 세 개의 에피소드를 선택했습니다. 즉, 30분 에피소드로 구성된 드라마 제목 하나와 45분 에피소드로 구성된 다큐멘터리 제목 하나입니다. 우리는 pyannote의 측정 도구 키트를 활용했습니다. pyannote.metrics, 계산하기 위해 분할 오류율(DER). 평가에서는 ZOO에서 제공한 수동으로 전사하고 일기로 작성한 녹취록이 근거 자료로 사용되었습니다.
우리는 DER을 다음과 같이 정의했습니다.
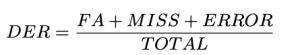
금액 실제 영상의 길이입니다. FA (False Alarm)은 예측에서는 음성으로 간주되지만 실제 진실에서는 고려되지 않는 세그먼트의 길이입니다. 미스 실측에서는 음성으로 간주되지만 예측에서는 고려되지 않는 세그먼트의 길이입니다. 오류라고도 혼동는 예측 및 지상 진실에서 서로 다른 화자에게 할당되는 세그먼트의 길이입니다. 모든 단위는 초 단위로 측정됩니다. DER의 일반적인 값은 특정 애플리케이션, 데이터 세트 및 분할 시스템의 품질에 따라 달라질 수 있습니다. DER은 1.0보다 클 수 있습니다. DER이 낮을수록 좋습니다.
미디어에 대한 DER을 계산하려면 WhisperX가 기록하고 분할한 출력뿐만 아니라 실제 분할도 필요합니다. 이는 구문 분석되어 미디어의 각 음성 세그먼트에 대한 화자 레이블, 음성 세그먼트 시작 시간 및 음성 세그먼트 종료 시간을 포함하는 튜플 목록이 생성되어야 합니다. WhisperX와 Ground Truth 분할 간에 화자 라벨이 일치할 필요는 없습니다. 결과는 주로 세그먼트 시간을 기반으로 합니다. pyannote.metrics는 이러한 Ground Truth 분할 및 출력 분할의 튜플을 취합니다(pyannote.metrics 문서에서 다음과 같이 참조됨). 참고 과 가설) DER을 계산합니다. 다음 표에는 결과가 요약되어 있습니다.
| 비디오 유형 | NS | 옳은 | 미스 | 오류 | 거짓 경보 |
| 드라마 | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| 다큐멘터리 | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| 평균 | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
이러한 결과는 드라마 제목과 다큐멘터리 제목 사이에 상당한 성능 차이가 있음을 보여 주며, 모델은 다큐멘터리 제목과 비교하여 드라마 에피소드에 대해 눈에 띄게 더 나은 결과(DER을 집계 지표로 사용)를 달성했습니다. 제목을 면밀히 분석하면 이러한 성과 격차에 기여하는 잠재적인 요인에 대한 통찰력을 얻을 수 있습니다. 한 가지 핵심 요인은 다큐멘터리 제목에 배경 음악이 대사와 겹치는 경우가 많다는 점입니다. 음성을 분리하기 위해 배경 소음을 제거하는 등 분할 정확도를 높이기 위한 미디어 전처리는 이 프로토타입의 범위를 벗어났지만 잠재적으로 WhisperX의 성능을 향상할 수 있는 향후 작업의 길을 열어줍니다.
결론
이 게시물에서는 분할 워크플로를 향상시키기 위해 SageMaker 및 WhisperX 모델과 함께 기계 학습 기술을 사용하여 AWS와 ZOO Digital 간의 협력 파트너십을 살펴보았습니다. AWS 팀은 분할을 위해 특별히 설계된 사용자 지정 ML 모델의 효과적인 배포를 프로토타입화, 평가 및 이해하는 과정에서 ZOO를 지원하는 데 중추적인 역할을 했습니다. 여기에는 SageMaker를 사용하여 확장성을 위한 자동 크기 조정 통합이 포함되었습니다.
분할을 위해 AI를 활용하면 ZOO를 위한 현지화된 콘텐츠를 생성할 때 비용과 시간 모두에서 상당한 절감 효과를 얻을 수 있습니다. 화자를 신속하고 정확하게 생성하고 식별하는 점역자를 지원함으로써 이 기술은 전통적으로 시간이 많이 걸리고 오류가 발생하기 쉬운 작업 특성을 해결합니다. 기존 프로세스에서는 오류를 최소화하기 위해 비디오를 여러 번 통과하고 추가 품질 관리 단계를 거치는 경우가 많습니다. 분할을 위해 AI를 채택하면 보다 목표화되고 효율적인 접근 방식이 가능해지며, 이를 통해 더 짧은 시간 내에 생산성이 향상됩니다.
SageMaker 비동기 엔드포인트에 WhisperX 모델을 배포하는 주요 단계를 설명했으며 제공된 코드를 사용하여 직접 시도해 보시기 바랍니다. ZOO Digital의 서비스 및 기술에 대한 자세한 내용을 보려면 다음을 방문하세요. ZOO Digital 공식 사이트. SageMaker 및 다양한 추론 옵션에 OpenAI Whisper 모델을 배포하는 방법에 대한 자세한 내용은 다음을 참조하세요. Amazon SageMaker에서 속삭임 모델 호스팅: 추론 옵션 탐색. 댓글로 여러분의 생각을 자유롭게 공유해 주세요.
저자에 관하여
 잉 허우 박사는 AWS의 기계 학습 프로토타이핑 아키텍트입니다. 그녀의 주요 관심 분야는 GenAI, 컴퓨터 비전, NLP 및 시계열 데이터 예측에 중점을 둔 딥 러닝입니다. 여가 시간에는 가족과 함께 좋은 시간을 보내고, 소설에 푹 빠져 있으며, 영국 국립공원에서 하이킹을 즐깁니다.
잉 허우 박사는 AWS의 기계 학습 프로토타이핑 아키텍트입니다. 그녀의 주요 관심 분야는 GenAI, 컴퓨터 비전, NLP 및 시계열 데이터 예측에 중점을 둔 딥 러닝입니다. 여가 시간에는 가족과 함께 좋은 시간을 보내고, 소설에 푹 빠져 있으며, 영국 국립공원에서 하이킹을 즐깁니다.
 에단 컴벌랜드 ZOO Digital의 AI 연구 엔지니어로서 AI와 머신러닝을 보조 기술로 사용하여 음성, 언어, 현지화 작업 흐름을 개선하는 작업을 하고 있습니다. 그는 보안 및 치안 분야의 소프트웨어 엔지니어링 및 연구에 대한 배경 지식을 갖고 있으며 웹에서 구조화된 정보를 추출하고 오픈 소스 ML 모델을 활용하여 수집된 데이터를 분석하고 강화하는 데 중점을 두고 있습니다.
에단 컴벌랜드 ZOO Digital의 AI 연구 엔지니어로서 AI와 머신러닝을 보조 기술로 사용하여 음성, 언어, 현지화 작업 흐름을 개선하는 작업을 하고 있습니다. 그는 보안 및 치안 분야의 소프트웨어 엔지니어링 및 연구에 대한 배경 지식을 갖고 있으며 웹에서 구조화된 정보를 추출하고 오픈 소스 ML 모델을 활용하여 수집된 데이터를 분석하고 강화하는 데 중점을 두고 있습니다.
 가우라브 카일라 영국과 아일랜드의 AWS 프로토타이핑 팀을 이끌고 있습니다. 그의 팀은 다양한 업계의 고객과 협력하여 AWS 서비스 채택을 가속화하기 위한 임무를 가지고 비즈니스에 중요한 워크로드를 구상하고 공동 개발합니다.
가우라브 카일라 영국과 아일랜드의 AWS 프로토타이핑 팀을 이끌고 있습니다. 그의 팀은 다양한 업계의 고객과 협력하여 AWS 서비스 채택을 가속화하기 위한 임무를 가지고 비즈니스에 중요한 워크로드를 구상하고 공동 개발합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

