생성적 AI 애플리케이션을 구축하려면 새로운 데이터로 대규모 언어 모델(LLM)을 강화하는 것이 필수적입니다. RAG(Retrieval Augmented Generation) 기술이 등장하는 곳입니다. RAG는 외부 문서(예: Wikipedia)를 사용하여 지식을 강화하고 지식 집약적인 작업에 대한 최첨단 결과를 달성하는 기계 학습(ML) 아키텍처입니다. . 이러한 외부 데이터 소스를 수집하기 위해 데이터 소스의 벡터 임베딩을 저장하고 유사성 검색을 허용하는 벡터 데이터베이스가 발전했습니다.
이 게시물에서는 RAG 추출, 변환 및 로드(ETL) 수집 파이프라인을 구축하여 대량의 데이터를 아마존 오픈서치 서비스 클러스터링 및 사용 PostgreSQL용 Amazon Relational Database Service(Amazon RDS) pgVector 확장자를 벡터 데이터 저장소로 사용합니다. 각 서비스는 k-NN(k-Nearest Neighbor) 또는 ANN(Approximous Nearest Neighbor) 알고리즘과 거리 측정법을 구현하여 유사성을 계산합니다. 통합을 소개합니다. 레이 RAG 상황별 문서 검색 메커니즘으로 전환됩니다. Ray는 오픈 소스, Python, 범용 분산 컴퓨팅 라이브러리입니다. 이를 통해 분산 데이터 처리를 통해 대량의 데이터에 대한 임베딩을 생성 및 저장하고 여러 GPU에 걸쳐 병렬화할 수 있습니다. 우리는 이러한 GPU와 함께 Ray 클러스터를 사용하여 각 서비스에 대해 병렬 수집 및 쿼리를 실행합니다.
이 실험에서는 Amazon RDS의 OpenSearch Service 및 pgVector 확장에 대한 다음 측면을 분석하려고 합니다.
- 벡터 저장소로서 RAG에 대한 수천만 개의 레코드가 포함된 대규모 데이터 세트를 확장하고 처리하는 기능
- RAG의 수집 파이프라인에서 병목 현상이 발생할 수 있음
- OpenSearch Service 및 Amazon RDS에 대한 수집 및 쿼리 검색 시간에서 최적의 성능을 달성하는 방법
벡터 데이터 저장소와 생성 AI 애플리케이션 구축에서의 역할에 대해 자세히 알아보려면 다음을 참조하세요. 생성적 AI 애플리케이션에서 벡터 데이터스토어의 역할.
OpenSearch 서비스 개요
OpenSearch 서비스는 비즈니스 및 운영 데이터를 안전하게 분석, 검색, 색인화하기 위한 관리형 서비스입니다. OpenSearch 서비스는 텍스트 및 벡터 데이터에 대한 여러 인덱스를 생성하는 기능을 통해 페타바이트 규모의 데이터를 지원합니다. 최적화된 구성으로 쿼리에 대한 높은 재현율을 목표로 합니다. OpenSearch 서비스는 ANN과 정확한 k-NN 검색을 지원합니다. OpenSearch 서비스는 다음에서 알고리즘 선택을 지원합니다. NMSLIB, 파이스및 루센 k-NN 검색을 지원하는 라이브러리입니다. 우리는 HNSW(Hierarchical Navigable Small World) 알고리즘을 사용하여 OpenSearch용 ANN 인덱스를 만들었습니다. 이는 대규모 데이터 세트에 대한 더 나은 검색 방법으로 간주되기 때문입니다. 인덱스 알고리즘 선택에 대한 자세한 내용은 다음을 참조하세요. OpenSearch를 사용하여 XNUMX억 규모 사용 사례에 대한 k-NN 알고리즘 선택.
pgVector를 사용한 PostgreSQL용 Amazon RDS 개요
pgVector 확장은 PostgreSQL에 오픈 소스 벡터 유사성 검색을 추가합니다. PostgreSQL은 pgVector 확장을 활용하여 벡터 임베딩에 대한 유사성 검색을 수행하여 기업에 빠르고 능숙한 솔루션을 제공할 수 있습니다. pgVector는 두 가지 유형의 벡터 유사성 검색을 제공합니다. 즉, 100% 재현율을 나타내는 정확한 최근접 이웃과 재현율을 절충하여 정확한 검색보다 더 나은 성능을 제공하는 근사 최근접 이웃(ANN)입니다. 인덱스에 대한 검색의 경우 검색에 사용할 센터 수를 선택할 수 있습니다. 센터가 많을수록 성능을 희생하면서 더 나은 재현율을 제공할 수 있습니다.
솔루션 개요
다음 다이어그램은 솔루션 아키텍처를 보여줍니다.

주요 구성요소를 좀 더 자세히 살펴보겠습니다.
데이터 세트
우리는 OSCAR 데이터를 코퍼스로 사용하고 SQUAD 데이터세트를 사용하여 샘플 질문을 제공합니다. 이러한 데이터 세트는 먼저 Parquet 파일로 변환됩니다. 그런 다음 Ray 클러스터를 사용하여 Parquet 데이터를 임베딩으로 변환합니다. 생성된 임베딩은 pgVector를 통해 OpenSearch Service 및 Amazon RDS로 수집됩니다.
OSCAR(Open Super-large Crawled Aggregated corpus)는 언어 분류 및 필터링을 통해 얻은 거대한 다국어 코퍼스입니다. 일반적인 크롤링 코퍼스를 사용하는 무자비한 건축학. 데이터는 원본 형식과 중복 제거된 형식으로 언어별로 배포됩니다. Oscar Corpus 데이터 세트는 약 609억 4.5백만 개의 레코드로 구성되어 있으며 원시 JSONL 파일로 약 1.8TB를 차지합니다. 그런 다음 JSONL 파일은 Parquet 형식으로 변환되어 전체 크기가 25TB로 최소화됩니다. 수집하는 동안 시간을 절약하기 위해 데이터세트를 XNUMX만 개의 레코드로 더욱 축소했습니다.
SQuAD(Stanford Question Answering Dataset)는 Wikipedia 기사 세트에 대해 크라우드 작업자가 제기한 질문으로 구성된 독해 데이터 세트입니다. 여기서 모든 질문에 대한 답변은 텍스트 세그먼트입니다. 기간, 해당 읽기 구절에서 또는 질문에 답할 수 없을 수도 있습니다. 우리는 사용 분대, 라이센스가 부여된 CC-BY-SA 4.0, 샘플 질문 제공. 여기에는 대략 100,000개의 질문이 있으며, 50,000개 이상의 답변할 수 없는 질문은 크라우드 작업자가 답변할 수 있는 질문과 유사하게 작성했습니다.
수집 및 벡터 임베딩 생성을 위한 광선 클러스터
테스트에서 우리는 임베딩을 생성할 때 GPU가 성능에 가장 큰 영향을 미치는 것으로 나타났습니다. 따라서 우리는 Ray 클러스터를 사용하여 원시 텍스트를 변환하고 임베딩을 생성하기로 결정했습니다. 레이 ML 엔지니어와 Python 개발자가 Python 애플리케이션을 확장하고 ML 워크로드를 가속화할 수 있도록 지원하는 오픈 소스 통합 컴퓨팅 프레임워크입니다. 우리 클러스터는 5개의 g4dn.12xlarge로 구성되었습니다. 아마존 엘라스틱 컴퓨트 클라우드 (Amazon EC2) 인스턴스. 각 인스턴스는 NVIDIA T4 Tensor Core GPU 4개, vCPU 48개, 메모리 192GiB로 구성되었습니다. 텍스트 레코드의 경우 1,000개의 청크가 겹치면서 각각을 100개의 조각으로 나누었습니다. 이는 레코드당 약 200개로 나뉩니다. 임베딩을 생성하는 데 사용되는 모델에 대해 우리는 다음과 같이 결정했습니다. 모든-mpnet-베이스-v2 768차원 벡터 공간을 생성합니다.
인프라 설정
우리는 인프라를 설정하기 위해 다음 RDS 인스턴스 유형과 OpenSearch 서비스 클러스터 구성을 사용했습니다.
다음은 RDS 인스턴스 유형 속성입니다.
- 인스턴스 유형: db.r7g.12xlarge
- 할당된 스토리지: 20TB
- 다중 AZ: 참
- 암호화된 저장소: True
- 성능 개선 도우미 활성화: True
- Performance Insight 보존: 7일
- 저장 유형: gp3
- 프로비저닝된 IOPS: 64,000
- 지수 유형: IVF
- 목록 수: 5,000
- 거리 함수: L2
다음은 OpenSearch 서비스 클러스터 속성입니다.
- 버전 : 2.5
- 데이터 노드: 10
- 데이터 노드 인스턴스 유형: r6g.4xlarge
- 기본 노드: 3
- 기본 노드 인스턴스 유형: r6g.xlarge
- 색인: HNSW 엔진:
nmslib - 새로 고침 간격: 30초
ef_construction: 256- 남: 16
- 거리 함수: L2
성능 병목 현상을 방지하기 위해 OpenSearch 서비스 클러스터와 RDS 인스턴스 모두에 대규모 구성을 사용했습니다.
우리는 다음을 사용하여 솔루션을 배포합니다. AWS 클라우드 개발 키트 (AWS 씨디케이) 스택, 다음 섹션에 설명된 대로.
AWS CDK 스택 배포
AWS CDK 스택을 사용하면 데이터 수집을 위해 OpenSearch Service 또는 Amazon RDS를 선택할 수 있습니다.
사전 요구 사항
설치를 진행하기 전에 cdk, bin, src.tc에서 Amazon RDS 및 OpenSearch Service의 부울 값을 원하는 대로 true 또는 false로 변경합니다.
서비스와 연계된 서비스도 필요합니다. AWS 자격 증명 및 액세스 관리 (IAM) OpenSearch 서비스 도메인에 대한 역할입니다. 자세한 내용은 다음을 참조하세요. Amazon OpenSearch 서비스 구성 라이브러리. 다음 명령을 실행하여 역할을 생성할 수도 있습니다.
이 AWS CDK 스택은 다음 인프라를 배포합니다.
- VPC
- 점프 호스트(VPC 내부)
- OpenSearch 서비스 클러스터(수집을 위해 OpenSearch 서비스를 사용하는 경우)
- RDS 인스턴스(수집을 위해 Amazon RDS를 사용하는 경우)
- An AWS 시스템 관리자 Ray 클러스터 배포 문서
- An 아마존 단순 스토리지 서비스 (Amazon S3) 버킷
- An AWS 접착제 OSCAR 데이터세트 JSONL 파일을 Parquet 파일로 변환하는 작업
- 아마존 클라우드 워치 대시 보드
데이터 다운로드
점프 호스트에서 다음 명령을 실행합니다.
git 저장소를 복제하기 전에 Hugging Face 프로필이 있고 OSCAR 데이터 코퍼스에 액세스할 수 있는지 확인하세요. OSCAR 데이터를 복제하려면 사용자 이름과 암호를 사용해야 합니다.
JSONL 파일을 Parquet로 변환
AWS CDK 스택이 AWS Glue ETL 작업을 생성했습니다. oscar-jsonl-parquet OSCAR 데이터를 JSONL에서 Parquet 형식으로 변환합니다.
실행 후 oscar-jsonl-parquet 작업을 수행하려면 Parquet 형식의 파일을 S3 버킷의 parquet 폴더에서 사용할 수 있어야 합니다.
질문 다운로드
점프 호스트에서 질문 데이터를 다운로드하여 S3 버킷에 업로드합니다.
Ray 클러스터 설정
AWS CDK 스택 배포의 일부로 우리는 다음과 같은 Systems Manager 문서를 생성했습니다. CreateRayCluster.
문서를 실행하려면 다음 단계를 완료하세요.
- Systems Manager 콘솔의 아래 서류 탐색 창에서 내가 소유함.
- 열기
CreateRayCluster문서를 참조하시기 바랍니다. - 왼쪽 메뉴에서 달리기.
실행 명령 페이지에는 클러스터에 대해 채워진 기본값이 있습니다.
기본 구성은 5개의 g4dn.12xlarge를 요청합니다. 귀하의 계정에 이를 지원하는 한도가 있는지 확인하세요. 관련 서비스 제한은 온디맨드 G 및 VT 인스턴스 실행입니다. 기본값은 64이지만 이 구성에는 240개의 CPU가 필요합니다.
- 클러스터 구성을 검토한 후 실행 명령의 대상으로 점프 호스트를 선택합니다.
이 명령은 다음 단계를 수행합니다.
- Ray 클러스터 파일 복사
- Ray 클러스터 설정
- OpenSearch 서비스 색인 설정
- RDS 테이블 설정
Systems Manager 콘솔에서 명령 출력을 모니터링할 수 있습니다. 이 프로세스는 초기 실행 시 10~15분 정도 소요됩니다.
수집 실행
점프 호스트에서 Ray 클러스터에 연결합니다.
호스트에 처음 연결할 때 요구 사항을 설치합니다. 이러한 파일은 이미 헤드 노드에 있어야 합니다.
수집 방법 중 하나에서 다음과 같은 오류가 발생하면 만료된 자격 증명과 관련된 것입니다. 현재 해결 방법(이 글을 쓰는 시점)은 자격 증명 파일을 Ray 헤드 노드에 배치하는 것입니다. 보안 위험을 방지하려면 특수 목적 소프트웨어를 개발하거나 실제 데이터로 작업할 때 인증에 IAM 사용자를 사용하지 마십시오. 대신 다음과 같은 ID 공급자와의 페더레이션을 사용하세요. AWS IAM Identity Center(AWS Single Sign-On의 후속 제품).
일반적으로 자격 증명은 파일에 저장됩니다. ~/.aws/credentials Linux 및 macOS 시스템에서 %USERPROFILE%.awscredentials Windows에서는 세션 토큰이 있는 단기 자격 증명입니다. 또한 기본 자격 증명 파일을 재정의할 수 없으므로 새 IAM 사용자를 사용하여 세션 토큰 없이 장기 자격 증명을 생성해야 합니다.
장기 자격 증명을 생성하려면 AWS 액세스 키와 AWS 보안 액세스 키를 생성해야 합니다. IAM 콘솔에서 이를 수행할 수 있습니다. 지침은 다음을 참조하세요. IAM 사용자 자격 증명으로 인증.
키를 생성한 후 다음을 사용하여 점프 호스트에 연결합니다. 세션 관리자, Systems Manager의 기능을 사용하고 다음 명령을 실행합니다.
이제 수집 단계를 다시 실행할 수 있습니다.
OpenSearch 서비스에 데이터 수집
OpenSearch 서비스를 사용하는 경우 다음 스크립트를 실행하여 파일을 수집합니다.
완료되면 시뮬레이션된 쿼리를 실행하는 스크립트를 실행합니다.
Amazon RDS로 데이터 수집
Amazon RDS를 사용하는 경우 다음 스크립트를 실행하여 파일을 수집합니다.
완료되면 RDS 인스턴스에서 전체 진공을 실행해야 합니다.
그런 다음 다음 스크립트를 실행하여 시뮬레이션된 쿼리를 실행합니다.
Ray 대시보드 설정
Ray 대시보드를 설정하기 전에 다음을 설치해야 합니다. AWS 명령 줄 인터페이스 (AWS CLI)를 로컬 머신에 설치하세요. 지침은 다음을 참조하세요. 최신 버전의 AWS CLI 설치 또는 업데이트.
대시보드를 설정하려면 다음 단계를 완료하세요.
- 설치 세션 관리자 플러그인 AWS CLI의 경우.
- Isengard 계정에서 bash/zsh에 대한 임시 자격 증명을 복사하고 로컬 터미널에서 실행합니다.
- 컴퓨터에 session.sh 파일을 만들고 다음 콘텐츠를 파일에 복사합니다.
- 이 session.sh 파일이 저장된 위치로 디렉터리를 변경합니다.
- 명령을 실행하십시오.
Chmod +x파일에 실행 권한을 부여합니다. - 다음 명령을 실행하십시오.
예 :
다음과 같은 메시지가 표시됩니다.
브라우저에서 새 탭을 열고 localhost:8265를 입력합니다.
Ray 대시보드와 실행 중인 작업 및 클러스터의 통계가 표시됩니다. 여기에서 측정항목을 추적할 수 있습니다.
예를 들어 Ray 대시보드를 사용하여 클러스터의 로드를 관찰할 수 있습니다. 다음 스크린샷에 표시된 것처럼 수집 중에 GPU는 거의 100% 활용률로 실행됩니다.
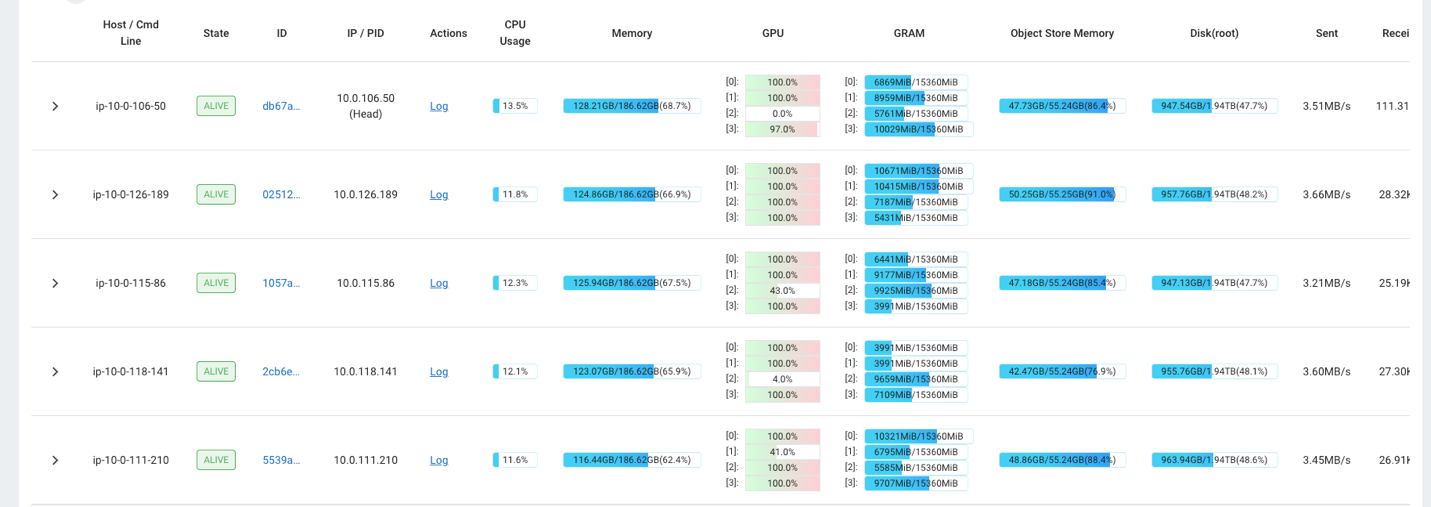
당신은 또한 사용할 수 있습니다 RAG_Benchmarks CloudWatch 대시보드를 통해 수집 속도와 쿼리 응답 시간을 확인할 수 있습니다.
솔루션 확장성
이 솔루션을 확장하여 다른 AWS 또는 타사 벡터 스토어에 연결할 수 있습니다. 모든 새로운 벡터 저장소에 대해 데이터 저장소를 구성하고 데이터를 수집하기 위한 스크립트를 생성해야 합니다. 파이프라인의 나머지 부분은 필요에 따라 재사용할 수 있습니다.
결론
이 게시물에서는 벡터화된 RAG 데이터를 OpenSearch Service와 Amazon RDS에 벡터 데이터 저장소로 pgVector 확장을 사용하여 저장하는 데 사용할 수 있는 ETL 파이프라인을 공유했습니다. 이 솔루션은 Ray 클러스터를 사용하여 대규모 데이터 코퍼스를 수집하는 데 필요한 병렬성을 제공했습니다. 이 방법론을 사용하여 선택한 벡터 데이터베이스를 통합하여 RAG 파이프라인을 구축할 수 있습니다.
저자에 관하여
 랜디 드포 AWS의 수석 수석 솔루션 아키텍트입니다. 그는 미시간 대학교에서 MSEE를 취득했으며 자율주행차용 컴퓨터 비전 분야에서 일했습니다. 그는 또한 콜로라도 주립대학교에서 MBA를 취득했습니다. Randy는 소프트웨어 엔지니어링에서 제품 관리에 이르기까지 기술 분야에서 다양한 직책을 맡았습니다. 그는 2013년부터 빅데이터 분야에 입문해 계속해서 그 분야를 탐구하고 있다. 그는 ML 공간의 프로젝트에 적극적으로 참여하고 있으며 Strata 및 GlueCon을 포함한 수많은 컨퍼런스에서 발표했습니다.
랜디 드포 AWS의 수석 수석 솔루션 아키텍트입니다. 그는 미시간 대학교에서 MSEE를 취득했으며 자율주행차용 컴퓨터 비전 분야에서 일했습니다. 그는 또한 콜로라도 주립대학교에서 MBA를 취득했습니다. Randy는 소프트웨어 엔지니어링에서 제품 관리에 이르기까지 기술 분야에서 다양한 직책을 맡았습니다. 그는 2013년부터 빅데이터 분야에 입문해 계속해서 그 분야를 탐구하고 있다. 그는 ML 공간의 프로젝트에 적극적으로 참여하고 있으며 Strata 및 GlueCon을 포함한 수많은 컨퍼런스에서 발표했습니다.
 데이비드 기독교 남부 캘리포니아에 본사를 둔 수석 솔루션 설계자입니다. 그는 정보 보안 학사 학위를 보유하고 있으며 자동화에 대한 열정을 가지고 있습니다. 그의 중점 분야는 DevOps 문화 및 혁신, 코드형 인프라, 탄력성입니다. AWS에 합류하기 전에는 보안, DevOps 및 시스템 엔지니어링 분야에서 대규모 프라이빗 및 퍼블릭 클라우드 환경을 관리하는 역할을 맡았습니다.
데이비드 기독교 남부 캘리포니아에 본사를 둔 수석 솔루션 설계자입니다. 그는 정보 보안 학사 학위를 보유하고 있으며 자동화에 대한 열정을 가지고 있습니다. 그의 중점 분야는 DevOps 문화 및 혁신, 코드형 인프라, 탄력성입니다. AWS에 합류하기 전에는 보안, DevOps 및 시스템 엔지니어링 분야에서 대규모 프라이빗 및 퍼블릭 클라우드 환경을 관리하는 역할을 맡았습니다.
 프라치 쿨카르니 AWS의 수석 솔루션 아키텍트입니다. 그녀의 전문 분야는 기계 학습이며 다양한 AWS ML, 빅 데이터 및 분석 제품을 사용하여 솔루션을 설계하는 데 적극적으로 노력하고 있습니다. Prachi는 의료, 복리후생, 소매, 교육을 포함한 다양한 영역에서 경험을 갖고 있으며 제품 엔지니어링 및 아키텍처, 관리, 고객 성공 분야에서 다양한 직책을 맡았습니다.
프라치 쿨카르니 AWS의 수석 솔루션 아키텍트입니다. 그녀의 전문 분야는 기계 학습이며 다양한 AWS ML, 빅 데이터 및 분석 제품을 사용하여 솔루션을 설계하는 데 적극적으로 노력하고 있습니다. Prachi는 의료, 복리후생, 소매, 교육을 포함한 다양한 영역에서 경험을 갖고 있으며 제품 엔지니어링 및 아키텍처, 관리, 고객 성공 분야에서 다양한 직책을 맡았습니다.
 리차 굽타 AWS의 솔루션스 아키텍트입니다. 그녀는 고객을 위한 엔드투엔드 솔루션을 설계하는 데 열정을 갖고 있습니다. 그녀의 전문 분야는 기계 학습과 이를 사용하여 운영 효율성을 높이고 비즈니스 수익을 창출하는 새로운 솔루션을 구축하는 방법입니다. AWS에 합류하기 전에는 소프트웨어 엔지니어 및 솔루션 아키텍트로 일하면서 대규모 통신 사업자를 위한 솔루션을 구축했습니다. 직장 밖에서 그녀는 새로운 장소를 탐험하는 것을 좋아하고 모험적인 활동을 좋아합니다.
리차 굽타 AWS의 솔루션스 아키텍트입니다. 그녀는 고객을 위한 엔드투엔드 솔루션을 설계하는 데 열정을 갖고 있습니다. 그녀의 전문 분야는 기계 학습과 이를 사용하여 운영 효율성을 높이고 비즈니스 수익을 창출하는 새로운 솔루션을 구축하는 방법입니다. AWS에 합류하기 전에는 소프트웨어 엔지니어 및 솔루션 아키텍트로 일하면서 대규모 통신 사업자를 위한 솔루션을 구축했습니다. 직장 밖에서 그녀는 새로운 장소를 탐험하는 것을 좋아하고 모험적인 활동을 좋아합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

