Các hồ dữ liệu ngày càng trở nên phổ biến để lưu trữ lượng lớn dữ liệu từ nhiều nguồn khác nhau theo cách có thể mở rộng và tiết kiệm chi phí. Khi số lượng người sử dụng dữ liệu tăng lên, quản trị viên hồ dữ liệu thường cần triển khai các biện pháp kiểm soát truy cập chi tiết cho các hồ sơ người dùng khác nhau. Họ có thể cần hạn chế quyền truy cập vào một số bảng hoặc cột nhất định tùy thuộc vào loại người dùng đưa ra yêu cầu. Ngoài ra, các doanh nghiệp đôi khi muốn cung cấp dữ liệu cho các ứng dụng bên ngoài nhưng không chắc chắn về cách thực hiện điều đó một cách an toàn. Để giải quyết những thách thức này, các tổ chức có thể chuyển sang GraphQL và Sự hình thành hồ AWS.
GraphQL cung cấp một cách mạnh mẽ, an toàn và linh hoạt để truy vấn và truy xuất dữ liệu. Ứng dụng AWS là dịch vụ tạo API GraphQL có thể truy vấn nhiều cơ sở dữ liệu, vi dịch vụ và API từ một điểm cuối GraphQL thống nhất.
Quản trị viên hồ dữ liệu có thể sử dụng Lake Formation để quản lý quyền truy cập vào hồ dữ liệu. Lake Formation cung cấp các biện pháp kiểm soát quyền truy cập chi tiết để quản lý quyền của người dùng và nhóm ở cấp độ bảng, cột và ô. Do đó, nó có thể đảm bảo tính bảo mật và tuân thủ dữ liệu. Ngoài ra, Lake Formation này tích hợp với các dịch vụ AWS khác, chẳng hạn như amazon Athena, khiến nó trở nên lý tưởng để truy vấn các hồ dữ liệu thông qua API.
Trong bài đăng này, chúng tôi trình bày cách xây dựng một ứng dụng có thể trích xuất dữ liệu từ hồ dữ liệu thông qua API GraphQL và cung cấp kết quả cho các loại người dùng khác nhau dựa trên đặc quyền truy cập dữ liệu cụ thể của họ. Ứng dụng mẫu được mô tả trong bài viết này được xây dựng bởi Đối tác AWS Công nghệ NETSOL.
Tổng quan về giải pháp
Giải pháp của chúng tôi sử dụng Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) để lưu trữ dữ liệu, Keo AWS Danh mục dữ liệu để chứa lược đồ dữ liệu và Lake Formation để cung cấp khả năng quản trị đối với các đối tượng Danh mục dữ liệu của AWS Glue bằng cách triển khai quyền truy cập dựa trên vai trò. Chúng tôi cũng dùng Sự kiện Amazon để nắm bắt các sự kiện trong hồ dữ liệu của chúng tôi và khởi chạy các quy trình tiếp theo. Kiến trúc giải pháp được thể hiện trong sơ đồ sau.
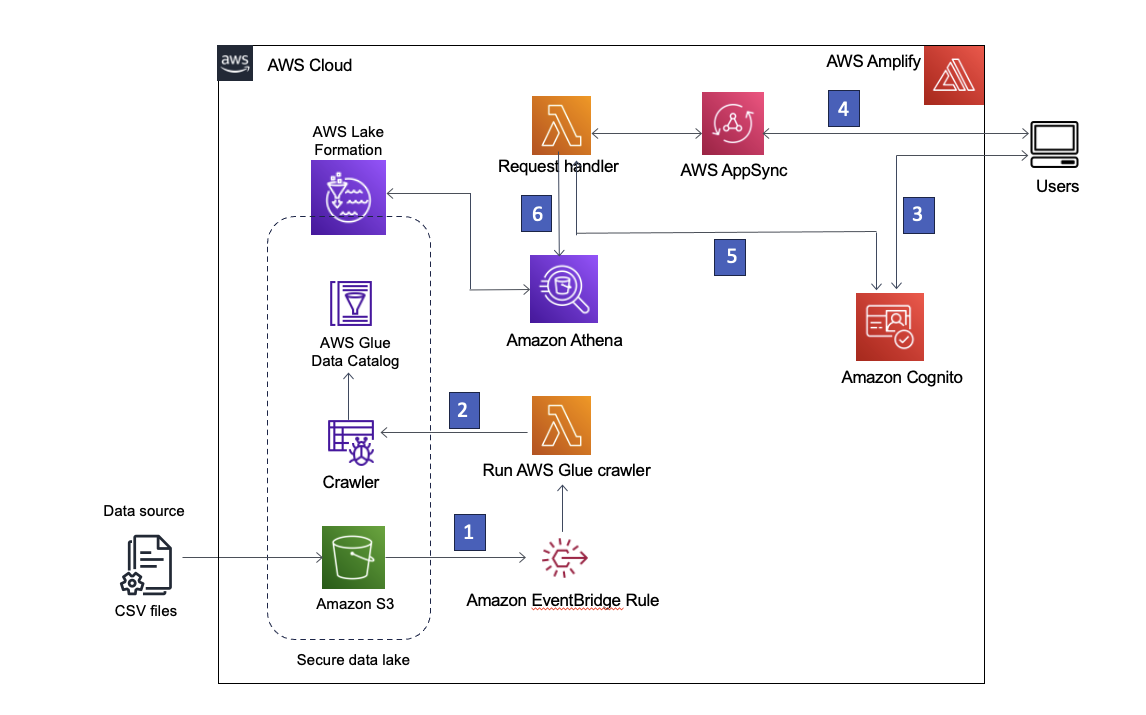
Hình 1 – Kiến trúc giải pháp
Sau đây là mô tả từng bước của giải pháp:
- Hồ dữ liệu được tạo trong nhóm S3 đã đăng ký với Lake Formation. Bất cứ khi nào có dữ liệu mới, quy tắc EventBridge sẽ được gọi.
- Quy tắc EventBridge chạy một AWS Lambda để khởi động trình thu thập thông tin AWS Glue nhằm khám phá dữ liệu mới và cập nhật mọi thay đổi về lược đồ để có thể truy vấn dữ liệu mới nhất.
Lưu ý: Trình thu thập thông tin AWS Glue cũng có thể được khởi chạy trực tiếp từ các sự kiện Amazon S3, như được mô tả trong phần này blog đăng bài. - Amplify AWS cho phép người dùng đăng nhập bằng Nhận thức về Amazon với tư cách là nhà cung cấp danh tính. Cognito xác thực thông tin xác thực của người dùng và trả về mã thông báo truy cập.
- Người dùng được xác thực gọi API GraphQL AWS AppSync thông qua Amplify, tìm nạp dữ liệu từ kho dữ liệu. Một hàm Lambda được chạy để xử lý yêu cầu.
- Hàm Lambda truy xuất chi tiết người dùng từ Cognito và giả định Quản lý truy cập và nhận dạng AWS (IAM) vai trò được liên kết với nhóm người dùng Cognito của người dùng yêu cầu.
- Sau đó, hàm Lambda chạy truy vấn Athena đối với các bảng kho dữ liệu và trả kết quả về AWS AppSync, sau đó trả về kết quả cho người dùng.
Điều kiện tiên quyết
Để triển khai giải pháp này, trước tiên bạn phải làm như sau:
Chuẩn bị quyền hình thành hồ
Đăng nhập vào Bảng điều khiển LakeFormation và thêm chính bạn làm quản trị viên. Nếu bạn đang đăng nhập vào Lake Formation lần đầu tiên, bạn có thể thực hiện việc này bằng cách chọn Thêm bản thân mình trên màn hình Chào mừng đến với Lake Formation và chọn Bắt đầu như trong Hình 2.

Hình 2 – Thêm chính bạn làm quản trị viên Lake Formation
Nếu không, bạn có thể chọn Vai trò và nhiệm vụ quản trị trong thanh điều hướng bên trái và chọn Quản lý quản trị viên để thêm chính mình. Bạn sẽ thấy tên người dùng IAM của mình trong phần Quản trị viên hồ dữ liệu với quyền truy cập đầy đủ khi hoàn tất.
Chọn Cài đặt danh mục dữ liệu trong thanh điều hướng bên trái và đảm bảo hai hộp kiểm soát truy cập IAM không được chọn, như trong Hình 3. Bạn muốn Lake Formation, chứ không phải IAM, kiểm soát quyền truy cập vào cơ sở dữ liệu mới.
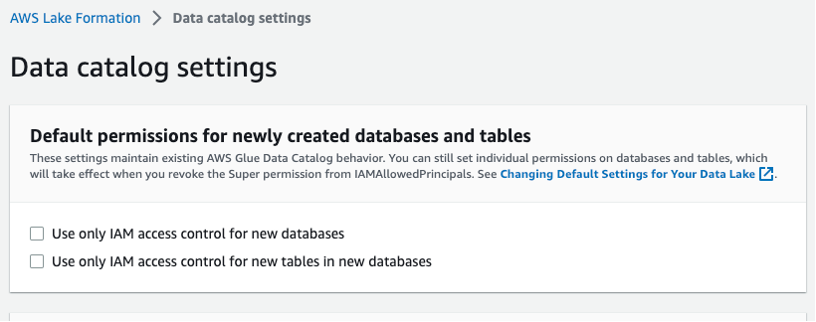
Hình 3 – Cài đặt danh mục dữ liệu Lake Formation
Triển khai giải pháp
Để tạo giải pháp trong môi trường AWS của bạn, hãy khởi chạy ngăn xếp AWS CloudFormation sau: ![]()
Các tài nguyên sau sẽ được khởi chạy thông qua mẫu CloudFormation:
- Amazon VPC và các thành phần mạng (mạng con, nhóm bảo mật và cổng NAT)
- Vai trò IAM
- Lake Formation đóng gói nhóm S3, trình thu thập thông tin AWS Glue và cơ sở dữ liệu AWS Glue
- Các hàm lambda
- Nhóm người dùng Cognito
- API đồ thị AWS AppSync
- Quy tắc EventBridge
Sau khi triển khai các tài nguyên cần thiết từ ngăn xếp CloudFormation, bạn phải tạo hai hàm Lambda và tải tập dữ liệu lên Amazon S3. Lake Formation sẽ quản lý hồ dữ liệu được lưu trữ trong bộ chứa S3.
Tạo các hàm Lambda
Bất cứ khi nào một tệp mới được đặt vào vùng lưu trữ S3 được chỉ định, quy tắc EventBridge sẽ được gọi, quy tắc này sẽ khởi chạy hàm Lambda để khởi chạy trình thu thập thông tin AWS Glue. Trình thu thập thông tin cập nhật Danh mục dữ liệu AWS Glue để phản ánh mọi thay đổi đối với lược đồ.
Khi ứng dụng thực hiện truy vấn dữ liệu thông qua API GraphQL, hàm Lambda xử lý yêu cầu sẽ được gọi để xử lý truy vấn và trả về kết quả.
Để tạo hai hàm Lambda này, hãy tiến hành như sau.
- Đăng nhập vào bảng điều khiển Lambda.
- Chọn hàm Lambda xử lý yêu cầu có tên
dl-dev-crawlerLambdaFunction. - Tìm tệp hàm Lambda của trình thu thập thông tin trong
lambdas/crawler-lambdathư mục trong kho git mà bạn đã sao chép vào máy cục bộ của mình. - Sao chép và dán mã trong tệp đó vào phần Mã của
dl-dev-crawlerLambdaFunctiontrong bảng điều khiển Lambda của bạn. Sau đó chọn Deploy để triển khai chức năng.
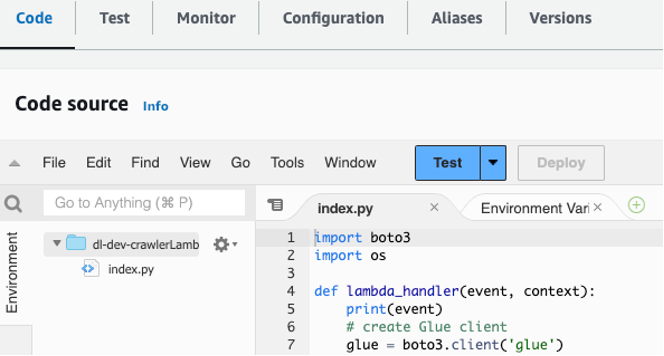
Hình 4 – Sao chép và dán mã vào hàm Lambda
- Lặp lại các bước từ 2 đến 4 cho hàm xử lý yêu cầu có tên
dl-dev-requestHandlerLambdaFunctionsử dụng mã tronglambdas/request-handler-lambda.
Tạo một lớp cho trình xử lý yêu cầu Lambda
Bây giờ, bạn phải tải lên một số mã thư viện bổ sung cần thiết cho hàm Lambda xử lý yêu cầu.
- Chọn Layers ở menu bên trái và chọn Tạo lớp.
- Nhập tên chẳng hạn như
appsync-lambda-layer. - tải về máy tập tin ZIP lớp gói vào máy cục bộ của bạn.
- Tải tệp ZIP lên bằng cách sử dụng Tải lên nút trên Tạo lớp .
- Chọn Python 3.7 làm thời gian chạy cho lớp.
- Chọn Tạo.
- Chọn Chức năng trên menu bên trái và chọn
dl-dev-requestHandlerHàm lambda. - Cuộn xuống Layers phần và chọn Thêm một lớp.
- Chọn hình ba gạch Lớp tùy chỉnh tùy chọn và sau đó chọn lớp bạn đã tạo ở trên.
- Nhấp chuột Thêm.
Tải dữ liệu lên Amazon S3
Điều hướng đến thư mục gốc của kho lưu trữ git nhân bản và chạy các lệnh sau để tải tập dữ liệu mẫu lên. Thay thế cái bucket_name giữ chỗ với nhóm S3 được cung cấp bằng mẫu CloudFormation. Bạn có thể lấy tên nhóm từ bảng điều khiển CloudFormation bằng cách đi tới Kết quả đầu ra tab có phím datalakes3bucketName như thể hiện trong hình dưới đây.

Hình 5 – Tên nhóm S3 được hiển thị trong tab Đầu ra CloudFormation
Nhập các lệnh sau vào thư mục dự án trên máy cục bộ của bạn để tải tập dữ liệu lên bộ chứa S3.
Bây giờ chúng ta hãy xem các hiện vật được triển khai.
Hồ dữ liệu
Nhóm S3 chứa dữ liệu mẫu cho hai thực thể: công ty và chủ sở hữu tương ứng của chúng. Nhóm được đăng ký với Lake Formation, như trong Hình 6. Điều này cho phép Lake Formation tạo và quản lý danh mục dữ liệu cũng như quản lý các quyền trên dữ liệu.

Hình 6 – Bảng điều khiển Lake Formation hiển thị vị trí hồ dữ liệu
Cơ sở dữ liệu được tạo để chứa lược đồ dữ liệu có trong Amazon S3. Trình thu thập thông tin AWS Glue được sử dụng để cập nhật mọi thay đổi về lược đồ trong bộ chứa S3. Trình thu thập thông tin này được cấp quyền TẠO, THAY ĐỔI và THẢ các bảng trong cơ sở dữ liệu bằng cách sử dụng Lake Formation.
Áp dụng các biện pháp kiểm soát truy cập hồ dữ liệu
Hai vai trò IAM được tạo, dl-us-east-1-developer và dl-us-east-1-business-analyst, mỗi nhóm được gán cho một nhóm người dùng Cognito khác nhau. Mỗi vai trò được chỉ định các quyền khác nhau thông qua Lake Formation. Vai trò Nhà phát triển có quyền truy cập vào mọi cột trong hồ dữ liệu, trong khi vai trò Nhà phân tích nghiệp vụ chỉ được cấp quyền truy cập vào các cột thông tin không thể nhận dạng cá nhân (PII).
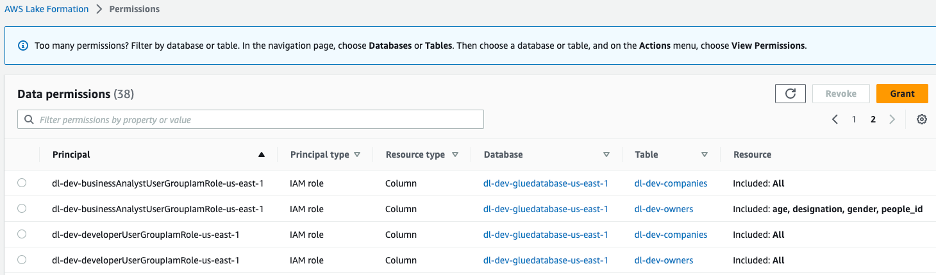
Hình 7 –Các quyền của hồ dữ liệu của bảng điều khiển Lake Formation được gán cho các vai trò nhóm
Lược đồ GraphQL
API GraphQL có thể xem được từ bảng điều khiển AWS AppSync. Các Companies loại bao gồm một số thuộc tính mô tả chủ sở hữu của các công ty.
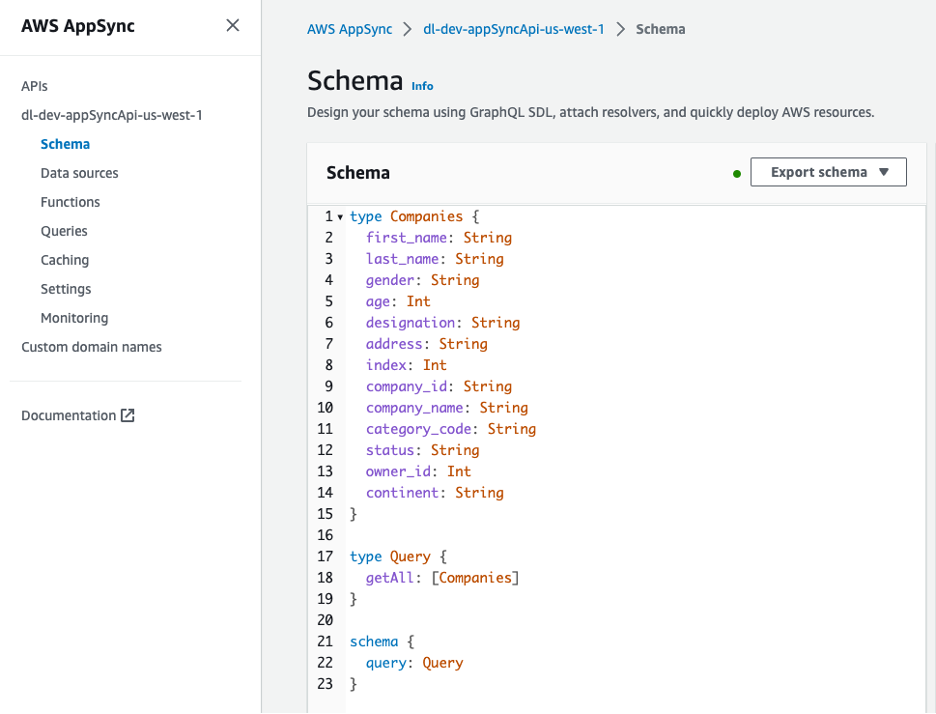
Hình 8 – Lược đồ cho API GraphQL
Nguồn dữ liệu cho API GraphQL là hàm Lambda xử lý các yêu cầu.
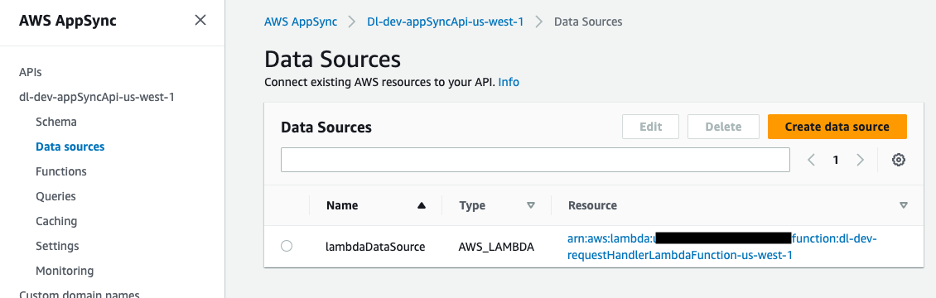
Hình 9 – Nguồn dữ liệu AWS AppSync được ánh xạ tới hàm Lambda
Xử lý các yêu cầu API GraphQL
Hàm Lambda của trình xử lý yêu cầu API GraphQL truy xuất ID nhóm người dùng Cognito từ các biến môi trường. Bằng cách sử dụng thư viện boto3, bạn tạo ứng dụng khách Cognito và sử dụng get_group phương pháp để có được vai trò IAM được liên kết với nhóm người dùng Cognito.
Bạn sử dụng hàm trợ giúp trong hàm Lambda để nhận vai trò.
Sử dụng Dịch vụ mã thông báo bảo mật AWS (AWS STS) thông qua ứng dụng khách boto3, bạn có thể đảm nhận vai trò IAM và nhận thông tin xác thực tạm thời bạn cần để chạy truy vấn Athena.
Chúng tôi chuyển thông tin xác thực tạm thời dưới dạng tham số khi tạo ứng dụng khách Boto3 Amazon Athena.
athena_client = boto3.client('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)Máy khách và truy vấn được chuyển vào hàm trợ giúp truy vấn Athena của chúng tôi để thực thi truy vấn và trả về id truy vấn. Với id truy vấn, chúng tôi có thể đọc kết quả từ S3 và gói nó dưới dạng từ điển Python để trả về trong phản hồi.
Cho phép quyền truy cập phía máy khách vào hồ dữ liệu
Về phía máy khách, AWS Amplify được cấu hình với nhóm người dùng Amazon Cognito để xác thực. Chúng ta sẽ điều hướng tới bảng điều khiển Amazon Cognito để xem nhóm người dùng và các nhóm đã được tạo.
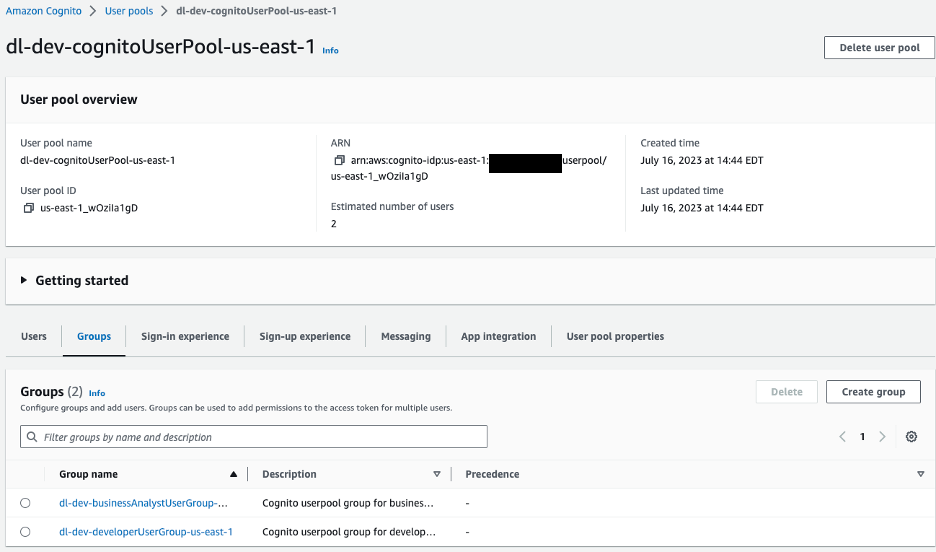
Hình 10 – Nhóm người dùng Amazon Cognito
Đối với ứng dụng mẫu của chúng tôi, chúng tôi có hai nhóm trong nhóm người dùng của mình:
dl-dev-businessAnalystUserGroup– Các nhà phân tích kinh doanh với quyền hạn chế.dl-dev-developerUserGroup– Nhà phát triển có đầy đủ quyền.
Nếu khám phá các nhóm này, bạn sẽ thấy vai trò IAM được liên kết với từng nhóm. Đây là vai trò IAM được gán cho người dùng khi họ xác thực. Athena đảm nhận vai trò này khi truy vấn hồ dữ liệu.
Nếu xem các quyền cho vai trò IAM này, bạn sẽ nhận thấy rằng nó không bao gồm các biện pháp kiểm soát quyền truy cập ở cấp độ bảng dưới. Bạn cần có lớp quản trị bổ sung do Lake Formation cung cấp để bổ sung khả năng kiểm soát truy cập chi tiết.
Sau khi người dùng được Cognito xác minh và xác thực, Amplify sử dụng mã thông báo truy cập để gọi API GraphQL AWS AppSync và tìm nạp dữ liệu. Dựa trên nhóm người dùng, hàm Lambda sẽ đảm nhận vai trò nhóm người dùng Cognito tương ứng. Khi sử dụng vai trò giả định, truy vấn Athena sẽ được chạy và kết quả được trả về cho người dùng.
Tạo người dùng thử nghiệm
Tạo hai người dùng, một dành cho nhà phát triển và một dành cho nhà phân tích kinh doanh rồi thêm họ vào nhóm người dùng.
- Điều hướng đến Cognito và chọn nhóm người dùng,
dl-dev-cognitoUserPool, điều đó đã được tạo. - Chọn Tạo người dùng và cung cấp thông tin chi tiết để tạo người dùng phân tích kinh doanh mới. Tên người dùng có thể là nhà phân tích biz. Để trống địa chỉ email và nhập mật khẩu.
- Chọn hình ba gạch Người dùng tab và chọn người dùng bạn vừa tạo.
- Thêm người dùng này vào nhóm phân tích kinh doanh bằng cách chọn Thêm người dùng vào nhóm .
- Thực hiện theo các bước tương tự để tạo người dùng khác bằng tên người dùng nhà phát triển và thêm người dùng vào nhóm nhà phát triển.
Kiểm tra giải pháp
Để kiểm tra giải pháp của bạn, hãy khởi chạy ứng dụng React trên máy cục bộ của bạn.
- Trong thư mục dự án nhân bản, điều hướng đến
react-appthư mục. - Cài đặt các phụ thuộc của dự án.
- Cài đặt CLI khuếch đại:
- Tạo một tệp mới gọi là
.envbằng cách chạy các lệnh sau. Sau đó sử dụng trình soạn thảo văn bản để cập nhật các giá trị biến môi trường trong tệp.
Sử dụng Kết quả đầu ra tab của ngăn xếp bảng điều khiển CloudFormation của bạn để nhận các giá trị cần thiết từ các khóa như sau:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- Thêm các biến trước vào môi trường của bạn.
- Tạo mã cần thiết để tương tác với API bằng cách sử dụng Khuếch đại CodeGen. Trong tab Đầu ra của bảng điều khiển Cloudformation, hãy tìm ID API AWS Appsync bên cạnh
appsyncApiIdChìa khóa.
Chấp nhận tất cả các tùy chọn mặc định cho lệnh trên bằng cách nhấn đăng ký hạng mục thi tại mỗi dấu nhắc.
- Khởi động ứng dụng.
Bạn có thể xác nhận rằng ứng dụng đang chạy bằng cách truy cập http://localhost:3000 và đăng nhập với tư cách là người dùng nhà phát triển mà bạn đã tạo trước đó.
Bây giờ bạn đã chạy ứng dụng, hãy xem mỗi vai trò được thực hiện như thế nào từ companies điểm cuối.
Đầu tiên, ký tên là vai trò của nhà phát triển, có quyền truy cập vào tất cả các trường và đưa ra yêu cầu API tới điểm cuối của công ty. Lưu ý những trường bạn có quyền truy cập.
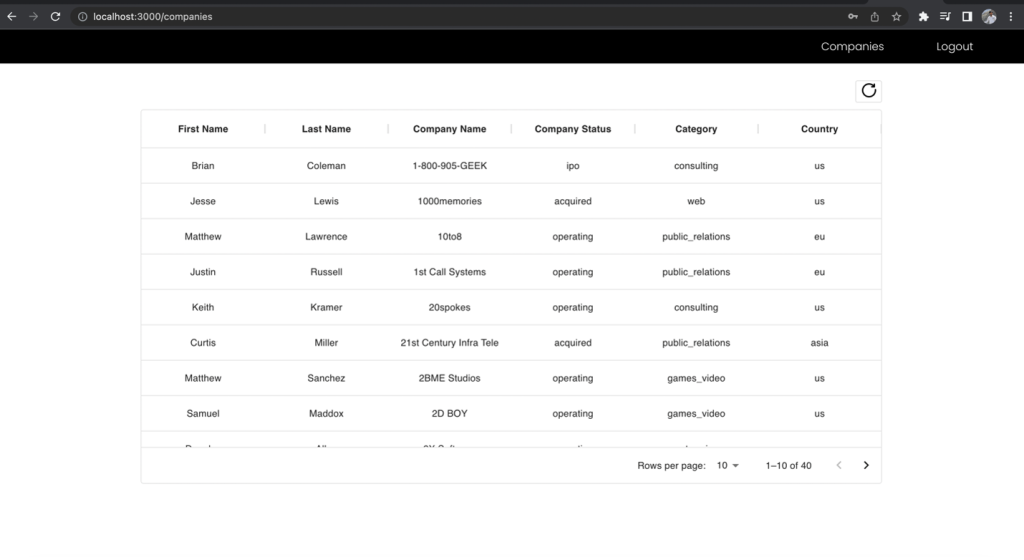
Hình 11 –Kết quả cho vai trò nhà phát triển
Bây giờ, hãy đăng nhập với tư cách là người dùng phân tích kinh doanh và gửi yêu cầu đến cùng một điểm cuối và so sánh các trường được bao gồm.
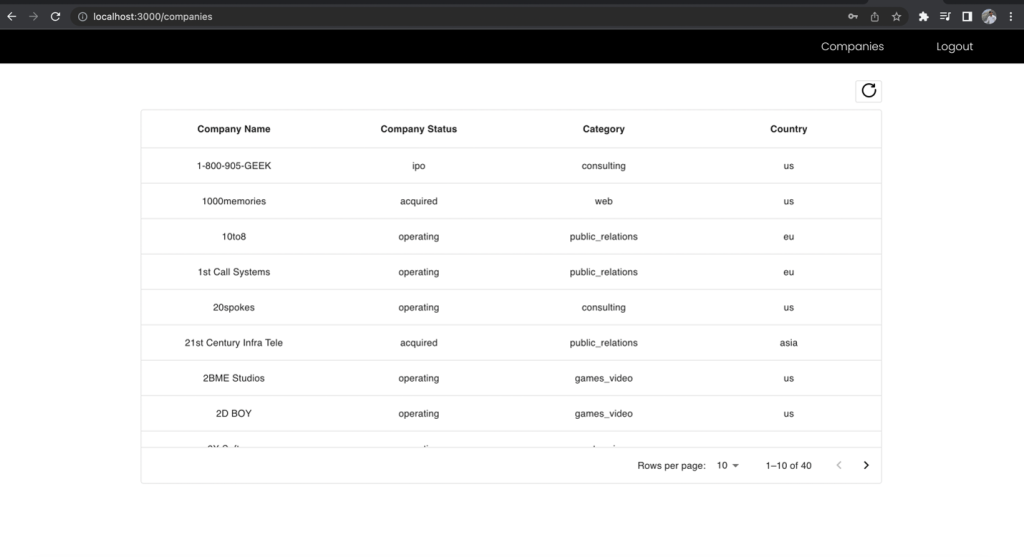
Hình 12 –Kết quả cho vai trò Business Analyst
Cột Họ và Tên của danh sách công ty bị loại trừ trong chế độ xem nhà phân tích kinh doanh ngay cả khi bạn đã thực hiện yêu cầu tới cùng một điểm cuối. Điều này thể hiện sức mạnh của việc sử dụng một điểm cuối GraphQL thống nhất cùng với nhiều vai trò IAM của nhóm người dùng Cognito được ánh xạ tới các quyền của Lake Formation để quản lý quyền truy cập dựa trên vai trò vào dữ liệu của bạn.
Dọn dẹp
Sau khi bạn thử nghiệm xong giải pháp, hãy dọn sạch các tài nguyên sau để tránh phát sinh các khoản phí trong tương lai:
- Làm trống các nhóm S3 được tạo bởi mẫu CloudFormation.
- Xóa ngăn xếp CloudFormation để xóa nhóm S3 và các tài nguyên khác.
Kết luận
Trong bài đăng này, chúng tôi đã chỉ cho bạn cách cung cấp dữ liệu một cách an toàn trong hồ dữ liệu cho những người dùng đã được xác thực của ứng dụng React dựa trên đặc quyền truy cập dựa trên vai trò của họ. Để thực hiện điều này, bạn đã sử dụng API GraphQL trong AWS AppSync, các biện pháp kiểm soát truy cập chi tiết từ Lake Formation và Cognito để xác thực người dùng theo nhóm và ánh xạ họ tới các vai trò IAM. Bạn cũng đã sử dụng Athena để truy vấn dữ liệu.
Để đọc liên quan về chủ đề này, xem Trực quan hóa dữ liệu lớn với AWS AppSync, Amazon Athena và AWS Amplify và Thiết kế kiến trúc lưới dữ liệu bằng AWS Lake Formation và AWS Glue.
Bạn sẽ triển khai phương pháp này để phân phát dữ liệu từ hồ dữ liệu của mình chứ? Hãy cho chúng tôi biết trong phần bình luận!
Về các tác giả
 Rana Dutt là Kiến trúc sư giải pháp chính tại Amazon Web Services. Anh có kiến thức nền tảng về kiến trúc nền tảng phần mềm có thể mở rộng cho các công ty dịch vụ tài chính, chăm sóc sức khỏe và viễn thông, đồng thời rất nhiệt tình giúp đỡ khách hàng xây dựng trên AWS.
Rana Dutt là Kiến trúc sư giải pháp chính tại Amazon Web Services. Anh có kiến thức nền tảng về kiến trúc nền tảng phần mềm có thể mở rộng cho các công ty dịch vụ tài chính, chăm sóc sức khỏe và viễn thông, đồng thời rất nhiệt tình giúp đỡ khách hàng xây dựng trên AWS.
 Ranjith Rayaprolu là Kiến trúc sư giải pháp cấp cao tại AWS làm việc với khách hàng ở Tây Bắc Thái Bình Dương. Anh giúp khách hàng thiết kế và vận hành các giải pháp Kiến trúc tối ưu trong AWS nhằm giải quyết các vấn đề kinh doanh của họ và đẩy nhanh quá trình áp dụng dịch vụ AWS. Anh tập trung vào các công nghệ mạng và bảo mật AWS để phát triển các giải pháp trên đám mây ở các ngành dọc khác nhau. Ranjith sống ở khu vực Seattle và yêu thích các hoạt động ngoài trời.
Ranjith Rayaprolu là Kiến trúc sư giải pháp cấp cao tại AWS làm việc với khách hàng ở Tây Bắc Thái Bình Dương. Anh giúp khách hàng thiết kế và vận hành các giải pháp Kiến trúc tối ưu trong AWS nhằm giải quyết các vấn đề kinh doanh của họ và đẩy nhanh quá trình áp dụng dịch vụ AWS. Anh tập trung vào các công nghệ mạng và bảo mật AWS để phát triển các giải pháp trên đám mây ở các ngành dọc khác nhau. Ranjith sống ở khu vực Seattle và yêu thích các hoạt động ngoài trời.
 Justin Leto là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services với chuyên môn về cơ sở dữ liệu, phân tích dữ liệu lớn và học máy. Niềm đam mê của anh là giúp khách hàng tiếp nhận đám mây tốt hơn. Trong thời gian rảnh rỗi, anh thích chèo thuyền ngoài khơi và chơi piano jazz. Anh sống ở thành phố New York cùng vợ và con gái nhỏ.
Justin Leto là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services với chuyên môn về cơ sở dữ liệu, phân tích dữ liệu lớn và học máy. Niềm đam mê của anh là giúp khách hàng tiếp nhận đám mây tốt hơn. Trong thời gian rảnh rỗi, anh thích chèo thuyền ngoài khơi và chơi piano jazz. Anh sống ở thành phố New York cùng vợ và con gái nhỏ.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/using-aws-appsync-and-aws-lake-formation-to-access-a-secure-data-lake-through-a-graphql-api/

