Giới thiệu
Bài viết này sẽ xem xét kỹ thuật thị giác máy tính của Phân đoạn ngữ nghĩa hình ảnh. Mặc dù điều này nghe có vẻ phức tạp nhưng chúng tôi sẽ chia nhỏ nó ra từng bước và sẽ giới thiệu một khái niệm thú vị về phân đoạn ngữ nghĩa hình ảnh, đây là một cách triển khai sử dụng các biến áp dự đoán dày đặc hoặc viết tắt là DPT từ bộ sưu tập Ôm Mặt. Sử dụng DPT giới thiệu một giai đoạn mới của thị giác máy tính với những khả năng khác thường.
Mục tiêu học tập
- So sánh DPT với sự hiểu biết thông thường về các kết nối ở xa.
- Triển khai phân đoạn ngữ nghĩa thông qua dự đoán độ sâu với DPT trong Python.
- Khám phá các thiết kế DPT, hiểu những đặc điểm độc đáo của chúng.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Phân đoạn ngữ nghĩa hình ảnh là gì?
Hãy tưởng tượng bạn có một hình ảnh và muốn gắn nhãn cho từng pixel trong đó theo những gì nó đại diện. Đó là ý tưởng đằng sau việc phân đoạn ngữ nghĩa hình ảnh. Nó có thể được sử dụng trong thị giác máy tính, phân biệt một chiếc ô tô với một cái cây hoặc tách các phần của hình ảnh; đây là tất cả về việc gắn nhãn pixel thông minh. Tuy nhiên, thách thức thực sự nằm ở việc hiểu được bối cảnh và mối quan hệ giữa các đối tượng. Chúng ta hãy so sánh điều này với, cho phép tôi nói, cách tiếp cận cũ để xử lý hình ảnh.
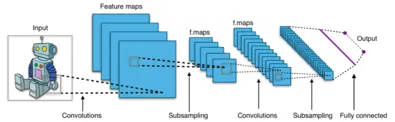
Mạng thần kinh hợp pháp (CNN)
Bước đột phá đầu tiên là sử dụng Mạng lưới thần kinh chuyển đổi để giải quyết các nhiệm vụ liên quan đến hình ảnh. Tuy nhiên, CNN có những hạn chế, đặc biệt là trong việc ghi lại các kết nối tầm xa trong hình ảnh. Hãy tưởng tượng nếu bạn đang cố gắng hiểu cách các phần tử khác nhau trong một hình ảnh tương tác với nhau qua khoảng cách xa — đó là điều mà các CNN truyền thống gặp khó khăn. Đây là nơi chúng tôi kỷ niệm DPT. Những mô hình này, bắt nguồn từ kiến trúc máy biến áp mạnh mẽ, thể hiện khả năng nắm bắt các liên kết. Chúng ta sẽ thấy DPT tiếp theo.
Máy biến áp dự đoán dày đặc (DPT) là gì?
Để hiểu khái niệm này, hãy tưởng tượng việc kết hợp sức mạnh của Transformers mà chúng ta đã từng biết trong NLP nhiệm vụ phân tích hình ảnh. Đó là khái niệm đằng sau Máy biến áp dự đoán dày đặc. Họ giống như những siêu thám tử của thế giới hình ảnh. Chúng có khả năng không chỉ gắn nhãn pixel trong hình ảnh mà còn dự đoán độ sâu của từng pixel - loại pixel này cung cấp thông tin về khoảng cách giữa mỗi đối tượng với hình ảnh. Chúng ta sẽ thấy điều này dưới đây.
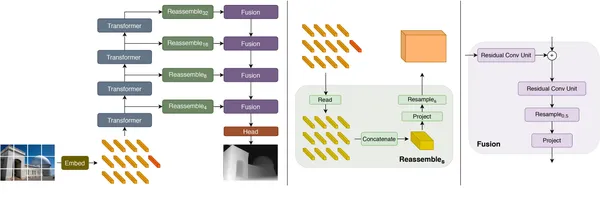
Hộp công cụ của DPT Architecture
DPT có nhiều loại khác nhau, mỗi loại có lớp “bộ mã hóa” và “bộ giải mã”. Chúng ta hãy xem xét hai cái phổ biến ở đây:
- Máy biến áp DPT-Swin: Hãy nghĩ về một máy biến áp lớn với 10 lớp mã hóa và 5 lớp giải mã. Thật tuyệt vời khi hiểu được mối quan hệ giữa các phần tử ở các cấp độ trong hình ảnh.
- DPT-ResNet: Con này giống như một thám tử thông minh với 18 lớp mã hóa và 5 lớp giải mã. Nó vượt trội trong việc phát hiện các kết nối giữa các vật thể ở xa trong khi vẫn giữ nguyên cấu trúc không gian của hình ảnh.
Các tính năng chính
Dưới đây là cái nhìn sâu hơn về cách DPT hoạt động bằng cách sử dụng một số tính năng chính:
- Khai thác tính năng phân cấp: Giống như Mạng thần kinh chuyển đổi truyền thống (CNN), DPT trích xuất các tính năng từ hình ảnh đầu vào. Tuy nhiên, họ tuân theo cách tiếp cận phân cấp trong đó hình ảnh được chia thành các mức độ chi tiết khác nhau. Chính hệ thống phân cấp này giúp nắm bắt cả bối cảnh cục bộ và toàn cầu, cho phép mô hình hiểu được mối quan hệ giữa các đối tượng ở các quy mô khác nhau.
- Cơ chế tự chú ý: Đây là xương sống của DPT lấy cảm hứng từ kiến trúc Transformer ban đầu, cho phép mô hình nắm bắt các phần phụ thuộc tầm xa trong hình ảnh và tìm hiểu các mối quan hệ phức tạp giữa các pixel. Mỗi pixel xem xét thông tin từ tất cả các pixel khác, giúp mô hình hiểu biết toàn diện về hình ảnh.
Trình diễn Python về phân đoạn ngữ nghĩa hình ảnh bằng DPT
Chúng ta sẽ thấy việc triển khai DPT bên dưới. Trước tiên, hãy thiết lập môi trường của chúng ta bằng cách cài đặt các thư viện chưa được cài đặt sẵn trên Colab. Bạn có thể tìm thấy mã cho điều này tại đây hoặc tại https://github.com/inuwamobarak/semantic-segmentation
Đầu tiên, chúng tôi cài đặt và thiết lập môi trường của mình.
!pip install -q git+https://github.com/huggingface/transformers.gitTiếp theo, chúng tôi chuẩn bị mô hình mà chúng tôi dự định đào tạo.
## Define model # Import the DPTForSemanticSegmentation from the Transformers library
from transformers import DPTForSemanticSegmentation # Create the DPTForSemanticSegmentation model and load the pre-trained weights
# The "Intel/dpt-large-ade" model is a large-scale model trained on the ADE20K dataset
model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")Bây giờ chúng tôi tải và chuẩn bị một hình ảnh mà chúng tôi muốn sử dụng để phân đoạn.
# Import the Image class from the PIL (Python Imaging Library) module
from PIL import Image import requests # URL of the image to be downloaded
url = 'https://img.freepik.com/free-photo/happy-lady-hugging-her-white-friendly-dog-while-walking-park_171337-19281.jpg?w=740&t=st=1689214254~exp=1689214854~hmac=a8de6eb251268aec16ed61da3f0ffb02a6137935a571a4a0eabfc959536b03dd' # The `stream=True` parameter ensures that the response is not immediately downloaded, but is kept in memory
response = requests.get(url, stream=True) # Create the Image class
image = Image.open(response.raw) # Display image
image
from torchvision.transforms import Compose, Resize, ToTensor, Normalize # Set the desired height and width for the input image
net_h = net_w = 480 # Define a series of image transformations
transform = Compose([ # Resize the image Resize((net_h, net_w)), # Convert the image to a PyTorch tensor ToTensor(), # Normalize the image Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), ])Bước tiếp theo từ đây sẽ là áp dụng một số chuyển đổi cho hình ảnh.
# Transform input image
pixel_values = transform(image) pixel_values = pixel_values.unsqueeze(0)Tiếp theo là chúng tôi chuyển tiếp vượt qua.
import torch # Disable gradient computation
with torch.no_grad(): # Perform a forward pass through the model outputs = model(pixel_values) # Obtain the logits (raw predictions) from the output logits = outputs.logitsBây giờ, chúng ta in ra hình ảnh dưới dạng nhiều mảng. Chúng tôi sẽ chuyển đổi điều này bên cạnh hình ảnh với dự đoán ngữ nghĩa.
import torch # Interpolate the logits to the original image size
prediction = torch.nn.functional.interpolate( logits, size=image.size[::-1], # Reverse the size of the original image (width, height) mode="bicubic", align_corners=False
) # Convert logits to class predictions
prediction = torch.argmax(prediction, dim=1) + 1 # Squeeze the prediction tensor to remove dimensions
prediction = prediction.squeeze() # Move the prediction tensor to the CPU and convert it to a numpy array
prediction = prediction.cpu().numpy()Chúng tôi thực hiện dự đoán ngữ nghĩa ngay bây giờ.
from PIL import Image # Convert the prediction array to an image
predicted_seg = Image.fromarray(prediction.squeeze().astype('uint8')) # Apply the color map to the predicted segmentation image
predicted_seg.putpalette(adepallete) # Blend the original image and the predicted segmentation image
out = Image.blend(image, predicted_seg.convert("RGB"), alpha=0.5)
Ở đó chúng ta có hình ảnh của mình với ngữ nghĩa được dự đoán. Bạn có thể thử nghiệm với hình ảnh của riêng bạn. Bây giờ chúng ta hãy xem một số đánh giá đã được áp dụng cho DPT.
Đánh giá hiệu suất trên DPT
DPT đã được thử nghiệm trong nhiều công việc và bài báo nghiên cứu cũng như được sử dụng trên các sân chơi hình ảnh khác nhau như bộ dữ liệu Cityscapes, PASCAL VOC và ADE20K và chúng hoạt động tốt hơn các mô hình CNN truyền thống. Các liên kết đến tập dữ liệu và tài liệu nghiên cứu này sẽ có trong phần liên kết bên dưới.
Trên Cityscapes, DPT-Swin-Transformer đạt 79.1% trên chỉ số giao điểm trung bình trên kết hợp (mIoU). Trên PASCAL VOC, DPT-ResNet đạt được mIoU là 82.8% theo tiêu chuẩn mới. Những điểm số này là minh chứng cho khả năng hiểu sâu hình ảnh của DPT.
Tương lai của DPT và những gì ở phía trước
DPT là một kỷ nguyên mới trong việc hiểu hình ảnh. Nghiên cứu về DPT đang thay đổi cách chúng ta nhìn và tương tác với hình ảnh, đồng thời mang đến những khả năng mới. Tóm lại, Phân đoạn ngữ nghĩa hình ảnh bằng DPT là một bước đột phá đang thay đổi cách chúng ta giải mã hình ảnh và chắc chắn sẽ làm được nhiều điều hơn thế trong tương lai. Từ nhãn pixel đến hiểu biết sâu sắc, DPT là những gì có thể thực hiện được trong thế giới thị giác máy tính. Chúng ta hãy nhìn sâu hơn.
Ước tính độ sâu chính xác
Một trong những đóng góp quan trọng nhất của DPT là dự đoán thông tin độ sâu từ hình ảnh. Tiến bộ này có các ứng dụng như tái tạo cảnh 3D, thực tế tăng cường và thao tác đối tượng. Điều này sẽ cung cấp sự hiểu biết quan trọng về sự sắp xếp không gian của các vật thể trong một khung cảnh.
Dự đoán độ sâu và phân đoạn ngữ nghĩa đồng thời
DPT có thể cung cấp cả phân đoạn ngữ nghĩa và dự đoán độ sâu trong một khung thống nhất. Điều này cho phép hiểu biết toàn diện về hình ảnh, cho phép ứng dụng cả thông tin ngữ nghĩa và kiến thức chuyên sâu. Ví dụ, trong lái xe tự động, sự kết hợp này rất quan trọng để điều hướng an toàn.
Giảm nỗ lực thu thập dữ liệu
DPT có khả năng làm giảm bớt nhu cầu ghi nhãn thủ công cho dữ liệu độ sâu. Hình ảnh huấn luyện có bản đồ độ sâu đi kèm có thể học cách dự đoán độ sâu mà không cần chú thích độ sâu theo pixel. Điều này làm giảm đáng kể chi phí và công sức liên quan đến việc thu thập dữ liệu.
Hiểu cảnh
Chúng cho phép máy móc hiểu được môi trường của chúng theo ba chiều, điều này rất quan trọng để robot điều hướng và tương tác hiệu quả. Trong các ngành như sản xuất và hậu cần, DPT có thể hỗ trợ tự động hóa bằng cách cho phép robot điều khiển các vật thể với sự hiểu biết sâu sắc hơn về các mối quan hệ không gian.
Máy biến áp dự đoán dày đặc đang định hình lại lĩnh vực thị giác máy tính bằng cách cung cấp thông tin chuyên sâu chính xác cùng với sự hiểu biết về ngữ nghĩa của hình ảnh. Tuy nhiên, việc giải quyết các thách thức liên quan đến ước tính độ sâu chi tiết, khái quát hóa, ước tính độ không đảm bảo, giảm thiểu sai lệch và tối ưu hóa thời gian thực sẽ rất quan trọng để nhận ra đầy đủ tác động biến đổi của DPT trong tương lai.
Kết luận
Phân đoạn ngữ nghĩa hình ảnh bằng cách sử dụng Biến áp dự đoán dày đặc là một hành trình kết hợp ghi nhãn pixel với hiểu biết sâu sắc về không gian. Sự kết hợp của DPT với phân đoạn ngữ nghĩa hình ảnh mở ra một con đường thú vị trong nghiên cứu thị giác máy tính. Bài viết này đã tìm cách làm sáng tỏ những điểm phức tạp cơ bản của DPT, từ kiến trúc đến khả năng thực hiện và tiềm năng đầy hứa hẹn để định hình lại tương lai của phân đoạn ngữ nghĩa trong thị giác máy tính.
Chìa khóa chính
- DPT vượt ra ngoài pixel để hiểu bối cảnh không gian và dự đoán độ sâu.
- DPT vượt trội hơn khả năng nhận dạng hình ảnh truyền thống, ghi lại khoảng cách và thông tin chi tiết 3D.
- DPT xác định lại hình ảnh nhận thức, cho phép hiểu sâu hơn về các đối tượng và mối quan hệ.
Những câu hỏi thường gặp
Câu trả lời 1: Mặc dù DPT được thiết kế chủ yếu để phân tích hình ảnh nhưng các nguyên tắc cơ bản của chúng có thể truyền cảm hứng cho việc điều chỉnh cho các dạng dữ liệu khác. Ý tưởng nắm bắt bối cảnh và các mối quan hệ thông qua máy biến áp có những ứng dụng tiềm năng trong các lĩnh vực.
Câu trả lời 2: DPT có tiềm năng trong thực tế tăng cường thông qua việc sắp xếp và tương tác đối tượng chính xác hơn trong môi trường ảo.
Câu trả lời 3: Các phương pháp nhận dạng hình ảnh truyền thống, như CNN, tập trung vào việc gắn nhãn các đối tượng trong hình ảnh mà không nắm bắt đầy đủ bối cảnh hoặc bố cục không gian của chúng nhưng các mô hình DPT còn tiến xa hơn bằng cách vừa xác định đối tượng vừa dự đoán độ sâu của chúng.
A4: Các ứng dụng rất rộng rãi. Họ có thể tăng cường khả năng lái tự động bằng cách giúp ô tô hiểu và điều hướng các môi trường phức tạp. Họ có thể xử lý hình ảnh y tế thông qua phân tích chính xác và chi tiết. Ngoài ra, DPT còn có khả năng cải thiện khả năng nhận dạng đối tượng trong chế tạo robot, cải thiện khả năng hiểu cảnh trong nhiếp ảnh và thậm chí hỗ trợ trải nghiệm thực tế tăng cường.
Câu trả lời 5: Có, có nhiều loại kiến trúc DPT khác nhau. Hai ví dụ nổi bật bao gồm DPT-Swin-Transformer và DPT-ResNet trong đó DPT-Swin-Transformer có cơ chế chú ý phân cấp cho phép nó hiểu mối quan hệ giữa các thành phần hình ảnh ở các cấp độ khác nhau. Và DPT-ResNet kết hợp các cơ chế chú ý còn lại để nắm bắt các yếu tố phụ thuộc tầm xa trong khi vẫn bảo toàn cấu trúc không gian của hình ảnh.
Liên kết:
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/09/image-semantic-segmentation-using-dense-prediction-transformers/

