Mặc dù việc áp dụng LLM dường như không thể ngăn cản được trong các ngành, nhưng chúng vẫn là một thành phần của hệ sinh thái công nghệ rộng lớn hơn đang thúc đẩy làn sóng AI mới. Nhiều trường hợp sử dụng AI đàm thoại yêu cầu LLM như Llama 2, Flan T5 và Bloom để trả lời các truy vấn của người dùng. Những mô hình này dựa vào kiến thức tham số để trả lời các câu hỏi. Mô hình học kiến thức này trong quá trình đào tạo và mã hóa nó thành các tham số của mô hình. Để cập nhật kiến thức này, chúng ta phải đào tạo lại LLM, việc này tốn rất nhiều thời gian và tiền bạc.
May mắn thay, chúng tôi cũng có thể sử dụng kiến thức nguồn để thông báo cho LLM của mình. Kiến thức nguồn là thông tin được đưa vào LLM thông qua lời nhắc đầu vào. Một cách tiếp cận phổ biến để cung cấp kiến thức nguồn là Thế hệ tăng cường truy xuất (RAG). Bằng cách sử dụng RAG, chúng tôi truy xuất thông tin liên quan từ nguồn dữ liệu bên ngoài và cung cấp thông tin đó vào LLM.
Trong bài đăng blog này, chúng ta sẽ khám phá cách triển khai các LLM như Llama-2 bằng cách sử dụng Amazon Sagemaker JumpStart và cập nhật các LLM của chúng tôi với thông tin liên quan thông qua Thế hệ tăng cường truy xuất (RAG) bằng cơ sở dữ liệu vectơ Pinecone để ngăn ảo giác AI .
Truy xuất thế hệ tăng cường (RAG) trong Amazon SageMaker
Pinecone sẽ xử lý thành phần truy xuất của RAG, nhưng bạn cần thêm hai thành phần quan trọng hơn: nơi nào đó để chạy suy luận LLM và nơi nào đó để chạy mô hình nhúng.
Amazon SageMaker Studio là một môi trường phát triển tích hợp (IDE) cung cấp một giao diện trực quan dựa trên web duy nhất nơi bạn có thể truy cập các công cụ chuyên dụng để thực hiện mọi hoạt động phát triển máy học (ML). Nó cung cấp SageMaker JumpStart, một trung tâm mô hình nơi người dùng có thể định vị, xem trước và khởi chạy một mô hình cụ thể trong tài khoản SageMaker của riêng họ. Nó cung cấp các mô hình được đào tạo trước, công khai và độc quyền cho nhiều loại vấn đề, bao gồm cả Mô hình nền tảng.
Amazon SageMaker Studio cung cấp môi trường lý tưởng để phát triển quy trình LLM hỗ trợ RAG. Trước tiên, bằng cách sử dụng bảng điều khiển AWS, hãy truy cập Amazon SageMaker và tạo miền SageMaker Studio rồi mở sổ ghi chép Jupyter Studio.
Điều kiện tiên quyết
Hoàn thành các bước điều kiện tiên quyết sau:
- Thiết lập Amazon SageMaker Studio.
- Tham gia vào Miền Amazon SageMaker.
- Đăng ký Cơ sở dữ liệu Vector Pinecone miễn phí.
- Thư viện tiên quyết: SageMaker Python SDK, Pinecone Client
Hướng dẫn giải pháp
Sử dụng sổ ghi chép SageMaker Studio, trước tiên chúng tôi cần cài đặt các thư viện tiên quyết:
Triển khai LLM
Trong bài đăng này, chúng tôi thảo luận về hai cách tiếp cận để triển khai LLM. Đầu tiên là thông qua HuggingFaceModel sự vật. Bạn có thể sử dụng điều này khi triển khai LLM (và nhúng mô hình) trực tiếp từ trung tâm mô hình Ôm Mặt.
Ví dụ: bạn có thể tạo cấu hình có thể triển khai cho google/flan-t5-xl mô hình như trong ảnh chụp màn hình sau:
Khi triển khai các mô hình trực tiếp từ Ôm Mặt, hãy khởi tạo my_model_configuration với những điều sau đây:
- An
envconfig cho chúng tôi biết chúng tôi muốn sử dụng mô hình nào và cho nhiệm vụ gì. - Việc thực thi SageMaker của chúng tôi
rolecấp cho chúng tôi quyền triển khai mô hình của mình. - An
image_urilà cấu hình hình ảnh dành riêng cho việc triển khai LLM từ Ôm mặt.
Ngoài ra, SageMaker có một bộ mô hình tương thích trực tiếp với một mô hình đơn giản hơn JumpStartModel sự vật. Nhiều LLM phổ biến như Llama 2 được mô hình này hỗ trợ, có thể được khởi tạo như trong ảnh chụp màn hình sau:
Đối với cả hai phiên bản của my_model, hãy triển khai chúng như trong ảnh chụp màn hình sau:
Với điểm cuối LLM khởi tạo của chúng tôi, bạn có thể bắt đầu truy vấn. Định dạng truy vấn của chúng tôi có thể khác nhau (đặc biệt là giữa LLM đàm thoại và không đàm thoại), nhưng quy trình nói chung là giống nhau. Đối với mô hình Ôm Mặt, hãy làm như sau:
Bạn có thể tìm thấy giải pháp trong Kho GitHub.
Câu trả lời được tạo ra mà chúng tôi nhận được ở đây không có nhiều ý nghĩa - đó là ảo giác.
Cung cấp bối cảnh bổ sung cho LLM
Llama 2 cố gắng trả lời câu hỏi của chúng tôi chỉ dựa trên kiến thức tham số nội bộ. Rõ ràng, các tham số mô hình không lưu trữ kiến thức về những trường hợp chúng tôi có thể lưu trữ với hoạt động đào tạo tại chỗ được quản lý trong SageMaker.
Để trả lời chính xác câu hỏi này, chúng ta phải sử dụng kiến thức nguồn. Nghĩa là, chúng tôi cung cấp thông tin bổ sung cho LLM thông qua lời nhắc. Hãy thêm thông tin đó trực tiếp làm bối cảnh bổ sung cho mô hình.
Bây giờ chúng ta thấy câu trả lời đúng cho câu hỏi; điều đó thật dễ dàng! Tuy nhiên, người dùng khó có thể chèn ngữ cảnh vào lời nhắc của họ, họ đã biết câu trả lời cho câu hỏi của mình.
Thay vì chèn thủ công một ngữ cảnh, hãy tự động xác định thông tin liên quan từ cơ sở dữ liệu thông tin phong phú hơn. Để làm được điều đó, bạn sẽ cần Thế hệ tăng cường truy xuất.
Truy xuất thế hệ tăng cường
Với Thế hệ tăng cường truy xuất, bạn có thể mã hóa cơ sở dữ liệu thông tin vào không gian vectơ trong đó khoảng cách giữa các vectơ thể hiện mức độ liên quan/tương tự về ngữ nghĩa của chúng. Với không gian vectơ này làm cơ sở kiến thức, bạn có thể chuyển đổi một truy vấn người dùng mới, mã hóa nó thành cùng một không gian vectơ và truy xuất các bản ghi phù hợp nhất đã được lập chỉ mục trước đó.
Sau khi truy xuất các bản ghi có liên quan này, hãy chọn một vài bản ghi trong số chúng và đưa chúng vào lời nhắc LLM làm ngữ cảnh bổ sung, cung cấp cho LLM kiến thức nguồn có liên quan cao. Đây là một quá trình gồm hai bước trong đó:
- Lập chỉ mục điền chỉ mục vectơ với thông tin từ tập dữ liệu.
- Quá trình truy xuất diễn ra trong quá trình truy vấn và là nơi chúng tôi truy xuất thông tin liên quan từ chỉ mục vectơ.
Cả hai bước đều yêu cầu một mô hình nhúng để dịch văn bản thuần túy mà con người có thể đọc được sang không gian vectơ ngữ nghĩa. Sử dụng công cụ chuyển đổi câu MiniLM hiệu quả cao từ Ôm mặt như trong ảnh chụp màn hình sau. Mô hình này không phải là LLM và do đó không được khởi tạo giống như mô hình Llama 2 của chúng tôi.
Trong tạp chí hub_config, chỉ định ID mô hình như được hiển thị trong ảnh chụp màn hình ở trên nhưng đối với tác vụ, hãy sử dụng trích xuất tính năng vì chúng tôi đang tạo các nhúng vectơ chứ không phải văn bản như LLM của chúng tôi. Theo đó, khởi tạo cấu hình mô hình với HuggingFaceModel như trước, nhưng lần này không có hình ảnh LLM và có một số thông số phiên bản.
Bạn có thể triển khai lại mô hình với deploy, sử dụng phiên bản nhỏ hơn (chỉ CPU) của ml.t2.large. Mô hình MiniLM rất nhỏ nên không cần nhiều bộ nhớ và không cần GPU vì nó có thể nhanh chóng tạo các phần nhúng ngay cả trên CPU. Nếu muốn, bạn có thể chạy mô hình nhanh hơn trên GPU.
Để tạo phần nhúng, hãy sử dụng predict phương thức và chuyển danh sách các ngữ cảnh để mã hóa thông qua inputs phím như hình:
Hai bối cảnh đầu vào được truyền, trả về hai phần nhúng vectơ bối cảnh như được hiển thị:
len(out)
2
Chiều nhúng của mô hình MiniLM là 384 có nghĩa là mỗi vectơ nhúng đầu ra MiniLM phải có chiều là 384. Tuy nhiên, nhìn vào độ dài nhúng của chúng tôi, bạn sẽ thấy như sau:
len(out[0]), len(out[1])
(8, 8)
Hai danh sách mỗi danh sách chứa tám mục. MiniLM trước tiên xử lý văn bản trong bước mã thông báo. Mã thông báo này biến văn bản thuần túy mà con người có thể đọc được của chúng tôi thành danh sách ID mã thông báo có thể đọc được bằng mô hình. Trong các tính năng đầu ra của mô hình, bạn có thể thấy các phần nhúng ở cấp độ mã thông báo. một trong những phần nhúng này cho thấy chiều hướng dự kiến của 384 như hình:
len(out[0][0])
384
Chuyển đổi các nội dung nhúng ở cấp độ mã thông báo này thành các nội dung nhúng ở cấp độ tài liệu bằng cách sử dụng các giá trị trung bình trên từng thứ nguyên vectơ, như minh họa trong hình minh họa sau.

Hoạt động gộp trung bình để có được một vectơ 384 chiều.
Với hai phần nhúng vectơ 384 chiều, một phần cho mỗi văn bản đầu vào. Để làm cho cuộc sống của chúng ta dễ dàng hơn, hãy gói quy trình mã hóa thành một chức năng duy nhất như trong ảnh chụp màn hình sau:
Đang tải xuống bộ dữ liệu
Tải xuống Câu hỏi thường gặp về Amazon SageMaker làm cơ sở kiến thức để lấy dữ liệu chứa cả cột câu hỏi và câu trả lời.

Tải xuống Câu hỏi thường gặp về Amazon SageMaker
Khi thực hiện tìm kiếm, chỉ tìm Câu trả lời để bạn có thể bỏ cột Câu hỏi. Xem sổ ghi chép để biết chi tiết.
Tập dữ liệu của chúng tôi và đường dẫn nhúng đã sẵn sàng. Bây giờ tất cả những gì chúng ta cần là một nơi nào đó để lưu trữ những phần nhúng đó.
Lập chỉ mục
Cơ sở dữ liệu vectơ Pinecone lưu trữ các phần nhúng vectơ và tìm kiếm chúng một cách hiệu quả trên quy mô lớn. Để tạo cơ sở dữ liệu, bạn sẽ cần khóa API miễn phí từ Pinecone.
Sau khi bạn đã kết nối với cơ sở dữ liệu vectơ Pinecone, hãy tạo một chỉ mục vectơ duy nhất (tương tự như bảng trong DB truyền thống). Đặt tên cho chỉ mục retrieval-augmentation-aws và căn chỉnh chỉ số dimension và metric các tham số theo yêu cầu của mô hình nhúng (MiniLM trong trường hợp này).
Để bắt đầu chèn dữ liệu, hãy chạy như sau:
Bạn có thể bắt đầu truy vấn chỉ mục bằng câu hỏi ở phần trước của bài đăng này.
Kết quả đầu ra ở trên cho thấy rằng chúng tôi đang trả lại các bối cảnh có liên quan để giúp chúng tôi trả lời câu hỏi của mình. Vì chúng tôi top_k = 1, index.query trả về kết quả hàng đầu cùng với siêu dữ liệu có nội dung Managed Spot Training can be used with all instances supported in Amazon.
Tăng cường lời nhắc
Sử dụng ngữ cảnh được truy xuất để tăng cường lời nhắc và quyết định số lượng ngữ cảnh tối đa để đưa vào LLM. Sử dụng 1000 giới hạn ký tự để lặp lại thêm từng ngữ cảnh được trả về vào lời nhắc cho đến khi bạn vượt quá độ dài nội dung.
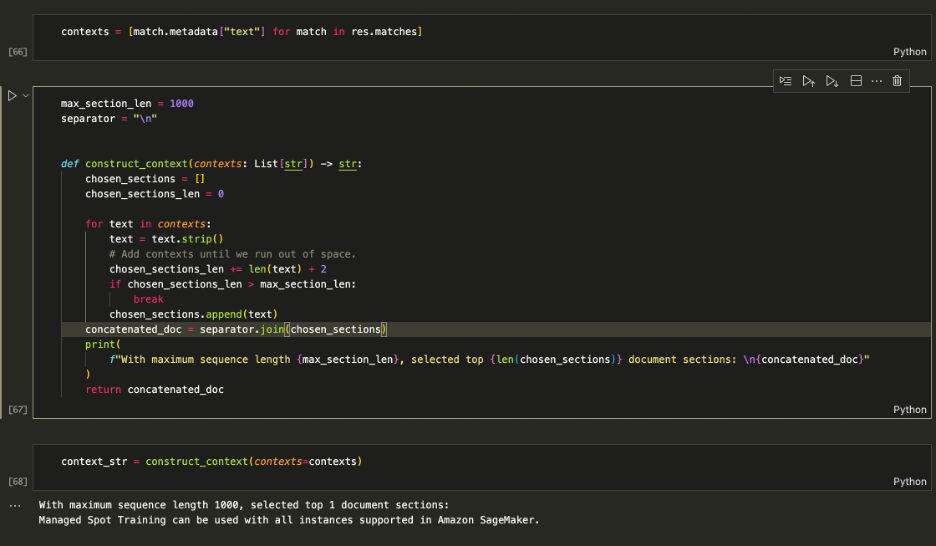
Tăng cường lời nhắc
Nuôi context_str vào dấu nhắc LLM như trong ảnh chụp màn hình sau:
[Đầu vào]: Tôi có thể sử dụng phiên bản nào với Managed Spot Training trong SageMaker? [Đầu ra]: Dựa trên ngữ cảnh được cung cấp, bạn có thể sử dụng Đào tạo tại chỗ được quản lý với tất cả các phiên bản được hỗ trợ trong Amazon SageMaker. Do đó, câu trả lời là: Tất cả các phiên bản đều được hỗ trợ trong Amazon SageMaker.
Logic hoạt động nên hãy gói gọn nó thành một chức năng duy nhất để giữ mọi thứ gọn gàng.
Bây giờ bạn có thể đặt câu hỏi giống như những câu hỏi được hiển thị sau đây:
Làm sạch
Để ngừng phát sinh mọi khoản phí không mong muốn, hãy xóa mô hình và điểm cuối.
Kết luận
Trong bài đăng này, chúng tôi đã giới thiệu cho bạn về RAG với LLM truy cập mở trên SageMaker. Chúng tôi cũng đã trình bày cách triển khai các mô hình Khởi động Amazon SageMaker với Llama 2, LLM ôm mặt với Flan T5 và nhúng các mô hình với MiniLM.
Chúng tôi đã triển khai một đường dẫn RAG từ đầu đến cuối hoàn chỉnh bằng cách sử dụng các mô hình truy cập mở và chỉ mục vectơ Pinecone. Bằng cách sử dụng điều này, chúng tôi đã chỉ ra cách giảm thiểu ảo giác và cập nhật kiến thức LLM, đồng thời cuối cùng là nâng cao trải nghiệm người dùng và sự tin tưởng vào hệ thống của chúng tôi.
Để tự chạy ví dụ này, hãy sao chép kho lưu trữ GitHub này và hướng dẫn các bước trước đó bằng cách sử dụng Sổ tay trả lời câu hỏi trên GitHub.
Giới thiệu về tác giả
 Vedant Jain là Chuyên gia AI/ML cấp cao, làm việc về các sáng kiến AI sáng tạo mang tính chiến lược. Trước khi gia nhập AWS, Vedant đã giữ các vị trí Chuyên môn ML/Khoa học dữ liệu tại nhiều công ty khác nhau như Databricks, Hortonworks (nay là Cloudera) & JP Morgan Chase. Ngoài công việc của mình, Vedant còn đam mê sáng tác âm nhạc, leo núi, sử dụng khoa học để có một cuộc sống ý nghĩa và khám phá ẩm thực từ khắp nơi trên thế giới.
Vedant Jain là Chuyên gia AI/ML cấp cao, làm việc về các sáng kiến AI sáng tạo mang tính chiến lược. Trước khi gia nhập AWS, Vedant đã giữ các vị trí Chuyên môn ML/Khoa học dữ liệu tại nhiều công ty khác nhau như Databricks, Hortonworks (nay là Cloudera) & JP Morgan Chase. Ngoài công việc của mình, Vedant còn đam mê sáng tác âm nhạc, leo núi, sử dụng khoa học để có một cuộc sống ý nghĩa và khám phá ẩm thực từ khắp nơi trên thế giới.
 James Briggs là Người hỗ trợ Nhà phát triển Nhân viên tại Pinecone, chuyên về tìm kiếm vectơ và AI/ML. Ông hướng dẫn các nhà phát triển và doanh nghiệp phát triển giải pháp GenAI của riêng họ thông qua giáo dục trực tuyến. Trước Pinecone, James đã làm việc về AI cho các công ty khởi nghiệp công nghệ nhỏ cho đến các tập đoàn tài chính đã thành lập. Ngoài công việc, James có niềm đam mê du lịch và đón nhận những cuộc phiêu lưu mới, từ lướt sóng và lặn biển đến Muay Thái và BJJ.
James Briggs là Người hỗ trợ Nhà phát triển Nhân viên tại Pinecone, chuyên về tìm kiếm vectơ và AI/ML. Ông hướng dẫn các nhà phát triển và doanh nghiệp phát triển giải pháp GenAI của riêng họ thông qua giáo dục trực tuyến. Trước Pinecone, James đã làm việc về AI cho các công ty khởi nghiệp công nghệ nhỏ cho đến các tập đoàn tài chính đã thành lập. Ngoài công việc, James có niềm đam mê du lịch và đón nhận những cuộc phiêu lưu mới, từ lướt sóng và lặn biển đến Muay Thái và BJJ.
 Tân Hoàng là Nhà khoa học ứng dụng cấp cao cho Amazon SageMaker JumpStart và các thuật toán tích hợp sẵn của Amazon SageMaker. Anh ấy tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số. Ông đã xuất bản nhiều bài báo tại các hội nghị ACL, ICDM, KDD và Hiệp hội Thống kê Hoàng gia: Series A.
Tân Hoàng là Nhà khoa học ứng dụng cấp cao cho Amazon SageMaker JumpStart và các thuật toán tích hợp sẵn của Amazon SageMaker. Anh ấy tập trung vào việc phát triển các thuật toán học máy có thể mở rộng. Mối quan tâm nghiên cứu của ông là trong lĩnh vực xử lý ngôn ngữ tự nhiên, học sâu có thể giải thích được trên dữ liệu dạng bảng và phân tích mạnh mẽ về phân cụm không-thời gian phi tham số. Ông đã xuất bản nhiều bài báo tại các hội nghị ACL, ICDM, KDD và Hiệp hội Thống kê Hoàng gia: Series A.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/mitigate-hallucinations-through-retrieval-augmented-generation-using-pinecone-vector-database-llama-2-from-amazon-sagemaker-jumpstart/

