Khi chạy các ứng dụng Apache Flink trên Dịch vụ được quản lý của Amazon dành cho Apache Flink, bạn có lợi ích duy nhất là tận dụng tính chất không có máy chủ của nó. Điều này có nghĩa là các hoạt động tối ưu hóa chi phí có thể diễn ra bất kỳ lúc nào—chúng không cần phải diễn ra trong giai đoạn lập kế hoạch nữa. Với Dịch vụ được quản lý dành cho Apache Flink, bạn có thể thêm và xóa điện toán chỉ bằng một nút bấm.
Apache Flink là một khung xử lý luồng nguồn mở được hàng trăm công ty sử dụng trong các ứng dụng kinh doanh quan trọng và bởi hàng nghìn nhà phát triển có nhu cầu xử lý luồng cho khối lượng công việc của họ. Nó có tính sẵn sàng cao và có khả năng mở rộng, cung cấp thông lượng cao và độ trễ thấp cho các ứng dụng xử lý luồng có yêu cầu khắt khe nhất. Các thuộc tính có thể mở rộng này của Apache Flink có thể là chìa khóa để tối ưu hóa chi phí của bạn trên đám mây.
Dịch vụ được quản lý dành cho Apache Flink là dịch vụ được quản lý hoàn toàn giúp giảm độ phức tạp của việc xây dựng và quản lý các ứng dụng Apache Flink. Dịch vụ được quản lý dành cho Apache Flink quản lý cơ sở hạ tầng cơ bản và các thành phần Apache Flink cung cấp trạng thái ứng dụng, số liệu, nhật ký bền vững, v.v.
Trong bài đăng này, bạn có thể tìm hiểu về mô hình chi phí Dịch vụ được quản lý cho Apache Flink, các lĩnh vực cần tiết kiệm chi phí trong các ứng dụng Apache Flink của bạn và hiểu rõ hơn về tổng thể các quy trình xử lý dữ liệu của bạn. Chúng tôi đi sâu vào tìm hiểu chi phí của bạn, hiểu xem ứng dụng của bạn có được cung cấp quá mức hay không, cách suy nghĩ về việc mở rộng quy mô tự động và các cách tối ưu hóa ứng dụng Apache Flink của bạn để tiết kiệm chi phí. Cuối cùng, chúng tôi đặt những câu hỏi quan trọng về khối lượng công việc của bạn để xác định xem Apache Flink có phải là công nghệ phù hợp cho trường hợp sử dụng của bạn hay không.
Cách tính chi phí trên Dịch vụ được quản lý cho Apache Flink
Để tối ưu hóa chi phí liên quan đến Dịch vụ được quản lý cho ứng dụng Apache Flink của bạn, bạn có thể biết rõ những gì sẽ tính vào giá cho dịch vụ được quản lý.
Dịch vụ được quản lý dành cho các ứng dụng Apache Flink bao gồm Đơn vị xử lý Kinesis (KPU), là các phiên bản điện toán bao gồm 1 CPU ảo và 4 GB bộ nhớ. Tổng số KPU được gán cho ứng dụng được xác định bằng cách nhân hai tham số mà bạn điều khiển trực tiếp:
- Song song – Mức độ xử lý song song trong ứng dụng Apache Flink
- Tính song song trên mỗi KPU – Số lượng tài nguyên dành riêng cho mỗi song song
Số lượng KPU được xác định theo công thức đơn giản: KPU = Parallelism / ParallelismPerKPU, làm tròn đến số nguyên tiếp theo.
KPU bổ sung cho mỗi ứng dụng cũng được tính phí cho việc điều phối và không được sử dụng trực tiếp để xử lý dữ liệu.
Tổng số KPU xác định số lượng tài nguyên, CPU, bộ nhớ và bộ nhớ ứng dụng được phân bổ cho ứng dụng. Đối với mỗi KPU, ứng dụng nhận được 1 vCPU và 4 GB bộ nhớ, trong đó 3 GB được phân bổ mặc định cho ứng dụng đang chạy và 1 GB còn lại được sử dụng để quản lý cửa hàng trạng thái ứng dụng. Mỗi KPU cũng đi kèm với 50 GB dung lượng lưu trữ kèm theo ứng dụng. Apache Flink duy trì trạng thái ứng dụng trong bộ nhớ ở giới hạn có thể định cấu hình và lan sang bộ lưu trữ đính kèm.
Thành phần chi phí thứ ba là sao lưu ứng dụng lâu bền, hoặc snapshots. Điều này hoàn toàn không bắt buộc và tác động của nó lên tổng chi phí là nhỏ, trừ khi bạn giữ lại một số lượng ảnh chụp nhanh rất lớn.
Tại thời điểm viết bài, mỗi KPU ở Khu vực AWS Miền Đông Hoa Kỳ (Ohio) có giá 0.11 USD mỗi giờ và dung lượng lưu trữ ứng dụng kèm theo có giá 0.10 USD mỗi GB mỗi tháng. Chi phí sao lưu ứng dụng lâu bền (ảnh chụp nhanh) là 0.023 USD mỗi GB mỗi tháng. tham khảo Dịch vụ được quản lý của Amazon để định giá Apache Flink để biết giá cập nhật và các khu vực khác nhau.
Sơ đồ sau minh họa tỷ lệ tương đối của các thành phần chi phí cho một ứng dụng đang chạy trên Dịch vụ được quản lý cho Apache Flink. Bạn kiểm soát số lượng KPU thông qua tính song song và song song trên mỗi tham số KPU. Lưu trữ sao lưu ứng dụng bền vững không được đại diện.
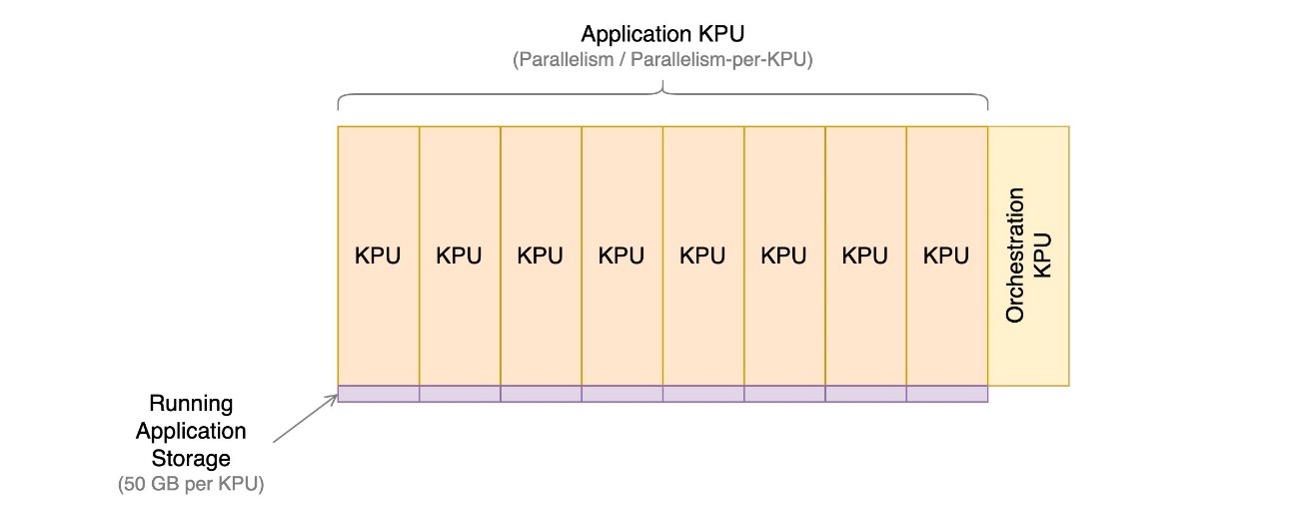
Trong các phần sau, chúng tôi sẽ xem xét cách giám sát chi phí, tối ưu hóa việc sử dụng tài nguyên ứng dụng và tìm số lượng KPU cần thiết để xử lý hồ sơ thông lượng của bạn.
AWS Cost Explorer và tìm hiểu hóa đơn của bạn
Để xem Dịch vụ được quản lý hiện tại của bạn dành cho chi tiêu Apache Flink là gì, bạn có thể sử dụng Trình khám phá chi phí AWS.
Trên bảng điều khiển Cost Explorer, bạn có thể lọc theo phạm vi ngày, loại sử dụng và dịch vụ để tách riêng chi tiêu của mình cho Dịch vụ được quản lý cho các ứng dụng Apache Flink. Ảnh chụp màn hình sau đây hiển thị chi phí trong 12 tháng qua được chia thành các loại giá được mô tả trong phần trước. Phần lớn chi tiêu trong nhiều tháng này là từ KPU tương tác từ Dịch vụ được quản lý của Amazon dành cho Apache Flink Studio.
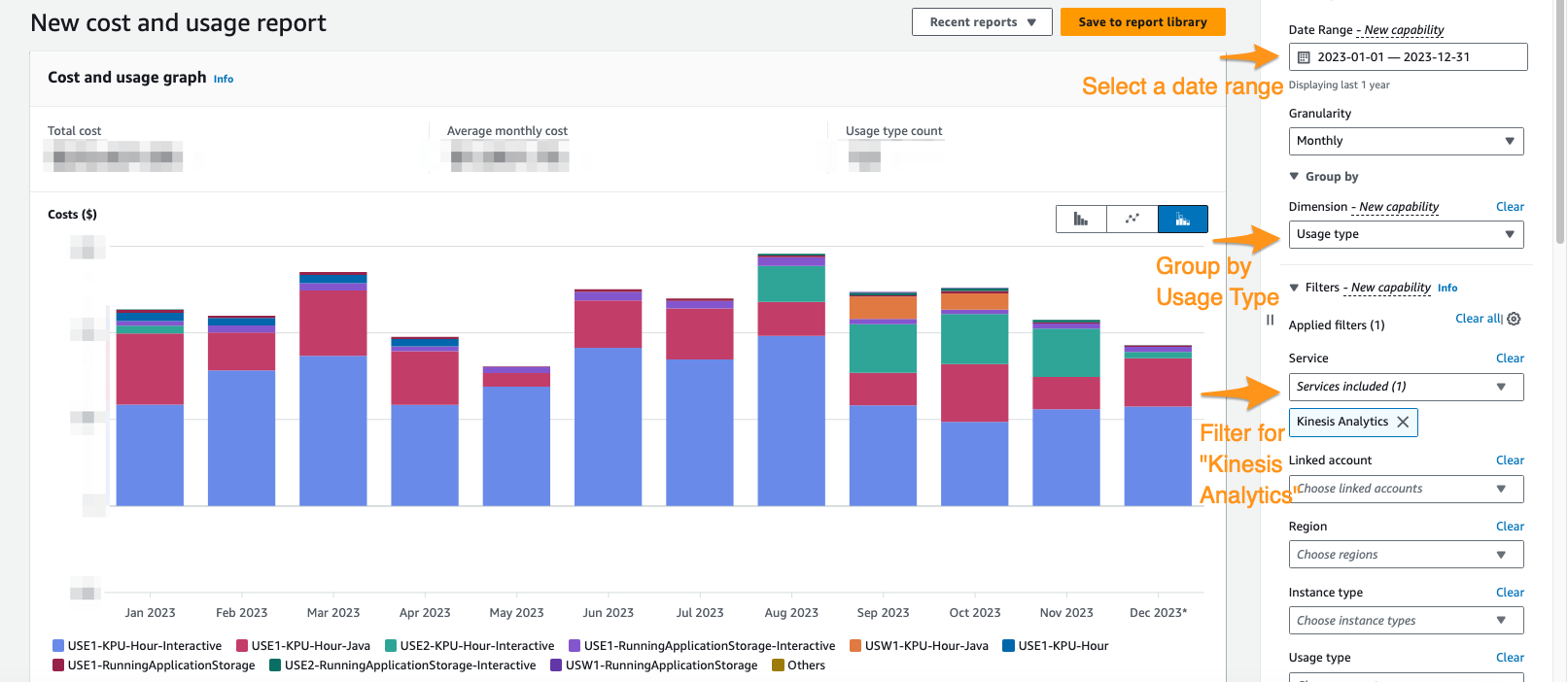
Sử dụng Cost Explorer không chỉ có thể giúp bạn hiểu hóa đơn của mình mà còn giúp tối ưu hóa hơn nữa các ứng dụng cụ thể có thể tự động mở rộng vượt quá mong đợi hoặc do yêu cầu về thông lượng. Với việc gắn thẻ ứng dụng phù hợp, bạn cũng có thể chia nhỏ khoản chi tiêu này theo ứng dụng để xem ứng dụng nào chiếm chi phí.
Dấu hiệu cung cấp quá mức hoặc sử dụng tài nguyên không hiệu quả
Để giảm thiểu chi phí liên quan đến Dịch vụ được quản lý cho các ứng dụng Apache Flink, một cách tiếp cận đơn giản bao gồm việc giảm số lượng KPU mà ứng dụng của bạn sử dụng. Tuy nhiên, điều quan trọng cần phải nhận ra là mức giảm này có thể ảnh hưởng xấu đến hiệu suất nếu không được đánh giá và kiểm tra kỹ lưỡng. Để nhanh chóng đánh giá xem ứng dụng của bạn có bị cung cấp quá mức hay không, hãy kiểm tra các chỉ số chính như mức sử dụng CPU và bộ nhớ, chức năng ứng dụng và phân phối dữ liệu. Tuy nhiên, mặc dù các chỉ báo này có thể gợi ý khả năng cung cấp quá mức nhưng điều cần thiết là phải tiến hành kiểm tra hiệu suất và xác thực các mẫu mở rộng của bạn trước khi thực hiện bất kỳ điều chỉnh nào đối với số lượng KPU.
Metrics
Phân tích số liệu cho ứng dụng của bạn on amazoncloudwatch có thể bộc lộ những dấu hiệu rõ ràng về việc cung cấp quá mức. Nếu containerCPUUtilization và containerMemoryUtilization các số liệu luôn duy trì ở mức dưới 20% trong một khoảng thời gian có ý nghĩa thống kê đối với mẫu lưu lượng truy cập của ứng dụng của bạn, thì bạn có thể giảm quy mô và phân bổ nhiều dữ liệu hơn cho ít máy hơn. Nói chung, chúng tôi xem xét các ứng dụng có kích thước phù hợp khi containerCPUUtilization dao động trong khoảng 50–75%. Mặc dù containerMemoryUtilization có thể dao động suốt cả ngày và bị ảnh hưởng bởi việc tối ưu hóa mã, giá trị thấp liên tục trong một khoảng thời gian đáng kể có thể cho thấy khả năng cung cấp quá mức.
Tính song song trên mỗi KPU không được sử dụng đúng mức
Một dấu hiệu tinh tế khác cho thấy ứng dụng của bạn được cung cấp quá mức là nếu ứng dụng của bạn hoàn toàn bị ràng buộc I/O hoặc chỉ thực hiện các lệnh gọi đơn giản đến cơ sở dữ liệu và các hoạt động không cần CPU. Nếu đúng như vậy, bạn có thể sử dụng tính song song trên mỗi tham số KPU trong Dịch vụ được quản lý dành cho Apache Flink để tải nhiều tác vụ hơn lên một đơn vị xử lý duy nhất.
Bạn có thể xem tính song song trên mỗi tham số KPU dưới dạng thước đo mật độ khối lượng công việc trên mỗi đơn vị tài nguyên điện toán và bộ nhớ (KPU). Việc tăng tính song song trên mỗi KPU lên trên giá trị mặc định là 1 làm cho quá trình xử lý dày đặc hơn, phân bổ nhiều quy trình song song hơn trên một KPU.
Sơ đồ sau minh họa cách thức, bằng cách giữ nguyên tính song song của ứng dụng (ví dụ: 4) và tăng tính song song trên mỗi KPU (ví dụ: từ 1 lên 2), ứng dụng của bạn sử dụng ít tài nguyên hơn với cùng mức độ chạy song song.
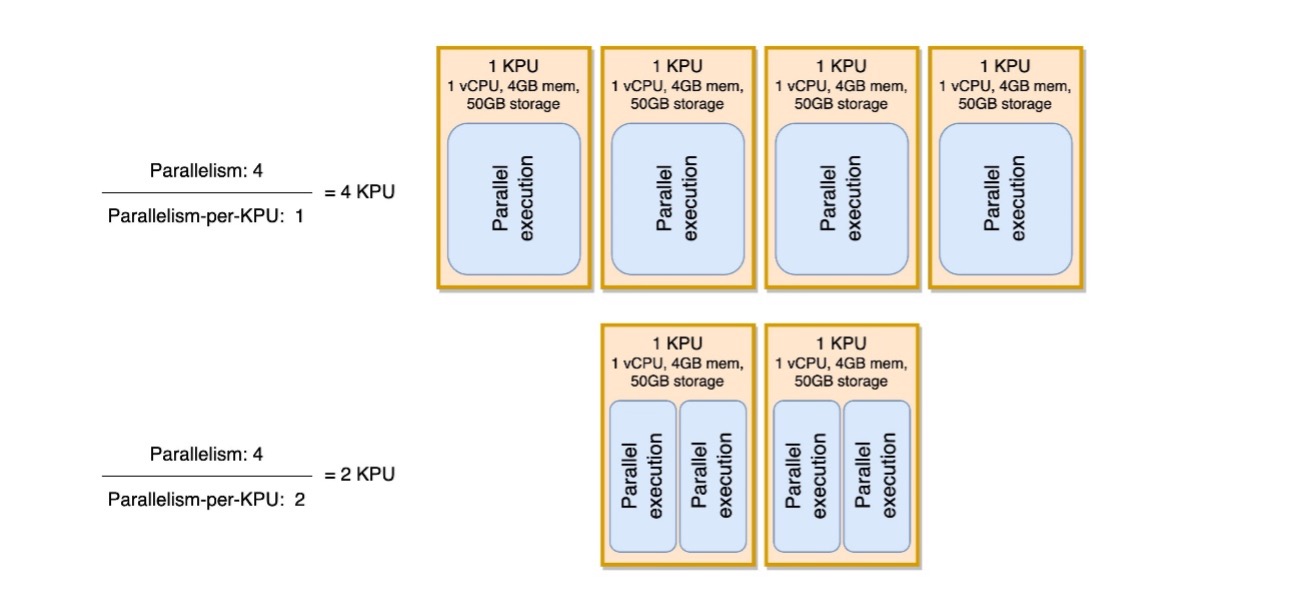
Quyết định tăng tính song song trên mỗi KPU, giống như tất cả các đề xuất trong bài đăng này, cần được thực hiện hết sức thận trọng. Việc tăng tính song song trên mỗi giá trị KPU có thể đặt thêm tải lên một KPU và nó phải sẵn sàng chịu tải đó. Các hoạt động giới hạn I/O sẽ không làm tăng mức sử dụng CPU hoặc bộ nhớ theo bất kỳ cách nào có ý nghĩa, nhưng hàm xử lý tính toán nhiều hoạt động phức tạp dựa trên dữ liệu sẽ không phải là hoạt động lý tưởng để đối chiếu vào một KPU duy nhất, vì nó có thể sử dụng quá nhiều tài nguyên. Kiểm tra hiệu suất và đánh giá xem đây có phải là một lựa chọn tốt cho ứng dụng của bạn hay không.
Cách tiếp cận kích thước
Trước khi bạn thiết lập Dịch vụ được quản lý cho ứng dụng Apache Flink, có thể khó ước tính số lượng KPU bạn nên phân bổ cho ứng dụng của mình. Nói chung, bạn nên hiểu rõ về mô hình lưu lượng truy cập của mình trước khi ước tính. Việc hiểu mô hình lưu lượng truy cập của bạn trên cơ sở tốc độ nhập megabyte mỗi giây có thể giúp bạn ước tính điểm bắt đầu.
Theo nguyên tắc chung, bạn có thể bắt đầu với một KPU trên 1 MB/s mà ứng dụng của bạn sẽ xử lý. Ví dụ: nếu ứng dụng của bạn xử lý trung bình 10 MB/s, bạn sẽ phân bổ 10 KPU làm điểm bắt đầu cho ứng dụng của mình. Hãy nhớ rằng đây là phép tính gần đúng ở mức rất cao mà chúng tôi thấy có hiệu quả đối với ước tính chung. Tuy nhiên, bạn cũng cần kiểm tra hiệu năng và đánh giá xem đây có phải là kích thước phù hợp về lâu dài hay không dựa trên các số liệu (CPU, bộ nhớ, độ trễ, hiệu suất công việc tổng thể) trong một khoảng thời gian dài.
Để tìm kích thước phù hợp cho ứng dụng của bạn, bạn cần mở rộng quy mô ứng dụng Apache Flink. Như đã đề cập, trong Dịch vụ được quản lý dành cho Apache Flink, bạn có hai điều khiển riêng biệt: tính song song và tính song song trên mỗi KPU. Cùng với nhau, các tham số này xác định mức độ xử lý song song trong ứng dụng cũng như tài nguyên điện toán, bộ nhớ và lưu trữ tổng thể có sẵn.
Phương pháp thử nghiệm được đề xuất là thay đổi tính song song hoặc tính song song riêng biệt cho mỗi KPU, đồng thời thử nghiệm để tìm ra kích thước phù hợp. Nói chung, chỉ thay đổi tính song song trên mỗi KPU để tăng số lượng hoạt động song song có giới hạn I/O mà không làm tăng tổng tài nguyên. Đối với tất cả các trường hợp khác, chỉ thay đổi tính song song—KPU sẽ thay đổi sau đó—để tìm kích thước phù hợp cho khối lượng công việc của bạn.
Quý vị cũng có thể thiết lập tính song song ở cấp độ toán tử để hạn chế các nguồn, phần chìm hoặc bất kỳ toán tử nào khác có thể cần được hạn chế và độc lập với các cơ chế mở rộng quy mô. Bạn có thể sử dụng điều này cho ứng dụng Apache Flink đọc từ chủ đề Apache Kafka có 10 phân vùng. Với setParallelism() phương pháp này, bạn có thể giới hạn KafkaSource ở mức 10, nhưng mở rộng Dịch vụ được quản lý cho ứng dụng Apache Flink lên mức song song cao hơn 10 mà không tạo các tác vụ nhàn rỗi cho nguồn Kafka. Đối với các trường hợp xử lý dữ liệu khác, chúng tôi khuyên bạn không nên đặt tĩnh tính song song của toán tử thành một giá trị tĩnh mà nên đặt một hàm của tính song song của ứng dụng để nó chia tỷ lệ khi ứng dụng tổng thể chia tỷ lệ.
Chia tỷ lệ và tự động chia tỷ lệ
Trong Dịch vụ được quản lý dành cho Apache Flink, việc sửa đổi tính song song hoặc tính song song trên mỗi KPU là bản cập nhật cấu hình ứng dụng. Nó khiến ứng dụng tự động mất một ảnh chụp (trừ khi bị tắt), hãy dừng ứng dụng và khởi động lại ứng dụng với kích thước mới, khôi phục trạng thái từ ảnh chụp nhanh. Hoạt động thay đổi quy mô không gây mất dữ liệu hoặc mâu thuẫn nhưng sẽ tạm dừng quá trình xử lý dữ liệu trong một khoảng thời gian ngắn khi cơ sở hạ tầng được thêm hoặc xóa. Đây là điều bạn cần cân nhắc khi thay đổi quy mô trong môi trường sản xuất.
Trong quá trình thử nghiệm và tối ưu hóa, chúng tôi khuyên bạn nên tắt tự động mở rộng quy mô và sửa đổi tính song song và tính song song trên mỗi KPU để tìm ra các giá trị tối ưu. Như đã đề cập, việc chia tỷ lệ thủ công chỉ là bản cập nhật của cấu hình ứng dụng và có thể chạy qua Bảng điều khiển quản lý AWS hoặc API với Cập nhật hành động ứng dụng.
Khi bạn đã tìm thấy kích thước tối ưu, nếu bạn mong đợi thông lượng được nhập vào sẽ thay đổi đáng kể, bạn có thể quyết định bật tự động điều chỉnh quy mô.
Trong Dịch vụ được quản lý dành cho Apache Flink, bạn có thể sử dụng nhiều loại tỷ lệ tự động:
- Chia tỷ lệ tự động sẵn dùng – Bạn có thể kích hoạt tính năng này để tự động điều chỉnh tính song song của ứng dụng dựa trên
containerCPUUtilizationHệ mét. Tự động chia tỷ lệ được bật theo mặc định trên các ứng dụng mới. Để biết chi tiết về thuật toán chia tỷ lệ tự động, hãy tham khảo Tự động mở rộng quy mô. - Chia tỷ lệ tự động dựa trên số liệu, chi tiết - Việc này dễ thực hiện. Việc tự động hóa có thể dựa trên hầu hết mọi số liệu, bao gồm số liệu tùy chỉnh ứng dụng của bạn lộ ra.
- Chia tỷ lệ theo lịch trình – Điều này có thể hữu ích nếu bạn mong đợi khối lượng công việc đạt mức cao nhất vào những thời điểm nhất định trong ngày hoặc các ngày trong tuần.
Chia tỷ lệ tự động dùng ngay và chia tỷ lệ dựa trên số liệu chi tiết loại trừ lẫn nhau. Để biết thêm chi tiết về tỷ lệ tự động chi tiết dựa trên số liệu và tỷ lệ theo lịch trình cũng như ví dụ về mã hoạt động đầy đủ, hãy tham khảo Bật quy mô dựa trên số liệu và theo lịch trình cho Dịch vụ được quản lý của Amazon cho Apache Flink.
Tối ưu hóa mã
Một cách khác để tiết kiệm chi phí cho Dịch vụ được quản lý dành cho ứng dụng Apache Flink của bạn là thông qua tối ưu hóa mã. Mã không được tối ưu hóa sẽ cần nhiều máy hơn để thực hiện các phép tính tương tự. Tối ưu hóa mã có thể cho phép sử dụng tài nguyên tổng thể thấp hơn, từ đó có thể cho phép giảm quy mô và tiết kiệm chi phí tương ứng.
Bước đầu tiên để hiểu hiệu suất mã của bạn là thông qua tiện ích tích hợp sẵn trong Apache Flink có tên là Đồ thị ngọn lửa.
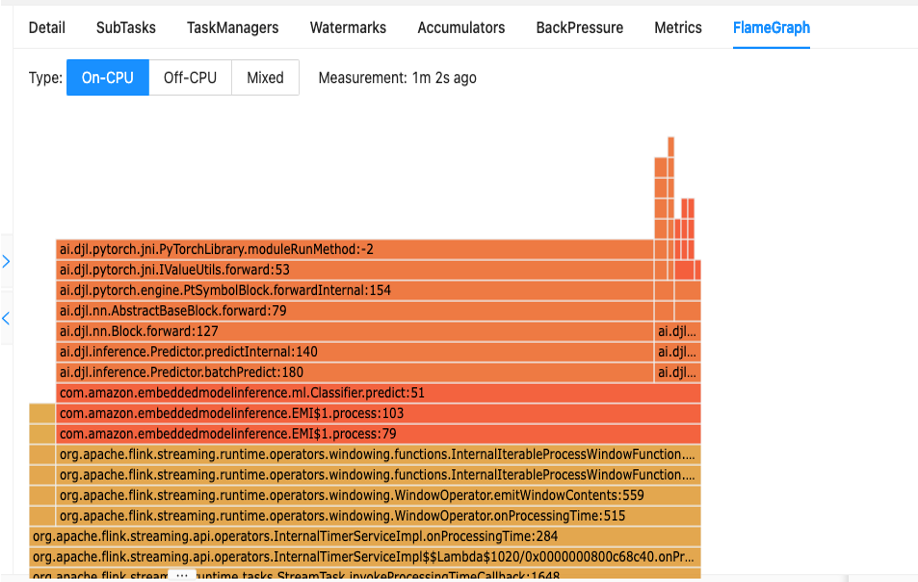
Biểu đồ ngọn lửa, có thể truy cập được thông qua bảng điều khiển Apache Flink, cung cấp cho bạn bản trình bày trực quan về dấu vết ngăn xếp của bạn. Mỗi khi một phương thức được gọi, thanh đại diện cho lệnh gọi phương thức đó trong dấu vết ngăn xếp sẽ lớn hơn tỷ lệ thuận với tổng số mẫu. Điều này có nghĩa là nếu bạn có một đoạn mã không hiệu quả với một thanh rất dài trong biểu đồ ngọn lửa, thì đây có thể là nguyên nhân cần phải điều tra xem làm cách nào để làm cho mã này hiệu quả hơn. Ngoài ra, bạn có thể sử dụng Trình biên dịch mã CodeGuru của Amazon đến giám sát và tối ưu hóa các ứng dụng Apache Flink của bạn đang chạy trên Dịch vụ được quản lý cho Apache Flink.
Khi thiết kế ứng dụng của bạn, bạn nên sử dụng API cấp cao nhất được yêu cầu cho một hoạt động cụ thể tại một thời điểm nhất định. Apache Flink cung cấp bốn cấp độ hỗ trợ API: Flink SQL, API bảng, Datastream API và ProcessFunction API, với mức độ phức tạp và trách nhiệm ngày càng tăng. Nếu ứng dụng của bạn có thể được viết hoàn toàn bằng Flink SQL hoặc Table API, thì việc sử dụng ứng dụng này có thể giúp tận dụng khung Apache Flink thay vì quản lý trạng thái và tính toán theo cách thủ công.
Dữ liệu lệch
Trên bảng điều khiển Apache Flink, bạn có thể thu thập thông tin hữu ích khác về Dịch vụ được quản lý cho các công việc Apache Flink.
Trên bảng điều khiển, bạn có thể kiểm tra từng nhiệm vụ trong biểu đồ đơn xin việc của mình. Mỗi hộp màu xanh biểu thị một nhiệm vụ và mỗi nhiệm vụ bao gồm các nhiệm vụ phụ hoặc đơn vị công việc được phân bổ cho nhiệm vụ đó. Bạn có thể xác định độ lệch dữ liệu giữa các nhiệm vụ con theo cách này.
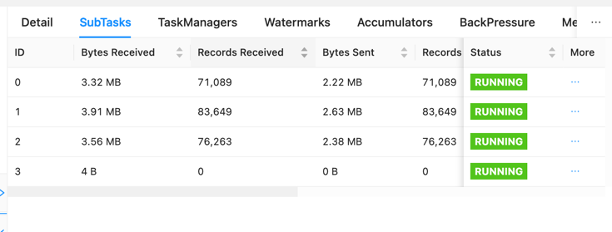
Độ lệch dữ liệu là một chỉ báo cho thấy nhiều dữ liệu đang được gửi đến một nhiệm vụ con hơn một nhiệm vụ con khác và rằng một nhiệm vụ con nhận được nhiều dữ liệu hơn đang thực hiện nhiều công việc hơn nhiệm vụ kia. Nếu bạn có các triệu chứng sai lệch dữ liệu như vậy, bạn có thể tìm cách loại bỏ nó bằng cách xác định nguồn. Ví dụ, một GroupBy or KeyedStream có thể có một sai lệch trong chìa khóa. Điều này có nghĩa là dữ liệu không được trải đều giữa các khóa, dẫn đến sự phân bổ công việc không đồng đều trên các phiên bản điện toán Apache Flink. Hãy tưởng tượng một tình huống mà bạn đang nhóm theo userId, nhưng ứng dụng của bạn nhận được dữ liệu từ một người dùng nhiều hơn đáng kể so với những người dùng còn lại. Điều này có thể dẫn đến sai lệch dữ liệu. Để loại bỏ điều này, bạn có thể chọn một khóa nhóm khác để phân bổ đều dữ liệu cho các nhiệm vụ phụ. Hãy nhớ rằng điều này sẽ yêu cầu sửa đổi mã để chọn một khóa khác.
Khi độ lệch dữ liệu được loại bỏ, bạn có thể quay lại containerCPUUtilization và containerMemoryUtilization số liệu để giảm số lượng KPU.
Các lĩnh vực khác để tối ưu hóa mã bao gồm đảm bảo rằng bạn đang truy cập các hệ thống bên ngoài thông qua API I/O không đồng bộ hoặc thông qua việc nối luồng dữ liệu, vì truy vấn đồng bộ tới kho lưu trữ dữ liệu có thể tạo ra sự chậm lại và các vấn đề trong việc kiểm tra điểm. Ngoài ra, hãy tham khảo Khắc phục sự cố hiệu suất để biết các sự cố bạn có thể gặp phải với điểm kiểm tra hoặc ghi nhật ký chậm, điều này có thể gây ra áp lực ngược cho ứng dụng.
Cách xác định xem Apache Flink có phải là công nghệ phù hợp không
Nếu ứng dụng của bạn không sử dụng bất kỳ khả năng mạnh mẽ nào đằng sau khung Apache Flink và Dịch vụ được quản lý cho Apache Flink, thì bạn có thể tiết kiệm chi phí bằng cách sử dụng thứ gì đó đơn giản hơn.
Khẩu hiệu của Apache Flink là “Tính toán trạng thái trên luồng dữ liệu”. Trong ngữ cảnh này, có trạng thái có nghĩa là bạn đang sử dụng cấu trúc trạng thái Apache Flink. State, trong Apache Flink, cho phép bạn ghi nhớ các tin nhắn bạn đã thấy trong quá khứ trong thời gian dài hơn, giúp thực hiện những việc như kết nối trực tuyến, chống trùng lặp, xử lý chính xác một lần, cửa sổ và xử lý dữ liệu muộn. Nó làm như vậy bằng cách sử dụng một kho lưu trữ trạng thái trong bộ nhớ. Trên Dịch vụ được quản lý cho Apache Flink, nó sử dụng RocksDB để duy trì trạng thái của nó.
Nếu ứng dụng của bạn không liên quan đến các hoạt động có trạng thái, bạn có thể xem xét các lựa chọn thay thế như AWS Lambda, các ứng dụng được đóng gói hoặc một Đám mây điện toán đàn hồi Amazon (Amazon EC2) đang chạy ứng dụng của bạn. Sự phức tạp của Apache Flink có thể không cần thiết trong những trường hợp như vậy. Các tính toán trạng thái, bao gồm dữ liệu được lưu trong bộ nhớ đệm hoặc quy trình làm giàu yêu cầu bộ nhớ vị trí luồng độc lập, có thể đảm bảo khả năng trạng thái của Apache Flink. Nếu ứng dụng của bạn có khả năng trở thành trạng thái trong tương lai, cho dù thông qua việc lưu giữ dữ liệu kéo dài hay các yêu cầu trạng thái khác, thì việc tiếp tục sử dụng Apache Flink có thể đơn giản hơn. Các tổ chức nhấn mạnh Apache Flink về khả năng xử lý luồng có thể thích gắn bó với Apache Flink cho các ứng dụng có trạng thái và không trạng thái để tất cả các ứng dụng của họ xử lý dữ liệu theo cùng một cách. Bạn cũng nên tính đến các tính năng điều phối của nó như xử lý chính xác một lần, khả năng phân xuất và tính toán phân tán trước khi chuyển từ Apache Flink sang các lựa chọn thay thế.
Một cân nhắc khác là yêu cầu về độ trễ của bạn. Bởi vì Apache Flink vượt trội trong việc xử lý dữ liệu theo thời gian thực nên việc sử dụng nó cho một ứng dụng có yêu cầu độ trễ 6 giờ hoặc 1 ngày là không có ý nghĩa. Tiết kiệm chi phí bằng cách chuyển sang quy trình xử lý hàng loạt theo thời gian Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), chẳng hạn, sẽ rất có ý nghĩa.
Kết luận
Trong bài đăng này, chúng tôi đã đề cập đến một số khía cạnh cần xem xét khi thử các biện pháp tiết kiệm chi phí cho Dịch vụ được quản lý cho Apache Flink. Chúng tôi đã thảo luận cách xác định tổng chi tiêu của bạn cho dịch vụ được quản lý, một số số liệu hữu ích cần theo dõi khi giảm quy mô KPU, cách tối ưu hóa mã để giảm quy mô và cách xác định xem Apache Flink có phù hợp với trường hợp sử dụng của bạn hay không.
Việc triển khai các chiến lược tiết kiệm chi phí này không chỉ nâng cao hiệu quả chi phí của bạn mà còn cung cấp khả năng triển khai Apache Flink được tối ưu hóa tốt và hợp lý. Bằng cách lưu ý đến tổng chi tiêu của mình, sử dụng các số liệu chính và đưa ra quyết định sáng suốt về việc giảm quy mô tài nguyên, bạn có thể đạt được hoạt động tiết kiệm chi phí mà không ảnh hưởng đến hiệu suất. Khi bạn điều hướng bối cảnh của Apache Flink, việc liên tục đánh giá xem liệu nó có phù hợp với trường hợp sử dụng cụ thể của bạn hay không sẽ trở thành vấn đề then chốt, để bạn có thể đạt được giải pháp phù hợp và hiệu quả cho nhu cầu xử lý dữ liệu của mình.
Nếu bất kỳ đề xuất nào được thảo luận trong bài đăng này phù hợp với khối lượng công việc của bạn, chúng tôi khuyên bạn nên thử chúng. Với các số liệu được chỉ định và các mẹo về cách hiểu rõ hơn khối lượng công việc của bạn, giờ đây bạn sẽ có những gì mình cần để tối ưu hóa hiệu quả khối lượng công việc Apache Flink trên Dịch vụ được quản lý cho Apache Flink. Sau đây là một số tài nguyên hữu ích mà bạn có thể sử dụng để bổ sung cho bài đăng này:
Về các tác giả
 Jeremy Ber đã làm việc trong không gian dữ liệu đo từ xa trong 10 năm qua với tư cách là Kỹ sư phần mềm, Kỹ sư máy học và gần đây nhất là Kỹ sư dữ liệu. Tại AWS, anh là Kiến trúc sư giải pháp chuyên gia phát trực tuyến, hỗ trợ cả Truyền phát được quản lý của Amazon cho Apache Kafka (Amazon MSK) và Dịch vụ được quản lý của Amazon cho Apache Flink.
Jeremy Ber đã làm việc trong không gian dữ liệu đo từ xa trong 10 năm qua với tư cách là Kỹ sư phần mềm, Kỹ sư máy học và gần đây nhất là Kỹ sư dữ liệu. Tại AWS, anh là Kiến trúc sư giải pháp chuyên gia phát trực tuyến, hỗ trợ cả Truyền phát được quản lý của Amazon cho Apache Kafka (Amazon MSK) và Dịch vụ được quản lý của Amazon cho Apache Flink.
 Lorenzo Nicora làm việc với tư cách là Kiến trúc sư giải pháp phát trực tuyến cấp cao tại AWS, giúp đỡ khách hàng trên khắp EMEA. Ông đã xây dựng các hệ thống dựa trên đám mây, sử dụng nhiều dữ liệu trong hơn 25 năm, làm việc trong ngành tài chính thông qua tư vấn và cho các công ty sản phẩm FinTech. Ông đã tận dụng rộng rãi các công nghệ nguồn mở và đóng góp cho một số dự án, bao gồm cả Apache Flink.
Lorenzo Nicora làm việc với tư cách là Kiến trúc sư giải pháp phát trực tuyến cấp cao tại AWS, giúp đỡ khách hàng trên khắp EMEA. Ông đã xây dựng các hệ thống dựa trên đám mây, sử dụng nhiều dữ liệu trong hơn 25 năm, làm việc trong ngành tài chính thông qua tư vấn và cho các công ty sản phẩm FinTech. Ông đã tận dụng rộng rãi các công nghệ nguồn mở và đóng góp cho một số dự án, bao gồm cả Apache Flink.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

