트로트
기계 학습으로 데이터의 힘을 잠금 해제하십시오! Kubeflow를 사용하여 생성 및 배포 ML 파이프라인 더 이상 복잡하고 시간이 많이 걸리지 않습니다. ML 워크플로 관리의 번거로움에 작별을 고하고 Kubeflow의 단순함을 만나보세요.
Kubeflow는 데이터를 귀중한 인사이트로 쉽게 전환할 수 있는 오픈 소스 플랫폼입니다. 인기 있는 컨테이너 오케스트레이션 플랫폼인 Kubernetes를 기반으로 구축된 Kubeflow는 모든 ML 요구 사항을 충족하는 원스톱 상점을 제공합니다.
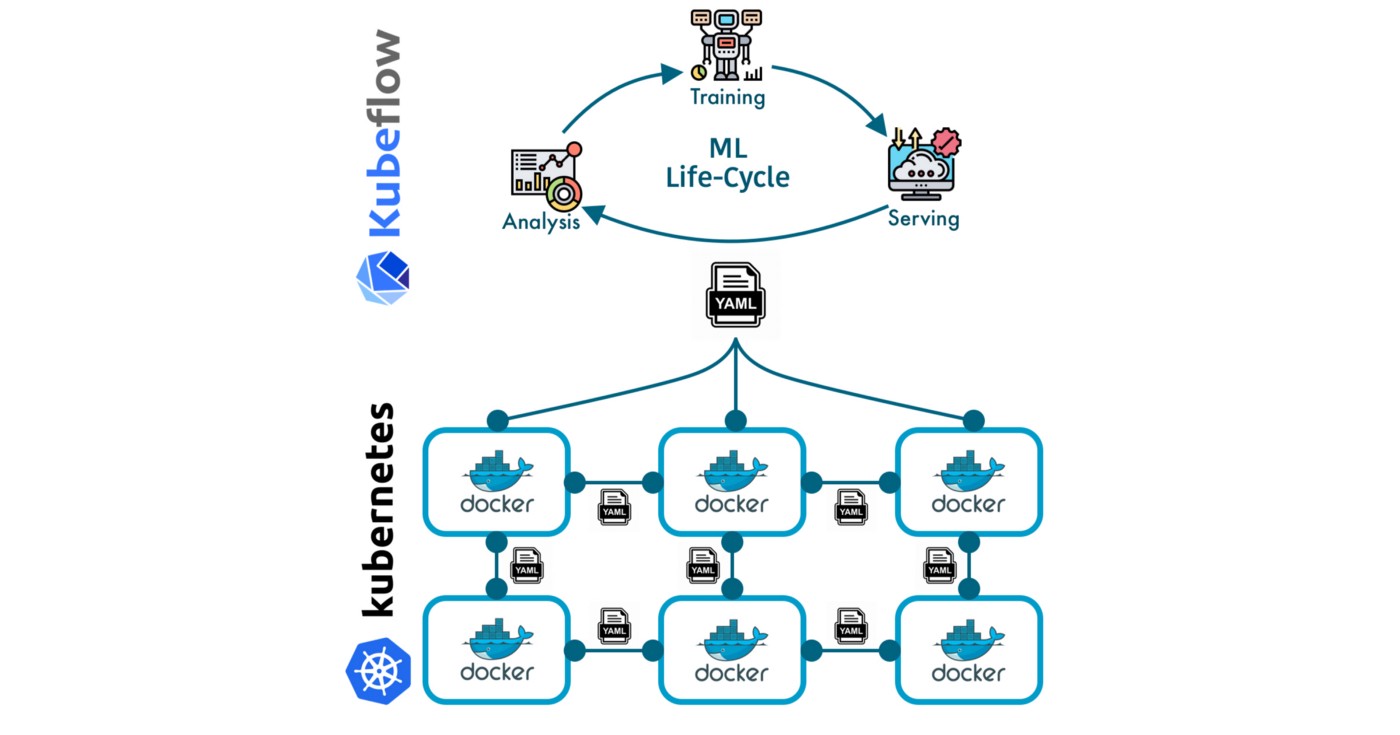
Kubeflow로 강력한 ML 파이프라인을 만들고 배포하는 단계를 안내하는 스릴 넘치는 모험을 시작하세요. 데이터의 잠재력을 최대한 활용하고 새로운 차원의 데이터 기반 인사이트와 결과를 얻으십시오. ML 기능을 다음 단계로 끌어올릴 준비를 하십시오!
학습 목표
- ML 파이프라인 생성 및 배포에 Kubeflow를 사용할 때의 기본 개념과 이점 이해
- s Kubeflow를 배우려면
- Kubeflow를 사용하여 ML 워크플로 및 배포를 관리하는 실무 경험을 얻으려면
- ML pips에서 retd 평가의 중요성과 Kubeflow로 이를 처리하는 방법을 이해하기 위해
- 기존 ML 파이프라인 개발 및 배포 프로세스에 대한 Kubeflow 사용의 이점을 이해합니다.
이 기사는 데이터 과학 Blogathon.
차례
- 개요
- 기계 학습 파이프라인에 대한 심층 검토
2.1 전처리
2.2 CMLE에서 학습 및 하이퍼파라미터 조정
2.3 Kubernetes에서 로컬로 교육
2.4 Cloud ML Engine에 배포
2.5 DSL 컴파일러로 Kubeflow ML 파이프라인 컴파일 - 사용자 인터페이스에 Kubeflow ML 파이프라인 업로드
- 실험, 개발, 재교육 및 평가
4.1 모델 재교육
4.2 노트북으로 모델 성능 평가 및 모니터링 - 결론
영구 Kubeflow 파이프라인 설치로 Kubernetes 클러스터 실행
KFP를 실행하려면 Kubernetes 클러스터가 필요합니다. 다음 명령을 사용하여 Google Kubernetes Engine(GKE) 클러스터를 만들고 KFP가 클러스터를 관리하도록 할 수 있습니다(저장소의 create_cluster.sh).
#!/bin/bash CLUSTERNAME=mykfp ZONE=us-central1-bgcloud config set compute/zone $ZONE gcloud beta container clusters create $CLUSTERNAME --cluster-version 1.11.2-gke.18 --enable-autoupgrade --zone $ZONE -- 범위 클라우드 플랫폼 --enable-cloud-logging --enable-cloud-monitoring --machine-type n1-standard-2 --num-nodes 4kubectl create clusterrolebinding ml-pipeline-admin-binding --clusterrole =cluster-admin --user=$(gcloud config get-value 계정)
GKE 클러스터를 만드는 데 최대 3분이 걸릴 수 있습니다. 따라서 클러스터가 시작되고 준비되었는지 확인하려면 GCP 콘솔의 GKE 섹션으로 이동하는 것이 좋습니다.
클러스터가 가동되면 다음 명령어를 사용하여 GKE 클러스터에 ML 파이프라인 설치를 진행할 수 있습니다.
#!/bin/bash PIPELINE_VERSION=0.1.3 kubectl create -f https://storage.googleapis.com/ml-pipeline/release/$PIPELINE_VERSION/bootstrapper.yaml
소프트웨어 설치가 진행되는 동안 프로세스의 향후 단계에 대해 자세히 알아보기 위해 계속 읽을 수 있습니다.
2. 기계 학습 파이프라인에 대한 심층 분석
Python3 및 Docker("dev-ops" 접근 방식) 또는 Jupyter 노트북(보다 데이터 과학자 친화적인 접근 방식)을 사용하는 등 파이프라인을 생성하는 다양한 방법이 있습니다. 이 게시물에서는 Jupyter 노트북 방법을 사용하여 기본 프로세스에 대한 더 깊은 이해를 제공할 수 있는 Python3-Docker 메커니즘을 탐색합니다.
예를 들어 기계 학습 모델을 사용하여 아기의 체중을 예측하는 파이프라인을 시연합니다. 파이프라인에는 (a) BigQuery에서 데이터를 추출하여 변환하고 변환된 데이터를 Cloud Storage에 저장하는 단계가 포함됩니다. (b) TensorFlow Estimator API 모델 교육 및 하이퍼파라미터 튜닝 수행. (c) 최적의 학습률, 배치 크기 등이 결정되면 해당 매개변수를 사용하여 더 많은 데이터로 더 긴 기간 동안 모델을 교육합니다. (d) 학습된 모델을 Cloud ML Engine에 배포합니다.
전처리 = dsl.ContainerOp( 이름='전처리', 이미지='gcr.io/cloud-training-demos/babyweight-pipeline-bqtocsv:latest', 인수=[ '--프로젝트', 프로젝트, '--방법', '구름', '--버킷', 버킷 ], file_outputs={'버킷': '/output.txt'} )hparam_train = dsl.ContainerOp( 이름='하이퍼트레인', 이미지='gcr.io/cloud-training-demos/babyweight-pipeline-hypertrain:latest', 인수=[ 전처리.출력['버킷'] ], file_outputs={'직업 이름': '/output.txt'} )train_tuned = dsl.ContainerOp( 이름='훈련된', 이미지='gcr.io/cloud-training-demos/babyweight-pipeline-trained-trainer:latest', 인수=[ hparam_train.outputs['직업 이름'], 버킷 ], file_outputs={'기차': '/output.txt'} ) train_tuned.set_memory_request('2G') train_tuned.set_cpu_request('1')deploy_cmle = dsl.ContainerOp( 이름='deploycmle', 이미지='gcr.io/cloud-training-demos/babyweight-pipeline-deploycmle:latest', 인수=[ train_tuned.outputs['기차'], # 모델디렉토리 '베이비급', 'mlp' ], 파일_출력={ '모델': '/model.txt', '버전': '/version.txt' } )
이 프로세스의 단계는 Docker 컨테이너로 표시되어 한 컨테이너의 출력이 다음 컨테이너의 입력 역할을 하는 방향성 비순환 그래프를 형성합니다. 파이프라인 UI에서 볼 때 연결된 파이프라인으로 나타납니다.
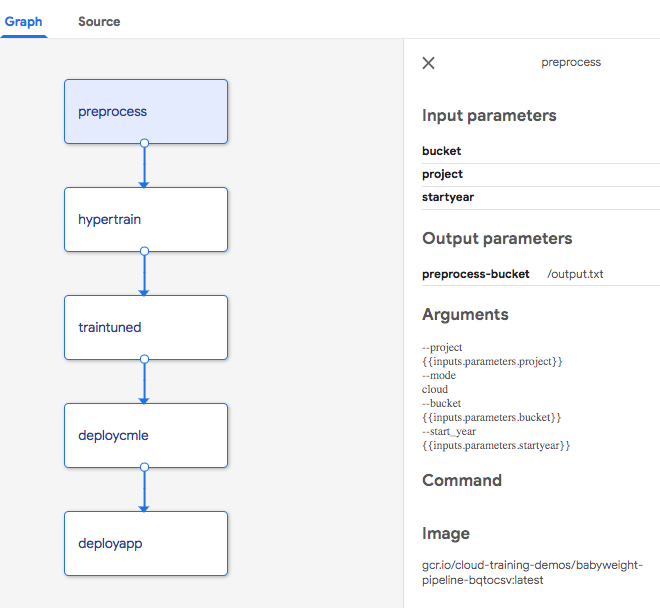
또한 모델과 상호 작용하기 위해 사용자 친화적인 인터페이스로 웹 애플리케이션을 배포하는 다섯 번째 단계도 전체 엔드 투 엔드 솔루션을 완성하기 위해 구현되어야 합니다.
전처리 단계를 검토합니다.
전처리 = dsl.ContainerOp( 이름='전처리', 이미지='gcr.io/cloud-training-demos/babyweight-pipeline-bqtocsv:latest', 인수=[
'--프로젝트', 프로젝트,
'--방법', '구름',
'--버킷', 버킷 ], file_outputs={'버킷': '/output.txt'} )
프리프레서, 프로젝트 및 버킷이 전처리된 데이터를 /output.txt로 출력하는 것을 관찰하는 것이 중요합니다.
그 후 두 번째 단계에서는 전처리 단계의 출력에서 전처리로 표시되는 버킷 이름을 검색합니다. 출력['버킷']. 가장 효과적인 하이퍼파라미터 튜닝 시도의 작업 이름인 이 단계의 출력은 세 번째 단계에서 hparam_train.outputs['jobname']으로 활용됩니다.
이 프로세스는 비교적 간단합니다.
그러나 두 가지 질문이 제기됩니다. 첫 번째 단계는 필요한 프로젝트와 버킷을 어디서 얻고 개별 단계는 어떻게 구현됩니까?
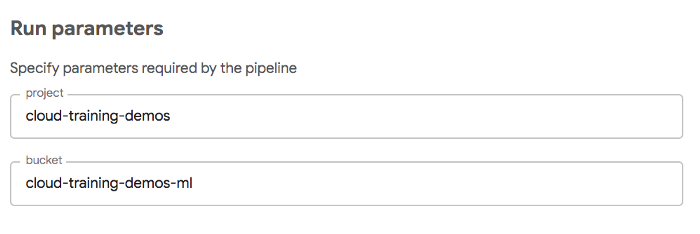
이러한 질문에 대한 답은 첫 번째 단계에 대한 프로젝트 및 버킷 입력을 제공하는 파이프라인 매개변수에 있습니다.
def train_and_deploy( project='cloud-training-demos', bucket='cloud-training-demos-ml' ):
본질적으로 프로젝트 및 버킷 매개변수는 파이프라인을 실행할 때 최종 사용자가 제공합니다. 사용자 인터페이스는 이전에 지정된 기본값으로 사전 구성됩니다.
다음 섹션에서는 각 단계의 구현에 대해 자세히 설명합니다. 앞에서 언급했듯이 이 설명은 Python3-Docker 구현 방법에 중점을 둘 것입니다. Jupyter 기반 접근 방식을 선호하는 사용자를 위해 향후 이 문제를 해결하기 위해 별도의 문서가 게시될 예정입니다. Docker 경로가 자신에게 적합하지 않다고 확신하는 경우 이 섹션을 훑어보거나 섹션 3으로 바로 진행하십시오.
2.1 전처리
파이프라인의 각 단계에서 Docker 컨테이너를 생성해야 합니다. 이 컨테이너에는 필요한 종속성과 함께 독립 실행형 프로그램(예: bash 스크립트, Python 코드, C++ 또는 기타 언어)이 포함되어 있어 클러스터에서 KFP가 실행할 수 있습니다.
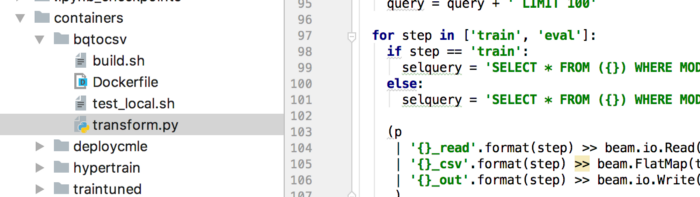
이 예의 경우 전처리 code는 Apache Beam을 활용하고 Cloud Dataflow에서 실행하기 위한 독립형 Python 프로그램입니다. 전체 코드는 transform.py라는 단일 명령줄 프로그램에 포함되어 있습니다.
Dockerfile은 프로그램에 필요한 모든 종속성을 지정해야 합니다. 다행스럽게도 KFP는 다양한 샘플 컨테이너를 제공하며 그 중 하나에는 이 예제에 필요한 모든 종속성이 포함되어 있습니다. 노력을 최소화하기 위해 Dockerfile은 이 기존 컨테이너에서 상속되어 간결한 4줄 파일이 됩니다.
gcr.io/ml-pipeline/ml-pipeline-dataflow-tft에서: 최신 실행 mkdir /babyweight COPY transform.py /babyweight ENTRYPOINT ["python", "/babyweight/transform.py"]
Dockerfile은 transform.py 파일을 컨테이너에 복사하고 진입점으로 설정합니다. 즉, 컨테이너가 실행될 때 파일이 실행됩니다.
Dockerfile이 완료되면 build.sh 스크립트를 사용하여 Docker 컨테이너를 빌드하고 프로젝트 내의 gcr.io 레지스트리에 게시할 수 있습니다.
CONTAINER_NAME=babyweight-파이프라인-bqtocsv
도커 빌드 -t ${CONTAINER_NAME} . 도커 태그 ${CONTAINER_NAME} gcr.io/${PROJECT_ID}/${CONTAINER_NAME}:${TAG_NAME} 도커 푸시 gcr.io/${PROJECT_ID}/${CONTAINER_NAME}:${TAG_NAME}
전처리 단계에 대해 지정된 특정 이미지 이름을 나타냅니다.
2.2 CMLE에서 학습 및 하이퍼파라미터 튜닝
훈련 및 하이퍼파라미터 동조 Cloud ML Engine에서 수행됩니다.
gcloud ml-engine 작업 제출 교육 $JOBNAME --region=$REGION --module-name=trainer.task --package-path=${CODEDIR}/babyweight/trainer --job-dir=$OUTDIR --staging- 버킷=gs://$BUCKET --scale-tier=STANDARD_1 --config=hyperparam.yaml --runtime-version=$TFVERSION --스트림-로그 -- --bucket=${BUCKET} --output_dir=${OUTDIR} --eval_steps=10 --train_examples=20000# 파이프라인의 다음 단계에 대한 출력 파일 쓰기 echo $JOBNAME > /output.txt
gcloud 명령어에서 –stream-logs 옵션을 사용한다는 점에 유의해야 합니다. 이렇게 하면 명령이 완료될 때까지 대기합니다. 또한 명령 출력에는 파이프라인의 이 단계와 후속 단계 간의 통신에 필수적인 작업 이름이 포함됩니다.
이 단계에서 Dockerfile은 gcloud가 설치된 컨테이너에서 상속됩니다. 트레이너 코드는 git clone 명령을 사용하여 해당 저장소를 복제하여 얻습니다.
google/cloud-sdk에서:latestRUN mkdir -p /babyweight/src && cd /babyweight/src && git 클론 https://github.com/GoogleCloudPlatform/training-data-analyst
복사 train.sh hyperparam.yaml ./ ENTRYPOINT ["bash", "./train.sh"]
2.3 Kubernetes에서 로컬로 교육
전처리 및 하이퍼파라미터 조정의 이전 단계에서는 관리형 서비스를 활용했으며, KFP는 작업 제출만 담당하고 관리형 서비스가 프로세스를 처리하도록 허용했습니다.
그러나 다음 학습 단계는 Python 프로그램을 직접 실행하는 Docker 컨테이너를 실행하여 GKE 클러스터를 실행하는 KFP에서 로컬로 수행할 수 있습니다. 이것은 다양성을 추가하고 KFP의 유연성을 보여줍니다.
NEMBEDS=$(gcloud ml-engine jobs describe $HYPERJOB --format 'value(trainingOutput.trials.hyperparameters.nembeds.slice(0))') TRIALID=$(gcloud ml-engine jobs describe $HYPERJOB --format '값 (trainingOutput.trials.trialId.slice(0))')...OUTDIR=gs://${BUCKET}/babyweight/hyperparam/$TRIALID python3 -m trainer.task --job-dir=$OUTDIR -- 버킷=${BUCKET} --output_dir=${OUTDIR} --eval_steps=10 --nnsize=$NNSIZE --batch_size=$BATCHSIZE --nembeds=$NEMBEDS --train_examples=200000
KFP 클러스터에서 작업을 실행할 때 현재 리소스 사용률을 고려하는 것이 중요합니다. train-turned-container 작업은 클러스터에 작업에 대한 충분한 리소스가 있는지 확인하기 위해 필요한 양의 메모리 및 CPU 리소스를 예약합니다. KFP는 필요한 리소스를 사용할 수 있을 때만 작업을 예약하여 클러스터 리소스를 효율적으로 사용할 수 있도록 합니다.
train_tuned.set_memory_request('2G') train_tuned.set_cpu_request('1')
2.4 Cloud ML Engine에 배포
XNUMXD덴탈의 Cloud ML Engine에 배포 gcloud를 활용하여 해당 디렉터리 내의 deploy.sh 및 build.sh 스크립트에서 볼 수 있듯이 이전 단계와 유사한 배포 프로세스를 만듭니다.
gcloud ml-engine 버전 생성 ${MODEL_VERSION} --model ${MODEL_NAME} --origin ${MODEL_LOCATION} --runtime-version $TFVERSIONecho $MODEL_NAME > /model.txt echo $MODEL_VERSION > /version.txt
과
google/cloud-sdk에서:최신 실행 mkdir -p /babyweight/src && cd /babyweight/src && git clone https://github.com/GoogleCloudPlatform/training-data-analyst COPY deploy.sh ./ ENTRYPOINT ["bash", "./deploy.sh"]
마찬가지로 Kubernetes 클러스터 자체에서도 배포를 수행할 수 있습니다. 구성 요소 예
2.5 DSL 컴파일러로 Kubeflow ML 파이프라인 컴파일
파이프라인 설정을 완료하려면 파이프라인 코드를 DSL(도메인별 언어) 형식으로 컴파일해야 합니다. 이는 KFP Python3 SDK와 함께 제공되는 DSL 컴파일 도구를 사용하여 수행됩니다. 파이프라인을 컴파일하기 전에 스크립트를 실행하여 SDK를 설치해야 합니다. 3_install_sdk.sh
pip3 설치 python-dateutil
https://storage.googleapis.com/ml-pipeline/release/0.1.2/kfp.tar.gz --업그레이드
이제 다음 명령을 사용하여 DSL(Domain-Specific-Language)을 컴파일합니다.
python3 mlp_babyweight.py mlp_babyweight.tar.gz
또는 다음 단계를 통해 dsl-compile이 포함된 디렉토리를 PATH에 추가할 수 있습니다.”
내보내기 PATH=”$PATH:`python -m 사이트 --user-base`/bin
그리고 다음 명령을 실행하여 컴파일러를 호출합니다.
dsl-컴파일 --py mlp_babyweight.py --출력 mlp_babyweight.tar.gz
파이프라인의 Python3 파일을 컴파일한 결과는 tar 아카이브 파일이며, 다음 단계(섹션 3)에서 ML Pipelines 사용자 인터페이스에 업로드합니다.
3. 사용자 인터페이스에 Kubeflow ML 파이프라인 업로드
포트 전달을 통해 GKE 클러스터와 로컬 머신 간의 연결을 설정할 수 있습니다. 이렇게 하면 포트 80의 노트북에서 GKE 클러스터의 포트 8085에서 실행 중인 사용자 인터페이스 서버에 액세스할 수 있습니다.
이 연결을 설정하는 프로세스는 스크립트를 사용하여 수행할 수 있습니다. 4_start_ui.sh.
export NAMESPACE=kubeflow kubectl port-forward -n ${NAMESPACE} $(kubectl get pods -n ${NAMESPACE} --selector=service=ambassador -o jsonpath='{.items[0].metadata.name}') 8085:80
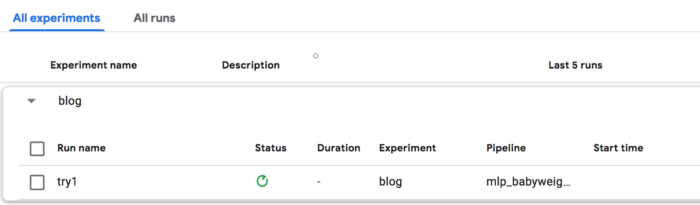
실험을 생성하고 파이프라인을 실행하려면 다음에서 KFP 사용자 인터페이스에 액세스하십시오. http://localhost:8085/pipeline 파이프라인 탭으로 전환합니다. 섹션 2e에서 컴파일된 tar.gz 파일을 업로드합니다. 실험을 시작하려면 새 실험을 만들고 '블로그'와 같은 이름을 지정합니다.
그런 다음 실험 내에서 새 실행을 만들고 "try1"과 같은 이름을 지정합니다. 마지막으로 파이프라인을 이전에 업로드한 파이프라인으로 설정합니다.
4. 실험, 개발, 재교육 및 평가
이 파이프라인 구현을 위한 전체 소스 코드에는 이전 단계에서 완전히 설명되지 않은 다양한 측면이 포함되어 있습니다. 코드가 원활하게 실행되기 전에 여러 번 반복하고 수정해야 하는 것이 일반적입니다.
디버깅 및 테스트 프로세스를 간소화하기 위해 파이프라인은 각 단계가 이전 단계의 출력에 종속되도록 하면서 모든 단계에서 시작할 수 있도록 설계되었습니다. 이 요구 사항을 해결하기 위해 솔루션이 고안되었습니다.
start_step <= 2인 경우: hparam_train = dsl.ContainerOp( name='hypertrain', # 이미지는 컴파일 타임 문자열이어야 함 image='gcr.io/cloud-training-demos/babyweight-pipeline-hypertrain:latest', arguments=[ preprocess.outputs ['버킷'] ], file_outputs={'작업 이름': '/output.txt'} ) 그렇지 않으면: hparam_train = ObjectDict({ 'outputs': { 'jobname': 'babyweight_181008_210829' } })
기본적으로 컨테이너 작업은 start_step이 2보다 작거나 같은 경우에만 실행됩니다. 2보다 크면 이전 단계의 미리 정의된 출력이 있는 사전이 대신 생성됩니다. 이렇게 하면 start_step을 4로 설정하고 이전 단계에서 필요한 입력을 계속 유지하면서 네 번째 단계에서 시작할 수 있으므로 보다 효율적인 개발이 가능합니다.
내 실험은 여러 실행으로 구성되었습니다.
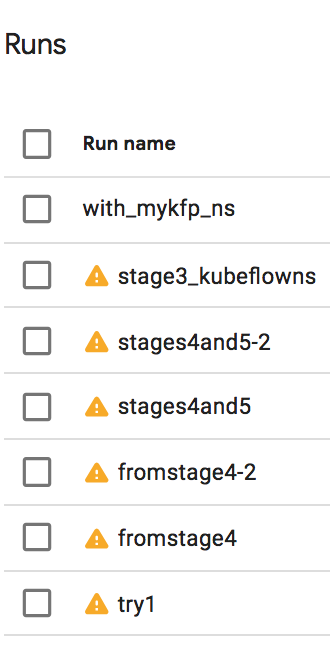
내 실험은 각각 구성과 매개변수가 다른 여러 반복으로 구성되었습니다. 예를 들어 'try1' 실행은 4단계를 성공적으로 수행한 후 실패했고 4단계부터 시작해야 했습니다. 5단계를 올바르게 완료하는 데 두 번의 시도가 필요했습니다. 그런 다음 웹 서비스를 호스팅하기 위해 AppEngine 애플리케이션을 배포하는 3단계를 추가했습니다. 그런 다음 XNUMX단계를 다시 방문하여 다양한 변형을 실험했습니다.
4.1 모델 재교육
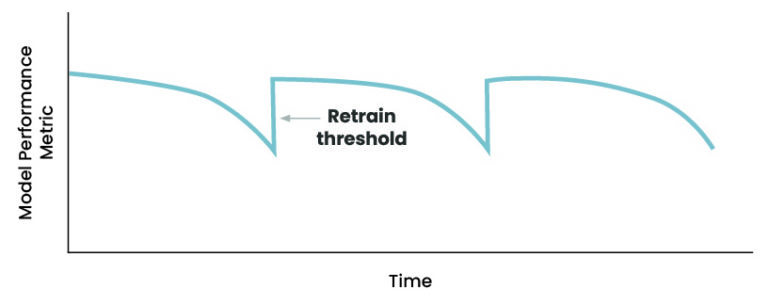
물론 모델의 학습은 한 번만 실행하면 중지되지 않습니다. 더 많은 데이터를 사용할 수 있게 되면 모델을 재교육해야 합니다. 예를 들어, 아기 체중 모델에서 추가 XNUMX년의 데이터가 있으면 재교육이 발생할 수 있습니다. 파이프라인에서 이를 수용하기 위해 입력 매개변수로 스타터를 포함했습니다.
def train_and_deploy( project=dsl.PipelineParam(name='project', value='cloud-training-demos'), bucket=dsl.PipelineParam(name='bucket', value='cloud-training-demos-ml') , startYear=dsl.PipelineParam(name='startYear', value='2000') ):
"bqtocsv" 단계의 사전 처리 코드는 지정된 시작 연도 이전에 발생하는 모든 행을 필터링합니다. 이렇게 하면 단순히 시작 연도 입력 매개변수를 조정하여 업데이트된 데이터에 대해 모델을 재교육할 수 있습니다.
WHERE 연도 >= 시작_연도
그리고 이전 출력을 덮어쓰지 않는 방식으로 출력 파일의 이름을 지정합니다.
os.path.join(OUTPUT_DIR, 'train_{}.csv', start_year)
재학습 처리는 기계 학습 파이프라인의 중요한 측면입니다. 우리의 경우 bqtocsv 단계의 전처리 코드는 지정된 시작 연도의 데이터만 필터링하여 보다 크고 최신 데이터 세트에서 학습이 이루어지도록 합니다. 또한 출력 파일은 이전 출력을 덮어쓰지 않도록 이름이 지정됩니다.
4.2 노트북으로 모델 성능 평가 및 모니터링
훈련된 모델을 프로덕션에 배포하기 전에 적절한 평가를 수행하고 잠재적으로 A/B 테스트를 수행하는 것이 중요합니다. 평가 프로세스는 전체 구현 전에 모델의 신뢰성과 효율성을 보장하는 데 도움이 됩니다. 아기 체중 모델의 경우 대부분 Python으로 작성되어 코드가 쉽게 Dockerized되었습니다. 그러나 많은 기계 학습 모델은 Jupyter 노트북을 사용하여 개발됩니다.
Jupyter 노트북에서 개발된 모델을 평가하고 이를 파이프라인으로 변환하는 과정은 별도의 디스크가 필요한 주제입니다.
결론
결론적으로 Kubeflow는 일련의 도구와 프레임을 제공하는 오픈 소스 플랫폼입니다.ML 파이프라인을 구축, 배포 및 관리하기 위한 작업입니다. 이 플랫폼은 Kubernetes 위에 구축되어 파이프라인을 쉽게 관리하고 확장할 수 있습니다. 이 가이드의 도움으로 이제 Kubeflow로 ML 파이프라인을 만들고 배포하는 것과 관련된 단계를 명확하게 이해할 수 있습니다.
주요 테이크 아웃 :
- Kubeflow는 ML 파이프라인을 관리하기 위한 오픈 소스 플랫폼입니다.
- 이 플랫폼은 Kubernetes 위에 구축되어 확장 가능하고 관리하기 쉽습니다.
- 이 가이드는 Kubeflow로 ML 파이프라인을 만들고 배포하는 것과 관련된 단계를 다룹니다.
- 프로세스에는 모델의 교육, 평가, 배포 및 재교육이 포함됩니다.
- KFP(Kubeflow Pipelines)는 기계 학습 모델을 운영하는 데 중요한 도구입니다.
나와 연결해주세요 Linkedin.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/02/a-step-by-step-guide-to-creating-and-deploying-a-machine-learning-pipeline-with-kubeflow/

