Giới thiệu
Mô hình ngôn ngữ lớn (LLM) và Generative AI đại diện cho một bước đột phá mang tính biến đổi trong Trí tuệ nhân tạo và Xử lý ngôn ngữ tự nhiên. Chúng có thể hiểu và tạo ra ngôn ngữ của con người cũng như tạo ra nội dung như văn bản, hình ảnh, âm thanh và dữ liệu tổng hợp, khiến chúng trở nên rất linh hoạt trong nhiều ứng dụng khác nhau. AI sáng tạo có tầm quan trọng to lớn trong các ứng dụng trong thế giới thực bằng cách tự động hóa và tăng cường tạo nội dung, cá nhân hóa trải nghiệm người dùng, hợp lý hóa quy trình làm việc và thúc đẩy sự sáng tạo. Trong bài đọc này, chúng tôi sẽ tập trung vào cách Doanh nghiệp có thể tích hợp với LLM mở bằng cách căn cứ các lời nhắc một cách hiệu quả bằng cách sử dụng Sơ đồ tri thức doanh nghiệp.
Mục tiêu học tập
- Thu thập kiến thức về Nối đất và xây dựng nhanh chóng trong khi tương tác với hệ thống LLM/Gen-AI.
- Hiểu được mức độ liên quan của Nối đất đối với Doanh nghiệp, giá trị kinh doanh khi tích hợp với các hệ thống Gen-AI mở bằng một ví dụ.
- Phân tích hai biểu đồ kiến thức giải pháp nối đất chính và các kho lưu trữ Vector trên nhiều mặt trận khác nhau và tìm hiểu xem cái nào phù hợp khi nào.
- Nghiên cứu một thiết kế doanh nghiệp mẫu về nền tảng và xây dựng nhanh chóng, tận dụng các biểu đồ tri thức, mô hình hóa dữ liệu học tập và mô hình hóa biểu đồ trong JAVA để đưa ra đề xuất được cá nhân hóa cho khách hàng.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Mô hình Ngôn ngữ Lớn là gì?
Mô hình ngôn ngữ lớn là mô hình AI tiên tiến được đào tạo bằng cách sử dụng các kỹ thuật học sâu trên số lượng lớn văn bản|dữ liệu phi cấu trúc. Những mô hình này có khả năng tương tác với ngôn ngữ của con người, tạo ra văn bản, hình ảnh và âm thanh giống con người và thực hiện nhiều chức năng khác nhau. xử lý ngôn ngữ tự nhiên nhiệm vụ.
Ngược lại, định nghĩa của mô hình ngôn ngữ đề cập đến việc gán xác suất cho các chuỗi từ dựa trên phân tích ngữ liệu văn bản. Một mô hình ngôn ngữ có thể thay đổi từ các mô hình n-gram đơn giản đến các mô hình mạng thần kinh phức tạp hơn. Tuy nhiên, thuật ngữ “mô hình ngôn ngữ lớn” thường đề cập đến các mô hình sử dụng kỹ thuật deep learning và có số lượng tham số lớn, có thể dao động từ hàng triệu đến hàng tỷ. Những mô hình này có thể nắm bắt các mẫu phức tạp trong ngôn ngữ và tạo ra văn bản thường không thể phân biệt được với văn bản do con người viết.
Lời nhắc là gì?
Lời nhắc đối với bất kỳ LLM nào hoặc hệ thống AI chatbot tương tự là thông tin đầu vào hoặc tin nhắn dựa trên văn bản mà bạn cung cấp để bắt đầu cuộc trò chuyện hoặc tương tác với AI. LLM rất linh hoạt, được đào tạo với nhiều loại dữ liệu lớn và có thể được sử dụng cho nhiều nhiệm vụ khác nhau; do đó, bối cảnh, phạm vi, chất lượng và sự rõ ràng của lời nhắc của bạn ảnh hưởng đáng kể đến phản hồi bạn nhận được từ hệ thống LLM.
Nối đất/RAG là gì?
Nối đất, Thế hệ tăng cường truy xuất AKA (RAG), trong bối cảnh xử lý LLM ngôn ngữ tự nhiên, đề cập đến việc làm phong phú lời nhắc bằng ngữ cảnh, siêu dữ liệu bổ sung và phạm vi mà chúng tôi cung cấp cho LLM để cải thiện và truy xuất các phản hồi chính xác và phù hợp hơn. Kết nối này giúp hệ thống AI hiểu và diễn giải dữ liệu theo cách phù hợp với phạm vi và bối cảnh cần thiết. Nghiên cứu về LLM cho thấy chất lượng phản hồi của họ phụ thuộc vào chất lượng của lời nhắc.
Đây là một khái niệm cơ bản trong AI, vì nó thu hẹp khoảng cách giữa dữ liệu thô và khả năng xử lý và diễn giải dữ liệu đó của AI theo cách phù hợp với hiểu biết của con người và bối cảnh trong phạm vi. Nó nâng cao chất lượng và độ tin cậy của hệ thống AI cũng như khả năng cung cấp thông tin hoặc phản hồi chính xác và hữu ích.
Hạn chế của LLM là gì?
Mô hình ngôn ngữ lớn (LLM), như GPT-3, đã thu hút được sự chú ý và sử dụng đáng kể trong nhiều ứng dụng khác nhau, nhưng chúng cũng có một số nhược điểm hoặc hạn chế. Một số nhược điểm chính của LLM bao gồm:
1. Thiên vị và Công bằng: LLM thường kế thừa các thành kiến từ dữ liệu huấn luyện. Điều này có thể dẫn đến việc tạo ra nội dung thiên vị hoặc phân biệt đối xử, có thể củng cố những định kiến có hại và duy trì những thành kiến hiện có.
2. Ảo giác: LLM không thực sự hiểu nội dung họ tạo ra; họ tạo ra văn bản dựa trên các mẫu trong dữ liệu huấn luyện. Điều này có nghĩa là chúng có thể tạo ra thông tin thực tế không chính xác hoặc vô nghĩa, khiến chúng không phù hợp cho các ứng dụng quan trọng như chẩn đoán y tế hoặc tư vấn pháp lý.
3. Tài nguyên tính toán: Việc đào tạo và chạy LLM đòi hỏi nguồn lực tính toán khổng lồ, bao gồm phần cứng chuyên dụng như GPU và TPU. Điều này làm cho chúng tốn kém để phát triển và duy trì.
4. Bảo mật và bảo mật dữ liệu: LLM có thể tạo ra nội dung giả mạo có sức thuyết phục, bao gồm văn bản, hình ảnh và âm thanh. Điều này gây rủi ro cho quyền riêng tư và bảo mật dữ liệu vì chúng có thể bị khai thác để tạo nội dung lừa đảo hoặc mạo danh cá nhân.
5. Mối quan tâm về đạo đức: Việc sử dụng LLM trong các ứng dụng khác nhau, chẳng hạn như deepfake hoặc tạo nội dung tự động, đặt ra câu hỏi về đạo đức về khả năng sử dụng sai mục đích và tác động đến xã hội của chúng.
6. Những thách thức về quy định: Sự phát triển nhanh chóng của công nghệ LLM đã vượt xa các khung pháp lý, khiến việc thiết lập các hướng dẫn và quy định phù hợp nhằm giải quyết các rủi ro và thách thức tiềm ẩn liên quan đến LLM trở nên khó khăn.
Điều quan trọng cần lưu ý là nhiều nhược điểm trong số này không phải là cố hữu của LLM mà phản ánh cách chúng được phát triển, triển khai và sử dụng. Những nỗ lực đang được thực hiện để giảm thiểu những hạn chế này và làm cho LLM có trách nhiệm hơn và mang lại lợi ích cho xã hội. Đây là nơi nền tảng và mặt nạ có thể được tận dụng và mang lại lợi thế rất lớn cho Doanh nghiệp.
Sự liên quan của doanh nghiệp đối với việc nối đất
Các doanh nghiệp phát triển mạnh mẽ để đưa Mô hình ngôn ngữ lớn (LLM) vào các ứng dụng quan trọng của họ. Họ hiểu giá trị tiềm năng mà LLM có thể mang lại lợi ích trên nhiều lĩnh vực khác nhau. Việc xây dựng LLM, đào tạo trước và tinh chỉnh chúng khá tốn kém và cồng kềnh đối với chúng. Thay vào đó, họ có thể sử dụng các hệ thống AI mở có sẵn trong ngành với nền tảng và che giấu các lời nhắc xung quanh các trường hợp sử dụng của doanh nghiệp.
Do đó, Nối đất là vấn đề được các doanh nghiệp cân nhắc hàng đầu và phù hợp và hữu ích hơn cho họ trong việc cải thiện chất lượng phản hồi cũng như khắc phục mối lo ngại về ảo giác, bảo mật dữ liệu và tuân thủ, vì nó có thể mang lại giá trị kinh doanh đáng kinh ngạc. LLM có sẵn trên thị trường cho nhiều trường hợp sử dụng mà ngày nay họ gặp khó khăn trong việc tự động hóa.
Lợi ích cho doanh nghiệp
Có một số lợi ích cho Doanh nghiệp khi triển khai nối đất với LLM:
1. Uy tín được nâng cao: Bằng cách đảm bảo rằng thông tin và nội dung do LLM tạo ra có căn cứ trên các nguồn dữ liệu đã được xác minh, doanh nghiệp có thể nâng cao độ tin cậy của thông tin liên lạc, báo cáo và nội dung của họ. Điều này có thể giúp xây dựng niềm tin với khách hàng, khách hàng và các bên liên quan.
2. Cải thiện việc ra quyết định: Trong các ứng dụng doanh nghiệp, đặc biệt là những ứng dụng liên quan đến phân tích dữ liệu và hỗ trợ quyết định, việc sử dụng LLM với nền tảng dữ liệu có thể cung cấp những hiểu biết đáng tin cậy hơn. Điều này có thể dẫn đến việc ra quyết định sáng suốt hơn, điều này rất quan trọng cho việc hoạch định chiến lược và tăng trưởng kinh doanh.
3. Tuân thủ quy định: Nhiều ngành phải tuân theo các yêu cầu pháp lý về tính chính xác và tuân thủ của dữ liệu. Nền tảng dữ liệu với LLM có thể hỗ trợ đáp ứng các tiêu chuẩn tuân thủ này, giảm rủi ro về các vấn đề pháp lý hoặc quy định.
4. Tạo nội dung chất lượng: LLM thường được sử dụng trong việc tạo nội dung, chẳng hạn như để tiếp thị, hỗ trợ khách hàng và mô tả sản phẩm. Nền tảng dữ liệu đảm bảo rằng nội dung được tạo ra là chính xác về mặt thực tế, giảm nguy cơ phổ biến thông tin sai lệch hoặc gây hiểu lầm hoặc ảo giác.
5. Giảm thông tin sai lệch: Trong thời đại tin tức giả và thông tin sai lệch, nền tảng dữ liệu có thể giúp doanh nghiệp chống lại sự lan truyền thông tin sai lệch bằng cách đảm bảo rằng nội dung họ tạo hoặc chia sẻ dựa trên các nguồn dữ liệu đã được xác thực.
6. Sự hài lòng của khách hàng: Cung cấp cho khách hàng thông tin chính xác và đáng tin cậy có thể nâng cao sự hài lòng và tin tưởng của họ đối với sản phẩm hoặc dịch vụ của doanh nghiệp.
7. Giảm thiểu rủi ro: Căn cứ dữ liệu có thể giúp giảm rủi ro khi đưa ra quyết định dựa trên thông tin không chính xác hoặc không đầy đủ, điều này có thể dẫn đến tổn hại về tài chính hoặc danh tiếng.
Ví dụ: Kịch bản giới thiệu sản phẩm của khách hàng
Hãy xem nền tảng dữ liệu có thể trợ giúp như thế nào đối với trường hợp sử dụng của doanh nghiệp bằng cách sử dụng openAI chatGPT
Lời nhắc cơ bản
Generate a short email adding coupons on recommended products to customer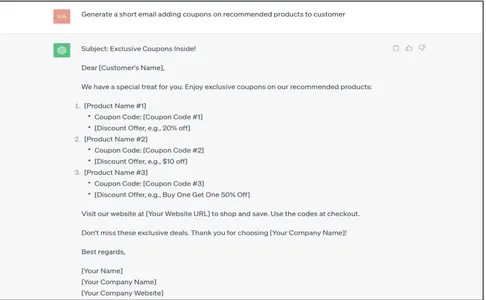
Phản hồi do ChatGPT tạo ra rất chung chung, không theo ngữ cảnh và thô sơ. Điều này cần phải được cập nhật/ánh xạ thủ công với dữ liệu khách hàng doanh nghiệp phù hợp, việc này rất tốn kém. Hãy xem làm thế nào điều này có thể được tự động hóa bằng các kỹ thuật nối đất dữ liệu.
Giả sử doanh nghiệp đã nắm giữ dữ liệu khách hàng doanh nghiệp và hệ thống đề xuất thông minh có thể tạo phiếu giảm giá và đề xuất cho khách hàng; Chúng tôi rất có thể đưa ra lời nhắc trên bằng cách làm phong phú siêu dữ liệu phù hợp để văn bản email được tạo từ chatGPT sẽ giống hệt như cách chúng tôi mong muốn và rất có thể được tự động hóa để gửi email cho khách hàng mà không cần can thiệp thủ công.
Giả sử công cụ nền tảng của chúng tôi sẽ lấy được siêu dữ liệu làm giàu phù hợp từ dữ liệu khách hàng và cập nhật lời nhắc bên dưới. Hãy xem phản hồi của ChatGPT cho lời nhắc có căn cứ sẽ như thế nào.
Lời nhắc có căn cứ
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off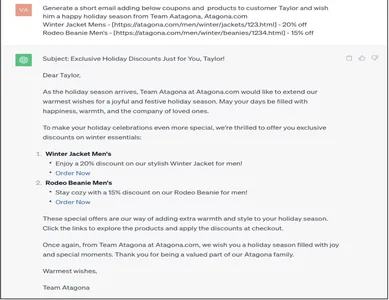
Phản hồi được tạo ra bằng lời nhắc cơ bản chính xác là cách doanh nghiệp muốn khách hàng được thông báo. Dữ liệu khách hàng phong phú được nhúng vào phản hồi email từ Gen AI là một quá trình tự động hóa đáng chú ý để mở rộng quy mô và duy trì doanh nghiệp.
Giải pháp nối đất LLM doanh nghiệp cho hệ thống phần mềm
Có nhiều cách để tạo nền tảng cho dữ liệu trong hệ thống doanh nghiệp và việc kết hợp các kỹ thuật này có thể được sử dụng để tạo nền tảng dữ liệu hiệu quả và tạo ra lời nhắc cụ thể cho từng trường hợp sử dụng. Hai đối thủ chính là giải pháp tiềm năng để triển khai thế hệ tăng cường truy xuất (nối đất) là
- Dữ liệu ứng dụng|Biểu đồ kiến thức
- nhúng vector và tìm kiếm ngữ nghĩa
Việc sử dụng các giải pháp này sẽ tùy thuộc vào trường hợp sử dụng và nền tảng bạn muốn áp dụng. Ví dụ: các cửa hàng vectơ cung cấp phản hồi có thể không chính xác và mơ hồ, trong khi biểu đồ tri thức sẽ trả về chính xác, chính xác và được lưu trữ ở định dạng mà con người có thể đọc được.
Một vài chiến lược khác có thể được kết hợp bên trên những chiến lược trên có thể là
- Liên kết với API bên ngoài, Công cụ tìm kiếm
- Hệ thống tuân thủ và che giấu dữ liệu
- Tích hợp với các kho dữ liệu, hệ thống nội bộ
- Thống nhất dữ liệu theo thời gian thực từ nhiều nguồn
Trong blog này, chúng ta hãy xem một thiết kế phần mềm mẫu về cách bạn có thể đạt được bằng biểu đồ dữ liệu ứng dụng doanh nghiệp.
Sơ đồ tri thức doanh nghiệp
Biểu đồ tri thức có thể biểu diễn thông tin ngữ nghĩa của các thực thể khác nhau và mối quan hệ giữa chúng. Trong thế giới Doanh nghiệp, họ lưu trữ kiến thức về khách hàng, sản phẩm và hơn thế nữa. Biểu đồ khách hàng doanh nghiệp sẽ là một công cụ mạnh mẽ để thu thập dữ liệu một cách hiệu quả và tạo ra các lời nhắc phong phú. Sơ đồ tri thức cho phép tìm kiếm dựa trên biểu đồ, cho phép người dùng khám phá thông tin thông qua các khái niệm và thực thể được liên kết, điều này có thể dẫn đến kết quả tìm kiếm chính xác và đa dạng hơn.
So sánh với cơ sở dữ liệu Vector
Việc lựa chọn giải pháp nối đất sẽ tùy thuộc vào từng trường hợp sử dụng cụ thể. Tuy nhiên, đồ thị trên vectơ có nhiều ưu điểm như
| Tiêu chuẩn | Nối đất đồ thị | nối đất vector |
| Truy vấn phân tích | Biểu đồ dữ liệu phù hợp với dữ liệu có cấu trúc và truy vấn phân tích, cung cấp kết quả chính xác do bố cục biểu đồ trừu tượng của chúng. | Kho dữ liệu vectơ có thể không hoạt động tốt với các truy vấn phân tích vì chúng chủ yếu hoạt động trên dữ liệu phi cấu trúc, tìm kiếm ngữ nghĩa bằng cách nhúng vectơ và dựa vào tính điểm tương tự. |
| Độ chính xác và độ tin cậy | đồ thị tri thức sử dụng các nút và mối quan hệ để lưu trữ dữ liệu, chỉ trả về thông tin hiện có. Họ tránh những kết quả không đầy đủ hoặc không liên quan. | Cơ sở dữ liệu vectơ có thể cung cấp các kết quả không đầy đủ hoặc không liên quan, chủ yếu là do chúng phụ thuộc vào việc chấm điểm tương tự và giới hạn kết quả được xác định trước. |
| Điều chỉnh ảo giác | Biểu đồ tri thức minh bạch với cách trình bày dữ liệu mà con người có thể đọc được. Chúng giúp xác định và sửa thông tin sai lệch, theo dõi lộ trình của truy vấn và chỉnh sửa thông tin đó, cải thiện độ chính xác của LLM (Mô hình ngôn ngữ lớn). | Cơ sở dữ liệu vectơ thường được coi là hộp đen không được lưu trữ ở định dạng có thể đọc được và có thể không tạo điều kiện dễ dàng cho việc xác định và sửa thông tin sai lệch. |
| An ninh và Quản trị | Sơ đồ tri thức mang lại khả năng kiểm soát tốt hơn đối với việc tạo dữ liệu, quản trị và tuân thủ tuân thủ, bao gồm các quy định như GDPR. | Cơ sở dữ liệu vectơ có thể phải đối mặt với những thách thức trong việc áp đặt các hạn chế và quản trị do tính chất không minh bạch của chúng. |
Thiết kế cấp cao
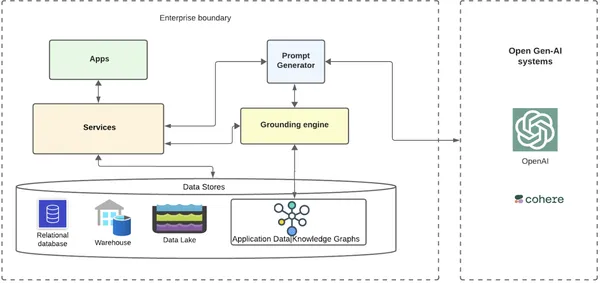
Chúng ta hãy xem ở mức độ rất cao cách hệ thống có thể tìm kiếm một doanh nghiệp sử dụng biểu đồ tri thức và LLM mở để làm nền tảng.
Lớp cơ sở là nơi lưu trữ dữ liệu và siêu dữ liệu của khách hàng doanh nghiệp trên nhiều cơ sở dữ liệu, kho dữ liệu và hồ dữ liệu khác nhau. Có thể có một dịch vụ xây dựng các biểu đồ kiến thức dữ liệu từ dữ liệu này và lưu trữ nó trong biểu đồ db. Có thể có nhiều dịch vụ doanh nghiệp|dịch vụ vi mô trong thế giới đám mây phân tán sẽ tương tác với các kho dữ liệu này. Phía trên các dịch vụ này có thể có nhiều ứng dụng khác nhau tận dụng cơ sở hạ tầng cơ bản.
Các ứng dụng có thể có nhiều trường hợp sử dụng để nhúng AI vào các tình huống của chúng hoặc các luồng khách hàng tự động thông minh, đòi hỏi phải tương tác với các hệ thống AI bên trong và bên ngoài. Trong trường hợp các kịch bản AI tổng quát, hãy lấy một ví dụ đơn giản về quy trình làm việc trong đó doanh nghiệp muốn nhắm mục tiêu khách hàng thông qua email đưa ra một số chương trình giảm giá cho các sản phẩm được đề xuất được cá nhân hóa trong mùa lễ. Họ có thể đạt được điều này bằng khả năng tự động hóa hạng nhất, tận dụng AI hiệu quả hơn.
Quy trình công việc
- Quy trình làm việc muốn gửi email có thể nhận được sự trợ giúp của các hệ thống Gen-AI mở bằng cách gửi lời nhắc có căn cứ kèm theo dữ liệu theo ngữ cảnh của khách hàng.
- Ứng dụng quy trình làm việc sẽ gửi yêu cầu đến dịch vụ phụ trợ của nó để nhận văn bản email tận dụng hệ thống GenAI.
- Dịch vụ phụ trợ sẽ định tuyến dịch vụ đến dịch vụ máy phát điện nhắc nhở, dịch vụ này sẽ định tuyến đến động cơ nối đất.
- Công cụ nền tảng lấy tất cả siêu dữ liệu của khách hàng từ một trong các dịch vụ của nó và truy xuất biểu đồ kiến thức dữ liệu khách hàng.
- Công cụ nối đất đi qua biểu đồ qua các nút và các mối quan hệ có liên quan sẽ trích xuất thông tin cuối cùng cần thiết và gửi nó trở lại trình tạo dấu nhắc.
- Trình tạo lời nhắc thêm dữ liệu căn cứ với mẫu có sẵn cho trường hợp sử dụng và gửi lời nhắc căn cứ tới các hệ thống AI mở mà doanh nghiệp chọn để tích hợp (ví dụ: OpenAI/Cohere).
- Các hệ thống GenAI mở trả về phản hồi phù hợp hơn và phù hợp với ngữ cảnh hơn nhiều cho doanh nghiệp, được gửi cho khách hàng qua email.
Hãy chia phần này thành hai phần và hiểu chi tiết:
1. Tạo biểu đồ kiến thức khách hàng
Thiết kế dưới đây phù hợp với ví dụ trên, việc lập mô hình có thể được thực hiện theo nhiều cách khác nhau tùy theo yêu cầu.
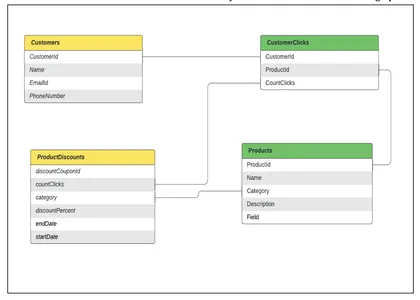
Mô hình hóa dữ liệu: Giả sử chúng ta có nhiều bảng khác nhau được mô hình hóa dưới dạng các nút trong biểu đồ và nối giữa các bảng dưới dạng mối quan hệ giữa các nút. Đối với ví dụ trên, chúng ta cần
- một bảng chứa dữ liệu của Khách hàng,
- một bảng chứa dữ liệu sản phẩm,
- một bảng chứa dữ liệu Sở thích của khách hàng(Số lần nhấp chuột) để đưa ra các đề xuất được cá nhân hóa
- một bảng chứa dữ liệu ProductDiscounts
Trách nhiệm của doanh nghiệp là phải nhập tất cả dữ liệu này từ nhiều nguồn dữ liệu và cập nhật thường xuyên để tiếp cận khách hàng một cách hiệu quả.
Hãy xem cách mô hình hóa các bảng này và cách chuyển đổi chúng thành biểu đồ khách hàng.
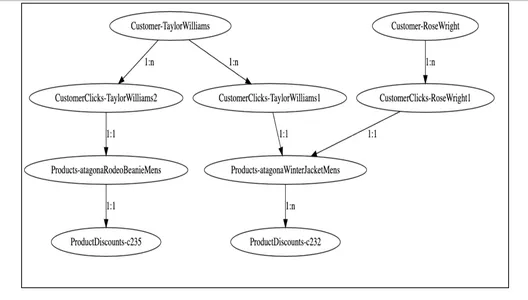
2. Mô hình hóa đồ thị
Từ trình hiển thị biểu đồ ở trên, chúng ta có thể thấy các nút của khách hàng có liên quan như thế nào với các sản phẩm khác nhau dựa trên dữ liệu tương tác với số lần nhấp chuột của họ và xa hơn là các nút giảm giá. Dịch vụ cơ bản có thể dễ dàng truy vấn các biểu đồ khách hàng này, duyệt qua các nút này thông qua các mối quan hệ và thu được thông tin cần thiết về các khoản giảm giá đủ điều kiện cho khách hàng tương ứng.
Nút biểu đồ mẫu và mối quan hệ JAVA POJO cho phần trên có thể trông giống như bên dưới
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }Một biểu đồ thô mẫu trong trường hợp này có thể trông giống như bên dưới
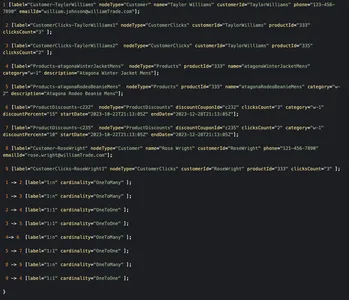
Việc duyệt qua biểu đồ từ nút khách hàng 'Taylor Williams' sẽ giải quyết vấn đề cho chúng tôi và tìm ra các đề xuất sản phẩm phù hợp cũng như các khoản giảm giá đủ điều kiện.
3. Cửa hàng Graph phổ biến trong ngành
Có rất nhiều cửa hàng đồ thị có sẵn trên thị trường có thể phù hợp với kiến trúc doanh nghiệp. Neo4j, TigerGraph, Amazon Neptune và OrientDB được sử dụng rộng rãi làm cơ sở dữ liệu đồ thị.
Chúng tôi giới thiệu mô hình mới của Hồ dữ liệu đồ thị, cho phép truy vấn đồ thị trên dữ liệu dạng bảng (dữ liệu có cấu trúc trong hồ, nhà kho và nhà ở trong hồ). Điều này đạt được nhờ các giải pháp mới được liệt kê bên dưới mà không cần hydrat hóa hoặc lưu giữ dữ liệu trong kho dữ liệu biểu đồ, tận dụng Zero-ETL.
- PuppyGraph(Hồ dữ liệu đồ thị)
- Timbr.ai
Tuân thủ và cân nhắc về đạo đức
Bảo vệ dữ liệu: Doanh nghiệp phải có trách nhiệm lưu trữ và sử dụng dữ liệu khách hàng tuân thủ GDPR và các PII khác. Dữ liệu được lưu trữ cần phải được quản lý và làm sạch trước khi xử lý và sử dụng lại để hiểu biết sâu sắc hoặc áp dụng AI.
Ảo giác & Hòa giải: Doanh nghiệp cũng có thể thêm các dịch vụ đối chiếu để xác định thông tin sai lệch trong dữ liệu, theo dõi lại lộ trình của truy vấn và thực hiện các chỉnh sửa đối với thông tin đó, điều này có thể giúp cải thiện độ chính xác của LLM. Với biểu đồ tri thức, vì dữ liệu được lưu trữ minh bạch và con người có thể đọc được nên điều này tương đối dễ đạt được.
Chính sách lưu giữ hạn chế: Để tuân thủ việc bảo vệ dữ liệu và ngăn chặn việc lạm dụng dữ liệu khách hàng khi tương tác với các hệ thống LLM mở, điều rất quan trọng là phải có chính sách lưu giữ bằng XNUMX để các hệ thống bên ngoài mà doanh nghiệp tương tác sẽ không lưu giữ dữ liệu kịp thời được yêu cầu cho bất kỳ mục đích kinh doanh hoặc phân tích nào khác.
Kết luận
Tóm lại, Mô hình ngôn ngữ lớn (LLM) thể hiện một tiến bộ vượt trội trong trí tuệ nhân tạo và xử lý ngôn ngữ tự nhiên. Chúng có thể chuyển đổi các ngành công nghiệp và ứng dụng khác nhau, từ hiểu và tạo ngôn ngữ tự nhiên đến hỗ trợ các nhiệm vụ phức tạp. Tuy nhiên, sự thành công và sử dụng LLM có trách nhiệm đòi hỏi một nền tảng và nền tảng vững chắc trong nhiều lĩnh vực chính khác nhau.
Chìa khóa chính
- Các doanh nghiệp có thể được hưởng lợi rất nhiều từ nền tảng và thúc đẩy hiệu quả khi sử dụng LLM cho các tình huống khác nhau.
- Sơ đồ tri thức và cửa hàng Vector là những giải pháp Nối đất phổ biến và việc chọn một giải pháp sẽ tùy thuộc vào mục đích của giải pháp.
- Sơ đồ tri thức có thể có thông tin chính xác và đáng tin cậy hơn so với các cửa hàng vectơ, điều này mang lại lợi thế cho các trường hợp sử dụng của Doanh nghiệp mà không cần phải thêm các lớp tuân thủ và bảo mật bổ sung.
- Chuyển đổi mô hình hóa dữ liệu truyền thống với các thực thể và mối quan hệ thành Biểu đồ tri thức có nút và cạnh.
- Tích hợp Đồ thị tri thức doanh nghiệp với nhiều nguồn dữ liệu khác nhau với các doanh nghiệp lưu trữ dữ liệu lớn hiện có.
- Sơ đồ tri thức là lựa chọn lý tưởng cho các truy vấn phân tích. Hồ dữ liệu đồ thị cho phép truy vấn dữ liệu dạng bảng dưới dạng biểu đồ trong bộ lưu trữ dữ liệu doanh nghiệp.
Những câu hỏi thường gặp
A. LLM là thuật toán AI sử dụng kỹ thuật DL và tập dữ liệu lớn để hiểu, tóm tắt, tạo và dự đoán nội dung mới.
A. Biểu đồ dữ liệu ứng dụng là cấu trúc dữ liệu lưu trữ dữ liệu ở dạng nút và cạnh. Mô hình hóa chúng như mối quan hệ giữa các nút dữ liệu khác nhau.
A. Cơ sở dữ liệu vectơ lưu trữ và quản lý dữ liệu phi cấu trúc như văn bản, âm thanh và video. Nó vượt trội trong việc lập chỉ mục và truy xuất nhanh chóng cho các ứng dụng như công cụ đề xuất, học máy và Gen-AI.
A. Trong kho vectơ, phần nhúng là biểu diễn số của các đối tượng, từ hoặc điểm dữ liệu trong không gian vectơ nhiều chiều. Các phần nhúng này nắm bắt các mối quan hệ ngữ nghĩa và sự tương đồng giữa các mục, cho phép phân tích dữ liệu hiệu quả, tìm kiếm điểm tương đồng và các tác vụ học máy.
A. Dữ liệu có cấu trúc được tổ chức tốt với các bảng và lược đồ được xác định. Dữ liệu phi cấu trúc, như văn bản, hình ảnh, âm thanh hoặc video, khó phân tích hơn do thiếu định dạng.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/

