Gần đây chúng tôi đã giới thiệu một khả năng mới trong SDK Python SageMaker của Amazon cho phép các nhà khoa học dữ liệu chạy mã máy học (ML) được tạo trong môi trường dành cho nhà phát triển tích hợp (IDE) ưa thích của họ và sổ ghi chép cùng với các phụ thuộc thời gian chạy được liên kết như Amazon SageMaker công việc đào tạo với những thay đổi mã tối thiểu đối với thử nghiệm được thực hiện tại địa phương. Các nhà khoa học dữ liệu thường thực hiện một số lần lặp lại thử nghiệm trong các mô hình đào tạo và xử lý dữ liệu trong khi giải quyết bất kỳ vấn đề ML nào. Họ muốn chạy mã ML này và thực hiện thử nghiệm một cách dễ sử dụng và ít thay đổi mã nhất. Đào tạo về người mẫu Amazon SageMaker giúp các nhà khoa học dữ liệu chạy các công việc đào tạo quy mô lớn được quản lý hoàn toàn trên cơ sở hạ tầng điện toán của AWS. Đào tạo SageMaker cũng giúp các nhà khoa học dữ liệu với các công cụ tiên tiến như Trình gỡ lỗi Amazon SageMaker và Profiler để gỡ lỗi và phân tích các công việc đào tạo quy mô lớn của họ.
Đối với khách hàng có ngân sách nhỏ, nhóm nhỏ và thời gian chặt chẽ, mọi khái niệm và dòng mã mới được viết lại để chạy trên SageMaker đều khiến họ làm việc kém hiệu quả hơn đối với các nhiệm vụ cốt lõi của mình, cụ thể là xử lý dữ liệu và đào tạo mô hình ML. Họ muốn viết mã một lần trong khuôn khổ mà họ lựa chọn và có thể di chuyển liền mạch từ chạy mã trong sổ ghi chép hoặc máy tính xách tay của họ sang chạy mã trên quy mô lớn bằng các khả năng của SageMaker.
Với khả năng mới này của SageMaker Python SDK, các nhà khoa học dữ liệu có thể đưa mã ML của họ vào nền tảng Đào tạo SageMaker trong vài phút. Bạn chỉ cần thêm một dòng mã vào mã ML của mình và SageMaker hiểu mã của bạn một cách thông minh cùng với bộ dữ liệu và thiết lập môi trường không gian làm việc và chạy nó như một công việc Đào tạo SageMaker. Sau đó, bạn có thể tận dụng các khả năng chính của nền tảng Đào tạo SageMaker, chẳng hạn như khả năng mở rộng quy mô công việc một cách dễ dàng và các công cụ liên quan khác như Trình gỡ lỗi và Trình lập hồ sơ. Trong bản phát hành này, bạn có thể chạy mã Python máy học (ML) cục bộ của mình dưới dạng tác vụ đào tạo Amazon SageMaker một nút hoặc nhiều tác vụ song song. Các công việc đào tạo phân tán (trên nhiều nút) không được hỗ trợ bởi các chức năng từ xa.
Trong bài đăng này, chúng tôi chỉ cho bạn cách sử dụng khả năng mới này để chạy mã ML cục bộ dưới dạng công việc Đào tạo SageMaker.
Tổng quan về giải pháp
Giờ đây, bạn có thể chạy mã ML được viết trong IDE hoặc sổ ghi chép của mình dưới dạng công việc Đào tạo SageMaker bằng cách chú thích hàm, hoạt động như một điểm nhập vào cơ sở mã của người dùng, với một trình trang trí đơn giản. Khi gọi, khả năng này sẽ tự động chụp nhanh tất cả các biến, hàm, gói, biến môi trường và các yêu cầu thời gian chạy khác có liên quan từ mã ML của bạn, sắp xếp theo thứ tự và gửi chúng dưới dạng công việc Đào tạo SageMaker. Nó tích hợp với công bố gần đây Tính năng SageMaker Python SDK để đặt giá trị mặc định cho tham số. Khả năng này đơn giản hóa các cấu trúc SageMaker mà bạn cần tìm hiểu để có thể chạy mã bằng cách sử dụng chương trình Đào tạo SageMaker. Các nhà khoa học dữ liệu có thể viết, gỡ lỗi và lặp lại mã của họ trong bất kỳ IDE ưa thích nào (chẳng hạn như Xưởng sản xuất Amazon SageMaker, sổ ghi chép, Mã VS hoặc PyCharm). Khi đã sẵn sàng, bạn có thể chú thích hàm Python của mình bằng @remote decorator và chạy nó như một công việc SageMaker trên quy mô lớn.
Khả năng này lấy các đối tượng Python nguồn mở quen thuộc làm đối số và đầu ra. Ngoài ra, bạn không cần phải hiểu về quản lý vòng đời của bộ chứa và có thể chỉ cần chạy khối lượng công việc của mình trên các bối cảnh điện toán khác nhau (chẳng hạn như IDE cục bộ, Studio hoặc công việc đào tạo) với chi phí cấu hình tối thiểu. Để chạy bất kỳ mã cục bộ nào dưới dạng công việc Đào tạo SageMaker, khả năng này suy ra các cấu hình cần thiết để chạy công việc, chẳng hạn như Quản lý truy cập và nhận dạng AWS (IAM), khóa mã hóa và cấu hình mạng, từ cài đặt Studio hoặc IDE (có thể là thiết lập mặc định) và chuyển chúng đến nền tảng theo mặc định. Bạn có thể linh hoạt tùy chỉnh thời gian chạy của mình trong cơ sở hạ tầng do SageMaker quản lý bằng cách sử dụng cấu hình được phỏng đoán hoặc ghi đè chúng ở cấp SDK bằng cách chuyển chúng làm đối số cho trình trang trí.
Khả năng mới này của SageMaker Python SDK biến đổi mã ML của bạn trong môi trường không gian làm việc hiện có và bất kỳ bộ dữ liệu và mã xử lý dữ liệu liên quan nào thành công việc Đào tạo SageMaker. Khả năng này tìm kiếm mã ML được bao bọc bên trong một @remote decorator và tự động dịch nó thành một công việc chạy trong Studio hoặc IDE cục bộ, chẳng hạn như PyCharm.
Trong các phần sau, chúng ta sẽ tìm hiểu các tính năng của khả năng mới này và cách khởi chạy các hàm python dưới dạng công việc Đào tạo SageMaker.
Điều kiện tiên quyết
Để sử dụng khả năng SageMaker Python SDK mới này và chạy mã được liên kết với bài đăng này, bạn cần có các điều kiện tiên quyết sau:
- Tài khoản AWS sẽ chứa tất cả tài nguyên AWS của bạn
- Vai trò IAM để truy cập SageMaker
- Truy cập vào Studio hoặc phiên bản sổ ghi chép SageMaker hoặc IDE chẳng hạn như PyCharm
Sử dụng SDK từ sổ ghi chép Studio và SageMaker
Bạn có thể sử dụng khả năng này từ Studio bằng cách khởi chạy sổ ghi chép và gói mã của bạn bằng một @remote trang trí bên trong cuốn sổ. Trước tiên, bạn cần nhập chức năng từ xa bằng mã sau:
from sagemaker.remote_function import remoteKhi bạn sử dụng chức năng trang trí, khả năng này sẽ tự động diễn giải chức năng mã của bạn và chạy nó dưới dạng công việc Đào tạo SageMaker.
Bạn cũng có thể sử dụng khả năng này từ phiên bản sổ ghi chép SageMaker. Trước tiên, bạn cần bắt đầu phiên bản sổ ghi chép, mở Jupyter hoặc Jupyter Lab trên đó và khởi chạy sổ ghi chép. Sau đó, nhập chức năng từ xa như được hiển thị trong mã trước đó và bọc mã của bạn bằng @remote người trang trí. Chúng tôi bao gồm một ví dụ về cách sử dụng chức năng trang trí và các cài đặt liên quan sau trong bài đăng này.
Sử dụng SDK từ môi trường cục bộ của bạn
Bạn cũng có thể sử dụng khả năng này từ IDE cục bộ của mình. Như một điều kiện tiên quyết, bạn phải có Giao diện dòng lệnh AWS (AWS CLI), SageMaker Python SDK và AWS SDK cho Python (Boto3) được cài đặt trong môi trường địa phương của bạn. Bạn cần nhập các thư viện này vào mã của mình, đặt phiên SageMaker, chỉ định cài đặt và trang trí chức năng của bạn bằng @remote người trang trí. Trong mã ví dụ sau, chúng tôi chạy một chức năng phân chia đơn giản dưới dạng công việc Đào tạo SageMaker:
import boto3
import sagemaker
from sagemaker.remote_function import remote sm_session = sagemaker.Session(boto_session=boto3.session.Session(region_name="us-west-2"))
settings = dict(
sagemaker_session=sm_session,
role=<IAM_ROLE_NAME>
instance_type="ml.m5.xlarge",
)
@remote(**settings)
def divide(x, y):
return x / y
if __name__ == "__main__":
print(divide(2, 3.0))Chúng ta có thể sử dụng phương pháp tương tự để chạy các chức năng nâng cao dưới dạng công việc đào tạo, như được trình bày trong phần tiếp theo.
Khởi chạy các chức năng Python dưới dạng công việc SageMaker
Tính năng SageMaker Python SDK mới cho phép bạn chạy các hàm Python dưới dạng Công việc đào tạo SageMaker. Bất kỳ mã Python, mã đào tạo ML nào do các nhà khoa học dữ liệu phát triển bằng cách sử dụng IDE cục bộ ưa thích của họ (PyCharm, VS Code), sổ ghi chép SageMaker hoặc sổ ghi chép Studio đều có thể được khởi chạy dưới dạng công việc SageMaker được quản lý.
Trong khối lượng công việc ML sử dụng khả năng này, các tập dữ liệu liên quan, phần phụ thuộc và thiết lập môi trường không gian làm việc được sắp xếp theo thứ tự bằng cách sử dụng mã ML và chạy dưới dạng công việc SageMaker một cách đồng bộ và không đồng bộ.
Bạn có thể thêm một @remote chú thích trang trí cho bất kỳ mã Python nào, bao gồm chức năng đào tạo hoặc xử lý ML cục bộ để khởi chạy nó dưới dạng công việc Đào tạo SageMaker được quản lý, nhờ đó tận dụng các lợi ích về quy mô, hiệu suất và chi phí của SageMaker. Điều này có thể đạt được với những thay đổi mã tối thiểu bằng cách thêm một trình trang trí vào mã hàm Python. Yêu cầu chức năng trang trí được chạy đồng bộ và chức năng chạy đợi cho đến khi công việc SageMaker hoàn tất.
Trong ví dụ sau, chúng tôi sử dụng @remote decorator để khởi chạy công việc SageMaker ở chế độ decorator bằng cách sử dụng phiên bản ml.m5.large. SageMaker sử dụng công việc đào tạo để khởi chạy chức năng này dưới dạng công việc được quản lý.
from sagemaker.remote_function import remote
from numpy as np @remote(instance_type="ml.m5.large")
def matrix_multiply(a, b): return np.matmul(a, b) a = np.array([[1, 0], [0, 1]])
b = np.array([1, 2]) assert matrix_multiply(a, b) == np.array([1,2])Bạn cũng có thể sử dụng chế độ trang trí để khởi chạy công việc SageMaker, gói Python và phần phụ thuộc. Bạn có thể bao gồm các biến môi trường như VPC, mạng con và nhóm bảo mật để khởi chạy công việc đào tạo SageMaker trong environment.yml tài liệu. Điều này cho phép các kỹ sư ML và quản trị viên định cấu hình các biến môi trường này để các nhà khoa học dữ liệu có thể tập trung vào việc xây dựng mô hình ML và lặp lại nhanh hơn. Xem đoạn mã sau:
from sagemaker.remote_function import remote @remote(instance_type="ml.g4dn.xlarge",dependencies = "./environment.yml")
def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
... <TRUCNATED>
return os.path.join(s3_output_path, model_dir), eval_resultBạn có thể sử dụng RemoteExecutor để khởi chạy các chức năng Python dưới dạng công việc SageMaker không đồng bộ. Người thực hiện thăm dò không đồng bộ các công việc Đào tạo SageMaker để cập nhật trạng thái của công việc. Các RemoteExecutor lớp là một thực hiện của đồng thời.futures.Executor, được sử dụng để gửi các công việc Đào tạo SageMaker một cách không đồng bộ. Xem đoạn mã sau:
from sagemaker.remote_function import RemoteExecutor def train_hf_model(
train_input_path,test_input_path,s3_output_path = None,
*,epochs = 1, train_batch_size = 32, eval_batch_size = 64,
warmup_steps = 500,learning_rate = 5e-5
):
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
...<TRUNCATED>
return os.path.join(s3_output_path, model_dir), eval_result with RemoteExecutor(instance_type="ml.g4dn.xlarge", dependencies = './requirements.txt') as e:
future = e.submit(train_hf_model, train_input_path,test_input_path,s3_output_path,
epochs, train_batch_size, eval_batch_size,warmup_steps,learning_rate)Tùy chỉnh môi trường thời gian chạy
Chế độ trang trí và RemoteExecutor cho phép bạn xác định và tùy chỉnh môi trường thời gian chạy cho công việc SageMaker. Các phụ thuộc thời gian chạy, bao gồm các gói Python và biến môi trường cho công việc SageMaker, có thể được chỉ định để tùy chỉnh thời gian chạy. Để chạy mã Python cục bộ dưới dạng công việc do SageMaker quản lý, gói Python và các thành phần phụ thuộc cần phải được cung cấp cho SageMaker. Kỹ sư ML hoặc quản trị viên khoa học dữ liệu có thể định cấu hình mạng và cấu hình bảo mật, chẳng hạn như VPC, mạng con và nhóm bảo mật cho công việc SageMaker, vì vậy, các nhà khoa học dữ liệu có thể sử dụng các cấu hình được quản lý tập trung này trong khi khởi chạy công việc SageMaker. Bạn có thể sử dụng một trong hai requirements.txt tập tin hoặc một Conda environment.yaml tập tin.
Khi các phụ thuộc được xác định với requirements.txt, các gói sẽ được cài đặt bằng cách sử dụng pip trong thời gian chạy công việc. Nếu hình ảnh được sử dụng để chạy công việc đi kèm với môi trường Conda, các gói sẽ được cài đặt trong môi trường Conda được khai báo để sử dụng cho công việc. Đoạn mã sau đây cho thấy một ví dụ requirements.txt tập tin:
datasets
transformers
torch
scikit-learn
s3fs==0.4.2
sagemaker>=2.148.0Bạn có thể vượt qua của bạn Conda environment.yaml tệp để tạo môi trường Conda mà bạn muốn mã của mình chạy trong quá trình đào tạo. Nếu hình ảnh được sử dụng để chạy công việc khai báo một môi trường Conda để chạy mã bên dưới, thì chúng tôi sẽ cập nhật môi trường Conda đã khai báo với thông số kỹ thuật đã cho. Đoạn mã sau đây là một ví dụ về một Conda environment.yaml tập tin:
name: sagemaker_example
channels: - conda-forge
dependencies: - python=3.10 - pandas - pip: - sagemakerNgoài ra, bạn có thể đặt dependencies=”auto_capture” để cho phép SageMaker Python SDK ghi lại các thành phần phụ thuộc đã cài đặt trong môi trường Conda đang hoạt động. Bạn phải có một môi trường Conda đang hoạt động cho auto_capture làm việc. Lưu ý rằng có những điều kiện tiên quyết cho auto_capture làm việc; chúng tôi khuyên bạn nên chuyển các phần phụ thuộc của mình dưới dạng requirement.txt or Conda environment.yml tập tin như được mô tả trong phần trước.
Để biết thêm chi tiết, hãy tham khảo Chạy mã cục bộ của bạn dưới dạng công việc Đào tạo SageMaker.
Cấu hình cho công việc SageMaker
Các cài đặt liên quan đến cơ sở hạ tầng có thể được tải xuống một tệp cấu hình mà người dùng quản trị có thể giúp thiết lập. Bạn chỉ cần thiết lập nó một lần. Cài đặt cơ sở hạ tầng bao gồm cấu hình mạng, vai trò IAM, Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) cho dữ liệu đầu vào, đầu ra và thẻ. tham khảo Định cấu hình và sử dụng các giá trị mặc định với SageMaker Python SDK để biết thêm chi tiết.
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
Dependencies: path/to/requirements.txt
EnvironmentVariables: {"EnvVarKey": "EnvVarValue"}
ImageUri: 366666666666.dkr.ecr.us-west-2.amazonaws.com/my-image:latest
InstanceType: ml.m5.large
RoleArn: arn:aws:iam::366666666666:role/MyRole
S3KmsKeyId: somekmskeyid
S3RootUri: s3://my-bucket/my-project
SecurityGroupIds:
- sg123
Subnets:
- subnet-1234
Tags:
- {"Key": "someTagKey", "Value": "someTagValue"}
VolumeKmsKeyId: somekmskeyidThực hiện
Các mô hình học sâu như PyTorch hoặc TensorFlow cũng có thể chạy trong Studio bằng cách chạy mã dưới dạng công việc đào tạo trong sổ ghi chép. Để giới thiệu khả năng này trong Studio, bạn có thể sao chép repo này vào Studio của mình và chạy sổ ghi chép nằm trong GitHub kho.
Ví dụ này minh họa trường hợp sử dụng phân loại văn bản nhị phân từ đầu đến cuối. Chúng tôi đang sử dụng thư viện bộ dữ liệu và máy biến áp Hugging Face để tinh chỉnh một máy biến áp được đào tạo trước về phân loại văn bản nhị phân. Đặc biệt, mô hình được đào tạo trước sẽ được tinh chỉnh bằng cách sử dụng tập dữ liệu IMDb.
Khi bạn sao chép kho lưu trữ, bạn nên định vị các tệp sau:
- config.yaml – Hầu hết các đối số trang trí có thể được giảm tải vào tệp cấu hình để tách các cài đặt liên quan đến cơ sở hạ tầng khỏi cơ sở mã
- ômface.ipynb – Phần này chứa mã để đào tạo mô hình HuggingFace đã được đào tạo trước, mô hình này sẽ được tinh chỉnh bằng bộ dữ liệu IMDB
- Yêu cầu.txt – Tệp này chứa tất cả các phụ thuộc để chạy chức năng sẽ được sử dụng trong sổ ghi chép này để chạy mã và chạy đào tạo từ xa trong phiên bản GPU dưới dạng công việc đào tạo
Khi bạn mở sổ ghi chép, bạn sẽ được nhắc thiết lập môi trường sổ ghi chép. Bạn có thể chọn hình ảnh Data Science 3.0 có nhân Python 3 và ml.m5.large làm loại phiên bản khởi chạy nhanh để chạy mã sổ ghi chép. Loại phiên bản này nhanh hơn đáng kể trong việc tạo ra một môi trường.
Công việc đào tạo sẽ được chạy trong phiên bản ml.g4dn.xlarge như được xác định trong config.yaml tập tin:
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
RemoteFunction:
# role arn is not required if in SageMaker Notebook instance or SageMaker Studio
# Uncomment the following line and replace with the right execution role if in a local IDE
# RoleArn: <IAM_ROLE_ARN>
InstanceType: ml.g4dn.xlarge
Dependencies: ./requirements.txtSản phẩm requirements.txt tệp phụ thuộc để chạy chức năng đào tạo mô hình Hugging Face bao gồm:
datasets
transformers
torch
scikit-learn
# lock s3fs to this specific version as more recent ones introduce dependency on aiobotocore, which is not compatible with botocore
s3fs==0.4.2
sagemaker>=2.148.0,<3Máy tính xách tay Hugging Face giới thiệu cách điều hành đào tạo từ xa thông qua @remote chức năng, được chạy đồng bộ. Do đó, chức năng chạy để đào tạo mô hình sẽ đợi cho đến khi công việc Đào tạo SageMaker hoàn tất. Quá trình đào tạo sẽ được chạy từ xa với phiên bản GPU trong đó loại phiên bản được xác định trong tệp cấu hình trước đó.
Sau khi bạn chạy công việc đào tạo, bạn có thể chạy phần còn lại của các ô trong sổ ghi chép để kiểm tra các chỉ số đánh giá và phân loại văn bản trên mô hình được đào tạo của chúng tôi.
Bạn cũng có thể xem trạng thái công việc đào tạo đã được kích hoạt từ xa trong phiên bản GPU trên bảng điều khiển SageMaker bằng cách điều hướng trở lại bảng điều khiển SageMaker.
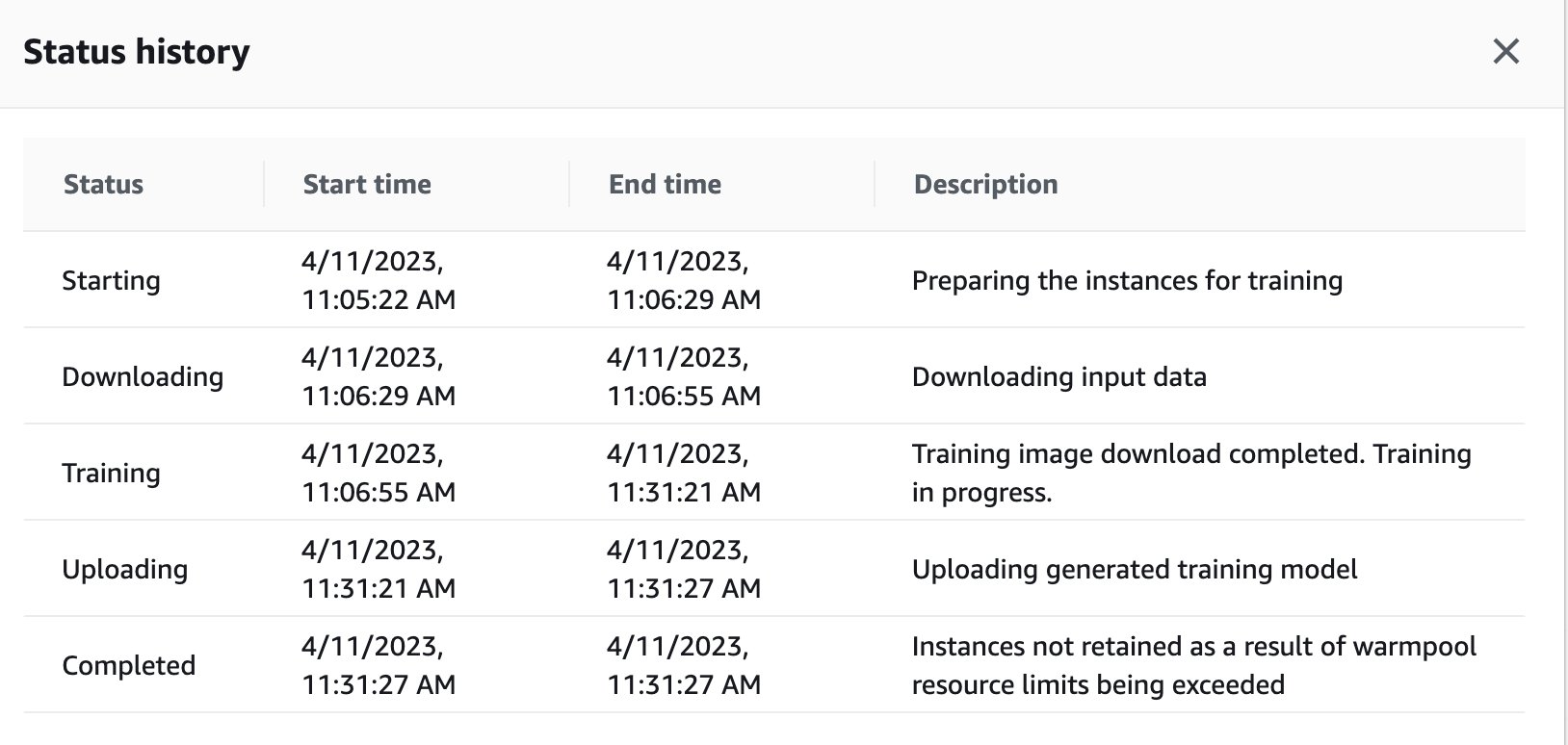
Ngay khi công việc huấn luyện hoàn thành, nó tiếp tục chạy các hướng dẫn trong sổ ghi chép để đánh giá và phân loại. Các công việc tương tự có thể được đào tạo và chạy thông qua chức năng thực thi từ xa được nhúng trong sổ ghi chép Studio để thực hiện các hoạt động không đồng bộ.
Tích hợp với các thử nghiệm SageMaker bên trong chức năng @remote
Bạn có thể chuyển tên thử nghiệm, tên chạy và các tham số khác vào chức năng từ xa của mình để tạo chạy thử nghiệm SageMaker. Ví dụ mã sau đây nhập tên thử nghiệm, tên của lần chạy và các tham số để ghi nhật ký cho mỗi lần chạy:
from sagemaker.remote_function import remote
from sagemaker.experiments.run import Run
# Define your remote function
@remote
def train(value_1, value_2, exp_name, run_name):
...
...
#Creates the experiment
with Run( experiment_name=exp_name, run_name=run_name, sagemaker_session=sagemaker_session
) as run:
...
...
#Define values for the parameters to log
run.log_parameter("param_1", value_1)
run.log_parameter("param_2", value_2)
...
...
#Define metrics to log
run.log_metric("metric_a", 0.5)
run.log_metric("metric_b", 0.1) # Invoke your remote function
train(1.0, 2.0, "my-exp-name", "my-run-name") Trong ví dụ trước, các tham số p1 và p2 được ghi lại theo thời gian bên trong một vòng lặp đào tạo. Các tham số phổ biến có thể bao gồm kích thước lô hoặc kỷ nguyên. Trong ví dụ, các chỉ số A và B được ghi lại để chạy theo thời gian bên trong một vòng lặp đào tạo. Các số liệu phổ biến có thể bao gồm độ chính xác hoặc mất mát. Để biết thêm thông tin, xem Tạo thử nghiệm Amazon SageMaker.
Kết luận
Trong bài đăng này, chúng tôi đã giới thiệu khả năng SageMaker Python SDK mới cho phép các nhà khoa học dữ liệu chạy mã ML của họ trong IDE ưa thích của họ dưới dạng công việc Đào tạo SageMaker. Chúng tôi đã thảo luận về các điều kiện tiên quyết cần thiết để sử dụng khả năng này cùng với các tính năng của nó. Chúng tôi cũng đã chỉ ra cách sử dụng khả năng này trong Studio, phiên bản sổ ghi chép SageMaker và IDE cục bộ của bạn. Ngoài ra, chúng tôi đã cung cấp các ví dụ mã mẫu để minh họa cách sử dụng khả năng này. Bước tiếp theo, chúng tôi khuyên bạn nên thử khả năng này trong IDE hoặc SageMaker của mình bằng cách làm theo hướng dẫn mã ví dụ được đề cập trong bài viết này.
Về các tác giả
 Dipankar Patro là Kỹ sư phát triển phần mềm tại AWS SageMaker, đổi mới và xây dựng các giải pháp MLOps để giúp khách hàng áp dụng các giải pháp AI/ML trên quy mô lớn. Anh ấy có bằng Thạc sĩ Khoa học Máy tính và các lĩnh vực anh ấy quan tâm là Bảo mật Máy tính, Hệ thống Phân tán và AI/ML.
Dipankar Patro là Kỹ sư phát triển phần mềm tại AWS SageMaker, đổi mới và xây dựng các giải pháp MLOps để giúp khách hàng áp dụng các giải pháp AI/ML trên quy mô lớn. Anh ấy có bằng Thạc sĩ Khoa học Máy tính và các lĩnh vực anh ấy quan tâm là Bảo mật Máy tính, Hệ thống Phân tán và AI/ML.
 Farooq Sabir là Kiến trúc sư giải pháp chuyên gia trí tuệ nhân tạo và học máy cao cấp tại AWS. Ông có bằng Tiến sĩ và Thạc sĩ Kỹ thuật Điện của Đại học Texas ở Austin và bằng Thạc sĩ Khoa học Máy tính của Viện Công nghệ Georgia. Anh ấy có hơn 15 năm kinh nghiệm làm việc và cũng thích giảng dạy và cố vấn cho sinh viên đại học. Tại AWS, anh giúp khách hàng hình thành và giải quyết các vấn đề kinh doanh của họ trong khoa học dữ liệu, máy học, thị giác máy tính, trí tuệ nhân tạo, tối ưu hóa số học và các lĩnh vực liên quan. Có trụ sở tại Dallas, Texas, anh ấy và gia đình thích đi du lịch và thực hiện các chuyến đi đường dài.
Farooq Sabir là Kiến trúc sư giải pháp chuyên gia trí tuệ nhân tạo và học máy cao cấp tại AWS. Ông có bằng Tiến sĩ và Thạc sĩ Kỹ thuật Điện của Đại học Texas ở Austin và bằng Thạc sĩ Khoa học Máy tính của Viện Công nghệ Georgia. Anh ấy có hơn 15 năm kinh nghiệm làm việc và cũng thích giảng dạy và cố vấn cho sinh viên đại học. Tại AWS, anh giúp khách hàng hình thành và giải quyết các vấn đề kinh doanh của họ trong khoa học dữ liệu, máy học, thị giác máy tính, trí tuệ nhân tạo, tối ưu hóa số học và các lĩnh vực liên quan. Có trụ sở tại Dallas, Texas, anh ấy và gia đình thích đi du lịch và thực hiện các chuyến đi đường dài.
 Manoj Ravi là Giám đốc sản phẩm cấp cao của Amazon SageMaker. Anh đam mê xây dựng các sản phẩm AI thế hệ tiếp theo, đồng thời làm việc trên phần mềm và công cụ để giúp việc học máy quy mô lớn trở nên dễ dàng hơn cho khách hàng. Ông có bằng MBA của Trường Kinh doanh Haas và bằng Thạc sĩ Quản lý Hệ thống Thông tin của Đại học Carnegie Mellon. Khi rảnh rỗi, Manoj thích chơi quần vợt và chụp ảnh phong cảnh.
Manoj Ravi là Giám đốc sản phẩm cấp cao của Amazon SageMaker. Anh đam mê xây dựng các sản phẩm AI thế hệ tiếp theo, đồng thời làm việc trên phần mềm và công cụ để giúp việc học máy quy mô lớn trở nên dễ dàng hơn cho khách hàng. Ông có bằng MBA của Trường Kinh doanh Haas và bằng Thạc sĩ Quản lý Hệ thống Thông tin của Đại học Carnegie Mellon. Khi rảnh rỗi, Manoj thích chơi quần vợt và chụp ảnh phong cảnh.
 Shikhar Kwatra là Chuyên gia kiến trúc giải pháp AI/ML tại Amazon Web Services, làm việc với Nhà tích hợp hệ thống toàn cầu hàng đầu. Anh đã giành được danh hiệu là một trong những Nhà phát minh bậc thầy trẻ nhất Ấn Độ với hơn 500 bằng sáng chế trong lĩnh vực AI/ML và IoT. Shikhar hỗ trợ kiến trúc, xây dựng và duy trì môi trường đám mây có thể mở rộng, tiết kiệm chi phí cho tổ chức và hỗ trợ đối tác GSI trong việc xây dựng các giải pháp công nghiệp chiến lược trên AWS. Shikhar thích chơi ghi-ta, sáng tác nhạc và thực hành chánh niệm khi rảnh rỗi.
Shikhar Kwatra là Chuyên gia kiến trúc giải pháp AI/ML tại Amazon Web Services, làm việc với Nhà tích hợp hệ thống toàn cầu hàng đầu. Anh đã giành được danh hiệu là một trong những Nhà phát minh bậc thầy trẻ nhất Ấn Độ với hơn 500 bằng sáng chế trong lĩnh vực AI/ML và IoT. Shikhar hỗ trợ kiến trúc, xây dựng và duy trì môi trường đám mây có thể mở rộng, tiết kiệm chi phí cho tổ chức và hỗ trợ đối tác GSI trong việc xây dựng các giải pháp công nghiệp chiến lược trên AWS. Shikhar thích chơi ghi-ta, sáng tác nhạc và thực hành chánh niệm khi rảnh rỗi.
 Vikram Elango là Kiến trúc sư giải pháp chuyên gia cao cấp về AI/ML tại AWS, có trụ sở tại Virginia, Hoa Kỳ. Anh ấy hiện đang tập trung vào AI tổng quát, LLM, kỹ thuật nhanh, tối ưu hóa suy luận mô hình lớn và mở rộng quy mô ML trong các doanh nghiệp. Vikram giúp các khách hàng trong ngành tài chính và bảo hiểm có khả năng lãnh đạo về thiết kế và tư duy để xây dựng và triển khai các ứng dụng máy học trên quy mô lớn. Khi rảnh rỗi, anh ấy thích đi du lịch, đi bộ đường dài, nấu ăn và cắm trại.
Vikram Elango là Kiến trúc sư giải pháp chuyên gia cao cấp về AI/ML tại AWS, có trụ sở tại Virginia, Hoa Kỳ. Anh ấy hiện đang tập trung vào AI tổng quát, LLM, kỹ thuật nhanh, tối ưu hóa suy luận mô hình lớn và mở rộng quy mô ML trong các doanh nghiệp. Vikram giúp các khách hàng trong ngành tài chính và bảo hiểm có khả năng lãnh đạo về thiết kế và tư duy để xây dựng và triển khai các ứng dụng máy học trên quy mô lớn. Khi rảnh rỗi, anh ấy thích đi du lịch, đi bộ đường dài, nấu ăn và cắm trại.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/run-your-local-machine-learning-code-as-amazon-sagemaker-training-jobs-with-minimal-code-changes/

