Amazon SageMaker điểm cuối đa mô hình (MME) là khả năng suy luận SageMaker được quản lý hoàn toàn cho phép bạn triển khai hàng nghìn mô hình trên một điểm cuối duy nhất. Trước đây, MME đã xác định trước việc phân bổ sức mạnh tính toán của CPU cho các mô hình một cách tĩnh bất kể tải lưu lượng mô hình, sử dụng Máy chủ đa mô hình (MMS) làm máy chủ mẫu của nó. Trong bài đăng này, chúng tôi thảo luận về giải pháp trong đó MME có thể điều chỉnh linh hoạt công suất tính toán được chỉ định cho từng mô hình dựa trên mẫu lưu lượng của mô hình. Giải pháp này cho phép bạn sử dụng tính toán cơ bản của MME hiệu quả hơn và tiết kiệm chi phí.
MME tải và dỡ tải các mô hình động dựa trên lưu lượng truy cập đến điểm cuối. Khi sử dụng MMS làm máy chủ mô hình, MME sẽ phân bổ một số lượng nhân viên mô hình cố định cho mỗi mô hình. Để biết thêm thông tin, hãy tham khảo Các mẫu lưu trữ mô hình trong Amazon SageMaker, Phần 3: Chạy và tối ưu hóa suy luận đa mô hình với các điểm cuối đa mô hình của Amazon SageMaker.
Tuy nhiên, điều này có thể dẫn đến một số vấn đề khi mô hình lưu lượng truy cập của bạn thay đổi. Giả sử bạn có một hoặc một vài mô hình nhận được lượng truy cập lớn. Bạn có thể định cấu hình MMS để phân bổ số lượng lớn nhân viên cho các mô hình này, nhưng điều này sẽ được chỉ định cho tất cả các mô hình phía sau MME vì đây là cấu hình tĩnh. Điều này dẫn đến một số lượng lớn công nhân sử dụng máy tính phần cứng—ngay cả những mô hình nhàn rỗi. Vấn đề ngược lại có thể xảy ra nếu bạn đặt một giá trị nhỏ cho số lượng công nhân. Các mô hình phổ biến sẽ không có đủ nhân viên ở cấp máy chủ mô hình để phân bổ hợp lý đủ phần cứng đằng sau điểm cuối cho các mô hình này. Vấn đề chính là khó có thể duy trì mô hình lưu lượng truy cập bất khả tri nếu bạn không thể tự động mở rộng quy mô nhân viên của mình ở cấp máy chủ mô hình để phân bổ lượng điện toán cần thiết.
Giải pháp chúng tôi thảo luận trong bài viết này sử dụng DJLPhục vụ làm máy chủ mô hình, có thể giúp giảm thiểu một số vấn đề mà chúng ta đã thảo luận, đồng thời cho phép mở rộng quy mô theo mô hình và cho phép MME trở thành bất khả tri về mẫu lưu lượng truy cập.
Kiến trúc MME
MME SageMaker cho phép bạn triển khai nhiều mô hình đằng sau một điểm cuối suy luận duy nhất có thể chứa một hoặc nhiều phiên bản. Mỗi phiên bản được thiết kế để tải và phục vụ nhiều mô hình tùy theo dung lượng bộ nhớ và CPU/GPU của nó. Với kiến trúc này, doanh nghiệp phần mềm dưới dạng dịch vụ (SaaS) có thể phá vỡ chi phí ngày càng tăng tuyến tính của việc lưu trữ nhiều mô hình và đạt được khả năng tái sử dụng cơ sở hạ tầng phù hợp với mô hình nhiều bên thuê được áp dụng ở nơi khác trong ngăn xếp ứng dụng. Sơ đồ sau minh họa kiến trúc này.
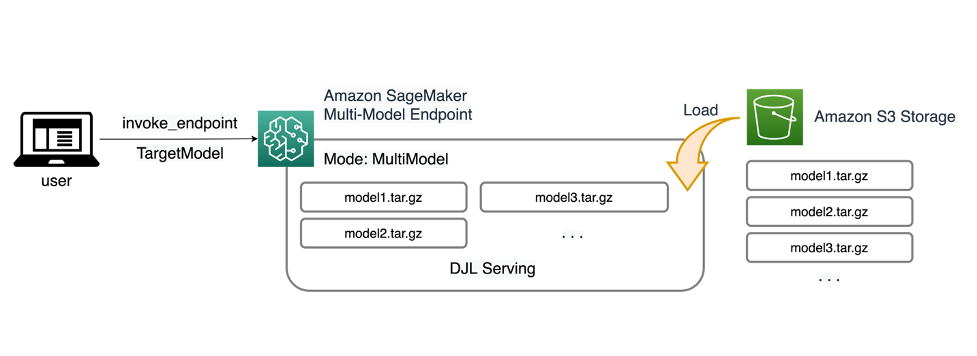
SageMaker MME tải động các mô hình từ Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) khi được gọi, thay vì tải xuống tất cả các mô hình khi điểm cuối được tạo lần đầu tiên. Kết quả là, lệnh gọi mô hình ban đầu có thể có độ trễ suy luận cao hơn so với các lần suy luận tiếp theo được hoàn thành với độ trễ thấp. Nếu mô hình đã được tải trên vùng chứa khi được gọi thì bước tải xuống sẽ bị bỏ qua và mô hình sẽ trả về kết quả suy luận có độ trễ thấp. Ví dụ: giả sử bạn có một mô hình chỉ được sử dụng một vài lần trong ngày. Nó được tải tự động theo yêu cầu, trong khi các mô hình được truy cập thường xuyên sẽ được giữ lại trong bộ nhớ và được gọi với độ trễ thấp nhất quán.
Đằng sau mỗi MME là các phiên bản lưu trữ mô hình, như được mô tả trong sơ đồ sau. Các phiên bản này tải và loại bỏ nhiều mô hình đến và đi từ bộ nhớ dựa trên các mẫu lưu lượng truy cập đến các mô hình.
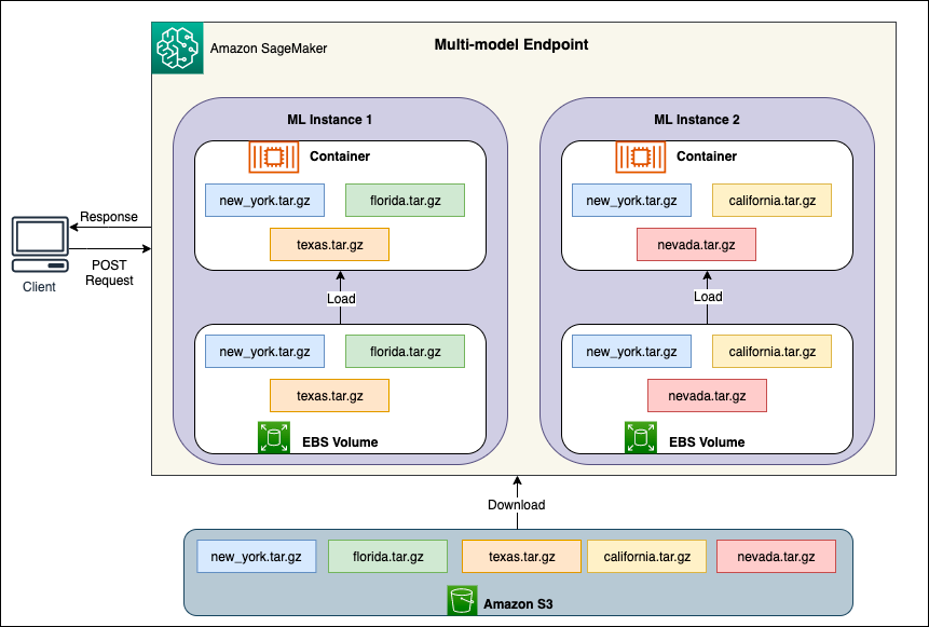
SageMaker tiếp tục định tuyến các yêu cầu suy luận cho một mô hình đến phiên bản mà mô hình đã được tải sao cho các yêu cầu đó được phân phối từ một bản sao mô hình được lưu trong bộ nhớ đệm (xem sơ đồ sau đây, hiển thị đường dẫn yêu cầu cho yêu cầu dự đoán đầu tiên so với dự đoán được lưu trong bộ nhớ đệm đường dẫn yêu cầu). Tuy nhiên, nếu mô hình nhận được nhiều yêu cầu gọi và có thêm phiên bản cho MME, SageMaker sẽ chuyển một số yêu cầu đến phiên bản khác để đáp ứng mức tăng. Để tận dụng khả năng chia tỷ lệ mô hình tự động trong SageMaker, hãy đảm bảo bạn có ví dụ tự động mở rộng thiết lập để cung cấp năng lực phiên bản bổ sung. Thiết lập chính sách chia tỷ lệ cấp điểm cuối của bạn với thông số tùy chỉnh hoặc lệnh gọi mỗi phút (được khuyến nghị) để thêm nhiều phiên bản hơn vào nhóm điểm cuối.

Tổng quan về máy chủ mẫu
Máy chủ mô hình là một thành phần phần mềm cung cấp môi trường thời gian chạy để triển khai và phục vụ các mô hình máy học (ML). Nó hoạt động như một giao diện giữa các mô hình được đào tạo và ứng dụng khách muốn đưa ra dự đoán bằng cách sử dụng các mô hình đó.
Mục đích chính của máy chủ mô hình là cho phép tích hợp dễ dàng và triển khai hiệu quả các mô hình ML vào hệ thống sản xuất. Thay vì nhúng mô hình trực tiếp vào một ứng dụng hoặc một khung cụ thể, máy chủ mô hình cung cấp một nền tảng tập trung nơi nhiều mô hình có thể được triển khai, quản lý và phục vụ.
Máy chủ mô hình thường cung cấp các chức năng sau:
- Tải mô hình – Máy chủ tải các mô hình ML đã được đào tạo vào bộ nhớ, giúp chúng sẵn sàng phục vụ các dự đoán.
- API suy luận – Máy chủ hiển thị API cho phép ứng dụng khách gửi dữ liệu đầu vào và nhận dự đoán từ các mô hình đã triển khai.
- Mở rộng quy mô – Máy chủ mô hình được thiết kế để xử lý các yêu cầu đồng thời từ nhiều máy khách. Chúng cung cấp các cơ chế xử lý song song và quản lý tài nguyên một cách hiệu quả để đảm bảo thông lượng cao và độ trễ thấp.
- Tích hợp với các công cụ phụ trợ – Máy chủ mô hình có tích hợp với các khung phụ trợ như DeepSpeed và FasterTransformer để phân vùng các mô hình lớn và chạy suy luận được tối ưu hóa cao.
Kiến trúc DJL
phục vụ DJL là một máy chủ mô hình phổ quát, mã nguồn mở, hiệu suất cao. Dịch vụ DJL được xây dựng dựa trên Djl, một thư viện deep learning được viết bằng ngôn ngữ lập trình Java. Nó có thể sử dụng một mô hình học sâu, một số mô hình hoặc quy trình công việc và cung cấp chúng thông qua điểm cuối HTTP. DJL Serve hỗ trợ triển khai các mô hình từ nhiều khung như PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer, v.v.
DJL Serve cung cấp nhiều tính năng cho phép bạn triển khai các mô hình của mình với hiệu suất cao:
- Dễ sử dụng – Phục vụ DJL có thể phục vụ hầu hết các mẫu máy ngay từ đầu. Chỉ cần mang theo các tạo phẩm mô hình và DJL Serve có thể lưu trữ chúng.
- Hỗ trợ nhiều thiết bị và máy gia tốc – DJL Serve hỗ trợ triển khai các mô hình trên CPU, GPU và Suy luận AWS.
- HIỆU QUẢ – DJL Serve chạy suy luận đa luồng trong một JVM duy nhất để tăng thông lượng.
- Lô động – DJL Serve hỗ trợ phân khối động để tăng thông lượng.
- Tự động chia tỷ lệ – DJL Serve sẽ tự động tăng giảm quy mô công nhân dựa trên lưu lượng truy cập.
- Hỗ trợ đa động cơ – DJL Serve có thể lưu trữ đồng thời các mô hình bằng cách sử dụng các khung khác nhau (chẳng hạn như PyTorch và TensorFlow).
- Mô hình tập hợp và quy trình làm việc – DJL Serve hỗ trợ triển khai các quy trình công việc phức tạp bao gồm nhiều mô hình và chạy các phần của quy trình làm việc trên CPU và các bộ phận trên GPU. Các mô hình trong quy trình làm việc có thể sử dụng các khung công tác khác nhau.
Đặc biệt, tính năng tự động chia tỷ lệ của DJL Serve giúp việc đảm bảo các mô hình được chia tỷ lệ phù hợp với lưu lượng đến trở nên đơn giản. Theo mặc định, DJL Serve xác định số lượng nhân viên tối đa cho một mô hình có thể được hỗ trợ dựa trên phần cứng có sẵn (lõi CPU, thiết bị GPU). Bạn có thể đặt giới hạn dưới và giới hạn trên cho từng mô hình để đảm bảo rằng mức lưu lượng truy cập tối thiểu luôn có thể được cung cấp và một mô hình duy nhất không tiêu tốn tất cả tài nguyên có sẵn.
Phục vụ DJL sử dụng Netty giao diện người dùng ở trên cùng của nhóm luồng công nhân phụ trợ. Giao diện người dùng sử dụng một thiết lập Netty duy nhất với nhiều HttpRequestHandlers. Các trình xử lý yêu cầu khác nhau sẽ cung cấp hỗ trợ cho API suy luận, API quản lýhoặc các API khác có sẵn từ nhiều plugin khác nhau.
Phần phụ trợ dựa trên Trình quản lý khối lượng công việc (WLM) mô-đun. WLM xử lý nhiều luồng công việc cho từng mô hình cùng với việc phân nhóm và định tuyến yêu cầu tới chúng. Khi nhiều mô hình được phục vụ, WLM trước tiên sẽ kiểm tra kích thước hàng đợi yêu cầu suy luận của từng mô hình. Nếu kích thước hàng đợi lớn hơn hai lần kích thước lô của mô hình, WLM sẽ tăng số lượng công nhân được chỉ định cho mô hình đó.
Tổng quan về giải pháp
Việc triển khai DJL bằng MME khác với thiết lập MMS mặc định. Đối với việc Cung cấp DJL bằng MME, chúng tôi nén các tệp sau ở định dạng model.tar.gz mà SageMaker Inference đang mong đợi:
- người mẫu.joblib – Để triển khai việc này, chúng tôi trực tiếp đẩy siêu dữ liệu mô hình vào tarball. Trong trường hợp này, chúng tôi đang làm việc với một
.joblibtệp, vì vậy chúng tôi cung cấp tệp đó trong tarball để tập lệnh suy luận của chúng tôi đọc. Nếu thành phần lạ quá lớn, bạn cũng có thể đẩy nó lên Amazon S3 và hướng tới thành phần đó trong cấu hình phân phối mà bạn xác định cho DJL. - phục vụ.properties – Tại đây bạn có thể cấu hình bất kỳ mô hình máy chủ nào liên quan đến biến môi trường. Sức mạnh của DJL ở đây là bạn có thể cấu hình
minWorkersvàmaxWorkerscho mỗi tarball mô hình. Điều này cho phép mỗi mô hình tăng giảm quy mô ở cấp máy chủ mô hình. Ví dụ: nếu một mô hình đơn lẻ nhận được phần lớn lưu lượng truy cập cho MME, thì máy chủ mô hình sẽ tự động mở rộng quy mô công nhân. Trong ví dụ này, chúng tôi không định cấu hình các biến này và để DJL xác định số lượng công nhân cần thiết tùy thuộc vào kiểu lưu lượng truy cập của chúng tôi. - model.py – Đây là tập lệnh suy luận cho bất kỳ quá trình tiền xử lý hoặc hậu xử lý tùy chỉnh nào mà bạn muốn triển khai. model.py mong muốn logic của bạn được gói gọn trong một phương thức xử lý theo mặc định.
- yêu cầu.txt (tùy chọn) – Theo mặc định, DJL được cài đặt sẵn với PyTorch, nhưng mọi phần phụ thuộc bổ sung mà bạn cần đều có thể được đưa vào đây.
Trong ví dụ này, chúng tôi thể hiện sức mạnh của DJL với MME bằng cách lấy mô hình SKLearn mẫu. Chúng tôi thực hiện công việc đào tạo với mô hình này và sau đó tạo 1,000 bản sao của tạo phẩm mô hình này để hỗ trợ MME của chúng tôi. Sau đó, chúng tôi giới thiệu cách DJL có thể mở rộng quy mô một cách linh hoạt để xử lý bất kỳ loại mẫu lưu lượng truy cập nào mà MME của bạn có thể nhận được. Điều này có thể bao gồm việc phân bổ lưu lượng truy cập đồng đều trên tất cả các mô hình hoặc thậm chí một số mô hình phổ biến nhận được phần lớn lưu lượng truy cập. Bạn có thể tìm thấy tất cả các mã sau đây Repo GitHub.
Điều kiện tiên quyết
Trong ví dụ này, chúng tôi sử dụng phiên bản sổ ghi chép SageMaker với kernel conda_python3 và phiên bản ml.c5.xlarge. Để thực hiện kiểm tra tải, bạn có thể sử dụng một Đám mây điện toán đàn hồi Amazon (Amazon EC2) hoặc phiên bản sổ ghi chép SageMaker lớn hơn. Trong ví dụ này, chúng tôi mở rộng quy mô lên hơn một nghìn giao dịch mỗi giây (TPS), vì vậy, chúng tôi khuyên bạn nên thử nghiệm trên phiên bản EC2 nặng hơn, chẳng hạn như ml.c5.18xlarge để bạn có nhiều khả năng điện toán hơn để làm việc.
Tạo một tạo phẩm mô hình
Trước tiên, chúng ta cần tạo tạo phẩm mô hình và dữ liệu mà chúng ta sử dụng trong ví dụ này. Trong trường hợp này, chúng tôi tạo một số dữ liệu nhân tạo bằng NumPy và huấn luyện bằng mô hình hồi quy tuyến tính SKLearn với đoạn mã sau:
Sau khi chạy đoạn mã trước, bạn sẽ có một model.joblib tập tin được tạo trong môi trường cục bộ của bạn.
Kéo hình ảnh DJL Docker
Hình ảnh Docker djl-inference:0.23.0-cpu-full-v1.0 là vùng chứa phân phối DJL của chúng tôi được sử dụng trong ví dụ này. Bạn có thể điều chỉnh URL sau tùy thuộc vào Khu vực của bạn:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
Theo tùy chọn, bạn cũng có thể sử dụng hình ảnh này làm hình ảnh cơ sở và mở rộng nó để xây dựng hình ảnh Docker của riêng bạn trên Đăng ký container đàn hồi Amazon (Amazon ECR) với bất kỳ phần phụ thuộc nào khác mà bạn cần.
Tạo tập tin mô hình
Đầu tiên, chúng tôi tạo một tệp có tên serving.properties. Điều này hướng dẫn DJLServing sử dụng công cụ Python. Chúng tôi cũng định nghĩa max_idle_time của một công nhân là 600 giây. Điều này đảm bảo rằng chúng tôi mất nhiều thời gian hơn để giảm số lượng công nhân mà chúng tôi có trên mỗi mô hình. Chúng tôi không điều chỉnh minWorkers và maxWorkers mà chúng tôi có thể xác định và cho phép DJL tính toán linh hoạt số lượng công nhân cần thiết tùy thuộc vào lưu lượng truy cập mà mỗi mô hình đang nhận được. Các thuộc tính phục vụ được hiển thị như sau. Để xem danh sách đầy đủ các tùy chọn cấu hình, hãy tham khảo Cấu hình động cơ.
Tiếp theo, chúng ta tạo tệp model.py để xác định logic tải và suy luận mô hình. Đối với MME, mỗi tệp model.py dành riêng cho một mô hình. Các mô hình được lưu trữ theo đường dẫn riêng của chúng trong kho mô hình (thường là /opt/ml/model/). Khi tải mô hình, chúng sẽ được tải theo đường dẫn lưu trữ mô hình trong thư mục riêng. Bạn có thể xem ví dụ đầy đủ về model.py trong bản demo này trong phần Repo GitHub.
Chúng tôi tạo ra một model.tar.gz tập tin bao gồm mô hình của chúng tôi (model.joblib), model.pyvà serving.properties:
Nhằm mục đích trình diễn, chúng tôi tạo ra 1,000 bản giống nhau model.tar.gz tập tin để thể hiện số lượng lớn các mô hình sẽ được lưu trữ. Trong quá trình sản xuất, bạn cần tạo một model.tar.gz tập tin cho mỗi mô hình của bạn.
Cuối cùng, chúng tôi tải các mô hình này lên Amazon S3.
Tạo mô hình SageMaker
Bây giờ chúng tôi tạo ra một Mô hình SageMaker. Chúng tôi sử dụng hình ảnh ECR được xác định trước đó và tạo phẩm mô hình từ bước trước để tạo mô hình SageMaker. Trong quá trình thiết lập mô hình, chúng tôi định cấu hình Chế độ là MultiModel. Điều này cho DJLServing biết rằng chúng tôi đang tạo MME.
Tạo điểm cuối SageMaker
Trong bản demo này, chúng tôi sử dụng 20 phiên bản ml.c5d.18xlarge để mở rộng quy mô TPS trong phạm vi hàng nghìn. Đảm bảo tăng giới hạn cho loại phiên bản của bạn, nếu cần, để đạt được TPS mà bạn đang nhắm mục tiêu.
Kiểm tra tải
Tại thời điểm viết bài, công cụ kiểm tra tải nội bộ của SageMaker Người đề xuất suy luận của Amazon SageMaker vốn không hỗ trợ thử nghiệm MME. Vì vậy, chúng tôi sử dụng công cụ Python mã nguồn mở giống châu chấu. Locust rất dễ thiết lập và có thể theo dõi các số liệu như TPS và độ trễ từ đầu đến cuối. Để hiểu đầy đủ về cách thiết lập với SageMaker, hãy xem Các phương pháp hay nhất để kiểm tra tải Điểm cuối suy luận thời gian thực của Amazon SageMaker.
Trong trường hợp sử dụng này, chúng tôi có ba mẫu lưu lượng truy cập khác nhau mà chúng tôi muốn mô phỏng bằng MME, vì vậy chúng tôi có ba tập lệnh Python sau đây phù hợp với từng mẫu. Mục tiêu của chúng tôi ở đây là chứng minh rằng, bất kể mô hình lưu lượng truy cập của chúng tôi là gì, chúng tôi đều có thể đạt được cùng một TPS mục tiêu và mở rộng quy mô một cách thích hợp.
Chúng tôi có thể chỉ định trọng số trong tập lệnh Locust để chỉ định lưu lượng truy cập trên các phần khác nhau của mô hình. Ví dụ: với mô hình duy nhất nóng của chúng tôi, chúng tôi triển khai hai phương pháp như sau:
Sau đó, chúng tôi có thể chỉ định một trọng số nhất định cho từng phương thức, đó là khi một phương thức nhất định nhận được tỷ lệ phần trăm lưu lượng truy cập cụ thể:
Đối với các phiên bản 20 ml.c5d.18xlarge, chúng tôi thấy các chỉ số lệnh gọi sau đây trên amazoncloudwatch bảng điều khiển. Các giá trị này vẫn khá nhất quán trên cả ba kiểu lưu lượng truy cập. Để hiểu rõ hơn về số liệu CloudWatch cho suy luận thời gian thực và MME của SageMaker, hãy tham khảo Số liệu gọi điểm cuối SageMaker.
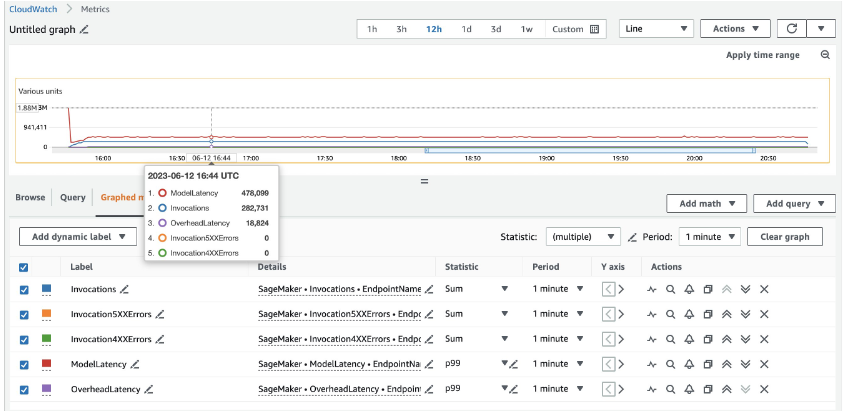
Bạn có thể tìm thấy phần còn lại của tập lệnh Locust trong thư mục locus-utils trong kho lưu trữ GitHub.
Tổng kết
Trong bài đăng này, chúng tôi đã thảo luận về cách MME có thể điều chỉnh linh hoạt công suất tính toán được chỉ định cho từng mô hình dựa trên mẫu lưu lượng của mô hình. Tính năng mới ra mắt này có sẵn ở tất cả các Khu vực AWS có sẵn SageMaker. Lưu ý rằng tại thời điểm thông báo, chỉ hỗ trợ phiên bản CPU. Để tìm hiểu thêm, hãy tham khảo Các thuật toán, khung và phiên bản được hỗ trợ.
Về các tác giả
 Ram Vegiraju là một Kiến trúc sư ML với nhóm Dịch vụ SageMaker. Anh ấy tập trung vào việc giúp khách hàng xây dựng và tối ưu hóa các giải pháp AI / ML của họ trên Amazon SageMaker. Trong thời gian rảnh rỗi, anh ấy thích đi du lịch và viết lách.
Ram Vegiraju là một Kiến trúc sư ML với nhóm Dịch vụ SageMaker. Anh ấy tập trung vào việc giúp khách hàng xây dựng và tối ưu hóa các giải pháp AI / ML của họ trên Amazon SageMaker. Trong thời gian rảnh rỗi, anh ấy thích đi du lịch và viết lách.
 Thanh Vĩ là Chuyên gia Máy học tại Amazon Web Services. Ông nhận bằng Tiến sĩ. trong Nghiên cứu Hoạt động sau khi ông phá vỡ tài khoản tài trợ nghiên cứu của cố vấn và không thực hiện được giải Nobel mà ông đã hứa. Hiện anh đang giúp khách hàng trong ngành dịch vụ tài chính và bảo hiểm xây dựng các giải pháp máy học trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách và dạy học.
Thanh Vĩ là Chuyên gia Máy học tại Amazon Web Services. Ông nhận bằng Tiến sĩ. trong Nghiên cứu Hoạt động sau khi ông phá vỡ tài khoản tài trợ nghiên cứu của cố vấn và không thực hiện được giải Nobel mà ông đã hứa. Hiện anh đang giúp khách hàng trong ngành dịch vụ tài chính và bảo hiểm xây dựng các giải pháp máy học trên AWS. Khi rảnh rỗi, anh ấy thích đọc sách và dạy học.
 James Wu là Kiến trúc sư Giải pháp Chuyên gia về AI / ML Cấp cao tại AWS. giúp khách hàng thiết kế và xây dựng các giải pháp AI / ML. Công việc của James bao gồm một loạt các trường hợp sử dụng ML, với mối quan tâm chính là tầm nhìn máy tính, học sâu và mở rộng ML trong toàn doanh nghiệp. Trước khi gia nhập AWS, James là kiến trúc sư, nhà phát triển và nhà lãnh đạo công nghệ trong hơn 10 năm, bao gồm 6 năm trong lĩnh vực kỹ thuật và 4 năm trong ngành tiếp thị & quảng cáo.
James Wu là Kiến trúc sư Giải pháp Chuyên gia về AI / ML Cấp cao tại AWS. giúp khách hàng thiết kế và xây dựng các giải pháp AI / ML. Công việc của James bao gồm một loạt các trường hợp sử dụng ML, với mối quan tâm chính là tầm nhìn máy tính, học sâu và mở rộng ML trong toàn doanh nghiệp. Trước khi gia nhập AWS, James là kiến trúc sư, nhà phát triển và nhà lãnh đạo công nghệ trong hơn 10 năm, bao gồm 6 năm trong lĩnh vực kỹ thuật và 4 năm trong ngành tiếp thị & quảng cáo.
 Saurabh Trikande là Giám đốc Sản phẩm Cấp cao của Amazon SageMaker Inference. Anh ấy đam mê làm việc với khách hàng và được thúc đẩy bởi mục tiêu dân chủ hóa việc học máy. Ông tập trung vào những thách thức cốt lõi liên quan đến việc triển khai các ứng dụng ML phức tạp, mô hình ML nhiều người thuê, tối ưu hóa chi phí và làm cho việc triển khai các mô hình học sâu dễ tiếp cận hơn. Khi rảnh rỗi, Saurabh thích đi bộ đường dài, tìm hiểu về các công nghệ tiên tiến, theo dõi TechCrunch và dành thời gian cho gia đình.
Saurabh Trikande là Giám đốc Sản phẩm Cấp cao của Amazon SageMaker Inference. Anh ấy đam mê làm việc với khách hàng và được thúc đẩy bởi mục tiêu dân chủ hóa việc học máy. Ông tập trung vào những thách thức cốt lõi liên quan đến việc triển khai các ứng dụng ML phức tạp, mô hình ML nhiều người thuê, tối ưu hóa chi phí và làm cho việc triển khai các mô hình học sâu dễ tiếp cận hơn. Khi rảnh rỗi, Saurabh thích đi bộ đường dài, tìm hiểu về các công nghệ tiên tiến, theo dõi TechCrunch và dành thời gian cho gia đình.
 Xu Đặng là Giám đốc kỹ sư phần mềm của nhóm SageMaker. Anh tập trung vào việc giúp khách hàng xây dựng và tối ưu hóa trải nghiệm suy luận AI/ML của họ trên Amazon SageMaker. Trong thời gian rảnh rỗi, anh ấy thích đi du lịch và trượt tuyết.
Xu Đặng là Giám đốc kỹ sư phần mềm của nhóm SageMaker. Anh tập trung vào việc giúp khách hàng xây dựng và tối ưu hóa trải nghiệm suy luận AI/ML của họ trên Amazon SageMaker. Trong thời gian rảnh rỗi, anh ấy thích đi du lịch và trượt tuyết.
 Siddharth Venkatesan là Kỹ sư phần mềm trong AWS Deep Learning. Hiện tại anh đang tập trung xây dựng các giải pháp cho suy luận mô hình lớn. Trước AWS, anh đã làm việc trong tổ chức tạp hóa Amazon để xây dựng các tính năng thanh toán mới cho khách hàng trên toàn thế giới. Ngoài công việc, anh ấy thích trượt tuyết, hoạt động ngoài trời và xem thể thao.
Siddharth Venkatesan là Kỹ sư phần mềm trong AWS Deep Learning. Hiện tại anh đang tập trung xây dựng các giải pháp cho suy luận mô hình lớn. Trước AWS, anh đã làm việc trong tổ chức tạp hóa Amazon để xây dựng các tính năng thanh toán mới cho khách hàng trên toàn thế giới. Ngoài công việc, anh ấy thích trượt tuyết, hoạt động ngoài trời và xem thể thao.
 Rohith Nallamaddi là Kỹ sư phát triển phần mềm tại AWS. Anh làm việc về việc tối ưu hóa khối lượng công việc học sâu trên GPU, xây dựng các giải pháp cung cấp và suy luận ML hiệu suất cao. Trước đó, anh ấy đã làm việc trong việc xây dựng các vi dịch vụ dựa trên AWS cho doanh nghiệp Amazon F3. Ngoài công việc, anh ấy thích chơi và xem thể thao.
Rohith Nallamaddi là Kỹ sư phát triển phần mềm tại AWS. Anh làm việc về việc tối ưu hóa khối lượng công việc học sâu trên GPU, xây dựng các giải pháp cung cấp và suy luận ML hiệu suất cao. Trước đó, anh ấy đã làm việc trong việc xây dựng các vi dịch vụ dựa trên AWS cho doanh nghiệp Amazon F3. Ngoài công việc, anh ấy thích chơi và xem thể thao.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

