Introduction
In today’s ever-advancing world of technology, there’s an exciting development on the horizon – Advanced Multi-modal Generative AI. This cutting-edge technology is about making computers more innovative and great, creating content and understanding. Imagine a digital assistant that seamlessly works with text, images, and sounds and generates information. In this article, we’ll look at how this technology functions in its real-time/practical applications and examples and even provide simplified code snippets to make it all available and understandable. So, let’s dive in and explore the world of Advanced Multimodal Generative AI.

In the following sections, we will unravel the core modules of Multimodal AI, from Input to Fusion and Output, gaining a clearer understanding of how they collaborate to make this technology function seamlessly. Additionally, we’ll explore practical code examples that illustrate its capabilities and real-world use cases. Advanced Multimodal Generative AI is a leap toward a more interactive, creative, and efficient digital era where machines understand and communicate with us in ways we’ve imagined.
Learning Objectives
- Understand the basics of Advanced Multimodal Generative AI in simple terms.
- Explore how Multimodal AI functions through its Input, Fusion, and Output Modules.
- Gain insights into the inner workings of Multimodal AI with practical code examples.
- Discovering the real-world applications of Multimodal AI with real-world use cases.
- Differentiate between Single-Modal and Multi-Modal AI and their capabilities.
- Delve into the these when deploying Multimodal AI in real-world scenarios.
This article was published as a part of the Data Science Blogathon.
Table of contents
Understanding Advanced Multimodal Generative AI
Imagine having a robot friend, Robbie, who’s incredibly smart and can understand you in many number of different ways. When you want to tell Robbie a funny story about your day at the beach, you can choose to speak to him, draw a art/picture, or even show him a photo. Then Robbie able to understand/get your words, pictures, and more. This ability to understand and use different ways to communicate and comprehend is the essence of “Multimodal.”
How does Multimodal AI Work?
Multimodal AI is designed to understand and generate content in different data modes like text, images, and audio. It achieves this by three key modules.

- Input Module
- Fusion Module
- Output Module
Let’s delve into these modules to understand how Multimodal AI works.
Input Module
The Input Module is like the door where different data types are entered. Here’s what it does:
- Text Data: It looks at words and phrases and how they relate in sentences, like understanding language.
- Image Data: It checks pictures and figures out what’s in them, like objects, scenes, or patterns.
- Audio Data: It listens to sounds and turns them into words so AI can understand.
The Input Module takes all these data and turns them into a language AI can understand. It finds the critical stuff and gets it ready for the next step.
Fusion Module
The Fusion Module is where things come together.
- Text-Image Fusion: It puts together words and pictures. This helps us understand the terms and what’s in the pictures, making it all make sense.
- Text-Audio Fusion: With sounds It makes up the words. This helps catch things like how someone’s talking or the mood, which you miss with just the sound.
- Image-Audio Fusion: This part connects what you see with what you hear. It’s handy for describing what’s happening or making stuff like videos more relaxed.
The Fusion Module makes by putting all this information together and making it easier to get.
Output Module
The Output Module is like the talk-back part. It says stuff based on what it learned. Here’s how:
- Text Generation: It uses words to make sentences, from answering questions to making up fantastic stories.
- Image Generation: It makes pictures that match what’s happening, like scenes or things.
- Speech Generation: It talks back using words and sounds like a natural person, so it’s easy to understand.
The Output Module ensures AI’s answers are accurate and make sense with what it hears.
In a nutshell, Multimodal AI puts together data from different places in the Input Module, gets the big picture in the Fusion Module, and says stuff that fits with what it learned in the Output Module. This helps AI understand and talk to us better, no matter what data it gets.
# Import the Multimodal AI library
from multimodal_ai import MultimodalAI # Initialize the Multimodal AI model
model = MultimodalAI() # Input data for each modality
text_data = "A cat chasing a ball."
image_data = load_image("cat_chasing_ball.jpg")
audio_data = load_audio("cat_sound.wav") # Process each modality separately
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Combine information from different modalities
combined_embedding = model.combine_modalities(text_embedding, image_embedding, audio_embedding) # Generate a response based on the combined information
response = model.generate_response(combined_embedding) # Print the generated response
print(response)
In this code, shows how Multimodal AI can process and combine information from many different modalities to generate a meaningful response. It’s a simplified example to help you understand the concept without unnecessary complexity.
The Inner Working
Are you curious to understand the inner workings? Let’s look at the various segments of it:

Multimodal Inputs
Inputs can be text, images, audio, or even these models can accept a combination of these. This is achieved by processing each modality through dedicated sub-networks while allowing interactions between them.
from multimodal_generative_ai import MultiModalModel # Initialize a Multi-Modal Model
model = MultiModalModel() # Input data in the form of text, image, and audio
text_data = "A beautiful sunset at the beach."
image_data = load_image("beach_sunset.jpg")
audio_data = load_audio("ocean_waves.wav") # Process each modality through dedicated sub-networks
text_embedding = model.process_text(text_data)
image_embedding = model.process_image(image_data)
audio_embedding = model.process_audio(audio_data) # Allow interactions between modalities
output = model.generate_multi_modal_output(text_embedding, image_embedding, audio_embedding)In this code, we develop a Multi-Modal Model capable of handling diverse inputs like text, images, and audio.
Cross-Modal Understanding
One of the key features is the model’s ability to understand relationships between different modalities. For example, it can describe an image based on a textual description or generate relevant images from a text format.
from multimodal_generative_ai import CrossModalModel # Initialize a Cross-Modal Model
model = CrossModalModel() # Input textual description and image
description = "A cabin in the snowy woods."
image_data = load_image("snowy_cabin.jpg") # Generating text based on the image
generated_text = model.generate_text_from_image(image_data)
generated_image = model.generate_image_from_text(description)In this code, we work with a Cross-Modal Model that excels in understanding and generating content across different modalities. Like as it can describe an image based on a textual input like “A cabin in the snowy woods.” Alternatively, it can generate an image from a textual description, making it a very important tool for tasks like image captioning or content creation.
Contextual Awareness
These AI systems excel at capturing context. They understand nuances and can generate content that’s contextually relevant. This contextual awareness is precious in content generation and recommendation systems tasks.
from multimodal_generative_ai import ContextualModel # Initialize a Contextual Model
model = ContextualModel() # Input contextual data
context = "In a bustling city street, people rush to respective homes." # Generate contextually relevant content
generated_content = model.generate_contextual_content(context)This code showcases a Contextual Model designed to capture context effectively. It takes input like context = “In a bustling city street, people rush to respective homes.” and generates content that aligns with the provided context. This ability to produce contextually relevant content is useful in tasks like content generation and recommendation systems, where understanding the context is crucial for generating appropriate responses.
Training Data
These models should require multimodal training data and also the training data should be heavy and more. This includes text paired with images, audio paired with video, and other combinations, allowing the model to learn meaningful cross-modal representations.
from multimodal_generative_ai import MultiModalTrainer # Initialize a Multi-Modal Trainer
trainer = MultiModalTrainer() # Load multimodal training data (text paired with images, audio paired with video, etc.)
training_data = load_multi_modal_data() # Train the Multi-Modal Model
model = trainer.train_model(training_data)This code example showcases a Multi-Modal Trainer that facilitates the training of a Multi-Modal Model using diverse training data.
Real-World Applications
Advanced Multimodal Generative AI has a large amount need and helps in many of practical uses in many number of different fields. Let’s explore some simple examples of how this technology can be applied, along with code snippets and explanations.
Content Generation
Imagine a system that can create content like articles, images, and even audio based on a brief description. This can be a game-changer for content production, advertising, and creative industries. Here’s a code snippet:
from multimodal_generative_ai import ContentGenerator # Initialize the Content Generator
generator = ContentGenerator() # Input a description
description = "A beautiful sunset at the beach." # Generate content
generated_text = generator.generate_text(description)
generated_image = generator.generate_image(description)
generated_audio = generator.generate_audio(description)In this example, the Content Generator takes a description as input and generates text, images, and audio content related to that description.
Assistive Healthcare
In healthcare, multimodal AI can analyse patient past, present data , including text, medical images, and audio notes and combination of these three. It can assist in diagnosing diseases, creating treatment plans, and even predict patient future outcome by taking all relevant data.
from multimodal_generative_ai import HealthcareAssistant # Initialize the Healthcare Assistant
assistant = HealthcareAssistant() # Input a patient record
patient_record = { "text": "Patient complains of persistent cough and fatigue.", "images": ["xray1.jpg", "mri_scan.jpg"], "audio_notes": ["heartbeat.wav", "breathing_pattern.wav"]
} # Analyze the patient record
diagnosis = assistant.diagnose(patient_record)
treatment_plan = assistant.create_treatment_plan(patient_record)
predicted_outcome = assistant.predict_outcome(patient_record)This code shows how the Healthcare Assistant can process a patient’s record, combining text, images, and audio to assist in medical diagnosis and treatment planning.
Interactive Chatbots
Chatbots have become more engaging and helpful with Multimodal AI capabilities. They can understand both text and images, making interactions with users more natural and effective. Here’s a code snippet:
from multimodal_generative_ai import Chatbot # Initialize the Chatbot
chatbot = Chatbot() # User input
user_message = "Show me images of cute cats." # Engage with the user
response = chatbot.interact(user_message)This code shows how the Chatbot, powered by Multimodal AI, can respond effectively to user input that includes both text and image requests.
Content Moderation
Multimodal AI can improve the detection and moderation of inappropriate content on online platforms by analyzing both text and visual or auditory elements. Here’s a code snippet:
from multimodal_generative_ai import ContentModerator # Initialize the Content Moderator
moderator = ContentModerator() # User-generated content
user_content = { "text": "Inappropriate text message.", "image": "inappropriate_image.jpg", "audio": "offensive_audio.wav"
} # Moderate the user-generated content
moderated = moderator.moderate_content(user_content)In this example, the Content Moderator can analyze user-generated content, ensuring a safer online environment by taking into consider of all multiple modalities.
These practical examples illustrate the real-world applications of Advanced Multimodal Generative AI. This technology has the potential in many number of industries by understanding and generating content across different modes of data.
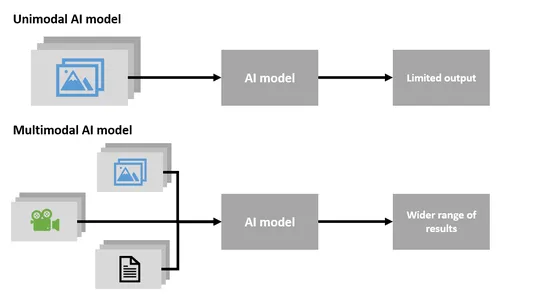
Single-Modal Vs Multi-Modal

Multi-Modal AI
- Multi-Modal AI is a very unique and important technology that can handle different types of data simultaneously, including text, images, and audio.
- It excels at understanding and generating content that combines these diverse data types.
- Multi-Modal AI can generate text based on images or create images from text descriptions, making it highly adaptable.
- This technology is capable of processing and making sense of a vide range of information.
Single-Modal AI
- Single-Modal AI specializes in working with only one type of data, such as text or images.
- It cannot handle multiple data types simultaneously or generate content that combines different modalities.
- Single-Modal AI is limited to its specific data type and lacks the adaptability of Multi-Modal AI.
In summary, Multi-Modal AI can work with multiple types of data at once, making it more versatile and capable of understanding and generating content in various ways. Single-Modal AI, on the other hand, specializes in one data type and cannot handle the diversity of Multi-Modal AI.
Ethical Considerations
Privacy Concerns
- Ensure proper handling of sensitive user data, particularly in healthcare applications.
- Implement robust data encryption and anonymisation techniques to protect user privacy.
Bias and Fairness
- Address potential biases in the training data to prevent unfair outcomes.
- Regularly audit and update the model to minimise biases in content generation.
Content Moderation
- Deploy effective content moderation to filter out inappropriate or harmful content generated by AI.
- Establish clear guidelines and policies for users to adhere to ethical standards.
Transparency
- Make AI-generated content distinguishable from human-generated content to maintain transparency.
- Provide clear information to users about the involvement of AI in content creation.
Accountability
- Define responsibilities for the use and deployment of Multimodal AI, ensuring accountability for its actions.
- Establish mechanisms for addressing issues or errors that may arise from AI-generated content.
Informed Consent
- Seek user consent when collecting and utilizing their data for training and improving the AI model.
- Clearly communicate how user data will be used to build trust with users.
Accessibility
- Ensure that AI-generated content is accessible to users with disabilities by adhering to accessibility standards.
- Implement features like screen readers for visually impaired users.
Continuous Monitoring
- Regularly monitor AI-generated content for compliance with ethical guidelines.
- Adapt and refine the AI model to align with evolving ethical standards.
These ethical considerations are essential for the responsible development and deployment of Advanced Multimodal Generative AI, ensuring it benefits society while upholding ethical standards and user rights.
Conclusion
As we navigated the complex landscape of modern technology, the horizon beckons with a fascinating development: Advanced Multimodal Generative AI. This groundbreaking technology promises to revolutionise the way computers generate content and understand our multifaceted world. Picture a digital assistant seamlessly working with text, images, and sounds, communicating in multiple languages and crafting innovative content. I hope this article takes you on a journey through the intricacies of Advanced Multimodal Generative AI, exploring its practical applications, code snippets for clarity, and its potential to reshape our digital interactions.
“Multimodal AI is the bridge that helps computers understand and process text, images, and audio, revolutionising how we interact with machines.”
Key Takeaways
- Advanced Multimodal Generative AI is a game-changer in technology, enabling computers to understand and generate content across text, images, and audio.
- The three core modules, Input, Fusion, and Output, work seamlessly together to process and generate information effectively.
- Multimodal AI can find applications in content generation, healthcare assistance, interactive chatbots, and content moderation, making it versatile and practical.
- Cross-modal understanding, contextual awareness, and extensive training data are pivotal aspects that enhance its capabilities.
- Multimodal AI has the potential to revolutionise industries by offering a new way of interacting with machines and generating content more creatively.
- Its ability to combine multiple data modes enhances its adaptability and real-world usability.
Frequently Asked Questions
A. Advanced Multimodal Generative AI stands out by its capability to understand and generate content using various data types, such as text, images, and audio, while traditional AI often focuses on one data type.
A. Advanced Multimodal Generative AI distinguishes itself by its capacity to understand and generate content using diverse data types, including text, images, and audio, whereas traditional AI typically specialises in a single data type.
A. Multimodal AI adeptly operates in multiple languages by processing and comprehending text in the desired language.
A. Yes, Multimodal AI is capable of producing creative content based on textual descriptions or prompts, encompassing text, images, and audio.
A. Multimodal AI offers benefits across a wide array of domains, including content generation, healthcare, chatbots, and content moderation, owing to its proficiency in understanding and generating content across diverse data modes.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2023/10/exploring-the-advanced-multi-modal-generative-ai/

