ABBYY là một công ty công nghệ toàn cầu cung cấp các giải pháp xử lý tài liệu, thu thập dữ liệu và công nghệ dựa trên ngôn ngữ. Nó được thành lập vào năm 1989 bởi một nhóm các nhà ngôn ngữ học và kỹ sư từ Đại học quốc gia Moscow. Tên của công ty là từ viết tắt của “Advanced Business Computer Systems.”
Sản phẩm đầu tiên của ABBYY là từ điển và phần mềm ngôn ngữ cho các thị trường khác nhau. Vào những năm 1990, ABBYY đã mở rộng dòng sản phẩm của mình để bao gồm các ứng dụng quét tài liệu và nhận dạng ký tự quang học (OCR). Các sản phẩm PDF của ABBYY là một số sản phẩm phổ biến nhất trên thị trường. Hơn 100 triệu người sử dụng các sản phẩm ABBYY PDF mỗi ngày. Công ty cố gắng cung cấp các giải pháp chính xác, đáng tin cậy và thân thiện với người dùng mà mọi người đều có thể sử dụng, từ các cá nhân đến các tổ chức lớn.
Bài đăng trên blog này sẽ tổng quan về dòng sản phẩm của họ và một số ưu/nhược điểm khi làm việc cùng nhau. Chúng tôi cũng sẽ so sánh một số sản phẩm của họ với những sản phẩm được cung cấp bởi các công ty hàng đầu khác trong ngành này để bạn có thể quyết định xem chúng có phù hợp với nhu cầu của mình hay không.
Hãy lặn xuống.
ABBYY cung cấp những giải pháp nào?
ABBYY cung cấp đầy đủ các phần mềm chỉnh sửa và chuyển đổi OCR và PDF dễ sử dụng và đáng tin cậy. Sản phẩm của họ cho phép người dùng chuyển đổi tài liệu thành tệp PDF có thể tìm kiếm, chỉnh sửa tệp PDF và trích xuất dữ liệu từ biểu mẫu và bảng. Công ty cũng cung cấp ứng dụng di động cho thiết bị iOS và Android cho phép người dùng quét và chuyển đổi tài liệu giấy sang định dạng kỹ thuật số. Trong phần này, chúng ta sẽ khám phá các dịch vụ khác nhau mà họ cung cấp.
ABBYY thuận lợi
ABBYY Vantage là một giải pháp quản lý tài liệu cho phép bạn tự động hóa các quy trình kinh doanh của mình với sự trợ giúp của các thuật toán thông minh và trí tuệ nhân tạo. Bạn có thể cải thiện hiệu quả quy trình làm việc của mình bằng cách sử dụng công cụ này để chuyển đổi, chú thích, xử lý và trích xuất dữ liệu từ nhiều tài liệu khác nhau. Công cụ này cũng cho phép bạn sử dụng công nghệ OCR cho nhiều mục đích khác nhau như phân loại tài liệu, lập chỉ mục và tìm kiếm. ABBYY Vantage cũng cung cấp khả năng phân tích dữ liệu để giúp các công ty theo dõi xu hướng và có được những hiểu biết mới về hoạt động kinh doanh của họ.
Dòng thời gian ABBYY
ABBYY Timeline là một ứng dụng để trực quan hóa các sự kiện lịch sử từ các tài liệu văn bản phi cấu trúc, chẳng hạn như các bài báo hoặc email. Công cụ này cho phép người dùng xem các khái niệm phát triển như thế nào và xác định các mẫu theo xu hướng theo thời gian. Về cơ bản, ứng dụng này sử dụng các kỹ thuật xử lý ngôn ngữ tự nhiên để xác định các sự kiện từ tài liệu văn bản, sau đó nhóm các sự kiện đó thành các mốc thời gian dựa trên loại sự kiện.
ABBYY FlexiCapture
ABBYY FlexiCapture là bộ phần mềm giúp các tổ chức tự động thu thập các trường chính từ biểu mẫu giấy vào cơ sở dữ liệu hoặc hệ thống CRM của họ. Công cụ này có thể dễ dàng trích xuất dữ liệu từ nhiều biểu mẫu khác nhau, bao gồm hóa đơn, đơn đặt hàng, sao kê ngân hàng, yêu cầu bảo hiểm, v.v.
ABBYY FlexiCapture cho hóa đơn
ABBYY FlexiCapture for Invoices được thiết kế để giúp các doanh nghiệp hợp lý hóa các quy trình quản lý hóa đơn của họ bằng cách tự động hóa các tác vụ xử lý hóa đơn. Giải pháp này cho phép bạn tiết kiệm thời gian bằng cách tự động trích xuất, chuẩn hóa và bổ sung dữ liệu từ hóa đơn với thông tin bổ sung từ cơ sở dữ liệu nội bộ của bạn và tạo các báo cáo tùy chỉnh dựa trên nhu cầu của bạn.
Máy chủ ABBYY FineReader
ABBYY FineReader Server là một giải pháp để chuyển đổi, lập chỉ mục và truy xuất tài liệu tự động ở phía máy chủ. Nó chuyển đổi các tài liệu được quét thành các định dạng có thể chỉnh sửa trong thời gian thực bằng công nghệ OCR (nhận dạng ký tự quang học), do đó cho phép người dùng chỉnh sửa và sử dụng lại chúng khi cần. Giải pháp này cũng cung cấp các tính năng nâng cao như lập chỉ mục chi tiết cho khả năng tìm kiếm và phân tích tài liệu nâng cao để hiểu rõ hơn về cấu trúc nội dung trong số những thứ khác.
Các giải pháp doanh nghiệp từ ABBYY có sẵn để tích hợp với các hệ thống khác nhau thông qua SDK và công cụ dành cho nhà phát triển.
ABBYY FlexiCapture và ABBYY FineReader là hai dịch vụ phổ biến nhất do ABBYY cung cấp. Hãy xem xét kỹ hơn.
ABBYY FlexiCapture có nhiều chức năng chung với ABBYY FineReader Server (trước đây có tên là Recognition Server). Tuy nhiên, mỗi sản phẩm được thiết kế với các chức năng riêng biệt, mà các công ty phải xem xét khi đánh giá các giải pháp cho các yêu cầu thu thập tài liệu và OCR của họ. Để giúp bạn so sánh các sản phẩm dễ dàng hơn, chúng tôi đã biên soạn một danh sách các trường hợp sử dụng cho phép bạn đánh giá giữa ABBYY FlexiCapture và FineReader Server.
Tìm kiếm một giải pháp Nhận dạng Văn bản thông minh? Đi tới Ống nano và sử dụng giải pháp với độ chính xác trên 95%.
Các trường hợp sử dụng kinh doanh của ABBYY Finereader OCR là gì?
ABBYY FineReader Server là chương trình chuyển đổi tài liệu được sử dụng để chuyển đổi tài liệu và hình ảnh thành các định dạng có thể tìm kiếm được. Chương trình hoạt động trên một máy chủ, cho phép chuyển đổi tài liệu quy mô lớn trong khung thời gian xử lý của công ty. Nó cũng có thể cung cấp một phương tiện hiệu quả về chi phí để các công ty nắm bắt và lập chỉ mục thủ công các tài liệu trong toàn doanh nghiệp, thông qua quét tài liệu giấy hoặc xử lý tệp và hình ảnh điện tử. Tuy nhiên, một nhược điểm là nó không cung cấp tính năng chuyển đổi giá trị chữ viết tay hoặc dấu kiểm [1].
Trong hình ảnh bên dưới, bạn có thể thấy mối quan hệ giữa các thành phần của Máy chủ FineReader.
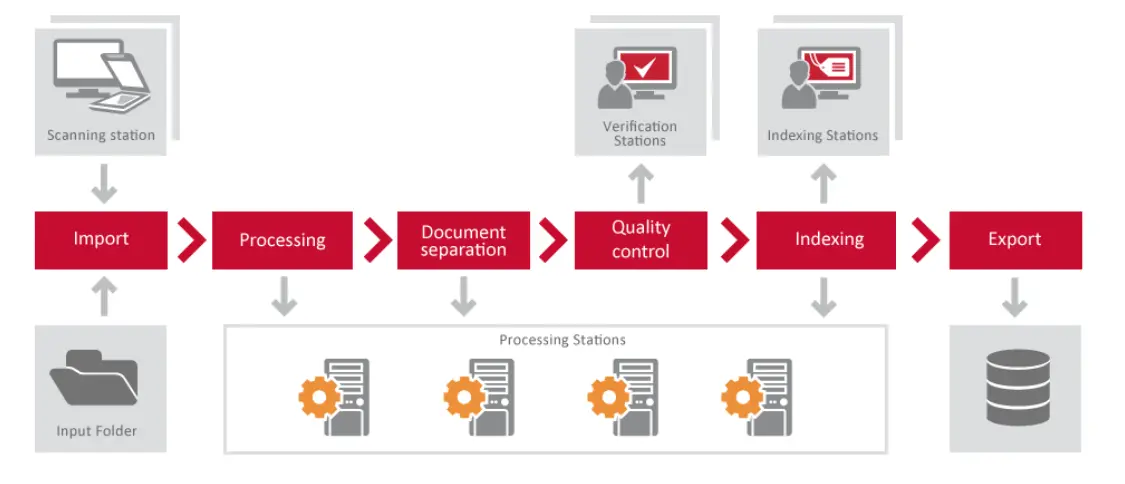
Một số trường hợp sử dụng phổ biến
Xử lý hàng loạt
Giám sát các thư mục được chia sẻ trên mạng và thực hiện chuyển đổi hình ảnh thành văn bản PDF từ hình ảnh hoặc tài liệu. Khi một tệp mới được thêm vào một thư mục, nó sẽ được chuyển đổi thành phiên bản có thể tìm kiếm bằng văn bản và sau đó được chuyển đến thư mục xuất tương ứng trong khi vẫn duy trì chỉ định thư mục con ban đầu. Tệp xuất sẽ duy trì tính toàn vẹn hợp pháp của tệp hình ảnh gốc trong khi thêm một lớp văn bản có thể tìm kiếm phía sau hình ảnh trong tệp PDF trong các thư mục xuất.
Quét tài liệu
Khi bạn quét tài liệu sang định dạng kỹ thuật số, bạn sẽ nhận được thêm lợi ích là có thể sao chép và dán văn bản từ các tài liệu đó vào các tài liệu khác. Tuy nhiên, bạn phải nhập lại văn bản theo cách thủ công nếu không có phần mềm OCR. Thời gian cần thiết để làm điều này có thể là đáng kể. FineReader OCR cho phép người dùng nhanh chóng chuyển đổi các hình ảnh được quét thành các tệp văn bản có thể chỉnh sửa để có thể dễ dàng truy cập và thao tác trong các ứng dụng khác, chẳng hạn như Word hoặc Excel. Điều tương tự cũng xảy ra với các bản fax thường được nhận ở định dạng TIFF và không hỗ trợ chỉnh sửa hoặc thao tác. Sử dụng FineReader OCR, những bản fax này có thể được chuyển đổi thành tệp PDF có thể chỉnh sửa hoặc thậm chí là tài liệu từ chỉ với một vài cú nhấp chuột.
Số hóa tài liệu (Hình ảnh thành văn bản)
ABBYY cung cấp giải pháp trích xuất dữ liệu có thể được sử dụng để chuyển đổi hình ảnh của văn bản in hoặc viết tay sang định dạng có thể chỉnh sửa. Đây là một công cụ quan trọng cho các doanh nghiệp và tổ chức cần số hóa khối lượng lớn tài liệu, chẳng hạn như tài chính, pháp lý hoặc y tế. Quá trình trích xuất dữ liệu có thể tự động trích xuất văn bản từ hình ảnh, sau đó có thể lưu trữ trong cơ sở dữ liệu hoặc chuyển đổi thành PDF có thể tìm kiếm hoặc định dạng tài liệu khác. Giải pháp này có thể tiết kiệm đáng kể thời gian và tiền bạc cho các doanh nghiệp và tổ chức bằng cách giảm nhu cầu nhập dữ liệu thủ công. Ngoài ra, quy trình trích xuất dữ liệu có thể được sử dụng để cải thiện độ chính xác của việc nhập dữ liệu bằng cách cung cấp một phương pháp nhất quán và chính xác để chuyển đổi tài liệu giấy sang định dạng kỹ thuật số.
Dịch máy
ABBYY FineReader OCR có thể được sử dụng làm công cụ dịch máy bằng cách chuyển đổi hình ảnh thành văn bản ở ngôn ngữ khác (dịch máy). Điều này có thể hữu ích nếu bạn muốn cung cấp dịch vụ dịch thuật mà không phải duy trì nhân viên dịch thuật tại địa điểm của mình nhưng vẫn muốn cung cấp bản dịch chất lượng cho khách hàng của mình (hoặc đơn giản là không muốn lãng phí thời gian để tự mình dịch một thứ gì đó).
Trích xuất bảng là quá trình trích xuất dữ liệu từ tệp PDF hoặc hình ảnh của tài liệu bảng thông qua việc sử dụng nhận dạng ký tự quang học (OCR). Nó thường được sử dụng để chuyển đổi các tài liệu giấy được quét, chẳng hạn như biên lai, sang định dạng kỹ thuật số để dữ liệu có thể được xử lý, phân tích và lưu trữ hiệu quả hơn. Có nhiều phần mềm OCR khác nhau trên thị trường nhưng ABBYY FineReader là một trong những lựa chọn phổ biến nhất. Công nghệ này có thể nhận dạng các dòng và ô, đồng thời nó cũng có thể phát hiện các đầu trang và chân trang. Có thể xử lý tài liệu nhiều trang cùng một lúc, giúp tiết kiệm thời gian. Ngoài ra, ABBYY FineReader hỗ trợ nhiều loại ngôn ngữ, lý tưởng cho việc trích xuất dữ liệu từ các tài liệu ở các ngôn ngữ khác nhau.
Bạn muốn tự động nhập dữ liệu từ các tài liệu? Giải pháp OCR dựa trên AI của Nanonets có thể giúp trích xuất thông tin quan trọng từ các tài liệu có cấu trúc / phi cấu trúc và đưa quy trình vào chế độ tự động thí điểm!
Các trường hợp sử dụng kinh doanh của Flexicapture OCR là gì?
ABBYY FlexiCapture chủ yếu là một ứng dụng phần mềm trích xuất dữ liệu cấp doanh nghiệp cung cấp các chức năng nhận dạng ký tự quang học (OCR). FlexiCapture cung cấp một phương tiện để tự động trích xuất thông tin từ các tài liệu dựa trên việc thiết lập các quy tắc, bao gồm các từ khóa và vị trí của dữ liệu trên một trang. FlexiCapture hiện có sẵn trong các gói giải pháp đặc biệt, sẵn sàng hoạt động, chẳng hạn như FlexiCapture cho Hóa đơn và FlexiCapture cho Phòng thư. Mặc dù giải pháp chủ yếu dựa vào việc sử dụng cùng một công nghệ OCR có trong FineReader Server và nó có thể xuất phiên bản có thể tìm kiếm văn bản của tài liệu nếu cần, các chức năng cốt lõi của nó như sau:
- Phân loại tài liệu (xác định loại tài liệu)
- Kết hợp các lớp tài liệu này với các quy tắc trích xuất dữ liệu tương ứng
- Xuất dữ liệu ở đâu đó chẳng hạn như cơ sở dữ liệu, tệp XML hoặc Microsoft Excel.
Khả năng phân loại tài liệu của FlexiCapture có thể được sử dụng để trích xuất và sau đó so sánh các giá trị trường từ các bộ tài liệu. Ví dụ: một đơn xin vay có thể chứa nửa tá tài liệu, một số trong đó có SSN. Có thể dễ dàng định cấu hình quy tắc để so sánh các SSN từ mỗi tài liệu chứa giá trị cho trường này và sau đó trình bày bất kỳ lỗi nào cho người vận hành trong giai đoạn xác minh tài liệu.
Trong hình bên dưới, bạn có thể thấy mối quan hệ giữa các thành phần của Máy chủ FlexiCapture.
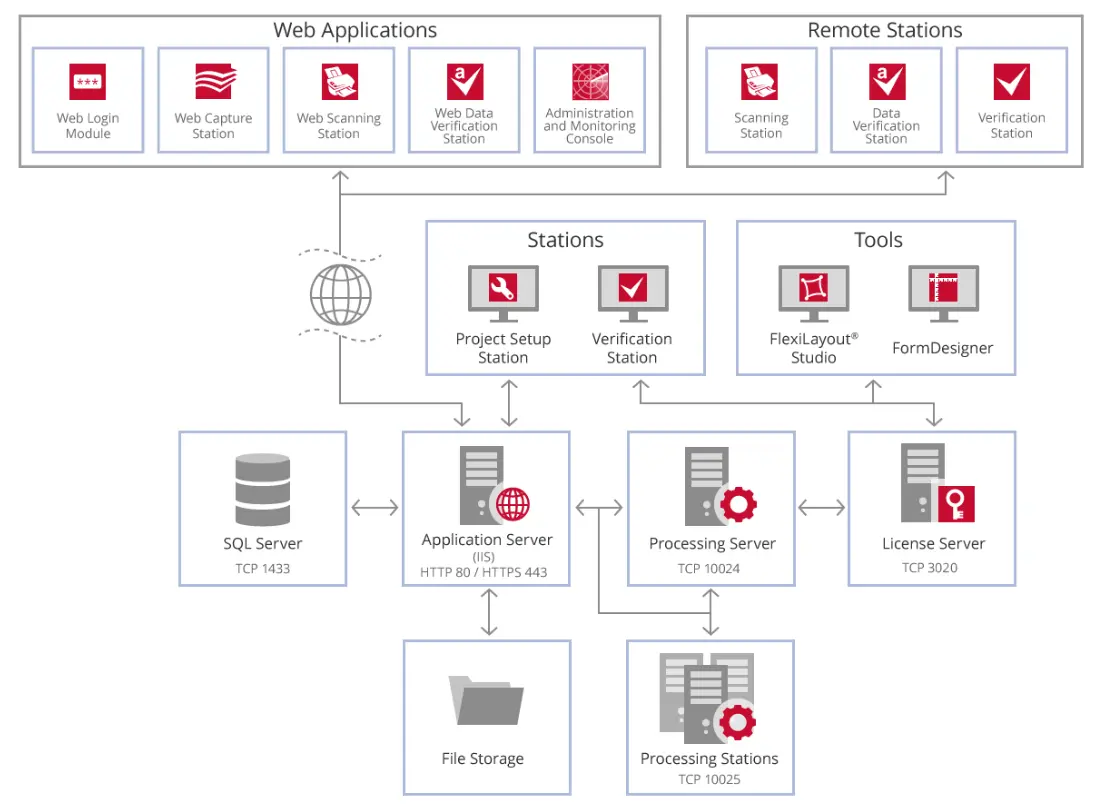
Một số trường hợp sử dụng phổ biến
Kết hợp 2 chiều
ABBYY FineReader có các tính năng có thể giúp bộ phận tài khoản phải trả của bạn hoạt động trơn tru hơn. Điêu nay bao gôm:
- Tự động trích xuất dữ liệu hóa đơn từ chứng từ giấy và chứng từ điện tử
- Kết hợp 2 chiều các mục hàng hóa đơn với giao dịch mua tương ứng trong hệ thống ERP
- Tìm kiếm thông qua hóa đơn có thể tìm kiếm bằng văn bản
- Phê duyệt thanh toán theo số tiền đô la hoặc các quy tắc khác
- Tự động xử lý các đơn đặt hàng đến
Phân loại tài liệu
- Phân loại tài liệu đến theo loại và trích xuất dữ liệu từ tài liệu bằng các quy tắc đã được cấu hình sẵn.
- Xuất phiên bản PDF có thể tìm kiếm văn bản của tài liệu sang hệ thống quản lý nội dung và điền vào các trường bằng dữ liệu được trích xuất từ tài liệu.
- Cung cấp cho người dùng phương tiện sửa dữ liệu được trích xuất cùng với hàng đợi để quản lý các ngoại lệ đối với các quy tắc được lập trình sẵn trong quy trình xử lý tài liệu.
Các giải pháp thay thế hàng đầu cho giải pháp ABBYY

Amazon Textract là dịch vụ tự động trích xuất văn bản và dữ liệu từ tài liệu được quét. Nó vượt xa nhận dạng ký tự quang học đơn giản (OCR) để xác định nội dung của các trường trong biểu mẫu và thông tin được lưu trữ trong bảng.
Amazon AWS Textract là một công cụ mới hơn đang ngày càng phổ biến nhờ chi phí thấp và dễ sử dụng. Đó là lý tưởng để quét một số lượng lớn tài liệu, mặc dù mức độ chính xác của nó không cao bằng ABBYY [2].
Sự khác biệt chính giữa ABBYY và Amazon Textract là trong khi ABBYY cung cấp giải pháp độc lập để trích xuất văn bản từ hình ảnh bằng Nhận dạng ký tự quang học (OCR), thì Amazon cung cấp cho khách hàng API mà họ có thể tích hợp vào ứng dụng của riêng mình. Họ thậm chí còn cung cấp các SDK khác nhau, giúp các nhà phát triển tích hợp tính năng này vào sản phẩm của họ dễ dàng hơn; tuy nhiên, điều này đòi hỏi kiến thức bổ sung về các ngôn ngữ lập trình như Java hoặc Python.
Hơn nữa, không giống như AWS Textract, ABBYY cung cấp khả năng kiểm soát tuyệt đối đối với mọi khía cạnh của quy trình OCR của bạn (ví dụ: nó cho phép bạn tùy chỉnh phân đoạn từ).
Cả ABBYY và AWS Textract đều hoạt động rất tốt về độ chính xác và tốc độ trong hầu hết các trường hợp.
Ưu điểm của Textract
- Bạn có thể sử dụng AWS Textract với mọi ứng dụng xử lý văn bản có SDK.
- AWS Textract hỗ trợ hơn 25 ngôn ngữ trên 200 quốc gia và vùng lãnh thổ. Bạn có thể sử dụng nó để dịch các tệp hình ảnh của mình trong thời gian thực và tạo các quy trình xử lý đa ngôn ngữ.
- Công cụ này tiết kiệm chi phí. Chi phí chỉ 0.0025 USD cho mỗi 100,000 ký tự được xử lý—chưa đến một nửa chi phí so với các giải pháp khác!
- AWS Textract có thể thay đổi quy mô, nghĩa là bạn có thể sử dụng nó ở quy mô lớn hoặc nhỏ, tùy thuộc vào nhu cầu của bạn.
Nhược điểm của Textract
- AWS Textract cần nhiều thời gian và tài nguyên để huấn luyện dữ liệu của bạn trước khi bạn có thể sử dụng dữ liệu đó trong sản xuất.
- Phần mềm nhận dạng ký tự quang học (OCR) hiện đại có thể xác định xem tài liệu đã tải lên là tài liệu gốc hay tài liệu giả mạo bằng cách xác thực ngày tháng, tìm các vùng có pixel và các phương pháp khác. AWS Textract không có khả năng này; nó chỉ có thể trích xuất văn bản từ tài liệu đã tải lên.
- Textract không cho phép tích hợp với các nhà cung cấp ngược dòng và xuôi dòng một cách dễ dàng. Ví dụ: chúng tôi có thể phải xây dựng đường dẫn RPA với dịch vụ của bên thứ ba. Sẽ rất khó để tìm thấy các plugin thích hợp phù hợp với Textract.
ABBYY so với Tesseract

Tesseract OCR được thiết kế để nhận dạng nhiều loại ngôn ngữ được viết bằng mã C++ thuần túy. Nó cũng có thể được biên dịch để sử dụng trên các thiết bị di động như nền tảng Android và iOS. Phần mềm sử dụng các tính năng nâng cao như phát hiện bố cục văn bản theo chiều dọc, cho phép người dùng đọc văn bản từ nhiều góc độ khác nhau mà không làm giảm độ chính xác.
ABBYY và Tesseract cung cấp các giải pháp OCR và tự hào về tỷ lệ chính xác cao cũng như hỗ trợ nhiều ngôn ngữ khác nhau. Tuy nhiên, có một số khác biệt quan trọng giữa hai. ABBYY cung cấp giao diện thân thiện với người dùng hơn, khiến nó trở nên lý tưởng cho những người mới sử dụng OCR. Nó cũng cung cấp nhiều tính năng hơn, chẳng hạn như xuất nhiều định dạng và thực hiện chỉnh sửa hình ảnh. Mặt khác, Tesseract là nguồn mở và do đó miễn phí sử dụng. Nó cũng có một động cơ chính xác hơn, làm cho nó trở thành lựa chọn tốt hơn cho những người cần mức độ chính xác cao nhất có thể.
Ưu điểm của Tesseract
- Nó hoạt động với nhiều ngôn ngữ khác nhau với nhiều phông chữ khác nhau, bao gồm chữ viết La Mã, Cyrillic, chữ Hán, tiếng Do Thái, tiếng Ả Rập và tiếng Thái.
- Mã nguồn có sẵn theo giấy phép Apache, do đó, nó được sử dụng và sửa đổi miễn phí. Nó cũng có dung lượng bộ nhớ thấp so với các công cụ OCR khác, vì vậy nó không chiếm quá nhiều dung lượng trên máy tính hoặc điện thoại thông minh của bạn.
- Tesseract rất linh hoạt và có thể được sử dụng cho nhiều tác vụ khác nhau, từ Nhận dạng ký tự quang học (OCR) đơn giản đến các tác vụ phức tạp hơn như Học máy (ML).
Nhược điểm của Tesseract
- Tesseract không phải lúc nào cũng tạo ra kết quả hoàn hảo, đặc biệt với văn bản viết tay hoặc phức tạp.
- Quá trình xử lý hình ảnh của Tesseract còn thô sơ; do đó, bạn cần sử dụng bộ tiền xử lý hoặc ảnh đã được xử lý sẵn để thu được kết quả tốt nhất [8].
ABBYY so với Ephesoft

Ephesoft là một công cụ nhận dạng tài liệu khác sử dụng công nghệ nhận dạng ký tự quang học (OCR) để chuyển đổi hình ảnh thành tệp văn bản. Phần mềm này được thiết kế dành riêng cho các doanh nghiệp cần một giải pháp quản lý khối lượng lớn tài liệu giấy như hóa đơn hoặc phiếu thu. Giống như các sản phẩm của ABBYY, Ephesoft có thể được sử dụng trong nhiều ngành, bao gồm chăm sóc sức khỏe, chính phủ, tài chính và sản xuất.
Cả hai bộ phần mềm đều cung cấp nhiều tính năng và lợi ích, nhưng có một số khác biệt quan trọng giữa chúng. Ví dụ: ABBYY thường được coi là chính xác hơn Ephesoft [6]t, đặc biệt khi nhận dạng văn bản trong tài liệu có bố cục phức tạp. Tuy nhiên, Ephesoft thường nhanh hơn ABBYY, khiến nó trở thành lựa chọn tốt cho các tổ chức phải xử lý khối lượng lớn tài liệu hàng ngày. Về giá cả, ABBYY thường đắt hơn Ephesoft, mặc dù cả hai công ty đều giảm giá khi cấp phép số lượng lớn. Cuối cùng, phần mềm OCR tốt nhất cho doanh nghiệp của bạn sẽ phụ thuộc vào nhu cầu và ngân sách cụ thể của bạn.
Ưu điểm của Ephesoft
- Hệ thống có chức năng theo dõi giúp theo dõi sự thay đổi tài liệu của người dùng. Điều này có thể hữu ích để ngăn chặn gian lận và theo dõi xem ai đã thực hiện các thay đổi khi nhiều người dùng cùng làm việc trên một tài liệu.
- Ephesoft sử dụng các kỹ thuật nâng cao chất lượng hình ảnh để trích xuất dữ liệu từ hình ảnh, chẳng hạn như OCR (Nhận dạng ký tự quang học), nhận dạng mã vạch và nhận dạng ký tự. Điều này làm tăng đáng kể độ chính xác của việc trích xuất dữ liệu so với các phương pháp thủ công, trong đó dữ liệu có thể không hoàn toàn chính xác hoặc đầy đủ do chất lượng hình ảnh kém hoặc các yếu tố khác.
- Hỗ trợ các tài liệu bằng nhiều ngôn ngữ, chẳng hạn như tiếng Anh, tiếng Tây Ban Nha, tiếng Pháp, v.v., làm cho nó phù hợp với các ngành có cơ sở khách hàng đa dạng sử dụng các ngôn ngữ khác nhau làm phương thức giao tiếp/tài liệu chính của họ.
Nhược điểm của Ephesoft
- Nó cần đào tạo thích hợp trước khi sử dụng nó. Nếu bạn chưa từng có kinh nghiệm làm việc với loại phần mềm này, thì bạn có thể thấy khó sử dụng nó một cách hiệu quả. Tuy nhiên, một khi bạn đã quen với nó, bạn sẽ rất dễ dàng sử dụng sản phẩm này một cách hiệu quả trong môi trường kinh doanh của mình.
- Phần mềm Ephesoft có giá cao hơn so với các sản phẩm tương tự khác trên thị trường. Khoản đầu tư ban đầu cần thiết để mua Ephesoft có thể cao, nhưng chi phí có thể giảm bằng cách chọn phiên bản đám mây [7].
ABBYY so với siêu khoa học

Các mô hình máy học độc quyền của Hyperscience và công nghệ nhận dạng ký tự quang học (OCR) mạnh mẽ mang lại khả năng trích xuất dữ liệu vô song cho các biểu mẫu viết tay, cùng với các tài liệu có cấu trúc và bán cấu trúc khác. Nền tảng này tự hào có báo cáo hiệu suất vượt trội, đảm bảo chất lượng tích hợp và trích xuất cấp cao để thu thập và phân tích tài liệu chính xác và nhanh chóng.
Cả ABBYY và Hyperscience đều cung cấp các giải pháp OCR trên nền tảng đám mây và máy tính để bàn. Nếu bạn cần OCR một khối lượng lớn tài liệu, ABBYY có thể là một lựa chọn tốt hơn vì bạn sẽ có thể xử lý chúng theo lô bằng ứng dụng dành cho máy tính để bàn.
Công cụ OCR của ABBYY dựa trên trí tuệ nhân tạo (AI), trong khi công cụ OCR của Hyperscience dựa trên học máy (ML). Điều này có nghĩa là ABBYY có thể học hỏi và cải thiện theo thời gian, trong khi Hyperscience sẽ luôn tạo ra kết quả phù hợp với dữ liệu đào tạo của mình. Vì vậy, nếu bạn cần một công cụ OCR có thể thích ứng với các điều kiện thay đổi (ví dụ: phông chữ khác, hình ảnh chất lượng kém, v.v.), thì ABBYY có thể là lựa chọn tốt hơn. Tuy nhiên, nếu bạn cần một công cụ OCR luôn tạo ra mức độ chính xác cao như nhau, bất kể tài liệu đầu vào là gì, thì Hyperscience có thể là một lựa chọn tốt hơn.
ABBYY vs. Đọc sách

Readiris là một công cụ OCR mạnh mẽ và chính xác, có thể được sử dụng để chuyển đổi các tài liệu và hình ảnh được quét thành văn bản có thể chỉnh sửa và tìm kiếm được. Nó cung cấp một loạt các tính năng và tùy chọn, làm cho nó trở thành một giải pháp OCR linh hoạt và mạnh mẽ cho các nhu cầu khác nhau.
Readiris là một trong những lựa chọn thay thế phổ biến cho ABBYY FineReader. Nó cũng là một chương trình OCR với nhiều tính năng và nhiều người dùng.
Ưu điểm của Readiris
- Xử lý tài liệu nhanh hơn 20%
- Chỉnh sửa văn bản được nhúng trong hình ảnh của bạn bằng OCR
- Chuyển đổi tài liệu Microsoft Office sang PDF
- Chú thích và bình luận
- Bảo vệ và ký các tệp PDF
- Tích hợp với máy in (máy quét Twain) [3]
Nhược điểm của Readiris
- Giá có thể đắt khi làm việc với dữ liệu khổng lồ.
- Độ chính xác có thể thấp khi làm việc với dữ liệu phi cấu trúc so với các công cụ khác [4]
ABBYY so với Google Cloud Vision

Google Cloud Vision OCR là một giải pháp phân tích hình ảnh và nhận dạng văn bản dựa trên đám mây. Dịch vụ này sử dụng các thuật toán học sâu để xử lý hình ảnh và video, nhận dạng đối tượng, cảnh và khuôn mặt cũng như phát hiện văn bản bằng hơn 100 ngôn ngữ.
Ưu điểm của Google Cloud Vision
- Kết quả chính xác và đáng tin cậy—Google sử dụng các mô hình học sâu cho dịch vụ OCR của mình, điều đó có nghĩa là Google tìm hiểu thêm về cách tài liệu cụ thể của bạn được định dạng theo thời gian, cải thiện độ chính xác của tài liệu theo thời gian.
- Nó tương thích với hầu hết các loại tệp—Google Cloud Vision OCR hoạt động với các tệp JPEG, PNG, BMP, TIFF, PDF và GIF động! Bạn thậm chí có thể chuyển đổi các trang HTML thành văn bản thuần túy bằng Google Cloud Vision OCR (mặc dù không phải tất cả định dạng sẽ được giữ nguyên).
- Thật dễ sử dụng—tất cả những gì bạn cần làm là tải lên một hình ảnh có chứa văn bản bạn muốn chuyển đổi và nhấp vào “Tạo văn bản” trong bảng điều khiển Google Cloud Vision. Bạn không cần cài đặt bất kỳ phần mềm nào hoặc tải xuống bất kỳ thư viện phần mềm nào.
- Cung cấp giao diện API để tích hợp với phần mềm tùy chỉnh.
Nhược điểm của Google Cloud Vision
- Nó yêu cầu kết nối internet (có nghĩa là bạn không thể sử dụng ngoại tuyến).
- Nó chậm để xử lý khối lượng dữ liệu lớn. Bạn có thể sử dụng giải pháp này cho lượng văn bản từ nhỏ đến trung bình, nhưng nếu bạn muốn xử lý lượng lớn văn bản ở chế độ hàng loạt, thì giải pháp này có thể không đủ nhanh cho nhu cầu của bạn.
- Trong một số trường hợp như trích xuất bảng, độ chính xác của Google Cloud Vision OCR không cao bằng các công cụ khác [5].
Bạn muốn tự động nhập dữ liệu từ các tài liệu? Giải pháp OCR dựa trên AI của Nanonets có thể giúp trích xuất thông tin quan trọng từ các tài liệu có cấu trúc / phi cấu trúc và đưa quy trình vào chế độ tự động thí điểm!
ABBYY so với Nanonet

Nanonets là một phần mềm OCR dựa trên AI để tự động hóa thu thập dữ liệu cho xử lý tài liệu thông minh của hóa đơn, biên lai, thẻ ID, v.v. Nanonets sử dụng OCR tiên tiến, xử lý hình ảnh học máyvà Deep Learning để trích xuất thông tin liên quan từ dữ liệu phi cấu trúc. Nó nhanh, chính xác, dễ sử dụng, cho phép người dùng xây dựng các mô hình OCR tùy chỉnh từ đầu và có một số tích hợp Zapier gọn gàng. Số hóa tài liệu, trích xuất trường dữ liệu và tích hợp với các ứng dụng hàng ngày của bạn thông qua API trong một giao diện đơn giản, trực quan.
Ưu điểm của Nanonet
- UI hiện đại
- Xử lý khối lượng lớn tài liệu
- giá hợp lý
- Dễ sử dụng
- Nắm bắt nhận thức về dữ liệu - dẫn đến can thiệp tối thiểu
- Không yêu cầu nhóm nhà phát triển nội bộ
- Thuật toán / mô hình có thể được đào tạo / đào tạo lại
- Tài liệu và hỗ trợ tuyệt vời
- Rất nhiều tùy chọn tùy chỉnh
- Nhiều lựa chọn các tùy chọn tích hợp
- Hoạt động với các ngôn ngữ không phải tiếng Anh hoặc nhiều ngôn ngữ
- Hầu như không cần xử lý hậu kỳ
- Tích hợp 2 chiều liền mạch với nhiều phần mềm kế toán
- API OCR tuyệt vời cho nhà phát triển
Nhược điểm của Nanonet
- Không thể xử lý đột biến âm lượng rất cao
- Giao diện người dùng chụp bảng có thể tốt hơn.
So sánh và Đánh giá Giá ABBYY
|
Công cụ |
Hỗ trợ ngôn ngữ |
Demo |
GIÁ CẢ |
|
|
Adobe Acrobat Pro DC |
Hơn 100 ngôn ngữ |
7 ngày |
Bắt đầu từ 14.99$/tháng |
đám mây |
|
ĐọcIRIS |
Hơn 130 ngôn ngữ |
30 ngày |
Bắt đầu từ 129$/tháng |
Windows và Mac |
|
ABBY FineReader |
Hơn 198 ngôn ngữ |
7 ngày |
$ 117 / năm |
Windows, iOS, Android và Mac. |
|
Tầm nhìn đám mây của Google |
Hơn 130 ngôn ngữ |
Miễn phí |
Phiên bản miễn phí $ 1.5 trên 1000 đơn vị |
Đám mây, API |
|
Ống nano |
Hơn 100 ngôn ngữ |
MIỄN PHÍ |
Phiên bản miễn phí Pro: $ 499 / tháng |
Đám mây, Windows và Mac |
|
Tesseract |
Hơn 120 ngôn ngữ |
MIỄN PHÍ |
MIỄN PHÍ |
Windows |
Tại sao chọn Nanonets thay vì ABBYY?
Nanonets là một phần mềm OCR sử dụng trí thông minh nhân tạo để tự động trích xuất các bảng từ tài liệu PDF, hình ảnh và tệp được quét. Không giống như các giải pháp khác, nó không yêu cầu các quy tắc và mẫu riêng biệt cho từng loại tài liệu mới. Thay vào đó, nó dựa vào trí thông minh nhận thức để xử lý các tài liệu bán cấu trúc và không nhìn thấy được đồng thời cải thiện theo thời gian. Bạn cũng có thể tùy chỉnh đầu ra để chỉ trích xuất các bảng hoặc mục dữ liệu mà bạn quan tâm.
Nó nhanh, chính xác, dễ sử dụng, cho phép người dùng xây dựng các mô hình OCR tùy chỉnh từ đầu và có một số tích hợp Zapier gọn gàng. Số hóa tài liệu, trích xuất bảng hoặc trường dữ liệu và tích hợp với các ứng dụng hàng ngày của bạn thông qua API trong một giao diện trực quan, đơn giản.
Tại sao Nanonets là OCR tốt nhất?
- Nanonet có thể trích xuất dữ liệu trên trang trong khi trình phân tích cú pháp PDF dòng lệnh chỉ trích xuất các đối tượng, tiêu đề & siêu dữ liệu như (tiêu đề, trang, trạng thái mã hóa, v.v.)
- Công nghệ phân tích cú pháp PDF nanonets không dựa trên mẫu. Ngoài việc cung cấp các mô hình được đào tạo trước cho các trường hợp sử dụng phổ biến, thuật toán phân tích cú pháp PDF Nanonets cũng có thể xử lý các loại tài liệu không nhìn thấy!
- Ngoài việc xử lý các tài liệu PDF gốc, khả năng OCR tích hợp của Nanonet cho phép nó xử lý các tài liệu và hình ảnh được quét!
- Các tính năng tự động hóa mạnh mẽ với khả năng AI và ML.
- Nanonet xử lý dữ liệu phi cấu trúc, các ràng buộc dữ liệu phổ biến, tài liệu PDF nhiều trang, bảng và mục nhiều dòng một cách dễ dàng.
- Nanonets là một công cụ không mã có thể liên tục tự học và tự đào tạo lại trên dữ liệu tùy chỉnh để cung cấp kết quả đầu ra mà không cần xử lý hậu kỳ.
Phân tích cú pháp hóa đơn tự động bằng Nanonets – tạo quy trình xử lý hóa đơn hoàn toàn không chạm.
Tích hợp các công cụ hiện có của bạn với Nanonet và tự động hóa việc thu thập dữ liệu, lưu trữ xuất và ghi sổ kế toán.
Nanonet cũng có thể giúp tự động hóa quy trình phân tích cú pháp hóa đơn bằng cách:
- Nhập và tổng hợp dữ liệu hóa đơn từ nhiều nguồn - email, tài liệu được quét, tệp / hình ảnh kỹ thuật số, lưu trữ đám mây, ERP, API, v.v.
- Thu thập và trích xuất dữ liệu hóa đơn một cách thông minh từ các hóa đơn, biên lai, hóa đơn và các tài liệu tài chính khác.
- Phân loại và mã hóa các giao dịch dựa trên các quy tắc kinh doanh.
- Thiết lập quy trình phê duyệt tự động để nhận phê duyệt nội bộ và quản lý các trường hợp ngoại lệ.
- Đối chiếu tất cả các giao dịch.
- Tích hợp hoàn toàn với ERP hoặc phần mềm kế toán như Quickbooks, Sage, Xero, Netsuite, v.v.
dự án
[1] Tôi có thể nhận dạng văn bản viết tay trong ABBYY FineReader không? - Trung tâm trợ giúp
[2] ABBYY FineReader VS Amazon Textract – so sánh sự khác biệt & đánh giá?
[3] 7 Phần mềm OCR tốt nhất năm 2022 (Miễn phí và TRẢ TIỀN)
[4] Top 10 phần mềm OCR năm 2022 | Giải pháp OCR tốt nhất
[6] Ephesoft so với FineReader PDF cho Windows và Mac 2022 | G2
[7] 21 Phần mềm OCR tốt nhất năm 2022
[8] Tesseract OCR trong Python với Pytesseract & OpenCV
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://nanonets.com/blog/abbyy-reviews-compare-competitors-alternatives/

