Giới thiệu
ChatGPT
Trong bối cảnh năng động của doanh nghiệp hiện đại, sự giao thoa giữa học máy và vận hành (MLOps) đã nổi lên như một động lực mạnh mẽ, định hình lại các phương pháp tiếp cận truyền thống để tối ưu hóa chuyển đổi bán hàng. Bài viết sẽ đưa bạn vào vai trò biến đổi mà chiến lược MLOps đóng trong việc cách mạng hóa thành công chuyển đổi bán hàng. Khi các doanh nghiệp cố gắng nâng cao hiệu quả và tăng cường tương tác với khách hàng, việc tích hợp các kỹ thuật máy học vào hoạt động sẽ chiếm vị trí trung tâm. Cuộc khám phá này tiết lộ các chiến lược đổi mới thúc đẩy MLOps để không chỉ hợp lý hóa quy trình bán hàng mà còn mở ra thành công chưa từng có trong việc chuyển đổi khách hàng tiềm năng thành khách hàng trung thành. Hãy tham gia cùng chúng tôi trong cuộc hành trình xuyên qua những phức tạp của MLOps và khám phá cách ứng dụng chiến lược của nó đang định hình lại bối cảnh chuyển đổi doanh số bán hàng.
Mục tiêu học tập
- Tầm quan trọng của mô hình tối ưu hóa bán hàng
- Làm sạch dữ liệu, chuyển đổi tập dữ liệu và tiền xử lý tập dữ liệu
- Xây dựng tính năng phát hiện gian lận toàn diện bằng Kedro và Deepcheck
- Triển khai mô hình sử dụng Streamlit và ôm mặt
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Mô hình tối ưu hóa bán hàng là gì?
Mô hình tối ưu hóa bán hàng là mô hình học máy từ đầu đến cuối nhằm tối đa hóa doanh số bán sản phẩm và cải thiện tỷ lệ chuyển đổi. Mô hình lấy một số thông số làm đầu vào như số lần hiển thị, nhóm tuổi, giới tính, Tỷ lệ nhấp và Giá mỗi lần nhấp. Sau khi bạn đào tạo, mô hình sẽ dự đoán số lượng người sẽ mua sản phẩm sau khi xem quảng cáo.
Điều kiện tiên quyết cần thiết
1) Sao chép kho lưu trữ
git clone https://github.com/ashishk831/Final-THC.git
cd Final-THC2) Tạo và kích hoạt môi trường ảo
#create a virtual environment
python3 -m venv SOP
#Activate your virtual environment in your project folder
source SOP/bin/activate
pip install -r requirements.txt4)Cài đặt Kedro, Kedro-viz, Streamlit và Deepcheck
pip install streamlit
pip install Deepcheck
pip install Kedro
pip install Kedro-vizmô tả dữ liệu
Hãy để chúng tôi thực hiện Phân tích dữ liệu cơ bản bằng cách sử dụng triển khai Python trên tập dữ liệu từ Kaggle. Để tải xuống tập dữ liệu, hãy nhấp vào tại đây.
import pandas as pd
import numpy as np
df = pd.read_csv('KAG_conversion_data.csv')
df.head()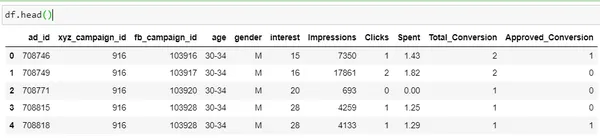
| Cột | Mô tả |
| ad_id | ID duy nhất cho mỗi quảng cáo |
| xyz_chiến dịch_id | ID được liên kết với từng chiến dịch quảng cáo của công ty XYZ |
| fb_chiến dịch_id | ID liên quan đến cách Facebook theo dõi từng chiến dịch |
| tuổi | Độ tuổi của người được hiển thị quảng cáo |
| giới | Giới tính của người muốn thêm được hiển thị |
| quan tâm | một mã chỉ định danh mục sở thích của người đó (sở thích được đề cập trong hồ sơ công khai trên Facebook của người đó) |
| Ấn tượng | số lần quảng cáo được hiển thị. |
| Nhấp chuột | Số lần nhấp chuột vào quảng cáo đó. |
| Bỏ ra | Số tiền mà công ty xyz trả cho Facebook để hiển thị quảng cáo đó |
| Tổng số: Chuyển đổi |
Tổng số: số người hỏi về sản phẩm sau khi xem quảng cáo |
| Được chấp thuận Chuyển đổi |
Tổng số: số người đã mua sản phẩm sau khi xem quảng cáo |
Đây là “Chuyển đổi được phê duyệt” là cột mục tiêu. Của chúng tôi
Mục tiêu là thiết kế một mô hình giúp tăng doanh số bán sản phẩm khi mọi người nhìn thấy
quảng cáo.
Phát triển mô hình bằng Kedro
Để xây dựng dự án này từ đầu đến cuối, chúng tôi sẽ sử dụng công cụ Kedro. Kedro, là một công cụ nguồn mở được sử dụng để xây dựng mô hình máy học sẵn sàng sản xuất, mang lại một số lợi ích.
- Xử lý sự phức tạp: Nó cung cấp một cấu trúc để kiểm tra dữ liệu có thể được đưa vào sản xuất sau khi thử nghiệm thành công.
- Tiêu chuẩn hoá: Nó cung cấp mẫu tiêu chuẩn cho dự án. Làm cho người khác dễ hiểu hơn.
- Sản xuất-Sẵn sàng: Mã có thể dễ dàng được đưa vào sản xuất với mã khám phá mà bạn có thể chuyển đổi sang các thử nghiệm mô-đun, có thể duy trì và tái tạo.
Tìm hiểu thêm: Hướng dẫn sử dụng Kedro Framework
Cấu trúc đường ống
Để tạo một dự án trong Kedro, hãy làm theo các bước dưới đây.
#create project
kedro new
#create pipeline
kedro pipeline create <pipeline-name>
#Run kedro
kedro run
#Visualizing pipeline
kedro vizSử dụng kedro, chúng tôi sẽ thiết kế đường dẫn mô hình từ đầu đến cuối như hiển thị bên dưới.
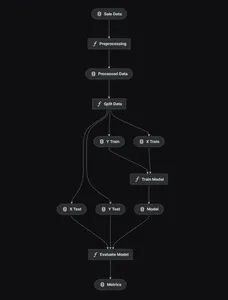
Xử lý dữ liệu
- Kiểm tra các giá trị còn thiếu và xử lý chúng.
- Tạo hai cột mới CTR và CPC.
- Chuyển đổi biến cột thành số.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
def preprocessing(data: pd.DataFrame):
data.gender = data.gender.apply(lambda x: 1 if x=="M" else 0)
data['CTR'] = ((data['Clicks']/data['Impressions'])*100)
data['CPC'] = data['Spent']/data['Clicks']
data['CPC'] = data['CPC'].replace(np.nan,0)
encoder=LabelEncoder()
encoder.fit(data["age"])
data["age"]=encoder.transform(data["age"])
#data.Approved_Conversion = data.Approved_Conversion.apply(lambda x: 0 if x==0 else 1)
preprocessed_data = data.copy()
return preprocessed_dataTách dữ liệu
import pandas as pd
from sklearn.model_selection import train_test_split
def split_data(processed_data: pd.DataFrame):
X = processed_data[['ad_id', 'age', 'gender', 'interest', 'Spent',
'Total_Conversion','CTR', 'CPC']]
y = processed_data["Approved_Conversion"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1,
random_state=42)
return X_train, X_test, y_train, y_testỞ trên tập dữ liệu được chia thành tập dữ liệu huấn luyện và tập dữ liệu thử nghiệm cho mục đích huấn luyện mô hình.
Đào tạo người mẫu
from sklearn.ensemble import RandomForestRegressor
def train_model(X_train, y_train):
model = RandomForestRegressor(n_estimators = 50, random_state = 0, max_samples=0.75)
model.fit(X_train, y_train)
return model
Chúng tôi sẽ sử dụng mô-đun RandomForestRegressor để đào tạo mô hình. Riêng với RandomForestRegressor, chúng tôi đang chuyển tham số khác như n_estimators ngẫu nhiên_state và max_samples.
Đánh giá
import numpy as np
import logging
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, max_error
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
mse=mean_squared_error(y_test, y_pred)
rmse=np.sqrt(mse)
r2score=r2_score(y_test, y_pred)
me = max_error(y_test, y_pred)
print("MAE Of Model is: ",mae)
print("MSE Of Model is: ",mse)
print("RMSE Of Model is: ",rmse)
print("R2_Score Of Model is: ",r2score)
logger = logging.getLogger(__name__)
logger.info("Model has a coefficient R^2 of %.3f on test data.", r2score)
return {"r2_score": r2score, "mae": mae, "max_error": me}Sau khi đào tạo mô hình, mô hình sẽ được đánh giá bằng cách sử dụng một số số liệu chính như MAE, MSE, RMSE và điểm R2.
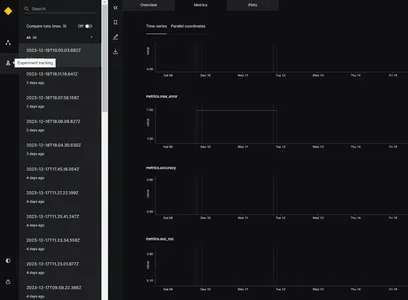
Trình theo dõi thí nghiệm
Để theo dõi hiệu suất của mô hình và chọn mô hình tốt nhất, chúng tôi sẽ sử dụng trình theo dõi thử nghiệm. Chức năng của trình theo dõi thử nghiệm là lưu tất cả thông tin về thử nghiệm khi ứng dụng được chạy. Để bật trình theo dõi thử nghiệm trong Kedro, chúng tôi có thể cập nhật tệp catalog.xml. Thông số được phiên bản cần phải được đặt Đúng. Dưới đây là ví dụ
model:
type: pickle.PickleDataSet
filepath: data/06_models/model.pkl
backend: pickle
versioned: TrueĐiều này giúp theo dõi kết quả mô hình và lưu phiên bản mô hình. Ở đây, chúng tôi sẽ sử dụng trình theo dõi thử nghiệm ở bước đánh giá để theo dõi hiệu suất của mô hình trong giai đoạn phát triển.
Khi mô hình được thực thi, nó sẽ tạo ra các số liệu đánh giá khác nhau như điểm MAE, MSE, RMSE và R2 cho dấu thời gian khác nhau như hiển thị trong hình ảnh. Trên cơ sở các số liệu đánh giá trên, mô hình tốt nhất có thể được lựa chọn.
Deepcheck: Để giám sát dữ liệu và mô hình
Khi mô hình được triển khai trong sản xuất, có khả năng chất lượng dữ liệu sẽ thay đổi theo thời gian và do hiệu suất của mô hình này cũng có thể thay đổi. Để khắc phục sự cố này, chúng ta cần theo dõi dữ liệu trong môi trường sản xuất. Để làm điều này, chúng tôi sẽ sử dụng công cụ mã nguồn mở Deepcheck. Deepcheck có các thư viện sẵn có như Label-drift và Feature-Drift có thể dễ dàng tích hợp với mã mô hình.
- FeatureDrift: – Sự trôi dạt có nghĩa là sự thay đổi trong việc phân phối dữ liệu theo thời gian do hiệu suất của mô hình bị suy giảm. FeaturDift có nghĩa là đã xảy ra thay đổi trong một tính năng duy nhất của tập dữ liệu.
- Labeldrift: – Labeldrift xảy ra khi nhãn sự thật cơ bản cho một tập dữ liệu thay đổi theo thời gian. Nó chủ yếu xảy ra do sự thay đổi trong tiêu chí nhãn.
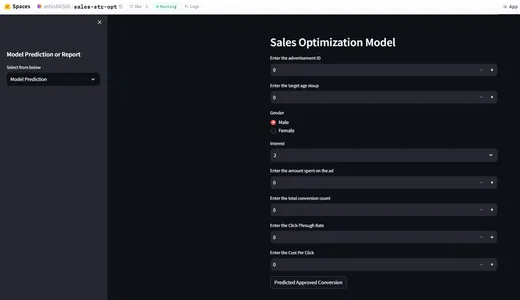
Tích hợp dự đoán và giám sát mô hình với Streamlit
Bây giờ chúng ta sẽ xây dựng giao diện người dùng để tương tác với mô hình đưa ra dự đoán về các tham số đầu vào đã cho nhằm kiểm tra tỷ lệ chuyển đổi.
import streamlit as st
import pandas as pd
import joblib
import numpy as np
st.sidebar.header("Model Prediction or Report")
selected_report = st.sidebar.selectbox("Select from below", ["Model Prediction",
"Data Integrity","Feature Drift", "Label Drift"])
if selected_report=="Model Prediction":
st.header("Sales Optimization Model")
#def predict(ad_id, age, gender, interest, Impressions, Clicks, Spent,
#Total_Conversion, CTR, CPC):
def predict(ad_id, age, gender, interest, Spent, Total_Conversion, CTR, CPC):
if gender == 'Male':
gender = 0
else:
gender = 1
ad_id = int(ad_id)
age = int(age)
gender = int(gender)
interest = int(interest)
#Impressions = int(Impressions)
#Clicks = int(Clicks)
Spent = float(Spent)
Total_Conversion = int(Total_Conversion)
CTR = float(CTR*0.000001)
CPC = float(CPC)
input=np.array([[ad_id, age, gender, interest, Spent,
Total_Conversion, CTR, CPC]]).astype(np.float64)
model = joblib.load('model/model.pkl')
# Make prediction
prediction = model.predict(input)
prediction= np.round(prediction)
# Return the predicted value for Approved_Conversion
return prediction
ad_id = st.number_input('Enter the advertisement ID',min_value = 0)
age = st.number_input('Enter the target age stoup',min_value = 0)
gender = st.radio("Gender",('Male','Female'))
interest = st.selectbox('Interest', [2, 7, 10, 15, 16, 18, 19, 20, 21, 22, 23,
24, 25,
26, 27, 28, 29, 30, 31, 32, 36, 63, 64, 65, 66, 100, 101, 102,
103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114])
#Impressions = st.number_input('Enter the number of impressions',min_value = 0)
#Clicks = st.number_input('Enter the number of clicks',min_value = 0)
Spent = st.number_input('Enter the amount spent on the ad',min_value = 0)
Total_Conversion = st.number_input('Enter the total conversion count',
min_value = 0)
CTR = st.number_input('Enter the Click-Through Rate',min_value = 0)
CPC = st.number_input('Enter the Cost Per Click',min_value = 0)
if st.button("Predicted Approved Conversion"):
output = predict(ad_id, age, gender, interest, Spent, Total_Conversion,
CTR, CPC)
st.success("Approved Conversion Rate :{}".format(output))
else:
st.header("Sales Model Monitoring Report")
report_file_name = "report/"+ selected_report.replace(" ", "") + ".html"
HtmlFile = open(report_file_name, 'r', encoding='utf-8')
source_code = HtmlFile.read()
st.components.v1.html(source_code, width=1200, height=1500, scrolling=True)
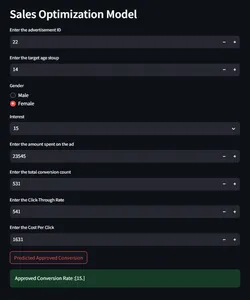
Triển khai bằng HuggingFace
Bây giờ chúng ta đã xây dựng được mô hình tối ưu hóa hoạt động bán hàng từ đầu đến cuối, chúng ta sẽ triển khai mô hình đó bằng HuggingFace. Trong ôm mặt, chúng ta cần định cấu hình tệp README.md để triển khai mô hình. Huggingface chăm sóc CI/CD. Vì bất cứ khi nào có thay đổi trong tệp, nó sẽ theo dõi các thay đổi và triển khai lại ứng dụng. Dưới đây là cấu hình tệp readme.md.
title: {{Sale-str-opt}}
emoji: {{Sale-str-opt}}
colorFrom: {{colorFrom}}
colorTo: {{colorTo}}
sdk: {{sdk}}
sdk_version: {{sdkVersion}}
app_file: app.py
pinned: falseDemo ứng dụng HuggingFace
Đối với phiên bản đám mây, hãy nhấp vào tại đây.
Kết luận
- Các ứng dụng học máy có thể đưa ra tỷ lệ chuyển đổi thử nghiệm ở thị trường chưa xác định, giúp doanh nghiệp biết nhu cầu sản phẩm.
- Việc sử dụng mô hình tối ưu hóa hoạt động kinh doanh có thể nhắm mục tiêu đến nhóm đối tượng phù hợp của họ.
- Ứng dụng này giúp tăng doanh thu kinh doanh.
- Giám sát dữ liệu trong thời gian thực cũng có thể giúp theo dõi sự thay đổi mô hình và thay đổi hành vi của người dùng.
Những câu hỏi thường gặp
A. Mục đích của mô hình tối ưu hóa việc bán hàng là dự đoán số lượng khách hàng sẽ mua sản phẩm sau khi xem quảng cáo.
A. Giám sát dữ liệu giúp theo dõi hành vi của tập dữ liệu và mô hình.
A. Có, ôm mặt được sử dụng miễn phí với tính năng cơ bản 2 vCPU, RAM 16 GB.
A. Không có quy tắc nghiêm ngặt nào cho việc lựa chọn báo cáo ở giai đoạn giám sát mô hình, deepcheck có nhiều thư viện sẵn có như mô hình trôi dạt, sai lệch phân phối.
A. Streamlit giúp triển khai cục bộ, giúp sửa lỗi trong giai đoạn phát triển.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/01/mlops-strategies-for-sales-conversion-success/

