Mở khóa các câu trả lời chính xác và sâu sắc từ số lượng lớn văn bản là một khả năng thú vị được kích hoạt bởi các mô hình ngôn ngữ lớn (LLM). Khi xây dựng các ứng dụng LLM, thường cần kết nối và truy vấn các nguồn dữ liệu bên ngoài để cung cấp bối cảnh phù hợp cho mô hình. Một cách tiếp cận phổ biến là sử dụng Thế hệ tăng cường truy xuất (RAG) để tạo các hệ thống Hỏi & Đáp có khả năng hiểu thông tin phức tạp và cung cấp phản hồi tự nhiên cho các truy vấn. RAG cho phép các mô hình khai thác cơ sở kiến thức rộng lớn và cung cấp cuộc đối thoại giống con người cho các ứng dụng như chatbot và trợ lý tìm kiếm doanh nghiệp.
Trong bài đăng này, chúng ta khám phá cách khai thác sức mạnh của Llama Index, Llama 2-70B-Trò chuyệnvà LangChain để xây dựng các ứng dụng Hỏi & Đáp mạnh mẽ. Với những công nghệ tiên tiến này, bạn có thể nhập nội dung văn bản, lập chỉ mục kiến thức quan trọng và tạo văn bản trả lời câu hỏi của người dùng một cách chính xác và rõ ràng.
Llama 2-70B-Trò chuyện
Llama 2-70B-Chat là một LLM mạnh mẽ cạnh tranh với các mô hình hàng đầu. Nó được đào tạo trước trên hai nghìn tỷ mã thông báo văn bản và được Meta dự định sử dụng để hỗ trợ trò chuyện cho người dùng. Dữ liệu trước khi đào tạo được lấy từ dữ liệu có sẵn công khai và kết thúc vào tháng 2022 năm 2023, còn dữ liệu tinh chỉnh kết thúc vào tháng XNUMX năm XNUMX. Để biết thêm chi tiết về quy trình đào tạo của mô hình, các cân nhắc về an toàn, nội dung học tập và mục đích sử dụng, hãy tham khảo bài viết Llama 2: Nền tảng mở và các mô hình trò chuyện được tinh chỉnh. Mẫu Llama 2 đã có sẵn Khởi động Amazon SageMaker để triển khai nhanh chóng và đơn giản.
Llama Index
Llama Index là một khung dữ liệu cho phép xây dựng các ứng dụng LLM. Nó cung cấp các công cụ cung cấp trình kết nối dữ liệu để nhập dữ liệu hiện có của bạn với nhiều nguồn và định dạng khác nhau (PDF, tài liệu, API, SQL, v.v.). Cho dù bạn có dữ liệu được lưu trữ trong cơ sở dữ liệu hay dưới dạng PDF, LlamaIndex sẽ giúp bạn dễ dàng đưa dữ liệu đó vào sử dụng cho LLM. Như chúng tôi đã trình bày trong bài đăng này, API LlamaIndex giúp việc truy cập dữ liệu trở nên dễ dàng và cho phép bạn tạo các ứng dụng và quy trình làm việc LLM tùy chỉnh mạnh mẽ.
Nếu bạn đang thử nghiệm và xây dựng LLM, bạn có thể quen thuộc với LangChain, cung cấp một khuôn khổ mạnh mẽ, đơn giản hóa việc phát triển và triển khai các ứng dụng hỗ trợ LLM. Tương tự như LangChain, LlamaIndex cung cấp một số công cụ, bao gồm trình kết nối dữ liệu, chỉ mục dữ liệu, công cụ và tác nhân dữ liệu, cũng như tích hợp ứng dụng như công cụ và khả năng quan sát, truy tìm và đánh giá. LlamaIndex tập trung vào việc thu hẹp khoảng cách giữa dữ liệu và LLM mạnh mẽ, hợp lý hóa các tác vụ dữ liệu bằng các tính năng thân thiện với người dùng. LlamaIndex được thiết kế và tối ưu hóa đặc biệt để xây dựng các ứng dụng tìm kiếm và truy xuất, chẳng hạn như RAG, vì nó cung cấp giao diện đơn giản để truy vấn LLM và truy xuất các tài liệu liên quan.
Tổng quan về giải pháp
Trong bài đăng này, chúng tôi trình bày cách tạo ứng dụng dựa trên RAG bằng cách sử dụng LlamaIndex và LLM. Sơ đồ sau đây thể hiện kiến trúc từng bước của giải pháp này được nêu trong các phần sau.
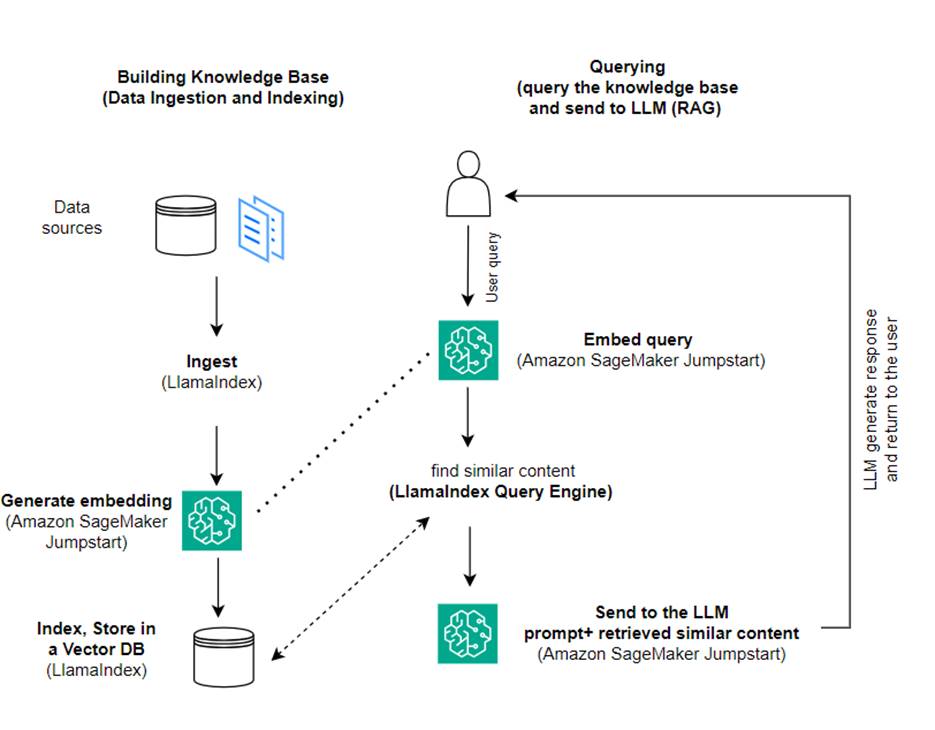
RAG kết hợp việc truy xuất thông tin với việc tạo ngôn ngữ tự nhiên để tạo ra những phản hồi sâu sắc hơn. Khi được nhắc, trước tiên RAG sẽ tìm kiếm kho văn bản để truy xuất các ví dụ phù hợp nhất cho đầu vào. Trong quá trình tạo phản hồi, mô hình xem xét các ví dụ này để tăng cường khả năng của nó. Bằng cách kết hợp các đoạn văn được truy xuất có liên quan, phản hồi RAG có xu hướng thực tế hơn, mạch lạc hơn và phù hợp với bối cảnh hơn so với các mô hình tổng quát cơ bản. Khung truy xuất-tạo này tận dụng các điểm mạnh của cả truy xuất và tạo, giúp giải quyết các vấn đề như sự lặp lại và thiếu ngữ cảnh có thể phát sinh từ các mô hình hội thoại tự hồi quy thuần túy. RAG giới thiệu một cách tiếp cận hiệu quả để xây dựng các tác nhân đàm thoại và trợ lý AI với các phản hồi chất lượng cao, phù hợp với ngữ cảnh.
Việc xây dựng giải pháp bao gồm các bước sau:
- Thiết lập Xưởng sản xuất Amazon SageMaker làm môi trường phát triển và cài đặt các phụ thuộc cần thiết.
- Triển khai mô hình nhúng từ trung tâm JumpStart của Amazon SageMaker.
- Tải xuống các thông cáo báo chí để sử dụng làm cơ sở kiến thức bên ngoài của chúng tôi.
- Xây dựng chỉ mục từ các thông cáo báo chí để có thể truy vấn và thêm ngữ cảnh bổ sung vào lời nhắc.
- Truy vấn cơ sở kiến thức.
- Xây dựng ứng dụng Hỏi đáp bằng cách sử dụng tác nhân LlamaIndex và LangChain.
Tất cả mã trong bài đăng này đều có sẵn trong Repo GitHub.
Điều kiện tiên quyết
Đối với ví dụ này, bạn cần có tài khoản AWS có miền SageMaker và Quản lý truy cập và nhận dạng AWS (IAM) quyền. Để biết hướng dẫn thiết lập tài khoản, hãy xem Tạo tài khoản AWS. Nếu bạn chưa có miền SageMaker, hãy tham khảo Miền Amazon SageMaker tổng quan để tạo một. Trong bài đăng này, chúng tôi sử dụng AmazonSageMakerTruy cập đầy đủ vai trò. Bạn không nên sử dụng thông tin xác thực này trong môi trường sản xuất. Thay vào đó, bạn nên tạo và sử dụng vai trò có quyền có ít đặc quyền nhất. Bạn cũng có thể khám phá cách bạn có thể sử dụng Trình quản lý vai trò Amazon SageMaker để xây dựng và quản lý các vai trò IAM dựa trên cá nhân cho các nhu cầu học máy phổ biến trực tiếp thông qua bảng điều khiển SageMaker.
Ngoài ra, bạn cần có quyền truy cập vào tối thiểu các kích thước phiên bản sau:
- ml.g5.2xlarge để sử dụng điểm cuối khi triển khai Ôm Mặt GPT-J mô hình nhúng văn bản
- ml.g5.48xlarge để sử dụng điểm cuối khi triển khai điểm cuối mô hình Llama 2-Chat
Để tăng hạn ngạch của bạn, hãy tham khảo Yêu cầu tăng hạn ngạch.
Triển khai mô hình nhúng GPT-J bằng SageMaker JumpStart
Phần này cung cấp cho bạn hai tùy chọn khi triển khai mô hình SageMaker JumpStart. Bạn có thể sử dụng triển khai dựa trên mã bằng cách sử dụng mã được cung cấp hoặc sử dụng giao diện người dùng (UI) của SageMaker JumpStart.
Triển khai bằng SDK Python của SageMaker
Bạn có thể sử dụng SageMaker Python SDK để triển khai LLM, như minh họa trong mã có sẵn trong kho lưu trữ. Hoàn thành các bước sau:
- Đặt kích thước phiên bản sẽ được sử dụng để triển khai mô hình nhúng bằng cách sử dụng
instance_type = "ml.g5.2xlarge" - Xác định vị trí ID mà mô hình sẽ sử dụng để nhúng. Trong SageMaker JumpStart, nó được xác định là
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Truy xuất vùng chứa mô hình được đào tạo trước và triển khai nó để suy luận.
SageMaker sẽ trả về tên của điểm cuối mô hình và thông báo sau khi mô hình nhúng đã được triển khai thành công:
Triển khai với SageMaker JumpStart trong SageMaker Studio
Để triển khai mô hình bằng SageMaker JumpStart trong Studio, hãy hoàn thành các bước sau:
- Trên bảng điều khiển SageMaker Studio, chọn JumpStart trong ngăn điều hướng.

- Tìm kiếm và chọn mẫu GPT-J 6B Embedding FP16.
- Chọn Triển khai và tùy chỉnh cấu hình triển khai.

- Đối với ví dụ này, chúng ta cần một phiên bản ml.g5.2xlarge, đây là phiên bản mặc định được SageMaker JumpStart đề xuất.
- Chọn Triển khai lại để tạo điểm cuối.
Điểm cuối sẽ mất khoảng 5–10 phút để đi vào hoạt động.

Sau khi triển khai mô hình nhúng, để sử dụng tính năng tích hợp LangChain với API SageMaker, bạn cần tạo một hàm để xử lý dữ liệu đầu vào (văn bản thô) và chuyển đổi chúng thành nội dung nhúng bằng mô hình. Bạn làm điều này bằng cách tạo một lớp có tên ContentHandler, lấy JSON của dữ liệu đầu vào và trả về JSON chứa văn bản nhúng: class ContentHandler(EmbeddingsContentHandler).
Truyền tên điểm cuối của mô hình cho ContentHandler chức năng chuyển đổi văn bản và trả về các phần nhúng:
Bạn có thể định vị tên điểm cuối trong đầu ra của SDK hoặc trong chi tiết triển khai trong giao diện người dùng SageMaker JumpStart.
Bạn có thể kiểm tra xem ContentHandler và điểm cuối đang hoạt động như mong đợi bằng cách nhập một số văn bản thô và chạy embeddings.embed_query(text) chức năng. Bạn có thể sử dụng ví dụ được cung cấp text = "Hi! It's time for the beach" hoặc thử văn bản của riêng bạn.
Triển khai và thử nghiệm Llama 2-Chat bằng SageMaker JumpStart
Bây giờ bạn có thể triển khai mô hình có khả năng trò chuyện tương tác với người dùng của mình. Trong trường hợp này, chúng tôi chọn một trong các mô hình trò chuyện 2 Llama, được xác định thông qua
Mô hình cần được triển khai đến điểm cuối thời gian thực bằng cách sử dụng predictor = my_model.deploy(). SageMaker sẽ trả về tên điểm cuối của mô hình mà bạn có thể sử dụng cho endpoint_name biến để tham khảo sau này.
Bạn xác định một print_dialogue chức năng gửi đầu vào đến mô hình trò chuyện và nhận phản hồi đầu ra của nó. Tải trọng bao gồm các siêu tham số cho mô hình, bao gồm:
- max_new_tokens – Đề cập đến số lượng mã thông báo tối đa mà mô hình có thể tạo trong đầu ra của nó.
- đầu_p – Đề cập đến xác suất tích lũy của các mã thông báo có thể được mô hình giữ lại khi tạo đầu ra của nó
- nhiệt độ – Đề cập đến tính ngẫu nhiên của các đầu ra do mô hình tạo ra. Nhiệt độ lớn hơn 0 hoặc bằng 1 sẽ làm tăng mức độ ngẫu nhiên, trong khi nhiệt độ bằng 0 sẽ tạo ra các mã thông báo có nhiều khả năng nhất.
Bạn nên chọn siêu tham số dựa trên trường hợp sử dụng của mình và kiểm tra chúng một cách thích hợp. Các mô hình như dòng Llama yêu cầu bạn đưa vào một tham số bổ sung cho biết rằng bạn đã đọc và chấp nhận Thỏa thuận cấp phép người dùng cuối (EULA):
Để kiểm tra mô hình, hãy thay thế phần nội dung của tải trọng đầu vào: "content": "what is the recipe of mayonnaise?". Bạn có thể sử dụng các giá trị văn bản của riêng mình và cập nhật các siêu tham số để hiểu chúng rõ hơn.
Tương tự như việc triển khai mô hình nhúng, bạn có thể triển khai Llama-70B-Chat bằng giao diện người dùng SageMaker JumpStart:
- Trên bảng điều khiển SageMaker Studio, chọn Khởi động trong ngăn điều hướng
- Tìm kiếm và chọn
Llama-2-70b-Chat model - Chấp nhận EULA và chọn Triển khai, sử dụng lại phiên bản mặc định
Tương tự như mô hình nhúng, bạn có thể sử dụng tích hợp LangChain bằng cách tạo mẫu xử lý nội dung cho đầu vào và đầu ra của mô hình trò chuyện của mình. Trong trường hợp này, bạn xác định đầu vào là những đầu vào đến từ người dùng và cho biết rằng chúng bị chi phối bởi system prompt. Các system prompt thông báo cho mô hình về vai trò của nó trong việc hỗ trợ người dùng trong một trường hợp sử dụng cụ thể.
Sau đó, trình xử lý nội dung này sẽ được chuyển khi gọi mô hình, bên cạnh các siêu tham số và thuộc tính tùy chỉnh đã nói ở trên (chấp nhận EULA). Bạn phân tích tất cả các thuộc tính này bằng mã sau:
Khi điểm cuối có sẵn, bạn có thể kiểm tra xem nó có hoạt động như mong đợi hay không. Bạn có thể cập nhật llm("what is amazon sagemaker?") bằng văn bản của riêng bạn. Bạn cũng cần phải xác định cụ thể ContentHandler để gọi LLM bằng LangChain, như được hiển thị trong mã và đoạn mã sau:
Sử dụng LlamaIndex để xây dựng RAG
Để tiếp tục, hãy cài đặt LlamaIndex để tạo ứng dụng RAG. Bạn có thể cài đặt LlamaIndex bằng pip: pip install llama_index
Trước tiên, bạn cần tải dữ liệu (cơ sở kiến thức) của mình lên LlamaIndex để lập chỉ mục. Điều này bao gồm một số bước:
- Chọn trình tải dữ liệu:
LlamaIndex cung cấp một số trình kết nối dữ liệu có sẵn trên LlamaHub dành cho các loại dữ liệu phổ biến như JSON, CSV và tệp văn bản cũng như các nguồn dữ liệu khác, cho phép bạn nhập nhiều loại tập dữ liệu. Trong bài đăng này, chúng tôi sử dụng SimpleDirectoryReader để nhập một vài tệp PDF như được hiển thị trong mã. Mẫu dữ liệu của chúng tôi là hai thông cáo báo chí của Amazon ở dạng PDF ở thông cáo báo chí thư mục trong kho lưu trữ mã của chúng tôi. Sau khi tải các tệp PDF, bạn có thể thấy rằng chúng đã được chuyển đổi thành danh sách gồm 11 thành phần.
Thay vì tải tài liệu trực tiếp, bạn cũng có thể bí mật tải Document đối tượng vào Node đối tượng trước khi gửi chúng tới chỉ mục. Sự lựa chọn giữa việc gửi toàn bộ Document phản đối chỉ mục hoặc chuyển đổi Tài liệu thành Node đối tượng trước khi lập chỉ mục tùy thuộc vào trường hợp sử dụng cụ thể và cấu trúc dữ liệu của bạn. Cách tiếp cận nút nói chung là một lựa chọn tốt cho các tài liệu dài, nơi bạn muốn ngắt và truy xuất các phần cụ thể của tài liệu thay vì toàn bộ tài liệu. Để biết thêm thông tin, hãy tham khảo Tài liệu / Nút.
- Khởi tạo trình tải và tải tài liệu:
Bước này khởi tạo lớp trình tải và mọi cấu hình cần thiết, chẳng hạn như có bỏ qua các tệp ẩn hay không. Để biết thêm chi tiết, hãy tham khảo SimpleDirectoryReader.
- Gọi cho người tải
load_dataphương pháp phân tích các tệp và dữ liệu nguồn của bạn và chuyển đổi chúng thành các đối tượng Tài liệu LlamaIndex, sẵn sàng để lập chỉ mục và truy vấn. Bạn có thể sử dụng mã sau để hoàn tất quá trình nhập dữ liệu và chuẩn bị cho tìm kiếm toàn văn bản bằng khả năng lập chỉ mục và truy xuất của LlamaIndex:
- Xây dựng chỉ số:
Tính năng chính của LlamaIndex là khả năng xây dựng các chỉ mục có tổ chức trên dữ liệu, được biểu diễn dưới dạng tài liệu hoặc nút. Việc lập chỉ mục tạo điều kiện cho việc truy vấn dữ liệu hiệu quả. Chúng tôi tạo chỉ mục của mình bằng kho lưu trữ vectơ trong bộ nhớ mặc định và với cấu hình cài đặt đã xác định của chúng tôi. Chỉ số Llama Cài đặt là một đối tượng cấu hình cung cấp các tài nguyên và cài đặt thường được sử dụng cho các hoạt động lập chỉ mục và truy vấn trong ứng dụng LlamaIndex. Nó hoạt động như một đối tượng đơn lẻ, do đó nó cho phép bạn đặt cấu hình chung, đồng thời cho phép bạn ghi đè cục bộ các thành phần cụ thể bằng cách chuyển chúng trực tiếp vào các giao diện (chẳng hạn như LLM, mô hình nhúng) sử dụng chúng. Khi một thành phần cụ thể không được cung cấp rõ ràng, khung LlamaIndex sẽ quay trở lại các cài đặt được xác định trong Settings object làm mặc định chung. Để sử dụng các mô hình nhúng và LLM của chúng tôi với LangChain và định cấu hình Settings chúng ta cần cài đặt llama_index.embeddings.langchain và llama_index.llms.langchain. Chúng ta có thể cấu hình Settings đối tượng như trong đoạn mã sau:
Theo mặc định, VectorStoreIndex sử dụng bộ nhớ trong SimpleVectorStore được khởi tạo như một phần của bối cảnh lưu trữ mặc định. Trong các trường hợp sử dụng thực tế, bạn thường cần kết nối với các kho vectơ bên ngoài như Dịch vụ Tìm kiếm Mở của Amazon. Để biết thêm chi tiết, hãy tham khảo Công cụ Vector cho Amazon OpenSearch Serverless.
Bây giờ bạn có thể chạy Hỏi & Đáp trên tài liệu của mình bằng cách sử dụng công cụ truy vấn từ Llama Index. Để làm như vậy, hãy chuyển chỉ mục bạn đã tạo trước đó cho các truy vấn và đặt câu hỏi của bạn. Công cụ truy vấn là một giao diện chung để truy vấn dữ liệu. Nó lấy một truy vấn ngôn ngữ tự nhiên làm đầu vào và trả về một phản hồi phong phú. Công cụ truy vấn thường được xây dựng dựa trên một hoặc nhiều chỉ số sử dụng chó săn.
Bạn có thể thấy rằng giải pháp RAG có thể truy xuất câu trả lời đúng từ các tài liệu được cung cấp:
Sử dụng các công cụ và tác nhân LangChain
Loader lớp học. Trình tải được thiết kế để tải dữ liệu vào LlamaIndex hoặc sau đó dưới dạng một công cụ trong Đại lý LangChain. Điều này mang lại cho bạn nhiều sức mạnh và tính linh hoạt hơn để sử dụng nó như một phần của ứng dụng của bạn. Bạn bắt đầu bằng cách xác định công cụ từ lớp đại lý LangChain. Hàm mà bạn chuyển cho công cụ của mình truy vấn chỉ mục bạn đã tạo trên tài liệu của mình bằng cách sử dụng LlamaIndex.
Sau đó, bạn chọn đúng loại tác nhân mà bạn muốn sử dụng để triển khai RAG của mình. Trong trường hợp này, bạn sử dụng chat-zero-shot-react-description đại lý. Với tác nhân này, LLM sẽ sử dụng công cụ có sẵn (trong kịch bản này là RAG trên cơ sở kiến thức) để cung cấp phản hồi. Sau đó, bạn khởi tạo tác nhân bằng cách chuyển công cụ, LLM và loại tác nhân của mình:
Bạn có thể thấy đại lý đi qua thoughts, actionsvà observation , hãy sử dụng công cụ này (trong trường hợp này là truy vấn các tài liệu được lập chỉ mục của bạn); và trả về một kết quả:
Bạn có thể tìm thấy mã triển khai end-to-end trong tài liệu đi kèm Repo GitHub.
Làm sạch
Để tránh những chi phí không cần thiết, bạn có thể dọn sạch tài nguyên của mình thông qua các đoạn mã sau hoặc Giao diện người dùng Amazon JumpStart.
Để sử dụng Boto3 SDK, hãy sử dụng mã sau để xóa điểm cuối của mô hình nhúng văn bản và điểm cuối của mô hình tạo văn bản cũng như các cấu hình điểm cuối:
Để sử dụng bảng điều khiển SageMaker, hãy hoàn thành các bước sau:
- Trên bảng điều khiển SageMaker, trong Suy luận trong ngăn điều hướng, chọn Điểm cuối
- Tìm kiếm điểm cuối nhúng và tạo văn bản.
- Trên trang chi tiết điểm cuối, chọn Xóa.
- Chọn Xóa lần nữa để xác nhận.
Kết luận
Đối với các trường hợp sử dụng tập trung vào tìm kiếm và truy xuất, LlamaIndex cung cấp các khả năng linh hoạt. Nó vượt trội trong việc lập chỉ mục và truy xuất LLM, khiến nó trở thành một công cụ mạnh mẽ để khám phá sâu dữ liệu. LlamaIndex cho phép bạn tạo các chỉ mục dữ liệu có tổ chức, sử dụng LLM đa dạng, tăng cường dữ liệu để có hiệu suất LLM tốt hơn và truy vấn dữ liệu bằng ngôn ngữ tự nhiên.
Bài đăng này trình bày một số khái niệm và khả năng chính của LlamaIndex. Chúng tôi đã sử dụng GPT-J để nhúng và Llama 2-Chat làm LLM để xây dựng ứng dụng RAG nhưng thay vào đó, bạn có thể sử dụng bất kỳ mô hình phù hợp nào. Bạn có thể khám phá toàn bộ các mô hình có sẵn trên SageMaker JumpStart.
Chúng tôi cũng cho thấy cách LlamaIndex có thể cung cấp các công cụ mạnh mẽ, linh hoạt để kết nối, lập chỉ mục, truy xuất và tích hợp dữ liệu với các khung khác như LangChain. Với tích hợp LlamaIndex và LangChain, bạn có thể xây dựng các ứng dụng LLM mạnh mẽ, linh hoạt và sâu sắc hơn.
Về các tác giả
 Tiến sĩ Romina Sharifpour là Kiến trúc sư giải pháp trí tuệ nhân tạo và học máy cao cấp tại Amazon Web Services (AWS). Cô đã dành hơn 10 năm lãnh đạo việc thiết kế và triển khai các giải pháp sáng tạo toàn diện được hỗ trợ bởi những tiến bộ trong ML và AI. Lĩnh vực quan tâm của Romina là xử lý ngôn ngữ tự nhiên, mô hình ngôn ngữ lớn và MLOps.
Tiến sĩ Romina Sharifpour là Kiến trúc sư giải pháp trí tuệ nhân tạo và học máy cao cấp tại Amazon Web Services (AWS). Cô đã dành hơn 10 năm lãnh đạo việc thiết kế và triển khai các giải pháp sáng tạo toàn diện được hỗ trợ bởi những tiến bộ trong ML và AI. Lĩnh vực quan tâm của Romina là xử lý ngôn ngữ tự nhiên, mô hình ngôn ngữ lớn và MLOps.
 Nicole Pinto là Kiến trúc sư Giải pháp Chuyên gia AI/ML có trụ sở tại Sydney, Australia. Nền tảng về chăm sóc sức khỏe và dịch vụ tài chính mang đến cho cô một góc nhìn độc đáo trong việc giải quyết các vấn đề của khách hàng. Cô đam mê hỗ trợ khách hàng thông qua học máy và trao quyền cho thế hệ phụ nữ tiếp theo trong lĩnh vực STEM.
Nicole Pinto là Kiến trúc sư Giải pháp Chuyên gia AI/ML có trụ sở tại Sydney, Australia. Nền tảng về chăm sóc sức khỏe và dịch vụ tài chính mang đến cho cô một góc nhìn độc đáo trong việc giải quyết các vấn đề của khách hàng. Cô đam mê hỗ trợ khách hàng thông qua học máy và trao quyền cho thế hệ phụ nữ tiếp theo trong lĩnh vực STEM.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

