차례
개요
학습은 경험을 통해 영역에 대한 지식을 습득하고 숙달하는 것입니다. 그것은 인간에게만 해당되는 것이 아니라 기계에도 해당됩니다. 컴퓨팅 세계는 인공 지능의 출현과 함께 비효율적인 기계 시스템에서 엄청난 자동화 기술로 급격히 변모했습니다. 데이터는 이 기술을 구동하는 연료입니다. 최근 엄청난 양의 데이터를 사용할 수 있게 되면서 기술의 유행어가 되었습니다. 가장 단순한 형태의 인공 지능은 더 나은 의사 결정을 위해 인간 지능을 기계에 시뮬레이션하는 것입니다.
인공 지능(AI)은 기계에 의한 인간 지능 프로세스의 시뮬레이션을 다루는 컴퓨터 과학의 한 분야입니다. 인지 컴퓨팅이라는 용어는 인간의 사고 과정을 시뮬레이션하기 위해 컴퓨터 모델이 배포되기 때문에 AI를 지칭하는 데에도 사용됩니다. 현재 환경을 인식하고 목표를 최적화하는 모든 장치를 AI 지원이라고 합니다. AI는 크게 약한 것과 강한 것으로 분류할 수 있습니다. 특정 작업을 수행하도록 설계되고 훈련된 시스템을 음성 활성화 시스템과 같이 약한 AI라고 합니다. 그들은 질문에 대답하거나 프로그램 명령을 따를 수 있지만 사람의 개입 없이는 작동할 수 없습니다. Strong AI는 일반화된 인간의 인지 능력입니다. 사람의 개입 없이 작업을 해결하고 솔루션을 찾을 수 있습니다. 자율주행차는 컴퓨터 비전, 이미지 인식 및 딥 러닝을 사용하여 차량을 조종하는 강력한 AI의 예입니다. AI는 기업과 소비자 모두에게 이익이 되는 다양한 산업에 진출했습니다. 의료, 교육, 금융, 법률 및 제조업이 그 중 일부입니다. 자동화, 머신 러닝, 머신 비전, 자연어 처리 및 로보틱스와 같은 많은 기술이 AI를 통합합니다.
인간이 수행하는 일상적인 작업의 급격한 증가는 자동화의 필요성을 요구합니다. 정밀도와 정확도는 수동 시스템과 대조되는 지능형 시스템의 발명을 요구하는 차세대 구동 조건입니다. 의사 결정 및 패턴 인식은 해당 도메인의 과거 데이터에 대한 집중 학습을 통해 얻을 수 있는 편향되지 않은 결정적인 결과가 필요하기 때문에 자동화를 고집하는 매력적인 작업입니다. 이는 예측을 하는 시스템이 미래에 정확한 예측을 하기 위해 과거 데이터에 대한 대규모 훈련을 거치는 데 필요한 기계 학습을 통해 달성할 수 있습니다. 일상 생활에서 널리 사용되는 ML 응용 프로그램 중 일부는 더 빠른 경로를 제공하고 최적의 경로 및 여행당 가격을 추정하여 출퇴근 시간을 예측하는 것입니다. 그 응용 프로그램은 스팸 필터, 이메일 분류 및 스마트 답장을 수행하는 이메일 인텔리전스에서 볼 수 있습니다. 은행 및 개인 금융 분야에서 신용 결정, 사기 거래 방지에 사용됩니다. 의료 및 진단, 소셜 네트워킹 및 Siri 및 Cortana와 같은 개인 비서에서 중요한 역할을 합니다. 목록은 거의 끝이 없으며 점점 더 많은 분야에서 일상 활동에 AI와 ML을 사용함에 따라 매일 계속 증가하고 있습니다.
진정한 인공 지능은 수십 년 후에 있지만 오늘날 기계 학습이라는 AI 유형이 있습니다. 인지 컴퓨팅으로도 알려진 AI는 머신 러닝과 딥 러닝이라는 두 가지 동족 기술로 분기됩니다. 기계 학습은 훌륭하고 자동화된 기계를 만드는 연구에서 상당한 공간을 차지했습니다. 명시적으로 프로그래밍하지 않고도 데이터의 패턴을 인식할 수 있습니다. 머신 러닝은 데이터, 더 중요하게는 데이터의 변화로부터 학습할 수 있는 도구와 기술을 제공합니다. 기계 학습 알고리즘은 많은 응용 프로그램에서 그 위치를 찾았습니다. 당신이 선택한 음식을 결정하는 앱부터 술집 약속을 예약하는 채팅 봇을 포함하여 볼 다음 영화를 결정하는 앱에 이르기까지 정보 기술 산업을 뒤흔드는 놀라운 기계 학습 응용 프로그램 중 일부입니다. 그에 상응하는 딥 러닝 기술은 인간의 뇌 세포에서 영감을 얻은 기능을 가지고 있으며 더 많은 인기를 얻고 있습니다. 딥 러닝은 낮은 수준 범주에서 높은 수준 범주로 이동하는 증분 방식으로 학습하는 기계 학습의 하위 집합입니다. 딥 러닝 알고리즘은 매우 많은 양의 데이터로 훈련될 때 더 정확한 결과를 제공합니다. 마술 상자/블랙 박스라는 이름을 부여하는 엔드 투 엔드 패션을 사용하여 문제를 해결합니다. 성능은 고급 기계를 사용하여 최적화됩니다. 딥 러닝은 인간의 뇌 세포에서 영감을 얻은 기능을 가지고 있으며 더 많은 인기를 얻고 있습니다. 딥 러닝은 실제로 낮은 수준 범주에서 높은 수준 범주로 이동하는 증분 방식으로 학습하는 기계 학습의 하위 집합입니다. 딥 러닝은 자율 주행 자동차, 픽셀 복원 및 자연어 처리와 같은 애플리케이션에서 선호됩니다. 이러한 응용 프로그램은 단순히 우리의 마음을 놀라게 하지만 현실은 이러한 기술의 절대적인 힘이 아직 공개되지 않았다는 것입니다. 이 문서에서는 응용 프로그램과 함께 이론을 캡슐화하는 이러한 기술에 대한 개요를 제공합니다.
머신 러닝이란 무엇입니까?
컴퓨터는 프로그래밍된 작업만 수행할 수 있습니다. 이것은 컴퓨터가 인간처럼 작업을 수행하고 결정을 내릴 수 있을 때까지는 과거의 이야기였습니다. AI의 하위 집합인 기계 학습은 컴퓨터가 인간을 모방할 수 있도록 하는 기술입니다. 기계 학습이라는 용어는 1952년 Arthur Samuel이 실행하면서 학습할 수 있는 최초의 컴퓨터 프로그램을 설계하면서 발명되었습니다. Arthur Samuel은 가장 많이 찾는 두 분야인 인공 지능과 컴퓨터 게임의 선구자였습니다. 그에 따르면 기계 학습은 "컴퓨터가 명시적으로 프로그래밍하지 않고도 학습할 수 있는 기능을 제공하는 연구 분야"입니다.
일반적으로 머신 러닝은 소프트웨어가 과거 경험에서 스스로 학습하고 그 지식을 사용하여 명시적으로 프로그래밍하지 않고도 향후 작업에서 성능을 향상시킬 수 있도록 하는 인공 지능의 하위 집합입니다. 색상, 모양, 냄새, 꽃잎 크기 등과 같은 다른 속성을 기반으로 다른 꽃을 식별하는 예를 고려하십시오. 전통적인 프로그래밍에서 모든 작업은 식별 프로세스에서 따라야 하는 몇 가지 규칙으로 하드코딩됩니다. 기계 학습에서 이 작업은 프로그래밍 없이 기계를 학습하게 함으로써 쉽게 달성할 수 있습니다. 기계는 제공된 데이터에서 학습합니다. 데이터는 학습 과정을 주도하는 연료입니다. 머신 러닝이라는 용어는 1959년에 도입되었지만 이 기술을 구동하는 연료는 이제야 사용할 수 있습니다. 머신 러닝에는 방대한 데이터가 필요하며 한때 꿈이었던 컴퓨팅 성능이 이제 우리의 처분에 있습니다.
전통적인 프로그래밍과 기계 학습:
컴퓨터가 인간을 대신하여 어떤 작업을 수행하는 데 사용되는 경우 컴퓨터 프로그램이라는 명령이 제공되어야 합니다. 전통적인 프로그래밍은 1800년 이상 동안 실행되어 왔습니다. 그들은 컴퓨터 프로그램이 데이터를 사용하고 출력을 생성하기 위해 컴퓨터 시스템에서 실행되는 XNUMX년대 중반에 시작했습니다. 예를 들어, 전통적으로 프로그래밍된 비즈니스 분석은 비즈니스 데이터와 규칙(컴퓨터 프로그램)을 입력으로 사용하고 규칙을 데이터에 적용하여 비즈니스 통찰력을 출력합니다.
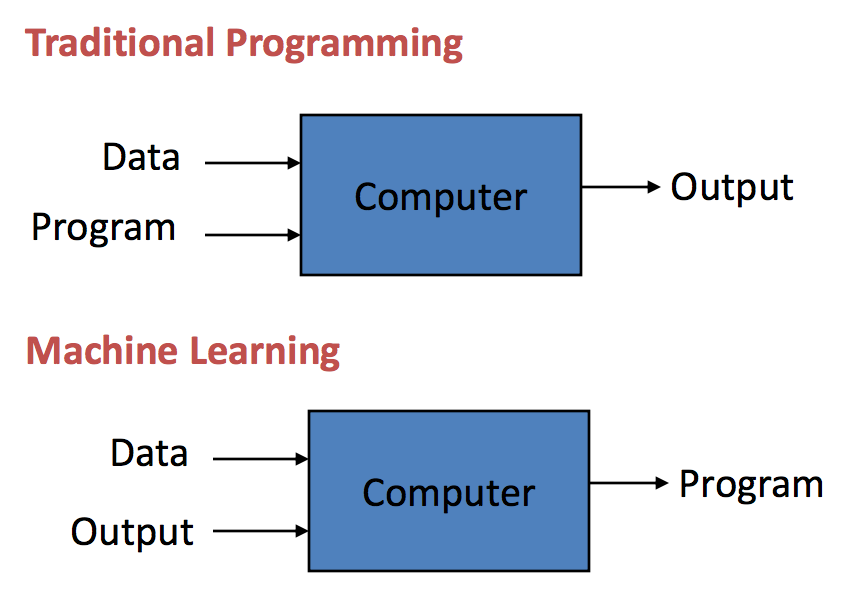
반대로 기계 학습에서는 데이터와 레이블이라고도 하는 출력이 모델을 생성하는 알고리즘의 입력으로 출력으로 제공됩니다.
예를 들어 고객 인구 통계 및 거래가 입력 데이터로 제공되고 과거 고객 이탈률을 출력 데이터(레이블)로 사용하는 경우 알고리즘은 고객 이탈 여부를 예측할 수 있는 모델을 구성할 수 있습니다. 이 모델을 예측 모델이라고 합니다. 이러한 기계 학습 모델은 필요한 과거 데이터와 함께 제공되는 모든 상황을 예측하는 데 사용할 수 있습니다. 기계 학습 기술은 컴퓨터가 고차원의 복잡한 공간에서 인간이 이해하기 어려운 새로운 규칙을 학습할 수 있게 해주기 때문에 매우 가치 있는 기술입니다.
기계 학습의 필요성:
머신 러닝이 등장한지는 꽤 되었지만, 방대한 데이터에 수학적 계산을 자동으로 신속하게 적용하는 능력이 이제 탄력을 받고 있습니다. 머신 러닝은 많은 작업, 특히 타고난 지능을 가진 인간만이 수행할 수 있는 작업을 자동화하는 데 사용할 수 있습니다. 이 인텔리전스는 기계 학습을 통해 기계에 복제될 수 있습니다.
기계 학습은 자율 주행 자동차와 같은 응용 프로그램, Facebook의 친구 추천과 같은 온라인 추천 엔진, Amazon의 제안 제안, 사이버 사기 탐지에서 그 자리를 찾았습니다. 기계 학습은 이미지 및 음성 인식, 언어 번역 및 판매 예측과 같은 문제에 대해 따라야 할 고정 규칙을 적을 수 없는 문제에 필요합니다.
의사 결정, 예측, 예측, 편차에 대한 경고 제공, 숨겨진 추세 또는 관계 발견과 같은 작업에는 기계 학습 패러다임에서만 가장 잘 처리할 수 있는 다양한 아티팩트의 다양한 비정형 실시간 데이터가 필요합니다.
기계 학습의 역사
이 섹션에서는 수년에 걸친 기계 학습 개발에 대해 설명합니다. 오늘날 우리는 처리를 위해 ML 기술을 사용하는 자율 주행 자동차, 자연어 처리 및 안면 인식 시스템과 같은 놀라운 애플리케이션을 목격하고 있습니다. 이 모든 것은 1943년 신경생리학자인 Warren McCulloch가 수학자 Walter Pitts와 함께 뉴런과 그 작용에 대해 조명한 논문을 저술하면서 시작되었습니다. 그들은 전기 회로로 모델을 만들었고 따라서 신경망이 탄생했습니다.
유명한 "Turing Test"는 1950년에 Alan Turing이 컴퓨터가 실제 지능을 가지고 있는지 확인하기 위해 만들었습니다. 사람이 컴퓨터가 아니라 사람이라고 믿게 만들어야 시험을 통과한다. Arthur Samuel은 1952년 체커 게임을 하면서 학습할 수 있는 최초의 컴퓨터 프로그램을 개발했습니다. 퍼셉트론이라는 최초의 신경망은 1957년 Frank Rosenblatt에 의해 설계되었습니다.
1990년대에 기계 학습이 방대한 데이터의 가용성으로 인해 지식 기반에서 데이터 기반 기술로 이동하면서 큰 변화가 일어났습니다. 1997년에 개발된 IBM의 Deep Blue는 체스 게임에서 세계 챔피언을 이긴 최초의 기계였습니다. 기업은 기계 학습을 통해 복잡한 계산의 잠재력을 높일 수 있음을 인식했습니다. 최신 프로젝트 중 일부는 다음과 같습니다. 2012년에 개발된 Google Brain은 이미지와 비디오의 패턴 인식에 중점을 둔 심층 신경망이었습니다. 나중에 YouTube 동영상에서 개체를 감지하는 데 사용되었습니다. 2014년 페이스북은 인간처럼 사람을 인식할 수 있는 딥페이스를 개발했다. 2014년 Deep Mind는 프로 바둑 선수를 물리치는 보드 게임인 Alpha Go라는 컴퓨터 프로그램을 만들었습니다. 복잡성으로 인해 게임은 매우 도전적이지만 인공 지능을 위한 고전적인 게임이라고 합니다. 과학자 스티븐 호킹(Stephen Hawking)과 스튜어트 러셀(Stuart Russel)은 AI가 더욱 빠른 속도로 스스로를 재설계할 수 있는 힘을 얻는다면 타의 추종을 불허하는 "지능 폭발"이 인류의 멸종으로 이어질 수 있다고 느꼈습니다. 머스크는 AI를 인류의 "가장 큰 실존적 위협"으로 규정합니다. Open AI는 Elon Musk가 인류에게 도움이 될 수 있는 안전하고 친근한 AI를 개발하기 위해 2015년에 만든 조직입니다. 최근 AI의 획기적인 영역 중 일부는 컴퓨터 비전, 자연어 처리 및 강화 학습입니다.
기계 학습의 특징
최근 몇 년 동안 기술 영역은 기계 학습이라는 매우 인기 있는 주제를 목격했습니다. 거의 모든 기업이 이 기술을 수용하려고 시도하고 있습니다. 기업은 비즈니스를 수행하는 방식을 변화시켰고 기계 학습의 영향으로 인해 미래는 더 밝고 유망해 보입니다. 기계 학습의 주요 기능 중 일부는 다음과 같습니다.
자동화: 반복 작업을 자동화하여 비즈니스 생산성을 높이는 능력은 머신 러닝의 가장 큰 핵심 요소입니다. ML 기반 서류 작업 및 이메일 자동화는 많은 조직에서 사용되고 있습니다. 금융 부문에서 ML은 회계 업무를 더 빠르고 정확하게 만들고 유용한 인사이트를 빠르고 쉽게 도출합니다. 이메일 분류는 스팸 이메일이 Gmail에 의해 자동으로 스팸 폴더로 분류되는 자동화의 전형적인 예입니다.
향상된 고객 참여: 고객에게 맞춤형 경험을 제공하고 우수한 서비스를 제공하는 것은 브랜드 충성도를 높이고 장기적인 고객 관계를 유지하는 데 매우 중요합니다. 이는 ML을 통해 달성할 수 있습니다. 고객의 니즈에 완벽하게 맞춘 추천 엔진을 만들고 대화의 뉘앙스를 이해하고 질문에 적절하게 대답함으로써 인간의 대화를 원활하게 시뮬레이션할 수 있는 챗봇을 만듭니다. Air Asia 항공사의 AVA는 이러한 채팅 봇 중 하나의 예입니다. AI로 구동되는 가상 비서로 고객 문의에 즉각 대응한다. 11개의 인간 언어를 모방할 수 있으며 자연어 이해 기술을 활용합니다.
자동화된 데이터 시각화: 우리는 방대한 데이터가 비즈니스, 기계 및 개인에 의해 생성되고 있음을 알고 있습니다. 기업은 거래, 전자 상거래, 의료 기록, 금융 시스템 등에서 데이터를 생성합니다. 기계는 또한 위성, 센서, 카메라, 컴퓨터 로그 파일, IoT 시스템, 카메라 등에서 엄청난 양의 데이터를 생성합니다. 개인은 소셜 네트워크, 이메일에서 엄청난 양의 데이터를 생성합니다. , 블로그, 인터넷 등. 시각화를 통해 데이터 간의 관계를 쉽게 식별할 수 있습니다. 데이터의 패턴과 추세를 식별하는 것은 스프레드시트에서 수천 개의 행을 검토하는 대신 정보의 시각적 요약을 통해 쉽게 수행할 수 있습니다. 기업은 기계 학습 애플리케이션에서 제공하는 사용자 친화적인 자동화된 데이터 시각화 플랫폼을 통해 도메인의 생산성을 높이기 위해 데이터 시각화를 통해 가치 있는 새로운 통찰력을 얻을 수 있습니다. Auto Viz는 기업의 생산성을 향상시키기 위해 자동화된 데이터 시각화 요금을 제공하는 플랫폼 중 하나입니다.
정확한 데이터 분석: 데이터 분석의 목적은 비즈니스 분석 및 비즈니스 인텔리전스를 식별하려는 특정 질문에 대한 답변을 찾는 것입니다. 기존의 데이터 분석에는 많은 시행착오 방법이 포함되며, 대량의 정형 및 비정형 데이터로 작업할 때는 절대 불가능합니다. 데이터 분석은 많은 시간을 요하는 매우 중요한 작업입니다. 머신 러닝은 실시간 데이터를 완벽하게 처리할 수 있는 많은 알고리즘과 데이터 기반 모델을 제공하여 유용합니다.
비즈니스 인텔리전스: 비즈니스 인텔리전스는 간소화된 수집 작업을 의미합니다. 조직의 데이터 처리 및 분석. AI로 구동되는 비즈니스 인텔리전스 애플리케이션은 새로운 데이터를 면밀히 조사하고 조직과 관련된 패턴과 추세를 인식할 수 있습니다. 기계 학습 기능이 빅 데이터 분석과 결합되면 비즈니스가 성장하고 더 많은 수익을 창출하는 데 도움이 되는 문제에 대한 솔루션을 찾는 데 도움이 될 수 있습니다. ML은 전자 상거래에서 금융 부문, 의료에 이르기까지 비즈니스 운영을 확장하는 가장 강력한 기술 중 하나가 되었습니다.
기계 학습을 위한 언어
기계 학습을 위한 많은 프로그래밍 언어가 있습니다. 언어 선택과 원하는 프로그래밍 수준은 응용 프로그램에서 기계 학습이 사용되는 방식에 따라 다릅니다. 모든 비즈니스 애플리케이션을 위한 기계 학습 기술을 구현하려면 프로그래밍, 논리, 데이터 구조, 알고리즘 및 메모리 관리의 기초가 필요합니다. 이 지식을 사용하면 많은 프로그래밍 언어에서 제공하는 다양한 내장 라이브러리의 도움으로 기계 학습 모델을 즉시 구현할 수 있습니다. 또한 Orange, Big ML, Weka 등과 같은 많은 그래픽 및 스크립팅 언어가 있어 하드코딩 없이 ML 알고리즘을 구현할 수 있습니다. 프로그래밍에 대한 기본적인 지식만 있으면 됩니다.
기계 학습에 '최고'라고 할 수 있는 단일 프로그래밍 언어는 없습니다. 그들 각각은 그들이 적용되는 곳에서 좋습니다. NLP 애플리케이션에 Python을 사용하는 것을 선호하는 사람도 있고 감정 분석 애플리케이션에 R 또는 Python을 선호하는 사람도 있고 보안 및 위협 감지와 관련된 ML 애플리케이션에 Java를 사용하는 사람도 있습니다. ML 프로그래밍에 가장 적합한 다섯 가지 언어가 아래에 나열되어 있습니다.

파이썬 :
거의 8만 명의 개발자가 전 세계 코딩에 Python을 사용하고 있습니다. IEEE Spectrum의 연간 순위에서 Python이 가장 인기 있는 프로그래밍 언어로 선정되었습니다. 또한 프로그래밍 언어의 스택 오버플로 추세는 Python이 지난 2년 동안 상승하고 있음을 보여줍니다. 여기에는 기계 학습을 위한 광범위한 패키지 및 라이브러리 모음이 있습니다. Python 프로그래밍에 대한 기본 지식이 있는 사용자라면 누구나 큰 어려움 없이 바로 이 라이브러리를 사용할 수 있습니다.
텍스트 데이터로 작업하려면 NLTK, SciKit 및 Numpy와 같은 패키지가 편리합니다. OpenCV 및 Sci-Kit 이미지를 사용하여 이미지를 처리할 수 있습니다. 오디오 데이터로 작업하는 동안 Librosa를 사용할 수 있습니다. 딥 러닝 애플리케이션을 구현할 때 TensorFlow, Keras 및 PyTorch는 생명의 은인으로 등장합니다. Sci-Kit-learn은 기본 기계 학습 알고리즘을 구현하는 데 사용할 수 있으며 Sci-Py는 과학적 계산을 수행하는 데 사용할 수 있습니다. Matplotlib, Sci-Kit 및 Seaborn과 같은 패키지는 최상의 데이터 시각화에 가장 적합합니다.
R:
R은 통계 데이터를 사용하는 기계 학습 애플리케이션을 위한 탁월한 프로그래밍 언어입니다. R에는 정확한 미래 예측을 위해 기계 학습 모델을 훈련하고 평가하는 다양한 도구가 포함되어 있습니다. R은 오픈 소스 프로그래밍 언어이며 매우 비용 효율적입니다. 매우 유연하고 플랫폼 간 호환이 가능합니다. 데이터 샘플링, 데이터 분석, 모델 평가 및 데이터 시각화 작업을 위한 광범위한 기술을 보유하고 있습니다. 포괄적인 패키지 목록에는 누락된 값을 처리하는 데 사용되는 MICE, 회귀 문제 분류를 수행하는 CARET, 데이터에 파티션을 생성하는 PARTY 및 rpart, 의사 결정 트리 생성을 위한 random FOREST, 데이터 조작에 사용되는 tidyr 및 dplyr, 다음을 위한 ggplot이 포함됩니다. 데이터 시각화 생성, Rmarkdown 및 Shiny는 보고서 생성을 통해 통찰력을 인식합니다.
자바와 자바스크립트:
Java 배경에서 온 엔지니어로부터 기계 학습에서 Java가 더 많은 관심을 받고 있습니다. 빅 데이터 처리에 사용되는 Hadoop 및 Spark와 같은 대부분의 오픈 소스 도구는 Java로 작성됩니다. 기계 학습 알고리즘을 구현하기 위해 JavaML과 같은 다양한 타사 라이브러리가 있습니다. Arbiter Java는 ML에서 하이퍼 매개변수 튜닝에 사용됩니다. 나머지는 딥 러닝 응용 프로그램에 사용되는 Deeplearning4J 및 Neuroph입니다. Java의 확장성은 복잡하고 거대한 애플리케이션을 생성할 수 있는 ML 알고리즘을 크게 향상시킵니다. JVM(Java Virtual Machine)은 여러 플랫폼에서 코드를 생성할 수 있는 추가 이점입니다.
줄리아 :
Julia는 복잡한 수치 분석 및 계산 과학을 수행할 수 있는 범용 프로그래밍 언어입니다. 기계 학습 알고리즘에서 수학적 및 과학적 작업을 수행하도록 특별히 설계되었습니다. Julia 코드는 고속으로 실행되며 성능과 관련된 문제를 해결하기 위한 최적화 기술이 필요하지 않습니다. TensorFlow, MLBase.jl, Flux.jl, SciKitlearn.jl과 같은 다양한 도구가 있습니다. TPU 및 GPU를 포함한 모든 유형의 하드웨어를 지원합니다. Apple 및 Oracle과 같은 기술 대기업은 기계 학습 애플리케이션을 위해 Julia를 고용하고 있습니다.
리스프:
LIST(목록 처리)는 여전히 사용되고 있는 두 번째로 오래된 프로그래밍 언어입니다. AI 중심 애플리케이션을 위해 개발되었습니다. LISP는 귀납 논리 프로그래밍 및 기계 학습에 사용됩니다. 최초의 AI 채팅 봇인 ELIZA는 LISP를 사용하여 개발되었습니다. 챗봇 전자 상거래와 같은 많은 기계 학습 응용 프로그램은 LISP를 사용하여 개발됩니다. 빠른 프로토타이핑 기능을 제공하고 자동 가비지 수집을 수행하며 동적 개체 생성을 제공하고 작업에 많은 유연성을 제공합니다.
기계 학습의 유형
높은 수준의 머신 러닝은 특정 작업을 자동으로 개선하기 위해 컴퓨터 프로그램이나 알고리즘을 가르치는 연구로 정의됩니다. 연구 관점에서 전체 프로세스의 작업에 대해 이론적 및 수학적 모델링의 눈을 통해 볼 수 있습니다. 인공 지능과 기계 학습에 흠뻑 젖은 세상에서 다양한 유형의 기계 학습에 대해 배우고 이해하는 것은 흥미 롭습니다. 이는 컴퓨터 사용자의 입장에서 머신러닝의 종류와 다양한 애플리케이션에서 어떻게 나타날 수 있는지에 대한 이해로 볼 수 있다. 그리고 실무자의 관점에서 주어진 작업에 대해 이러한 애플리케이션을 만들기 위한 기계 학습 유형을 알아야 합니다.
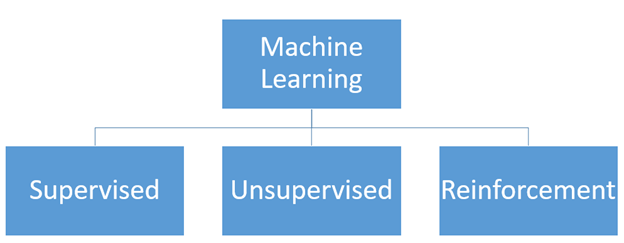
지도 학습:
감독 학습은 모델을 사용하여 입력 변수와 대상 변수 간의 매핑을 학습하는 문제 클래스입니다. 다양한 입력 변수 및 대상 변수는 감독 학습 작업으로 알려져 있습니다.
입력 변수 집합을 (x)로 하고 대상 변수를 (y)로 설정합니다. 지도 학습 알고리즘은 x의 함수인 y=f(x)라는 표현으로 주어진 매핑인 가상 함수를 학습하려고 합니다.
여기서 학습 과정은 모니터링되거나 감독됩니다. 우리는 이미 출력을 알고 있기 때문에 예측을 할 때마다 알고리즘이 수정되어 결과를 최적화합니다. 모델은 입력 변수와 출력 변수로 구성된 교육 데이터에 적합하며 테스트 데이터에 대한 예측을 만드는 데 사용됩니다. 테스트 단계에서는 입력만 제공되며 모델에서 생성된 출력은 보관된 대상 변수와 비교되어 모델의 성능을 추정하는 데 사용됩니다.
기본적으로 지도 문제에는 두 가지 유형이 있습니다. 분류(클래스 레이블 예측 포함)와 회귀(수치 예측 포함)입니다.
MINST 필기 숫자 데이터 세트는 분류 작업의 예로 볼 수 있습니다. 입력은 손으로 쓴 숫자의 이미지이고 출력은 0에서 9 사이의 숫자를 다른 클래스로 식별하는 클래스 레이블입니다.
보스턴 주택 가격 데이터 세트는 입력이 집의 특징이고 출력이 숫자 값인 달러로 표시되는 주택 가격인 회귀 문제의 예로 볼 수 있습니다.
비지도 학습:
에서 비지도 학습 문제는 모델이 스스로 학습하고 패턴을 인식하여 데이터 간의 관계를 추출하려는 것입니다. 감독 학습의 경우와 마찬가지로 모델을 구동할 감독자나 교사가 없습니다. 비지도 학습은 입력 변수에 대해서만 작동합니다. 학습 과정을 안내하는 목표 변수는 없습니다. 여기서 목표는 기본 데이터에 대한 숙련도를 높이기 위해 데이터의 기본 패턴을 해석하는 것입니다.
비지도 학습에는 두 가지 주요 범주가 있습니다. 그들은 클러스터링하고 있습니다. 여기서 작업은 데이터에서 다른 그룹을 찾는 것입니다. 다음은 데이터 분포를 통합하려는 밀도 추정입니다. 이러한 작업은 데이터의 패턴을 이해하기 위해 수행됩니다. 시각화 및 프로젝션은 데이터에 대한 더 많은 통찰력을 제공하려고 하기 때문에 감독되지 않은 것으로 간주될 수도 있습니다. 시각화에는 데이터에 대한 플롯 및 그래프 작성이 포함되며 프로젝션은 데이터의 차원 축소와 관련됩니다.
강화 학습:
강화 학습은 에이전트가 있고 에이전트가 작동하는 환경에서 에이전트에게 제공되는 피드백 또는 보상을 기반으로 환경에서 작동하는 문제의 유형입니다. 보상은 긍정적이거나 부정적일 수 있습니다. 그런 다음 에이전트는 얻은 보상을 기반으로 환경에서 진행합니다.
강화 에이전트는 특정 작업을 수행하는 단계를 결정합니다. 여기에는 고정된 교육 데이터 세트가 없으며 기계가 스스로 학습합니다.
게임 플레이는 에이전트의 목표가 높은 점수를 획득하는 강화 문제의 전형적인 예입니다. 그것은 보상 또는 불이익의 관점에서 볼 수 있는 환경에 의해 주어진 피드백을 기반으로 게임에서 연속적인 움직임을 만듭니다. 강화 학습은 세계 XNUMX위 바둑 플레이어를 꺾은 Google의 AplhaGo에서 엄청난 결과를 보여주었습니다.
기계 학습 알고리즘
사용 가능한 다양한 기계 학습 알고리즘이 있으며 당면한 문제에 가장 적합한 것을 선택하는 것은 매우 어렵고 시간이 많이 걸립니다. 이러한 알고리즘은 두 가지 범주로 그룹화할 수 있습니다. 첫째, 학습 패턴에 따라 그룹화할 수 있고 두 번째로 기능의 유사성에 따라 그룹화할 수 있습니다.
학습 스타일에 따라 세 가지 유형으로 나눌 수 있습니다.
- 지도 학습 알고리즘 : 학습 데이터는 학습 프로세스를 안내하는 레이블과 함께 제공됩니다. 훈련 데이터로 원하는 정확도 수준에 도달할 때까지 모델을 훈련합니다. 이러한 문제의 예로는 분류 및 회귀가 있습니다. 사용되는 알고리즘의 예로는 Logistic Regression, Nearest Neighbor, Naive Bayes, Decision Trees, Linear Regression, Support Vector Machines(SVM), Neural Networks가 있습니다.
- 비지도 학습 알고리즘 : 입력 데이터는 레이블이 지정되지 않으며 레이블과 함께 제공되지 않습니다. 모델은 입력 데이터에 존재하는 패턴을 식별하여 준비됩니다. 이러한 문제의 예로는 클러스터링, 차원 축소 및 연관 규칙 학습이 있습니다. 이러한 유형의 문제에 사용되는 알고리즘 목록에는 Apriori 알고리즘과 K-Means 및 연관 규칙이 포함됩니다.
- 준지도 학습 알고리즘: 숙련된 인간 전문가의 지식이 필요하기 때문에 데이터에 레이블을 지정하는 비용이 상당히 비쌉니다. 입력 데이터는 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터의 조합입니다. 모델은 자체적으로 기본 패턴을 학습하여 예측을 수행합니다. 분류 및 클러스터링 문제가 혼합되어 있습니다.
기능의 유사성에 따라 알고리즘을 다음과 같이 그룹화할 수 있습니다.
- 회귀 알고리즘: 회귀는 새 데이터에 대한 예측을 만들기 위해 대상 출력 변수와 입력 기능 간의 관계를 식별하는 것과 관련된 프로세스입니다. 상위 XNUMX개의 회귀 알고리즘은 단순 선형 회귀, 라소 회귀, 로지스틱 회귀, 다변량 회귀 알고리즘, 다중 회귀 알고리즘입니다.
- 인스턴스 기반 알고리즘: 이들은 훈련 데이터에 있는 문제의 새로운 사례를 측정하여 가장 일치하는 것을 찾고 그에 따라 예측하는 학습 계열에 속합니다. 상위 인스턴스 기반 알고리즘은 k-Nearest Neighbor, Learning Vector Quantization, Self-Organizing Map, Locally Weighted Learning 및 Support Vector Machines입니다.
- 정규화: 정규화는 특정 기능 집합에서 학습 프로세스를 정규화하는 기술을 나타냅니다. 정상화하고 완화합니다. 기능에 첨부된 가중치는 정규화되어 특정 기능이 예측 프로세스를 지배하는 것을 방지합니다. 이 기술은 기계 학습에서 과적합 문제를 방지하는 데 도움이 됩니다. 다양한 정규화 알고리즘은 Ridge Regression, LASSO(Least Absolute Shrinkage and Selection Operator) 및 LARS(Least-Angle Regression)입니다.
- 의사 결정 트리 알고리즘: 이러한 방법은 속성 값을 검사하여 내린 결정에 따라 구성된 트리 기반 모델을 구성합니다. 결정 트리는 분류 및 회귀 문제 모두에 사용됩니다. 잘 알려진 결정 트리 알고리즘에는 분류 및 회귀 트리, C4.5 및 C5.0, 조건부 결정 트리, 카이 제곱 자동 상호 작용 감지 및 결정 스텀프가 있습니다.
- 베이지안 알고리즘: 이러한 알고리즘은 분류 및 회귀 문제에 베이즈 정리를 적용합니다. 여기에는 Naive Bayes, Gaussian Naive Bayes, Multinomial Naive Bayes, Bayesian Belief Network, Bayesian Network 및 Averaged One-Dependence Estimators가 포함됩니다.
- 클러스터링 알고리즘: 클러스터링 알고리즘에는 데이터 포인트를 클러스터로 그룹화하는 작업이 포함됩니다. 동일한 그룹에 있는 모든 데이터 포인트는 유사한 속성을 공유하며 다른 그룹의 데이터 포인트는 매우 다른 속성을 가집니다. 클러스터링은 감독되지 않은 학습 방식이며 많은 분야에서 통계 데이터 분석에 주로 사용됩니다. k-Means, k-Medians, Expectation Maximisation, Hierarchical Clustering, Density-Based Spatial Clustering of Applications with Noise와 같은 알고리즘이 이 범주에 속합니다.
- 연관 규칙 학습 알고리즘: 연관 규칙 학습은 매우 큰 데이터 세트에서 변수 간의 관계를 식별하기 위한 규칙 기반 학습 방법입니다. 연관 규칙 학습은 주로 장바구니 분석에 사용됩니다. 가장 널리 사용되는 알고리즘은 Apriori 알고리즘과 Eclat 알고리즘입니다.
- 인공 신경망 알고리즘: 인공 신경망 알고리즘은 인간 두뇌의 생물학적 뉴런에서 기반을 찾습니다. 분류 및 회귀 문제에서 복잡한 패턴 일치 및 예측 프로세스 클래스에 속합니다. 인기 있는 인공 신경망 알고리즘 중 일부는 Perceptron, Multilayer Perceptrons, Stochastic Gradient Descent, Back-Propagation, Hopfield Network 및 Radial Basis Function Network입니다.
- 딥 러닝 알고리즘: 이들은 레이블이 지정된 데이터의 매우 크고 복잡한 데이터베이스를 처리할 수 있는 현대화된 인공 신경망 버전입니다. 딥 러닝 알고리즘은 텍스트, 이미지, 오디오 및 비디오 데이터를 처리하도록 맞춤화되었습니다. 딥 러닝은 숨겨진 계층이 많은 독학 학습 구조를 사용하여 빅 데이터를 처리하고 보다 강력한 계산 리소스를 제공합니다. 가장 인기 있는 딥 러닝 알고리즘은 다음과 같습니다. 인기 있는 딥 러닝 MS에는 Convolutional Neural Network, Recurrent Neural Networks, Deep Boltzmann Machine, Auto-Encoders Deep Belief Networks 및 Long Short-Term Memory Networks가 포함됩니다.
- 차원 감소 알고리즘: 차원 축소 알고리즘은 축소된 정보 집합을 사용하여 데이터를 표현하기 위해 감독되지 않은 방식으로 데이터의 고유 구조를 활용합니다. 고차원 데이터를 분류 및 회귀와 같은 감독 학습 방법에 사용할 수 있는 저차원으로 변환합니다. 잘 알려진 차원 감소 알고리즘에는 주성분 분석, 주성분 회귀, 선형 판별 분석, XNUMX차 판별 분석, 혼합 판별 분석, 유연한 판별 분석 및 Sammon 매핑이 포함됩니다.
- 앙상블 알고리즘: 앙상블 방법은 개별적으로 훈련되는 다양한 약한 모델로 구성된 모델이며 모델의 개별 예측은 최종 전체 예측을 얻기 위해 일부 방법을 사용하여 결합됩니다. 출력 품질은 개별 결과를 결합하기 위해 선택한 방법에 따라 다릅니다. 인기 있는 방법으로는 Random Forest, Boosting, Bootstrapped Aggregation, AdaBoost, Stacked Generalization, Gradient Boosting Machines, Gradient Boosted Regression Trees 및 Weighted Average가 있습니다.
기계 학습 수명 주기
기계 학습은 명시적으로 프로그래밍할 필요 없이 컴퓨터가 자동으로 학습할 수 있는 기능을 제공합니다. 기계 학습 프로세스는 고품질 모델을 설계, 개발 및 배포하는 여러 단계로 구성됩니다. 기계 학습 수명 주기는 다음 단계로 구성됩니다.
- 데이터 수집
- 데이터 준비
- 데이터 랭 글링
- 데이터 분석
- 모델 훈련
- 모델 테스트
- 모델의 전개
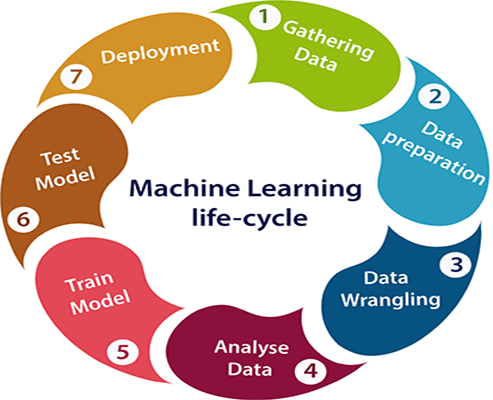
- 데이터 수집: 이것은 기계 학습 모델을 만드는 첫 번째 단계입니다. 이 단계의 주요 목적은 문제와 관련된 모든 데이터를 식별하고 수집하는 것입니다. 파일, 데이터베이스, 인터넷, IoT 장치와 같은 다양한 소스에서 데이터를 수집할 수 있으며 그 목록은 계속 증가하고 있습니다. 출력의 효율성은 수집된 데이터의 품질에 직접적으로 의존합니다. 따라서 많은 양의 양질의 데이터를 수집하는 데 각별한 주의를 기울여야 합니다.
- 데이터 준비 : 수집된 데이터는 정리되어 한 곳에 보관되거나 추가 처리됩니다. 데이터 탐색은 이 단계의 일부로서 데이터의 특성, 특성, 형식 및 품질에 액세스합니다. 여기에는 파이 차트, 막대 차트, 히스토그램, 왜도 등의 생성이 포함됩니다. 데이터 탐색은 데이터에 대한 유용한 통찰력을 제공하고 문제의 75%를 해결하는 데 도움이 됩니다.
- 데이터 랭글링: 데이터 랭글링에서 원시 데이터는 정리되고 유용한 형식으로 변환됩니다. 수집된 데이터를 최대한 활용하기 위해 적용되는 일반적인 기술은 다음과 같습니다.
- 결측치 확인 및 결측치 대치
- 원치 않는 데이터 및 Null 값 제거
- 관심 도메인을 기반으로 데이터 최적화
- 이상값 감지 및 제거
- 데이터 차원 줄이기
- 데이터 균형, 언더 샘플링 및 오버 샘플링.
- 중복 기록 제거
- 데이터 분석: 이 단계는 기능 선택 및 모델 선택 프로세스와 관련이 있습니다. 종속 변수와 관련된 독립 변수의 예측력이 추정됩니다. 모델에 유익한 변수만 선택됩니다. 다음으로 분류, 회귀, 클러스터링, 연관 등과 같은 적절한 기계 학습 기술이 선택되고 데이터를 사용하여 모델이 구축됩니다.
- 모델 교육 : 학습은 모델이 기본 데이터의 다양한 패턴, 기능 및 규칙을 이해하려고 하기 때문에 기계 학습에서 매우 중요한 단계입니다. 데이터는 학습 데이터와 테스트 데이터로 나뉩니다. 모델은 성능이 허용 가능한 수준에 도달할 때까지 훈련 데이터에 대해 훈련됩니다.
- 모델 테스트 : 모델을 교육한 후 보이지 않는 테스트 데이터에 대한 성능을 평가하기 위해 테스트를 받습니다. 예측의 정확도와 모델의 성능은 혼동 행렬, 정밀도 및 재현율, 민감도 및 특이도, 곡선 아래 영역, F1 점수, R 제곱, 지니 값 등과 같은 다양한 측정을 사용하여 측정할 수 있습니다.
- 전개: 이것은 기계 학습 수명 주기의 마지막 단계이며 실제 시스템에서 구축된 모델을 배포합니다. 배포 전에 모델은 피클됩니다. 즉, 플랫폼 독립적인 실행 가능 형식으로 변환되어야 합니다. 절인 모델은 Rest API 또는 마이크로 서비스를 사용하여 배포할 수 있습니다.
깊은 학습
딥 러닝은 인간 두뇌의 뉴런 기능을 따르는 기계 학습의 하위 집합입니다. 딥 러닝 네트워크는 계층으로 서로 연결된 여러 뉴런으로 구성됩니다. 신경망에는 학습 프로세스를 가능하게 하는 많은 심층 계층이 있습니다. 딥 러닝 신경망은 완전한 네트워크를 구성하는 입력 계층, 출력 계층 및 여러 숨겨진 계층으로 구성됩니다. 처리는 입력 데이터, 미리 할당된 가중치 및 네트워크를 통한 제어 흐름의 경로를 결정하는 활성화 기능을 포함하는 연결을 통해 발생합니다. 네트워크는 방대한 양의 데이터에서 작동하며 각 수준에서 복잡한 기능을 학습하여 각 계층을 통해 전파합니다. 모델의 결과가 예상과 다르면 가중치를 조정하고 원하는 결과를 얻을 때까지 프로세스를 다시 반복합니다.

심층 신경망은 명시적으로 프로그래밍하지 않고도 자동으로 기능을 학습할 수 있습니다. 각 레이어는 더 깊은 수준의 정보를 나타냅니다. 딥 러닝 모델은 각 계층에 표현된 지식의 계층 구조를 따릅니다. XNUMX개의 레이어가 있는 신경망은 XNUMX개의 레이어가 있는 신경망보다 더 많은 것을 학습합니다. 신경망의 학습은 두 단계로 이루어집니다. 첫 번째 단계에서 비선형 변환이 입력에 적용되고 통계 모델이 생성됩니다. 두 번째 단계에서 생성된 모델은 도함수라는 수학적 모델의 도움으로 개선됩니다. 이 두 단계는 원하는 수준의 정확도에 도달할 때까지 신경망에 의해 수천 번 반복됩니다. 이 두 단계의 반복을 반복이라고 합니다.
은닉층이 하나만 있는 신경망을 얕은 신경망이라고 하고, 은닉층이 둘 이상인 신경망을 심층 신경망이라고 합니다.
신경망 유형:
다양한 유형의 프로세스에 사용할 수 있는 다양한 유형의 신경망이 있습니다. 여기서는 가장 일반적으로 사용되는 유형에 대해 설명합니다.
- 퍼셉트론: 퍼셉트론은 입력 레이어와 출력 레이어만 포함하는 단일 레이어 신경망입니다. 숨겨진 레이어가 없습니다. 여기서 사용하는 활성화 함수는 시그모이드 함수입니다.
- 피드포워드: 피드 포워드 신경망은 정보가 한 방향으로만 흐르는 가장 단순한 형태의 신경망입니다. 신경망의 경로에는 주기가 없습니다. 계층의 모든 노드는 다음 계층의 모든 노드에 연결됩니다. 따라서 모든 노드가 완전히 연결되고 백 루프가 없습니다.
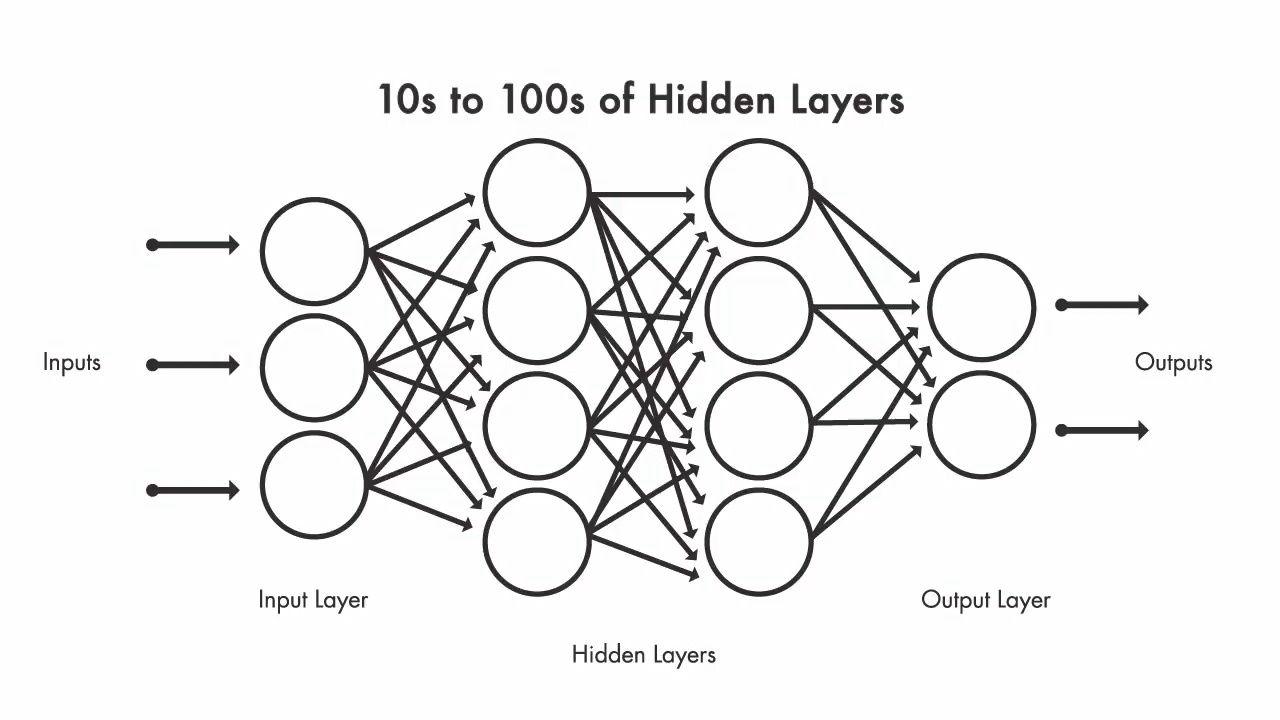
- 순환 신경망: Recurrent Neural Networks는 네트워크의 출력을 메모리에 저장하고 네트워크에 피드백하여 출력 예측을 돕습니다. 네트워크는 두 개의 서로 다른 계층으로 구성됩니다. 첫 번째는 피드 포워드 신경망이고 두 번째는 이전 네트워크 값과 상태가 메모리에 기억되는 순환 신경망입니다. 잘못된 예측이 이루어지면 학습률을 사용하여 역전파를 통해 점진적으로 올바른 예측을 향해 이동합니다.
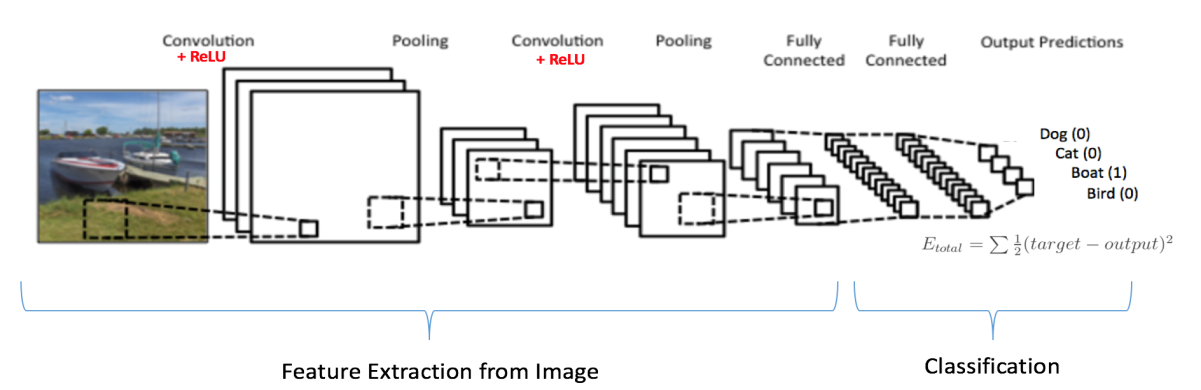
- 컨벌루션 신경망: Convolutional Neural Networks는 구조화되지 않은 데이터에서 유용한 정보를 추출해야 하는 경우에 사용됩니다. 시그나 전파는 CNN에서 단방향입니다. 첫 번째 레이어는 컨볼루션 레이어이고 그 다음에는 풀링이 있고 그 다음에는 여러 컨볼루션 및 풀링 레이어가 있습니다. 이러한 계층의 출력은 완전히 연결된 계층과 분류 프로세스를 수행하는 소프트맥스로 공급됩니다. CNN의 뉴런에는 학습 가능한 가중치와 편향이 있습니다. 컨볼루션은 비선형 RELU 활성화 함수를 사용합니다. CNN은 신호 및 이미지 처리 애플리케이션에 사용됩니다.
- 강화 학습: 강화 학습에서 복잡하고 불확실한 환경에서 작동하는 에이전트는 시행 착오 방법으로 학습합니다. 에이전트는 행동의 결과로 사실상 보상을 받거나 처벌을 받으며 생산된 출력을 개선하는 데 도움을 줍니다. 목표는 에이전트가 받는 총 보상 수를 최대화하는 것입니다. 모델은 보상을 최대화하기 위해 자체적으로 학습합니다. Google의 DeepMind 및 Self drivig 자동차는 강화 학습이 활용되는 애플리케이션의 예입니다.
기계 학습과 딥 러닝의 차이점
딥 러닝은 기계 학습의 하위 집합입니다. 기계 학습 모델은 일부 안내를 통해 기능을 학습함에 따라 점진적으로 개선됩니다. 예측이 정확하지 않으면 전문가가 모델을 조정해야 합니다. 딥 러닝에서 모델 자체는 예측이 올바른지 여부를 식별할 수 있습니다.
- 작동: 딥 러닝은 데이터를 입력으로 사용하고 인공 신경망의 스테이크 레이어를 사용하여 자동으로 지능적인 결정을 내리려고 합니다. 기계 학습은 입력 데이터를 가져와 구문 분석하고 데이터에 대해 교육을 받습니다. 학습 단계에서 학습한 내용을 기반으로 데이터에 대한 결정을 내리려고 합니다.
- 특징 추출: 딥 러닝은 입력 데이터에서 관련 기능을 추출합니다. 계층적 방식으로 피처를 자동으로 추출합니다. 기능은 레이어 방식으로 학습됩니다. 처음에는 낮은 수준의 기능을 학습하고 네트워크 아래로 이동하면서 보다 구체적인 기능을 학습하려고 시도합니다. 반면 기계 학습 모델에는 데이터 세트에서 직접 선택한 기능이 필요합니다. 이러한 기능은 예측을 수행하기 위해 모델에 대한 입력으로 제공됩니다.
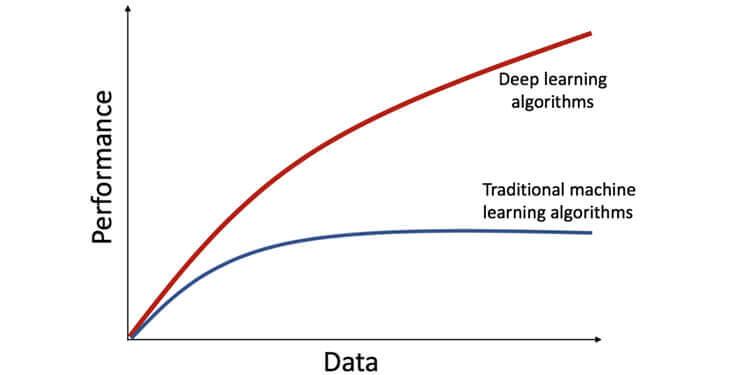
- 데이터 종속성: 딥 러닝 모델은 자체적으로 특징 추출 프로세스를 수행하기 때문에 방대한 양의 데이터가 필요합니다. 그러나 기계 학습 모델은 더 작은 데이터 세트와 완벽하게 잘 작동합니다. 딥 러닝 모델의 네트워크 깊이는 데이터와 함께 증가하므로 딥 러닝 모델의 복잡성도 증가합니다. 다음 다이어그램은 데이터가 증가함에 따라 딥 러닝 모델의 성능이 향상되지만 머신 러닝 모델은 일정 기간이 지나면 곡선을 평평하게 만드는 것을 보여줍니다.
- 계산 능력: 딥 러닝 네트워크는 일반 CPU가 아닌 GPU의 지원이 필요한 방대한 데이터에 크게 의존합니다. GPU는 동시에 여러 계산을 처리할 수 있으므로 딥 러닝 모델의 처리를 극대화할 수 있습니다. GPU의 높은 메모리 대역폭은 딥 러닝 모델에 적합합니다. 반면 기계 학습 모델은 CPU에서 구현할 수 있습니다.
- 실행 시간: 일반적으로 딥 러닝 알고리즘은 관련 매개변수가 많기 때문에 훈련하는 데 오랜 시간이 걸립니다. 딥 러닝 알고리즘의 예인 ResNet 아키텍처는 처음부터 훈련하는 데 거의 XNUMX주가 걸립니다. 그러나 기계 학습 알고리즘은 훈련하는 데 더 적은 시간이 걸립니다(몇 분에서 몇 시간). 이것은 테스트 시간과 관련하여 완전히 반대입니다. 딥 러닝 알고리즘은 실행하는 데 더 적은 시간이 걸립니다.
- 해석 가능성 : 기계 학습 알고리즘을 해석하고 각 단계에서 수행되는 작업과 수행되는 이유를 이해하기가 더 쉽습니다. 그러나 딥 러닝 알고리즘은 딥 러닝 아키텍처 내부에서 무슨 일이 일어나고 있는지 실제로 알지 못하기 때문에 블랙 박스로 알려져 있습니다. 어떤 뉴런이 활성화되고 출력에 얼마나 기여하는지. 따라서 기계 학습 모델의 해석은 딥 러닝 모델보다 훨씬 쉽습니다.
기계 학습의 응용
- 교통 도우미: 우리 모두는 여행할 때 교통 도우미를 사용합니다. Google 지도는 목적지까지의 경로를 제공하고 트래픽이 적은 경로를 표시하는 데 유용합니다. 지도를 사용하는 모든 사람은 자신의 위치, 이동 경로 및 운전 속도를 Google 지도에 제공하고 있습니다. 트래픽에 대한 이러한 세부 정보는 Google 지도에서 수집되며 경로의 트래픽을 예측하고 이에 따라 경로를 조정하려고 시도합니다.
- 소셜 미디어: 기계 학습의 가장 일반적인 적용은 자동 친구 태깅 및 친구 제안에서 볼 수 있습니다. Facebook은 Deep Face를 사용하여 디지털 이미지에서 이미지 인식 및 얼굴 감지를 수행합니다.
- 제품 추천: Amazon에서 특정 제품을 탐색했지만 구매하지 않은 경우 다음 날 YouTube나 Facebook을 열면 관련 광고를 보게 됩니다. Google에서 검색 기록을 추적하고 있으며 검색 기록을 기반으로 제품을 추천합니다. 이것은 기계 학습 기술의 응용 프로그램입니다.
- 개인 비서: 개인 비서는 유용한 정보를 찾는 데 도움을 줍니다. 개인 비서에 대한 입력은 음성 또는 텍스트를 통해 이루어질 수 있습니다. Siri와 Alexa에 대해 모른다고 말할 수 있는 사람은 없습니다. 개인 비서가 전화 응답, 회의 일정 잡기, 메모 작성, 이메일 전송 등을 도와줄 수 있습니다.
- 감정 분석: 사람들의 의견을 이해할 수 있는 실시간 기계 학습 응용 프로그램입니다. 그 적용은 검토 기반 웹 사이트와 의사 결정 응용 프로그램에서 볼 수 있습니다.
- 언어 번역 : 언어 번역은 현재 사용 가능한 언어 번역가로 가득 차 있기 때문에 더 이상 어려운 작업이 아닙니다. Google의 GNMT는 자연어 처리 기술을 사용하여 문장이나 단어의 정확한 번역을 제공하기 위해 수천 개의 사전과 언어에 액세스할 수 있는 효율적인 신경망 기계 번역 도구입니다.
- 온라인 사기 탐지: ML 알고리즘은 과거 사기 패턴에서 학습하고 미래의 사기 거래를 인식할 수 있습니다. ML 알고리즘은 정보 처리 속도에서 인간보다 더 효율적인 것으로 입증되었습니다. ML로 구동되는 사기 탐지 시스템은 사람이 탐지하지 못하는 사기를 찾을 수 있습니다.
- 의료 서비스: AI는 의료 산업의 미래가 되고 있습니다. AI는 임상 의사 결정에 핵심적인 역할을 하여 질병을 조기에 발견하고 환자에게 맞춤 치료를 가능하게 합니다. 기계 학습을 사용하는 PathAI는 병리학자가 질병을 정확하게 진단하는 데 사용됩니다. Quantitative Insights는 유방암 진단의 속도와 정확성을 향상시키는 AI 지원 소프트웨어입니다. 방사선과 전문의의 향상된 진단을 통해 환자에게 더 나은 결과를 제공합니다.
딥러닝의 응용
- 자율주행 자동차: 자율주행차는 딥러닝 기술을 통해 구현됩니다. Ai Labs에서는 음식 배달과 같은 기능을 무인 자동차에 통합하기 위한 연구도 진행되고 있습니다. 데이터는 센서, 카메라 및 지리적 매핑에서 수집되어 트래픽을 원활하게 이동할 수 있는 보다 정교한 모델을 만드는 데 도움이 됩니다.
- 사기 뉴스 감지: 사기 뉴스를 탐지하는 것은 오늘날의 세계에서 매우 중요합니다. 인터넷은 진짜와 가짜를 막론하고 모든 종류의 뉴스의 출처가 되었습니다. 가짜 뉴스를 식별하는 것은 매우 어려운 작업입니다. 딥 러닝의 도움으로 우리는 가짜 뉴스를 감지하고 뉴스 피드에서 제거할 수 있습니다.
- 자연어 처리 : 언어의 구문, 의미론, 어조 또는 뉘앙스를 이해하려고 노력하는 것은 인간에게 매우 어렵고 복잡한 작업입니다. 기계는 언어의 뉘앙스를 식별하고 자연어 처리 기술의 도움을 받아 그에 따라 응답을 구성하도록 훈련될 수 있습니다. 딥 러닝은 자연어 처리를 사용하는 텍스트 분류, 트위터 분석, 언어 모델링, 감정 분석 등과 같은 애플리케이션에서 인기를 얻고 있습니다.
- 가상 비서: 가상 비서는 딥 러닝 기술을 사용하여 사람들의 외식 선호도에서 좋아하는 노래에 이르기까지 주제에 대한 광범위한 지식을 갖습니다. 가상 비서가 말하는 언어를 이해하고 작업을 수행하려고 합니다. Google은 자연어 이해, 딥 러닝 및 텍스트 음성 변환을 사용하여 사람들이 주중 어느 곳에서나 약속을 예약할 수 있도록 도와주는 Google duplex라는 이 기술을 수년 동안 연구해 왔습니다. 그리고 비서가 작업을 완료하면 약속이 처리되었다는 확인 알림을 제공합니다. 통화가 예상대로 진행되지 않지만 어시스턴트는 뉘앙스에 대한 컨텍스트를 이해하고 대화를 우아하게 처리합니다.
- 시각적 인식 : 오래된 사진을 살펴보는 것은 향수를 불러일으킬 수 있지만 특정 사진을 검색하는 것은 시간이 많이 걸리는 분류 및 분리를 포함하기 때문에 지루한 과정이 될 수 있습니다. 이제 이미지에 딥 러닝을 적용하여 일부 이벤트나 날짜에 따라 사진의 위치, 사람들의 조합을 기준으로 이미지를 정렬할 수 있습니다. 사진 검색은 더 이상 지루하고 복잡하지 않습니다. Vision AI는 AutoML Vision 또는 사전 학습된 Vision API 모델을 사용하여 클라우드의 이미지에서 통찰력을 얻어 텍스트를 식별하고 이미지의 감정을 이해합니다.
- 흑백 이미지 색칠하기: 흑백 이미지를 채색하는 것은 딥 러닝 기술을 사용하여 올바른 색상 톤으로 채색하여 사진에 생명을 불어넣는 컴퓨터 비전 알고리즘의 도움으로 어린아이 놀이와 같습니다. Colorful Image Colorization 마이크로 서비스는 컴퓨터 비전 기술과 Imagenet 데이터베이스에서 훈련된 딥 러닝 알고리즘을 사용하여 흑백 이미지를 색칠하는 알고리즘입니다.
- 무성 영화에 사운드 추가: AI는 이제 무음 비디오를 위한 사실적인 사운드 트랙을 만들 수 있습니다. 특징 추출 및 예측 프로세스를 수행하기 위해 CNN 및 순환 신경망이 사용됩니다. 연구에 따르면 소리를 예측하는 방법을 학습한 이러한 알고리즘은 오래된 영화에 더 나은 음향 효과를 생성하고 로봇이 주변 물체를 이해하는 데 도움이 될 수 있습니다.
- 이미지를 언어로 번역: 이것은 딥 러닝의 또 다른 흥미로운 응용 프로그램입니다. Google 번역 앱은 이미지를 선택한 실시간 언어로 자동 번역할 수 있습니다. 딥 러닝 네트워크는 이미지를 읽고 텍스트를 필요한 언어로 번역합니다.
- 픽셀 복원: Google Brain의 연구원들은 사람 얼굴의 매우 낮은 해상도 이미지를 가져와 이를 통해 사람의 얼굴을 예측하는 딥 러닝 네트워크를 훈련했습니다. 이 방법은 Pixel Recursive Super Resolution으로 알려져 있습니다. 이 방법은 인물의 성격을 식별하기에 충분할 정도로 눈에 띄는 특징을 식별하여 사진의 해상도를 향상시킵니다.
결론
이 장에서는 인공 지능의 현재 및 미래 기능에 대한 명확한 아이디어를 제공하기 위해 기계 학습 및 딥 러닝의 응용 프로그램을 발견했습니다. 가까운 미래에 인공 지능의 많은 응용 프로그램이 우리 삶에 영향을 미칠 것으로 예상됩니다. 예측 분석 및 인공 지능 콘텐츠 제작과 소프트웨어 개발에서 미래의 근본적인 역할을 하게 될 것입니다. 사실 그들은 이미 영향을 미치고 있습니다. 향후 몇 년 내에 AI 개발 도구, 라이브러리 및 언어는 이름을 지정할 수 있는 모든 소프트웨어 개발 툴킷의 보편적으로 허용되는 표준 구성 요소가 될 것입니다. 인공 지능 기술은 건강, 비즈니스, 환경, 공공 안전 및 보안을 포함한 모든 영역에서 미래가 될 것입니다.
참고자료
[1] Aditya Sharma(2018), "머신러닝과 딥러닝의 차이점"
[2] 키슬레이 케샤리(2020), "기계 학습의 10대 응용 프로그램: 일상 생활에서의 기계 학습 응용 프로그램"
[3] Brett Grossfeld(2020), "딥 러닝 vs 머신 러닝: 차이를 이해하는 간단한 방법"
[4] Nikita Duggal(2020), "당신을 놀라게 할 실제 기계 학습 애플리케이션"
[5] PP Shinde 및 S. Shah, "A Review of Machine Learning and Deep Learning Applications," 2018 제2018차 컴퓨팅 통신 제어 및 자동화 국제 회의(ICCUBEA), 인도 푸네, 1, pp. 6-XNUMX
[6] https://www.javatpoint.com/machine-learning-life-cycle
[7] https://medium.com/app-affairs/9-applications-of-machine-learning-from-day-to-day-life-112a47a429d0
[8] 댄 쉬완(2019), “멋진 방법으로 기계 학습을 사용하는 10개 회사”
[9] 마리나 채터지(2019), "20년 산업 전반에 걸친 딥 러닝의 상위 2020개 애플리케이션
[10] 기계 학습 알고리즘 둘러보기 제이슨 브라운 리 in 기계 학습 알고리즘
[11] Jaderberg, Max, 외. “공간 변압기 네트워크.” 신경 정보 처리 시스템의 발전(2015): 2017-2025.
[12] Van Veen, F. & Leijnen, S. (2019). 신경망 동물원. 에서 검색 https://www.asimovinstitute.org/neural-network-zoo
[13] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, Deep Convolutional Neural Networks를 사용한 ImageNet 분류, [pdf], 2012
[14] Yadav, Neha, Anupam, Kumar, Manoj, 미분 방정식을 위한 신경망 소개(ISBN: 978-94-017-9815-0)
[15] Hugo Mayo, Hashan Punchihewa, Julie Emile, Jackson Morrison 기계 학습의 역사, 2018
[16] Pedro Domingos , 2012, 기계 학습 응용 프로그램을 발전시키는 데 필요한 "전통 지식" 활용. A Few Useful 작성, doi:10.1145/2347736.2347755
[17] Alex Smola 및 SVN Vishwanathan, 기계 학습 소개, Cambridge University Press 2008
[18] Antonio Guili와 Sujit Pal, Keras를 사용한 딥 러닝: Python의 힘으로 딥 러닝 모델 및 신경망 구현, 출시 연도: 2017; 팩트 퍼블리싱 주식회사
[19] 아우렐리앙 게론,Scikit-Learn 및 Tensor Flow를 사용한 실습 기계 학습: 지능형 시스템 구축을 위한 개념, 도구 및 기술, 출시 연도: 2017. 오라일리
[20] 기계 학습을 위한 최고의 언어: 배워야 할 프로그래밍 언어, 31년 2020월 XNUMX일, Springboard India.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.mygreatlearning.com/blog/machine-learning-and-deep-learning/

