Đây là một bài đăng trên blog của khách được đồng viết với Hussain Jagirdar từ Games24x7.
Trò chơi24x7 là một trong những nền tảng đa trò chơi có giá trị nhất của Ấn Độ và giải trí cho hơn 100 triệu người chơi qua các trò chơi kỹ năng khác nhau. Với triết lý cốt lõi là “Khoa học về trò chơi”, họ đã tạo ra tầm nhìn về tin học toàn diện xung quanh tính năng động của trò chơi, nền tảng trò chơi và người chơi bằng cách hợp nhất các hướng nghiên cứu trực giao về AI trò chơi, khoa học dữ liệu trò chơi và nghiên cứu người dùng trò chơi. Nhóm khoa học dữ liệu và AI đi sâu vào rất nhiều dữ liệu đa chiều và chạy nhiều trường hợp sử dụng khác nhau như tối ưu hóa hành trình của người chơi, phát hiện hành động trong trò chơi, siêu cá nhân hóa, khách hàng 360, v.v. trên AWS.
Games24x7 sử dụng khung được hỗ trợ bởi AI, tự động, dựa trên dữ liệu để đánh giá hành vi của từng người chơi thông qua các tương tác trên nền tảng và gắn cờ người dùng có hành vi bất thường. Họ đã xây dựng một mô hình học sâu ScarceGAN, tập trung vào việc xác định các mẫu cực hiếm hoặc khan hiếm từ dữ liệu đo từ xa theo chiều dọc đa chiều với các nhãn nhỏ và yếu. Công trình này đã được xuất bản trong CIKM'21 và mã nguồn mở để nhận dạng lớp hiếm đối với bất kỳ dữ liệu đo từ xa theo chiều dọc nào. Nhu cầu sản xuất và áp dụng mô hình là tối quan trọng để tạo ra một xương sống đằng sau việc cho phép chơi trò chơi có trách nhiệm trong nền tảng của họ, nơi những người dùng bị gắn cờ có thể được đưa qua một hành trình kiểm duyệt và kiểm soát khác.
Trong bài đăng này, chúng tôi chia sẻ cách Games24x7 cải thiện quy trình đào tạo cho nền tảng trò chơi có trách nhiệm của họ bằng cách sử dụng Amazon SageMaker.
thách thức khách hàng
Nhóm DS/AI tại Games24x7 đã sử dụng nhiều dịch vụ do AWS cung cấp, bao gồm sổ ghi chép SageMaker, Chức năng bước AWS, AWS Lambdavà Amazon EMR, để xây dựng đường ống cho các trường hợp sử dụng khác nhau. Để xử lý sự sai lệch trong phân phối dữ liệu và do đó để đào tạo lại mô hình ScarceGAN của mình, họ đã phát hiện ra rằng hệ thống hiện có cần một giải pháp MLOps tốt hơn.
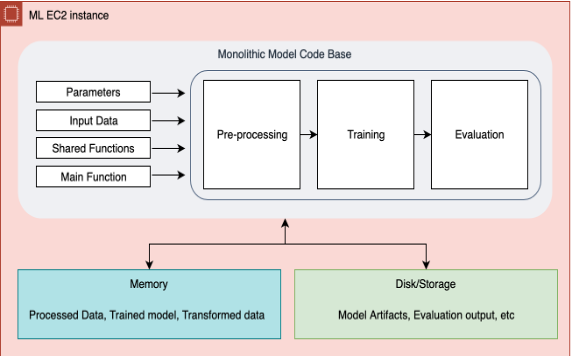
Trong quy trình trước đó thông qua Step Functions, một cơ sở mã nguyên khối duy nhất chạy tiền xử lý dữ liệu, đào tạo lại và đánh giá. Điều này trở thành một nút cổ chai trong việc khắc phục sự cố, thêm hoặc xóa một bước hoặc thậm chí thực hiện một số thay đổi nhỏ trong cơ sở hạ tầng tổng thể. Chức năng bước này khởi tạo một cụm phiên bản để trích xuất và xử lý dữ liệu từ S3 và các bước tiếp theo về tiền xử lý, đào tạo, đánh giá sẽ chạy trên một phiên bản EC2 lớn duy nhất. Trong các tình huống mà đường ống bị lỗi ở bất kỳ bước nào, toàn bộ quy trình làm việc cần được khởi động lại từ đầu, điều này dẫn đến việc chạy lặp lại và tăng chi phí. Tất cả chỉ số đào tạo và đánh giá đều được kiểm tra thủ công từ Amazon Simple Storage Service (Amazon S3). Không có cơ chế nào để chuyển và lưu trữ siêu dữ liệu của nhiều thử nghiệm được thực hiện trên mô hình. Do việc giám sát mô hình phi tập trung, điều tra kỹ lưỡng và chọn ra mô hình tốt nhất mà nhóm khoa học dữ liệu cần hàng giờ. Tích lũy tất cả những nỗ lực này đã dẫn đến năng suất của nhóm thấp hơn và tăng chi phí chung. Ngoài ra, với một nhóm đang phát triển nhanh chóng, việc chia sẻ kiến thức này trong nhóm là rất khó khăn.
Vì các khái niệm MLOps rất rộng và việc thực hiện tất cả các bước sẽ cần thời gian, nên chúng tôi quyết định rằng trong giai đoạn đầu tiên, chúng tôi sẽ giải quyết các vấn đề cốt lõi sau:
- Một môi trường an toàn, được kiểm soát và tạo khuôn mẫu để đào tạo lại mô hình học sâu nội bộ của chúng tôi bằng cách sử dụng các phương pháp hay nhất trong ngành
- Một môi trường đào tạo được tham số hóa để gửi một bộ tham số khác nhau cho từng công việc đào tạo lại và kiểm tra các lần chạy cuối cùng
- Khả năng theo dõi trực quan các chỉ số đào tạo và chỉ số đánh giá, đồng thời có siêu dữ liệu để theo dõi và so sánh các thử nghiệm
- Khả năng mở rộng quy mô từng bước riêng lẻ và sử dụng lại các bước trước đó trong trường hợp lỗi bước
- Một môi trường chuyên dụng duy nhất để đăng ký các mô hình, lưu trữ các tính năng và gọi các đường ống dẫn suy luận
- Một bộ công cụ hiện đại có thể giảm thiểu yêu cầu điện toán, giảm chi phí và thúc đẩy hoạt động và phát triển ML bền vững bằng cách kết hợp tính linh hoạt của việc sử dụng các phiên bản khác nhau cho các bước khác nhau
- Tạo mẫu điểm chuẩn của quy trình MLOps hiện đại có thể được sử dụng trong các nhóm khoa học dữ liệu khác nhau
Games24x7 bắt đầu đánh giá các giải pháp khác, bao gồm Đường ống Amazon SageMaker Studio. Giải pháp hiện có thông qua Step Functions có những hạn chế. Studio pipelines có thể linh hoạt thêm hoặc xóa một bước tại bất kỳ thời điểm nào. Ngoài ra, kiến trúc tổng thể và sự phụ thuộc dữ liệu của chúng giữa mỗi bước có thể được hiển thị thông qua DAG. Việc đánh giá và tinh chỉnh các bước đào tạo lại trở nên khá hiệu quả sau khi chúng tôi áp dụng các chức năng khác nhau của Amazon SageMaker như Amazon SageMaker Studio, Đường ống, Xử lý, Đào tạo, đăng ký mô hình cũng như các thử nghiệm và bản dùng thử. Nhóm Kiến trúc giải pháp AWS đã thể hiện khả năng nghiên cứu sâu tuyệt vời và thực sự đóng vai trò quan trọng trong việc thiết kế và triển khai giải pháp này.
Tổng quan về giải pháp
Sơ đồ sau minh họa kiến trúc giải pháp.
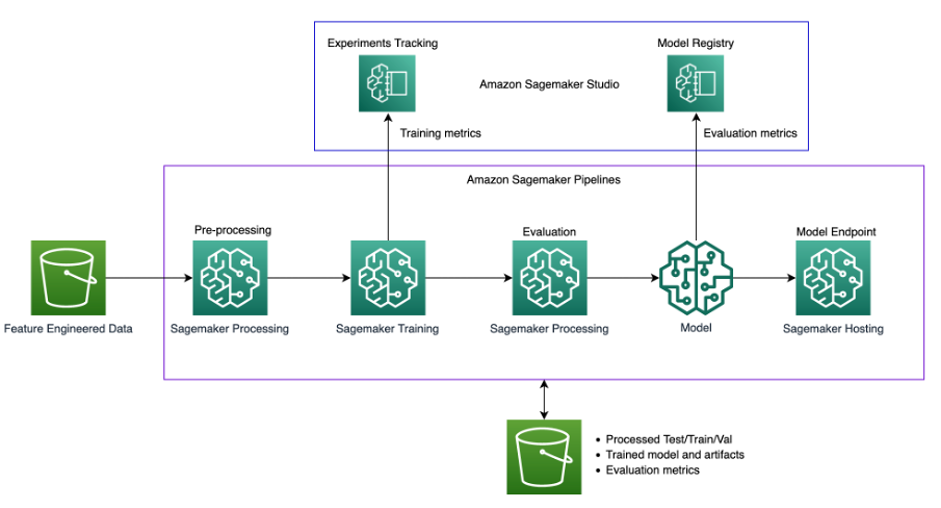
Giải pháp sử dụng một Studio SageMaker môi trường để chạy các thí nghiệm đào tạo lại. Mã để gọi tập lệnh đường ống có sẵn trong sổ ghi chép của Studio và chúng tôi có thể thay đổi siêu tham số cũng như đầu vào/đầu ra khi gọi đường ống. Điều này hoàn toàn khác với phương pháp trước đây của chúng tôi, nơi chúng tôi có tất cả các tham số được mã hóa cứng trong các tập lệnh và tất cả các quy trình được liên kết chặt chẽ với nhau. Điều này yêu cầu mô đun hóa mã nguyên khối thành các bước khác nhau.
Sơ đồ sau đây minh họa quy trình nguyên khối ban đầu của chúng tôi.
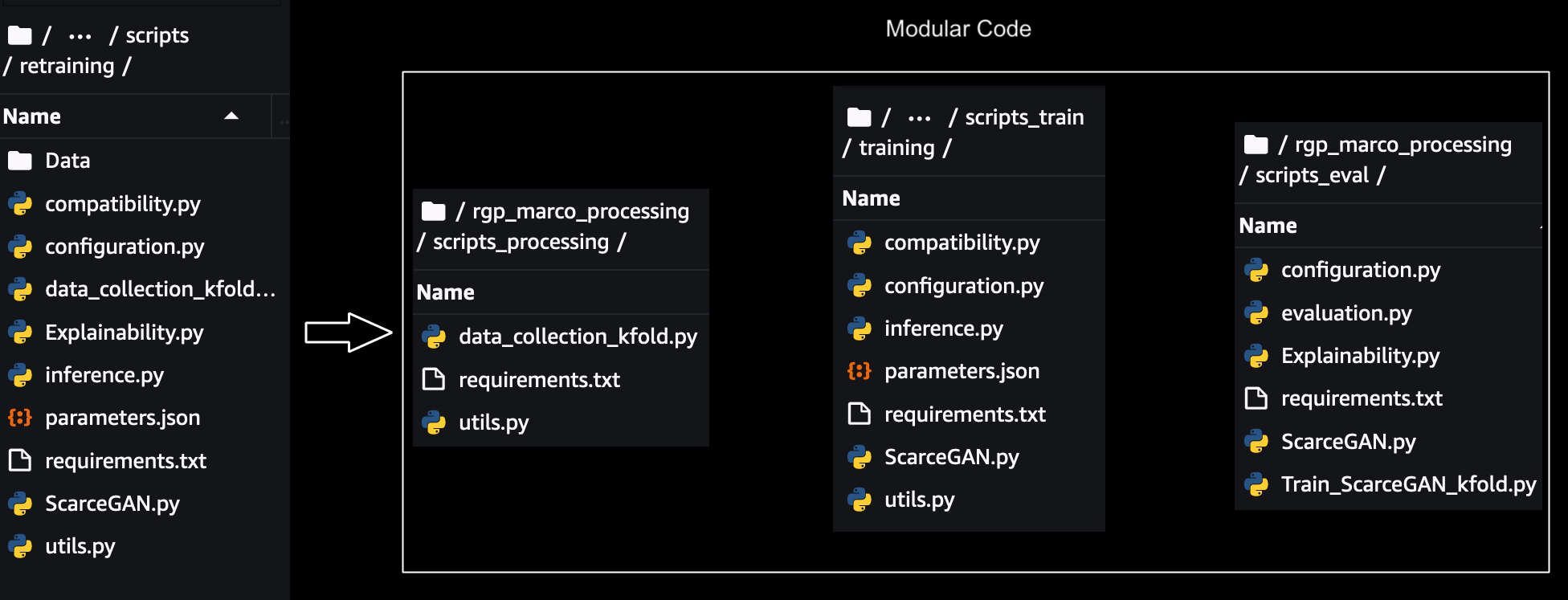
Mô-đun hóa
Để chia tỷ lệ, theo dõi và chạy từng bước riêng lẻ, mã nguyên khối cần phải được mô đun hóa. Các phần phụ thuộc tham số, dữ liệu và mã giữa mỗi bước đã bị xóa và các mô-đun dùng chung cho các thành phần dùng chung trong các bước đã được tạo. Một minh họa về mô đun hóa được hiển thị bên dưới: -
Đối với mỗi mô-đun đơn lẻ, thử nghiệm được thực hiện cục bộ bằng SageMaker SDK's Chế độ tập lệnh cho đào tạo, xử lý và đánh giá mà thay đổi nhỏ bắt buộc trong mã để chạy với SageMaker. Các thử nghiệm chế độ cục bộ đối với các tập lệnh học sâu có thể được thực hiện trên sổ ghi chép SageMaker nếu đã được sử dụng hoặc bằng cách sử dụng Chế độ cục bộ sử dụng Đường ống SageMaker trong trường hợp bắt đầu trực tiếp với Đường ống. Điều này giúp xác thực xem các tập lệnh tùy chỉnh của chúng tôi có chạy trên các phiên bản SageMaker hay không.
Sau đó, mỗi mô-đun được thử nghiệm riêng biệt bằng cách sử dụng SDK đào tạo/xử lý SageMaker bằng cách sử dụng Chế độ tập lệnh và chạy chúng theo trình tự thủ công bằng cách sử dụng các phiên bản SageMaker cho từng bước như bước đào tạo bên dưới:
Amazon S3 được sử dụng để lấy dữ liệu nguồn để xử lý, sau đó lưu trữ dữ liệu trung gian, khung dữ liệu và kết quả NumPy trở lại Amazon S3 cho bước tiếp theo. Sau khi thử nghiệm tích hợp giữa các mô-đun riêng lẻ để tiền xử lý, đào tạo, đánh giá hoàn tất, SDK đường ống của SageMaker được tích hợp với SageMaker Python SDK mà chúng tôi đã sử dụng trong các bước trên, cho phép chúng tôi xâu chuỗi tất cả các mô-đun này theo chương trình bằng cách chuyển các tham số đầu vào, dữ liệu, siêu dữ liệu và đầu ra của từng bước làm đầu vào cho các bước tiếp theo.
Chúng tôi có thể sử dụng lại mã Sagemaker Python SDK trước đó để chạy các mô-đun riêng lẻ vào các lần chạy dựa trên Sagemaker Pipeline SDK. Mối quan hệ giữa từng bước của quy trình được xác định bởi sự phụ thuộc dữ liệu giữa các bước.
Các bước cuối cùng của đường ống như sau:
- Tiền xử lý dữ liệu
- Đào tạo lại
- Đánh giá
- Đăng ký người mẫu
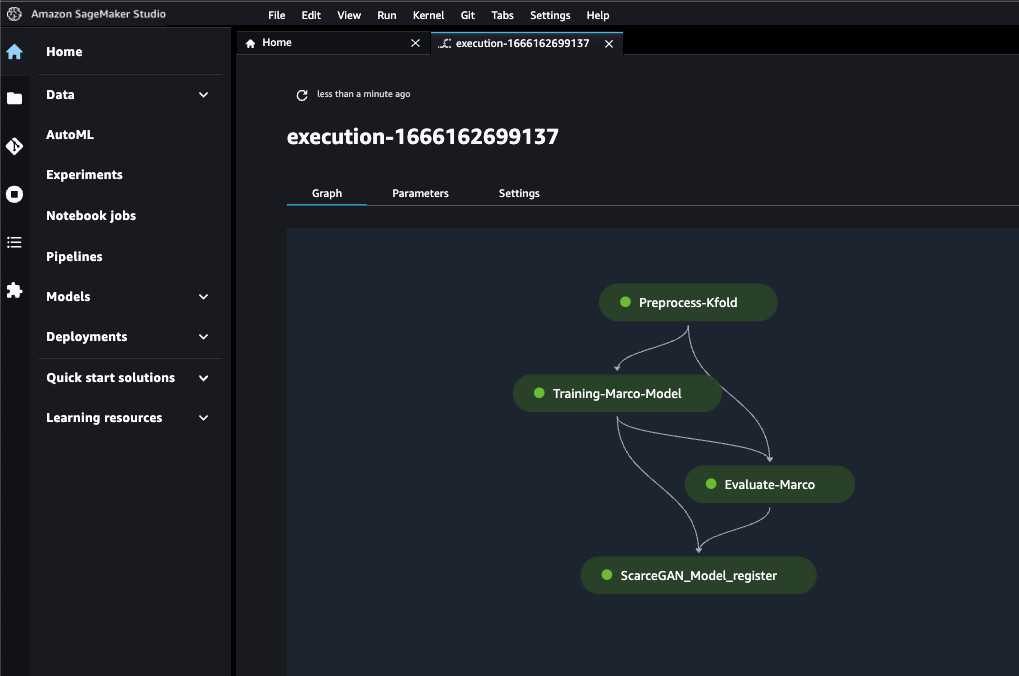
Trong các phần sau, chúng tôi sẽ thảo luận chi tiết hơn về từng bước khi chạy với SageMaker Pipeline SDK's.
Tiền xử lý dữ liệu
Bước này biến đổi dữ liệu đầu vào thô và tiền xử lý, đồng thời chia thành các tập huấn luyện, xác thực và kiểm tra. Đối với bước xử lý này, chúng tôi đã khởi tạo một công việc xử lý SageMaker với Bộ xử lý khung TensorFlow, lấy tập lệnh của chúng tôi, sao chép dữ liệu từ Amazon S3, sau đó lấy hình ảnh Docker do SageMaker cung cấp và duy trì. Bộ chứa Docker này cho phép chúng tôi chuyển các phụ thuộc thư viện của mình vào tệp tests.txt trong khi đã bao gồm tất cả các thư viện TensorFlow và chuyển đường dẫn cho source_dir cho tập lệnh. Dữ liệu đào tạo và xác thực chuyển sang bước đào tạo và dữ liệu thử nghiệm được chuyển tiếp đến bước đánh giá. Phần tốt nhất của việc sử dụng vùng chứa này là nó cho phép chúng tôi chuyển nhiều loại đầu vào và đầu ra dưới dạng các vị trí S3 khác nhau, sau đó có thể chuyển các vị trí này dưới dạng bước phụ thuộc sang các bước tiếp theo trong quy trình SageMaker.
Đào tạo lại
Chúng tôi kết thúc mô-đun đào tạo thông qua Đường ống SageMaker TrainingStep API và sử dụng hình ảnh bộ chứa deep learning đã có sẵn thông qua công cụ ước tính TensorFlow Framework (còn được gọi là chế độ Tập lệnh) cho Đào tạo SageMaker. Chế độ tập lệnh cho phép chúng tôi có những thay đổi tối thiểu trong mã đào tạo của mình và bộ chứa Docker dựng sẵn của SageMaker xử lý các phiên bản Python, Framework, v.v. Kết quả xử lý từ Data_Preprocessing bước được chuyển tiếp dưới dạng Đầu vào đào tạo của bước này.
Tất cả các siêu đường kính được chuyển qua công cụ ước tính thông qua tệp JSON. Đối với mỗi kỷ nguyên trong quá trình đào tạo của chúng tôi, chúng tôi đã gửi các chỉ số đào tạo của mình thông qua stdOut trong tập lệnh. Bởi vì chúng tôi muốn theo dõi các chỉ số của một công việc đào tạo đang diễn ra và so sánh chúng với các công việc đào tạo trước đó, nên chúng tôi chỉ cần phân tích cú pháp StdOut này bằng cách xác định các định nghĩa chỉ số thông qua biểu thức chính quy để tìm nạp các chỉ số từ StdOut cho mỗi kỷ nguyên.
Thật thú vị khi hiểu rằng SageMaker Pipelines tự động tích hợp với API thử nghiệm SageMaker, mà theo mặc định sẽ tạo thành phần thử nghiệm, bản dùng thử và bản dùng thử cho mỗi lần chạy. Điều này cho phép chúng tôi so sánh các chỉ số đào tạo như độ chính xác và độ chính xác qua nhiều lần chạy như hình bên dưới.
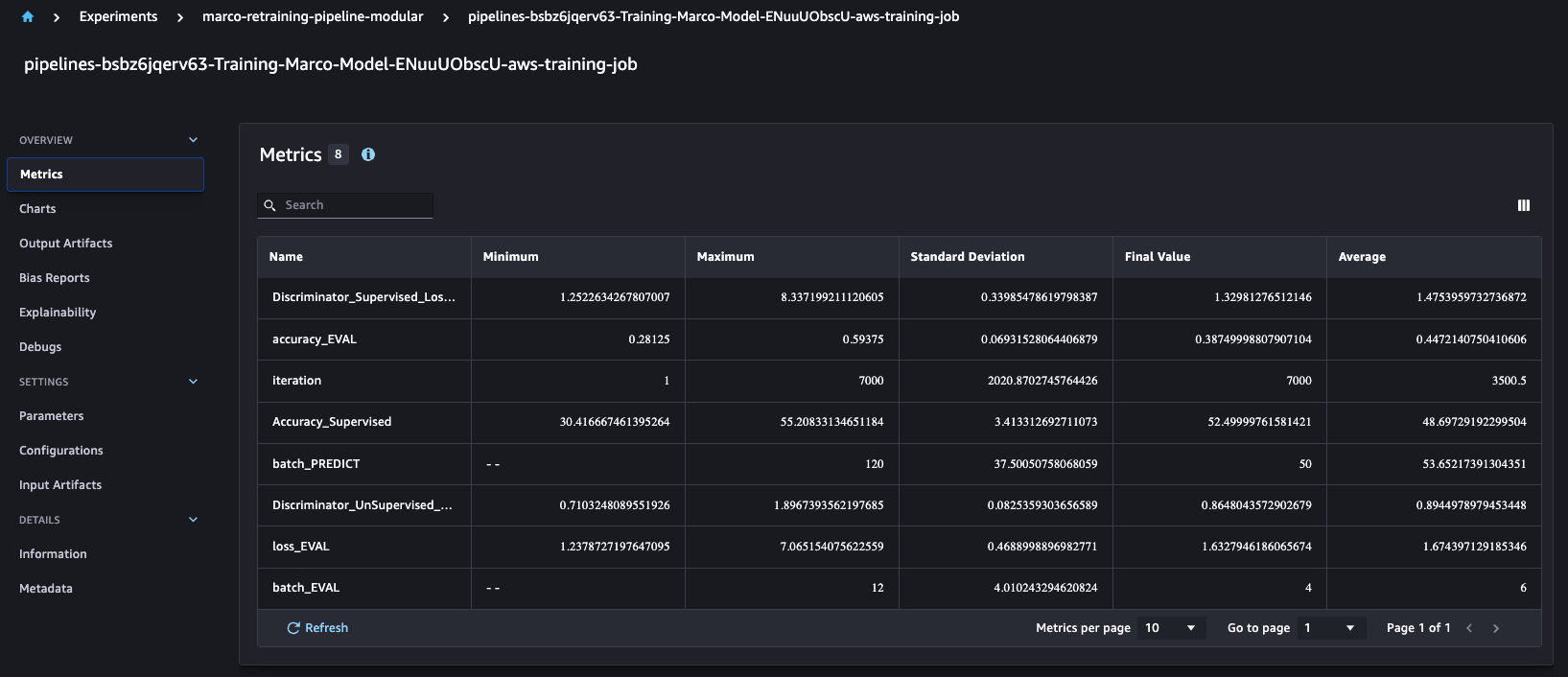
Đối với mỗi lần chạy công việc đào tạo, chúng tôi tạo bốn mô hình khác nhau cho Amazon S3 dựa trên định nghĩa kinh doanh tùy chỉnh của chúng tôi.
Đánh giá
Bước này tải các mô hình được đào tạo từ Amazon S3 và đánh giá dựa trên các chỉ số tùy chỉnh của chúng tôi. Bước Xử lý này lấy mô hình và dữ liệu thử nghiệm làm đầu vào và kết xuất các báo cáo về hiệu suất của mô hình trên Amazon S3.
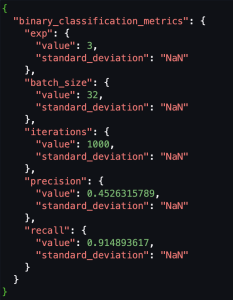
Chúng tôi đang sử dụng các chỉ số tùy chỉnh, vì vậy, để đăng ký các chỉ số tùy chỉnh này với cơ quan đăng ký mô hình, chúng tôi cần chuyển đổi giản đồ của các chỉ số đánh giá được lưu trữ trong Amazon S3 dưới dạng CSV sang định dạng CSV. Chất lượng mô hình SageMaker Đầu ra JSON. Sau đó, chúng ta có thể đăng ký vị trí của các chỉ số JSON đánh giá này vào sổ đăng ký mô hình.
Các ảnh chụp màn hình sau đây cho thấy ví dụ về cách chúng tôi chuyển đổi CSV sang định dạng JSON chất lượng của Mô hình Sagemaker.

Đăng ký người mẫu
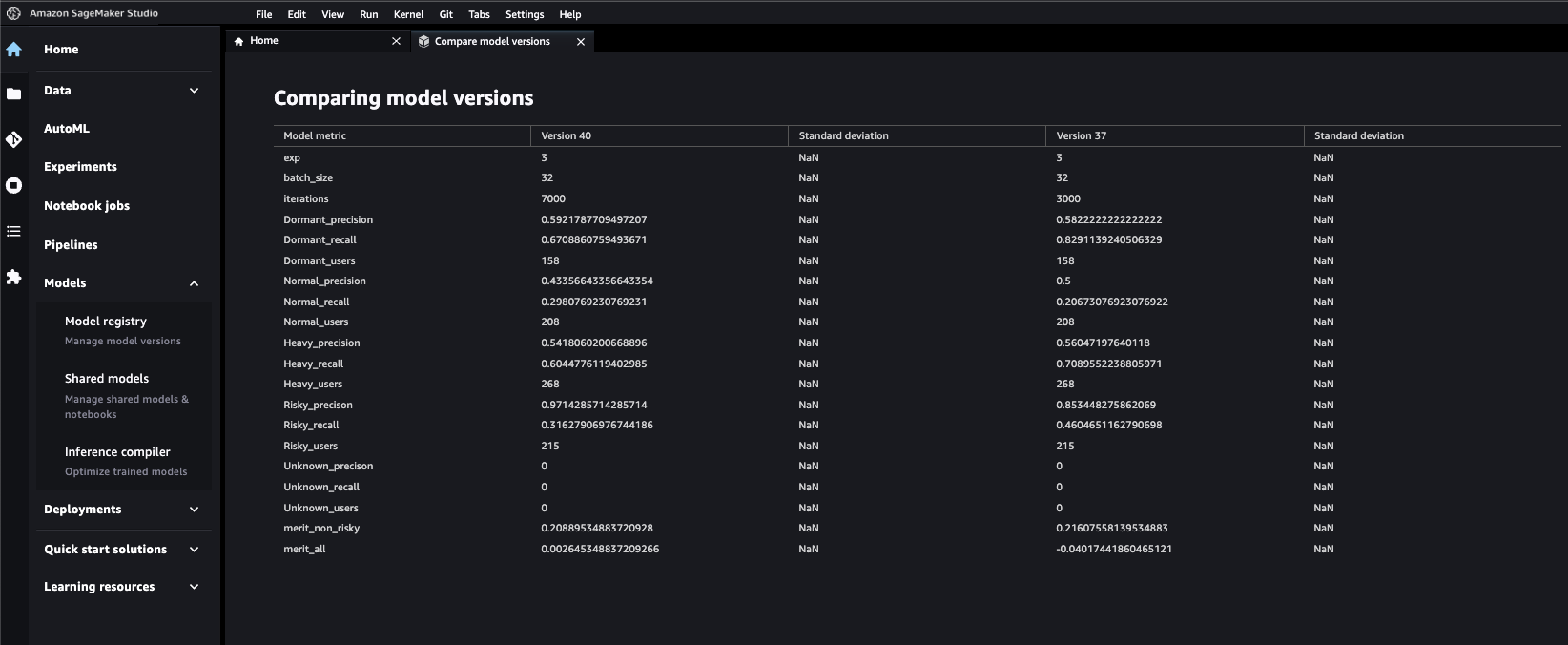
Như đã đề cập trước đó, chúng tôi đang tạo nhiều mô hình trong một bước đào tạo duy nhất, vì vậy chúng tôi phải sử dụng tích hợp SageMaker Pipelines Lambda để đăng ký cả bốn mô hình vào sổ đăng ký mô hình. Đối với một đăng ký mô hình duy nhất, chúng tôi có thể sử dụng Mô hìnhBước API để tạo mô hình SageMaker trong sổ đăng ký. Đối với mỗi mô hình, hàm Lambda truy xuất phần mềm mô hình và chỉ số đánh giá từ Amazon S3, đồng thời tạo gói mô hình cho một ARN cụ thể để có thể đăng ký cả bốn mô hình vào một sổ đăng ký mô hình duy nhất. API Python của SageMaker cũng cho phép chúng tôi gửi siêu dữ liệu tùy chỉnh mà chúng tôi muốn chuyển để chọn các mô hình tốt nhất. Đây được chứng minh là một cột mốc quan trọng đối với năng suất vì giờ đây tất cả các mô hình có thể được so sánh và kiểm tra từ một cửa sổ duy nhất. Chúng tôi đã cung cấp siêu dữ liệu để phân biệt duy nhất mô hình với nhau. Điều này cũng giúp phê duyệt một mô hình duy nhất với sự trợ giúp của đánh giá ngang hàng và đánh giá của ban quản lý dựa trên các số liệu của mô hình.
Khối mã trên cho thấy một ví dụ về cách chúng tôi đã thêm siêu dữ liệu thông qua đầu vào gói mô hình vào sổ đăng ký mô hình cùng với các chỉ số mô hình.
Ảnh chụp màn hình bên dưới cho thấy chúng tôi có thể so sánh số liệu của các phiên bản mô hình khác nhau dễ dàng như thế nào sau khi chúng được đăng ký.
Yêu cầu đường ống
Các đường ống có thể được gọi thông qua Tổ chức sự kiện , Sagemaker Studio hoặc SDK chính nó. Lời gọi chạy các công việc dựa trên sự phụ thuộc dữ liệu giữa các bước.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách Games24x7 chuyển đổi nội dung MLOps của họ thông qua các đường dẫn SageMaker. Khả năng theo dõi trực quan các chỉ số đào tạo và chỉ số đánh giá, với môi trường được tham số hóa, mở rộng quy mô các bước riêng lẻ với nền tảng xử lý phù hợp và sổ đăng ký mô hình trung tâm đã chứng tỏ là một cột mốc quan trọng trong việc chuẩn hóa và tiến tới quy trình làm việc có thể kiểm tra, tái sử dụng, hiệu quả và có thể giải thích được . Dự án này là một kế hoạch chi tiết giữa các nhóm khoa học dữ liệu khác nhau và đã tăng năng suất tổng thể bằng cách cho phép các thành viên vận hành, quản lý và cộng tác với các phương pháp hay nhất.
Nếu bạn có trường hợp sử dụng tương tự và muốn bắt đầu thì chúng tôi khuyên bạn nên xem qua SageMaker Chế độ tập lệnh và Các ví dụ từ đầu đến cuối của SageMaker sử dụng Sagemaker Studio. Những ví dụ này có các chi tiết kỹ thuật đã được đề cập trong blog này.
Chiến lược dữ liệu hiện đại cung cấp cho bạn một kế hoạch toàn diện để quản lý, truy cập, phân tích và hành động trên dữ liệu. AWS cung cấp bộ dịch vụ hoàn chỉnh nhất cho toàn bộ hành trình dữ liệu từ đầu đến cuối cho mọi khối lượng công việc, mọi loại dữ liệu và mọi kết quả kinh doanh mong muốn. Đổi lại, điều này làm cho AWS trở thành nơi tốt nhất để khai thác giá trị từ dữ liệu của bạn và biến nó thành thông tin chi tiết.
Về các tác giả
![]() Hussain Jagirdar là Nhà khoa học cấp cao - Nghiên cứu ứng dụng tại Games24x7. Anh ấy hiện đang tham gia vào các nỗ lực nghiên cứu trong lĩnh vực AI có thể giải thích được và học sâu. Công việc gần đây của anh ấy liên quan đến mô hình tổng quát sâu, mô hình chuỗi thời gian và các lĩnh vực con liên quan của máy học và AI. Anh ấy cũng đam mê MLOps và các dự án tiêu chuẩn hóa đòi hỏi những hạn chế như khả năng mở rộng, độ tin cậy và độ nhạy.
Hussain Jagirdar là Nhà khoa học cấp cao - Nghiên cứu ứng dụng tại Games24x7. Anh ấy hiện đang tham gia vào các nỗ lực nghiên cứu trong lĩnh vực AI có thể giải thích được và học sâu. Công việc gần đây của anh ấy liên quan đến mô hình tổng quát sâu, mô hình chuỗi thời gian và các lĩnh vực con liên quan của máy học và AI. Anh ấy cũng đam mê MLOps và các dự án tiêu chuẩn hóa đòi hỏi những hạn chế như khả năng mở rộng, độ tin cậy và độ nhạy.
![]() Sumir Kumar là Kiến trúc sư giải pháp tại AWS và có hơn 13 năm kinh nghiệm trong ngành công nghệ. Tại AWS, anh hợp tác chặt chẽ với các khách hàng chính của AWS để thiết kế và triển khai các giải pháp dựa trên đám mây nhằm giải quyết các vấn đề kinh doanh phức tạp. Anh ấy rất đam mê phân tích dữ liệu và máy học, đồng thời có thành tích đã được chứng minh trong việc giúp các tổ chức khai thác toàn bộ tiềm năng dữ liệu của họ bằng Đám mây AWS.
Sumir Kumar là Kiến trúc sư giải pháp tại AWS và có hơn 13 năm kinh nghiệm trong ngành công nghệ. Tại AWS, anh hợp tác chặt chẽ với các khách hàng chính của AWS để thiết kế và triển khai các giải pháp dựa trên đám mây nhằm giải quyết các vấn đề kinh doanh phức tạp. Anh ấy rất đam mê phân tích dữ liệu và máy học, đồng thời có thành tích đã được chứng minh trong việc giúp các tổ chức khai thác toàn bộ tiềm năng dữ liệu của họ bằng Đám mây AWS.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/how-games24x7-transformed-their-retraining-mlops-pipelines-with-amazon-sagemaker/

