Summarization is the technique of condensing sizable information into a compact and meaningful form, and stands as a cornerstone of efficient communication in our information-rich age. In a world full of data, summarizing long texts into brief summaries saves time and helps make informed decisions. Summarization condenses content, saving time and improving clarity by presenting information concisely and coherently. Summarization is invaluable for decision-making and in managing large volumes of content.
Summarization methods have a broad range of applications serving various purposes, such as:
- News aggregation – News aggregation involves summarizing news articles into a newsletter for the media industry
- Legal document summarization – Legal document summarization helps legal professionals extract key legal information from lengthy documents like terms, conditions, and contracts
- Academic research – Summarization annotates, indexes, condenses, and simplifies important information from academic papers
- Content curation for blogs and websites – You can create engaging and original content summaries for readers, especially in marketing
- Financial reports and market analysis – You can extract financial insights from reports and create executive summaries for investor presentations in the finance industry
With the advancements in natural language processing (NLP), language models, and generative AI, summarizing texts of varying lengths has become more accessible. Tools like LangChain, combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart, simplify the implementation process.
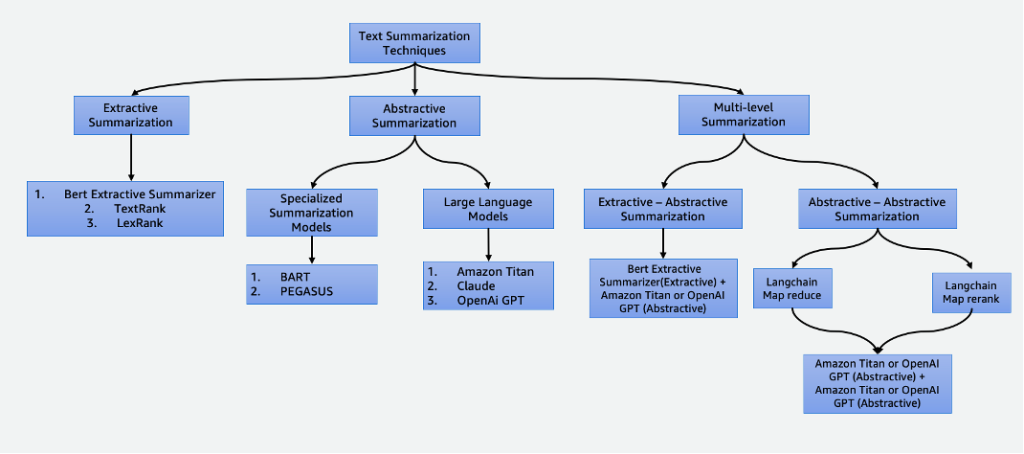
This post delves into the following summarization techniques:
- Extractive summarization using the BERT extractive summarizer
- Abstractive summarization using specialized summarization models and LLMs
- Two multi-level summarization techniques:
- Extractive-abstractive summarization using the extractive-abstractive content summarization strategy (EACSS)
- Abstractive-abstractive summarization using Map Reduce and Map ReRank
The complete code sample is found in the GitHub repo. You can launch this solution in Amazon SageMaker Studio.
Click here to open the AWS console and follow along.
Types of summarizations
There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. Furthermore, multi-level summarization methodologies incorporate a series of steps, combining both extractive and abstractive techniques. These multi-level approaches are advantageous when dealing with text with tokens longer than the limit of an LLM, enabling an understanding of complex narratives.
Extractive summarization
Extractive summarization is a technique used in NLP and text analysis to create a summary by extracting key sentences. Instead of generating new sentences or content as in abstractive summarization, extractive summarization relies on identifying and pulling out the most relevant and informative portions of the original text to create a condensed version.
Extractive summarization, although advantageous in preserving the original content and ensuring high readability by directly pulling important sentences from the source text, has limitations. It lacks creativity, is unable to generate novel sentences, and may overlook nuanced details, potentially missing important information. Moreover, it may produce lengthy summaries, sometimes overwhelming readers with excessive and unwanted information. There are many extractive summarization techniques, such as TextRank and LexRank. In this post, we focus on the BERT extractive summarizer.
BERT extractive summarizer
The BERT extractive summarizer is a type of extractive summarization model that uses the BERT language model to extract the most important sentences from a text. BERT is a pre-trained language model that can be fine-tuned for a variety of tasks, including text summarization. It works by first embedding the sentences in the text using BERT. This produces a vector representation for each sentence that captures its meaning and context. The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary.
Compared with LLMs, the advantage of the BERT extractive summarizer is it’s relatively straightforward to train and deploy the model and it’s more explainable. The disadvantage is the summarization isn’t creative and doesn’t generate sentences. It only selects sentences from the original text. This limits its ability to summarize complex or nuanced texts.
Abstractive summarization
Abstractive summarization is a technique used in NLP and text analysis to create a summary that goes beyond mere extraction of sentences or phrases from the source text. Instead of selecting and reorganizing existing content, abstractive summarization generates new sentences or phrases that capture the core meaning and main ideas of the original text in a more condensed and coherent form. This approach requires the model to understand the content of the text and express it in a way that is not necessarily present in the source material.
Specialized summarization models
These pre-trained natural language models, such as BART and PEGASUS, are specifically tailored for text summarization tasks. They employ encoder-decoder architectures and are smaller in parameters compared to their counterparts. This reduced size allows for ease of fine-tuning and deployment on smaller instances. However, it’s important to note that these summarization models also come with smaller input and output token sizes. Unlike their more general-purpose counterparts, these models are exclusively designed for summarization tasks. As a result, the input required for these models is solely the text that needs to be summarized.
Large language models
A large language model refers to any model that undergoes training on extensive and diverse datasets, typically through self-supervised learning at a large scale, and is capable of being fine-tuned to suit a wide array of specific downstream tasks. These models are larger in parameter size and perform better in tasks. Notably, they feature substantially larger input token sizes, some going up to 100,000, such as Anthropic’s Claude. To use one of these models, AWS offers the fully managed service Amazon Bedrock. If you need more control of the model development lifecycle, you can deploy LLMs through SageMaker.
Given their versatile nature, these models require specific task instructions provided through input text, a practice referred to as prompt engineering. This creative process yields varying outcomes based on the model type and input text. The effectiveness of both the model’s performance and the prompt’s quality significantly influence the final quality of the model’s outputs. The following are some tips when engineering prompts for summarization:
- Include the text to summarize – Input the text that needs to be summarized. This serves as the source material for the summary.
- Define the task – Clearly state that the objective is text summarization. For example, “Summarize the following text: [input text].”
- Provide context – Offer a brief introduction or context for the given text that needs to be summarized. This helps the model understand the content and context. For example, “You are given the following article about Artificial Intelligence and its role in Healthcare: [input text].”
- Prompt for the summary – Prompt the model to generate a summary of the provided text. Be clear about the desired length or format of the summary. For example, “Please generate a concise summary of the given article on Artificial Intelligence and its role in Healthcare: [input text].”
- Set constraints or length guidelines – Optionally, guide the length of the summary by specifying a desired word count, sentence count, or character limit. For example, “Please generate a summary that is no longer than 50 words: [input text].”
Effective prompt engineering is critical for ensuring that the generated summaries are accurate, relevant, and aligned with the intended summarization task. Refine the prompt for optimal summarization result with experiments and iterations. After you have established the effectiveness of the prompts, you can reuse them with the use of prompt templates.
Multi-level summarization
Extractive and abstractive summarizations are useful for shorter texts. However, when the input text exceeds the model’s maximum token limit, multi-level summarization becomes necessary. Multi-level summarization involves a combination of various summarization techniques, such as extractive and abstractive methods, to effectively condense longer texts by applying multiple layers of summarization processes. In this section, we discuss two multi-level summarization techniques: extractive-abstractive summarization and abstractive-abstractive summarization.
Extractive-abstractive summarization
Extractive-abstractive summarization works by first generating an extractive summary of the text. Then it uses an abstractive summarization system to refine the extractive summary, making it more concise and informative. This enhances accuracy by providing more informative summaries compared to extractive methods alone.
Extractive-abstractive content summarization strategy
The EACSS technique combines the strengths of two powerful techniques: the BERT extractive summarizer for the extractive phase and LLMs for the abstractive phase, as illustrated in the following diagram.
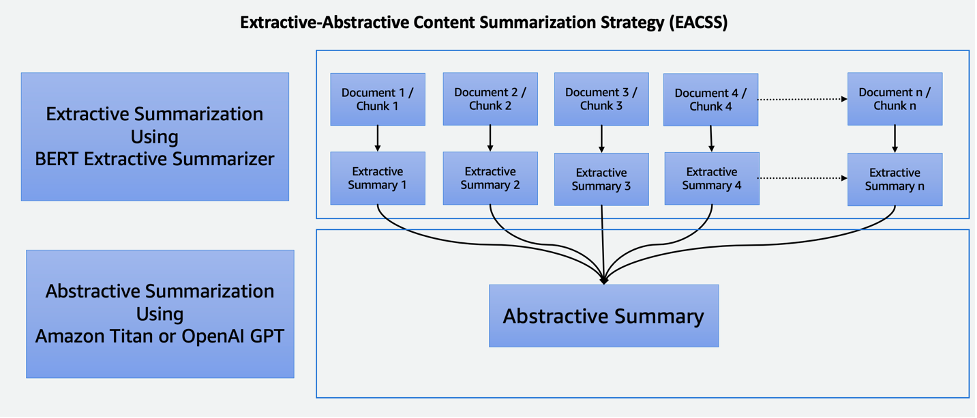
EACSS offers several advantages, including the preservation of crucial information, enhanced readability, and adaptability. However, implementing EACSS is computationally expensive and complex. There’s a risk of potential information loss, and the quality of the summarization heavily depends on the performance of the underlying models, making careful model selection and tuning essential for achieving optimal results. Implementation includes the following steps:
- The first step is to break down the large document, such as a book, into smaller sections, or chunks. These chunks are defined as sentences, paragraphs, or even chapters, depending on the granularity desired for the summary.
- For the extractive phase, we employ the BERT extractive summarizer. This component works by embedding the sentences within each chunk and then employing a clustering algorithm to identify sentences that are closest to the cluster’s centroids. This extractive step helps in preserving the most important and relevant content from each chunk.
- Having generated extractive summaries for each chunk, we move on to the abstractive summarization phase. Here, we utilize LLMs known for their ability to generate coherent and contextually relevant summaries. These models take the extracted summaries as input and produce abstractive summaries that capture the essence of the original document while ensuring readability and coherence.
By combining extractive and abstractive summarization techniques, this approach offers an efficient and comprehensive way to summarize lengthy documents such as books. It ensures that important information is extracted while allowing for the generation of concise and human-readable summaries, making it a valuable tool for various applications in the domain of document summarization.
Abstractive-abstractive summarization
Abstractive-abstractive summarization is an approach where abstractive methods are used for both extracting and generating summaries. It offers notable advantages, including enhanced readability, coherence, and the flexibility to adjust summary length and detail. It excels in language generation, allowing for paraphrasing and avoiding redundancy. However, there are drawbacks. For example, it’s computationally expensive and resource intensive, and its quality heavily depends on the effectiveness of the underlying models, which, if not well-trained or versatile, may impact the quality of the generated summaries. Selection of models is crucial to mitigate these challenges and ensure high-quality abstractive summaries. For abstractive-abstractive summarization, we discuss two strategies: Map Reduce and Map ReRank.
Map Reduce using LangChain
This two-step process comprises a Map step and a Reduce step, as illustrated in the following diagram. This technique enables you to summarize an input that is longer than the model’s input token limit.
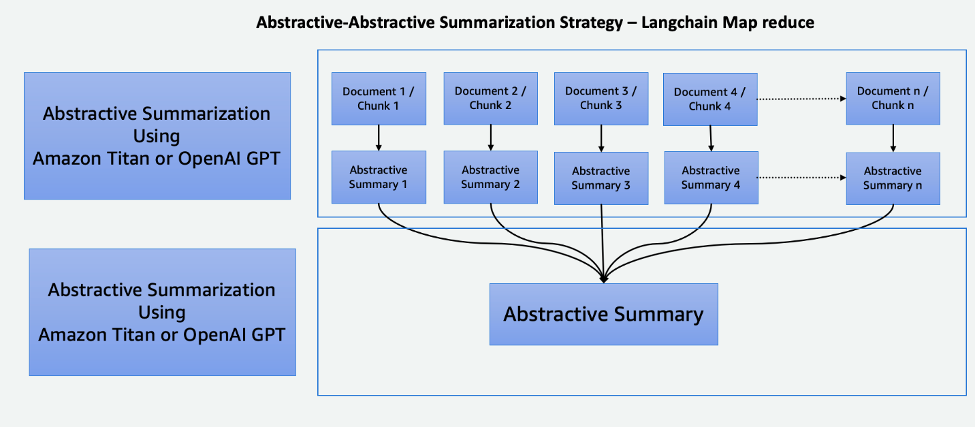
The process consists of three main steps:
- The corpora is split into smaller chunks that fit into the LLM’s token limit.
- We use a Map step to individually apply an LLM chain that extracts all the important information from each passage, and its output is used as a new passage. Depending on the size and structure of the corpora, this could be in the form of overarching themes or short summaries.
- The Reduce step combines the output passages from the Map step or a Reduce Step such that it fits the token limit and feeds it into the LLM. This process is repeated until the final output is a singular passage.
The advantage of using this technique is that it’s highly scalable and parallelizable. All the processing in each step is independent from each other, which takes advantage of distributed systems or serverless services and lower compute time.
Map ReRank using LangChain
This chain runs an initial prompt on each document that not only tries to complete a task but also gives a score for how certain it is in its answer. The highest scoring response is returned.
This technique is very similar to Map Reduce but with the advantage of requiring fewer overall calls, streamlining the summarization process. However, its limitation lies in its inability to merge information across multiple documents. This restriction makes it most effective in scenarios where a single, straightforward answer is expected from a singular document, making it less suitable for more complex or multifaceted information retrieval tasks that involve multiple sources. Careful consideration of the context and the nature of the data is essential to determine the appropriateness of this method for specific summarization needs.
Cohere ReRank uses a semantic-based reranking system that contextualizes the meaning of a user’s query beyond keyword relevance. It’s used with vector store systems as well as keyword-based search engines, giving it flexibility.
Comparing summarization techniques
Each summarization technique has its own unique advantages and disadvantages:
- Extractive summarization preserves the original content and ensures high readability but lacks creativity and may produce lengthy summaries.
- Abstractive summarization, while offering creativity and generating concise, fluent summaries, comes with the risk of unintentional content modification, challenges in language accuracy, and resource-intensive development.
- Extractive-abstractive multi-level summarization effectively summarizes large documents and provides better flexibility in fine-tuning the extractive part of the models. However, it’s expensive, time consuming, and lacks parallelization, making parameter tuning challenging.
- Abstractive-abstractive multi-level summarization also effectively summarizes large documents and excels in enhanced readability and coherence. However, it’s computationally expensive and resource intensive, relying heavily on the effectiveness of underlying models.
Careful model selection is crucial to mitigate challenges and ensure high-quality abstractive summaries in this approach. The following table summarizes the capabilities for each type of summarization.
| Aspect | Extractive Summarization | Abstractive Summarization | Multi-level Summarization |
| Generate creative and engaging summaries | No | Yes | Yes |
| Preserve original content | Yes | No | No |
| Balance information preservation and creativity | No | Yes | Yes |
| Suitable for short, objective text (input text length smaller than maximum tokens of the model) | Yes | Yes | No |
| Effective for longer, complex documents such as books (input text length greater than maximum tokens of the model) | No | No | Yes |
| Combines extraction and content generation | No | No | Yes |
Multi-level summarization techniques are suitable for long and complex documents where the input text length exceeds the token limit of the model. The following table compares these techniques.
| Technique | Advantages | Disadvantages |
| EACSS (extractive-abstractive) | Preserves crucial information, provides the ability to fine-tune the extractive part of the models. | Computationally expensive, potential information loss, and lacks parallelization. |
| Map Reduce (abstractive-abstractive) | Scalable and parallelizable, with less compute time. The best technique to generate creative and concise summaries. | Memory-intensive process. |
| Map ReRank (abstractive-abstractive) | Streamlined summarization with semantic-based ranking. | Limited information merging. |
Tips when summarizing text
Consider the following best practices when summarizing text:
- Be aware of the total token size – Be prepared to split the text if it exceeds the model’s token limits or employ multiple levels of summarization when using LLMs.
- Be aware of the types and number of data sources – Combining information from multiple sources may require transformations, clear organization, and integration strategies. LangChain Stuff has integration on a wide variety of data sources and document types. It simplifies the process of combining text from different documents and data sources with the use of this technique.
- Be aware of model specialization – Some models may excel at certain types of content but struggle with others. There may be fine-tuned models that are better suited for your domain of text.
- Use multi-level summarization for large bodies of text – For texts that exceed the token limits, consider a multi-level summarization approach. Start with a high-level summary to capture the main ideas and then progressively summarize subsections or chapters for more detailed insights.
- Summarize text by topics – This approach helps maintain a logical flow and reduce information loss, and it prioritizes the retention of crucial information. If you’re using LLMs, craft clear and specific prompts that guide the model to summarize a particular topic instead of the whole body of text.
Conclusion
Summarization stands as a vital tool in our information-rich era, enabling the efficient distillation of extensive information into concise and meaningful forms. It plays a pivotal role in various domains, offering numerous advantages. Summarization saves time by swiftly conveying essential content from lengthy documents, aids decision-making by extracting critical information, and enhances comprehension in education and content curation.
This post provided a comprehensive overview of various summarization techniques, including extractive, abstractive, and multi-level approaches. With tools like LangChain and language models, you can harness the power of summarization to streamline communication, improve decision-making, and unlock the full potential of vast information repositories. The comparison table in this post can help you identify the most suitable summarization techniques for your projects. Additionally, the tips shared in the post serve as valuable guidelines to avoid repetitive errors when experimenting with LLMs for text summarization. This practical advice empowers you to apply the knowledge gained, ensuring successful and efficient summarization in the projects.
References
About the authors
 Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS Cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
 Suhas chowdary Jonnalagadda is a Data Scientist at AWS Global Services. He is passionate about helping enterprise customers solve their most complex problems with the power of AI/ML. He has helped customers in transforming their business solutions across diverse industries, including finance, healthcare, banking, ecommerce, media, advertising, and marketing.
Suhas chowdary Jonnalagadda is a Data Scientist at AWS Global Services. He is passionate about helping enterprise customers solve their most complex problems with the power of AI/ML. He has helped customers in transforming their business solutions across diverse industries, including finance, healthcare, banking, ecommerce, media, advertising, and marketing.
 Tabby Ward is a Principal Cloud Architect/Strategic Technical Advisor with extensive experience migrating customers and modernizing their application workload and services to AWS. With over 25 years of experience developing and architecting software, she is recognized for her deep-dive ability as well as skillfully earning the trust of customers and partners to design architectures and solutions across multiple tech stacks and cloud providers.
Tabby Ward is a Principal Cloud Architect/Strategic Technical Advisor with extensive experience migrating customers and modernizing their application workload and services to AWS. With over 25 years of experience developing and architecting software, she is recognized for her deep-dive ability as well as skillfully earning the trust of customers and partners to design architectures and solutions across multiple tech stacks and cloud providers.
 Shyam Desai is a Cloud Engineer for big data and machine learning services at AWS. He supports enterprise-level big data applications and customers using a combination of software engineering expertise with data science. He has extensive knowledge in computer vision and imaging applications for artificial intelligence, as well as biomedical and bioinformatic applications.
Shyam Desai is a Cloud Engineer for big data and machine learning services at AWS. He supports enterprise-level big data applications and customers using a combination of software engineering expertise with data science. He has extensive knowledge in computer vision and imaging applications for artificial intelligence, as well as biomedical and bioinformatic applications.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/techniques-for-automatic-summarization-of-documents-using-language-models/

