Foundation-Modelle (FMs) sind große Modelle für maschinelles Lernen (ML), die auf einem breiten Spektrum unbeschrifteter und verallgemeinerter Datensätze trainiert werden. FMs bilden, wie der Name schon sagt, die Grundlage für den Aufbau spezialisierterer nachgelagerter Anwendungen und zeichnen sich durch ihre einzigartige Anpassungsfähigkeit aus. Sie können ein breites Spektrum unterschiedlicher Aufgaben ausführen, beispielsweise die Verarbeitung natürlicher Sprache, die Klassifizierung von Bildern, die Vorhersage von Trends, die Stimmungsanalyse und die Beantwortung von Fragen. Diese Skalierung und allgemeine Anpassungsfähigkeit unterscheiden FMs von herkömmlichen ML-Modellen. FMs sind multimodal; Sie arbeiten mit verschiedenen Datentypen wie Text, Video, Audio und Bildern. Große Sprachmodelle (LLMs) sind eine Art FM und werden anhand großer Textdatenmengen vorab trainiert und haben typischerweise Anwendungszwecke wie Textgenerierung, intelligente Chatbots oder Zusammenfassung.
Das Streaming von Daten erleichtert den ständigen Fluss vielfältiger und aktueller Informationen und verbessert die Fähigkeit der Modelle, sich anzupassen und genauere, kontextrelevante Ergebnisse zu generieren. Diese dynamische Integration von Streaming-Daten ermöglicht generative KI Anwendungen können schnell auf sich ändernde Bedingungen reagieren und so ihre Anpassungsfähigkeit und Gesamtleistung bei verschiedenen Aufgaben verbessern.
Um dies besser zu verstehen, stellen Sie sich einen Chatbot vor, der Reisenden bei der Buchung ihrer Reise hilft. In diesem Szenario benötigt der Chatbot Echtzeitzugriff auf den Fluglinienbestand, den Flugstatus, den Hotelbestand, die neuesten Preisänderungen und mehr. Diese Daten stammen in der Regel von Dritten, und Entwickler müssen einen Weg finden, diese Daten aufzunehmen und die Datenänderungen zu verarbeiten, sobald sie auftreten.
Die Stapelverarbeitung ist in diesem Szenario nicht die beste Lösung. Wenn sich Daten schnell ändern, kann die Stapelverarbeitung dazu führen, dass der Chatbot veraltete Daten verwendet und dem Kunden ungenaue Informationen liefert, was sich auf das gesamte Kundenerlebnis auswirkt. Durch die Stream-Verarbeitung kann der Chatbot jedoch auf Echtzeitdaten zugreifen und sich an Änderungen bei Verfügbarkeit und Preis anpassen, um dem Kunden die beste Beratung zu bieten und das Kundenerlebnis zu verbessern.
Ein weiteres Beispiel ist eine KI-gesteuerte Beobachtbarkeits- und Überwachungslösung, bei der FMs interne Kennzahlen eines Systems in Echtzeit überwachen und Warnungen erzeugen. Wenn das Modell eine Anomalie oder einen abnormalen Metrikwert feststellt, sollte es sofort eine Warnung ausgeben und den Bediener benachrichtigen. Allerdings nimmt der Wert solch wichtiger Daten mit der Zeit deutlich ab. Diese Benachrichtigungen sollten idealerweise innerhalb von Sekunden oder sogar während des Geschehens empfangen werden. Wenn Betreiber diese Benachrichtigungen Minuten oder Stunden nach ihrem Vorfall erhalten, ist eine solche Erkenntnis nicht umsetzbar und hat möglicherweise ihren Wert verloren. Ähnliche Anwendungsfälle finden Sie auch in anderen Branchen wie dem Einzelhandel, der Automobilherstellung, der Energiebranche und der Finanzindustrie.
In diesem Beitrag diskutieren wir, warum Datenstreaming aufgrund seines Echtzeitcharakters eine entscheidende Komponente generativer KI-Anwendungen ist. Wir diskutieren den Wert von AWS-Datenstreaming-Diensten wie z Amazon Managed Streaming für Apache Kafka (Amazon MSK), Amazon Kinesis-Datenströme, Amazon Managed Service für Apache Flink und Amazon Kinesis Data Firehose beim Aufbau generativer KI-Anwendungen.
Kontextbezogenes Lernen
LLMs werden mit Point-in-Time-Daten trainiert und verfügen nicht über die inhärente Fähigkeit, zum Inferenzzeitpunkt auf neue Daten zuzugreifen. Wenn neue Daten auftauchen, müssen Sie das Modell kontinuierlich verfeinern oder weiter trainieren. Dies ist nicht nur ein teurer Vorgang, sondern auch in der Praxis sehr einschränkend, da die Geschwindigkeit der Generierung neuer Daten die Geschwindigkeit der Feinabstimmung bei weitem übertrifft. Darüber hinaus mangelt es LLMs an Kontextverständnis, sie verlassen sich ausschließlich auf ihre Trainingsdaten und sind daher anfällig für Halluzinationen. Das bedeutet, dass sie eine flüssige, kohärente und syntaktisch fundierte, aber sachlich falsche Antwort erzeugen können. Außerdem mangelt es ihnen an Relevanz, Personalisierung und Kontext.
LLMs haben jedoch die Fähigkeit, aus den Daten zu lernen, die sie aus dem Kontext erhalten, um genauer zu reagieren, ohne die Modellgewichte zu ändern. Das nennt man kontextbezogenes Lernenund kann verwendet werden, um personalisierte Antworten zu erstellen oder eine genaue Antwort im Kontext von Organisationsrichtlinien bereitzustellen.
In einem Chatbot könnten sich Datenereignisse beispielsweise auf eine Bestandsaufnahme von Flügen und Hotels oder Preisänderungen beziehen, die ständig in eine Streaming-Speicher-Engine aufgenommen werden. Darüber hinaus werden Datenereignisse mithilfe eines Stream-Prozessors gefiltert, angereichert und in ein konsumierbares Format umgewandelt. Das Ergebnis wird der Anwendung durch Abfrage des neuesten Snapshots zur Verfügung gestellt. Der Snapshot wird durch die Stream-Verarbeitung ständig aktualisiert. Daher werden die aktuellen Daten im Kontext einer Benutzeraufforderung an das Modell bereitgestellt. Dadurch kann sich das Modell an die neuesten Preis- und Verfügbarkeitsänderungen anpassen. Das folgende Diagramm veranschaulicht einen grundlegenden Arbeitsablauf für kontextbezogenes Lernen.
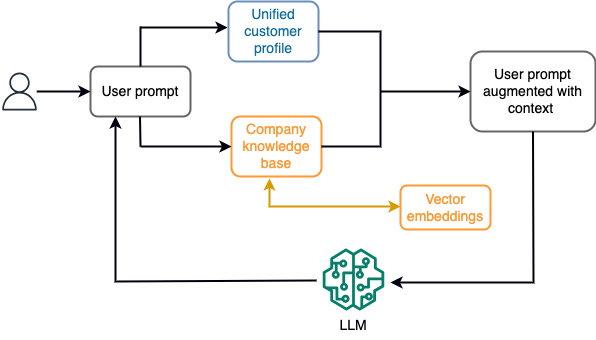
Ein häufig verwendeter Ansatz zum kontextbezogenen Lernen ist die Verwendung einer Technik namens Retrieval Augmented Generation (RAG). In RAG geben Sie die relevanten Informationen, wie z. B. die relevantesten Richtlinien- und Kundendatensätze, zusammen mit der Benutzerfrage an die Eingabeaufforderung an. Auf diese Weise generiert das LLM eine Antwort auf die Benutzerfrage unter Verwendung zusätzlicher Informationen, die als Kontext bereitgestellt werden. Weitere Informationen zu RAG finden Sie unter Beantwortung von Fragen mit Retrieval Augmented Generation mit Basismodellen in Amazon SageMaker JumpStart.
Eine RAG-basierte generative KI-Anwendung kann nur generische Antworten auf der Grundlage ihrer Trainingsdaten und der relevanten Dokumente in der Wissensdatenbank erzeugen. Diese Lösung greift nicht, wenn von der Anwendung eine personalisierte Antwort nahezu in Echtzeit erwartet wird. Von einem Reise-Chatbot wird beispielsweise erwartet, dass er die aktuellen Buchungen des Benutzers, das verfügbare Hotel- und Fluginventar und mehr berücksichtigt. Darüber hinaus werden die relevanten personenbezogenen Daten des Kunden (allgemein bekannt als einheitliches Kundenprofil) kann sich in der Regel ändern. Wenn ein Batch-Prozess verwendet wird, um die Benutzerprofildatenbank der generativen KI zu aktualisieren, erhält der Kunde möglicherweise unbefriedigende Antworten basierend auf alten Daten.
In diesem Beitrag besprechen wir die Anwendung der Stream-Verarbeitung zur Verbesserung einer RAG-Lösung, die zum Aufbau von Fragebeantworter-Agenten mit Kontext vom Echtzeitzugriff bis hin zu einheitlichen Kundenprofilen und einer organisatorischen Wissensdatenbank verwendet wird.
Aktualisierungen des Kundenprofils nahezu in Echtzeit
Kundendatensätze werden in der Regel über Datenspeicher innerhalb einer Organisation verteilt. Damit Ihre generative KI-Anwendung ein relevantes, genaues und aktuelles Kundenprofil bereitstellen kann, ist es wichtig, Streaming-Datenpipelines aufzubauen, die eine Identitätsauflösung und Profilaggregation über die verteilten Datenspeicher hinweg durchführen können. Streaming-Jobs erfassen ständig neue Daten zur systemübergreifenden Synchronisierung und können Anreicherungen, Transformationen, Verknüpfungen und Aggregationen über Zeitfenster hinweg effizienter durchführen. Change Data Capture (CDC)-Ereignisse enthalten Informationen über den Quelldatensatz, Aktualisierungen und Metadaten wie Zeit, Quelle, Klassifizierung (Einfügen, Aktualisieren oder Löschen) und den Initiator der Änderung.
Das folgende Diagramm veranschaulicht einen Beispielworkflow für die CDC-Streaming-Aufnahme und -Verarbeitung für einheitliche Kundenprofile.

In diesem Abschnitt diskutieren wir die Hauptkomponenten eines CDC-Streaming-Musters, das zur Unterstützung von RAG-basierten generativen KI-Anwendungen erforderlich ist.
CDC-Streaming-Aufnahme
Ein CDC-Replikator ist ein Prozess, der Datenänderungen von einem Quellsystem sammelt (normalerweise durch Lesen von Transaktionsprotokollen oder Binlogs) und CDC-Ereignisse in genau derselben Reihenfolge schreibt, in der sie in einem Streaming-Datenstrom oder -Thema aufgetreten sind. Dabei handelt es sich um eine protokollbasierte Erfassung mit Tools wie z.B AWS-Datenbankmigrationsservice (AWS DMS) oder Open-Source-Konnektoren wie Debezium für Apache Kafka Connect. Apache Kafka Connect ist Teil der Apache Kafka-Umgebung und ermöglicht die Erfassung von Daten aus verschiedenen Quellen und die Bereitstellung an verschiedene Ziele. Sie können Ihren Apache Kafka-Connector darauf ausführen Amazon MSK Connect innerhalb von Minuten, ohne sich Gedanken über die Konfiguration, Einrichtung und den Betrieb eines Apache Kafka-Clusters machen zu müssen. Sie müssen lediglich den kompilierten Code Ihres Connectors hochladen Amazon Simple Storage-Service (Amazon S3) und richten Sie Ihren Connector mit der spezifischen Konfiguration Ihrer Arbeitslast ein.
Es gibt auch andere Methoden zur Erfassung von Datenänderungen. Zum Beispiel, Amazon DynamoDB bietet eine Funktion zum Streamen von CDC-Daten Amazon DynamoDB-Streams oder Kinesis Data Streams. Amazon S3 bietet einen Auslöser zum Aufrufen eines AWS Lambda Funktion beim Speichern eines neuen Dokuments.
Streaming-Speicher
Streaming-Speicher fungiert als Zwischenpuffer zum Speichern von CDC-Ereignissen, bevor sie verarbeitet werden. Streaming-Speicher bietet zuverlässigen Speicher für Streaming-Daten. Aufgrund seines Designs ist es hochverfügbar und widerstandsfähig gegenüber Hardware- oder Knotenausfällen und behält die Reihenfolge der Ereignisse beim Schreiben bei. Streaming-Speicher können Datenereignisse entweder dauerhaft oder für einen festgelegten Zeitraum speichern. Dadurch können Stream-Prozessoren einen Teil des Streams lesen, wenn ein Fehler auftritt oder eine erneute Verarbeitung erforderlich ist. Kinesis Data Streams ist ein serverloser Streaming-Datendienst, der die einfache Erfassung, Verarbeitung und Speicherung von Datenströmen in großem Maßstab ermöglicht. Amazon MSK ist ein vollständig verwalteter, hochverfügbarer und sicherer Dienst, der von AWS für die Ausführung von Apache Kafka bereitgestellt wird.
Stream-Verarbeitung
Stream-Verarbeitungssysteme sollten auf Parallelität ausgelegt sein, um einen hohen Datendurchsatz zu bewältigen. Sie sollten den Eingabestrom auf mehrere Aufgaben aufteilen, die auf mehreren Rechenknoten ausgeführt werden. Aufgaben sollten in der Lage sein, das Ergebnis einer Operation über das Netzwerk an die nächste zu senden, sodass Daten parallel verarbeitet werden können, während Vorgänge wie Verknüpfungen, Filterung, Anreicherung und Aggregationen ausgeführt werden. Stream-Verarbeitungsanwendungen sollten in der Lage sein, Ereignisse im Hinblick auf die Ereigniszeit für Anwendungsfälle zu verarbeiten, in denen Ereignisse verspätet eintreffen könnten oder die korrekte Berechnung auf der Zeit, zu der Ereignisse auftreten, und nicht auf der Systemzeit beruht. Weitere Informationen finden Sie unter Zeitvorstellungen: Ereigniszeit und Verarbeitungszeit.
Stream-Prozesse erzeugen kontinuierlich Ergebnisse in Form von Datenereignissen, die an ein Zielsystem ausgegeben werden müssen. Ein Zielsystem könnte jedes System sein, das direkt in den Prozess oder über Streaming-Speicher als Vermittler integriert werden kann. Je nachdem, welches Framework Sie für die Stream-Verarbeitung wählen, stehen Ihnen je nach verfügbaren Sink-Anschlüssen unterschiedliche Optionen für Zielsysteme zur Verfügung. Wenn Sie sich entscheiden, die Ergebnisse in einen zwischengeschalteten Streaming-Speicher zu schreiben, können Sie einen separaten Prozess erstellen, der Ereignisse liest und Änderungen auf das Zielsystem anwendet, z. B. die Ausführung eines Apache Kafka-Sink-Connectors. Unabhängig davon, für welche Option Sie sich entscheiden, erfordern CDC-Daten aufgrund ihrer Beschaffenheit eine zusätzliche Bearbeitung. Da CDC-Ereignisse Informationen über Aktualisierungen oder Löschungen enthalten, ist es wichtig, dass sie im Zielsystem in der richtigen Reihenfolge zusammengeführt werden. Wenn Änderungen in der falschen Reihenfolge angewendet werden, ist das Zielsystem nicht mehr mit seiner Quelle synchronisiert.
Apache Flink ist ein leistungsstarkes Stream-Verarbeitungs-Framework, das für seine geringen Latenz- und hohen Durchsatzfähigkeiten bekannt ist. Es unterstützt Ereigniszeitverarbeitung, Exact-Once-Processing-Semantik und hohe Fehlertoleranz. Darüber hinaus bietet es native Unterstützung für CDC-Daten über eine spezielle Struktur namens dynamische Tabellen. Dynamische Tabellen ahmen die Tabellen der Quelldatenbank nach und bieten eine spaltenweise Darstellung der Streaming-Daten. Die Daten in dynamischen Tabellen ändern sich mit jedem verarbeiteten Ereignis. Neue Datensätze können jederzeit angehängt, aktualisiert oder gelöscht werden. Dynamische Tabellen abstrahieren die zusätzliche Logik, die Sie für jeden Datensatzvorgang (Einfügen, Aktualisieren, Löschen) separat implementieren müssen. Weitere Informationen finden Sie unter Dynamische Tabellen.
Mit der Amazon Managed Service für Apache Flinkkönnen Sie Apache Flink-Jobs ausführen und in andere AWS-Dienste integrieren. Es müssen keine Server und Cluster verwaltet und keine Rechen- und Speicherinfrastruktur eingerichtet werden.
AWS-Kleber ist ein vollständig verwalteter Extraktions-, Transformations- und Ladedienst (ETL), was bedeutet, dass AWS die Bereitstellung, Skalierung und Wartung der Infrastruktur für Sie übernimmt. Obwohl AWS Glue vor allem für seine ETL-Funktionen bekannt ist, kann es auch für Spark-Streaming-Anwendungen verwendet werden. AWS Glue kann mit Streaming-Datendiensten wie Kinesis Data Streams und Amazon MSK interagieren, um CDC-Daten zu verarbeiten und umzuwandeln. AWS Glue kann auch nahtlos in andere AWS-Dienste wie Lambda integriert werden. AWS Step-Funktionenund DynamoDB bieten Ihnen ein umfassendes Ökosystem für den Aufbau und die Verwaltung von Datenverarbeitungspipelines.
Einheitliches Kundenprofil
Um die Vereinheitlichung des Kundenprofils über eine Vielzahl von Quellsystemen hinweg zu überwinden, ist die Entwicklung robuster Datenpipelines erforderlich. Sie benötigen Datenpipelines, die alle Datensätze in einem Datenspeicher zusammenführen und synchronisieren können. Dieser Datenspeicher bietet Ihrem Unternehmen die ganzheitliche Kundendatenansicht, die für die betriebliche Effizienz RAG-basierter generativer KI-Anwendungen erforderlich ist. Für den Aufbau eines solchen Datenspeichers wäre ein unstrukturierter Datenspeicher am besten geeignet.
Ein Identitätsdiagramm ist eine nützliche Struktur für die Erstellung eines einheitlichen Kundenprofils, da es Kundendaten aus verschiedenen Quellen konsolidiert und integriert, Datengenauigkeit und Deduplizierung gewährleistet, Aktualisierungen in Echtzeit bietet, systemübergreifende Erkenntnisse verbindet, Personalisierung ermöglicht, das Kundenerlebnis verbessert usw unterstützt die Einhaltung gesetzlicher Vorschriften. Dieses einheitliche Kundenprofil ermöglicht es der generativen KI-Anwendung, Kunden effektiv zu verstehen und mit ihnen in Kontakt zu treten sowie Datenschutzbestimmungen einzuhalten, was letztendlich das Kundenerlebnis verbessert und das Geschäftswachstum vorantreibt. Sie können Ihre Identitätsdiagrammlösung mit erstellen Amazon Neptun, ein schneller, zuverlässiger und vollständig verwalteter Graphdatenbankdienst.
AWS bietet einige andere verwaltete und serverlose NoSQL-Speicherdienstangebote für unstrukturierte Schlüsselwertobjekte. Amazon DocumentDB (mit MongoDB-Kompatibilität) ist ein schnelles, skalierbares, hochverfügbares und vollständig verwaltetes Unternehmen Dokumentendatenbank Dienst, der native JSON-Workloads unterstützt. DynamoDB ist ein vollständig verwalteter NoSQL-Datenbankdienst, der schnelle und vorhersehbare Leistung mit nahtloser Skalierbarkeit bietet.
Aktualisierungen der organisatorischen Wissensdatenbank nahezu in Echtzeit
Ähnlich wie Kundendatensätze werden interne Wissensspeicher wie Unternehmensrichtlinien und Organisationsdokumente in verschiedenen Speichersystemen isoliert. Hierbei handelt es sich in der Regel um unstrukturierte Daten, die nicht inkrementell aktualisiert werden. Die Verwendung unstrukturierter Daten für KI-Anwendungen ist durch Vektoreinbettungen effektiv, eine Technik zur Darstellung hochdimensionaler Daten wie Textdateien, Bilder und Audiodateien als mehrdimensionale Zahlen.
AWS bietet mehrere Vektor-Engine-Dienste, sowie Amazon OpenSearch ohne Server, Amazon Kendra und Amazon Aurora PostgreSQL-kompatible Edition mit der pgvector-Erweiterung zum Speichern von Vektoreinbettungen. Generative KI-Anwendungen können das Benutzererlebnis verbessern, indem sie die Benutzeraufforderung in einen Vektor umwandeln und diesen zur Abfrage der Vektor-Engine verwenden, um kontextrelevante Informationen abzurufen. Sowohl die Eingabeaufforderung als auch die abgerufenen Vektordaten werden dann an das LLM weitergeleitet, um eine präzisere und personalisiertere Antwort zu erhalten.
Das folgende Diagramm veranschaulicht einen beispielhaften Stream-Verarbeitungsworkflow für Vektoreinbettungen.
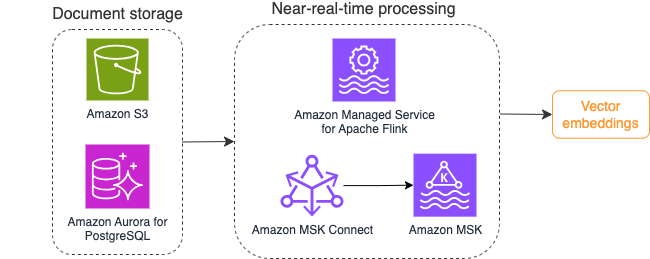
Inhalte der Wissensdatenbank müssen in Vektoreinbettungen konvertiert werden, bevor sie in den Vektordatenspeicher geschrieben werden. Amazonas Grundgestein or Amazon Sage Maker kann Ihnen dabei helfen, auf das Modell Ihrer Wahl zuzugreifen und einen privaten Endpunkt für diese Konvertierung bereitzustellen. Darüber hinaus können Sie Bibliotheken wie LangChain zur Integration in diese Endpunkte verwenden. Der Aufbau eines Batch-Prozesses kann Ihnen dabei helfen, den Inhalt Ihrer Wissensdatenbank in Vektordaten umzuwandeln und diese zunächst in einer Vektordatenbank zu speichern. Sie müssen sich jedoch auf ein Intervall für die erneute Verarbeitung der Dokumente verlassen, um Ihre Vektordatenbank mit Änderungen im Inhalt Ihrer Wissensdatenbank zu synchronisieren. Bei einer großen Anzahl von Dokumenten kann dieser Prozess ineffizient sein. Zwischen diesen Intervallen erhalten Ihre generativen KI-Anwendungsbenutzer Antworten entsprechend dem alten Inhalt oder eine ungenaue Antwort, da der neue Inhalt noch nicht vektorisiert ist.
Stream Processing ist eine ideale Lösung für diese Herausforderungen. Es erzeugt zunächst Ereignisse gemäß den vorhandenen Dokumenten, überwacht das Quellsystem weiter und erstellt ein Dokumentänderungsereignis, sobald diese auftreten. Diese Ereignisse können im Streaming-Speicher gespeichert werden und auf die Verarbeitung durch einen Streaming-Job warten. Ein Streaming-Job liest diese Ereignisse, lädt den Inhalt des Dokuments und wandelt den Inhalt in ein Array verwandter Wort-Tokens um. Jedes Token wird über einen API-Aufruf an ein einbettendes FM weiter in Vektordaten umgewandelt. Die Ergebnisse werden über einen Senkenoperator zur Speicherung an den Vektorspeicher gesendet.
Wenn Sie Amazon S3 zum Speichern Ihrer Dokumente verwenden, können Sie eine Ereignisquellenarchitektur basierend auf S3-Objektänderungsauslösern für Lambda erstellen. Eine Lambda-Funktion kann ein Ereignis im gewünschten Format erstellen und dieses in Ihren Streaming-Speicher schreiben.
Sie können Apache Flink auch zur Ausführung als Streaming-Job verwenden. Apache Flink stellt den nativen FileSystem-Quellkonnektor bereit, der vorhandene Dateien erkennen und deren Inhalte zunächst lesen kann. Danach kann es Ihr Dateisystem kontinuierlich auf neue Dateien überwachen und deren Inhalt erfassen. Der Connector unterstützt das Lesen einer Reihe von Dateien aus verteilten Dateisystemen wie Amazon S3 oder HDFS in den Formaten Nur-Text, Avro, CSV, Parquet und mehr und erstellt einen Streaming-Datensatz. Als vollständig verwalteter Dienst entfällt mit Managed Service for Apache Flink der Betriebsaufwand für die Bereitstellung und Wartung von Flink-Jobs, sodass Sie sich auf die Erstellung und Skalierung Ihrer Streaming-Anwendungen konzentrieren können. Durch die nahtlose Integration in die AWS-Streaming-Dienste wie Amazon MSK oder Kinesis Data Streams bietet es Funktionen wie automatische Skalierung, Sicherheit und Ausfallsicherheit und stellt zuverlässige und effiziente Flink-Anwendungen für die Verarbeitung von Echtzeit-Streaming-Daten bereit.
Basierend auf Ihrer DevOps-Präferenz können Sie zwischen Kinesis Data Streams oder Amazon MSK zum Speichern der Streaming-Datensätze wählen. Kinesis Data Streams vereinfacht die Komplexität der Erstellung und Verwaltung benutzerdefinierter Streaming-Datenanwendungen, sodass Sie sich auf die Gewinnung von Erkenntnissen aus Ihren Daten statt auf die Wartung der Infrastruktur konzentrieren können. Kunden, die Apache Kafka verwenden, entscheiden sich häufig für Amazon MSK aufgrund seiner Unkompliziertheit, Skalierbarkeit und Zuverlässigkeit bei der Überwachung von Apache Kafka-Clustern innerhalb der AWS-Umgebung. Als vollständig verwalteter Dienst übernimmt Amazon MSK die betriebliche Komplexität, die mit der Bereitstellung und Wartung von Apache Kafka-Clustern verbunden ist, sodass Sie sich auf den Aufbau und die Erweiterung Ihrer Streaming-Anwendungen konzentrieren können.
Da eine RESTful-API-Integration der Natur dieses Prozesses entspricht, benötigen Sie ein Framework, das ein zustandsbehaftetes Anreicherungsmuster über RESTful-API-Aufrufe unterstützt, um Fehler zu verfolgen und die fehlgeschlagene Anforderung erneut zu versuchen. Apache Flink ist wiederum ein Framework, das zustandsbehaftete Vorgänge mit Speichergeschwindigkeit ausführen kann. Informationen zu den besten Möglichkeiten zum Durchführen von API-Aufrufen über Apache Flink finden Sie unter Gängige Streaming-Datenanreicherungsmuster in Amazon Kinesis Data Analytics für Apache Flink.
Apache Flink bietet native Sink-Konnektoren zum Schreiben von Daten in Vektordatenspeicher wie Amazon Aurora für PostgreSQL mit pgvector oder Amazon OpenSearch-Dienst mit VectorDB. Alternativ können Sie die Ausgabe des Flink-Jobs (vektorisierte Daten) in einem MSK-Thema oder einem Kinesis-Datenstrom bereitstellen. OpenSearch Service bietet Unterstützung für die native Aufnahme von Kinesis-Datenströmen oder MSK-Themen. Weitere Informationen finden Sie unter Einführung von Amazon MSK als Quelle für die Amazon OpenSearch-Aufnahme und Laden von Streaming-Daten aus Amazon Kinesis Data Streams.
Feedback-Analyse und Feinabstimmung
Für Datenbetriebsmanager und KI/ML-Entwickler ist es wichtig, Einblicke in die Leistung der generativen KI-Anwendung und der verwendeten FMs zu erhalten. Um dies zu erreichen, müssen Sie Datenpipelines aufbauen, die wichtige KPI-Daten (Key Performance Indicator) basierend auf dem Benutzerfeedback und einer Vielzahl von Anwendungsprotokollen und -metriken berechnen. Diese Informationen sind für Stakeholder nützlich, um in Echtzeit Einblicke in die Leistung des FM, der Anwendung und die allgemeine Zufriedenheit der Benutzer mit der Qualität des Supports zu erhalten, den sie von Ihrer Anwendung erhalten. Sie müssen außerdem den Konversationsverlauf sammeln und speichern, um Ihre FMs weiter zu optimieren und ihre Fähigkeit zur Ausführung domänenspezifischer Aufgaben zu verbessern.
Dieser Anwendungsfall passt sehr gut in den Bereich Streaming Analytics. Ihre Anwendung sollte jede Konversation im Streaming-Speicher speichern. Ihre Anwendung kann Benutzer nach ihrer Bewertung der Genauigkeit jeder Antwort und ihrer Gesamtzufriedenheit fragen. Diese Daten können im Format einer binären Auswahl oder eines Freiformtextes vorliegen. Diese Daten können in einem Kinesis-Datenstrom oder MSK-Thema gespeichert und verarbeitet werden, um KPIs in Echtzeit zu generieren. Sie können FMs für die Stimmungsanalyse der Benutzer einsetzen. FMs können jede Antwort analysieren und eine Kategorie der Benutzerzufriedenheit zuweisen.
Die Architektur von Apache Flink ermöglicht eine komplexe Datenaggregation über Zeitfenster hinweg. Es bietet auch Unterstützung für SQL-Abfragen über den Strom von Datenereignissen. Daher können Sie mit Apache Flink rohe Benutzereingaben schnell analysieren und KPIs in Echtzeit generieren, indem Sie vertraute SQL-Abfragen schreiben. Weitere Informationen finden Sie unter Tabellen-API und SQL.
Mit der Amazon Managed Service für Apache Flink Studiokönnen Sie Apache Flink-Stream-Verarbeitungsanwendungen mit Standard-SQL, Python und Scala in einem interaktiven Notebook erstellen und ausführen. Studio-Notebooks basieren auf Apache Zeppelin und nutzen Apache Flink als Stream-Verarbeitungs-Engine. Studio-Notebooks kombinieren diese Technologien nahtlos, um Entwicklern aller Qualifikationsniveaus erweiterte Analysen von Datenströmen zugänglich zu machen. Durch die Unterstützung benutzerdefinierter Funktionen (UDFs) ermöglicht Apache Flink die Erstellung benutzerdefinierter Operatoren zur Integration mit externen Ressourcen wie FMs zur Durchführung komplexer Aufgaben wie Stimmungsanalysen. Sie können UDFs verwenden, um verschiedene Metriken zu berechnen oder Rohdaten des Benutzerfeedbacks mit zusätzlichen Erkenntnissen wie der Benutzerstimmung anzureichern. Weitere Informationen zu diesem Muster finden Sie unter Proaktive Bearbeitung von Kundenanliegen in Echtzeit mit GenAI, Flink, Apache Kafka und Kinesis.
Mit Managed Service für Apache Flink Studio können Sie Ihr Studio-Notebook mit einem Klick als Streaming-Job bereitstellen. Sie können die von Apache Flink bereitgestellten nativen Sink-Konnektoren verwenden, um die Ausgabe an den Speicher Ihrer Wahl zu senden oder sie in einem Kinesis-Datenstrom oder MSK-Thema bereitzustellen. Amazon RedShift und OpenSearch Service sind beide ideal für die Speicherung analytischer Daten. Beide Engines bieten native Aufnahmeunterstützung von Kinesis Data Streams und Amazon MSK über eine separate Streaming-Pipeline zu einem Data Lake oder Data Warehouse zur Analyse.
Amazon Redshift verwendet SQL, um strukturierte und halbstrukturierte Daten in Data Warehouses und Data Lakes zu analysieren und nutzt dabei von AWS entwickelte Hardware und maschinelles Lernen, um das beste Preis-Leistungs-Verhältnis im großen Maßstab zu liefern. OpenSearch Service bietet Visualisierungsfunktionen, die auf OpenSearch Dashboards und Kibana (Versionen 1.5 bis 7.10) basieren.
Sie können das Ergebnis einer solchen Analyse in Kombination mit den Eingabeaufforderungsdaten des Benutzers verwenden, um bei Bedarf eine Feinabstimmung des FM vorzunehmen. SageMaker ist der einfachste Weg zur Feinabstimmung Ihrer FMs. Die Verwendung von Amazon S3 mit SageMaker bietet eine leistungsstarke und nahtlose Integration zur Feinabstimmung Ihrer Modelle. Amazon S3 dient als skalierbare und langlebige Objektspeicherlösung und ermöglicht die unkomplizierte Speicherung und den Abruf großer Datensätze, Trainingsdaten und Modellartefakte. SageMaker ist ein vollständig verwalteter ML-Dienst, der den gesamten ML-Lebenszyklus vereinfacht. Durch die Verwendung von Amazon S3 als Speicher-Backend für SageMaker können Sie von der Skalierbarkeit, Zuverlässigkeit und Kosteneffizienz von Amazon S3 profitieren und es gleichzeitig nahtlos in die Schulungs- und Bereitstellungsfunktionen von SageMaker integrieren. Diese Kombination ermöglicht ein effizientes Datenmanagement, erleichtert die kollaborative Modellentwicklung und stellt sicher, dass ML-Workflows rationalisiert und skalierbar sind, was letztendlich die allgemeine Agilität und Leistung des ML-Prozesses verbessert. Weitere Informationen finden Sie unter Optimieren Sie Falcon 7B und andere LLMs auf Amazon SageMaker mit @remote decorator.
Mit einem Dateisystem-Sink-Connector können Apache Flink-Jobs Daten in offenen Formatdateien (z. B. JSON, Avro, Parquet usw.) als Datenobjekte an Amazon S3 liefern. Wenn Sie Ihren Data Lake lieber mit einem transaktionalen Data Lake-Framework (wie Apache Hudi, Apache Iceberg oder Delta Lake) verwalten möchten, bieten alle diese Frameworks einen benutzerdefinierten Connector für Apache Flink. Weitere Einzelheiten finden Sie unter Erstellen Sie mit Amazon MSK Connect, Apache Flink und Apache Hudi eine Source-to-Data-Lake-Pipeline mit niedriger Latenz.
Zusammenfassung
Für eine generative KI-Anwendung, die auf einem RAG-Modell basiert, müssen Sie den Aufbau von zwei Datenspeichersystemen in Betracht ziehen und Datenoperationen erstellen, die sie mit allen Quellsystemen auf dem neuesten Stand halten. Herkömmliche Batch-Jobs reichen nicht aus, um die Größe und Vielfalt der Daten zu verarbeiten, die Sie für die Integration in Ihre generative KI-Anwendung benötigen. Verzögerungen bei der Verarbeitung der Änderungen in Quellsystemen führen zu einer ungenauen Reaktion und verringern die Effizienz Ihrer generativen KI-Anwendung. Durch Datenstreaming können Sie Daten aus einer Vielzahl von Datenbanken in verschiedenen Systemen erfassen. Außerdem können Sie damit Daten aus vielen Quellen effizient und nahezu in Echtzeit umwandeln, anreichern, zusammenführen und aggregieren. Datenstreaming bietet eine vereinfachte Datenarchitektur zum Sammeln und Transformieren von Echtzeitreaktionen oder Kommentaren der Benutzer zu den Anwendungsantworten und hilft Ihnen, die Ergebnisse zur Feinabstimmung des Modells bereitzustellen und in einem Datensee zu speichern. Datenstreaming hilft Ihnen auch dabei, Datenpipelines zu optimieren, indem nur die Änderungsereignisse verarbeitet werden, sodass Sie schneller und effizienter auf Datenänderungen reagieren können.
Erfahren Sie mehr darüber AWS-Daten-Streaming-Dienste und beginnen Sie mit dem Aufbau Ihrer eigenen Daten-Streaming-Lösung.
Über die Autoren
 Ali Alemi ist ein Streaming Specialist Solutions Architect bei AWS. Ali berät AWS-Kunden mit architektonischen Best Practices und hilft ihnen, Echtzeit-Analysedatensysteme zu entwerfen, die zuverlässig, sicher, effizient und kostengünstig sind. Er arbeitet ausgehend von den Anwendungsfällen der Kunden rückwärts und entwirft Datenlösungen, um ihre Geschäftsprobleme zu lösen. Bevor er zu AWS kam, unterstützte Ali mehrere Kunden aus dem öffentlichen Sektor und AWS-Beratungspartner bei ihrer Reise zur Anwendungsmodernisierung und Migration in die Cloud.
Ali Alemi ist ein Streaming Specialist Solutions Architect bei AWS. Ali berät AWS-Kunden mit architektonischen Best Practices und hilft ihnen, Echtzeit-Analysedatensysteme zu entwerfen, die zuverlässig, sicher, effizient und kostengünstig sind. Er arbeitet ausgehend von den Anwendungsfällen der Kunden rückwärts und entwirft Datenlösungen, um ihre Geschäftsprobleme zu lösen. Bevor er zu AWS kam, unterstützte Ali mehrere Kunden aus dem öffentlichen Sektor und AWS-Beratungspartner bei ihrer Reise zur Anwendungsmodernisierung und Migration in die Cloud.
 Imtiaz (Taz) sagte ist der weltweite Technologieführer für Analytics bei AWS. Er genießt es, sich mit der Community zu allen Themen rund um Daten und Analysen auszutauschen. Er ist erreichbar über LinkedIn.
Imtiaz (Taz) sagte ist der weltweite Technologieführer für Analytics bei AWS. Er genießt es, sich mit der Community zu allen Themen rund um Daten und Analysen auszutauschen. Er ist erreichbar über LinkedIn.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

