Nhóm Tăng trưởng người bán quốc tế của Amazon (ISG) điều hành chương trình CSBA (Dịch vụ khách hàng của Amazon) hỗ trợ hơn 200,000 người bán thuộc Mạng lưới hoàn thiện đơn hàng của người bán (MFN) bên thứ ba. Các trung tâm cuộc gọi của Amazon hỗ trợ hàng trăm nghìn cuộc gọi điện thoại, trò chuyện và email giữa người tiêu dùng và người bán MFN của Amazon. Khối lượng lớn các liên hệ tạo ra một thách thức đối với CSBA trong việc trích xuất thông tin chính từ bảng điểm giúp người bán giải quyết kịp thời nhu cầu của khách hàng và cải thiện trải nghiệm của khách hàng. Do đó, điều quan trọng là phải tự động khám phá thông tin chuyên sâu từ các bản ghi này, thực hiện phát hiện chủ đề để phân tích nhiều cuộc trò chuyện của khách hàng và tự động trình bày một bộ chủ đề chỉ ra những lý do hàng đầu khiến khách hàng liên hệ, để các vấn đề của khách hàng được giải quyết đúng cách và như sớm nhất có thể.
Bài đăng này trình bày một giải pháp sử dụng quy trình làm việc cũng như các dịch vụ AWS AI và máy học (ML) để cung cấp thông tin chuyên sâu có thể hành động dựa trên các bản ghi đó. Chúng tôi sử dụng nhiều dịch vụ AWS AI/ML, chẳng hạn như Kính áp tròng cho Amazon Connect và Amazon SageMakervà sử dụng một kiến trúc kết hợp. Giải pháp này được thử nghiệm với ISG bằng cách sử dụng một lượng nhỏ mẫu dữ liệu. Trong bài đăng này, chúng tôi thảo luận về quá trình suy nghĩ, xây dựng giải pháp này và kết quả từ thử nghiệm. Chúng tôi tin rằng những bài học kinh nghiệm và hành trình của chúng tôi được trình bày ở đây có thể giúp ích cho bạn trên hành trình của chính mình.
Bối cảnh hoạt động và quy trình làm việc của doanh nghiệp
Hình dưới đây cho thấy bối cảnh hoạt động được đề xuất với các bên liên quan và quy trình kinh doanh cho ISG để người bán có thể ở gần khách hàng của họ mọi lúc, mọi nơi. Người tiêu dùng liên hệ với Dịch vụ khách hàng thông qua nền tảng trung tâm liên lạc và tương tác với Cộng tác viên dịch vụ khách hàng (CSA). Sau đó, bảng điểm của các liên hệ sẽ có sẵn cho CSBA để trích xuất thông tin chi tiết có thể hành động thông qua hàng triệu liên hệ của khách hàng cho người bán và dữ liệu được lưu trữ trong Hồ dữ liệu của người bán. Người bán sử dụng cổng thông tin Trung tâm người bán của Amazon để truy cập kết quả phân tích và thực hiện hành động để giải quyết các vấn đề của khách hàng một cách nhanh chóng và hiệu quả.
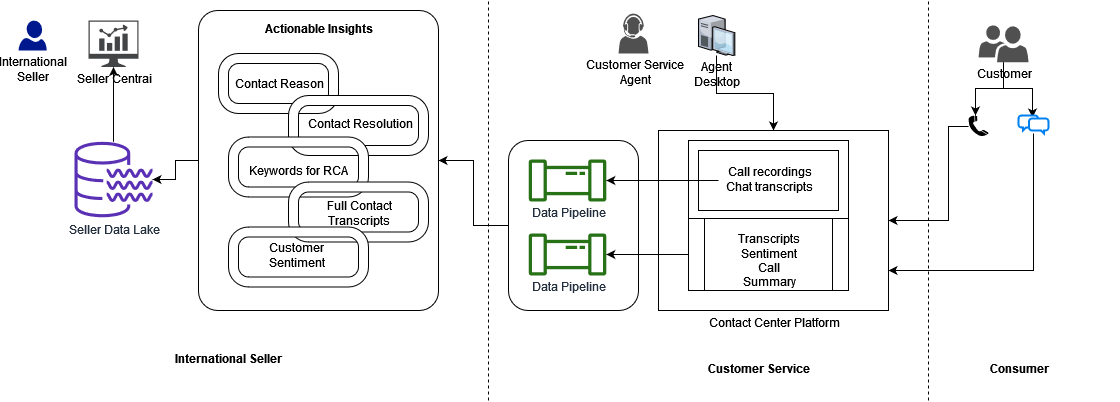
Tổng quan về giải pháp
Sơ đồ sau đây cho thấy kiến trúc phản ánh các hoạt động của quy trình làm việc trong các dịch vụ AI/ML và ETL (trích xuất, chuyển đổi và tải).
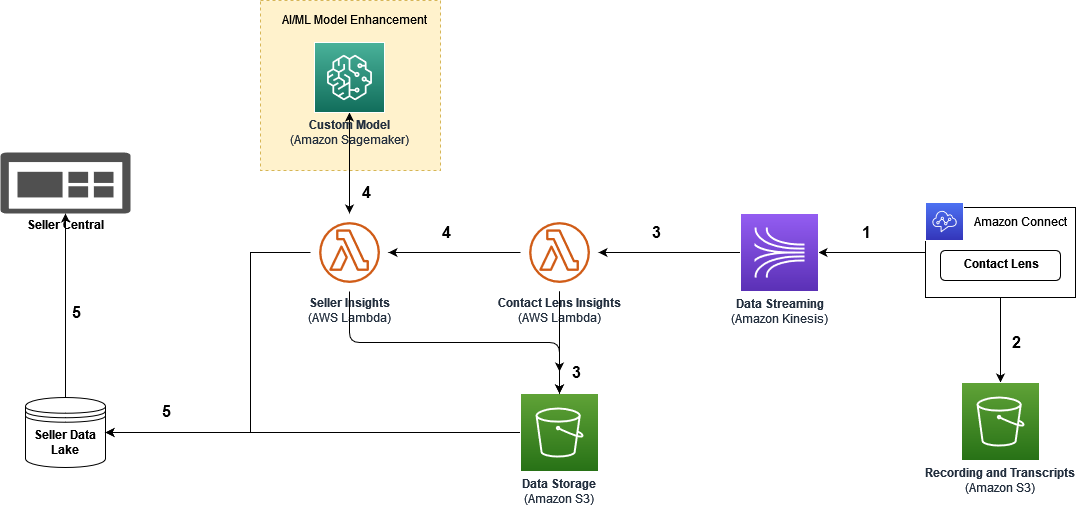
Các bước quy trình làm việc như sau:
- Chúng tôi sử dụng Kết nối Amazon làm trung tâm liên hệ trên đám mây cho các tương tác giữa người tiêu dùng và CSA. Contact Lens for Amazon Connect tạo bản ghi cuộc gọi và trò chuyện; rút ra bản tóm tắt liên hệ, phân tích, phân loại tương tác giữa khách hàng và cộng sự và phát hiện vấn đề; và đo lường tình cảm của khách hàng.
- Contact Lens sau đó lưu trữ dữ liệu phân tích vào một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) thùng để lưu giữ lâu dài.
- Luồng dữ liệu Amazon Kinesis thu thập và chuyển dữ liệu phân tích thông lượng cao, được xử lý bởi AWS Lambda, đưa và lưu trữ dữ liệu vào một trung gian Xô S3. Ở giai đoạn này, dữ liệu chứa bản ghi cuộc gọi và cuộc trò chuyện, điểm số cảm tính, sự cố đã phát hiện và danh mục.
- Nó kích hoạt các hàm Lambda để nhập luồng dữ liệu, trích xuất các trường dữ liệu được yêu cầu và kích hoạt suy luận của các phân tích ML tùy chỉnh bởi các dịch vụ AI/ML của AWS, trên kết quả của Contact Lens. Trong phân tích này, Contact Lens cung cấp điểm số cảm tính chính xác khi đo lường khách hàng sự hài lòng về tương tác của người tiêu dùng-CSA. Các quy tắc của Contact Lens giúp chúng tôi phân loại các sự cố đã biết trong trung tâm liên hệ. Ở giai đoạn này, ISG muốn cung cấp thông tin chi tiết bổ sung cho người bán bằng cách phát hiện chủ đề thông qua khám phá các vấn đề chưa biết trước đây trong các cuộc gọi dành riêng cho người bán, các giải pháp đã thực hiện và các cụm từ khóa cụ thể. Tại đây, một mô hình non-deep learning đã được đào tạo và chạy trên SageMaker, chi tiết về mô hình này sẽ được giải thích trong phần sau.
- Sau khi phân tích dựa trên AI/ML, tất cả thông tin chi tiết có thể hành động được tạo và sau đó được lưu trữ trong Hồ dữ liệu người bán. Thông tin chi tiết được chia sẻ trên Cổng thông tin trung tâm của người bán để người bán quốc tế xác định nguyên nhân gốc rễ và có hành động kịp thời.
Trong các phần sau, chúng ta sẽ tìm hiểu sâu hơn về giải pháp AI/ML và các thành phần của nó.
Ghi nhãn dữ liệu
Trong phần này, chúng tôi mô tả cách tiếp cận của chúng tôi đối với việc ghi nhãn dữ liệu để xác định lý do liên hệ và cách giải quyết cũng như phương pháp trích xuất từ khóa của chúng tôi để người bán thực hiện phân tích nguyên nhân gốc rễ.
Lý do liên hệ và ghi nhãn giải pháp
Để phát hiện lý do liên hệ từ bản chép lời của ML, chúng tôi đã sử dụng bảy Mã vấn đề được chuẩn hóa (SIC) làm nhãn dữ liệu từ dữ liệu mẫu do nhóm ISG cung cấp:
- Đã liên hệ với người bán để yêu cầu hủy bỏ
- Theo dõi cho thấy giao hàng nhưng không nhận được hàng
- Lô hàng không gửi được
- Lô hàng không được giao quá ngày giao hàng
- Đang chuyển hàng cho khách
- Yêu cầu trả lại nhãn gửi thư (RML)
- hàng không thể trả lại
Nhãn lý do liên hệ có thể được mở rộng thêm bằng cách thêm các vấn đề chưa biết trước đó cho người bán; tuy nhiên, những vấn đề đó chưa được xác định trong SIC. Không giống như lý do liên hệ, giải pháp liên hệ không có nhãn được liên kết với bản ghi. Nhóm ISG đã chỉ định các danh mục độ phân giải và các độ phân giải cần được gắn nhãn dựa trên các danh mục này. Vì vậy, chúng tôi đã tận dụng Sự thật về mặt đất của Amazon SageMaker để tạo hoặc cập nhật nhãn cho từng liên hệ.
Ground Truth cung cấp dịch vụ gắn nhãn dữ liệu giúp dễ dàng gắn nhãn dữ liệu và cung cấp cho bạn tùy chọn sử dụng trình chú thích của con người thông qua Amazon Mechanical Turk, nhà cung cấp bên thứ ba, hoặc là lực lượng lao động riêng của bạn. Đối với giải pháp này, nhóm ISG đã xác định các danh mục để giải quyết liên hệ trong hơn 140 tài liệu bản ghi, được các nhà thầu của Amazon Mechanical Turk gắn nhãn:
- Hoàn trả đầy đủ – 69 hồ sơ
- Liên hệ với người bán – 52 hồ sơ
- Hoàn lại một phần – 15 hồ sơ
- Nền tảng khác – 4 hồ sơ
Chỉ mất vài giờ để các nhà thầu hoàn thành việc dán nhãn giải pháp trung tâm liên hệ phân loại văn bản đa nhãn cho 140 tài liệu và yêu cầu khách hàng xem xét chúng. Trong bước tiếp theo, chúng tôi xây dựng các mô hình phân loại nhiều lớp, sau đó dự đoán lý do liên hệ và cách giải quyết từ bản ghi cuộc gọi và trò chuyện mới đến từ dịch vụ khách hàng.
Từ khóa để phân tích nguyên nhân gốc rễ
Một thách thức khác là trích xuất các từ khóa từ bản ghi có thể hướng dẫn người bán MFN thực hiện các hành động cụ thể. Đối với ví dụ này, người bán cần nắm bắt thông tin chính như thông tin sản phẩm, mốc thời gian quan trọng, chi tiết vấn đề và khoản tiền hoàn lại do CSA cung cấp, những thông tin này có thể không rõ ràng. Ở đây, chúng tôi đã xây dựng mô hình trích xuất cụm từ khóa tùy chỉnh trong SageMaker bằng thuật toán RAKE (Trích xuất từ khóa tự động nhanh), theo quy trình được hiển thị trong hình dưới đây. RAKE là một thuật toán trích xuất từ khóa độc lập với miền xác định các cụm từ chính bằng cách phân tích tần suất xuất hiện của từ và sự xuất hiện của từ đó với các từ khác trong văn bản.
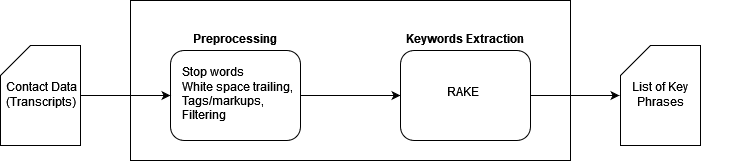
Sau quá trình tiền xử lý tài liệu tiêu chuẩn, RAKE phát hiện các từ và cụm từ khóa có liên quan nhất từ các tài liệu bản ghi. Đầu ra được liệt kê như sau:
Phương pháp này nắm bắt các cụm từ khóa có điểm số liên quan cao trên các thông tin quan trọng như thời gian (“ngày 23 tháng 5”), giải pháp hoàn tiền (“thẻ quà tặng Amazon,” “trong 1793 ngày làm việc”), thông tin sản phẩm (“lò nướng kết hợp than hoa,” “ khí nhiên liệu kép,” “gbcXNUMXw”) và chi tiết vấn đề (“bộ phận bị lỗi,” “bộ phận bị cong”). Những thông tin chi tiết này không chỉ cho người bán biết rằng khách hàng này đã được chăm sóc bằng cách được hoàn lại tiền mà còn hướng dẫn người bán điều tra thêm về lỗi sản phẩm bếp nướng gas và tránh gặp sự cố tương tự cho những khách hàng khác.
Đào tạo mô hình phân loại văn bản
Contact Lens đã tạo bảng điểm, tóm tắt liên hệ và cảm nhận cho các mẫu cuộc gọi và trò chuyện được thu thập từ Dịch vụ khách hàng của ISG. Trong suốt quá trình thử nghiệm, điểm số về phiên âm và cảm xúc đều chính xác như mong đợi. Cùng với các vấn đề đã biết, nhóm ISG cũng tìm cách phát hiện các vấn đề chưa biết từ bảng điểm để đáp ứng các nhu cầu cụ thể của người bán, chẳng hạn như vấn đề giao hàng, lỗi sản phẩm, cách giải quyết do người liên hệ cung cấp và các vấn đề hoặc cụm từ chính dẫn đến việc trả lại hàng hoặc hoàn tiền.
Để giải quyết thách thức này, chúng tôi đã mở rộng các thử nghiệm của mình thông qua các mô hình tùy chỉnh trên SageMaker. Kinh nghiệm của chúng tôi chỉ ra các mô hình dựa trên “bag-of-words”, thông thường hơn (không học sâu) bằng cách sử dụng SageMaker dựa trên kích thước của tập dữ liệu và các mẫu.
Chúng tôi đã thực hiện mô hình phân loại lý do liên hệ theo ba bước trên SageMaker như minh họa trong hình dưới đây.

Các bước thực hiện như sau:
- Sơ chế – Chúng tôi đã sử dụng thư viện NLTK để hạ thấp các trường hợp; xóa dấu câu, thẻ, đánh dấu và dấu khoảng trắng; và lọc các chữ cái đơn lẻ, giá trị số và danh sách từ dừng tùy chỉnh.
- Vector hóa – Chúng tôi đã sử dụng TF-IDF (Tần số thuật ngữ-Tần suất tài liệu nghịch đảo) để chuyển đổi tài liệu được xử lý thành ma trận các tính năng TF-IDF. Phương pháp định lượng tầm quan trọng và mức độ liên quan của các từ và cụm từ trong tài liệu với một bộ sưu tập tài liệu (tập văn bản), sau đó tạo các tính năng ở dạng giá trị số để biểu thị mức độ quan trọng của một từ đối với tài liệu trong tập văn bản. Đối với giải pháp này, chúng tôi đã thử nghiệm với việc chỉ định 750 và 1,500 tính năng.
- Phân loại nhiều lớp – Chúng tôi đã tạo mô hình phân loại bảy lớp bằng cách sử dụng danh sách tính năng được vector hóa và nhãn SIC. Chúng tôi đã sử dụng 90% mẫu để đào tạo và 10% để xác nhận.
Chúng tôi đã thử nghiệm ba thuật toán nhằm đạt được mô hình hoạt động tốt nhất:
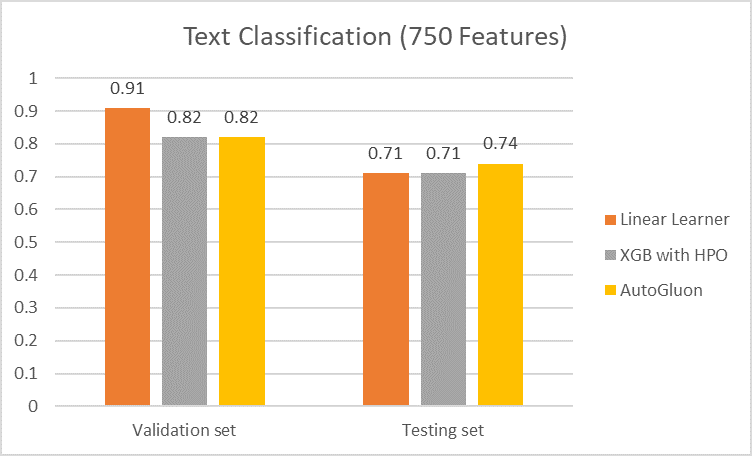
- Đầu tiên, chúng tôi sử dụng Trình học tuyến tính SageMaker thuật toán với siêu tham số mặc định và thực hiện 10 kỷ nguyên và đạt độ chính xác 71% cho bộ thử nghiệm.
- Tiếp theo, chúng tôi đã sử dụng Thuật toán XGBoost tích hợp SageMakervà chạy điều chỉnh tự động tối ưu hóa siêu tham số (HPO) trên bốn tham số (eta, alpha, min_child_weight, max_depth), mang lại cho chúng tôi độ chính xác 71% đối với bộ thử nghiệm.
- Cuối cùng, chúng tôi đã làm việc với Khung AutoML của AutoGluon trên SageMaker, thực hiện mô hình hóa tự động và lựa chọn siêu tham số với nhiều mô hình tập hợp và xếp chồng nhiều lớp. Khung đã đào tạo 13 mô hình và tạo ra mô hình tập hợp cuối cùng mang lại độ chính xác 74% cho bộ thử nghiệm. Chúng tôi cũng đã thử nghiệm bằng cách tăng số lượng tính năng của trình tạo véc tơ TF-IDF lên 1,500; với mô hình AutoGluon, độ chính xác phân loại trên bộ thử nghiệm có thể được cải thiện hơn nữa lên 82%.
Để đào tạo mô hình của chúng tôi thông qua AutoGluon, chúng tôi đã sử dụng phương pháp MultilabelPredictor từ thư viện AutoGluon. Công cụ dự đoán này thực hiện dự đoán nhiều nhãn cho dữ liệu dạng bảng. chúng tôi đã sử dụng mẫu máy tính xách tay từ các mẫu AWS trên GitHub. Chúng tôi đã sử dụng cùng một sổ ghi chép bằng cách bắt đầu nhập thư viện AutoGluon và xác định lớp cho MultilabelPredictor(). Để tiết kiệm dung lượng, chúng tôi không hiển thị các dòng đó trong đoạn mã sau; bạn có thể sao chép/dán phần đó từ sổ tay mẫu. Chúng tôi đã sử dụng phần đào tạo trong tệp train.csv trong bộ chứa S3 của mình (your_path_to_s3/train.csv), đã chỉ định cột được sử dụng cho nhãn và thực hiện đào tạo mô hình thông qua MultilabelPredictor.
Bảng sau đây liệt kê các mô hình và dịch vụ AI/ML, đồng thời tóm tắt độ chính xác.
| . | Học bạ, bảng điểm | Đặc tính | Người học tuyến tính | XGB với HPO | AutoGluon |
| Bộ xác thực | 11 | 750 | 0.91 | 0.82 | 0.82 |
| Bộ xác thực | 11 | 1500 | 0.82 | 0.82 | 0.91 |
| bộ kiểm tra | 34 | 750 | 0.71 | 0.71 | 0.74 |
| bộ kiểm tra | 34 | 1500 | 0.65 | 0.65 | 0.82 |
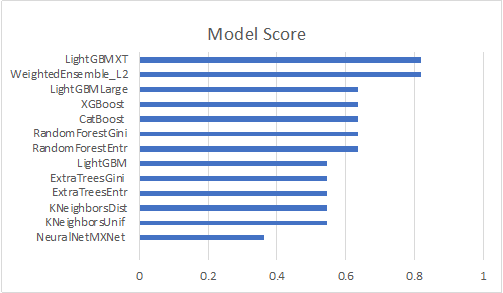
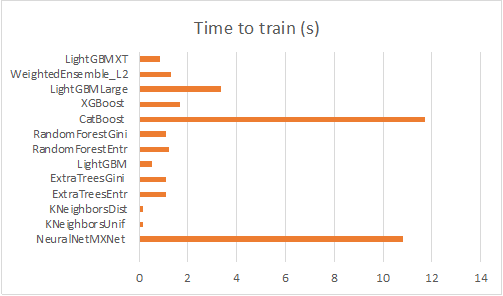
Các biểu đồ sau đây tóm tắt độ chính xác của tập hợp mẫu dựa trên số lượng tính năng.
 |
 |
Trong các biểu đồ sau, chúng tôi quan sát thấy rằng các mô hình của cây quyết định với máy tăng cường độ dốc, chẳng hạn như LGB, XGBoost và Rừng ngẫu nhiên, là những lựa chọn tốt hơn cho loại vấn đề này đối với cả mô hình 750 tính năng và mô hình 1,500 tính năng . Mô hình mạng lưới thần kinh được xếp hạng thấp hơn trong số 13 mô hình, điều này khẳng định kỳ vọng của chúng tôi rằng học sâu có thể không phù hợp với trường hợp của chúng tôi.
 |
 |
Kết luận
Với các dịch vụ AI/ML của AWS, chúng tôi có thể cung cấp lý do liên hệ chính xác và hiệu quả cũng như khả năng phát hiện cách giải quyết liên hệ cũng như những thông tin chi tiết hữu ích khác cho Tăng trưởng người bán quốc tế của Amazon. Người bán MFN có thể sử dụng những thông tin chi tiết này để hiểu rõ hơn các vấn đề của người tiêu dùng và thực hiện các hành động hiệu quả để giải quyết các vấn đề của người tiêu dùng Amazon, đồng thời tối ưu hóa quy trình và chi phí của họ.
Bạn có thể điều chỉnh giải pháp cho trung tâm liên hệ của mình bằng cách phát triển mô hình tùy chỉnh của riêng mình trong SageMaker, đồng thời cung cấp bản ghi cuộc gọi và cuộc trò chuyện để đào tạo và suy luận. Bạn cũng có thể áp dụng giải pháp này để phát hiện chủ đề chung nhằm phân tích các cuộc trò chuyện của khách hàng trong trung tâm liên hệ của mình.
Về các tác giả
 Vân Phi Bạch là Kiến trúc sư giải pháp cấp cao tại AWS. Với nền tảng về AI/ML, Khoa học dữ liệu và Phân tích, Yunfei giúp khách hàng áp dụng các dịch vụ AWS để mang lại kết quả kinh doanh. Ông thiết kế các giải pháp AI/ML và Phân tích dữ liệu để vượt qua các thách thức kỹ thuật phức tạp và thúc đẩy các mục tiêu chiến lược. Yunfei là Tiến sĩ về Kỹ thuật Điện và Điện tử. Ngoài công việc, Yunfei thích đọc sách và âm nhạc.
Vân Phi Bạch là Kiến trúc sư giải pháp cấp cao tại AWS. Với nền tảng về AI/ML, Khoa học dữ liệu và Phân tích, Yunfei giúp khách hàng áp dụng các dịch vụ AWS để mang lại kết quả kinh doanh. Ông thiết kế các giải pháp AI/ML và Phân tích dữ liệu để vượt qua các thách thức kỹ thuật phức tạp và thúc đẩy các mục tiêu chiến lược. Yunfei là Tiến sĩ về Kỹ thuật Điện và Điện tử. Ngoài công việc, Yunfei thích đọc sách và âm nhạc.
 Burak Gozluklu là Kiến trúc sư giải pháp chuyên gia ML chính ở Boston, MA. Burak có hơn 15 năm kinh nghiệm trong ngành về mô hình mô phỏng, khoa học dữ liệu và công nghệ ML. Anh ấy giúp khách hàng toàn cầu áp dụng các công nghệ AWS và đặc biệt là các giải pháp AI/ML để đạt được các mục tiêu kinh doanh của họ. Burak có bằng Tiến sĩ về Hàng không vũ trụ. từ METU, MS về Kỹ thuật hệ thống và hậu tài liệu về động lực học hệ thống từ MIT ở Cambridge, MA. Burak đam mê yoga và thiền định.
Burak Gozluklu là Kiến trúc sư giải pháp chuyên gia ML chính ở Boston, MA. Burak có hơn 15 năm kinh nghiệm trong ngành về mô hình mô phỏng, khoa học dữ liệu và công nghệ ML. Anh ấy giúp khách hàng toàn cầu áp dụng các công nghệ AWS và đặc biệt là các giải pháp AI/ML để đạt được các mục tiêu kinh doanh của họ. Burak có bằng Tiến sĩ về Hàng không vũ trụ. từ METU, MS về Kỹ thuật hệ thống và hậu tài liệu về động lực học hệ thống từ MIT ở Cambridge, MA. Burak đam mê yoga và thiền định.
 Chelsea Cái là Giám đốc sản phẩm cấp cao tại tổ chức Tăng trưởng người bán quốc tế (ISG) của Amazon, nơi cô làm việc cho Dịch vụ khách hàng của dịch vụ Amazon (CSBA) giúp người bán 3P cải thiện dịch vụ khách hàng/CX của họ thông qua công nghệ Amazon CS và các tổ chức trên toàn thế giới. Khi rảnh rỗi, cô ấy thích triết học, tâm lý học, bơi lội, đi bộ đường dài, thưởng thức đồ ăn ngon và dành thời gian cho gia đình và bạn bè.
Chelsea Cái là Giám đốc sản phẩm cấp cao tại tổ chức Tăng trưởng người bán quốc tế (ISG) của Amazon, nơi cô làm việc cho Dịch vụ khách hàng của dịch vụ Amazon (CSBA) giúp người bán 3P cải thiện dịch vụ khách hàng/CX của họ thông qua công nghệ Amazon CS và các tổ chức trên toàn thế giới. Khi rảnh rỗi, cô ấy thích triết học, tâm lý học, bơi lội, đi bộ đường dài, thưởng thức đồ ăn ngon và dành thời gian cho gia đình và bạn bè.
 Abhishek Kumar là Giám đốc sản phẩm cấp cao tại tổ chức Tăng trưởng người bán quốc tế (ISG) của Amazon, nơi ông phát triển các ứng dụng và nền tảng phần mềm để giúp người bán 3P toàn cầu quản lý hoạt động kinh doanh trên Amazon của họ. Khi rảnh rỗi, Abhishek thích đi du lịch, học tiếng Ý và khám phá các nền văn hóa và ẩm thực châu Âu cùng đại gia đình người Ý của mình.
Abhishek Kumar là Giám đốc sản phẩm cấp cao tại tổ chức Tăng trưởng người bán quốc tế (ISG) của Amazon, nơi ông phát triển các ứng dụng và nền tảng phần mềm để giúp người bán 3P toàn cầu quản lý hoạt động kinh doanh trên Amazon của họ. Khi rảnh rỗi, Abhishek thích đi du lịch, học tiếng Ý và khám phá các nền văn hóa và ẩm thực châu Âu cùng đại gia đình người Ý của mình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/ai-ml-driven-actionable-insights-and-themes-for-amazon-third-party-sellers-using-aws/

