Giới thiệu
Sự ra đời của các mô hình ngôn ngữ lớn là một trong những bước phát triển công nghệ thú vị nhất của thời đại chúng ta. Nó đã mở ra những khả năng vô tận trong trí tuệ nhân tạo, đưa ra giải pháp cho các vấn đề trong thế giới thực trong các ngành công nghiệp khác nhau. Một trong những ứng dụng hấp dẫn của các mô hình này là phát triển các chatbot hoặc trả lời câu hỏi tùy chỉnh lấy từ các nguồn dữ liệu cá nhân hoặc tổ chức. Tuy nhiên, vì các LLM được đào tạo dựa trên dữ liệu chung có sẵn công khai nên câu trả lời của họ có thể không phải lúc nào cũng cụ thể hoặc hữu ích cho người dùng cuối. Chúng tôi có thể sử dụng các khung như LangChain để giải quyết vấn đề này nhằm phát triển các chatbot tùy chỉnh cung cấp câu trả lời cụ thể dựa trên dữ liệu của chúng tôi. Trong bài viết này, chúng ta sẽ tìm hiểu cách xây dựng các ứng dụng Q&A tùy chỉnh với việc triển khai trên Streamlit Cloud.

Mục tiêu học tập
Trước khi đi sâu vào bài viết, hãy phác thảo các mục tiêu học tập chính:
- Tìm hiểu toàn bộ quy trình làm việc của câu hỏi và câu trả lời tùy chỉnh cũng như vai trò của từng thành phần trong quy trình làm việc
- Biết lợi thế của ứng dụng Hỏi & Đáp so với LLM tùy chỉnh tinh chỉnh
- Tìm hiểu kiến thức cơ bản về cơ sở dữ liệu vectơ Pinecone để lưu trữ và truy xuất vectơ
- Xây dựng quy trình tìm kiếm ngữ nghĩa bằng cách sử dụng OpenAI LLM, LangChain và cơ sở dữ liệu vectơ Pinecone để phát triển ứng dụng hợp lý hóa.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Tổng quan về các ứng dụng hỏi đáp

Trả lời câu hỏi hoặc “trò chuyện qua dữ liệu của bạn” là trường hợp sử dụng rộng rãi của LLM và LangChain. LangChain cung cấp một loạt các thành phần để tải bất kỳ nguồn dữ liệu nào bạn có thể tìm thấy cho trường hợp sử dụng của mình. Nó hỗ trợ nhiều nguồn dữ liệu và bộ biến áp để chuyển đổi thành một chuỗi chuỗi để lưu trữ trong cơ sở dữ liệu vector. Sau khi dữ liệu được lưu trữ trong cơ sở dữ liệu, người ta có thể truy vấn cơ sở dữ liệu bằng cách sử dụng các thành phần được gọi là bộ truy xuất. Hơn nữa, bằng cách sử dụng LLM, chúng tôi có thể nhận được câu trả lời chính xác như chatbot mà không cần tung hứng qua hàng tấn tài liệu.
LangChain hỗ trợ các nguồn dữ liệu sau. Như bạn có thể thấy trong hình, nó cho phép hơn 120 tích hợp kết nối mọi nguồn dữ liệu mà bạn có thể có.
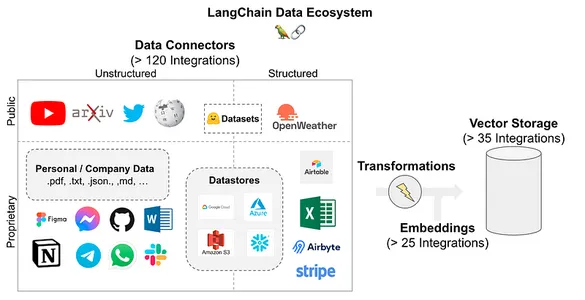
Quy trình ứng dụng hỏi đáp
Chúng tôi đã tìm hiểu về các nguồn dữ liệu được LangChain hỗ trợ, cho phép chúng tôi phát triển một quy trình trả lời câu hỏi bằng cách sử dụng các thành phần có sẵn trong LangChain. Dưới đây là các thành phần được sử dụng trong quá trình tải, lưu trữ, truy xuất và tạo đầu ra của tài liệu bằng LLM.
- Bộ nạp tài liệu: Để tải tài liệu người dùng cho mục đích vector hóa và lưu trữ
- Bộ tách văn bản: Đây là những bộ chuyển đổi tài liệu giúp chuyển đổi tài liệu thành các đoạn có độ dài cố định để lưu trữ chúng một cách hiệu quả
- Lưu trữ vectơ: Tích hợp cơ sở dữ liệu vector để lưu trữ các bản nhúng vector của văn bản đầu vào
- Truy xuất tài liệu: Để truy xuất văn bản dựa trên truy vấn của người dùng tới cơ sở dữ liệu. Họ sử dụng các kỹ thuật tìm kiếm tương tự để truy xuất giống nhau.
- Đầu ra mô hình: Đầu ra mô hình cuối cùng cho truy vấn người dùng được tạo từ dấu nhắc đầu vào của truy vấn và văn bản đã truy xuất.
Đây là quy trình công việc cấp cao của quy trình trả lời câu hỏi, có thể giải quyết nhiều vấn đề trong thế giới thực. Tôi chưa đi sâu vào từng Thành phần LangChain, nhưng nếu bạn đang muốn tìm hiểu thêm về nó, thì hãy xem bài viết trước của tôi được đăng trên Analytics Vidhya (Liên kết: Bấm vào đây)

Ưu điểm của ứng dụng Q&A tùy chỉnh so với Tinh chỉnh mô hình
- Câu trả lời theo ngữ cảnh cụ thể
- Thích nghi với các tài liệu đầu vào mới
- Không cần tinh chỉnh mô hình, giúp tiết kiệm chi phí đào tạo mô hình
- Câu trả lời chính xác và cụ thể hơn là câu trả lời chung chung
Cơ sở dữ liệu Vector Pinecone là gì?

Pinecone là một cơ sở dữ liệu vector phổ biến được sử dụng trong việc xây dựng các ứng dụng hỗ trợ LLM. Nó linh hoạt và có thể mở rộng cho các ứng dụng AI hiệu suất cao. Đó là một cơ sở dữ liệu vectơ gốc trên đám mây được quản lý hoàn toàn, không có sự phức tạp về cơ sở hạ tầng từ người dùng.
Các ứng dụng cơ sở LLM liên quan đến một lượng lớn dữ liệu phi cấu trúc, đòi hỏi bộ nhớ dài hạn tinh vi để truy xuất thông tin với độ chính xác tối đa. Các ứng dụng AI sáng tạo dựa trên tìm kiếm ngữ nghĩa trên các phép nhúng vectơ để trả về ngữ cảnh phù hợp dựa trên đầu vào của người dùng.
Pinecone rất thích hợp cho các ứng dụng như vậy và được tối ưu hóa để lưu trữ và truy vấn nhiều vectơ với độ trễ thấp nhằm xây dựng các ứng dụng thân thiện với người dùng. Hãy tìm hiểu cách tạo cơ sở dữ liệu vectơ hình nón tùng cho ứng dụng trả lời câu hỏi của chúng ta.
# install pinecone-client
pip install pinecone-client # import pinecone and initialize with your API key and environment name
import pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT") # create your first index to get started with storing vectors pinecone.create_index("first_index", dimension=8, metric="cosine") # Upsert sample data (5 8-dimensional vectors)
index.upsert([ ("A", [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]), ("B", [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]), ("C", [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]), ("D", [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]), ("E", [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5])
]) # Use list_indexes() method to call a number of indexes available in db
pinecone.list_indexes() [Output]>>> ['first_index']Trong phần trình diễn ở trên, chúng tôi cài đặt ứng dụng khách pinecone để khởi tạo cơ sở dữ liệu vectơ trong môi trường dự án của chúng tôi. Khi cơ sở dữ liệu vectơ được khởi tạo, chúng ta có thể tạo một chỉ mục có thứ nguyên và số liệu bắt buộc để chèn các nhúng vectơ vào cơ sở dữ liệu vectơ. Trong phần tiếp theo, chúng tôi sẽ phát triển một quy trình tìm kiếm ngữ nghĩa bằng Pinecone và LangChain cho ứng dụng của chúng tôi.
Xây dựng quy trình tìm kiếm ngữ nghĩa bằng OpenAI và Pinecone
Chúng tôi đã học được rằng có 5 bước trong quy trình ứng dụng trả lời câu hỏi. Trong phần này, chúng ta sẽ thực hiện 4 bước đầu tiên: bộ nạp tài liệu, bộ tách văn bản, lưu trữ vector và truy xuất tài liệu.
Để thực hiện các bước này trong môi trường cục bộ hoặc môi trường sổ ghi chép dựa trên đám mây như Google Colab, bạn phải cài đặt một số thư viện và tạo tài khoản trên OpenAI và Pinecone để lấy các khóa API tương ứng. Hãy bắt đầu với việc thiết lập môi trường:
Cài đặt thư viện cần thiết
# install langchain and openai with other dependencies
!pip install --upgrade langchain openai -q
!pip install pillow==6.2.2
!pip install unstructured -q
!pip install unstructured[local-inference] -q
!pip install detectron2@git+https://github.com/facebookresearch/[email protected] / #egg=detectron2 -q
!apt-get install poppler-utils
!pip install pinecone-client -q
!pip install tiktoken -q # setup openai environment
import os
os.environ["OPENAI_API_KEY"] = "YOUR-API-KEY" # importing libraries
import os
import openai
import pinecone
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chainSau khi thiết lập cài đặt, hãy nhập tất cả các thư viện được đề cập trong đoạn mã trên. Sau đó, hãy làm theo các bước tiếp theo dưới đây:
Tải tài liệu
Trong bước này, chúng tôi sẽ tải các tài liệu từ thư mục làm điểm bắt đầu cho quy trình dự án AI. chúng tôi có 2 tài liệu trong thư mục của mình, chúng tôi sẽ tải tài liệu này vào môi trường dự án của mình.
#load the documents from content/data dir
directory = '/content/data' # load_docs functions to load documents using langchain function
def load_docs(directory): loader = DirectoryLoader(directory) documents = loader.load() return documents documents = load_docs(directory)
len(documents)
[Output]>>> 5Tách dữ liệu văn bản
Nhúng văn bản và LLM hoạt động tốt hơn nếu mỗi tài liệu có độ dài cố định. Do đó, việc chia văn bản thành các đoạn có độ dài bằng nhau là cần thiết cho bất kỳ trường hợp sử dụng LLM nào. chúng tôi sẽ sử dụng 'Recursive CharacterTextSplitter' để chuyển đổi tài liệu thành cùng kích thước như tài liệu văn bản.
# split the docs using recursive text splitter
def split_docs(documents, chunk_size=200, chunk_overlap=20): text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) docs = text_splitter.split_documents(documents) return docs # split the docs
docs = split_docs(documents)
print(len(docs))
[Output]>>>12Lưu trữ dữ liệu trong bộ lưu trữ Vector
Sau khi các tài liệu được chia nhỏ, chúng tôi sẽ lưu trữ các phần nhúng của chúng trong cơ sở dữ liệu vectơ bằng cách sử dụng các phần nhúng OpenAI.
# embedding example on random word
embeddings = OpenAIEmbeddings() # initiate pinecondb
pinecone.init( api_key="YOUR-API-KEY", environment="YOUR-ENV"
) # define index name
index_name = "langchain-project" # store the data and embeddings into pinecone index
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)Lấy dữ liệu từ cơ sở dữ liệu Vector
Chúng tôi sẽ truy xuất các tài liệu ở giai đoạn này bằng cách sử dụng tìm kiếm ngữ nghĩa từ cơ sở dữ liệu vectơ của chúng tôi. chúng tôi có các vectơ được lưu trữ trong một chỉ mục có tên “dự án langchain” và một khi chúng tôi truy vấn giống như bên dưới, chúng tôi sẽ nhận được hầu hết các tài liệu tương tự từ cơ sở dữ liệu.
# An example query to our database
query = "What are the different types of pet animals are there?" # do a similarity search and store the documents in result variable result = index.similarity_search( query, # our search query k=3 # return 3 most relevant docs
)
-
--------------------------------[Output]--------------------------------------
result
[Document(page_content='Small mammals like hamsters, guinea pigs, and rabbits are often chosen for their
low maintenance needs. Birds offer beauty and song,
and reptiles like turtles and lizards can make intriguing pets.', metadata={'source': '/content/data/Different Types of Pet Animals.txt'}), Document(page_content='Pet animals come in all shapes and sizes, each suited to different lifestyles and home environments. Dogs and cats are the most common, known for their companionship and unique personalities. Small', metadata={'source': '/content/data/Different Types of Pet Animals.txt'}), Document(page_content='intriguing pets. Even fish, with their calming presence
, can be wonderful pets.', metadata={'source': '/content/data/Different Types of Pet Animals.txt'})]Chúng tôi có thể truy xuất các tài liệu dựa trên tìm kiếm tương tự từ kho lưu trữ vectơ, như được hiển thị trong đoạn mã trên. Nếu bạn đang muốn tìm hiểu thêm về các ứng dụng tìm kiếm ngữ nghĩa. Tôi thực sự khuyên bạn nên đọc bài viết trước của tôi về chủ đề này (liên kết: nhấn vào đây )
Ứng dụng trả lời câu hỏi tùy chỉnh với Streamlit
Trong giai đoạn cuối cùng của ứng dụng trả lời câu hỏi, chúng tôi sẽ tích hợp mọi thành phần quy trình làm việc để xây dựng ứng dụng Hỏi & Đáp tùy chỉnh cho phép người dùng nhập nhiều nguồn dữ liệu khác nhau như bài viết trên web, PDF, CSV, v.v. để trò chuyện với ứng dụng đó. do đó làm cho họ hiệu quả trong các hoạt động hàng ngày của họ. Chúng tôi cần tạo một kho lưu trữ GitHub và thêm các tệp sau.

Thêm các tệp dự án này
- chính.py — Một tệp python chứa mã front-end streamlit
- qanda.py — Nhắc thiết kế và chức năng đầu ra Mô hình để trả lời câu hỏi cho truy vấn của người dùng
- utils.py — Tiện ích chức năng load và chia tài liệu đầu vào
- vector_search.py — Chức năng nhúng văn bản và lưu trữ Vector
- yêu cầu.txt — Phụ thuộc dự án để chạy ứng dụng trong đám mây công cộng hợp lý
Chúng tôi đang hỗ trợ hai loại nguồn dữ liệu trong phần trình diễn dự án này:
- Dữ liệu văn bản dựa trên URL web
- Tệp PDF trực tuyến
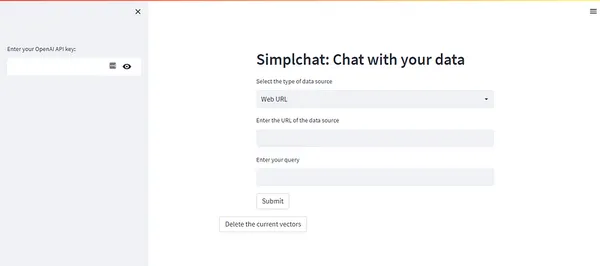
Hai loại này chứa nhiều loại dữ liệu văn bản và thường xuyên nhất đối với nhiều trường hợp sử dụng. Bạn có thể xem mã python main.py bên dưới để hiểu giao diện người dùng của ứng dụng.
# import necessary libraries
import streamlit as st
import openai
import qanda
from vector_search import *
from utils import *
from io import StringIO # take openai api key in
api_key = st.sidebar.text_input("Enter your OpenAI API key:", type='password')
# open ai key
openai.api_key = str(api_key) # header of the app
_ , col2,_ = st.columns([1,7,1])
with col2: col2 = st.header("Simplchat: Chat with your data") url = False query = False pdf = False data = False # select option based on user need options = st.selectbox("Select the type of data source", options=['Web URL','PDF','Existing data source']) #ask a query based on options of data sources if options == 'Web URL': url = st.text_input("Enter the URL of the data source") query = st.text_input("Enter your query") button = st.button("Submit") elif options == 'PDF': pdf = st.text_input("Enter your PDF link here") query = st.text_input("Enter your query") button = st.button("Submit") elif options == 'Existing data source': data= True query = st.text_input("Enter your query") button = st.button("Submit") # write code to get the output based on given query and data sources if button and url: with st.spinner("Updating the database..."): corpusData = scrape_text(url) encodeaddData(corpusData,url=url,pdf=False) st.success("Database Updated") with st.spinner("Finding an answer..."): title, res = find_k_best_match(query,2) context = "nn".join(res) st.expander("Context").write(context) prompt = qanda.prompt(context,query) answer = qanda.get_answer(prompt) st.success("Answer: "+ answer) # write a code to get output on given query and data sources
if button and pdf: with st.spinner("Updating the database..."): corpusData = pdf_text(pdf=pdf) encodeaddData(corpusData,pdf=pdf,url=False) st.success("Database Updated") with st.spinner("Finding an answer..."): title, res = find_k_best_match(query,2) context = "nn".join(res) st.expander("Context").write(context) prompt = qanda.prompt(context,query) answer = qanda.get_answer(prompt) st.success("Answer: "+ answer) if button and data: with st.spinner("Finding an answer..."): title, res = find_k_best_match(query,2) context = "nn".join(res) st.expander("Context").write(context) prompt = qanda.prompt(context,query) answer = qanda.get_answer(prompt) st.success("Answer: "+ answer) # delete the vectors from the database
st.expander("Delete the indexes from the database")
button1 = st.button("Delete the current vectors")
if button1 == True: index.delete(deleteAll='true')Để kiểm tra các tệp mã khác, vui lòng truy cập kho lưu trữ GitHub của dự án. (Liên kết: Bấm vào đây)
Triển khai ứng dụng Q&A trên Streamlit Cloud
Streamlit cung cấp một đám mây cộng đồng để lưu trữ các ứng dụng miễn phí. Hơn nữa, streamlit rất dễ sử dụng nhờ các tính năng đường dẫn CI/CD tự động của nó. Để tìm hiểu thêm về streamlit để xây dựng ứng dụng — Vui lòng truy cập bài viết trước của tôi, tôi đã viết trên Analytics Vidya (Liên kết: Bấm vào đây)
Các trường hợp sử dụng trong ngành của Ứng dụng Hỏi & Đáp tùy chỉnh
Áp dụng các ứng dụng trả lời câu hỏi tùy chỉnh trong nhiều ngành khi các trường hợp sử dụng mới và sáng tạo xuất hiện trong lĩnh vực này. Hãy xem xét các trường hợp sử dụng như vậy:
Hỗ trợ khách hàng
Cuộc cách mạng hỗ trợ khách hàng đã bắt đầu với sự gia tăng của LLM. Cho dù đó là ngành Thương mại điện tử, viễn thông hay Tài chính, bot dịch vụ khách hàng được phát triển trên tài liệu của công ty có thể giúp khách hàng đưa ra quyết định nhanh hơn và sáng suốt hơn, dẫn đến tăng doanh thu.
Ngành chăm sóc sức khỏe
Thông tin này rất quan trọng để bệnh nhân có hướng điều trị kịp thời đối với một số bệnh. Các công ty chăm sóc sức khỏe có thể phát triển một chatbot tương tác để cung cấp thông tin y tế, thông tin về thuốc, giải thích triệu chứng và hướng dẫn điều trị bằng ngôn ngữ tự nhiên mà không cần người thực.
Ngành pháp lý
Các luật sư xử lý một lượng lớn thông tin và tài liệu pháp lý để giải quyết các vụ kiện của tòa án. Các ứng dụng LLM tùy chỉnh được phát triển bằng cách sử dụng lượng dữ liệu lớn như vậy có thể giúp các luật sư làm việc hiệu quả hơn và giải quyết các vụ việc nhanh hơn nhiều.
Ngành công nghệ
Trường hợp sử dụng thay đổi trò chơi lớn nhất của các ứng dụng Hỏi & Đáp là hỗ trợ lập trình. các công ty công nghệ có thể xây dựng các ứng dụng như vậy trên cơ sở mã nội bộ của họ để giúp các lập trình viên giải quyết vấn đề, hiểu cú pháp mã, sửa lỗi và triển khai các chức năng cụ thể.
Chính phủ và dịch vụ công cộng
Các chính sách và kế hoạch của chính phủ chứa lượng thông tin khổng lồ có thể khiến nhiều người choáng ngợp. Công dân có thể nhận thông tin về các chương trình và quy định của chính phủ bằng cách phát triển các ứng dụng tùy chỉnh cho các dịch vụ của chính phủ đó. Nó cũng có thể giúp điền vào các biểu mẫu và ứng dụng của chính phủ một cách chính xác.
Kết luận
Tóm lại, chúng tôi đã khám phá những khả năng thú vị của việc xây dựng một ứng dụng trả lời câu hỏi tùy chỉnh bằng LangChain và cơ sở dữ liệu vectơ Pinecone. Blog này đã đưa chúng ta đi qua các khái niệm cơ bản, từ tổng quan về ứng dụng trả lời câu hỏi đến hiểu các khả năng của cơ sở dữ liệu vectơ Pinecone. Kết hợp sức mạnh của đường dẫn tìm kiếm ngữ nghĩa của OpenAI với hệ thống truy xuất và lập chỉ mục hiệu quả của Pinecone, chúng tôi đã khai thác tiềm năng để tạo ra một giải pháp trả lời câu hỏi mạnh mẽ và chính xác với streamlit. chúng ta hãy xem xét những điểm chính từ bài viết:
Chìa khóa chính
- Các mô hình ngôn ngữ lớn (LLM) đã cách mạng hóa AI, cho phép các ứng dụng đa dạng. Tùy chỉnh chatbot với dữ liệu cá nhân hoặc tổ chức là một cách tiếp cận hiệu quả.
- Mặc dù các LLM chung mang lại sự hiểu biết rộng rãi về ngôn ngữ, nhưng các ứng dụng trả lời câu hỏi phù hợp mang lại lợi thế khác biệt so với các LLM được cá nhân hóa tinh chỉnh do tính linh hoạt và hiệu quả chi phí của chúng.
- Bằng cách kết hợp cơ sở dữ liệu vectơ Pinecone, OpenAI LLM và LangChain, chúng tôi đã học cách phát triển một quy trình tìm kiếm ngữ nghĩa và triển khai nó trên nền tảng dựa trên đám mây như streamlit.
Những câu hỏi thường gặp
Trả lời: Pinecone là cơ sở dữ liệu vectơ bộ nhớ dài hạn có thể mở rộng để lưu trữ các phần nhúng văn bản cho các ứng dụng hỗ trợ LLM, trong khi LangChain là một khung cho phép các nhà phát triển xây dựng các ứng dụng hỗ trợ LLM.
Đ: Sử dụng các ứng dụng Trả lời câu hỏi trong chatbot hỗ trợ khách hàng, nghiên cứu học thuật, e-Learning, v.v.
Trả lời: LangChain cho phép các nhà phát triển sử dụng các thành phần khác nhau để tích hợp các LLM này theo cách thân thiện với nhà phát triển nhất có thể, do đó vận chuyển sản phẩm nhanh hơn.
Trả lời: Các bước để xây dựng ứng dụng Hỏi & Đáp là Tải tài liệu, bộ tách văn bản, lưu trữ véc-tơ, truy xuất và xuất mô hình.
Trả lời: LangChain có các công cụ sau: Trình tải tài liệu, Trình biến đổi tài liệu, Cửa hàng vectơ, Chuỗi, Bộ nhớ và Tác nhân.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- ChartPrime. Nâng cao trò chơi giao dịch của bạn với ChartPrime. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/08/qa-applications/

