개요
위조 지폐는 중소기업과 대기업 모두에게 쉽게 문제가 될 수 있습니다. 진품이 아닐 때 이러한 지폐를 식별할 수 있는 것은 매우 중요합니다. 이 프로세스는 일상적인 비즈니스 전문가와 현금을 다루는 개인에게 시간이 많이 소요될 수 있습니다. 따라서 자동화를 통해 이 목표를 달성해야 합니다. AI, 기계 학습 및 딥 러닝 덕분입니다.
결과적으로, 우리는 자동화 된 기계 학습 위조지폐감지 비전문가도 위조지폐의 진위를 판별할 수 있는 모델.
이 기사는 딥 러닝과 이미지 분류가 은행 부문에서 어떻게 사용될 수 있는지에 대한 실제 프로토타입을 개발한 실용적인 프로젝트를 다룹니다. 목표는 실제 문제 시나리오를 사용하여 기계 학습 데모를 완료하는 것입니다. 데이터 수집 및 심층 정리/전처리에서 단순히 훈련된 모델을 배포하는 것으로 이동합니다.
모델의 성능과 모델이 얼마나 적절하게 학습되었는지 확인하기 위해 몇 가지 적합한 평가 지표를 사용할 것입니다. 이것은 은행 시스템이므로 예측이 정확한지 확인하고 싶습니다.
이 기사는 데이터 과학 블로그.
차례
문제 정책
도입부에서 논의한 바와 같이, 위조 지폐와 진짜 지폐를 구별하는 것은 대부분의 사람들에게 어려운 일입니다. 대부분의 사람들은 이 분야에 대한 기술이 없으며 좋은 통화를 사기꾼의 가짜 통화로 쉽게 교환할 수 있습니다. 우리는 연구를 위해 전문적으로 사용할 수 있는 원본 및 위조 콜롬비아 지폐를 사용하여 이 문제를 해결하기 위한 도전에 착수할 것입니다.

이 프로젝트를 완료하기 위한 전제 조건은 기계 학습 모델 파이프라인에 대한 지식, jupyter 노트북에 대한 기본 경험 및 딥 러닝을 통해 이를 더 발전시키고자 하는 관심입니다. 이미지 처리가 처음이더라도 모든 세트가 이해하기 쉽게 구성되어 있으므로 걱정할 필요가 없습니다.
데이터 세트 설명
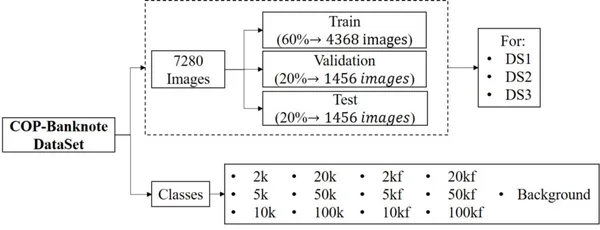
이 데이터 세트는 CC BY 2020 라이선스에 따라 Universidad Militar Nueva Granada에서 4.0년에 제공되었습니다. 이 데이터 세트는 시스템을 실시간으로 확인하여 지폐의 액면가와 위조품을 감지하는 데 사용할 수 있습니다. 데이터 세트는 크기와 이미지 수 면에서 큰 데이터이며 가짜 클래스와 진짜 클래스 모두에서 전문적으로 캡처한 이미지로 구성됩니다. 아래 하이라이트를 보자.
- 데이터 세트는 20800개의 클래스를 포함하는 13개의 이미지로 구성되며, 여기서 6개는 원본 지폐에 해당하고 다른 6개는 위조품에 해당하며 1개의 추가 카테고리는 배경에 해당합니다.
- 여기에는 조명 변형, 회전 및 지폐의 부분 보기가 포함됩니다. ds3, ds20800 및 ds1에 해당하는 각각 2개의 이미지가 있는 3개의 폴더를 포함합니다.
- 각 폴더에는 이미지가 포함된 훈련, 검증 및 테스트 하위 폴더가 있습니다.
- 모든 클래스는 이미지 수에서 균형을 이룹니다.
프로젝트 파이프 라인
우리가 다룰 모든 내용을 파악하기 위해 아래에서 자세히 개발된 모델의 다양한 단계를 설명했습니다.
- 환경 설정
- 의존성 가져 오기
- 데이터 세트 읽기 및 로드
- 데이터 변환
- 데이터 시각화
- 텐서보딩
- 모델 빌딩
- 예측 시각화
- 컨벌루션 네트워크 미세 조정
- 교육 및 평가
- 학습된 행렬에 대해 TensorBoard로 보고
- 모델 테스트
- 학습된 모델 아티팩트 저장
- 로컬 배포
- 클라우드에 배포(Streamlit Cloud)
참고: 후속 연습을 위해 특히 컴퓨터에 로컬 GPU나 그래픽 카드가 없는 경우 Google Colab을 사용하여 이 작업을 재현하는 것이 좋습니다. 딥 러닝의 난관은 컴퓨팅 환경인데 무료 GPU를 제공하는 Google Colab 덕분에 어떻게 참여하는지 보여드리겠습니다.
1단계: 환경 설정
더 이상 고민하지 않고 몇 가지 코드 작성을 시작하겠습니다. Google을 사용할 것입니다. 콜랩 개발 환경으로. 이제 온라인에서 Google Colaboratory를 쉽게 검색하거나 https://colab.research.google.com/을 방문할 수 있습니다. jupyter와 동일한 인터페이스를 가지고 있으므로 Google 계정만 있으면 이해하는 데 많은 시간이 걸리지 않습니다. 홈페이지는 아래와 같습니다.

이제 런타임에 추가하여 사용할 수 있는 무료 GPU를 활용해 보겠습니다. 아래와 같이 "런타임" 탭을 클릭하고 "런타임 유형 변경"을 선택합니다.

"Hardware accelerator"에서 드롭다운을 클릭하고 아래와 같이 "GPU"를 선택하십시오!
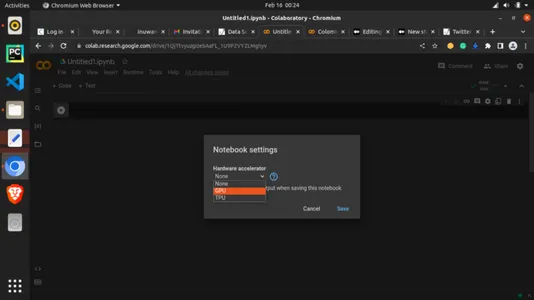
이제 GPU가 연결되었습니다. 이제 코드를 계속 사용할 수 있습니다.
종속성을 가져오기 시작하기 직전에 마지막 작업을 수행해야 합니다. 아래 줄을 사용하여 matplotlib로 플롯을 설정합니다. 이렇게 하면 출력이나 그래프를 구성하는 데 도움이 됩니다.
#magic function for matplotlib graphs. Graphs will be included in notebook next to the code. %matplotlib inline2단계: 종속성 가져오기
#importing dependencies
from __future__ import print_function, division from datetime import datetime
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
from torchvision.datasets import ImageFolder
import torchvision.transforms as T
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import time
import os
import copy plt.ion() # interactive mode3단계: 데이터셋 로딩
이 문서의 끝이나 이 문서와 함께 제공되는 공개 GitHub 리포지토리에서 데이터 세트에 대한 링크를 찾을 수 있습니다. 데이터 세트를 다운로드한 후 쉽게 사용할 수 있도록 Google 드라이브에 업로드할 수 있습니다. 이미 거기에 있고 오른쪽 열에서 드라이버를 로드하고 셀을 실행합니다.
from google.colab import drive
drive.mount('/content/drive')#Dataset from drive DATA_FILE = "/content/drive/MyDrive/MLProjects/dataset/COP"
train_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Train/"
val_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Validation/"참고 : 위 스니펫의 경우 경로를 자신의 Google 드라이브 파일 경로로 바꿔야 합니다.
4단계: 데이터 변환
#changing the format and structure of the data.
data_transforms = { 'Train': transforms.Compose([ transforms.Resize((224, 224)),# resizing the image dimention transforms.RandomHorizontalFlip(),# generating different possible image position transforms.ToTensor(), # tensors are like the data type for deep learning images transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # normalizes the tensor image for each channel regards mean and SD ]), 'Validation': transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'Test': transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]),
} data_dir = DATA_FILE
data_types = ['Train', 'Validation', 'Test'] # grouping into the various sets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in data_types}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in data_types}
dataset_sizes = {x: len(image_datasets[x]) for x in data_types}
class_names = image_datasets['Train'].classes #checking for available processor device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")5단계: 데이터 시각화
데이터 시각화의 도움으로 데이터가 어떻게 보이는지, 이미지에서 무엇을 다루고 있는지 확인할 수 있습니다.
# Reasigning images for visualization
image_size = 300
batch_size = 128
# converting to Tensors for visualization purpose
train_dataset = ImageFolder(data_dir+'/Train', transform=ToTensor())
val_dataset = ImageFolder(data_dir+'/Validation', transform=ToTensor())img, label = val_dataset[13]
print(img.shape, label)
img위의 코드는 인덱스 13에 있는 val_dataset 중 하나의 텐서 버전을 보여줍니다.
def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # Get a batch of training data
inputs, classes = next(iter(dataloaders['Train'])) # Make a grid from batch
out = torchvision.utils.make_grid(inputs) imshow(out, title=[class_names[x] for x in classes])
# attempting to show the image classes and directories
print("List of Directories:", os.listdir(data_dir))
classes = os.listdir(data_dir + "/Train")
print("List of classes:", classes)디렉토리 목록: ['Validation,' 'Test,' 'Train'] 클래스 목록: ['2k', '20k', '50kf', '20kf', '5kf', 'Background', '5k', '50k', '10k', '10kf', '100k', '2kf', '100kf']
# carrying out more visualization
import matplotlib.pyplot as plt def show_example(img, label): print('Label: ', train_dataset.classes[label], "("+str(label)+")") plt.imshow(img.permute(1, 2, 0)) import random
random_value = random.randint(1, 2000)# getting random images
show_example(*train_dataset[2000])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
6단계: 텐서보딩
TensorBoard는 다양한 매개변수가 어떻게 변경되었는지 나중에 시각화할 수 있도록 기계 학습 교육을 수행하는 좋은 방법입니다. 기계 학습 워크플로 중에 측정값의 변화를 시각화로 제공하는 도구입니다. 일종의 파라미터 로깅이라고 볼 수 있습니다. 여기에서 이를 사용하여 마지막 실행에 대한 손실, 정확도 및 이상값을 추적합니다.
코드 입력:
#tensorboard logging
#to track various metrics such as accuracy and log loss on training or validation set
from torch.utils.tensorboard import SummaryWriter TB_DIR = f'runs/exp_{datetime.now().strftime("%Y%m%d-%H%M%S")}' tb_train_writer = SummaryWriter(f'{TB_DIR}/Train')
tb_val_writer = SummaryWriter(f'{TB_DIR}/Validation') %load_ext tensorboard7단계: 모델 구축
이것은 고기가 치즈를 만나는 곳입니다. 아니면 아직은 아닙니다. 나중에 호출할 수 있는 원하는 모든 매개 변수와 설정을 사용하여 도우미 함수를 빌드해 보겠습니다.
코드 입력:
# helper function
def train_model(model, criterion, optimizer, scheduler, num_epochs=4): since = time.time() best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10) # Each epoch has a training and validation phase for phase in ['Train', 'Validation']: if phase == 'Train': model.train() # Set model to training mode else: model.eval() # Set model to evaluate mode running_loss = 0.0 running_corrects = 0 # Iterate over data. for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) labels = labels.to(device) # zero the parameter gradients optimizer.zero_grad() # forward # track history if only in train with torch.set_grad_enabled(phase == 'Train'): outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, labels) # backward + optimize only if in training phase if phase == 'Train': loss.backward() optimizer.step() # statistics running_loss += loss.item() * inputs.size(0) running_corrects += torch.sum(preds == labels.data) if phase == 'Train': scheduler.step() epoch_loss = running_loss / dataset_sizes[phase] epoch_acc = running_corrects.double() / dataset_sizes[phase] if phase == 'Train': tb_writer = tb_train_writer else: tb_writer = tb_val_writer tb_writer.add_scalar(f'Loss', epoch_loss, epoch) tb_writer.add_scalar(f'Accuracy', epoch_acc, epoch) print('{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) # deep copy the model if phase == 'Validation' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format( time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_acc)) tb_train_writer.close() tb_val_writer.close() # load best model weights model.load_state_dict(best_model_wts) return model8단계: 예측 시각화
우리는 여전히 예측을 위한 또 다른 도우미 함수를 작성합니다. 더 간단한 버전의 코드는 이 단계를 건너뛰고 얻은 정확도를 사용할 수 있습니다.
코드 입력:
def visualize_model(model, dataset, num_images=6): was_training = model.training model.eval() images_so_far = 0 fig = plt.figure() with torch.no_grad(): for i, (inputs, labels) in enumerate(dataloaders[dataset]): inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) _, preds = torch.max(outputs, 1) for j in range(inputs.size()[0]): images_so_far += 1 ax = plt.subplot(num_images//2, 2, images_so_far) ax.axis('off') ax.set_title('predicted: {}'.format(class_names[preds[j]])) imshow(inputs.cpu().data[j]) if images_so_far == num_images: model.train(mode=was_training) return model.train(mode=was_training)9단계: Convnet 미세 조정
사전 훈련된 모델을 로드하고 최종 완전 연결 계층을 재설정합니다. 이 방법을 전이 학습이라고 합니다. 매개변수와 관련하여 수행한 설정에 의존하는 대신 이미 훈련된 모델에서 일부 지식을 차용하기로 결정했습니다. 이것은 ResNet18로 알려진 잔여 네트워크입니다.
잔차 네트워크: 딥 러닝은 여러 유형의 인공 신경망으로 구성되며 잔차 신경망이 그 중 하나입니다.
코드 입력:
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to number of classes.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, len(class_names)) model_ft = model_ft.to(device) criterion = nn.CrossEntropyLoss() # Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9) # Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)10단계: 교육 및 평가
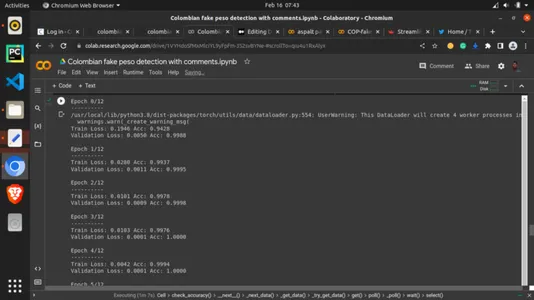
마지막으로 치즈가 고기를 만납니다. 이제 이전 도우미 함수를 호출하고 최선의 실험으로 훈련 매개변수를 할당합니다. 우리는 에포크를 13으로 설정했습니다. 에포크는 단순히 모든 훈련 데이터의 반복 횟수로 훈련 데이터를 한 번에 보는 라운드입니다. 트레이닝 세트가 알고리즘에 대해 취하는 뷰의 수로 볼 수 있습니다. 이것은 확실히 중요합니다. 많을수록 좋지만 모델이 너무 과하게 보이는 상황은 피하고 싶습니다. 13 에포크는 여기에서 13번 수행한다는 것을 의미하지만 다른 더 높은 값과 더 낮은 값으로 실험할 수 있습니다.
코드 입력:
# setting the number of epochs and other key parametersp model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=13)산출:
11단계: 학습된 메트릭에 대한 TensorBoard 표시
코드 입력:
# calling the tensorboard %tensorboard --logdir='./runs'12단계: 학습된 모델 저장
마지막으로 이 article.save 메소드와 PyTorch .pt 확장자에 대한 토치로 모델을 저장합니다. 잠시 기다린 다음 왼쪽 열에서 저장된 모드를 확인하고 마우스 오른쪽 버튼으로 클릭한 다음 다운로드를 선택합니다. 모드가 컴퓨터에 다운로드됩니다. 이것을 아티팩트라고 합니다. 다음 섹션에서 이 아티팩트를 사용할 것입니다.
코드 입력:
torch.save(model_ft, 'model100.pt')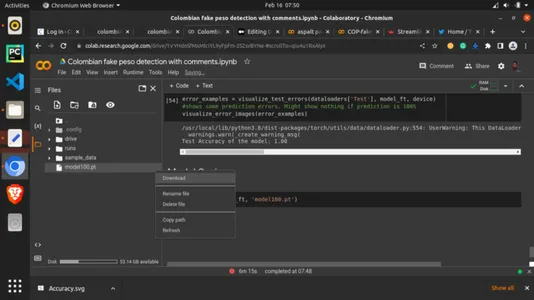
13단계: 저장된 모델을 로컬에 배포
이것은 재미있는 길입니다. 우리는 실시간으로 모델을 보고 GUI로 예측을 하려고 노력할 것입니다. 여기에서 Streamlit 프레임워크용 Python 스크립트를 생성합니다. 코드의 세부 사항은 이 기사와 함께 제공되는 GitHub 저장소에 있습니다. Streamlit은 기계 학습 프레임워크를 로컬 또는 클라우드에 배포하도록 설계된 경량 프레임워크입니다. 로컬을 먼저 본 다음 클라우드 버전을 봅니다. 파일을 생성하고 선택한 코드 편집기에서 python .py 확장자로 저장하고 아래 코드를 작성합니다.
코드 입력:
# importing dependencies
import io
from PIL import Image
import streamlit as st
import torch
from torchvision import transforms
import base64 # setting background
def add_bg_from_local(image_file): with open(image_file, "rb") as image_file: encoded_string = base64.b64encode(image_file.read()) st.markdown( f""" <style> .stApp {{ background-image: url(data:images/{"jpg"};base64,{encoded_string.decode()}); background-size: cover }} </style> """, unsafe_allow_html=True )
add_bg_from_local('images/bg2.jpg') # importing model
MODEL_PATH = 'model/model100.pt'
# importing class names
LABELS_PATH = 'model/model_classes.txt' # image picker
def load_image(): uploaded_file = st.file_uploader(label='Pick a banknote to test') if uploaded_file is not None: image_data = uploaded_file.getvalue() st.image(image_data) return Image.open(io.BytesIO(image_data)) else: return None def load_model(model_path): model = torch.load(model_path, map_location='cpu') model.eval() return model def load_labels(labels_file): with open(labels_file, "r") as f: categories = [s.strip() for s in f.readlines()] return categories def predict(model, categories, image): preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(image) input_batch = input_tensor.unsqueeze(0) with torch.no_grad(): output = model(input_batch) probabilities = torch.nn.functional.softmax(output[0], dim=0) all_prob, all_catid = torch.topk(probabilities, len(categories)) for i in range(all_prob.size(0)): st.write(categories[all_catid[i]], all_prob[i].item()) def main(): st.title('Colombian Pesu banknote Detection') model = load_model(MODEL_PATH) categories = load_labels(LABELS_PATH) image = load_image() result = st.button('Predict image') if result: st.write('Checking...') predict(model, categories, image) if __name__ == '__main__': main()참고 : 모델과 함께 가져온 클래스 파일도 생성해야 합니다. 이렇게 하려면 "model_classes.txt"라는 텍스트 파일을 만듭니다. 이것을 저장한 다음 파이썬 스크립트와 같은 디렉토리에 있는 "모델"이라는 폴더에 모델을 다운로드합니다. 또한 클래스 이름은 학습 방법에 따라 지정해야 합니다. 위의 클래스와 디렉토리를 인쇄한 곳에서 이것을 찾을 수 있습니다. 아래와 같이 모델이 한 줄씩 텍스트 파일을 읽을 것이므로 모든 클래스가 한 줄을 사용하도록 합니다.
Python 스크립트를 실행하려면 패키지가 아직 없는 경우 일부 패키지를 설치해야 합니다. 다음은 저장소에서 찾을 수 있는 종속성입니다.
- 유선형
- 토치
- 횃불
종속 항목을 설치한 후 스크립트가 있는 디렉터리의 터미널에서 실행합니다.
streamlit run filename.py이렇게 하면 앱이 아래와 같이 표시될 것입니다.

14단계: 클라우드에 배포
가까운 사람과 기계 학습 앱을 공유하고 싶을 수도 있습니다. 이는 클라우드 인프라를 통해 수행할 수 있습니다. 리포지토리를 Streamlit Cloud와 연결하려면 작업 디렉터리를 GitHub와 같은 온라인 코드 관리 플랫폼으로 이동해야 합니다. Git을 사용하여 디렉터리를 푸시하고 다음으로 이동합니다. https://streamlit.io/cloud 아래와 같이 홈 화면에서:
가입하고 "시작하기"를 클릭하십시오. 가입해야 합니다. 완전 무료입니다! 가입 후 앱이 있는 GitHub 리포지토리를 선택하고 선택합니다. 앱이 구워지는 동안 배치하고 보류하도록 선택하십시오! 이제 공유를 위해 링크를 복사할 수 있습니다.
결론
Streamlit 커뮤니티 클라우드를 사용하여 아름답고 강력한 기계 학습 제품을 클라우드에 교육, 저장 및 배포할 수 있었습니다. 우리는 또한 100번째 epoch에서 3%의 정확도를 얻었습니다.
주요 테이크 아웃
- 위조 지폐는 은행 부문에서 쉽게 문제가 될 수 있습니다. 이러한 지폐를 식별할 수 있는 것은 우리가 딥 러닝을 사용하여 달성할 수 있었던 작업입니다.
- 우리는 비전문가도 이러한 지폐의 진위를 감지하는 데 사용할 수 있는 자동화된 기계 학습 위조 지폐 감지 모델을 개발했습니다.
- 우리는 100%의 정확도로 손실 및 정확도를 포함한 몇 가지 적절한 평가 지표를 사용했습니다.
- 우리는 딥 러닝을 사용하여 로컬과 클라우드 모두에 모델을 배포했습니다.
참고자료
Pachon Suescun, 세자르; 발레스테로스, 도라 마리아; Renza, Diego (2020), "원본 및 위조 콜롬비아 페소 지폐", Mendeley Data, V1, doi: 10.17632/tj8kvrbfz6.1
링크
공개 GitHub 리포지토리: https://github.com/inuwamobarak/Deep-learning-in-Banking
데이터 세트 : https://data.mendeley.com/datasets/tj8kvrbfz6/1
합리화: https://streamlit.io/
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/02/deep-learning-in-banking-colombian-peso-banknote-detection/

