Bài đăng này được viết với sự cộng tác của Claudia Chitu và Liều lượng Spyridon từ ACAST.
Được thành lập vào 2014, Acast là công ty podcast độc lập hàng đầu thế giới, nâng tầm người sáng tạo podcast và nhà quảng cáo podcast để có trải nghiệm nghe tuyệt vời nhất. Bằng cách ủng hộ một hệ sinh thái độc lập và cởi mở cho podcasting, Acast đặt mục tiêu thúc đẩy podcasting bằng các công cụ và khả năng kiếm tiền cần thiết để phát triển.
Công ty sử dụng các dịch vụ Đám mây AWS để xây dựng các sản phẩm dựa trên dữ liệu và các biện pháp thực hành tốt nhất về kỹ thuật mở rộng quy mô. Để đảm bảo nền tảng dữ liệu bền vững trong các giai đoạn tăng trưởng và sinh lời, nhóm công nghệ của họ đã áp dụng cơ chế phi tập trung kiến trúc lưới dữ liệu.
Trong bài đăng này, chúng tôi thảo luận về cách Acast vượt qua thách thức về sự phụ thuộc kết hợp giữa các nhóm làm việc với dữ liệu trên quy mô lớn bằng cách sử dụng khái niệm lưới dữ liệu.
Vấn đề
Với tốc độ tăng trưởng và mở rộng nhanh chóng, Acast đã gặp phải một thách thức gây tiếng vang trên toàn cầu. Acast nhận thấy mình có các đơn vị kinh doanh đa dạng và lượng dữ liệu khổng lồ được tạo ra trong toàn tổ chức. Kiến trúc nguyên khối và tập trung hiện tại đang gặp khó khăn trong việc đáp ứng nhu cầu ngày càng tăng của người tiêu dùng dữ liệu. Các kỹ sư dữ liệu nhận thấy việc duy trì và mở rộng cơ sở hạ tầng dữ liệu ngày càng khó khăn, dẫn đến việc truy cập dữ liệu, lưu trữ dữ liệu và quản lý dữ liệu kém hiệu quả. Mục tiêu chính là nâng cao trải nghiệm người dùng từ đầu đến cuối, bắt đầu từ nhu cầu kinh doanh.
Acast cần phải giải quyết những thách thức này để đạt được quy mô hoạt động, nghĩa là số lượng người tối đa trên toàn cầu có thể hoạt động độc lập và mang lại giá trị. Trong trường hợp này, Acast đã cố gắng giải quyết thách thức của cấu trúc nguyên khối này và thời gian mang lại giá trị cao cho nhóm sản phẩm, nhóm công nghệ và người tiêu dùng cuối. Điều đáng nói là họ cũng có các nhóm sản phẩm và công nghệ khác, bao gồm cả nhóm vận hành hoặc kinh doanh, không có tài khoản AWS.
Acast có số lượng nhóm sản phẩm khác nhau, liên tục phát triển bằng cách hợp nhất các nhóm hiện có, chia tách, thêm người mới hoặc đơn giản là tạo nhóm mới. Trong 2 năm qua, họ có khoảng 10–20 đội, mỗi đội gồm 4–10 người. Mỗi nhóm sở hữu ít nhất hai tài khoản AWS, tối đa 10 tài khoản, tùy theo quyền sở hữu. Phần lớn dữ liệu do các tài khoản này tạo ra được sử dụng cho mục đích kinh doanh thông minh (BI) và trong amazon Athena, bởi hàng trăm người dùng doanh nghiệp mỗi ngày.
The solution Acast implemented is a data mesh, architected on AWS. The solution mirrors the organizational structure rather than an explicit architectural decision. As per the Inverse Conway Maneuver, Acast’s technology architecture displays isomorphism with the business architecture. In this case, the business users are enabled through the data mesh architecture to get faster time to insights and know directly who the domain-specific owners are, speeding up collaboration. This will be further detailed when we discuss the AWS Identity and Access Management (IAM) roles used in our AWS certification because one of the roles is dedicated to the business group.
Các thông số thành công
Acast đã thành công trong việc khởi động và mở rộng quy mô sản phẩm dữ liệu hướng đến miền và nhóm mới cũng như cơ sở hạ tầng và thiết lập tương ứng của nó, dẫn đến ít trở ngại hơn trong việc thu thập thông tin chi tiết và khiến người dùng cũng như người tiêu dùng hài lòng hơn.
Sự thành công của việc triển khai có nghĩa là đánh giá các khía cạnh khác nhau của cơ sở hạ tầng dữ liệu, quản lý dữ liệu và kết quả kinh doanh. Họ đã phân loại các số liệu và chỉ số theo các loại sau:
- Sử dụng thông tin – Hiểu biết rõ ràng về ai đang sử dụng nguồn dữ liệu nào, được cụ thể hóa bằng bản đồ về người tiêu dùng và nhà sản xuất. Các cuộc thảo luận với người dùng cho thấy họ vui hơn khi có quyền truy cập dữ liệu nhanh hơn theo cách đơn giản hơn, tổ chức dữ liệu có cấu trúc hơn và xác định rõ ràng ai là nhà sản xuất. Rất nhiều tiến bộ đã được thực hiện để nâng cao văn hóa dựa trên dữ liệu của họ (hiểu biết về dữ liệu, chia sẻ dữ liệu và cộng tác giữa các đơn vị kinh doanh).
- Quản trị dữ liệu – Với đối tượng cấp độ dịch vụ nêu rõ khi nào nguồn dữ liệu có sẵn (trong số các chi tiết khác), các nhóm biết cần thông báo cho ai và có thể thực hiện việc này trong thời gian ngắn hơn khi có dữ liệu đến muộn hoặc các vấn đề khác với dữ liệu. Với vai trò quản lý dữ liệu, quyền sở hữu đã được tăng cường.
- Năng suất của nhóm dữ liệu – Thông qua quá trình hồi cứu kỹ thuật, Acast nhận thấy rằng nhóm của họ đánh giá cao quyền tự chủ trong việc đưa ra quyết định liên quan đến miền dữ liệu của họ.
- Chi phí và hiệu quả nguồn lực – Đây là lĩnh vực mà Acast nhận thấy sự trùng lặp dữ liệu đã giảm và do đó giảm chi phí (trong một số tài khoản, loại bỏ bản sao dữ liệu 100%), bằng cách đọc dữ liệu trên các tài khoản trong khi cho phép mở rộng quy mô.
Tổng quan về lưới dữ liệu
Lưới dữ liệu là một cách tiếp cận kỹ thuật xã hội để xây dựng kiến trúc dữ liệu phi tập trung bằng cách sử dụng thiết kế tự phục vụ, hướng miền (trong góc độ phát triển phần mềm) và mượn lý thuyết về thiết kế hướng miền của Eric Evans và lý thuyết của Manuel Pais và Matthew Skelton. lý thuyết về cấu trúc liên kết nhóm. Điều quan trọng là phải thiết lập bối cảnh để hiểu lưới dữ liệu là gì vì nó tạo tiền đề cho các chi tiết kỹ thuật tiếp theo và có thể giúp bạn hiểu các khái niệm được thảo luận trong bài đăng này phù hợp với khuôn khổ rộng hơn của lưới dữ liệu như thế nào.
Tóm tắt lại trước khi đi sâu hơn vào cách triển khai Acast, khái niệm lưới dữ liệu dựa trên các nguyên tắc sau:
- Đó là mối quan tâm hàng đầu, trái ngược với các đường dẫn
- Nó phục vụ dữ liệu như một sản phẩm
- Đó là một sản phẩm tốt làm hài lòng người dùng (dữ liệu đáng tin cậy, tài liệu có sẵn và dễ sử dụng)
- Nó cung cấp khả năng quản trị tính toán liên kết và quyền sở hữu phi tập trung—một nền tảng dữ liệu tự phục vụ
Kiến trúc hướng miền
Theo phương pháp sở hữu bộ dữ liệu phân tích và vận hành của Acast, các nhóm được cấu trúc với quyền sở hữu dựa trên miền, đọc trực tiếp từ nhà sản xuất dữ liệu, thông qua API hoặc lập trình từ bộ lưu trữ Amazon S3 hoặc sử dụng Athena làm công cụ truy vấn SQL. Một số ví dụ về miền của Acast được trình bày trong hình sau.
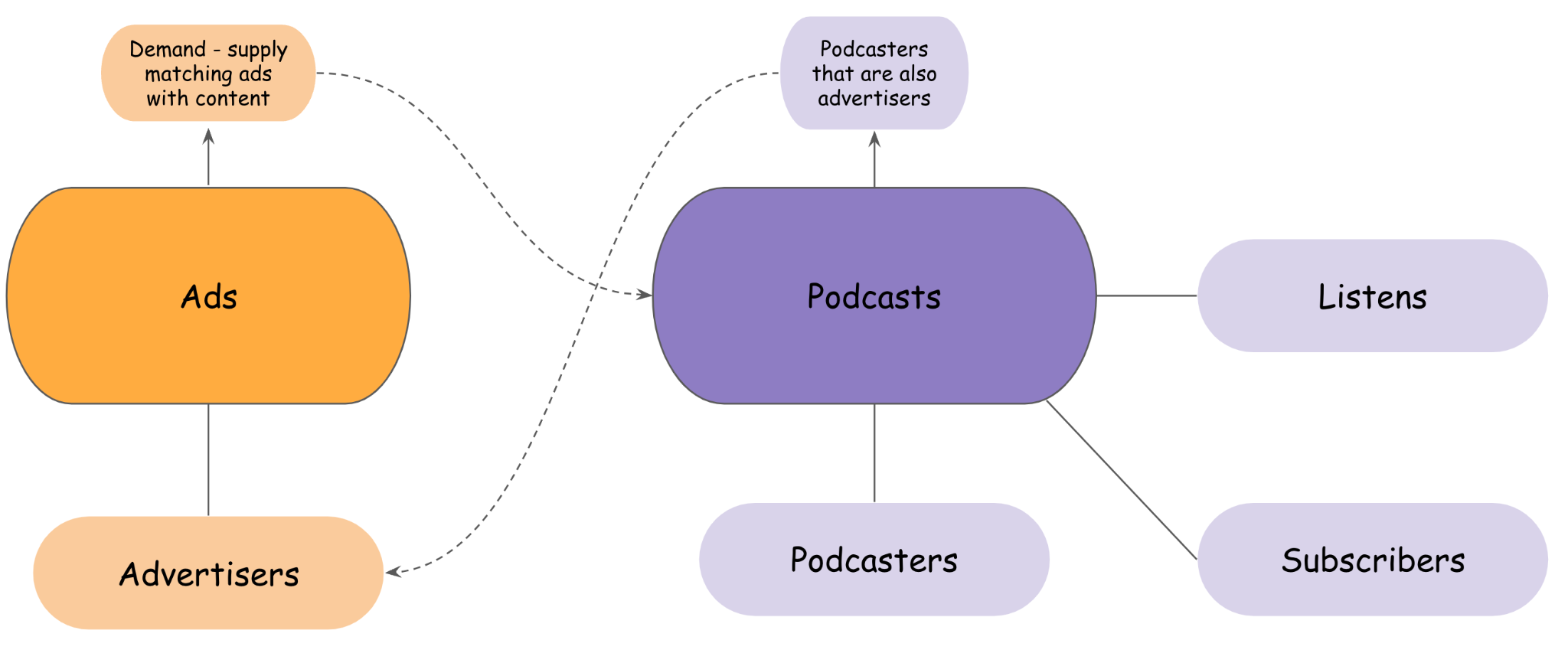
Như được minh họa trong hình trước, một số miền được liên kết lỏng lẻo với các điểm cuối phân tích hoặc hoạt động của các miền khác, với quyền sở hữu khác. Những người khác có thể có sự phụ thuộc mạnh mẽ hơn vào hoạt động kinh doanh (một số podcast cũng có thể là nhà quảng cáo, tạo quảng cáo tài trợ và chạy chiến dịch cho chương trình của riêng họ hoặc giao dịch quảng cáo bằng phần mềm của Acast dưới dạng dịch vụ).
Dữ liệu như một sản phẩm
Việc xử lý dữ liệu như một sản phẩm đòi hỏi ba thành phần chính: chính dữ liệu, siêu dữ liệu cũng như mã và cơ sở hạ tầng liên quan. Theo cách tiếp cận này, các nhóm chịu trách nhiệm tạo ra dữ liệu được gọi là nhà sản xuất. Các nhóm nhà sản xuất này có kiến thức chuyên sâu về người tiêu dùng, hiểu cách sử dụng sản phẩm dữ liệu của họ. Mọi thay đổi do nhà sản xuất dữ liệu lên kế hoạch đều được thông báo trước cho tất cả người tiêu dùng. Thông báo chủ động này đảm bảo rằng các quy trình xuôi dòng không bị gián đoạn. Bằng cách cung cấp cho người tiêu dùng thông báo trước, họ có đủ thời gian để chuẩn bị và thích ứng với những thay đổi sắp tới, duy trì quy trình làm việc suôn sẻ và không bị gián đoạn. Các nhà sản xuất chạy song song một phiên bản mới của tập dữ liệu ban đầu, thông báo cho từng người tiêu dùng và thảo luận với họ về khung thời gian cần thiết của họ để bắt đầu sử dụng phiên bản mới. Khi tất cả người tiêu dùng đang sử dụng phiên bản mới, nhà sản xuất sẽ tắt phiên bản đầu tiên.
Các lược đồ dữ liệu được suy ra từ định dạng chung đã được thống nhất để chia sẻ tệp giữa các nhóm, đó là Parquet trong trường hợp của Acast. Dữ liệu có thể được chia sẻ trong các tệp, sự kiện theo đợt hoặc luồng, v.v. Mỗi nhóm có tài khoản AWS riêng hoạt động như một thực thể độc lập và tự chủ với cơ sở hạ tầng riêng. Để phối hợp, họ sử dụng Bộ công cụ phát triển đám mây AWS (AWS CDK) dành cho cơ sở hạ tầng dưới dạng mã (IaC) và Keo AWS Danh mục dữ liệu để quản lý siêu dữ liệu. Người dùng cũng có thể đưa ra yêu cầu tới nhà sản xuất để cải thiện cách trình bày dữ liệu hoặc làm phong phú dữ liệu bằng các điểm dữ liệu mới để tạo ra giá trị kinh doanh cao hơn.
Với việc mỗi nhóm sở hữu một tài khoản AWS và ID danh mục dữ liệu từ Athena, thật dễ dàng nhận thấy điều này qua lăng kính của hồ dữ liệu phân tán trên Amazon S3, với một danh mục chung ánh xạ tất cả các danh mục từ tất cả các tài khoản.
Đồng thời, mỗi nhóm cũng có thể ánh xạ các danh mục khác vào tài khoản của riêng mình và sử dụng dữ liệu của riêng họ do họ tạo ra cùng với dữ liệu từ các tài khoản khác. Trừ khi đó là dữ liệu nhạy cảm, dữ liệu có thể được truy cập theo chương trình hoặc từ Bảng điều khiển quản lý AWS theo cách tự phục vụ mà không phụ thuộc vào các kỹ sư cơ sở hạ tầng dữ liệu. Đây là một cách chia sẻ, không phân biệt miền để dữ liệu tự phục vụ. Việc khám phá sản phẩm xảy ra thông qua việc đăng ký danh mục. Chỉ sử dụng một số tiêu chuẩn được thống nhất và áp dụng phổ biến trong toàn công ty, nhằm mục đích tương tác, Acast đã giải quyết các rào cản và rào cản bị phân mảnh để trao đổi dữ liệu hoặc sử dụng dữ liệu không xác định tên miền.
Với nguyên tắc này, các nhóm được đảm bảo rằng dữ liệu được an toàn, đáng tin cậy và chính xác, đồng thời quản lý các biện pháp kiểm soát quyền truy cập phù hợp ở từng cấp miền. Hơn nữa, trên tài khoản trung tâm, các vai trò được xác định cho các loại quyền và quyền truy cập khác nhau bằng cách sử dụng Trung tâm nhận dạng AWS IAM quyền. Tất cả các bộ dữ liệu đều có thể được khám phá từ một tài khoản trung tâm. Hình dưới đây minh họa cách nó được trang bị công cụ, trong đó hai vai trò IAM được đảm nhận bởi hai loại nhóm người dùng (người tiêu dùng): một nhóm có quyền truy cập vào tập dữ liệu giới hạn, tức là dữ liệu bị hạn chế và một vai trò có quyền truy cập vào dữ liệu không bị hạn chế. Ngoài ra còn có một cách để đảm nhận bất kỳ vai trò nào trong số này, đối với các tài khoản dịch vụ, chẳng hạn như các vai trò được sử dụng bởi các công việc xử lý dữ liệu trong Quy trình công việc được quản lý của Amazon cho Luồng khí Apache (Amazon MWAA) chẳng hạn.
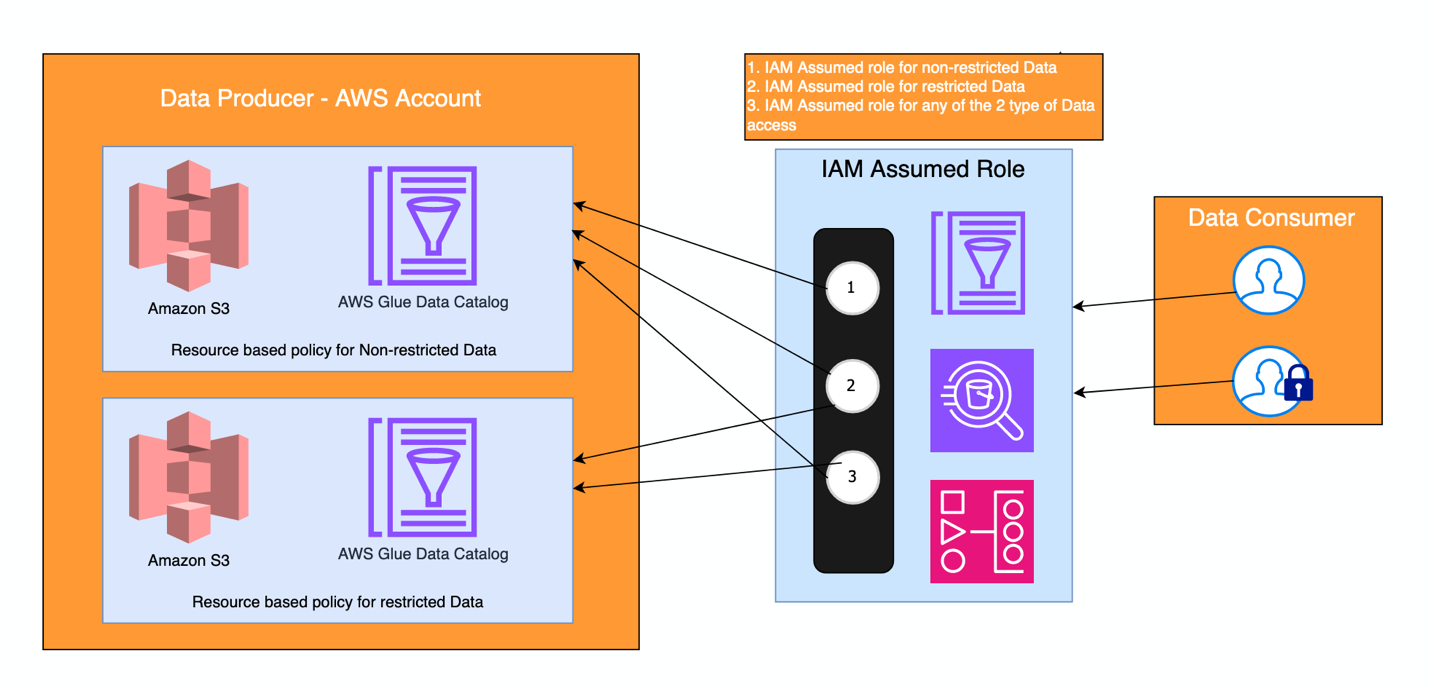
Cách Acast giải quyết để có được sự liên kết cao và kiến trúc được liên kết lỏng lẻo
Sơ đồ sau đây thể hiện kiến trúc khái niệm về cách các nhóm của Acast sắp xếp dữ liệu và cộng tác với nhau.
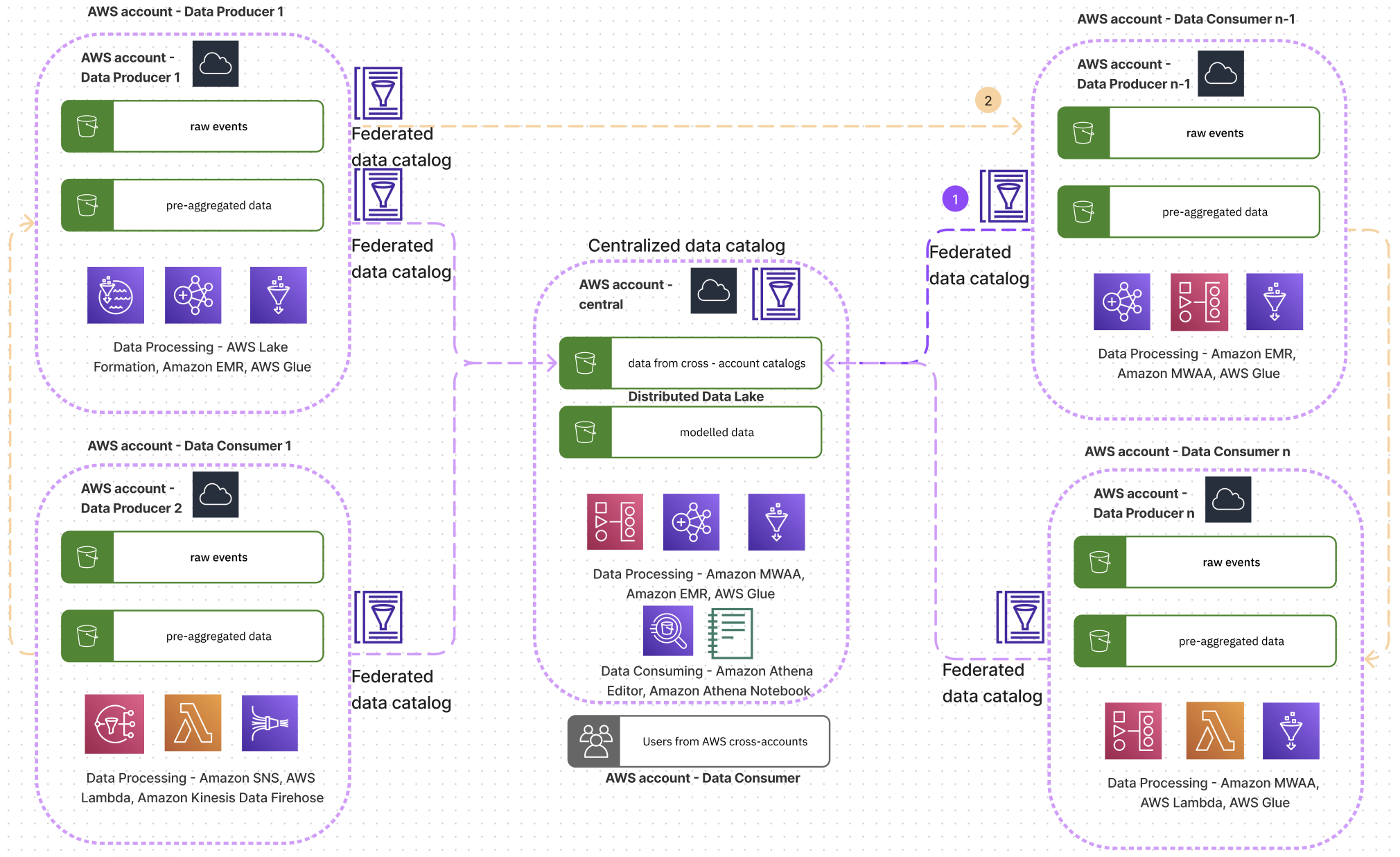
Acast đã sử dụng Khung kiến trúc tốt cho tài khoản trung tâm để cải thiện phương pháp chạy khối lượng công việc phân tích trên đám mây. Thông qua lăng kính của công cụ, Acast có thể giải quyết vấn đề giám sát tốt hơn, Tối ưu hóa chi phí, hiệu suất và bảo mật. Nó giúp họ hiểu những lĩnh vực mà họ có thể cải thiện khối lượng công việc và cách giải quyết các vấn đề phổ biến bằng các giải pháp tự động cũng như cách đo lường thành công, xác định KPI. Nó giúp họ tiết kiệm thời gian để tiếp thu những kiến thức mà nếu không thì sẽ mất nhiều thời gian hơn để tìm ra. Spyridon Dosis, Giám đốc bảo mật thông tin của Acast, chia sẻ: “Chúng tôi rất vui khi AWS luôn đi đầu trong việc phát hành các công cụ cho phép định cấu hình, đánh giá và đánh giá quá trình thiết lập nhiều tài khoản. Đây là một điểm cộng lớn đối với chúng tôi khi làm việc trong một tổ chức phi tập trung.” Spyridon cũng cho biết thêm: “Một khái niệm rất quan trọng mà chúng tôi đánh giá cao là các mặc định bảo mật AWS (ví dụ: mã hóa mặc định cho nhóm S3)”.
Trong sơ đồ kiến trúc, chúng ta có thể thấy rằng mỗi nhóm có thể là nhà sản xuất dữ liệu, ngoại trừ nhóm sở hữu tài khoản trung tâm, đóng vai trò là nền tảng dữ liệu trung tâm, mô hình hóa logic từ nhiều miền để vẽ nên bức tranh kinh doanh đầy đủ. Tất cả các nhóm khác có thể là nhà sản xuất dữ liệu hoặc người tiêu dùng dữ liệu. Họ có thể kết nối với tài khoản trung tâm và khám phá các tập dữ liệu thông qua Danh mục dữ liệu AWS Glue giữa nhiều tài khoản, phân tích chúng trong trình chỉnh sửa truy vấn Athena hoặc bằng sổ ghi chép Athena hoặc ánh xạ danh mục tới tài khoản AWS của riêng họ. Quyền truy cập vào danh mục Athena trung tâm được triển khai bằng Trung tâm nhận dạng IAM, với các vai trò dành cho dữ liệu mở và quyền truy cập dữ liệu bị hạn chế.
Đối với dữ liệu không nhạy cảm (dữ liệu mở), Acast sử dụng một mẫu trong đó các bộ dữ liệu theo mặc định được mở cho toàn bộ tổ chức đọc từ đó, sử dụng một điều kiện để cung cấp tham số ID do tổ chức chỉ định, như được hiển thị trong đoạn mã sau:
Khi xử lý dữ liệu nhạy cảm như tài chính, các nhóm sử dụng mô hình quản lý dữ liệu hợp tác. Người quản lý dữ liệu làm việc với người yêu cầu để đánh giá lý do truy cập cho trường hợp sử dụng dự định. Cùng nhau, họ xác định các phương pháp truy cập phù hợp để đáp ứng nhu cầu trong khi vẫn duy trì bảo mật. Điều này có thể bao gồm vai trò IAM, tài khoản dịch vụ hoặc dịch vụ AWS cụ thể. Cách tiếp cận này cho phép người dùng doanh nghiệp bên ngoài tổ chức công nghệ (có nghĩa là họ không có tài khoản AWS) truy cập và phân tích thông tin họ cần một cách độc lập. Bằng cách cấp quyền truy cập thông qua chính sách IAM đối với tài nguyên AWS Glue và bộ chứa S3, Acast cung cấp khả năng tự phục vụ trong khi vẫn quản lý dữ liệu nhạy cảm thông qua đánh giá của con người. Vai trò người quản lý dữ liệu rất có giá trị trong việc hiểu các trường hợp sử dụng, đánh giá rủi ro bảo mật và cuối cùng là tạo điều kiện thuận lợi cho việc truy cập nhằm thúc đẩy hoạt động kinh doanh thông qua những hiểu biết sâu sắc về phân tích.
Đối với trường hợp sử dụng của Acast, không cần có các biện pháp kiểm soát truy cập cấp hàng hoặc cấp chi tiết, vì vậy cách tiếp cận này là đủ. Tuy nhiên, các tổ chức khác có thể yêu cầu quản trị chi tiết hơn đối với các trường dữ liệu nhạy cảm. Trong những trường hợp đó, các giải pháp như Sự hình thành hồ AWS có thể triển khai các quyền cần thiết trong khi vẫn cung cấp mô hình truy cập dữ liệu tự phục vụ. Để biết thêm thông tin, hãy tham khảo Thiết kế kiến trúc lưới dữ liệu bằng AWS Lake Formation và AWS Glue.
Đồng thời, các nhóm có thể đọc trực tiếp từ các nhà sản xuất khác, từ Amazon S3 hoặc thông qua API, giữ mức độ phụ thuộc ở mức tối thiểu, giúp nâng cao tốc độ phát triển và phân phối. Do đó, một tài khoản có thể vừa là nhà sản xuất vừa là người tiêu dùng. Mỗi nhóm đều tự chủ và chịu trách nhiệm về kho công nghệ của riêng mình.
Học thêm
Acast đã học được gì? Cho đến giờ, chúng ta đã thảo luận rằng thiết kế kiến trúc là ảnh hưởng của cơ cấu tổ chức. Bởi vì tổ chức công nghệ bao gồm nhiều nhóm đa chức năng và việc xây dựng một nhóm mới rất đơn giản, tuân theo các nguyên tắc chung của lưới dữ liệu, nên Acast nhận thấy rằng điều này không phải lúc nào cũng diễn ra liền mạch. Để thiết lập một tài khoản hoàn toàn mới trong AWS, các nhóm sẽ thực hiện cùng một hành trình nhưng hơi khác một chút, tùy theo đặc điểm riêng của họ.
Điều này có thể tạo ra những xích mích nhất định và rất khó để tất cả các nhóm sản xuất dữ liệu đạt đến trình độ trưởng thành cao trong vai trò là nhà sản xuất dữ liệu. Điều này có thể được giải thích là do năng lực dữ liệu khác nhau trong các nhóm chức năng chéo đó chứ không phải do các nhóm dữ liệu chuyên dụng.
Bằng cách triển khai giải pháp phi tập trung, Acast đã giải quyết một cách hiệu quả thách thức về khả năng mở rộng bằng cách điều chỉnh đội ngũ của họ để phù hợp với nhu cầu kinh doanh ngày càng phát triển. Cách tiếp cận này đảm bảo khả năng tách rời và liên kết cao. Hơn nữa, họ tăng cường quyền sở hữu, giảm đáng kể thời gian cần thiết để xác định và giải quyết các vấn đề vì nguồn ngược dòng đã được biết đến và dễ dàng truy cập bằng SLA được chỉ định. Khối lượng yêu cầu hỗ trợ dữ liệu đã giảm hơn 50% vì người dùng doanh nghiệp được trao quyền để có được thông tin chi tiết nhanh hơn. Đáng chú ý, họ đã loại bỏ thành công hàng chục terabyte dung lượng lưu trữ dư thừa mà trước đây chỉ được sao chép để đáp ứng các yêu cầu tiếp theo. Thành tựu này có thể đạt được thông qua việc thực hiện đọc tài khoản chéo, dẫn đến việc loại bỏ các chi phí phát triển và bảo trì liên quan cho các đường ống này.
Kết luận
Acast đã sử dụng luật Thao tác Conway nghịch đảo và sử dụng các dịch vụ AWS trong đó mỗi nhóm sản phẩm đa chức năng có tài khoản AWS riêng để xây dựng kiến trúc lưới dữ liệu cho phép khả năng mở rộng, quyền sở hữu cao và tiêu thụ dữ liệu tự phục vụ. Điều này đã mang lại hiệu quả tốt cho công ty, liên quan đến cách tiếp cận quyền sở hữu và hoạt động dữ liệu, nhằm đáp ứng các nguyên tắc kỹ thuật của họ, dẫn đến việc coi lưới dữ liệu là một hiệu ứng chứ không phải là mục đích có chủ ý. Đối với các tổ chức khác, lưới dữ liệu mong muốn có thể trông khác và cách tiếp cận có thể có những bài học khác.
Để kết luận, a kiến trúc dữ liệu hiện đại trên AWS cho phép bạn xây dựng các sản phẩm dữ liệu và cơ sở hạ tầng lưới dữ liệu một cách hiệu quả với chi phí thấp mà không ảnh hưởng đến hiệu suất.
Sau đây là một số ví dụ về dịch vụ AWS mà bạn có thể sử dụng để thiết kế lưới dữ liệu mong muốn trên AWS:
Về các tác giả
 Claudia Chitu là Nhà chiến lược dữ liệu và là nhà lãnh đạo có ảnh hưởng trong lĩnh vực Analytics. Tập trung vào việc điều chỉnh các sáng kiến dữ liệu với các mục tiêu chiến lược tổng thể của tổ chức, cô sử dụng dữ liệu làm động lực hướng dẫn cho việc lập kế hoạch dài hạn và tăng trưởng bền vững.
Claudia Chitu là Nhà chiến lược dữ liệu và là nhà lãnh đạo có ảnh hưởng trong lĩnh vực Analytics. Tập trung vào việc điều chỉnh các sáng kiến dữ liệu với các mục tiêu chiến lược tổng thể của tổ chức, cô sử dụng dữ liệu làm động lực hướng dẫn cho việc lập kế hoạch dài hạn và tăng trưởng bền vững.
 Liều Spyridon là Chuyên gia bảo mật thông tin ở Acast. Spyridon hỗ trợ tổ chức trong việc thiết kế, triển khai và vận hành các dịch vụ của mình một cách an toàn, bảo vệ dữ liệu của công ty và người dùng.
Liều Spyridon là Chuyên gia bảo mật thông tin ở Acast. Spyridon hỗ trợ tổ chức trong việc thiết kế, triển khai và vận hành các dịch vụ của mình một cách an toàn, bảo vệ dữ liệu của công ty và người dùng.
 Srikant Das là Kiến trúc sư giải pháp phòng thí nghiệm tăng tốc tại Amazon Web Services. Anh ấy có hơn 13 năm kinh nghiệm trong lĩnh vực phân tích Dữ liệu lớn và Kỹ thuật dữ liệu, nơi anh ấy thích xây dựng các giải pháp đáng tin cậy, có thể mở rộng và hiệu quả. Ngoài công việc, anh thích đi du lịch và viết blog những trải nghiệm của mình trên mạng xã hội.
Srikant Das là Kiến trúc sư giải pháp phòng thí nghiệm tăng tốc tại Amazon Web Services. Anh ấy có hơn 13 năm kinh nghiệm trong lĩnh vực phân tích Dữ liệu lớn và Kỹ thuật dữ liệu, nơi anh ấy thích xây dựng các giải pháp đáng tin cậy, có thể mở rộng và hiệu quả. Ngoài công việc, anh thích đi du lịch và viết blog những trải nghiệm của mình trên mạng xã hội.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/design-a-data-mesh-on-aws-that-reflects-the-envisioned-organization/

