Tổng công ty KT là một trong những nhà cung cấp dịch vụ viễn thông lớn nhất tại Hàn Quốc, cung cấp nhiều loại dịch vụ bao gồm điện thoại cố định, liên lạc di động, internet và các dịch vụ AI. Thẻ thực phẩm AI của KT là giải pháp quản lý chế độ ăn uống dựa trên AI, xác định loại và hàm lượng dinh dưỡng của thực phẩm trong ảnh bằng mô hình thị giác máy tính. Mô hình thị giác này do KT phát triển dựa trên mô hình được đào tạo trước với một lượng lớn dữ liệu hình ảnh không được gắn nhãn để phân tích hàm lượng dinh dưỡng và thông tin về lượng calo của các loại thực phẩm khác nhau. Thẻ thực phẩm AI có thể giúp bệnh nhân mắc các bệnh mãn tính như tiểu đường quản lý chế độ ăn uống của họ. KT đã sử dụng AWS và Amazon SageMaker để đào tạo mô hình Thẻ thực phẩm AI này nhanh hơn 29 lần so với trước đây và tối ưu hóa nó để triển khai sản xuất bằng kỹ thuật chưng cất mô hình. Trong bài đăng này, chúng tôi mô tả hành trình phát triển mô hình và thành công của KT khi sử dụng SageMaker.
Giới thiệu dự án KT và xác định vấn đề
Mô hình AI Food Tag được KT đào tạo trước dựa trên kiến trúc máy biến đổi tầm nhìn (ViT) và có nhiều tham số mô hình hơn mô hình tầm nhìn trước đây của họ để cải thiện độ chính xác. Để thu nhỏ kích thước mô hình cho sản xuất, KT đang sử dụng kỹ thuật chắt lọc kiến thức (KD) để giảm số lượng tham số mô hình mà không ảnh hưởng đáng kể đến độ chính xác. Với việc chắt lọc kiến thức, mô hình được đào tạo trước được gọi là giáo viên mẫuvà một mô hình đầu ra nhẹ được đào tạo như một người mẫu sinh viên, như được minh họa trong hình dưới đây. Mô hình học sinh nhẹ có ít tham số mô hình hơn mô hình giáo viên, giúp giảm yêu cầu về bộ nhớ và cho phép triển khai trên các phiên bản nhỏ hơn, ít tốn kém hơn. Học sinh duy trì độ chính xác ở mức chấp nhận được dù độ chính xác nhỏ hơn bằng cách học từ kết quả đầu ra của mô hình giáo viên.

Mô hình giáo viên không thay đổi trong KD, nhưng mô hình học sinh được huấn luyện bằng cách sử dụng log đầu ra của mô hình giáo viên làm nhãn để tính toán tổn thất. Với mô hình KD này, cả giáo viên và học sinh đều cần sử dụng một bộ nhớ GPU duy nhất để đào tạo. KT ban đầu sử dụng hai GPU (A100 80 GB) trong môi trường nội bộ, tại chỗ của họ để đào tạo mô hình sinh viên, nhưng quá trình này mất khoảng 40 ngày để xử lý 300 kỷ nguyên. Để đẩy nhanh quá trình đào tạo và tạo ra mô hình sinh viên trong thời gian ngắn hơn, KT đã hợp tác với AWS. Cùng nhau, các đội đã giảm đáng kể thời gian đào tạo mô hình. Bài đăng này mô tả cách nhóm sử dụng Đào tạo Amazon SageMaker, Các Thư viện song song dữ liệu SageMaker, Trình gỡ lỗi Amazon SageMakervà Trình phân tích hồ sơ Amazon SageMaker để phát triển thành công mô hình Thẻ thực phẩm AI nhẹ.
Xây dựng môi trường đào tạo phân tán với SageMaker
SageMaker Training là môi trường đào tạo machine learning (ML) được quản lý trên AWS, cung cấp một bộ tính năng và công cụ để đơn giản hóa trải nghiệm đào tạo và có thể hữu ích trong điện toán phân tán, như được minh họa trong sơ đồ sau.
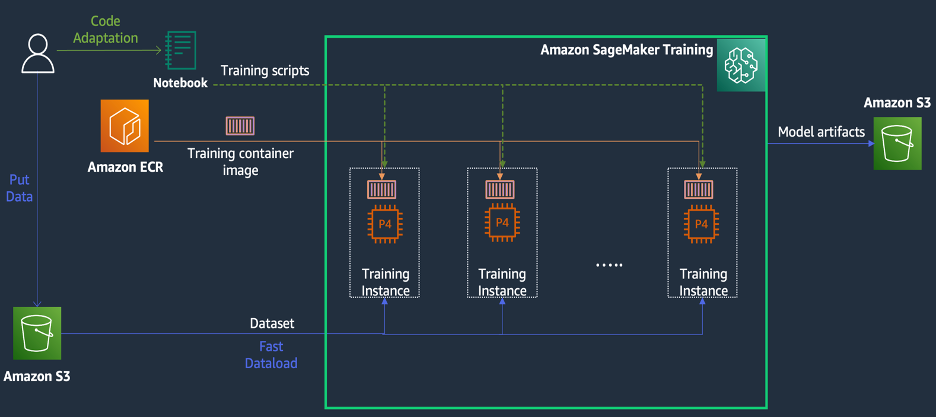
Khách hàng của SageMaker cũng có thể truy cập các hình ảnh Docker tích hợp sẵn với nhiều khung học sâu được cài đặt sẵn khác nhau và các gói Linux, NCCL và Python cần thiết để đào tạo mô hình. Các nhà khoa học dữ liệu hoặc kỹ sư ML muốn chạy đào tạo mô hình có thể làm như vậy mà không phải chịu gánh nặng cấu hình cơ sở hạ tầng đào tạo hoặc quản lý Docker cũng như khả năng tương thích của các thư viện khác nhau.
Trong hội thảo kéo dài 1 ngày, chúng tôi đã có thể thiết lập cấu hình đào tạo phân tán dựa trên SageMaker trong tài khoản AWS của KT, tăng tốc các tập lệnh đào tạo của KT bằng thư viện SageMaker Distributed Data Parallel (DDP) và thậm chí kiểm tra công việc đào tạo bằng cách sử dụng hai ml. phiên bản p4d.24xlarge. Trong phần này, chúng tôi mô tả trải nghiệm của KT khi làm việc với nhóm AWS và sử dụng SageMaker để phát triển mô hình của họ.
Trong quá trình chứng minh khái niệm, chúng tôi muốn tăng tốc công việc đào tạo bằng cách sử dụng thư viện SageMaker DDP, được tối ưu hóa cho cơ sở hạ tầng AWS trong quá trình đào tạo phân tán. Để thay đổi từ PyTorch DDP sang SageMaker DDP, bạn chỉ cần khai báo torch_smddp đóng gói và thay đổi phần phụ trợ thành smddp, như được hiển thị trong đoạn mã sau:
Để tìm hiểu thêm về thư viện SageMaker DDP, hãy tham khảo Thư viện song song dữ liệu của SageMaker.
Phân tích nguyên nhân khiến tốc độ đào tạo chậm bằng SageMaker Debugger và Profiler
Bước đầu tiên trong việc tối ưu hóa và đẩy nhanh khối lượng công việc đào tạo liên quan đến việc hiểu và chẩn đoán nơi xảy ra tắc nghẽn. Đối với công việc đào tạo của KT, chúng tôi đã đo thời gian đào tạo trên mỗi lần lặp của trình tải dữ liệu, chuyển tiếp và chuyển ngược:
| Thời gian 1 lần – bộ nạp dữ liệu: 0.00053 giây, tiến: 7.77474 giây, lùi: 1.58002 giây |
| Thời gian 2 lần – bộ nạp dữ liệu: 0.00063 giây, tiến: 0.67429 giây, lùi: 24.74539 giây |
| Thời gian 3 lần – bộ nạp dữ liệu: 0.00061 giây, tiến: 0.90976 giây, lùi: 8.31253 giây |
| Thời gian 4 lần – bộ nạp dữ liệu: 0.00060 giây, tiến: 0.60958 giây, lùi: 30.93830 giây |
| Thời gian 5 lần – bộ nạp dữ liệu: 0.00080 giây, tiến: 0.83237 giây, lùi: 8.41030 giây |
| Thời gian 6 lần – bộ nạp dữ liệu: 0.00067 giây, tiến: 0.75715 giây, lùi: 29.88415 giây |
Nhìn vào thời gian trong đầu ra tiêu chuẩn cho mỗi lần lặp, chúng tôi thấy rằng thời gian chạy của đường chuyền ngược dao động đáng kể từ lần lặp này sang lần lặp khác. Sự thay đổi này là bất thường và có thể ảnh hưởng đến tổng thời gian đào tạo. Để tìm ra nguyên nhân của tốc độ đào tạo không nhất quán này, trước tiên, chúng tôi đã cố gắng xác định các tắc nghẽn tài nguyên bằng cách sử dụng Trình giám sát hệ thống (Giao diện người dùng trình gỡ lỗi SageMaker), cho phép bạn gỡ lỗi các công việc đào tạo trên SageMaker Training và xem trạng thái của các tài nguyên, chẳng hạn như nền tảng đào tạo được quản lý. CPU, GPU, mạng và I/O trong một số giây đã đặt.
Giao diện người dùng trình gỡ lỗi SageMaker cung cấp dữ liệu chi tiết và cần thiết có thể giúp xác định và chẩn đoán các điểm nghẽn trong công việc đào tạo. Cụ thể, chúng tôi đã chú ý đến biểu đồ đường sử dụng CPU và bản đồ nhiệt sử dụng CPU/GPU trên mỗi bảng phiên bản.
Trong biểu đồ đường sử dụng CPU, chúng tôi nhận thấy rằng một số CPU đang được sử dụng 100%.
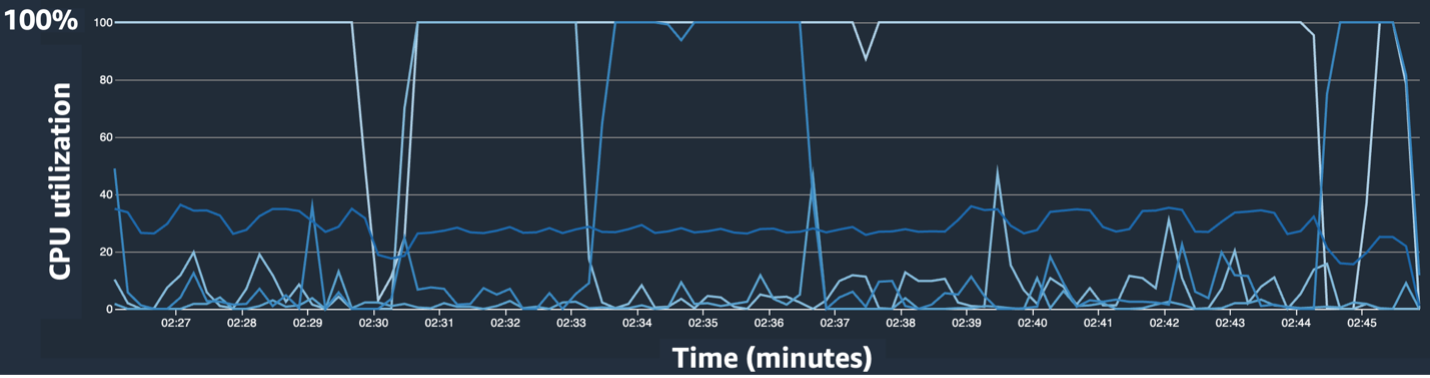
Trong bản đồ nhiệt (trong đó màu tối hơn biểu thị mức sử dụng cao hơn), chúng tôi lưu ý rằng một số lõi CPU có mức sử dụng cao trong suốt quá trình đào tạo, trong khi mức sử dụng GPU không cao nhất quán theo thời gian.

Từ đây, chúng tôi bắt đầu nghi ngờ rằng một trong những nguyên nhân khiến tốc độ đào tạo chậm là do tắc nghẽn CPU. Chúng tôi đã xem lại mã tập lệnh đào tạo để xem liệu có điều gì gây ra tắc nghẽn CPU hay không. Phần đáng ngờ nhất là giá trị lớn của num_workers trong trình tải dữ liệu, vì vậy chúng tôi đã thay đổi giá trị này thành 0 hoặc 1 để giảm mức sử dụng CPU. Sau đó chúng tôi thực hiện lại công việc đào tạo và kiểm tra kết quả.
Các ảnh chụp màn hình sau đây hiển thị biểu đồ đường sử dụng CPU, mức sử dụng GPU và bản đồ nhiệt sau khi giảm thiểu tắc nghẽn CPU.
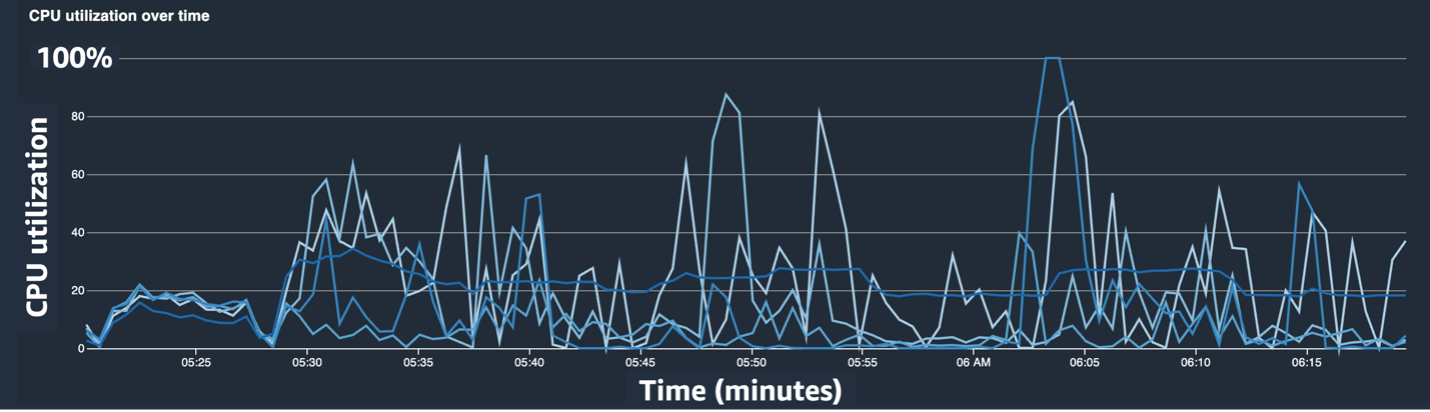


Đơn giản bằng cách thay đổi num_workers, chúng tôi nhận thấy mức sử dụng CPU giảm đáng kể và mức sử dụng GPU tổng thể tăng lên. Đây là một thay đổi quan trọng giúp cải thiện đáng kể tốc độ luyện tập. Tuy nhiên, chúng tôi muốn biết mình có thể tối ưu hóa việc sử dụng GPU ở đâu. Để làm điều này, chúng tôi đã sử dụng SageMaker Profiler.
SageMaker Profiler giúp xác định các manh mối tối ưu hóa bằng cách cung cấp khả năng hiển thị mức sử dụng theo hoạt động, bao gồm theo dõi số liệu sử dụng GPU và CPU cũng như mức tiêu thụ nhân của GPU/CPU trong các tập lệnh đào tạo. Nó giúp người dùng hiểu được hoạt động nào đang tiêu tốn tài nguyên. Đầu tiên, để sử dụng SageMaker Profiler, bạn cần thêm ProfilerConfig tới hàm gọi công việc đào tạo bằng SDK SageMaker, như minh họa trong đoạn mã sau:
Trong SageMaker Python SDK, bạn có thể linh hoạt thêm annotate các chức năng dành cho SageMaker Profiler để chọn mã hoặc các bước trong tập lệnh đào tạo cần lập hồ sơ. Sau đây là ví dụ về mã mà bạn nên khai báo cho SageMaker Profiler trong tập lệnh đào tạo:
Sau khi thêm mã trước đó, nếu bạn chạy công việc đào tạo bằng cách sử dụng tập lệnh đào tạo, bạn có thể nhận được thông tin về các hoạt động mà nhân GPU sử dụng (như minh họa trong hình sau) sau khi quá trình đào tạo diễn ra trong một khoảng thời gian. Trong trường hợp tập lệnh đào tạo của KT, chúng tôi đã chạy nó trong một kỷ nguyên và nhận được kết quả như sau.
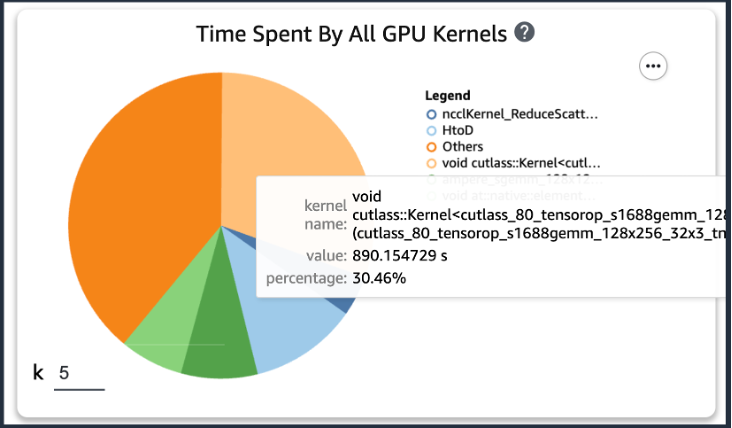
Khi kiểm tra năm thời gian tiêu thụ thao tác nhiều nhất của nhân GPU trong số các kết quả của SageMaker Profiler, chúng tôi nhận thấy rằng đối với tập lệnh đào tạo KT, thao tác sản phẩm ma trận tiêu tốn nhiều thời gian nhất, tức là thao tác nhân ma trận chung (GEMM). trên GPU. Với thông tin chi tiết quan trọng này từ SageMaker Profiler, chúng tôi bắt đầu nghiên cứu các cách để tăng tốc các hoạt động này và cải thiện việc sử dụng GPU.
Đẩy nhanh thời gian đào tạo
Chúng tôi đã xem xét nhiều cách khác nhau để giảm thời gian tính toán nhân ma trận và áp dụng hai hàm PyTorch.
Trạng thái trình tối ưu hóa phân đoạn với ZeroRedundancyOptimizer
Nếu bạn nhìn vào Trình tối ưu hóa dự phòng bằng không (ZeRO), kỹ thuật DeepSpeed/ZeRO cho phép đào tạo một mô hình lớn một cách hiệu quả với tốc độ đào tạo tốt hơn bằng cách loại bỏ phần dư thừa trong bộ nhớ được mô hình sử dụng. Trình tối ưu hóa ZeroDundancy trong PyTorch sử dụng kỹ thuật phân chia trạng thái trình tối ưu hóa để giảm mức sử dụng bộ nhớ trên mỗi quy trình trong Song song dữ liệu phân tán (DDP). DDP sử dụng các gradient được đồng bộ hóa trong quá trình truyền ngược để tất cả các bản sao của trình tối ưu hóa lặp lại trên cùng các tham số và giá trị gradient, nhưng thay vì có tất cả các tham số mô hình, mỗi trạng thái của trình tối ưu hóa chỉ được duy trì bằng cách phân chia cho các quy trình DDP khác nhau để giảm mức sử dụng bộ nhớ.
Để sử dụng nó, bạn có thể để Trình tối ưu hóa hiện tại của mình ở chế độ optimizer_class và tuyên bố một ZeroRedundancyOptimizer với phần còn lại của các tham số mô hình và tốc độ học tập là các tham số.
Độ chính xác hỗn hợp tự động
Độ chính xác hỗn hợp tự động (AMP) sử dụng kiểu dữ liệu torch.float32 cho một số thao tác và ngọn đuốc.bfloat16 hoặc torch.float16 cho những loại khác, để thuận tiện cho việc tính toán nhanh và giảm mức sử dụng bộ nhớ. Đặc biệt, vì các mô hình học sâu thường nhạy cảm hơn với các bit số mũ so với các bit phân số trong tính toán của chúng, nên torch.bfloat16 tương đương với các bit số mũ của torch.float32, cho phép chúng học nhanh chóng với tổn thất tối thiểu. torch.bfloat16 chỉ chạy trên các phiên bản có kiến trúc A100 NVIDIA (Ampere) trở lên, chẳng hạn như ml.p4d.24xlarge, ml.p4de.24xlarge và ml.p5.48xlarge.
Để áp dụng AMP, bạn có thể khai báo torch.cuda.amp.autocast trong các tập lệnh đào tạo như trong đoạn mã trên và khai báo dtype như ngọn đuốc.bfloat16.
Kết quả trong SageMaker Profiler
Sau khi áp dụng hai chức năng này cho các tập lệnh đào tạo và chạy lại công việc đào tạo trong một kỷ nguyên, chúng tôi đã kiểm tra năm thời gian tiêu thụ thao tác nhiều nhất cho nhân GPU trong SageMaker Profiler. Hình dưới đây cho thấy kết quả của chúng tôi.
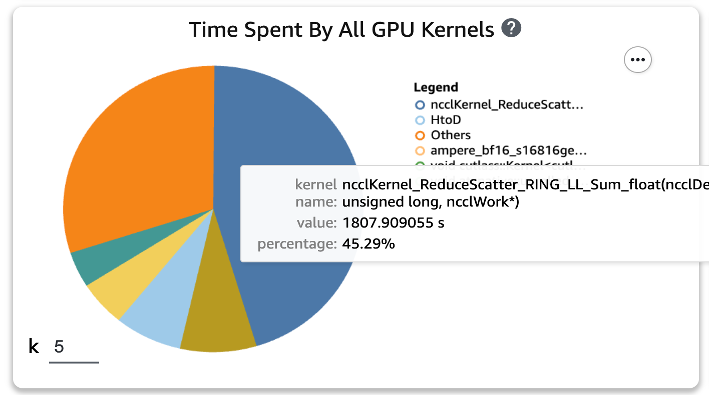
Chúng ta có thể thấy rằng hoạt động GEMM, đứng đầu danh sách trước khi áp dụng hai chức năng Torch, đã biến mất khỏi năm hoạt động hàng đầu, được thay thế bằng hoạt động GiảmScatter, thường xảy ra trong đào tạo phân tán.
Kết quả tốc độ huấn luyện của mô hình chắt lọc KT
Chúng tôi đã tăng kích thước lô đào tạo thêm 128 để tiết kiệm bộ nhớ khi áp dụng hai chức năng Torch, dẫn đến kích thước lô cuối cùng là 1152 thay vì 1024. Việc đào tạo mô hình sinh viên cuối cùng có thể chạy 210 kỷ nguyên mỗi 1 ngày ; thời gian đào tạo và tăng tốc giữa môi trường đào tạo nội bộ của KT và SageMaker được tóm tắt trong bảng sau.
| Môi trường đào tạo | Thông số GPU đào tạo. | Số lượng GPU | Thời gian đào tạo (giờ) | Kỷ nguyên | Số giờ mỗi kỷ nguyên | Tỉ lệ giảm |
| Môi trường đào tạo nội bộ của KT | A100 (80GB) | 2 | 960 | 300 | 3.20 | 29 |
| Amazon SageMaker | A100 (40GB) | 32 | 24 | 210 | 0.11 | 1 |
Khả năng mở rộng của AWS cho phép chúng tôi hoàn thành công việc đào tạo nhanh hơn 29 lần so với trước đây khi sử dụng 32 GPU thay vì 2 GPU tại cơ sở. Do đó, việc sử dụng nhiều GPU hơn trên SageMaker sẽ giảm đáng kể thời gian đào tạo mà không có sự khác biệt về chi phí đào tạo tổng thể.
Kết luận
Park Sang-min (Trưởng nhóm công nghệ phục vụ Vision AI) từ Phòng thí nghiệm AI2XL tại Trung tâm công nghệ hội tụ của KT nhận xét về việc hợp tác với AWS để phát triển mô hình Thẻ thực phẩm AI:
“Gần đây, khi có nhiều mô hình dựa trên máy biến áp hơn trong lĩnh vực thị giác, các thông số mô hình và bộ nhớ GPU yêu cầu ngày càng tăng. Chúng tôi đang sử dụng công nghệ nhẹ để giải quyết vấn đề này và phải mất rất nhiều thời gian, khoảng một tháng để tìm hiểu một lần. Thông qua PoC này với AWS, chúng tôi có thể xác định các tắc nghẽn tài nguyên với sự trợ giúp của SageMaker Profiler và Debugger, giải quyết chúng, sau đó sử dụng thư viện song song dữ liệu của SageMaker để hoàn thành khóa đào tạo trong khoảng một ngày với mã mô hình được tối ưu hóa trên bốn ml.p4d. phiên bản 24xlarge.”
SageMaker đã giúp nhóm của Sang-min tiết kiệm hàng tuần thời gian đào tạo và phát triển mô hình.
Dựa trên sự hợp tác trên mô hình tầm nhìn này, AWS và nhóm SageMaker sẽ tiếp tục cộng tác với KT trong nhiều dự án nghiên cứu AI/ML khác nhau để cải thiện việc phát triển mô hình và năng suất dịch vụ thông qua việc áp dụng các khả năng của SageMaker.
Để tìm hiểu thêm về các tính năng liên quan trong SageMaker, hãy xem phần sau:
Giới thiệu về tác giả
 Choi Youngjoon, AI/ML Expert SA, đã có kinh nghiệm về CNTT doanh nghiệp trong nhiều ngành khác nhau như sản xuất, công nghệ cao và tài chính với tư cách là nhà phát triển, kiến trúc sư và nhà khoa học dữ liệu. Ông đã tiến hành nghiên cứu về học máy và học sâu, đặc biệt về các chủ đề như tối ưu hóa siêu tham số và điều chỉnh miền, trình bày các thuật toán và bài viết. Tại AWS, anh ấy chuyên về AI/ML trong nhiều ngành, cung cấp dịch vụ xác thực kỹ thuật bằng dịch vụ AWS cho các mô hình đào tạo phân tán/quy mô lớn và xây dựng MLO. Ông đề xuất và đánh giá các kiến trúc nhằm góp phần mở rộng hệ sinh thái AI/ML.
Choi Youngjoon, AI/ML Expert SA, đã có kinh nghiệm về CNTT doanh nghiệp trong nhiều ngành khác nhau như sản xuất, công nghệ cao và tài chính với tư cách là nhà phát triển, kiến trúc sư và nhà khoa học dữ liệu. Ông đã tiến hành nghiên cứu về học máy và học sâu, đặc biệt về các chủ đề như tối ưu hóa siêu tham số và điều chỉnh miền, trình bày các thuật toán và bài viết. Tại AWS, anh ấy chuyên về AI/ML trong nhiều ngành, cung cấp dịch vụ xác thực kỹ thuật bằng dịch vụ AWS cho các mô hình đào tạo phân tán/quy mô lớn và xây dựng MLO. Ông đề xuất và đánh giá các kiến trúc nhằm góp phần mở rộng hệ sinh thái AI/ML.
 Jung Hoon Kim là tài khoản SA của AWS Hàn Quốc. Dựa trên kinh nghiệm thiết kế, phát triển kiến trúc ứng dụng và lập mô hình hệ thống trong các ngành khác nhau như công nghệ cao, sản xuất, tài chính và khu vực công, anh đang nghiên cứu tối ưu hóa hành trình và khối lượng công việc trên Đám mây AWS cho khách hàng doanh nghiệp.
Jung Hoon Kim là tài khoản SA của AWS Hàn Quốc. Dựa trên kinh nghiệm thiết kế, phát triển kiến trúc ứng dụng và lập mô hình hệ thống trong các ngành khác nhau như công nghệ cao, sản xuất, tài chính và khu vực công, anh đang nghiên cứu tối ưu hóa hành trình và khối lượng công việc trên Đám mây AWS cho khách hàng doanh nghiệp.
 Đá Sakong là nhà nghiên cứu tại KT R&D. Anh ấy đã tiến hành nghiên cứu và phát triển AI thị giác trong nhiều lĩnh vực khác nhau và chủ yếu tiến hành các thuộc tính khuôn mặt (giới tính/kính, mũ, v.v.)/công nghệ nhận dạng khuôn mặt liên quan đến khuôn mặt. Hiện tại, anh đang nghiên cứu công nghệ nhẹ cho các mô hình thị giác.
Đá Sakong là nhà nghiên cứu tại KT R&D. Anh ấy đã tiến hành nghiên cứu và phát triển AI thị giác trong nhiều lĩnh vực khác nhau và chủ yếu tiến hành các thuộc tính khuôn mặt (giới tính/kính, mũ, v.v.)/công nghệ nhận dạng khuôn mặt liên quan đến khuôn mặt. Hiện tại, anh đang nghiên cứu công nghệ nhẹ cho các mô hình thị giác.
 Manoj Ravi là Giám đốc sản phẩm cấp cao của Amazon SageMaker. Anh ấy đam mê xây dựng các sản phẩm AI thế hệ tiếp theo và làm việc trên phần mềm cũng như công cụ để giúp việc học máy trên quy mô lớn trở nên dễ dàng hơn cho khách hàng. Ông có bằng MBA của Trường Kinh doanh Haas và bằng Thạc sĩ Quản lý Hệ thống Thông tin của Đại học Carnegie Mellon. Trong thời gian rảnh rỗi, Manoj thích chơi quần vợt và theo đuổi nhiếp ảnh phong cảnh.
Manoj Ravi là Giám đốc sản phẩm cấp cao của Amazon SageMaker. Anh ấy đam mê xây dựng các sản phẩm AI thế hệ tiếp theo và làm việc trên phần mềm cũng như công cụ để giúp việc học máy trên quy mô lớn trở nên dễ dàng hơn cho khách hàng. Ông có bằng MBA của Trường Kinh doanh Haas và bằng Thạc sĩ Quản lý Hệ thống Thông tin của Đại học Carnegie Mellon. Trong thời gian rảnh rỗi, Manoj thích chơi quần vợt và theo đuổi nhiếp ảnh phong cảnh.
 Robert Van Dusen là Giám đốc sản phẩm cấp cao của Amazon SageMaker. Ông lãnh đạo các khung, trình biên dịch và kỹ thuật tối ưu hóa cho đào tạo deep learning.
Robert Van Dusen là Giám đốc sản phẩm cấp cao của Amazon SageMaker. Ông lãnh đạo các khung, trình biên dịch và kỹ thuật tối ưu hóa cho đào tạo deep learning.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/kts-journey-to-reduce-training-time-for-a-vision-transformers-model-using-amazon-sagemaker/

