Bài đăng trên blog này được đồng viết với Caroline Chung từ Veoneer.
Veoneer là công ty điện tử ô tô toàn cầu và là công ty hàng đầu thế giới về hệ thống an toàn điện tử ô tô. Họ cung cấp các hệ thống kiểm soát hạn chế tốt nhất và đã cung cấp hơn 1 tỷ bộ điều khiển điện tử và cảm biến va chạm cho các nhà sản xuất ô tô trên toàn cầu. Công ty tiếp tục xây dựng lịch sử 70 năm phát triển an toàn ô tô, chuyên về phần cứng và hệ thống tiên tiến giúp ngăn ngừa sự cố giao thông và giảm thiểu tai nạn.
Cảm biến trong cabin ô tô (ICS) là một không gian mới nổi sử dụng kết hợp một số loại cảm biến như máy ảnh và radar cũng như các thuật toán dựa trên trí tuệ nhân tạo (AI) và máy học (ML) để nâng cao độ an toàn và cải thiện trải nghiệm lái xe. Xây dựng một hệ thống như vậy có thể là một nhiệm vụ phức tạp. Các nhà phát triển phải chú thích thủ công khối lượng lớn hình ảnh cho mục đích đào tạo và thử nghiệm. Điều này rất tốn thời gian và tốn nhiều tài nguyên. Thời gian hoàn thành cho một nhiệm vụ như vậy là vài tuần. Hơn nữa, các công ty phải giải quyết các vấn đề như nhãn mác không nhất quán do lỗi của con người.
AWS tập trung vào việc giúp bạn tăng tốc độ phát triển và giảm chi phí xây dựng các hệ thống như vậy thông qua các phân tích nâng cao như ML. Tầm nhìn của chúng tôi là sử dụng ML để chú thích tự động, cho phép đào tạo lại các mô hình an toàn và đảm bảo các số liệu hiệu suất nhất quán và đáng tin cậy. Trong bài đăng này, chúng tôi chia sẻ cách thức cộng tác với Tổ chức Chuyên gia Toàn cầu của Amazon và Trung tâm đổi mới AI sáng tạo, chúng tôi đã phát triển một quy trình học tập tích cực cho các hộp giới hạn đầu hình ảnh trong cabin và chú thích các điểm chính. Giải pháp này giúp giảm hơn 90% chi phí, tăng tốc quá trình chú thích từ hàng tuần xuống hàng giờ xét về thời gian quay vòng và cho phép sử dụng lại cho các tác vụ ghi nhãn dữ liệu ML tương tự.
Tổng quan về giải pháp
Học tích cực là một cách tiếp cận ML bao gồm một quá trình lặp đi lặp lại trong việc lựa chọn và chú thích dữ liệu có nhiều thông tin nhất để huấn luyện một mô hình. Với một tập hợp nhỏ dữ liệu được gắn nhãn và một tập hợp lớn dữ liệu không được gắn nhãn, học tập tích cực sẽ cải thiện hiệu suất của mô hình, giảm nỗ lực gắn nhãn và tích hợp kiến thức chuyên môn của con người để mang lại kết quả chắc chắn. Trong bài đăng này, chúng tôi xây dựng một quy trình học tập tích cực cho chú thích hình ảnh bằng các dịch vụ AWS.
Sơ đồ sau đây thể hiện khuôn khổ tổng thể cho quy trình học tập tích cực của chúng tôi. Quy trình ghi nhãn lấy hình ảnh từ một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) và xuất ra các hình ảnh có chú thích với sự hợp tác của mô hình ML và kiến thức chuyên môn của con người. Quy trình đào tạo xử lý trước dữ liệu và sử dụng chúng để đào tạo các mô hình ML. Mô hình ban đầu được thiết lập và huấn luyện trên một tập hợp nhỏ dữ liệu được gắn nhãn thủ công và sẽ được sử dụng trong quy trình gắn nhãn. Quy trình gắn nhãn và quy trình đào tạo có thể được lặp lại dần dần với nhiều dữ liệu được gắn nhãn hơn để nâng cao hiệu suất của mô hình.
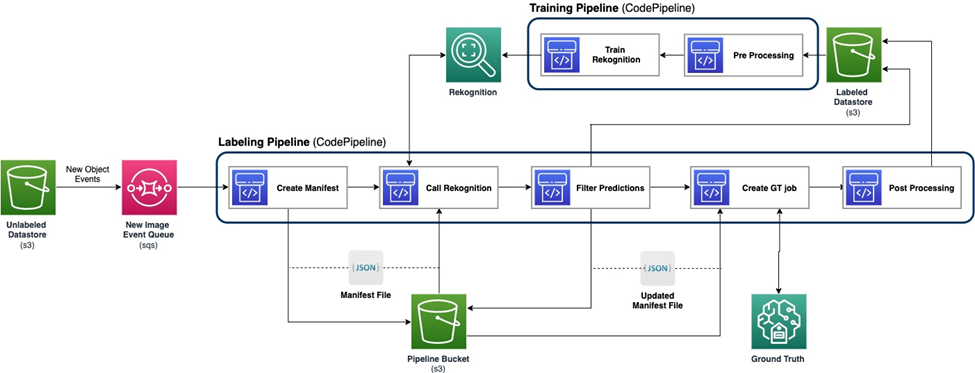
Trong quy trình ghi nhãn, một Thông báo sự kiện Amazon S3 được gọi khi một loạt hình ảnh mới đi vào bộ chứa Kho dữ liệu chưa được gắn nhãn S3, kích hoạt quy trình gắn nhãn. Mô hình đưa ra kết quả suy luận trên ảnh mới. Hàm phán đoán tùy chỉnh sẽ chọn các phần của dữ liệu dựa trên điểm tin cậy suy luận hoặc các hàm khác do người dùng xác định. Dữ liệu này, cùng với kết quả suy luận của nó, được gửi cho công việc ghi nhãn của con người trên Sự thật về mặt đất của Amazon SageMaker do đường ống tạo ra. Quy trình gắn nhãn của con người giúp chú thích dữ liệu và các kết quả đã sửa đổi được kết hợp với dữ liệu được chú thích tự động còn lại, dữ liệu này có thể được sử dụng sau này trong quy trình đào tạo.
Quá trình đào tạo lại mô hình diễn ra trong quy trình đào tạo, trong đó chúng tôi sử dụng tập dữ liệu chứa dữ liệu do con người gắn nhãn để đào tạo lại mô hình. Tệp kê khai được tạo để mô tả nơi lưu trữ tệp và mô hình ban đầu tương tự sẽ được đào tạo lại trên dữ liệu mới. Sau khi đào tạo lại, mô hình mới sẽ thay thế mô hình ban đầu và quá trình lặp lại tiếp theo của quy trình học tập tích cực sẽ bắt đầu.
Triển khai mô hình
Cả quy trình ghi nhãn và quy trình đào tạo đều được triển khai trên Đường ống dẫn mã AWS. Xây dựng mã AWS các phiên bản được sử dụng để triển khai, linh hoạt và nhanh chóng đối với một lượng nhỏ dữ liệu. Khi cần tốc độ, chúng tôi sử dụng Amazon SageMaker điểm cuối dựa trên phiên bản GPU để phân bổ nhiều tài nguyên hơn nhằm hỗ trợ và đẩy nhanh quá trình.
Quy trình đào tạo lại mô hình có thể được gọi khi có tập dữ liệu mới hoặc khi hiệu suất của mô hình cần được cải thiện. Một nhiệm vụ quan trọng trong quy trình đào tạo lại là có hệ thống kiểm soát phiên bản cho cả dữ liệu huấn luyện và mô hình. Mặc dù các dịch vụ AWS như Nhận thức lại Amazon có tính năng kiểm soát phiên bản tích hợp, giúp dễ dàng triển khai quy trình, các mô hình tùy chỉnh yêu cầu ghi nhật ký siêu dữ liệu hoặc các công cụ kiểm soát phiên bản bổ sung.
Toàn bộ quy trình làm việc được thực hiện bằng cách sử dụng Bộ công cụ phát triển đám mây AWS (AWS CDK) để tạo các thành phần AWS cần thiết, bao gồm:
- Hai vai trò cho công việc CodePipeline và SageMaker
- Hai công việc CodePipeline, điều phối quy trình làm việc
- Hai nhóm S3 dành cho các thành phần mã của quy trình
- Một nhóm S3 để gắn nhãn cho bảng kê khai công việc, bộ dữ liệu và mô hình
- Tiền xử lý và hậu xử lý AWS Lambda các chức năng dành cho công việc ghi nhãn SageMaker Ground Truth
Các ngăn xếp CDK của AWS có tính mô-đun hóa cao và có thể tái sử dụng cho nhiều tác vụ khác nhau. Bạn có thể thay thế mã đào tạo, mã suy luận và mẫu SageMaker Ground Truth cho mọi tình huống học tập tích cực tương tự.
Đào tạo người mẫu
Đào tạo mô hình bao gồm hai nhiệm vụ: chú thích hộp giới hạn đầu và chú thích các điểm chính của con người. Chúng tôi giới thiệu cả hai trong phần này.
Chú thích hộp giới hạn đầu
Chú thích hộp giới hạn đầu người là nhiệm vụ dự đoán vị trí của hộp giới hạn đầu người trong một hình ảnh. Chúng tôi sử dụng một Nhãn tùy chỉnh Rekognition của Amazon mô hình cho chú thích hộp giới hạn đầu. Sau đây mẫu máy tính xách tay cung cấp hướng dẫn từng bước về cách đào tạo mô hình Nhãn tùy chỉnh Rekognition thông qua SageMaker.
Trước tiên chúng ta cần chuẩn bị dữ liệu để bắt đầu đào tạo. Chúng tôi tạo tệp kê khai cho quá trình đào tạo và tệp kê khai cho tập dữ liệu thử nghiệm. Tệp kê khai chứa nhiều mục, mỗi mục dành cho một hình ảnh. Sau đây là ví dụ về tệp kê khai, bao gồm đường dẫn hình ảnh, kích thước và thông tin chú thích:
Bằng cách sử dụng tệp kê khai, chúng tôi có thể tải tập dữ liệu vào mô hình Nhãn tùy chỉnh Rekognition để đào tạo và thử nghiệm. Chúng tôi đã lặp lại mô hình với lượng dữ liệu huấn luyện khác nhau và thử nghiệm nó trên cùng 239 hình ảnh chưa được nhìn thấy. Trong thử nghiệm này, mAP_50 điểm tăng từ 0.33 với 114 ảnh huấn luyện lên 0.95 với 957 ảnh huấn luyện. Ảnh chụp màn hình sau đây hiển thị các số liệu hiệu suất của mô hình Nhãn tùy chỉnh Rekognition cuối cùng, mang lại hiệu suất tuyệt vời về điểm F1, độ chính xác và khả năng thu hồi.

Chúng tôi đã thử nghiệm thêm mô hình trên một tập dữ liệu bị giữ lại có 1,128 hình ảnh. Mô hình dự đoán nhất quán các dự đoán hộp giới hạn chính xác trên dữ liệu chưa được nhìn thấy, mang lại kết quả cao mAP_50 là 94.9%. Ví dụ sau đây hiển thị hình ảnh được chú thích tự động với hộp giới hạn phần đầu.

Chú thích điểm chính
Chú thích điểm chính tạo ra vị trí của các điểm chính, bao gồm mắt, tai, mũi, miệng, cổ, vai, khuỷu tay, cổ tay, hông và mắt cá chân. Ngoài dự đoán vị trí, cần có khả năng hiển thị của từng điểm để dự đoán trong nhiệm vụ cụ thể này, vì vậy chúng tôi thiết kế một phương pháp mới.
Để chú thích các điểm chính, chúng tôi sử dụng Mô hình tư thế Yolo 8 trên SageMaker làm mô hình ban đầu. Trước tiên, chúng tôi chuẩn bị dữ liệu cho việc đào tạo, bao gồm tạo tệp nhãn và tệp .yaml cấu hình theo yêu cầu của Yolo. Sau khi chuẩn bị dữ liệu, chúng tôi huấn luyện mô hình và lưu các tạo phẩm, bao gồm cả tệp trọng số mô hình. Với tệp trọng số mô hình đã được đào tạo, chúng ta có thể chú thích các hình ảnh mới.
Trong giai đoạn huấn luyện, tất cả các điểm được gắn nhãn cùng với vị trí, bao gồm các điểm nhìn thấy được và các điểm bị che khuất, đều được sử dụng để huấn luyện. Do đó, mô hình này theo mặc định cung cấp vị trí và độ tin cậy của dự đoán. Trong hình dưới đây, ngưỡng tin cậy lớn (ngưỡng chính) gần 0.6 có khả năng phân chia các điểm nhìn thấy hoặc bị che khuất so với bên ngoài tầm nhìn của máy ảnh. Tuy nhiên, các điểm bị che khuất và các điểm nhìn thấy không được phân tách bằng độ tin cậy, điều đó có nghĩa là độ tin cậy dự đoán không hữu ích cho việc dự đoán tầm nhìn.

Để có được dự đoán về khả năng hiển thị, chúng tôi giới thiệu một mô hình bổ sung được đào tạo trên tập dữ liệu chỉ chứa các điểm hiển thị, loại trừ cả các điểm bị che khuất và bên ngoài tầm nhìn của máy ảnh. Hình dưới đây cho thấy sự phân bố của các điểm có tầm nhìn khác nhau. Các điểm nhìn thấy được và các điểm khác có thể được tách biệt trong mô hình bổ sung. Chúng ta có thể sử dụng ngưỡng (ngưỡng bổ sung) gần 0.6 để lấy điểm hiển thị. Bằng cách kết hợp hai mô hình này, chúng tôi thiết kế một phương pháp dự đoán vị trí và tầm nhìn.

Điểm chính được dự đoán đầu tiên bởi mô hình chính với vị trí và độ tin cậy chính, sau đó chúng tôi nhận được dự đoán độ tin cậy bổ sung từ mô hình bổ sung. Khả năng hiển thị của nó sau đó được phân loại như sau:
- Hiển thị, nếu độ tin cậy chính của nó lớn hơn ngưỡng chính và độ tin cậy bổ sung của nó lớn hơn ngưỡng bổ sung
- Bị chặn, nếu độ tin cậy chính của nó lớn hơn ngưỡng chính và độ tin cậy bổ sung của nó nhỏ hơn hoặc bằng ngưỡng bổ sung
- Ngoài sự xem xét của máy ảnh, nếu không
Một ví dụ về chú thích các điểm chính được minh họa trong hình ảnh sau, trong đó các dấu liền là các điểm nhìn thấy được và các dấu rỗng là các điểm bị che khuất. Bên ngoài các điểm đánh giá của máy ảnh không được hiển thị.

Dựa trên tiêu chuẩn OK định nghĩa trên tập dữ liệu MS-COCO, phương pháp của chúng tôi có thể đạt được mAP_50 là 98.4% trên tập dữ liệu thử nghiệm chưa xem. Về khả năng hiển thị, phương pháp này mang lại độ chính xác phân loại 79.2% trên cùng một tập dữ liệu.
Ghi nhãn và đào tạo lại con người
Mặc dù các mô hình đạt được hiệu suất tuyệt vời trên dữ liệu thử nghiệm nhưng vẫn có khả năng mắc lỗi trên dữ liệu thực tế mới. Ghi nhãn con người là quá trình sửa chữa những lỗi này nhằm nâng cao hiệu suất của mô hình bằng cách đào tạo lại. Chúng tôi đã thiết kế một hàm phán đoán kết hợp giá trị tin cậy xuất ra từ các mô hình ML cho đầu ra của tất cả các hộp giới hạn đầu hoặc các điểm chính. Chúng tôi sử dụng điểm số cuối cùng để xác định những lỗi này và kết quả là các hình ảnh bị gắn nhãn xấu cần được gửi đến quy trình gắn nhãn của con người.
Ngoài những hình ảnh bị dán nhãn xấu, một phần nhỏ hình ảnh được chọn ngẫu nhiên để con người gắn nhãn. Những hình ảnh do con người gắn nhãn này được thêm vào phiên bản hiện tại của tập huấn luyện để đào tạo lại, nâng cao hiệu suất mô hình và độ chính xác của chú thích tổng thể.
Trong quá trình triển khai, chúng tôi sử dụng SageMaker Ground Truth cho ghi nhãn con người quá trình. SageMaker Ground Truth cung cấp giao diện người dùng thân thiện và trực quan để ghi nhãn dữ liệu. Ảnh chụp màn hình sau đây minh họa công việc gắn nhãn SageMaker Ground Truth cho chú thích hộp giới hạn đầu.

Ảnh chụp màn hình sau đây minh họa công việc gắn nhãn SageMaker Ground Truth cho chú thích các điểm chính.

Chi phí, tốc độ và khả năng sử dụng lại
Chi phí và tốc độ là những lợi thế chính khi sử dụng giải pháp của chúng tôi so với việc ghi nhãn do con người thực hiện, như được trình bày trong các bảng sau. Chúng tôi sử dụng các bảng này để thể hiện mức tiết kiệm chi phí và tăng tốc độ. Sử dụng phiên bản GPU SageMaker ml.g4dn.xlarge được tăng tốc, toàn bộ chi phí đào tạo và suy luận trên 100,000 hình ảnh thấp hơn 99% so với chi phí do con người ghi nhãn, trong khi tốc độ nhanh hơn 10–10,000 lần so với việc ghi nhãn do con người thực hiện, tùy thuộc vào nhiệm vụ.
Bảng đầu tiên tóm tắt các số liệu hiệu suất chi phí.
| Mô hình | mAP_50 dựa trên 1,128 hình ảnh thử nghiệm | Chi phí đào tạo dựa trên 100,000 hình ảnh | Chi phí suy luận dựa trên 100,000 hình ảnh | Giảm chi phí so với chú thích của con người | Thời gian suy luận dựa trên 100,000 hình ảnh | Tăng tốc thời gian so với chú thích của con người |
| Hộp giới hạn đầu Rekognition | 0.949 | $4 | $22 | 99% ít | 5.5 h | Ngày |
| Những điểm chính của Yolo | 0.984 | $27.20 | * $10 | 99.9% ít | phút | tuần |
Bảng sau đây tóm tắt các số liệu hiệu suất.
| Nhiệm vụ chú thích | mAP_50 (%) | Chi phí đào tạo ($) | Chi phí suy luận ($) | Thời gian suy luận |
| Hộp đóng đầu | 94.9 | 4 | 22 | 5.5 giờ |
| Những điểm chính | 98.4 | 27 | 10 | 5 phút |
Hơn nữa, giải pháp của chúng tôi cung cấp khả năng sử dụng lại cho các nhiệm vụ tương tự. Sự phát triển nhận thức camera cho các hệ thống khác như hệ thống hỗ trợ người lái tiên tiến (ADAS) và hệ thống trong cabin cũng có thể áp dụng giải pháp của chúng tôi.
Tổng kết
Trong bài đăng này, chúng tôi đã trình bày cách xây dựng quy trình học tập tích cực để tự động chú thích các hình ảnh trong cabin bằng cách sử dụng các dịch vụ AWS. Chúng tôi chứng minh sức mạnh của ML, cho phép bạn tự động hóa và đẩy nhanh quá trình chú thích cũng như tính linh hoạt của khung sử dụng các mô hình được dịch vụ AWS hỗ trợ hoặc được tùy chỉnh trên SageMaker. Với Amazon S3, SageMaker, Lambda và SageMaker Ground Truth, bạn có thể hợp lý hóa việc lưu trữ, chú thích, đào tạo và triển khai dữ liệu, đồng thời đạt được khả năng sử dụng lại đồng thời giảm đáng kể chi phí. Bằng cách triển khai giải pháp này, các công ty ô tô có thể trở nên linh hoạt hơn và tiết kiệm chi phí hơn bằng cách sử dụng các phân tích nâng cao dựa trên ML như chú thích hình ảnh tự động.
Hãy bắt đầu ngay hôm nay và mở khóa sức mạnh của Dịch vụ AWS và học máy cho các trường hợp sử dụng cảm biến trong cabin ô tô của bạn!
Về các tác giả
 Diên Hương Vũ là Nhà khoa học ứng dụng tại Trung tâm đổi mới AI sáng tạo của Amazon. Với hơn 9 năm kinh nghiệm xây dựng các giải pháp AI và máy học cho các ứng dụng công nghiệp, anh ấy chuyên về AI tổng quát, thị giác máy tính và mô hình hóa chuỗi thời gian.
Diên Hương Vũ là Nhà khoa học ứng dụng tại Trung tâm đổi mới AI sáng tạo của Amazon. Với hơn 9 năm kinh nghiệm xây dựng các giải pháp AI và máy học cho các ứng dụng công nghiệp, anh ấy chuyên về AI tổng quát, thị giác máy tính và mô hình hóa chuỗi thời gian.
 Thiên Nhất Mao là Nhà khoa học ứng dụng tại AWS có trụ sở tại khu vực Chicago. Anh có hơn 5 năm kinh nghiệm trong việc xây dựng các giải pháp học máy và học sâu, đồng thời tập trung vào thị giác máy tính và học tập tăng cường dựa trên phản hồi của con người. Anh thích làm việc với khách hàng để hiểu những thách thức của họ và giải quyết chúng bằng cách tạo ra các giải pháp sáng tạo bằng dịch vụ AWS.
Thiên Nhất Mao là Nhà khoa học ứng dụng tại AWS có trụ sở tại khu vực Chicago. Anh có hơn 5 năm kinh nghiệm trong việc xây dựng các giải pháp học máy và học sâu, đồng thời tập trung vào thị giác máy tính và học tập tăng cường dựa trên phản hồi của con người. Anh thích làm việc với khách hàng để hiểu những thách thức của họ và giải quyết chúng bằng cách tạo ra các giải pháp sáng tạo bằng dịch vụ AWS.
 Yanru Xiao là Nhà khoa học ứng dụng tại Trung tâm đổi mới AI sáng tạo của Amazon, nơi ông xây dựng các giải pháp AI/ML cho các vấn đề kinh doanh trong thế giới thực của khách hàng. Ông đã làm việc trong nhiều lĩnh vực, bao gồm sản xuất, năng lượng và nông nghiệp. Yanru lấy bằng tiến sĩ. về Khoa học Máy tính tại Đại học Old Dominion.
Yanru Xiao là Nhà khoa học ứng dụng tại Trung tâm đổi mới AI sáng tạo của Amazon, nơi ông xây dựng các giải pháp AI/ML cho các vấn đề kinh doanh trong thế giới thực của khách hàng. Ông đã làm việc trong nhiều lĩnh vực, bao gồm sản xuất, năng lượng và nông nghiệp. Yanru lấy bằng tiến sĩ. về Khoa học Máy tính tại Đại học Old Dominion.
 Paul George là công ty dẫn đầu về sản phẩm với hơn 15 năm kinh nghiệm trong lĩnh vực công nghệ ô tô. Ông rất thành thạo trong việc lãnh đạo các nhóm kỹ thuật hệ thống, chiến lược, tiếp cận thị trường và quản lý sản phẩm. Ông đã ươm tạo và cho ra mắt một số sản phẩm cảm biến và nhận thức mới trên toàn cầu. Tại AWS, ông là người chỉ đạo chiến lược và tiếp cận thị trường cho khối lượng công việc của xe tự lái.
Paul George là công ty dẫn đầu về sản phẩm với hơn 15 năm kinh nghiệm trong lĩnh vực công nghệ ô tô. Ông rất thành thạo trong việc lãnh đạo các nhóm kỹ thuật hệ thống, chiến lược, tiếp cận thị trường và quản lý sản phẩm. Ông đã ươm tạo và cho ra mắt một số sản phẩm cảm biến và nhận thức mới trên toàn cầu. Tại AWS, ông là người chỉ đạo chiến lược và tiếp cận thị trường cho khối lượng công việc của xe tự lái.
 Caroline Chung là giám đốc kỹ thuật tại Veoneer (được Magna International mua lại), cô có hơn 14 năm kinh nghiệm phát triển hệ thống cảm biến và nhận thức. Cô hiện đang lãnh đạo các chương trình tiền phát triển cảm biến nội thất tại Magna International, quản lý một nhóm kỹ sư thị giác máy tính và nhà khoa học dữ liệu.
Caroline Chung là giám đốc kỹ thuật tại Veoneer (được Magna International mua lại), cô có hơn 14 năm kinh nghiệm phát triển hệ thống cảm biến và nhận thức. Cô hiện đang lãnh đạo các chương trình tiền phát triển cảm biến nội thất tại Magna International, quản lý một nhóm kỹ sư thị giác máy tính và nhà khoa học dữ liệu.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

