Daten sind Ihr generatives KI-Unterscheidungsmerkmal und ein Erfolgsfaktor generative KI Die Umsetzung hängt von einer robusten Datenstrategie ab, die eine umfassende Datenstrategie beinhaltet Data Governance Ansatz. Die Arbeit mit großen Sprachmodellen (LLMs) für Unternehmensanwendungsfälle erfordert die Umsetzung von Qualitäts- und Datenschutzaspekten, um eine verantwortungsvolle KI voranzutreiben. Unternehmensdaten, die aus isolierten Quellen generiert werden, und das Fehlen einer Datenintegrationsstrategie führen jedoch zu Herausforderungen bei der Bereitstellung der Daten für generative KI-Anwendungen. Die Notwendigkeit einer End-to-End-Lösung Strategie für das Datenmanagement und Daten-Governance in jedem Schritt der Reise – von der Erfassung, Speicherung und Abfrage von Daten bis hin zur Analyse, Visualisierung und Ausführung von Modellen für künstliche Intelligenz (KI) und maschinelles Lernen (ML) – ist für Unternehmen weiterhin von größter Bedeutung.
In diesem Beitrag diskutieren wir die Daten-Governance-Anforderungen generativer KI-Anwendungsdatenpipelines, einem entscheidenden Baustein zur Steuerung der von LLMs verwendeten Daten, um die Genauigkeit und Relevanz ihrer Antworten auf Benutzeraufforderungen auf sichere und transparente Weise zu verbessern. Unternehmen tun dies, indem sie proprietäre Daten mit Ansätzen wie Retrieval Augmented Generation (RAG), Feinabstimmung und fortlaufendem Vortraining mit Basismodellen nutzen.
Data Governance ist bei all diesen Ansätzen ein entscheidender Baustein, und wir sehen zwei neue Schwerpunktbereiche. Erstens basieren viele LLM-Anwendungsfälle auf Unternehmenswissen, das zusätzlich zu strukturierten Daten aus Data Warehouses auch aus unstrukturierten Daten wie Dokumenten, Transkripten und Bildern gewonnen werden muss. Unstrukturierte Daten werden in der Regel in isolierten Systemen in unterschiedlichen Formaten gespeichert und im Allgemeinen nicht mit der gleichen Genauigkeit verwaltet oder verwaltet wie strukturierte Daten. Zweitens führen generative KI-Anwendungen zu einer höheren Anzahl von Dateninteraktionen als herkömmliche Anwendungen, was erfordert, dass die Datensicherheits-, Datenschutz- und Zugriffskontrollrichtlinien als Teil der generativen KI-Benutzerworkflows implementiert werden.
In diesem Beitrag behandeln wir die Datenverwaltung für die Erstellung generativer KI-Anwendungen auf AWS mit Blick auf strukturierte und unstrukturierte Unternehmenswissensquellen sowie die Rolle der Datenverwaltung während der Anforderungs-/Antwort-Workflows der Benutzer.
Anwendungsfallübersicht
Sehen wir uns ein Beispiel eines KI-Assistenten für den Kundensupport an. Die folgende Abbildung zeigt den typischen Konversationsworkflow, der mit einer Benutzeraufforderung initiiert wird.

Der Workflow umfasst die folgenden wichtigen Schritte zur Datenverwaltung:
- Schnelle Benutzerzugriffskontrolle und Sicherheitsrichtlinien.
- Greifen Sie auf Richtlinien zu, um Berechtigungen basierend auf relevanten Daten zu extrahieren und Ergebnisse basierend auf der Rolle und den Berechtigungen des Eingabeaufforderungsbenutzers herauszufiltern.
- Setzen Sie Datenschutzrichtlinien durch, z. B. die Schwärzung personenbezogener Daten (PII).
- Setzen Sie eine differenzierte Zugriffskontrolle durch.
- Gewähren Sie der Benutzerrolle Berechtigungen für vertrauliche Informationen und Compliance-Richtlinien.
Um eine Antwort bereitzustellen, die den Unternehmenskontext einschließt, muss jede Benutzeraufforderung durch eine Kombination aus Erkenntnissen aus strukturierten Daten aus dem Data Warehouse und unstrukturierten Daten aus dem Enterprise Data Lake ergänzt werden. Im Backend müssen die Batch-Data-Engineering-Prozesse, die den Enterprise Data Lake aktualisieren, erweitert werden, um unstrukturierte Daten aufzunehmen, zu transformieren und zu verwalten. Im Rahmen der Transformation müssen die Objekte behandelt werden, um den Datenschutz zu gewährleisten (z. B. PII-Schwärzung). Schließlich müssen Zugriffskontrollrichtlinien auch auf die unstrukturierten Datenobjekte ausgeweitet werden Vektordatenspeicher.
Sehen wir uns an, wie Data Governance auf die Datenpipelines der Wissensquellen des Unternehmens und die Anforderungs-/Antwort-Workflows der Benutzer angewendet werden kann.
Unternehmenswissen: Datenmanagement
Die folgende Abbildung fasst Überlegungen zur Datengovernance für Datenpipelines und den Workflow für die Anwendung der Datengovernance zusammen.
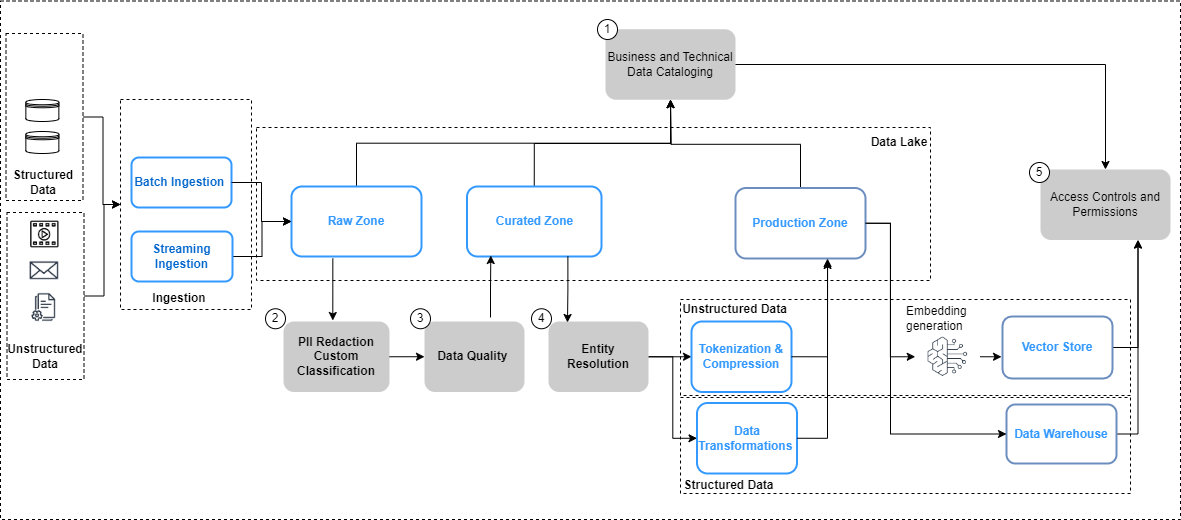
In der obigen Abbildung umfassen die Data-Engineering-Pipelines die folgenden Data-Governance-Schritte:
- Erstellen und aktualisieren Sie einen Katalog durch Datenentwicklung.
- Implementieren Sie Datenschutzrichtlinien.
- Implementieren Sie Datenqualität nach Datentyp und -quelle.
- Verknüpfen Sie strukturierte und unstrukturierte Datensätze.
- Implementieren Sie einheitliche, differenzierte Zugriffskontrollen für strukturierte und unstrukturierte Datensätze.
Schauen wir uns einige der wichtigsten Änderungen in den Datenpipelines genauer an, nämlich Datenkatalogisierung, Datenqualität und Vektoreinbettungssicherheit.
Auffindbarkeit von Daten
Im Gegensatz zu strukturierten Daten, die in klar definierten Zeilen und Spalten verwaltet werden, werden unstrukturierte Daten als Objekte gespeichert. Damit Benutzer die Daten entdecken und verstehen können, besteht der erste Schritt darin, einen umfassenden Katalog mithilfe der Metadaten zu erstellen, die in den Quellsystemen generiert und erfasst werden. Dies beginnt damit, dass die Objekte (z. B. Dokumente und Transkriptdateien) aus den relevanten Quellsystemen in die Rohzone im aufgenommen werden Daten See in Amazon Simple Storage-Service (Amazon S3) in ihren jeweiligen nativen Formaten (wie in der vorherigen Abbildung dargestellt). Von hier aus werden Objektmetadaten (z. B. Dateieigentümer, Erstellungsdatum und Vertraulichkeitsstufe) erfasst extrahiert und mithilfe von Amazon S3-Funktionen abgefragt. Metadaten können je nach Datenquelle variieren. Daher ist es wichtig, die Felder zu untersuchen und bei Bedarf die erforderlichen Felder abzuleiten, um alle erforderlichen Metadaten zu vervollständigen. Wenn beispielsweise ein Attribut wie die Vertraulichkeit von Inhalten nicht auf Dokumentebene in der Quellanwendung gekennzeichnet ist, muss dies möglicherweise im Rahmen des Metadatenextraktionsprozesses abgeleitet und als Attribut im Datenkatalog hinzugefügt werden. Der Aufnahmeprozess muss neben neuen Objekten fortlaufend auch Objektaktualisierungen (Änderungen, Löschungen) erfassen. Ausführliche Anleitungen zur Implementierung finden Sie unter Unstrukturierte Datenverwaltung und Governance mithilfe von AWS AI/ML und Analysediensten. Um die Entdeckung und Selbstbeobachtung zwischen Geschäftsglossaren und technischen Datenkatalogen weiter zu vereinfachen, können Sie Folgendes verwenden: Amazon DataZone Damit Geschäftsanwender über Datensilos hinweg gespeicherte Daten entdecken und teilen können.
Datenschutz
Unternehmenswissensquellen enthalten häufig personenbezogene Daten und andere sensible Daten (z. B. Adressen und Sozialversicherungsnummern). Basierend auf Ihren Datenschutzrichtlinien müssen diese Elemente aus den Quellen behandelt (maskiert, tokenisiert oder redigiert) werden, bevor sie für nachgelagerte Anwendungsfälle verwendet werden können. Aus der Rohzone in Amazon S3 müssen die Objekte verarbeitet werden, bevor sie von nachgelagerten generativen KI-Modellen genutzt werden können. Eine zentrale Anforderung hierbei ist Identifizierung und Schwärzung personenbezogener Daten, die Sie mit umsetzen können Amazon verstehen. Es ist wichtig zu bedenken, dass es nicht immer möglich sein wird, alle sensiblen Daten zu entfernen, ohne den Kontext der Daten zu beeinträchtigen. Semantischer Kontext ist einer der Schlüsselfaktoren, die die Genauigkeit und Relevanz generativer KI-Modellausgaben bestimmen, und es ist wichtig, vom Anwendungsfall aus rückwärts zu arbeiten und das notwendige Gleichgewicht zwischen Datenschutzkontrollen und Modellleistung zu finden.
Datenanreicherung
Darüber hinaus müssen möglicherweise zusätzliche Metadaten aus den Objekten extrahiert werden. Amazon Comprehend bietet Funktionen für Unternehmenserkennung (z. B. Identifizierung domänenspezifischer Daten wie Policennummern und Anspruchsnummern) und benutzerdefinierte Klassifizierung (z. B. Kategorisieren eines Kundenbetreuungs-Chat-Transkripts basierend auf der Problembeschreibung). Darüber hinaus müssen Sie möglicherweise die unstrukturierten und strukturierten Daten kombinieren, um ein ganzheitliches Bild wichtiger Einheiten wie Kunden zu erstellen. Beispielsweise wäre es in einem Loyalitätsszenario einer Fluggesellschaft von großem Nutzen, die unstrukturierte Datenerfassung von Kundeninteraktionen (z. B. Kunden-Chat-Transkripte und Kundenbewertungen) mit strukturierten Datensignalen (z. B. Ticketkäufen und Meileneinlösung) zu verknüpfen, um ein umfassenderes Szenario zu schaffen Kundenprofil, das dann die Bereitstellung besserer und relevanterer Reiseempfehlungen ermöglichen kann. AWS-Entitätsauflösung ist ein ML-Dienst, der beim Abgleichen und Verknüpfen von Datensätzen hilft. Dieser Dienst hilft dabei, zusammengehörige Informationssätze zu verknüpfen, um tiefere, besser vernetzte Daten über wichtige Entitäten wie Kunden, Produkte usw. zu erstellen, was die Qualität und Relevanz der LLM-Ergebnisse weiter verbessern kann. Dies ist in der transformierten Zone in Amazon S3 verfügbar und kann nachgelagert für Vektorspeicher, Feinabstimmung oder Training von LLMs genutzt werden. Nach diesen Transformationen können Daten in der kuratierten Zone in Amazon S3 verfügbar gemacht werden.
Datenqualität
Ein entscheidender Faktor für die Ausschöpfung des vollen Potenzials der generativen KI hängt von der Qualität der Daten ab, die zum Trainieren der Modelle verwendet werden, sowie der Daten, die zur Erweiterung und Verbesserung der Modellreaktion auf Benutzereingaben verwendet werden. Das Verständnis der Modelle und ihrer Ergebnisse im Kontext von Genauigkeit, Verzerrung und Zuverlässigkeit ist direkt proportional zur Qualität der Daten, die zum Erstellen und Trainieren der Modelle verwendet werden.
Amazon SageMaker-Modellmonitor Bietet eine proaktive Erkennung von Abweichungen in der Drift der Modelldatenqualität und der Drift der Modellqualitätsmetriken. Außerdem wird die Bias-Drift in den Vorhersagen und der Merkmalszuordnung Ihres Modells überwacht. Weitere Einzelheiten finden Sie unter Überwachung von ML-Modellen in der Produktion in großem Maßstab mit Amazon SageMaker Model Monitor. Das Erkennen von Verzerrungen in Ihrem Modell ist ein grundlegender Baustein für eine verantwortungsvolle KI Amazon SageMaker klären hilft dabei, potenzielle Verzerrungen zu erkennen, die zu einem negativen oder weniger genauen Ergebnis führen können. Weitere Informationen finden Sie unter Erfahren Sie, wie Amazon SageMaker Clarify dabei hilft, Voreingenommenheit zu erkennen.
Ein neuerer Schwerpunkt der generativen KI ist die Verwendung und Qualität von Daten in Eingabeaufforderungen aus Unternehmens- und proprietären Datenspeichern. Eine aufkommende Best Practice, die hier berücksichtigt werden sollte, ist nach links verschieben, das einen starken Schwerpunkt auf frühzeitige und proaktive Qualitätssicherungsmechanismen legt. Im Kontext von Datenpipelines, die zur Verarbeitung von Daten für generative KI-Anwendungen konzipiert sind, bedeutet dies, dass Datenqualitätsprobleme früher im Vorfeld erkannt und gelöst werden, um die möglichen Auswirkungen von Datenqualitätsproblemen später abzumildern. AWS Glue-Datenqualität misst und überwacht nicht nur die Qualität Ihrer ruhenden Daten in Ihren Data Lakes, Data Warehouses und Transaktionsdatenbanken, sondern ermöglicht auch die frühzeitige Erkennung und Korrektur von Qualitätsproblemen für Ihre Extraktions-, Transformations- und Ladepipelines (ETL), um Ihre Daten sicherzustellen erfüllt die Qualitätsstandards, bevor es verzehrt wird. Weitere Einzelheiten finden Sie unter Erste Schritte mit AWS Glue Data Quality aus dem AWS Glue Data Catalog.
Vector-Store-Governance
Einbettungen in Vektordatenbanken Erhöhen Sie die Intelligenz und Fähigkeiten generativer KI-Anwendungen, indem Sie Funktionen wie die semantische Suche ermöglichen und Halluzinationen reduzieren. Einbettungen enthalten typischerweise private und sensible Daten und die Verschlüsselung der Daten ist ein empfohlener Schritt im Benutzereingabe-Workflow. Amazon OpenSearch ohne Server speichert und durchsucht Ihre Vektoreinbettungen und verschlüsselt Ihre Daten im Ruhezustand mit AWS-Schlüsselverwaltungsservice (AWS KMS). Weitere Einzelheiten finden Sie unter Wir stellen die Vektor-Engine für Amazon OpenSearch Serverless vor, jetzt in der Vorschau. Ebenso zusätzliche Vektor-Engine-Optionen auf AWS, einschließlich Amazon Kendra und Amazonas-Aurora, verschlüsseln Sie Ihre Daten im Ruhezustand mit AWS KMS. Weitere Informationen finden Sie unter Verschlüsselung in Ruhe und Daten durch Verschlüsselung schützen.
Da Einbettungen generiert und in einem Vektorspeicher gespeichert werden, wird die Kontrolle des Zugriffs auf die Daten mit rollenbasierter Zugriffskontrolle (RBAC) zu einer wichtigen Voraussetzung für die Aufrechterhaltung der Gesamtsicherheit. Amazon OpenSearch-Dienst bietet Fein abgestimmte Zugangskontrollen (FGAC) Funktionen mit AWS Identity and Access Management and (IAM)-Regeln, denen zugeordnet werden kann Amazon Cognito Benutzer. Entsprechende Mechanismen zur Benutzerzugriffskontrolle werden ebenfalls bereitgestellt von Serverlos mit OpenSearch, Amazon Kendra, und Aurora. Weitere Informationen finden Sie unter Datenzugriffskontrolle für Amazon OpenSearch Serverless, Steuern des Benutzerzugriffs auf Dokumente mit Token und Identitäts- und Zugriffsverwaltung für Amazon Aurora, Bzw.
Benutzeranfrage-Antwort-Workflows
Kontrollen auf der Data-Governance-Ebene müssen als Teil des Gesamtkonzepts in die generative KI-Anwendung integriert werden Lösungsbereitstellung um die Einhaltung der Richtlinien zur Datensicherheit (basierend auf rollenbasierten Zugriffskontrollen) und Datenschutz (basierend auf rollenbasiertem Zugriff auf sensible Daten) sicherzustellen. Die folgende Abbildung veranschaulicht den Arbeitsablauf für die Anwendung von Data Governance.
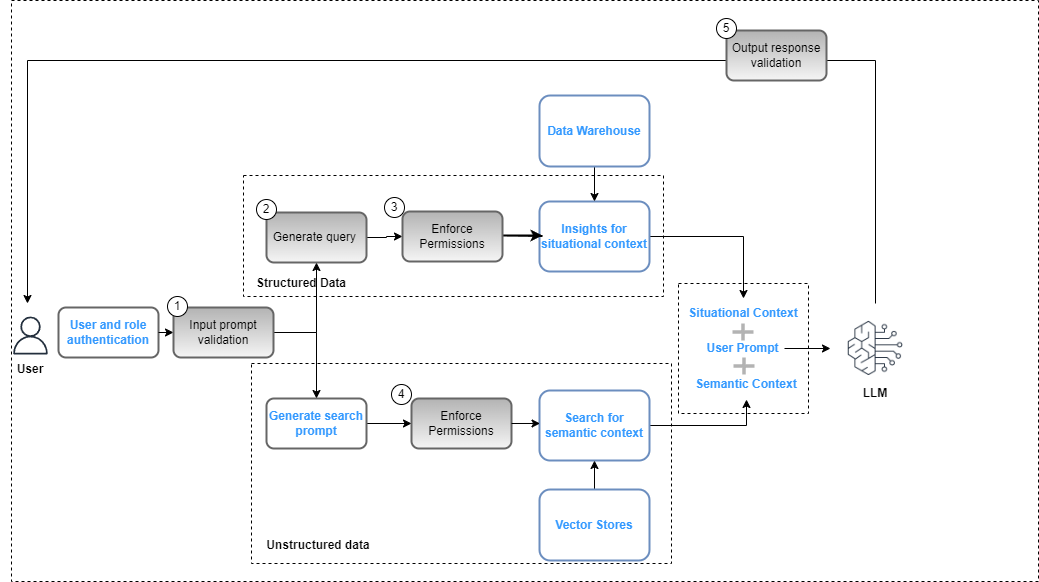
Der Workflow umfasst die folgenden wichtigen Schritte zur Datenverwaltung:
- Stellen Sie eine gültige Eingabeaufforderung zur Abstimmung mit Compliance-Richtlinien bereit (z. B. Voreingenommenheit und Toxizität).
- Generieren Sie eine Abfrage, indem Sie Eingabeaufforderungsschlüsselwörter dem Datenkatalog zuordnen.
- Wenden Sie FGAC-Richtlinien basierend auf der Benutzerrolle an.
- Wenden Sie RBAC-Richtlinien basierend auf der Benutzerrolle an.
- Wenden Sie Daten- und Inhaltsschwärzung auf die Antwort an, basierend auf Benutzerrollenberechtigungen und Compliance-Richtlinien.
Als Teil des Eingabeaufforderungszyklus muss die Benutzeraufforderung analysiert und Schlüsselwörter extrahiert werden, um die Übereinstimmung mit Compliance-Richtlinien mithilfe eines Dienstes wie Amazon Comprehend sicherzustellen (siehe). Neu für Amazon Comprehend – Toxizitätserkennungoder Leitplanken für Amazon Bedrock (Vorschau). Wenn dies validiert ist und die Eingabeaufforderung die Extraktion strukturierter Daten erfordert, können die Schlüsselwörter für den Datenkatalog (geschäftlich oder technisch) verwendet werden, um die relevanten Datentabellen und -felder zu extrahieren und eine Abfrage aus dem Data Warehouse zu erstellen. Die Benutzerberechtigungen werden mit ausgewertet AWS Lake-Formation um die relevanten Daten zu filtern. Bei unstrukturierten Daten werden die Suchergebnisse basierend auf den im Vector Store implementierten Benutzerberechtigungsrichtlinien eingeschränkt. Als letzten Schritt muss die Ausgabeantwort des LLM anhand der Benutzerberechtigungen (um Datenschutz und Sicherheit zu gewährleisten) und der Einhaltung von Sicherheitsbestimmungen (z. B. Bias- und Toxizitätsrichtlinien) bewertet werden.
Obwohl dieser Prozess spezifisch für eine RAG-Implementierung ist und auf andere LLM-Implementierungsstrategien anwendbar ist, gibt es zusätzliche Kontrollen:
- Schnelles Engineering – Der Zugriff auf die aufzurufenden Eingabeaufforderungsvorlagen muss basierend auf eingeschränkt werden Zugangskontrollen ergänzt durch Geschäftslogik.
- Modelle verfeinern und Grundlagenmodelle trainieren – In Fällen, in denen Objekte aus der kuratierten Zone in Amazon S3 als Trainingsdaten zur Feinabstimmung der Grundmodelle verwendet werden, müssen die Berechtigungsrichtlinien konfiguriert werden Amazon S3 Identitäts- und Zugriffsverwaltung auf Bucket- oder Objektebene basierend auf den Anforderungen.
Zusammenfassung
Data Governance ist von entscheidender Bedeutung, um Unternehmen in die Lage zu versetzen, generative KI-Anwendungen für Unternehmen zu erstellen. Da sich Unternehmensanwendungsfälle ständig weiterentwickeln, wird es notwendig sein, die Dateninfrastruktur zu erweitern, um neue, vielfältige, unstrukturierte Datensätze zu verwalten und zu verwalten und so die Übereinstimmung mit Datenschutz-, Sicherheits- und Qualitätsrichtlinien sicherzustellen. Diese Richtlinien müssen im Rahmen der Datenerfassung, -speicherung und -verwaltung der Wissensdatenbank des Unternehmens zusammen mit den Benutzerinteraktionsworkflows implementiert und verwaltet werden. Dadurch wird sichergestellt, dass die generativen KI-Anwendungen nicht nur das Risiko der Weitergabe ungenauer oder falscher Informationen minimieren, sondern auch vor Voreingenommenheit und Toxizität schützen, die zu schädlichen oder verleumderischen Ergebnissen führen können. Weitere Informationen zur Datenverwaltung in AWS finden Sie unter Was ist Data Governance?
In nachfolgenden Beiträgen werden wir Implementierungsanleitungen zur Erweiterung der Governance der Dateninfrastruktur zur Unterstützung generativer KI-Anwendungsfälle bereitstellen.
Über die Autoren
 Krishna Rupanagunta leitet ein Team von Daten- und KI-Spezialisten bei AWS. Er und sein Team arbeiten mit Kunden zusammen, um ihnen dabei zu helfen, mithilfe von Daten, Analysen und KI/ML schneller Innovationen zu entwickeln und bessere Entscheidungen zu treffen. Er ist über LinkedIn erreichbar.
Krishna Rupanagunta leitet ein Team von Daten- und KI-Spezialisten bei AWS. Er und sein Team arbeiten mit Kunden zusammen, um ihnen dabei zu helfen, mithilfe von Daten, Analysen und KI/ML schneller Innovationen zu entwickeln und bessere Entscheidungen zu treffen. Er ist über LinkedIn erreichbar.
 Imtiaz (Taz) sagte ist WW Tech Leader für Analytics bei AWS. Er genießt es, sich mit der Community zu allen Themen rund um Daten und Analysen auszutauschen. Er ist über LinkedIn erreichbar.
Imtiaz (Taz) sagte ist WW Tech Leader für Analytics bei AWS. Er genießt es, sich mit der Community zu allen Themen rund um Daten und Analysen auszutauschen. Er ist über LinkedIn erreichbar.
 Raghvender Arni (Arni) leitet das Customer Acceleration Team (CAT) innerhalb von AWS Industries. Das CAT ist ein globales, funktionsübergreifendes Team aus kundenorientierten Cloud-Architekten, Software-Ingenieuren, Datenwissenschaftlern sowie KI/ML-Experten und -Designern, das Innovationen durch fortschrittliches Prototyping vorantreibt und die operative Exzellenz der Cloud durch spezialisiertes technisches Fachwissen vorantreibt.
Raghvender Arni (Arni) leitet das Customer Acceleration Team (CAT) innerhalb von AWS Industries. Das CAT ist ein globales, funktionsübergreifendes Team aus kundenorientierten Cloud-Architekten, Software-Ingenieuren, Datenwissenschaftlern sowie KI/ML-Experten und -Designern, das Innovationen durch fortschrittliches Prototyping vorantreibt und die operative Exzellenz der Cloud durch spezialisiertes technisches Fachwissen vorantreibt.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

