Để xây dựng bất kỳ ứng dụng AI tổng quát nào, việc làm phong phú các mô hình ngôn ngữ lớn (LLM) bằng dữ liệu mới là điều bắt buộc. Đây là lúc kỹ thuật Tạo tăng cường truy xuất (RAG) xuất hiện. RAG là kiến trúc máy học (ML) sử dụng các tài liệu bên ngoài (như Wikipedia) để nâng cao kiến thức và đạt được kết quả tiên tiến trong các nhiệm vụ đòi hỏi nhiều kiến thức . Để sử dụng các nguồn dữ liệu bên ngoài này, cơ sở dữ liệu Vector đã phát triển, có thể lưu trữ các phần nhúng vectơ của nguồn dữ liệu và cho phép tìm kiếm sự tương đồng.
Trong bài đăng này, chúng tôi trình bày cách xây dựng quy trình nhập liệu trích xuất, chuyển đổi và tải (ETL) RAG để nhập một lượng lớn dữ liệu vào một Dịch vụ Tìm kiếm Mở của Amazon phân cụm và sử dụng Dịch vụ cơ sở dữ liệu quan hệ của Amazon (Amazon RDS) dành cho PostgreSQL với phần mở rộng pgvector làm kho lưu trữ dữ liệu vector. Mỗi dịch vụ triển khai thuật toán k-láng giềng gần nhất (k-NN) hoặc xấp xỉ lân cận gần nhất (ANN) và số liệu khoảng cách để tính toán độ tương tự. Chúng tôi giới thiệu sự tích hợp của cá đuối vào cơ chế truy xuất tài liệu theo ngữ cảnh RAG. Ray là một thư viện máy tính phân tán, mã nguồn mở, Python, có mục đích chung. Nó cho phép xử lý dữ liệu phân tán để tạo và lưu trữ các phần nhúng cho một lượng lớn dữ liệu, song song trên nhiều GPU. Chúng tôi sử dụng cụm Ray với các GPU này để chạy truy vấn và nhập song song cho từng dịch vụ.
Trong thử nghiệm này, chúng tôi cố gắng phân tích các khía cạnh sau đối với Dịch vụ OpenSearch và tiện ích mở rộng pgvector trên Amazon RDS:
- Là một kho lưu trữ vectơ, khả năng mở rộng quy mô và xử lý tập dữ liệu lớn với hàng chục triệu bản ghi cho RAG
- Những tắc nghẽn có thể xảy ra trong đường dẫn vào của RAG
- Cách đạt được hiệu suất tối ưu về thời gian nhập và truy xuất truy vấn cho Dịch vụ OpenSearch và Amazon RDS
Để hiểu thêm về kho dữ liệu vector và vai trò của chúng trong việc xây dựng các ứng dụng AI tổng hợp, hãy tham khảo Vai trò của kho dữ liệu vector trong các ứng dụng AI tổng quát.
Tổng quan về Dịch vụ OpenSearch
Dịch vụ OpenSearch là một dịch vụ được quản lý để phân tích, tìm kiếm và lập chỉ mục an toàn cho dữ liệu hoạt động và kinh doanh. Dịch vụ OpenSearch hỗ trợ dữ liệu ở quy mô petabyte với khả năng tạo nhiều chỉ mục trên dữ liệu văn bản và vectơ. Với cấu hình được tối ưu hóa, nó nhằm mục đích thu hồi cao cho các truy vấn. Dịch vụ OpenSearch hỗ trợ ANN cũng như tìm kiếm k-NN chính xác. Dịch vụ OpenSearch hỗ trợ lựa chọn các thuật toán từ NMSLIB, THẤT BẠIvà Lucene các thư viện hỗ trợ tìm kiếm k-NN. Chúng tôi đã tạo chỉ mục ANN cho OpenSearch bằng thuật toán Thế giới nhỏ có thể điều hướng theo cấp bậc (HNSW) vì thuật toán này được coi là phương pháp tìm kiếm tốt hơn cho các tập dữ liệu lớn. Để biết thêm thông tin về việc lựa chọn thuật toán chỉ mục, hãy tham khảo Chọn thuật toán k-NN cho trường hợp sử dụng quy mô hàng tỷ của bạn với OpenSearch.
Tổng quan về Amazon RDS cho PostgreSQL với pgvector
Tiện ích mở rộng pgvector thêm tính năng tìm kiếm tương tự vectơ nguồn mở vào PostgreSQL. Bằng cách sử dụng tiện ích mở rộng pgvector, PostgreSQL có thể thực hiện tìm kiếm tương tự trên các phần nhúng vectơ, cung cấp cho doanh nghiệp giải pháp nhanh chóng và hiệu quả. pgvector cung cấp hai loại tìm kiếm tương tự vectơ: hàng xóm gần nhất chính xác, cho kết quả thu hồi 100% và hàng xóm gần nhất gần đúng (ANN), cung cấp hiệu suất tốt hơn tìm kiếm chính xác với sự đánh đổi khi thu hồi. Đối với các tìm kiếm trên một chỉ mục, bạn có thể chọn số lượng trung tâm sẽ sử dụng trong tìm kiếm, với nhiều trung tâm hơn mang lại khả năng gợi nhớ tốt hơn với sự đánh đổi về hiệu suất.
Tổng quan về giải pháp
Sơ đồ sau minh họa kiến trúc giải pháp.

Chúng ta hãy xem xét các thành phần chính chi tiết hơn.
Bộ dữ liệu
Chúng tôi sử dụng dữ liệu OSCAR làm kho dữ liệu và bộ dữ liệu SQUAD để cung cấp các câu hỏi mẫu. Những bộ dữ liệu này lần đầu tiên được chuyển đổi thành tệp Parquet. Sau đó, chúng tôi sử dụng cụm Ray để chuyển đổi dữ liệu Parquet thành phần nhúng. Các phần nhúng đã tạo sẽ được đưa vào Dịch vụ OpenSearch và Amazon RDS bằng pgvector.
OSCAR (Khối liệu tổng hợp được thu thập thông tin siêu lớn mở) là một kho ngữ liệu đa ngôn ngữ khổng lồ có được bằng cách phân loại và lọc ngôn ngữ của Thu thập thông tin chung kho văn bản bằng cách sử dụng không ổn định ngành kiến trúc. Dữ liệu được phân phối theo ngôn ngữ ở cả dạng gốc và loại bỏ trùng lặp. Bộ dữ liệu Oscar Corpus có khoảng 609 triệu bản ghi và chiếm khoảng 4.5 TB dưới dạng tệp JSONL thô. Sau đó, các tệp JSONL được chuyển đổi sang định dạng Parquet, giúp giảm thiểu tổng kích thước xuống còn 1.8 TB. Chúng tôi tiếp tục thu nhỏ tập dữ liệu xuống còn 25 triệu bản ghi để tiết kiệm thời gian trong quá trình nhập.
SQuAD (Bộ dữ liệu trả lời câu hỏi của Stanford) là một tập dữ liệu về đọc hiểu bao gồm các câu hỏi do nhân viên đám đông đặt ra trên một tập hợp các bài viết trên Wikipedia, trong đó câu trả lời cho mọi câu hỏi là một đoạn văn bản hoặc nhịp cầu, từ đoạn đọc tương ứng, nếu không câu hỏi có thể không thể trả lời được. Chúng tôi sử dụng VÒI, được cấp phép như CC-BY-SA 4.0, để cung cấp các câu hỏi mẫu. Nó có khoảng 100,000 câu hỏi với hơn 50,000 câu hỏi không thể trả lời được viết bởi những người làm việc trong đám đông để trông giống với những câu hỏi có thể trả lời được.
Cụm tia để nhập và tạo các phần nhúng vector
Trong thử nghiệm của mình, chúng tôi nhận thấy rằng GPU có tác động lớn nhất đến hiệu suất khi tạo các phần nhúng. Do đó, chúng tôi quyết định sử dụng cụm Ray để chuyển đổi văn bản thô của mình và tạo các phần nhúng. cá đuối là một khung tính toán thống nhất mã nguồn mở cho phép các kỹ sư ML và nhà phát triển Python mở rộng quy mô ứng dụng Python và tăng tốc khối lượng công việc ML. Cụm của chúng tôi bao gồm 5 g4dn.12xlarge Đám mây điện toán đàn hồi Amazon (Amazon EC2). Mỗi phiên bản được cấu hình với 4 GPU NVIDIA T4 Tensor Core, 48 vCPU và 192 GiB bộ nhớ. Đối với các bản ghi văn bản của chúng tôi, cuối cùng chúng tôi đã chia từng phần thành 1,000 phần với phần chồng lên nhau là 100 phần. Con số này tăng lên khoảng 200 cho mỗi bản ghi. Đối với mô hình được sử dụng để tạo phần nhúng, chúng tôi đã giải quyết tất cả-mpnet-base-v2 để tạo không gian vectơ 768 chiều.
Thiết lập cơ sở hạ tầng
Chúng tôi đã sử dụng các loại phiên bản RDS và cấu hình cụm dịch vụ OpenSearch sau đây để thiết lập cơ sở hạ tầng của mình.
Sau đây là các thuộc tính loại phiên bản RDS của chúng tôi:
- Loại phiên bản: db.r7g.12xlarge
- Dung lượng được phân bổ: 20 TB
- Đa AZ: Đúng
- Bộ nhớ được mã hóa: Đúng
- Bật thông tin chi tiết về hiệu suất: Đúng
- Thời gian lưu giữ Thông tin chi tiết về hiệu suất: 7 ngày
- Loại lưu trữ: gp3
- IOPS được cung cấp: 64,000
- Loại chỉ số: IVF
- Số lượng danh sách: 5,000
- Hàm khoảng cách: L2
Sau đây là các thuộc tính cụm Dịch vụ OpenSearch của chúng tôi:
- Version: 2.5
- Nút dữ liệu: 10
- Loại phiên bản nút dữ liệu: r6g.4xlarge
- Nút chính: 3
- Loại phiên bản nút chính: r6g.xlarge
- Mục lục: Động cơ HNSW:
nmslib - Khoảng thời gian làm mới: 30 giây
ef_construction: 256- m: 16
- Hàm khoảng cách: L2
Chúng tôi đã sử dụng các cấu hình lớn cho cả cụm Dịch vụ OpenSearch và phiên bản RDS để tránh mọi tắc nghẽn về hiệu suất.
Chúng tôi triển khai giải pháp bằng cách sử dụng Bộ công cụ phát triển đám mây AWS (AWS CDK) ngăn xếp, như được trình bày ở phần sau.
Triển khai ngăn xếp AWS CDK
Ngăn xếp CDK AWS cho phép chúng tôi chọn Dịch vụ OpenSearch hoặc Amazon RDS để nhập dữ liệu.
Điều kiện tiên quyết
Trước khi tiếp tục cài đặt, trong cdk, bin, src.tc, hãy thay đổi các giá trị Boolean cho Amazon RDS và OpenSearch Service thành true hoặc false tùy theo sở thích của bạn.
Bạn cũng cần một dịch vụ liên kết Quản lý truy cập và nhận dạng AWS (IAM) cho miền Dịch vụ OpenSearch. Để biết thêm chi tiết, hãy tham khảo Thư viện xây dựng dịch vụ Amazon OpenSearch. Bạn cũng có thể chạy lệnh sau để tạo vai trò:
Ngăn xếp CDK AWS này sẽ triển khai cơ sở hạ tầng sau:
- VPC
- Máy chủ nhảy (bên trong VPC)
- Cụm Dịch vụ OpenSearch (nếu sử dụng dịch vụ OpenSearch để nhập)
- Phiên bản RDS (nếu sử dụng Amazon RDS để nhập)
- An Người quản lý hệ thống AWS tài liệu triển khai cụm Ray
- An Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) nhóm
- An Keo AWS công việc chuyển đổi các tệp JSONL của tập dữ liệu OSCAR thành các tệp Parquet
- amazoncloudwatch trang tổng quan
Tải xuống dữ liệu
Chạy các lệnh sau từ máy chủ nhảy:
Trước khi sao chép kho git, hãy đảm bảo bạn có hồ sơ Ôm khuôn mặt và quyền truy cập vào kho dữ liệu OSCAR. Bạn cần sử dụng tên người dùng và mật khẩu để sao chép dữ liệu OSCAR:
Chuyển đổi tệp JSONL sang Parquet
Ngăn xếp AWS CDK đã tạo công việc AWS Glue ETL oscar-jsonl-parquet để chuyển đổi dữ liệu OSCAR từ JSONL sang định dạng Parquet.
Sau khi bạn chạy oscar-jsonl-parquet công việc, các tệp ở định dạng Parquet sẽ có sẵn trong thư mục parquet trong nhóm S3.
Tải xuống các câu hỏi
Từ máy chủ nhảy của bạn, hãy tải xuống dữ liệu câu hỏi và tải nó lên bộ chứa S3 của bạn:
Thiết lập cụm Ray
Là một phần của quá trình triển khai ngăn xếp CDK AWS, chúng tôi đã tạo một tài liệu Trình quản lý hệ thống có tên CreateRayCluster.
Để chạy tài liệu, hãy hoàn thành các bước sau:
- Trên bảng điều khiển Systems Manager, bên dưới Tài liệu trong ngăn điều hướng, chọn Thuộc sở hữu của tôi.
- Mở
CreateRayClustertài liệu. - Chọn chạy.
Trang lệnh chạy sẽ có các giá trị mặc định được điền cho cụm.
Cấu hình mặc định yêu cầu 5 g4dn.12xlarge. Đảm bảo tài khoản của bạn có giới hạn để hỗ trợ việc này. Giới hạn dịch vụ liên quan là Chạy theo yêu cầu phiên bản G và VT. Mặc định cho điều này là 64, nhưng cấu hình này yêu cầu 240 CPUS.
- Sau khi bạn xem lại cấu hình cụm, hãy chọn máy chủ nhảy làm mục tiêu cho lệnh chạy.
Lệnh này sẽ thực hiện các bước sau:
- Sao chép các tập tin cụm Ray
- Thiết lập cụm Ray
- Thiết lập chỉ mục Dịch vụ OpenSearch
- Thiết lập bảng RDS
Bạn có thể giám sát đầu ra của các lệnh trên bảng điều khiển Systems Manager. Quá trình này sẽ mất 10–15 phút cho lần khởi chạy đầu tiên.
Chạy nhập
Từ máy chủ nhảy, kết nối với cụm Ray:
Lần đầu kết nối với máy chủ, cài đặt yêu cầu. Những tập tin này đã có sẵn trên nút đầu.
Đối với một trong hai phương thức nhập, nếu bạn gặp lỗi như sau thì lỗi đó có liên quan đến thông tin xác thực đã hết hạn. Cách giải quyết hiện tại (tại thời điểm viết bài này) là đặt các tệp thông tin xác thực vào nút đầu Ray. Để tránh rủi ro bảo mật, không sử dụng người dùng IAM để xác thực khi phát triển phần mềm chuyên dụng hoặc làm việc với dữ liệu thực. Thay vào đó, hãy sử dụng liên kết với nhà cung cấp danh tính như Trung tâm nhận dạng AWS IAM (kế thừa AWS Single Sign-On).
Thông thường, thông tin xác thực được lưu trữ trong tệp ~/.aws/credentials trên hệ thống Linux và macOS, và %USERPROFILE%.awscredentials trên Windows, nhưng đây là những thông tin xác thực ngắn hạn có mã thông báo phiên. Bạn cũng không thể ghi đè tệp thông tin xác thực mặc định và do đó, bạn cần tạo thông tin xác thực dài hạn mà không cần mã thông báo phiên bằng cách sử dụng người dùng IAM mới.
Để tạo thông tin xác thực dài hạn, bạn cần tạo khóa truy cập AWS và khóa truy cập bí mật AWS. Bạn có thể làm điều đó từ bảng điều khiển IAM. Để biết hướng dẫn, hãy tham khảo Xác thực bằng thông tin đăng nhập của người dùng IAM.
Sau khi bạn tạo khóa, hãy kết nối với máy chủ nhảy bằng cách sử dụng Quản lý phiên, khả năng của Trình quản lý hệ thống và chạy lệnh sau:
Bây giờ bạn có thể chạy lại các bước nhập.
Nhập dữ liệu vào Dịch vụ OpenSearch
Nếu bạn đang sử dụng dịch vụ OpenSearch, hãy chạy tập lệnh sau để nhập tệp:
Khi hoàn tất, hãy chạy tập lệnh chạy truy vấn mô phỏng:
Nhập dữ liệu vào Amazon RDS
Nếu bạn đang sử dụng Amazon RDS, hãy chạy tập lệnh sau để nhập tệp:
Khi quá trình hoàn tất, hãy đảm bảo chạy chân không hoàn toàn trên phiên bản RDS.
Sau đó chạy tập lệnh sau để chạy truy vấn mô phỏng:
Thiết lập bảng điều khiển Ray
Trước khi thiết lập bảng điều khiển Ray, bạn nên cài đặt Giao diện dòng lệnh AWS (AWS CLI) trên máy cục bộ của bạn. Để biết hướng dẫn, hãy tham khảo Cài đặt hoặc cập nhật phiên bản mới nhất của AWS CLI.
Hoàn tất các bước sau để thiết lập trang tổng quan:
- cài đặt Plugin quản lý phiên cho AWS CLI.
- Trong tài khoản Isengard, sao chép thông tin đăng nhập tạm thời cho bash/zsh và chạy trong thiết bị đầu cuối cục bộ của bạn.
- Tạo tệp session.sh trong máy của bạn và sao chép nội dung sau vào tệp:
- Thay đổi thư mục nơi lưu trữ tệp session.sh này.
- Chạy lệnh
Chmod +xđể cấp quyền thực thi cho tập tin. - Chạy lệnh sau:
Ví dụ:
Bạn sẽ thấy một thông báo như sau:
Mở một tab mới trong trình duyệt của bạn và nhập localhost:8265.
Bạn sẽ thấy bảng điều khiển Ray và số liệu thống kê về các công việc và cụm đang chạy. Bạn có thể theo dõi số liệu từ đây.
Ví dụ: bạn có thể sử dụng bảng điều khiển Ray để quan sát tải trên cụm. Như minh họa trong ảnh chụp màn hình sau, trong quá trình nhập, GPU đang hoạt động ở mức sử dụng gần 100%.
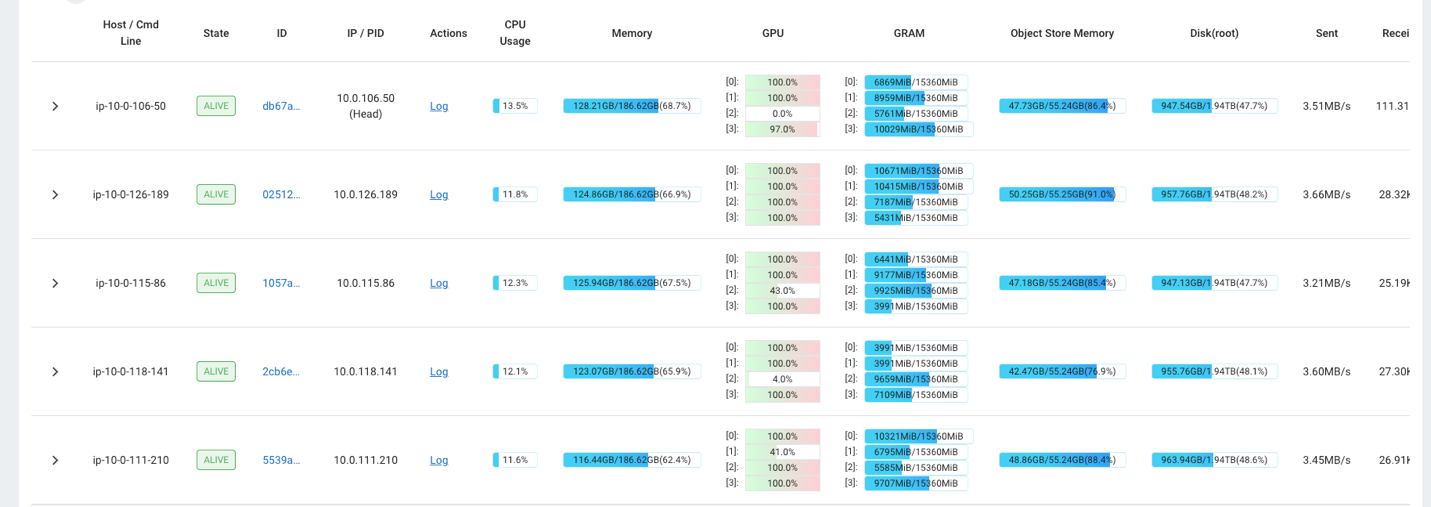
Bạn cũng có thể sử dụng RAG_Benchmarks Trang tổng quan CloudWatch để xem tốc độ nhập và thời gian phản hồi truy vấn.
Khả năng mở rộng của giải pháp
Bạn có thể mở rộng giải pháp này để cắm vào các cửa hàng vectơ AWS hoặc bên thứ ba khác. Đối với mỗi cửa hàng vectơ mới, bạn sẽ cần tạo tập lệnh để định cấu hình kho lưu trữ dữ liệu cũng như nhập dữ liệu. Phần còn lại của đường ống có thể được tái sử dụng khi cần thiết.
Kết luận
Trong bài đăng này, chúng tôi đã chia sẻ một quy trình ETL mà bạn có thể sử dụng để đưa dữ liệu RAG được vector hóa vào cả Dịch vụ OpenSearch cũng như Amazon RDS với phần mở rộng pgvector làm kho dữ liệu vectơ. Giải pháp đã sử dụng cụm Ray để cung cấp khả năng song song cần thiết để sử dụng một kho dữ liệu lớn. Bạn có thể sử dụng phương pháp này để tích hợp bất kỳ cơ sở dữ liệu vectơ nào bạn chọn để xây dựng đường dẫn RAG.
Về các tác giả
 Randy DeFauw là Kiến trúc sư giải pháp chính cấp cao tại AWS. Anh ấy có bằng MSEE của Đại học Michigan, nơi anh ấy nghiên cứu về thị giác máy tính cho xe tự hành. Ông cũng có bằng MBA của Đại học Bang Colorado. Randy đã đảm nhiệm nhiều vị trí khác nhau trong lĩnh vực công nghệ, từ kỹ thuật phần mềm đến quản lý sản phẩm. Anh ấy bước vào không gian dữ liệu lớn vào năm 2013 và tiếp tục khám phá lĩnh vực đó. Anh ấy đang tích cực thực hiện các dự án trong không gian ML và đã trình bày tại nhiều hội nghị, bao gồm Strata và GlueCon.
Randy DeFauw là Kiến trúc sư giải pháp chính cấp cao tại AWS. Anh ấy có bằng MSEE của Đại học Michigan, nơi anh ấy nghiên cứu về thị giác máy tính cho xe tự hành. Ông cũng có bằng MBA của Đại học Bang Colorado. Randy đã đảm nhiệm nhiều vị trí khác nhau trong lĩnh vực công nghệ, từ kỹ thuật phần mềm đến quản lý sản phẩm. Anh ấy bước vào không gian dữ liệu lớn vào năm 2013 và tiếp tục khám phá lĩnh vực đó. Anh ấy đang tích cực thực hiện các dự án trong không gian ML và đã trình bày tại nhiều hội nghị, bao gồm Strata và GlueCon.
 David Christian là Kiến trúc sư Giải pháp Chính có trụ sở tại Nam California. Anh ấy có bằng cử nhân về An toàn thông tin và có niềm đam mê với tự động hóa. Các lĩnh vực trọng tâm của anh là văn hóa và chuyển đổi DevOps, cơ sở hạ tầng dưới dạng mã và khả năng phục hồi. Trước khi gia nhập AWS, ông giữ các vai trò trong lĩnh vực bảo mật, DevOps và kỹ thuật hệ thống, quản lý môi trường đám mây riêng và công cộng quy mô lớn.
David Christian là Kiến trúc sư Giải pháp Chính có trụ sở tại Nam California. Anh ấy có bằng cử nhân về An toàn thông tin và có niềm đam mê với tự động hóa. Các lĩnh vực trọng tâm của anh là văn hóa và chuyển đổi DevOps, cơ sở hạ tầng dưới dạng mã và khả năng phục hồi. Trước khi gia nhập AWS, ông giữ các vai trò trong lĩnh vực bảo mật, DevOps và kỹ thuật hệ thống, quản lý môi trường đám mây riêng và công cộng quy mô lớn.
 Prachi Kulkarni là Kiến trúc sư giải pháp cấp cao tại AWS. Chuyên môn của cô là học máy và cô đang tích cực nghiên cứu thiết kế các giải pháp sử dụng nhiều dịch vụ AWS ML, dữ liệu lớn và phân tích. Prachi có kinh nghiệm trong nhiều lĩnh vực, bao gồm chăm sóc sức khỏe, phúc lợi, bán lẻ và giáo dục, đồng thời đã làm việc ở nhiều vị trí khác nhau về kỹ thuật và kiến trúc sản phẩm, quản lý cũng như thành công của khách hàng.
Prachi Kulkarni là Kiến trúc sư giải pháp cấp cao tại AWS. Chuyên môn của cô là học máy và cô đang tích cực nghiên cứu thiết kế các giải pháp sử dụng nhiều dịch vụ AWS ML, dữ liệu lớn và phân tích. Prachi có kinh nghiệm trong nhiều lĩnh vực, bao gồm chăm sóc sức khỏe, phúc lợi, bán lẻ và giáo dục, đồng thời đã làm việc ở nhiều vị trí khác nhau về kỹ thuật và kiến trúc sản phẩm, quản lý cũng như thành công của khách hàng.
 Richa Gupta là Kiến trúc sư giải pháp tại AWS. Cô ấy đam mê kiến trúc các giải pháp trọn gói cho khách hàng. Chuyên môn của cô là học máy và cách sử dụng nó để xây dựng các giải pháp mới giúp vận hành xuất sắc và thúc đẩy doanh thu kinh doanh. Trước khi gia nhập AWS, cô đã làm việc với tư cách là Kỹ sư phần mềm và Kiến trúc sư giải pháp, xây dựng giải pháp cho các nhà khai thác viễn thông lớn. Ngoài công việc, cô thích khám phá những địa điểm mới và yêu thích các hoạt động mạo hiểm.
Richa Gupta là Kiến trúc sư giải pháp tại AWS. Cô ấy đam mê kiến trúc các giải pháp trọn gói cho khách hàng. Chuyên môn của cô là học máy và cách sử dụng nó để xây dựng các giải pháp mới giúp vận hành xuất sắc và thúc đẩy doanh thu kinh doanh. Trước khi gia nhập AWS, cô đã làm việc với tư cách là Kỹ sư phần mềm và Kiến trúc sư giải pháp, xây dựng giải pháp cho các nhà khai thác viễn thông lớn. Ngoài công việc, cô thích khám phá những địa điểm mới và yêu thích các hoạt động mạo hiểm.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

